नाम पार्सर
क्या बड़ी मात्रा में डेटा स्क्रैप करना है? Thunderbit मुफ़्त में आज़माएँ।








ब्राउज़ करते हुए संरचित नाम निकालें
Thunderbit का उपयोग करके पूरा नाम कैसे पार्स करें



संरचित फ़ील्ड्स में पूरे नाम पार्स करना सीखें
पूरा नाम घटकों में पार्स करें

प्रीफिक्स, प्रत्यय और बहु-भाग उपनामों को संभालें

CRM और स्प्रेडशीट संपर्क डेटा को मानकीकृत करें
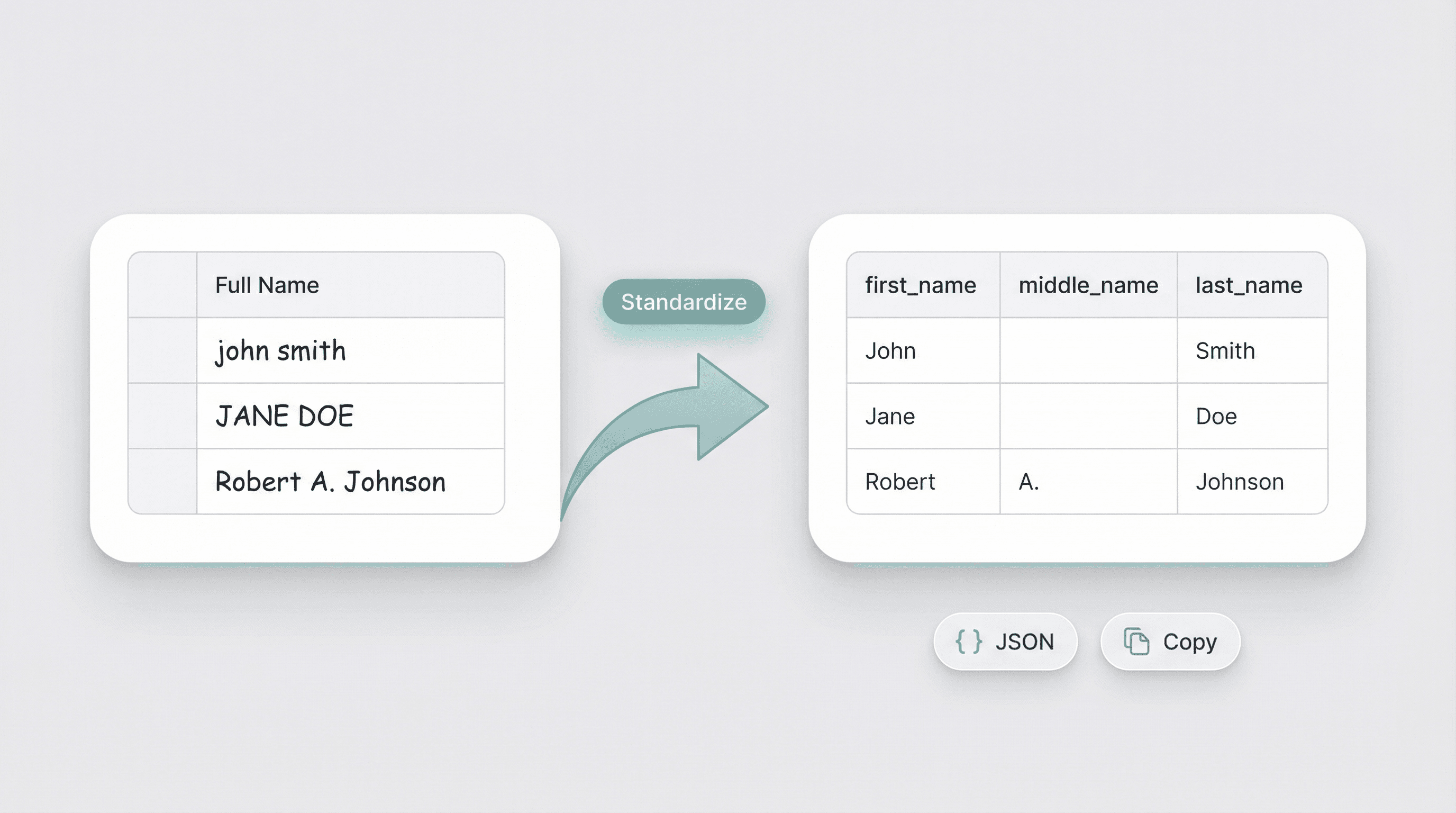
लीड एनरिचमेंट और वेब-स्क्रैप किए गए डेटासेट को बेहतर बनाएं
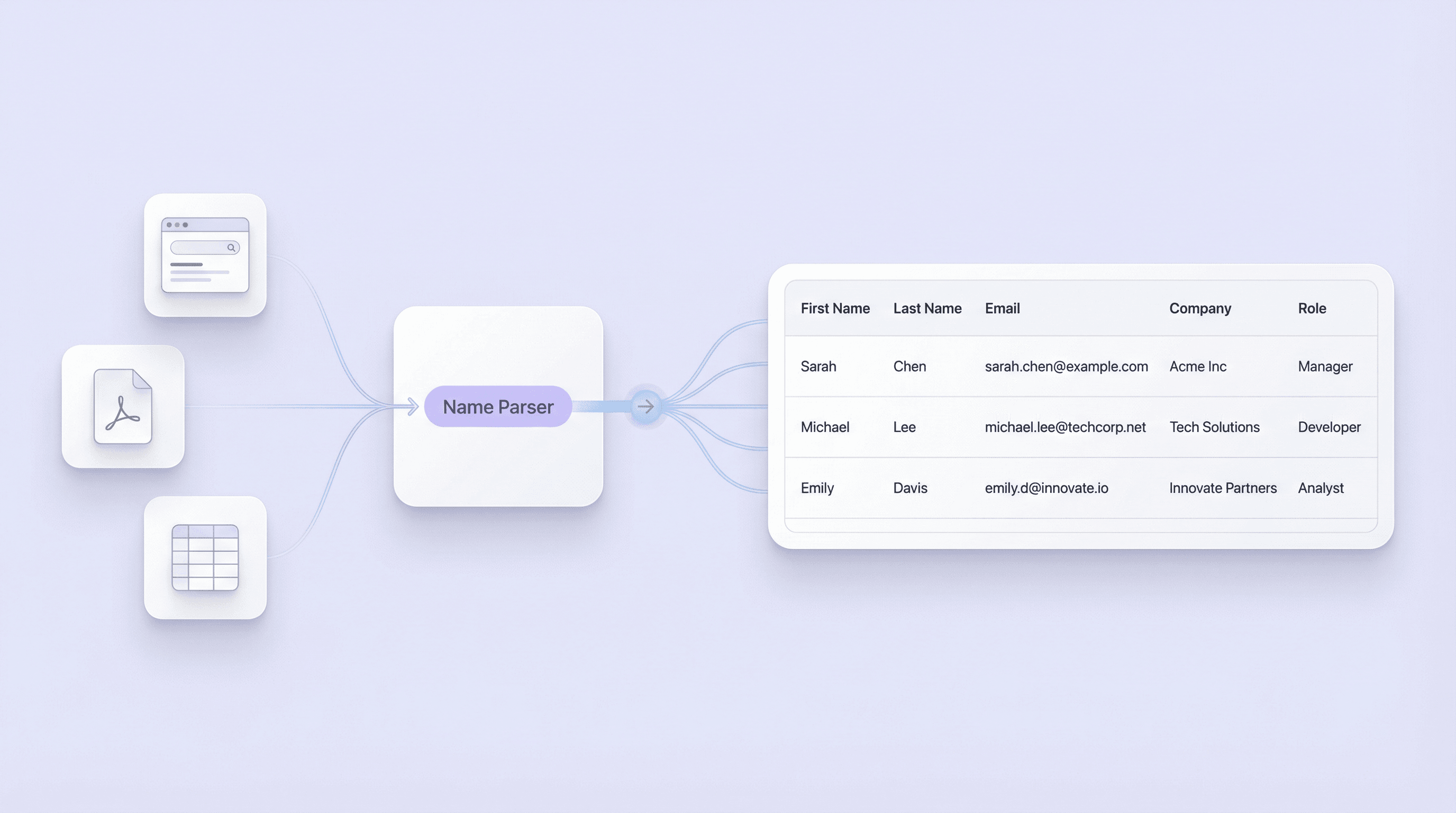
और मुफ़्त टूल्स खोजें
Google Shopping स्क्रैपर
Google Shopping के नतीजों से संरचित प्रोडक्ट लिस्टिंग निकालें, ताकि मूल्य निर्धारण और प्रतिस्पर्धी शोध किया जा सके। शीर्षक, कीमतें, रिटेलर, रेटिंग, समीक्षाएँ, शिपिंग और लिंक एक साफ़ टेबल में कैप्चर करें।
Amazon लिस्टिंग क्वालिटी चेकर
Amazon प्रोडक्ट लिस्टिंग की पूर्णता और SEO के लिए तैयारी का आकलन करता है। कमजोर या गायब टाइटल, बुलेट्स, इमेज, और कीवर्ड्स को चिन्हित करता है। विज़िबिलिटी बढ़ाने के लिए स्पष्ट स्कोर और तुरंत लागू होने वाले सुधार सुझाव देता है।
डिस्पोज़ेबल ईमेल चेकर
जांचें कि कोई ईमेल डिस्पोज़ेबल डोमेन का उपयोग कर रहा है या नहीं, और पता लगाएँ कि कौन-सा प्रदाता पाया गया है। स्पैम साइनअप कम करें और अपनी सूचियों को साफ़ रखें। संक्षिप्त व्याख्या के साथ स्पष्ट परिणाम पाएँ।
UPC लुकअप
UPC के जरिए प्रोडक्ट की जानकारी खोजें—आइटम वेरिफाई करें और लिस्टिंग्स की तुलना करें। एक ही सर्च में नाम, ब्रांड, निर्माता, कैटेगरी और इमेज मिलें।
Amazon प्रोडक्ट्स स्क्रैपर
Amazon उत्पादों के URL पेस्ट करके उनसे प्रोडक्ट जानकारी निकालें। शीर्षक, कीमत, रेटिंग और अन्य विवरणों को एक व्यवस्थित टेबल में पाएं, ताकि आप उन्हें जल्दी से एक्सपोर्ट और रिव्यू कर सकें।
ज़ूमइन्फो स्क्रैपर
तेज़ प्रॉस्पेक्टिंग और विश्लेषण के लिए ZoomInfo पेजों से कंपनी और संपर्क विवरण को एक संरचित तालिका में निकालें।
ईमेल फ़ॉर्मेट फ़ाइंडर
किसी भी कंपनी डोमेन के लिए सबसे संभावित ईमेल पैटर्न खोजें और किसी व्यक्ति के लिए संभावित पते बनाएँ। आउटरीच तेज़ करने और बाउंस जोखिम कम करने के लिए आत्मविश्वास के साथ रैंक किए गए फ़ॉर्मेट पाएं।
Idealista स्क्रैपर
Idealista की प्रॉपर्टी लिस्टिंग्स को विश्लेषण के लिए एक साफ़-सुथरी टेबल में निकालें। सर्च रिज़ल्ट्स से पता, URL, कीमत, बेडरूम और साइज (m²) कैप्चर करें। तेज़ रिसर्च और तुलना के लिए स्ट्रक्चर्ड डेटा एक्सपोर्ट करें।
LinkedIn संदेश जनरेटर
नेटवर्किंग, नौकरी संबंधी पूछताछ, या कनेक्शन अनुरोधों के लिए परिष्कृत LinkedIn आउटरीच संदेश बनाएं। नाम, उद्देश्य और मुख्य बिंदु जोड़कर समय बचाएं और पेशेवर बने रहें।
Naver Shopping क्रॉलिंग टूल
Naver Shopping सर्च रिज़ल्ट्स से प्रोडक्ट डेटा निकालें और कम मैन्युअल मेहनत में कीमतों, रेटिंग्स और विक्रेताओं की तुलना करें।
Redfin स्क्रैपर
Redfin की प्रॉपर्टी लिस्टिंग्स को विश्लेषण के लिए एक व्यवस्थित टेबल में निकालें। पता, कीमत, बेड्स, बाथ्स, स्क्वायर फुटेज और एजेंट की जानकारी कैप्चर करके घरों की तुलना तेज़ी से करें।
टाइमस्टैम्प कन्वर्टर
Unix टाइमस्टैम्प को पढ़ने योग्य तारीखों में बदलें या तारीखों को टाइमस्टैम्प में कन्वर्ट करें। अलग-अलग फ़ॉर्मैट में समय डेटा पर काम करते हुए समय बचाएँ।
मुफ़्त Amazon रेवेन्यू कैलकुलेटर
प्रोडक्ट की कीमत और अनुमानित मासिक बिक्री के आधार पर ग्रॉस मासिक रेवेन्यू का अनुमान लगाएँ। डिमांड को जल्दी परखें और इन्वेंट्री प्लानिंग के लिए एक साफ़ स्नैपशॉट पाएँ।
Amazon प्रॉफिट कैलकुलेटर
कीमत, COGS, शिपिंग, रेफरल रेट, FBA फीस और अन्य खर्च दर्ज करके Amazon प्रोडक्ट्स का नेट प्रॉफिट और मार्जिन अनुमानित करें। लिस्ट करने से पहले प्रोडक्ट की व्यवहार्यता जांचने के लिए लागत का साफ़ ब्रेकडाउन पाएं।
HTML एन्कोडर और डिकोडर
बेहतर वेब सामग्री के लिए विशेष वर्णों को HTML एंटिटी में एन्कोड करें या उन्हें वापस पढ़ने योग्य टेक्स्ट में डिकोड करें।
ASIN लुकअप
एक या कई ASIN डालकर Amazon प्रोडक्ट की जानकारी तुरंत निकालें—लिस्टिंग वेरिफाई करें और एट्रिब्यूट्स की तुलना करें। टाइटल, ब्रांड, कैटेगरी, कीमत और इमेज URL जैसी डिटेल्स साफ़, रिव्यू-रेडी आउटपुट में पाएं।