

経理や上司から「このPDFの束から、必要な数字をきれいにまとめておいて」と振られて、頭を抱えた経験はないでしょうか。これを一件ずつ手で書き写していたら、退社時間はどんどん後ろにずれていきます。PDFのデータ抽出が厄介なのは、Webページのように構造が一定ではないからです。表形式のものもあれば、画像や紙をスキャンしただけのものもあり、中身をそのまま取り出すのは簡単ではありません。
AIを使ってあらゆるWebサイトからデータを抽出 Get Started Free
わかりやすい例がメールアドレスです。PDF内のメールアドレスは画像として貼り付けられていたり、見た目では判別しにくい文字列の中に紛れていたりします。たとえば {john.doe,jane.doe}@example.com という表記。これは1つではなく、john.doe@example.com と jane.doe@example.com という2件のアドレスを縮めて書いたものです。{first.last}@example.com という形もあり、この場合は「first」と「last」を著者の名と姓に当てはめて読み解く必要があります。昔ながらの文字認識ツールでは、こうした変則的な書き方を正しく扱えません。ここで活躍するのが PDFスクレイパー というわけです。
PDFスクレイパーとは
PDFスクレイパー とは、PDFファイルの中身を自動で読み取り、表やテキストといったデータを Excel、CSV、JSON など使いたい形式に書き出してくれるツールのことです。端的にいえば、延々と続くコピペ作業を、ボタンひとつの作業に置き換えてくれます。
請求書、契約書、論文、あるいはスキャンしたPDFが山積みになっている状況を思い浮かべてください。これを全部手入力すれば、軽く数時間は飛んでいきます。PDFスクレイパーなら、ファイルを読み込ませるだけで数秒後にはデータがそろい、しかも内容を取り違えることなく、時間も労力も大きく削れます。地道な手打ち作業はもう必要ありません。
PDFの中に表やリンク、画像などが入り混じっているなら、その処理はAI PDFスクレイパーに任せるのが得策です。AI PDFスクレイパーは大規模言語モデル(LLM)を土台にしており、テキストと画像と表をまとめて読み解けるため、抽出の精度がとても高くなります。
AI PDFスクレイパーの魅力は、速さと正確さだけにとどまりません。扱える対象が幅広いことも、安心して使える大きな理由です。スキャン文書でも、画像でも、複数言語が混在したPDFでも、AIなら無理なくこなせます。こうしたツールにはいろいろな選択肢があり、たとえば Thunderbit、ChatGPT、ChatPDF などが代表的で、それぞれ得意分野が異なります。とにかく早く抽出したいときも、込み入った文書をじっくり読み解きたいときも、用途に合ったツールを選べば作業はぐっと楽になります。
ぜひ試してみましょう:AIでPDFからデータを抽出
ぜひ試してみてください。クリックして内容を確認しながら、実際にワークフローを操作できます。
適切なPDFスクレイパーの選び方
PDFスクレイパー選びは、車選びに近いものがあります。万人にとっての正解はなく、自分の使い方に合ったものがいちばんです。チェックしておきたいポイントは次のとおりです。
| 機能 | 説明 |
|---|---|
| 精度と安定性 | 特に重要な情報について、ツールが正確にデータを抽出できるか確認しましょう。 |
| 出力形式 | Excel、CSV、JSON など、必要な出力形式に対応しているか確認しましょう。 |
| 他ツールとの連携 | 会社のシステムと接続する必要があるなら、スムーズな連携に対応しているか確認しましょう。 |
| 使いやすいUI | 一般ユーザーには直感的なツールが向いており、より複雑なツールは技術チーム向きの場合があります。 |
どのツールにも得意な領域があり、目的に合うものを選べば作業効率は大きく変わってきます。ここからは、用途別に特徴のある人気PDFスクレイパーを3つ取り上げます。
| ツール | 長所 | 短所 |
|---|---|---|
| Thunderbit | 抽出が速い;ブラウザ拡張機能として使いやすい;チームコラボレーションに強い | データ処理の規模に制限がある |
| ChatPDF | 使いやすい;1つのPDFに対してチャット形式でQ&Aできる | CSV/Excel/JSON のネイティブ出力は不可。回答はチャット内に残る |
| ChatGPT | 複雑な意味理解に柔軟に対応でき、幅広い用途に使える | 毎回手動でプロンプトを入力する必要がある |
AI PDFスクレイパーの始め方
Thunderbit
とにかく手間をかけず、サッとPDFからデータを取り出したいなら、Thunderbitが向いています。操作は単純で、クリックを重ねていくだけでほとんどの工程が終わります。次の手順をたどれば、扱いにくいPDFデータも必要な形式へ手早く変換でき、日々の作業がぐっと軽くなります。
-
ThunderbitをChromeに追加してサインアップする:
Thunderbit公式サイト にアクセスし、Thunderbit 拡張機能をChromeブラウザに追加します。Googleアカウント、または他のメールアドレスでサインアップします。

-
ChromeでPDFを開く:
データを抽出したいPDFファイルをChromeで開き、右上のThunderbitアイコンをクリックします。
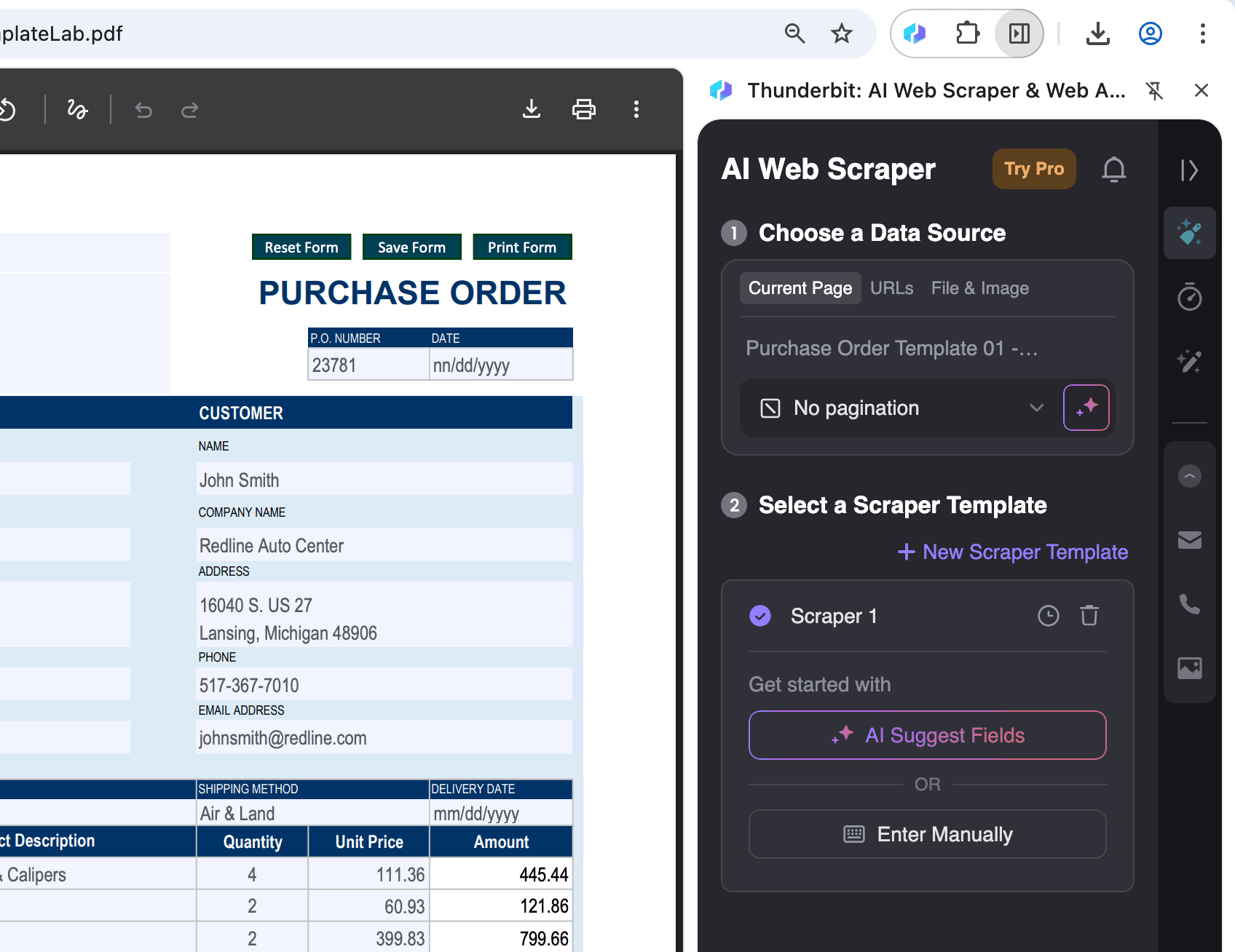
-
出力形式を選んでエクスポートする:
AI Suggest Columns を選んだあと、必要に応じてデータを絞り込んだり調整したりできます。その後、希望する出力形式(CSV、Google Sheets、Airtable、Notion)を選び、Scrape をクリックしてデータをエクスポートします。
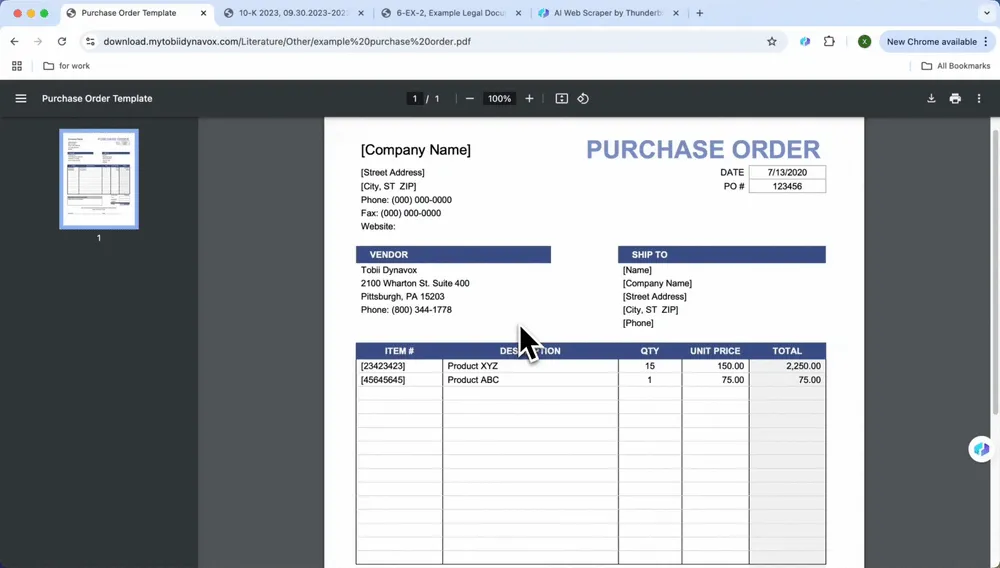 エクスポートしたデータは、Notion、Airtable、Google Sheets に直接連携でき、チームでの共同作業も簡単です。
エクスポートしたデータは、Notion、Airtable、Google Sheets に直接連携でき、チームでの共同作業も簡単です。
Thunderbitは、PDFから欲しいデータをすばやく取り出し、扱いやすい形式へまとめてくれるシンプルな抽出ツールです。一人で使っても、チームで使っても、作業効率を大きく押し上げ、PDFからのデータ取得をもっと身近なものにしてくれます。
ChatPDF
たくさんのPDFを扱いつつ、すべてではなく要点となる情報だけを抜き出したい場合は、ChatPDF が便利です。対話しながらデータを取り出せるので、はじめての人にも扱いやすいツールです。
ChatPDFでPDFデータを抽出する流れは次のとおりです。
- ChatPDFのサイトにアクセスする: ChatPDF のサイト、または関連プラットフォームのページを開きます。
- PDFファイルをアップロードする: 「Upload File」ボタンをクリックして、分析したいPDF文書をドラッグ&ドロップするか選択します。契約書、論文、財務諸表など、さまざまなファイル形式に対応しています。
- PDFを分析する: アップロードが完了すると、ChatPDFが自動でファイル内容を解析し、構造化された文書要約を生成します。その後、抽出された重要情報を確認できます。
- 対話形式で質問する: 入力欄に「このレポートの結論は何ですか?」や「請求書に記載された合計金額はいくらですか?」といった質問を入力します。ChatPDFは、質問に基づいて関連する内容を抽出します。
- 回答を外部にコピーする: ChatPDFの回答はチャット画面内に表示されます。結果をスプレッドシート、ドキュメント、または独自の表にコピーしてください。構造化された出力をきれいに出したい場合(多数のファイルで一貫した列を持つCSV/JSONなど)、Thunderbitや固定プロンプト付きのChatGPTのほうが適しています。
ChatPDFは対話しながら使える分、要点をつかんだり文書の中身を要約したりと、必要な情報を文書からすばやく探し出したい場面で特に頼りになります。
ChatGPT
ChatGPT は、契約条項の読み解きのように、意味を踏まえて深く理解する作業を得意としています。用途ごとにプロンプトを自在に書き換えられるため、対応の幅が広いのが特長です。一方で、似た作業を繰り返すたびに同じプロンプトを用意し直す必要があり、プロンプトを上手に書く力も問われます。
必要に応じて書き換えられる、ひな型のプロンプトを用意しました(抽出したい項目に合わせて列名を差し替えてください)。
あなたは今、PDFスクレイパーです。PDFが与えられたら、ユーザーが指定した列に基づいて内容を抽出してください。出力はCSVファイルにしてください。
列は次のとおりです。
1. 名前
2. メールアドレス
3. 電話番号
4. ...
- 登録またはログインする: ChatGPT のサイトを開いてアカウントを登録します。すでにアカウントがある場合は、そのままログインします。
- PDFをアップロードして質問を入力する: 入力欄に質問を直接入力します。具体的であるほど精度が上がります。たとえば、「このPDFには3つのグラフがあります。表として出力してください。」のように入力します。
- 結果を確認して調整する: 回答が期待どおりか確認します。必要に応じて、追加の質問をしたりプロンプトを調整したりして結果を改善します。
- データをExcelまたはCSVとして出力する: ChatGPTで抽出したデータが希望どおりなら、入力欄に「このデータをExcelまたはCSVで出力してください。」と入力します。
- 結果を保存する: ChatGPTが提供するファイルリンクをクリックして、ファイルをダウンロードします。
AI PDFスクレイパーの実践的な活用例
AI PDFスクレイパーは、請求書や契約書、財務レポート、発注書といった書類を相手にする業務で、何でもこなしてくれる頼れる相棒のような存在です。ここでは、特に効果を発揮する場面をいくつか紹介します。
請求書と領収書の処理
社内に溜まった請求書や領収書をまとめて処理し、金額や日付などの要点を抜き出して、分類・保管まで一気に進めます。
- Thunderbit を起動し、AI Web Scraperをクリックしてから Bulk Pages を選択する
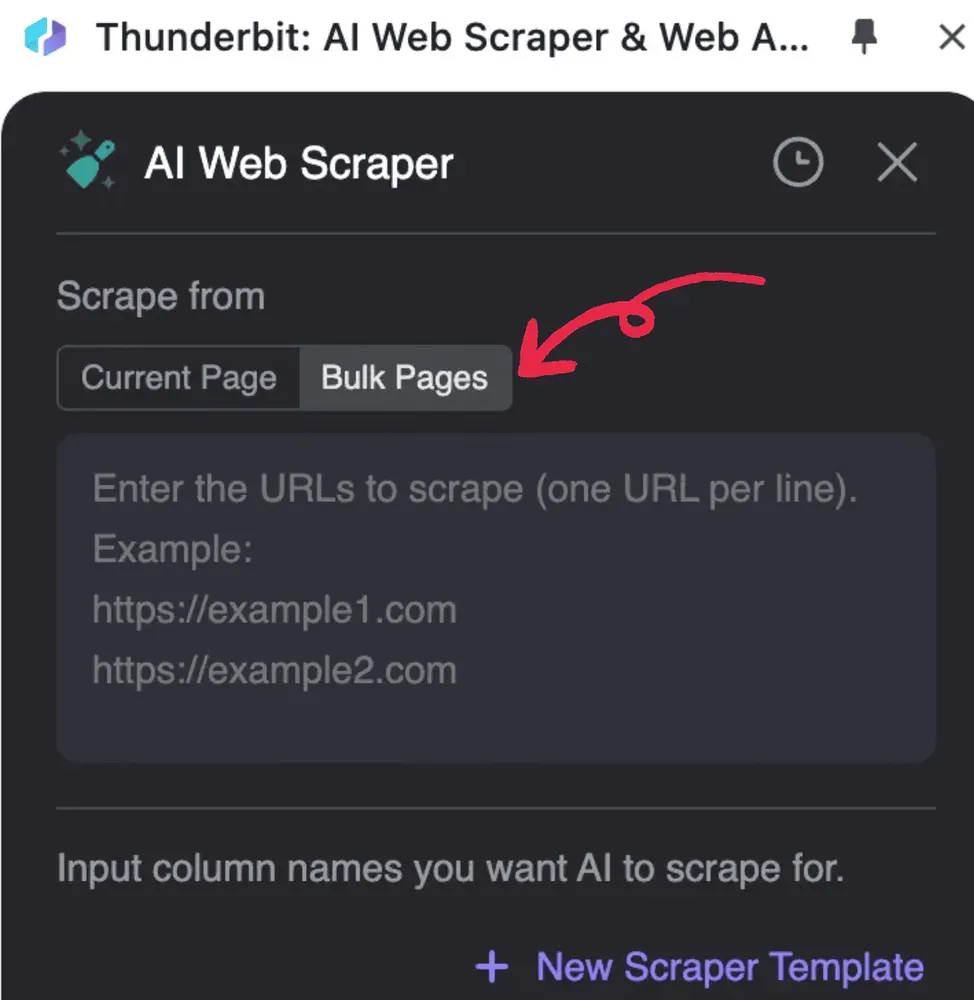 2. 処理したいPDFのURLを1行ずつ入力する
2. 処理したいPDFのURLを1行ずつ入力する
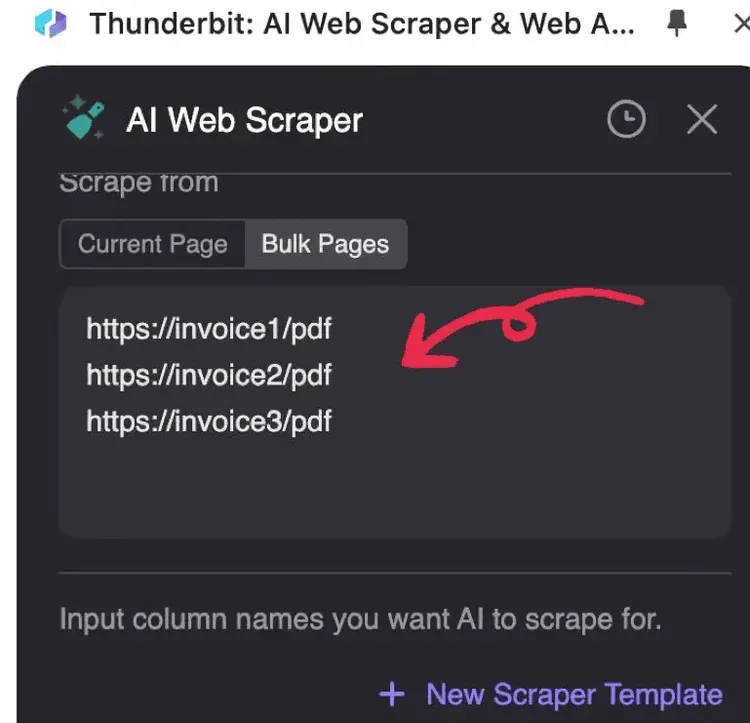 3. AI Suggest Columns をクリックする(AIがPDFを読み取り、データ構造を提案します)
4. Scrape をクリックしてデータをエクスポートする
3. AI Suggest Columns をクリックする(AIがPDFを読み取り、データ構造を提案します)
4. Scrape をクリックしてデータをエクスポートする
発注書の処理
発注書の品目・数量・単価をPDFから自動で読み取り、形式のそろったデータとして書き出すことで、手作業に費やす時間を減らせます。
- 発注書をChromeで開き、Thunderbit を起動する
- AI Web Scraperをクリックし、次に AI Suggest Columns を選択する
- 生成されたリスト名を確認し、Scrape をクリックする
- Download CSV をクリックする
財務データの抽出
財務レポートから利益率や売上といった数値をワンクリックで取り出し、目視でひとつずつ追う手間をなくします。
- 財務レポートをChromeで開き、Thunderbit を起動する
- Summarize をクリックする
- テキストと表の内容を含む重要情報の要約を自動生成する
自動で作られた要約がしっくりこない場合は、抽出したい項目を自分で指定することもできます。
- 財務レポートをChromeで開き、Thunderbit を起動する
- AI Web Scraperをクリックし、純利益、売上高など、欲しい項目名を入力する
- Scrape をクリックし、Table を出力する
法務文書の分析
契約書や合意書の条項を読み込むのに手こずっていませんか。AIツールを使えば、支払条件や違反条項、契約期間といった要点をすばやく拾い出せます。ワンクリックで抽出して簡潔な要約や条項リストを作れるので、時間の節約になるうえ、見落としも防げます。
財務レポートから要点を取り出すときと同じ要領で、PDFを開いて Summarize をクリックすれば、支払条件や違反条項、契約期間などの重要情報をワンクリックで確認できます。
よくある質問
-
複数のPDFから一度にデータを抽出できますか?
はい、高機能なPDFスクレイピングツールなら、複数のPDFから同時にデータを抽出できます。この一括処理機能により、手作業で抽出する方法よりも作業全体を大幅に高速化できます。
-
PDFスクレイパーは無料ですか?
はい、無料で使えるPDFスクレイパーツールはいくつかあります。Thunderbit や ChatPDF など、多くのオンラインツールは、ページ抽出やデータ抽出の無料機能を提供しています。一部の高度な機能は有料の場合がありますが、基本的なデータ抽出機能は通常無料です。
-
PDFスクレイパーを使うのにプログラミング知識は必要ですか?
いいえ、Thunderbit のような多くのAI PDFスクレイパーは、プログラミング経験のないユーザー向けに設計されています。ファイルをアップロードして数回クリックするだけでデータを抽出できる、使いやすいUIを備えています。
-
PDFスクレイパーで処理できる文書の種類は何ですか?
PDFスクレイパーは、請求書、契約書、財務レポート、学術論文など、PDFファイル内にある構造化データや半構造化データを含むさまざまな文書に対応できます。
-
PDFスクレイパーを使うとデータは安全ですか?
信頼できるPDFスクレイピングツールはユーザーの安全性を重視しており、GDPRなどの規制に準拠していることが多いです。通常、データは暗号化されたサーバーに保存され、許可なくアクセスされることはありません。
-
PDFからデータを抽出する他の方法はありますか?
PDFからデータを抽出する方法は、手入力やPythonスクリプトだけではありません。PDFコンバーターを使ってExcelやCSVなどの形式に変換する方法、TabulaやExcaliburのような構造化文書向けの専用PDFデータ抽出ツール、ネイティブPDFとスキャンPDFの両方にOCR(光学式文字認識)を活用するAIベースのソリューション、ExtractousやPymuPDF4llmのような効率的なデータ抽出向けのオープンソースツールなどがあります。それぞれに長所と短所があるため、用途や技術レベルに応じて選ぶのが最適です。
さらに詳しく
AI Web Scraperを試す Get Started Free




