
先週、私は3つのテストサイトでは問題なく動いていた Python スクリプトのデバッグに40分も費やしました。ところが4つ目のサイトにアクセスした瞬間、その裏に Cloudflare がいることに気づいたのです。スクレイパーはずっと「Checking your browser…」ページを繰り返し表示し、返ってくるのはチャレンジ用の HTML ばかり。心当たり、ありませんか?
もし似た壁にぶつかったことがあるなら、あなただけではありません。が今では Cloudflare を利用しており、インターネット上のがその対象です。つまり、リード獲得、価格監視、不動産リサーチ、競合分析など、Web データを集めようとする人にとって Cloudflare は最も一般的な障壁だということです。
問題は、多くのガイドがあらゆる回避手法をただ横並びで紹介するだけで、自分の状況ではどれを最初に試すべきかを教えてくれないことです。このガイドでは、優先順位付きの判断ツリー、率直な成功率の目安、そして多くの記事が完全に見落としているノーコードの選択肢まで含めて整理します。
- 難易度: 初級〜中級(使う方法による)
- 所要時間: ノーコードなら約10〜30分。コードベースの方法は内容次第
- 必要なもの: Chrome ブラウザ(ノーコードの場合)、必要に応じて Python 3.9 以上(コード方法の場合)、そして対象 URL
Cloudflare の保護とは何か、そしてなぜスクレイパーを止めるのか?
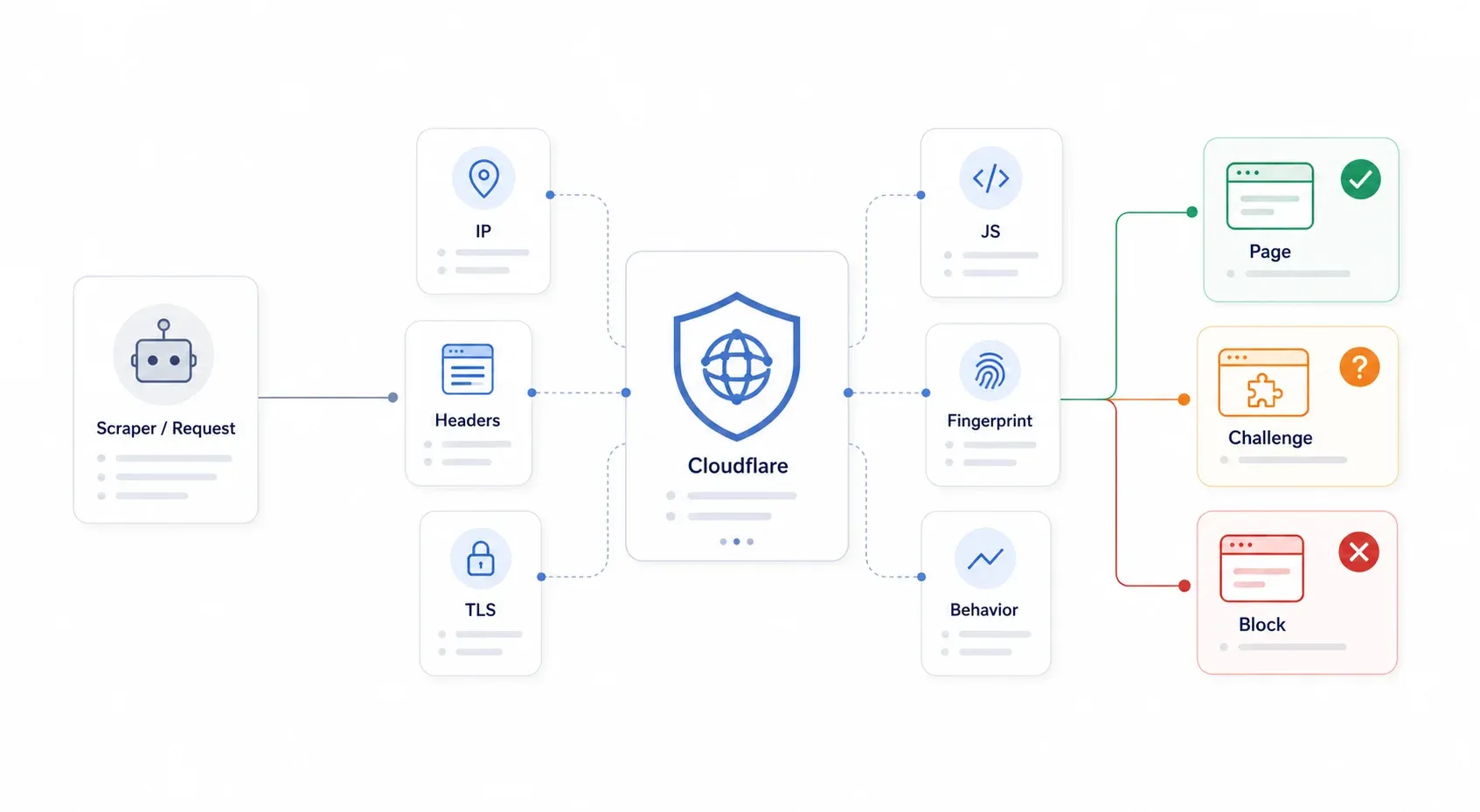
Cloudflare は、訪問者とサイトのオリジンサーバーの間に入るリバースプロキシです。すべてのリクエストはまず Cloudflare のエッジを通過し、そこでページを返すか、訪問者にチャレンジを出すか、完全に遮断するかが決まります。大事なのは、Cloudflare があなたのスクレイパーを「悪意あるもの」と知る必要はないという点です。自動化度が高い、あるいは疑わしいリクエストだと判断できれば十分なのです。
Cloudflare のは、単一の鍵ではなく、複数層のセキュリティゲートのように働きます。IP の評判、HTTP ヘッダー、TLS フィンガープリント、JavaScript 実行、ブラウザフィンガープリント、行動パターンまで確認します。Python の requests で Cloudflare 保護ページに GET すると、TLS ハンドシェイクが不自然、JavaScript を実行しない、Cookie がない、ブラウザらしい指紋がない、といった複数の層で弾かれます。単純なヘッダー偽装が何年も前に効かなくなったのはこのためです。
よくある症状は、403 Forbidden、503 とともに表示される「Checking your browser…」、1020 Access Denied、無限に続くチャレンジループ、解けない Turnstile、そして本来 JSON が返るはずなのに HTML のチャレンジページが返る、などです。
パッシブ検知:ページが開く前に Cloudflare がチェックしていること
ページを見る前の時点で、Cloudflare のパッシブ層はすでにリクエストを採点しています。
- IP の評判: データセンター IP、クラウド事業者のレンジ、既知のプロキシ出口は警戒されます。住宅回線やモバイル回線の IP の方がです。2026年のコミュニティ報告でも、ローカルの住宅回線ブラウジングは通るのに、Docker や VPS 環境だとブロックされるという話が一貫して見られます。
- HTTP ヘッダー分析: Cloudflare は User-Agent、Accept-Language、ヘッダー順序、HTTP バージョンを比較します。たとえば Chrome 136 を名乗っているのに TLS ハンドシェイクが「Python らしさ」を強く出していれば、一発で怪しまれます。
- TLS フィンガープリント(JA3/JA4): TLS ハンドシェイクの際、クライアントは対応暗号スイート、拡張、プロトコル優先度のパターンを明かします。 はそれを識別子に圧縮します。本物の Chrome と Python の
requestsでは、この「形」がまったく違います。 - HTTP/2 フィンガープリント: ブラウザと HTTP ライブラリでは、HTTP/2 の SETTINGS フレーム、擬似ヘッダーの順序、優先度の振る舞いが異なります。Cloudflare の は単発リクエストだけでなく、時間経過に伴うリクエスト間パターンも追跡します。
- AI Labyrinth: これは Cloudflare の新しい罠です。怪しいクローラーを単にブロックするのではなく、して、クローラーのリソースを消費させます。スクレイパー自身が捕まったことに気づかない場合もあります。
アクティブ検知:ブラウザ内で動くチャレンジ
パッシブチェックだけでは判断できないとき、Cloudflare はアクティブチャレンジに切り替えます。
- JavaScript チャレンジ: おなじみの「Checking your browser…」の中間ページです。Cloudflare の は、見えないスクリプトで自動化リクエストを判定します。
- Turnstile: Cloudflare の CAPTCHA 代替です。には Managed、Non-Interactive、Invisible があります。目に見えるパズルを出さなくても、マウス操作、ブラウザ環境、TLS フィンガープリントなどを分析します。
- Canvas と WebGL のフィンガープリント: これらのチェックは、ヘッドレスブラウザの描画が本物のブラウザと違うことを検出します。
- 行動シグナル: リクエストの間隔、スクロールのパターン、クリックの順序。3秒で50ページを取得し、マウス移動がゼロのスクレイパーは、人間とは到底見えません。
実務上の結論としては、Cloudflare がアクティブチャレンジまで上げてきたら、requests、httpx、あるいは curl_cffi のような素の HTTP クライアントでは通れません。本物のブラウザ環境を実行できるものが必要です。
Cloudflare 保護の段階:同じスクリプトがあるサイトでは動いて別のサイトでは失敗する理由
これは多くの回避ガイドが完全に見落としている点です。Cloudflare の保護は一律ではありません。Free プランで「Security Level: Medium」のサイトと、Enterprise で Bot Management と Turnstile が有効なサイトとでは、まったく別の難易度です。片方を軽々抜けるスクリプトが、もう片方では壁にぶつかるのは当然です。
| Cloudflare の段階 | 一般的な防御 | 回避の難易度 | たいてい有効な方法 |
|---|---|---|---|
| Free プラン(低セキュリティ) | Bot Fight Mode、基本的な WAF ルール、IP の評判 | ⭐ 低 | 内部 API の発見、適切なヘッダー付きの curl_cffi、本物のブラウザセッション |
| Pro プラン(中程度) | Super Bot Fight Mode、Managed Challenge、JavaScript 検知 | ⭐⭐ 中 | 本物のブラウザセッション、ステルス系ブラウザ自動化、住宅プロキシ |
| Business | より強い WAF、Bot Analytics、重要パスでの厳しいチャレンジ | ⭐⭐⭐ 中〜高 | ブラウザセッション抽出、セッション維持、住宅/モバイルプロキシ、有料スクレイピング API |
| Enterprise / Bot Management | Bot スコア、JA3/JA4 フィールド、エンドポイントごとのルール、Turnstile、AI Labyrinth | ⭐⭐⭐⭐ 高 | 内部 API(使えるなら)、実ユーザーセッション系ツール、プロバイダ級のスクレイピング API |
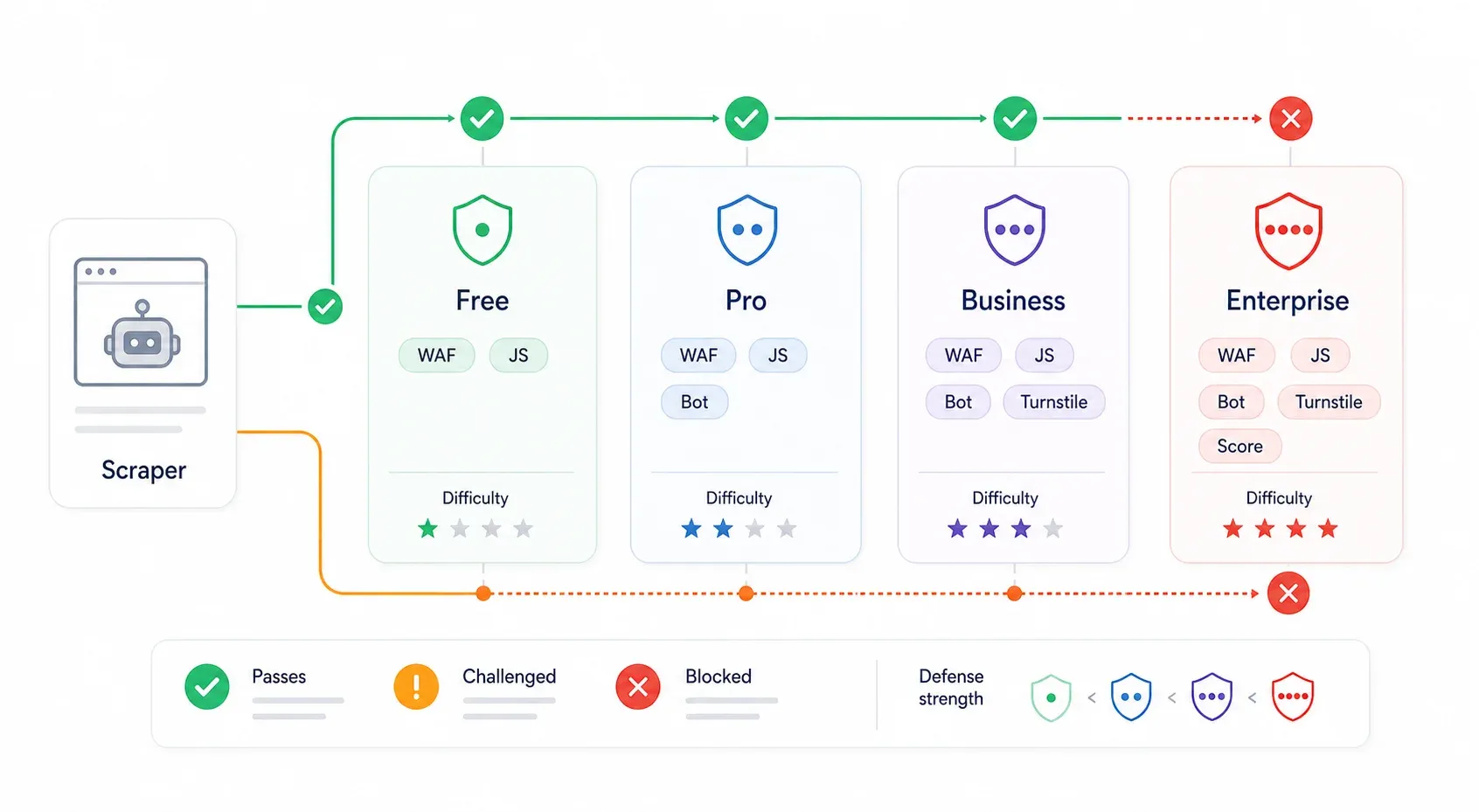
によると、Free は $0、Pro は月額 $20、Business は月額 $200、Enterprise は個別見積もりです。 は Free プラン向けのシンプルな切り替え、 は Pro/Business 向けの追加制御、Enterprise Bot Management はより細かい Bot スコアとエンドポイント単位のルールを追加します。
おおまかに階層を見分ける方法: Cloudflare ロゴ付きのブロックでチャレンジスクリプトが出ない 403 は、WAF かフィンガープリント拒否の可能性が高いです。cf-turnstile の div や challenges.cloudflare.com/turnstile/v0/api.js のスクリプトが見えれば Turnstile です。「Checking your browser」の中間ページなら Managed Challenge です。ホームページは正常に見えるのに特定パスだけ失敗するなら、エンドポイント単位の WAF または Bot Management ルールの可能性が高いです。
どの方法を選ぶにしても、まず保護レベルを見極めること。これだけで何時間ものデバッグを節約できます。
Cloudflare 回避でまず試すべきことを決めるフローチャート
やみくもに試すのではなく、優先順位に従って進めましょう。簡単で成功率の高いものから始め、必要になったら段階的に上げます。
| ステップ | まず試すこと | 理由 | 失敗したら → |
|---|---|---|---|
| 1 | 内部 / 非公開 API を探す | Cloudflare を完全に迂回でき、最速で最も安定 | ステップ 2 |
| 2 | ブラウザレンダリング内蔵のノーコードツールを使う(例: Thunderbit) | 設定不要、JS チャレンジを自動処理 | ステップ 3 |
| 3 | TLS フィンガープリントの偽装(curl_cffi) | 高速・軽量、ブラウザ不要 | ステップ 4 |
| 4 | ステルス系ブラウザ自動化(SeleniumBase UC / Puppeteer stealth) | JS チャレンジとフィンガープリントに対応 | ステップ 5 |
| 5 | FlareSolverr + Docker | オープンソースでサーバー向き | ステップ 6 |
| 6 | 有料スクレイピング API(ScrapingBee、ZenRows、Scrapfly など) | いたちごっこを丸ごと外部化できる | — |
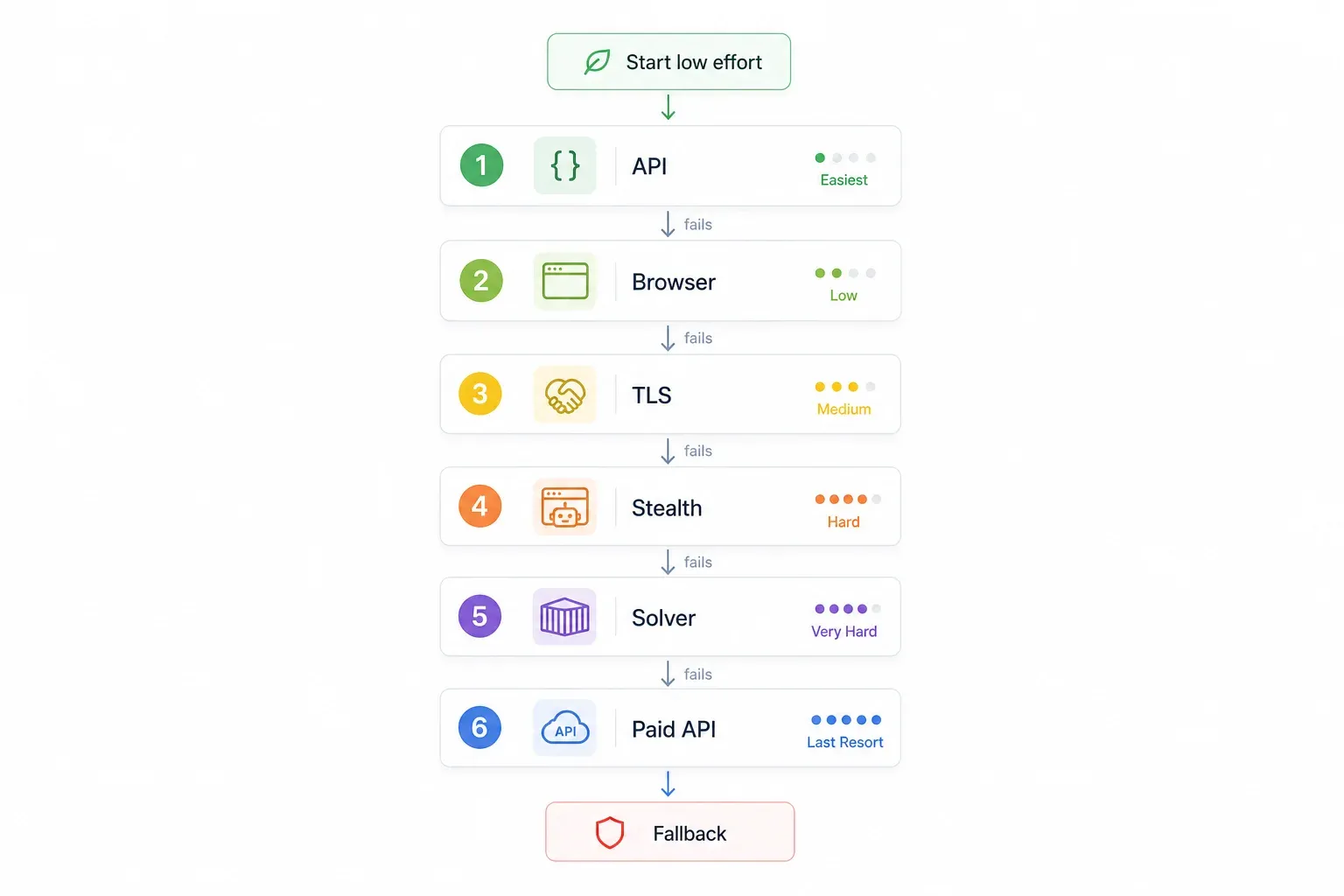
考え方はシンプルです。無料で手間の少ない方法を先に、コードが重くて有料のものは最後に回します。自分の状況に合うステップから始めてください。
2026年3月のコミュニティベンチマークでは、curl_cffi がテスト対象20ドメインの16件(80%)を通過し、FlareSolverr はおおよそ55〜70% をカバー、そして有料のプロキシ集約サービスは平均約97% の成功率に達したとされています。ただし同じスレッドでも、Cloudflare の更新で数値はすぐ変わると注意されています。成功率はあくまで目安であり、保証ではありません。
ステップ1: 戦わずに抜ける — Cloudflare の裏にある内部 API を探す
私が目にした4つのフォーラムスレッドは、Cloudflare と正面から戦うよりもサイトの内部 API を見つけることを勧めていました。率直に言って、これが最も賢い最初の一手です。内部 API があるなら、Cloudflare を完全に迂回できます。小細工も、フィンガープリント偽装も、ステルスプラグインも不要です。
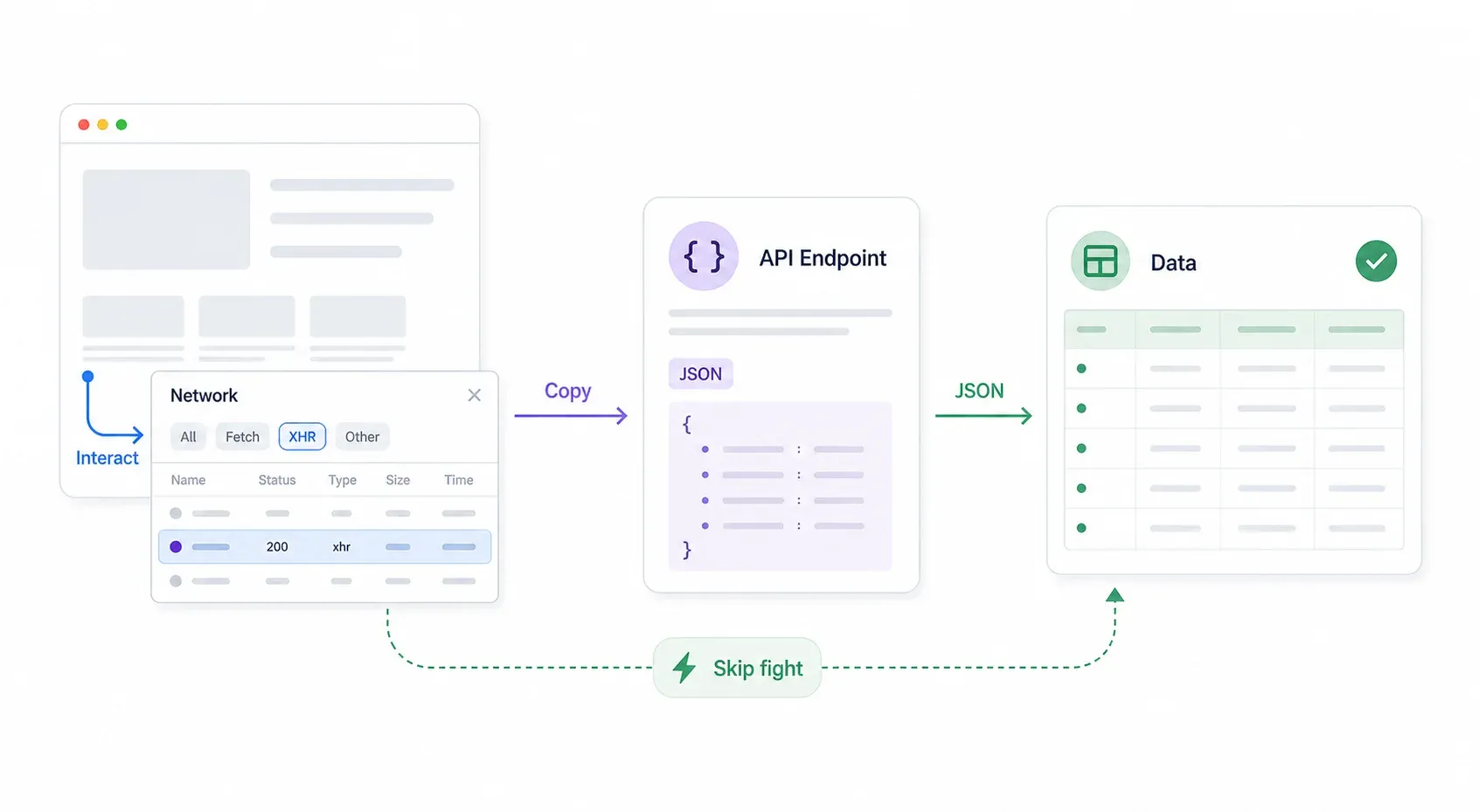
手順は次のとおりです。
- Chrome DevTools を開く → Network タブへ → XHR/Fetch で絞り込む。
- ページを操作する: 検索、フィルタ、ページ送り、スクロールを行い、Network タブに JSON レスポンスが出ていないか見る。
- リクエスト URL とヘッダーを確認する。 API エンドポイントは、フロントエンドより Cloudflare の保護が弱い、またはまったくないことがよくあります。
- リクエストを右クリック → Copy → Copy as cURL。 ターミナルや Postman に貼り付けて試します。
- 同じヘッダー、Cookie、クエリパラメータで Python に再現する(
requestsまたはcurl_cffiを使用)。
API が構造化 JSON を返すなら、従来型のスクレイパー自体が不要かもしれません。はまさにこのケースを扱っていました。curl_cffi でも Cloudflare に止められたユーザーが、唯一使えたのは API レスポンスを直接傍受する方法だった、という話です。
実用上のコツ: cURL のコピーで動いたら、不要なヘッダーを少しずつ削っていきます。sec-ch-ua、Cookie、CSRF トークン、referer は必要なことがありますが、ブラウザのキャッシュ制御はたいてい不要です。ブラウザの cURL からコードへ移す場合は、TLS フィンガープリントと User-Agent を一致させましょう。
制約: すべてのサイトにアクセス可能な API があるわけではありません。認証、CSRF トークン、署名付きリクエストパラメータ、セッションに紐づく Cookie が必要な場合もあります。それでも動けば、保守ほぼゼロで成功率約99%の方法です。
ステップ2: ノーコードの道 — ブラウザ拡張で Cloudflare を回避する(Thunderbit)
競合するガイドの多くは、読者が Python か JavaScript を書く前提で話を進めます。しかしこのキーワードで来るのは、リードリストを作る営業、競合価格を監視する EC 担当、不動産データを集めるアナリストかもしれません。こうした人たちは Docker コンテナを立ち上げたいわけではありません。
のような Chrome 拡張は、実際のブラウザセッション内で動くため、多くの Cloudflare チェックを自然に処理できます。Chrome の本物の TLS フィンガープリント、Cookie、ログイン状態、行動シグナルをそのまま引き継ぐので、Cloudflare が信頼しやすいのです。ステルスプラグインも、xvfb-run も、ターミナルコマンドも不要です。
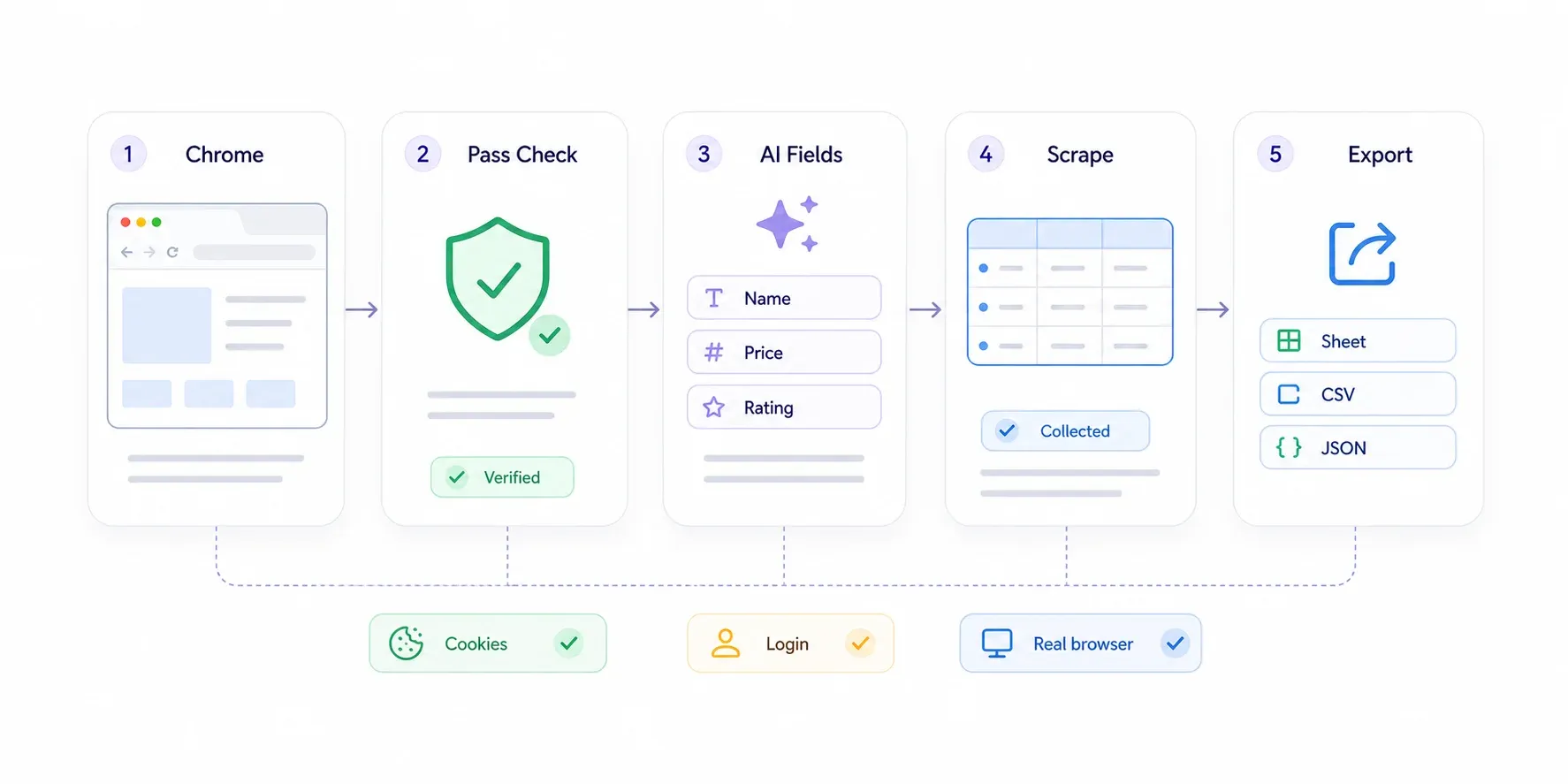
手順
- Chrome ウェブストアから をインストールします。
- Cloudflare 保護ページを Chrome で開きます。Cloudflare にチャレンジされたら、通常のユーザーとして通過してください。Turnstile のチェックボックスを押し、「Checking your browser」ページが消えるまで待ちます。あなたは本物のブラウザを使う本物の人間なので、Cloudflare は通します。
- Thunderbit のサイドバーで 「AI Suggest Fields」 をクリックします。AI がページを読み取り、「商品名」「価格」「評価」など、関連するデータ列を提案します。
- 提案された項目を確認します。不要なものは外し、欲しい内容は自然な英語で書いてカスタム項目として追加します。
- 「Scrape」 をクリックします。Thunderbit が表示中のページからデータを抽出します。
- Google Sheets、Excel、Airtable、Notion、CSV、JSON にエクスポートします。
ページネーションがあるサイトでも、Thunderbit はクリック型のページ送りと無限スクロールの両方に対応します。詳細ページがあるケース、たとえば商品リンク一覧から各商品の仕様を集めたい場合は、 を使えます。Thunderbit が各リンク先の詳細ページを巡回し、表を拡張します。
私の経験では、一般的な50〜100行規模のデータセットなら、インストールからスプレッドシート出力まで5〜10分ほどです。
ブラウザベースのスクレイピングが向いている場面/向いていない場面
制約についても正直に言います。ブラウザベースのスクレイピングは、自分のセッション速度に依存します。数百〜数千ページ規模の中程度の作業には最適です。毎日スケジュールで何百万ページもクロールするなら、コードベースか API ベースが向いています。
Thunderbit の Cloud Scraping オプションなら、公開サイトに対して一度に最大50ページまで取得できるため、処理を速められます。開発者向けワークフローやより大規模な用途では、Thunderbit の が JavaScript レンダリング、アンチボット対策、プロキシローテーションをまとめて処理し、1リクエストあたり最大 をバッチ処理できます。
とはいえ、リード、価格データ、不動産物件などを適度な規模で集めるビジネスユーザーにとっては、これだけで十分なことが多いです。コード不要、プロキシ不要、保守不要。
ステップ3: curl_cffi で TLS フィンガープリントを偽装する(軽量なコード手法)
Python に慣れていて、ノーコードの方法がワークフローに合わないなら、 が最も軽いコード選択肢です。これは libcurl を Python から扱うバインディングで、本物のブラウザの TLS フィンガープリントを偽装できます。requests や httpx と違い、TLS ハンドシェイクが Chrome や Safari 由来のように見えます。
2026年時点で、 には chrome136、safari184、その他多くの過去プロファイルがあります。ライブラリはがあり、現在も活発にメンテナンスされています。
使う場面: Cloudflare の Free〜Pro レベルの保護で、主にパッシブなフィンガープリントを見ているサイト。アクティブな JavaScript チャレンジや Turnstile がない場合です。
基本例:
1from curl_cffi import requests
2url = "https://example.com/products"
3resp = requests.get(
4 url,
5 impersonate="chrome136",
6 headers={
7 "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
8 "accept-language": "en-US,en;q=0.9",
9 },
10 timeout=30,
11)
12print(resp.status_code)
13print(resp.text[:500])つまずきやすい点: User-Agent を偽装ターゲットと一致させてください。Chrome 136 を偽装するなら、Chrome 120 の User-Agent を送ってはいけません。不一致はシグナルになります。
制限: curl_cffi は JavaScript を実行しません。サイトが「Checking your browser」チャレンジや Turnstile を出すなら、この方法は失敗します。ブラウザチャレンジから Cookie ベースのセッション状態を受け取るサイトにも向きません。パッシブ保護だけに対する、速くて安い最初の試みだと考えてください。
同系統の代替: tls-client と curl-impersonate も似た TLS 偽装機能を提供します。
ステップ4: ステルス系ブラウザ自動化(Puppeteer Stealth と SeleniumBase UC)
サイトが JavaScript 実行、アクティブチャレンジ、Turnstile を必要とするなら、TLS 偽装だけでは足りません。その場合は本物のブラウザが必要です。主な選択肢は2つです。
- SeleniumBase UC Mode(Python): を、より人間らしく見せてアンチボットサービスを避ける方法として明示しています。Cloudflare Turnstile の対応例も含まれます。
puppeteer-extra-plugin-stealthを使った Puppeteer(Node.js): まだ広く使われていますが、。コミュニティ報告では、CDP(Chrome DevTools Protocol)検知フラグやブラウザプロファイルの不一致が原因で失敗するケースが見られます。
どちらも本物の Chromium を起動しますが、navigator.webdriver、WebGL のメタデータ、プラグイン一覧など、検知されやすい自動化シグナルを修正します。
実際に重要な設定のコツ:
- ヘッドレスではなくヘッドありモードを使う。SeleniumBase のドキュメントでも、UC Mode はヘッドレスだと検知されやすいとされています。Linux サーバーでは仮想ディスプレイを使います。
- ビューポートサイズと User-Agent をランダム化する。ただし、互いに矛盾せず、プロキシの地理位置とも整合させます。
- 操作間に自然な遅延を入れる。ページ読み込み間隔が200msでは、いかにも bot です。
- 初回チャレンジ通過後は Cookie とブラウザプロファイルを保持する。毎回チャレンジを解き直さないようにします。
- 住宅プロキシと組み合わせると IP の評判が良くなります。
この方法の課題は保守です。Chrome の更新、Cloudflare の新しいシグナル、ステルスプラグインの遅れ、ターゲット側のパス単位 Turnstile 追加などで、ブラウザ自動化スタックは壊れます。 では、多くのステルスブラウザ構成が、タイムゾーン/言語/プロキシの地理情報が噛み合わない「フランケンフィンガープリント」により失敗したと報告されています。
強力ではありますが、運用コストは高いです。継続的な修正の時間を見込んでください。
プロキシローテーション:IP がフィンガープリントと同じくらい重要な理由
ブラウザのステルス性が完璧でも、1つの IP から大量にアクセスするとレート制限に引っかかります。Cloudflare はデータセンター IP よりも住宅 IP とモバイル IP を圧倒的に信頼します。
- 住宅プロキシ: 2026年の初期利用帯では です。信頼性は高いですが、価格も高めです。
- データセンタープロキシ: 安価ですが、 です。
- ローテーション戦略: リクエストごとではなく、セッションごとにローテーションします。リクエストごとの切り替えは、セッションに紐づく Cookie や
cf_clearanceを壊します。1セッション内では IP、Cookie、フィンガープリントを一致させてください。
「最小限必要なプロキシプール数」という魔法の数字はありません。少量のリード取得なら少数の sticky な住宅セッションで十分かもしれませんし、高頻度の価格監視なら何百もの出口とリトライロジックが必要になることもあります。
ステップ5: FlareSolverr — オープンソースの Cloudflare 回避サーバー
は、Docker コンテナ内で Chromium と undetected-chromedriver を使い、Cloudflare チャレンジを解いて Cookie / ヘッダーを再利用可能な形で返すオープンソースのプロキシサーバーです。 されており、今も活発に保守されています。
使う場面: 毎晩実行される自動ジョブのように、継続的にチャレンジを解くサービスが必要なサーバーサイドのスクレイピングパイプライン。たとえば新しい cf_clearance Cookie を定期的に取る必要があるケースです。
仕組み: あなたのスクレイパーが FlareSolverr の API に URL を送ると、FlareSolverr がブラウザでページを開き、チャレンジ解決を試み、HTML と Cookie を返します。その Cookie を通常の HTTP クライアントで次のリクエストに使い回せます。
セットアップの概要: Docker Compose でコンテナを立ち上げ、ローカル API エンドポイントへ POST します。 があります。
正直に言うと、制限はあります:
- 対話式の Turnstile や Enterprise Bot Management を安定して解くことはできません。
- や では、チャレンジ検知漏れ、Turnstile のタイムアウト、ページクラッシュなど、挙動の不安定さが報告されています。
- Docker インフラと継続的なメンテナンスが必要です。
- リソース消費が大きく、チャレンジ解決のたびにブラウザコンテキストを起動します。
推定成功率は、中程度の保護対象で60〜80% ほど。Enterprise では低く、単純なチャレンジページなら高めです。FlareSolverr で足りないなら、有料 API を検討する段階です。
ステップ6: Cloudflare 対応を丸ごと任せられる有料スクレイピング API
場合によっては、計算がそれだけで成り立ちます。自前でステルス基盤を維持する方が、エンジニア工数としてはサブスクリプションより高くつくのです。有料のスクレイピング API は、フィンガープリント、プロキシ、チャレンジ解決、リトライまで、面倒な部分を専用プロバイダに丸ごと任せられます。あなたは URL を送るだけです。
比較の見方:
| プロバイダ | Cloudflare 対応 | JS レンダリング | 住宅プロキシ | 構造化出力 | 課金モデル |
|---|---|---|---|---|---|
| ScrapingBee | あり | あり | あり | HTML のみ | リクエスト単位のクレジット |
| ZenRows | あり(成功率99%超を主張) | あり | あり(上位プラン) | HTML、一部パース | 係数付き CPM |
| Scrapfly | あり(CF、Akamai、DataDome を明記) | あり | あり | HTML、一部パース | クレジット制 |
| Browserless | あり | あり(ヘッドレス Chrome) | あり(内蔵) | HTML、スクリーンショット | ユニット制 |
| Thunderbit API | あり | あり | あり | AI スキーマによる構造化 JSON/CSV | 無料枠 + 有料プラン |
向いているケース: 大量スクレイピング、エンタープライズ級の安定性が必要な場合、または自社チームがスクレイピング基盤を保守したくない場合です。費用感は、小〜中規模ならおおよそ月 $30〜$500+、エンタープライズ規模ではさらに上がります。
Thunderbit API は、単なる生 HTML ではなく構造化データを返す点で特に紹介する価値があります。 は1リクエストあたり最大50 URL をバッチ処理でき、AI ベースのスキーマに従って JSON/CSV を返します。自分で HTML を解析するのではなく、すぐ分析に使えるきれいなデータが欲しいなら便利です。
正直な信頼性スコアボード:実際に動くもの、壊れるもの
私は2025〜2026年を通して、コミュニティ報告、GitHub issues、ベンダーの主張を追いかけてきました。以下は率直な比較です。いずれもラボでの厳密なベンチマークではなく、目安です。
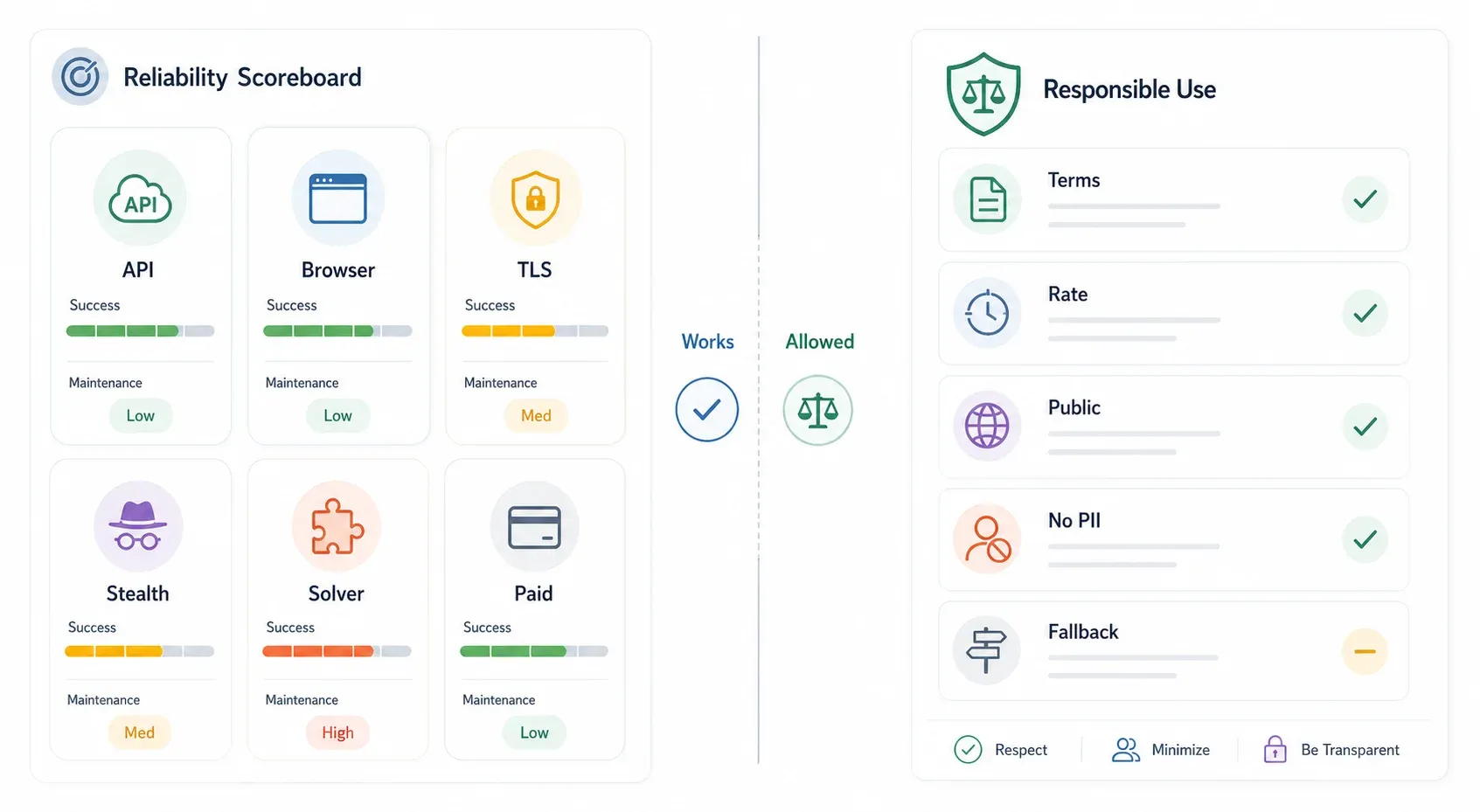
| 手法 | 推定成功率 | 保守負担 | 壊れる条件 | コスト感 |
|---|---|---|---|---|
| 内部 API(存在する場合) | 約90〜99% | 低 | API 変更、認証追加、トークン署名化 | 無料 |
| ブラウザ拡張(Thunderbit) | 約85〜95%(実セッション) | 低(AI がレイアウト変化に適応) | 特殊な認証フロー、アクションごとの厳しい Turnstile | 無料枠あり |
curl_cffi / TLS 偽装 | 約70〜85% | 中(フィンガープリント更新) | Cloudflare が JA3 チェックを更新、アクティブ JS チャレンジが必要 | 無料 |
| Puppeteer + stealth plugin | 約70〜90% | 高(プラグイン更新が遅れがち) | CDP 検知、新しいフィンガープリントシグナル、ヘッドレス検知 | 無料 + プロキシ費用 |
| FlareSolverr | 約60〜80% | 高(Docker、依存関係のズレ) | Enterprise レベルの保護、Turnstile の対話 | 無料 + インフラ費用 |
| 有料スクレイピング API | 約85〜95% | 低(提供側が保守) | ベンダー未更新、予算超過 | 約 $30〜500+/月 |
最も重要なのは成功率ではなく、**「壊れる条件」**の列です。どの方法にも失敗モードがあります。最善策は、対象に対して最も手間の少ない有効な方法を選び、必ずフォールバックを用意しておくことです。
永遠に使える方法はありません。Cloudflare は継続的に更新します。いたちごっこは現実です。
どの方法を使っても Cloudflare の目を避けるコツ
どの方法を選ぶにしても、いくつかの習慣で Cloudflare に見つかるまでの時間を延ばせます。
- レート制限を尊重する。 リクエスト間に自然な遅延を入れましょう。人間らしい閲覧なら最低でも2〜5秒は空けたいところです。機械的な速度で叩くのは、ブロックされる最短ルートです。
- フィンガープリントを一貫させる。 User-Agent、TLS フィンガープリント、ブラウザバージョン、タイムゾーン、ロケール、IP の地域は、同じストーリーを語っている必要があります。ドイツの IP から Chrome 136 を名乗り、
en-USロケールで Python っぽい TLS ハンドシェイクを出すのは矛盾です。 - チャレンジ通過後は Cookie とセッションを再利用する。 毎回やり直さないでください。
- セッション途中で IP を切り替えない。 Cloudflare はセッションの継続性を追跡します。
- 用途と予算が合うなら住宅 IP かモバイル IP を使う。
- ソフトブロックを監視する: JSON のはずなのにチャレンジ HTML、空のテーブル、ログインリダイレクト、 のホネポットのように見えるページなど。
- アクセスが増える時間帯を避ける。 サイト運営者が WAF ルールを厳しくすることがあります。
- フォールバック経路を作る: まず API、次にブラウザセッション、最後に有料プロバイダ。
Thunderbit ユーザーの場合は特に、AI がページレイアウトの変化に自動で適応するため、CSS セレクタの保守に時間を取られず、データを実際に使うことに時間を回せます。
法的・倫理的な注意点
この記事の中心テーマではありませんが、飛ばすには重要すぎます。
公開情報のスクレイピングには、 があります。hiQ v. LinkedIn の CFAA に関する考え方は最高裁差戻し後も残りましたが、2022年に和解しており、全体像は複雑です。より最近では、 し、2025年にユーザーコメントのスクレイピングを巡る疑いを争いました。また同年後半には、 しました。
EU では、個人データが関わる限り GDPR が適用され、 には に関する特定の義務があります。
実務上の目安:
- サイトの利用規約を必ず確認する。
- Cloudflare の保護は、サイト運営者が自動アクセスをコントロールしたいというサインです。その意図を尊重する。
- 正当な根拠なく個人データを収集しない。
- 商用または大量処理のワークフローでは、公式 API、ライセンス付きデータ、書面許可があるならそれを優先する。
- 迷ったら、自分の用途と法域について法律専門家に相談する。
Thunderbit は、公開アクセス可能なデータを使ったリード獲得、価格監視、市場調査など、正当なビジネス用途向けに設計されています。
まとめ:最初に試すこと、次に試すこと
この記事全体で最大の時短ポイントは、ツールでもコード片でもなく、最初に保護レベルを見極めることです。それだけで、そもそも成功しない方法のデバッグに何時間も溶かすことを防げます。
ここから始めましょう:
- 内部 API がないか確認する(無料・高速・見落とされがち)。
- コードを書かないビジネスユーザーなら、 を試す。実際のブラウザセッションこそ、Cloudflare に対する最大の武器です。
- 開発者で、対象がパッシブなフィンガープリントのみを使うなら、
curl_cffiを試す。 - より強い対策が必要なときだけ、ステルスブラウザ、FlareSolverr、有料 API に進む。
1つの方法が永遠に使えることはありません。自分の規模に合ったツールとフォールバック計画を組み合わせれば、403 ページを見つめ続ける時間はかなり減ります。
さらに深く知りたい方は、Thunderbit ブログで 、、 についても紹介しています。拡張機能の動きを見たいなら、 の解説動画をご覧ください。
FAQ
1. Cloudflare の保護を完全に回避できますか?
100% の成功を保証する単一の方法はありません。特に Turnstile、JA4 フィンガープリント、AI Labyrinth を備えた Enterprise レベルの Bot Management では難しいです。最も信頼性が高いのは、実際のブラウザフィンガープリントと良質な IP 評判を組み合わせる方法です。内部 API が見つかれば Cloudflare を完全に避けられるため、これが最も「完全回避」に近い方法ですが、どのサイトにもあるわけではありません。
2. Scraping 時に Cloudflare を回避するのは合法ですか?
法域、サイトの利用規約、収集するデータによって変わります。公開データのスクレイピングは、米国では一部の文脈で有利な判例があります(hiQ v. LinkedIn)。ただし、技術的なアクセス制御の回避、利用規約違反、正当な根拠のない個人データ収集は法的リスクを生みます。商用用途では、可能なら公式 API やライセンス付きデータを優先し、迷う場合は法律専門家に相談してください。
3. コードを書かずに Cloudflare を回避する最も簡単な方法は?
のように、実際の Chrome セッション内で動くブラウザ拡張です。Cloudflare チャレンジを自動で処理し、あなたは通常のユーザーのようにサイトを操作し、その後に拡張機能へ抽出とエクスポートを任せられます。Python も Docker もプロキシ設定も不要です。
4. なぜある Cloudflare サイトでは動くのに、別のサイトでは動かないのですか?
Cloudflare の保護レベルは、プラン(Free、Pro、Business、Enterprise)と設定によって大きく異なります。Free プランのサイトで単純な JS チャレンジに通る方法でも、Enterprise サイトの Turnstile や完全な Bot Management には失敗することがあります。回避手法を選ぶ前に、まずは単純な JS チェックなのか、Managed Challenge なのか、Turnstile ウィジェットなのかを確認して、保護階層を見極めてください。
5. Cloudflare の回避手法はどのくらいの頻度で壊れますか?
ステルスプラグインや TLS 偽装のようなコードベースの方法は、Cloudflare の検知更新により、難しい対象では数週間〜数か月単位で劣化することがあります。有料 API や実ブラウザセッション系ツールは、インフラ層またはユーザーセッション層で適応するため、比較的壊れにくい傾向があります。内部 API は、サイトがバックエンドを再設計したり認証方式を変えたりしない限り、あまり壊れません。長期的には、1つの方法に依存せず、複数のフォールバックを持つのが最も安全です。
さらに詳しく読む