
“आपके पास डेटा बिना सूचना के हो सकती है, लेकिन सूचना बिना डेटा के नहीं हो सकती।” — *
हाल के अनुमानों के मुताबिक, इंटरनेट पर से ज़्यादा वेबसाइटें हैं, और हर दिन लगभग 20 लाख नई पोस्ट प्रकाशित होती हैं। डेटा का यह विशाल समंदर ऐसे काम की जानकारियाँ समेटे हुए है, जो बेहतर फैसले लेने में मदद कर सकती हैं। लेकिन एक दिक्कत है: इसका लगभग असंरचित है, यानी इसे उपयोगी बनाने के लिए अतिरिक्त प्रोसेसिंग चाहिए। यहीं पर वेब स्क्रैपिंग टूल्स काम आते हैं और ऑनलाइन डेटा का उपयोग करने की कोशिश करने वाले किसी भी व्यक्ति के लिए ज़रूरी बन जाते हैं।
अगर आप वेब स्क्रैपिंग में नए हैं, तो और जैसे शब्द थोड़ा डराने वाले लग सकते हैं। लेकिन AI के दौर में इन चुनौतियों से निपटना पहले से कहीं आसान हो गया है। आज के AI-संचालित स्क्रैपिंग टूल्स आपको बिना गहरी तकनीकी जानकारी के शुरुआत करने में मदद कर सकते हैं। ये टूल्स डेटा को तेज़ी से इकट्ठा और प्रोसेस करना संभव बनाते हैं—कोडिंग कौशल की ज़रूरत नहीं पड़ती।
सर्वश्रेष्ठ वेब स्क्रैपिंग टूल्स और सॉफ़्टवेयर
- — आसान-से-इस्तेमाल होने वाले AI वेब स्क्रैपर के लिए, बेहतरीन नतीजों के साथ
- — रीयल-टाइम मॉनिटरिंग और बड़े पैमाने पर डेटा निकालने के लिए
- — बिना कोड ऑटोमेशन और व्यापक ऐप इंटीग्रेशन के लिए
- — अधिक प्रोफेशनल विज़ुअल वेब स्क्रैपिंग के लिए
- — IP ब्लॉकिंग और बॉट डिटेक्शन से बचते हुए शक्तिशाली नो-कोड स्क्रैपिंग के लिए
- — उन्नत AI-संचालित डेटा एक्सट्रैक्शन API और नॉलेज ग्राफ़ के लिए
वेब स्क्रैपिंग के लिए AI आज़माएँ
इसे आज़माएँ! आप देखते-देखते क्लिक कर सकते हैं, एक्सप्लोर कर सकते हैं और वर्कफ़्लो चला सकते हैं।
वेब स्क्रैपिंग कैसे काम करती है?
वेब स्क्रैपिंग का मतलब है वेबसाइटों से डेटा निकालना। आप किसी टूल को निर्देशों का एक सेट देते हैं, और वह वेबपेज से टेक्स्ट, इमेज या जो भी चाहिए, उसे एक टेबल में खींच लाता है। यह ई-कॉमर्स साइट्स पर कीमतों पर नज़र रखने से लेकर रिसर्च डेटा इकट्ठा करने या बस एक बढ़िया Excel स्प्रेडशीट या Google Sheets तैयार करने तक, कई कामों में उपयोगी होता है।
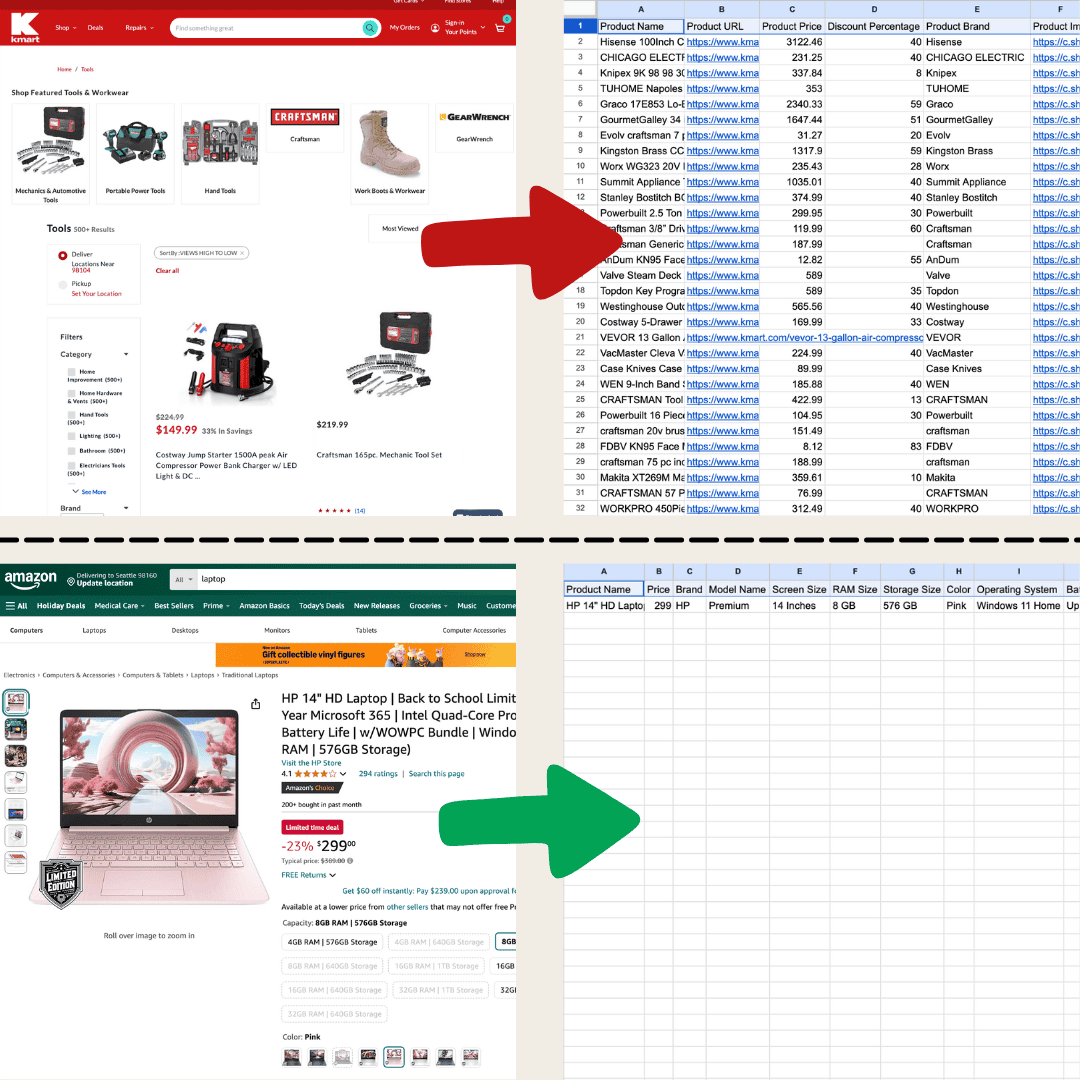 मैंने यह Thunderbit में AI Web Scraper का इस्तेमाल करके बनाया।
मैंने यह Thunderbit में AI Web Scraper का इस्तेमाल करके बनाया।
इसे करने के कुछ तरीके हैं। सबसे आसान स्तर पर आप खुद कॉपी-पेस्ट कर सकते हैं, लेकिन अगर डेटा बहुत ज़्यादा हो तो यह काफी मेहनत वाला काम है। इसलिए ज़्यादातर लोग तीन तरीकों में से एक चुनते हैं: पारंपरिक वेब स्क्रैपर्स, AI वेब स्क्रैपर्स, या कस्टम कोड।
पारंपरिक वेब स्क्रैपर्स पेज की संरचना के आधार पर यह तय करके काम करते हैं कि कौन-सा डेटा निकालना है। उदाहरण के लिए, आप उन्हें कुछ खास HTML टैग्स से प्रोडक्ट के नाम या कीमतें निकालने के लिए सेट कर सकते हैं। ये उन वेबसाइटों पर सबसे अच्छे काम करते हैं जो अक्सर नहीं बदलतीं, क्योंकि लेआउट में ज़रा-सा बदलाव होने पर आपको स्क्रैपर में जाकर उसे फिर से समायोजित करना पड़ता है।
 पारंपरिक स्क्रैपर का इस्तेमाल करना सीखने में काफ़ी समय लगता है, और सेटअप पूरा करने में आपको शायद दर्जनों क्लिक करने पड़ें।
पारंपरिक स्क्रैपर का इस्तेमाल करना सीखने में काफ़ी समय लगता है, और सेटअप पूरा करने में आपको शायद दर्जनों क्लिक करने पड़ें।
AI वेब स्क्रैपर्स का मतलब है: ChatGPT पूरी वेबसाइट को पढ़ता है और फिर आपकी ज़रूरत के मुताबिक सामग्री निकालता है। यह एक ही साथ डेटा एक्सट्रैक्शन, अनुवाद और सारांश—सब कुछ संभाल सकता है। ये प्राकृतिक भाषा प्रसंस्करण का उपयोग करके वेबसाइट के लेआउट का विश्लेषण और समझ करते हैं, इसलिए साइट में होने वाले बदलावों को ये ज़्यादा सहजता से संभाल लेते हैं। मान लीजिए वेबसाइट ने अपने सेक्शन थोड़े इधर-उधर कर दिए—तो AI वेब स्क्रैपर शायद बिना कुछ दोबारा लिखे खुद को ढाल ले। इसलिए ये उन साइटों के लिए बढ़िया हैं जिन्हें अक्सर मेंटेनेंस चाहिए या जिनकी संरचना काफ़ी जटिल है।
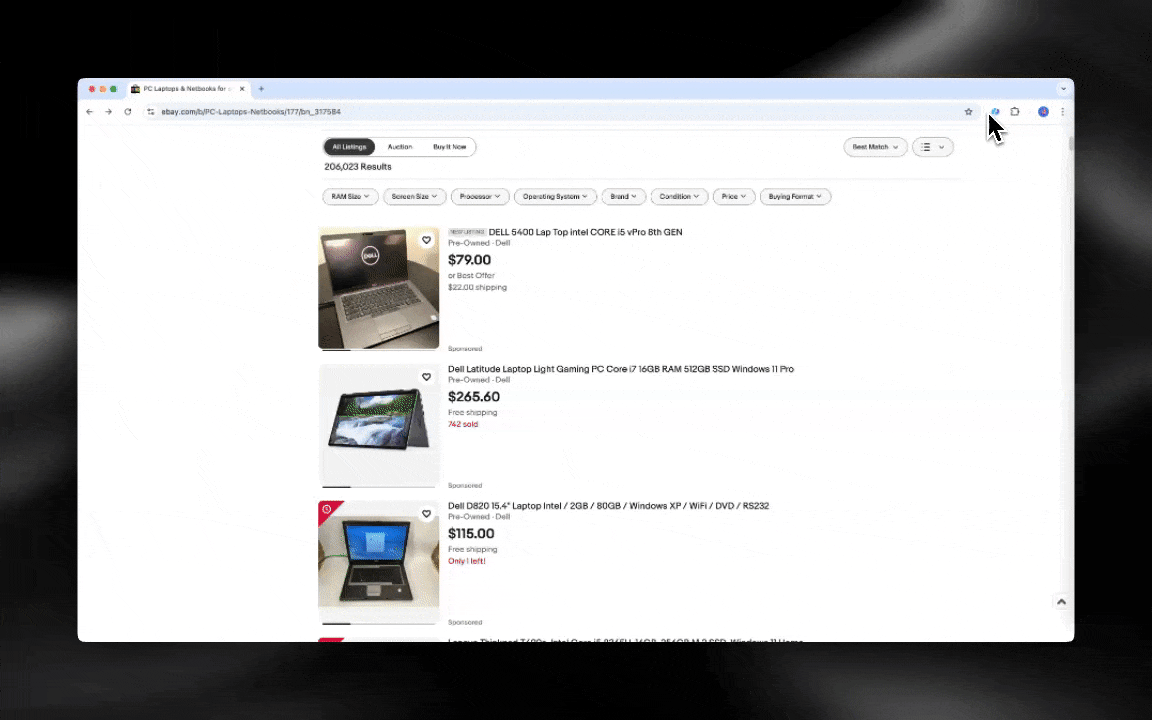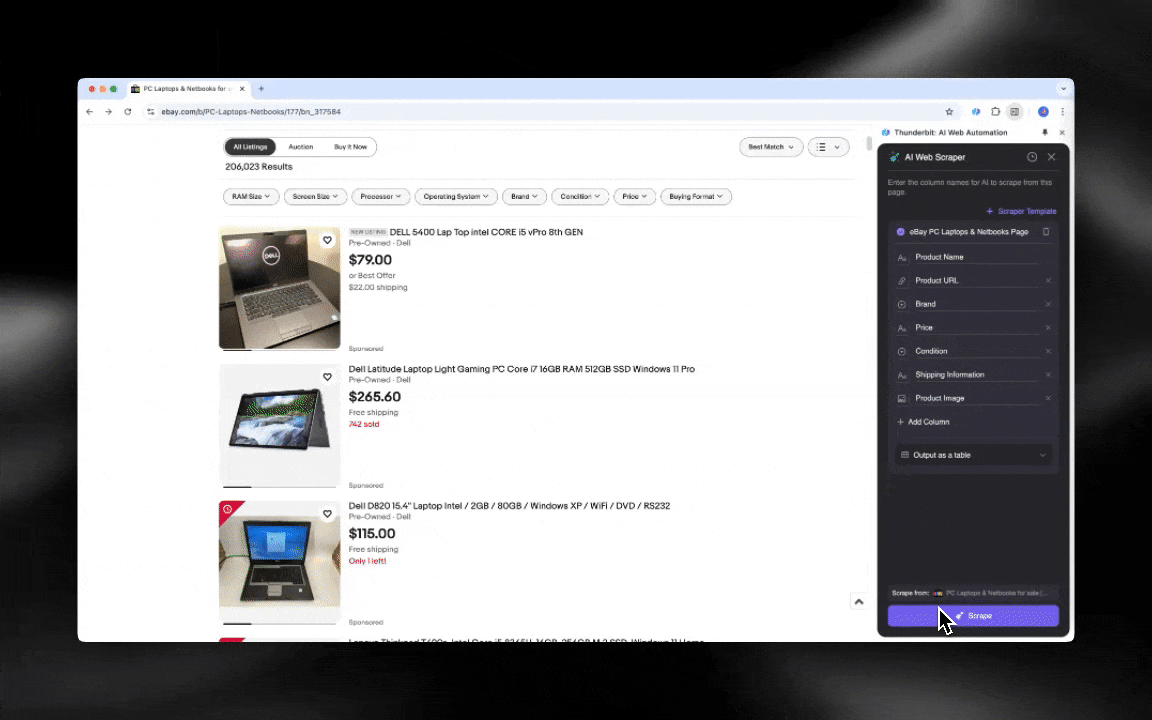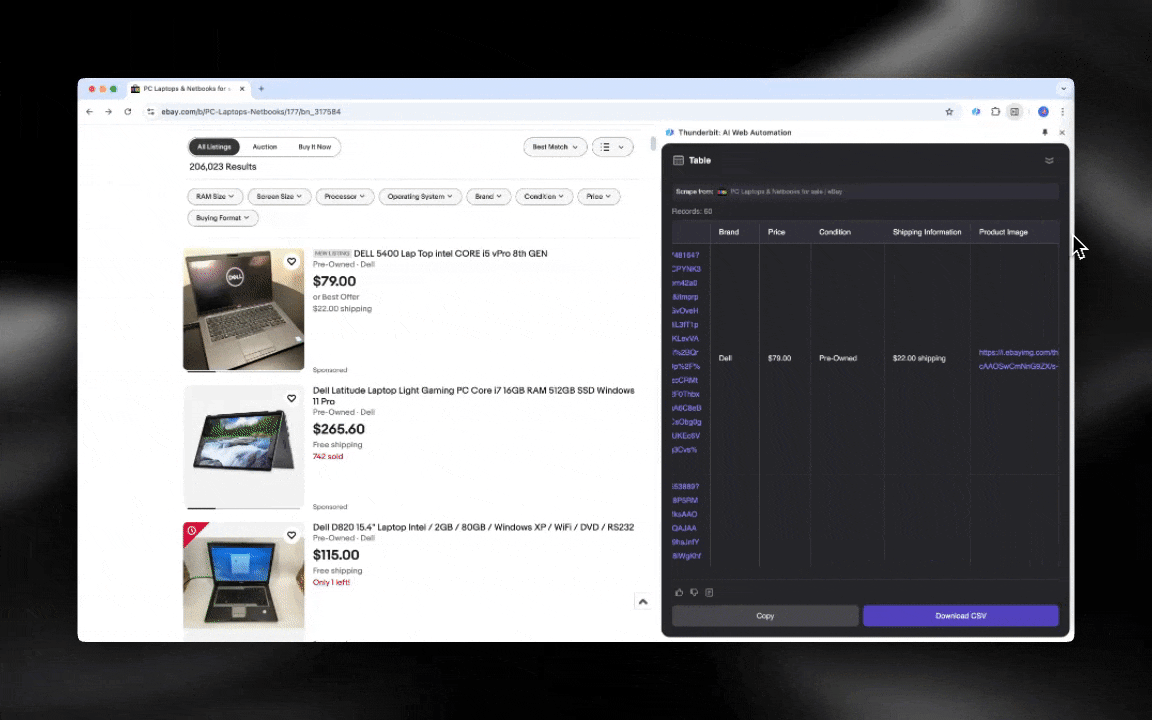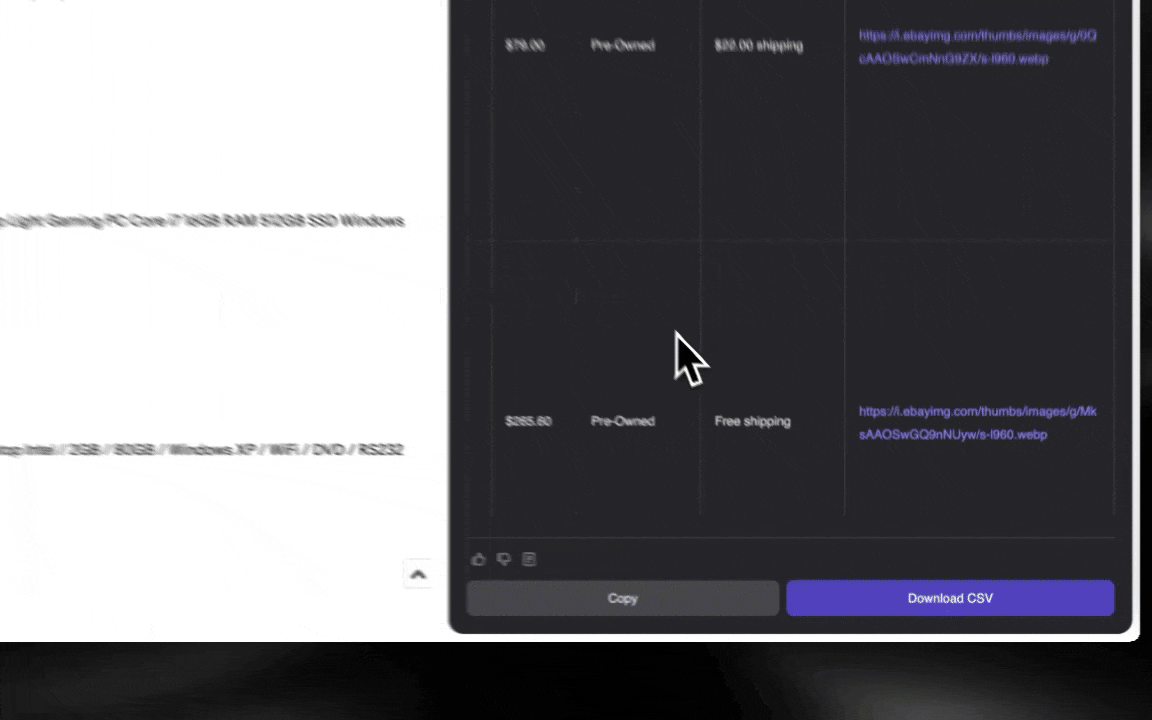 AI वेब स्क्रैपर शुरू करना आसान है और कुछ ही क्लिक में आपको विस्तृत डेटा दे देता है!
AI वेब स्क्रैपर शुरू करना आसान है और कुछ ही क्लिक में आपको विस्तृत डेटा दे देता है!
आपको कौन-सा चुनना चाहिए? यह स्थिति पर निर्भर करता है। अगर आपको कोड से छेड़छाड़ करने में सहजता है या किसी लोकप्रिय वेबसाइट से बहुत बड़ा डेटा इकट्ठा करना है, तो पारंपरिक स्क्रैपर्स काफ़ी दक्ष हो सकते हैं। लेकिन अगर आप वेब स्क्रैपिंग में नए हैं या ऐसा टूल चाहते हैं जो वेबसाइट अपडेट्स के साथ आसानी से चल सके, तो AI वेब स्क्रैपर्स आमतौर पर बेहतर विकल्प हैं। ज़्यादा विस्तृत परिस्थितियों के लिए नीचे दी गई तालिका देखें!
| परिदृश्य | सर्वश्रेष्ठ विकल्प |
|---|---|
| डायरेक्टरी, शॉपिंग वेबसाइटों या किसी भी सूची वाली वेबसाइट जैसे पेजों पर हल्का स्क्रैपिंग | AI Web Scraper |
| पेज में 200 से कम डेटा पंक्तियाँ हों, और पारंपरिक वेब स्क्रैपर से स्क्रैपर बनाना बहुत समय ले | AI Web Scraper |
| आपको जो डेटा स्क्रैप करना है, उसे कहीं और अपलोड करने के लिए किसी खास डेटा फ़ॉर्मैट की ज़रूरत हो। उदाहरण: HubSpot पर अपलोड करने के लिए संपर्क जानकारी स्क्रैप करना। | AI Web Scraper |
| बड़े पैमाने पर व्यापक रूप से उपयोग की जाने वाली वेबसाइटें, जैसे Amazon के हज़ारों प्रोडक्ट पेज या Zillow की प्रॉपर्टी लिस्टिंग। | Traditional Web Scraper |
एक नज़र में सर्वश्रेष्ठ वेब स्क्रैपिंग टूल्स और सॉफ़्टवेयर
| टूल | मूल्य | मुख्य विशेषताएँ | फायदे | कमियाँ |
|---|---|---|---|---|
| Thunderbit | $9/महीने से शुरू, मुफ़्त टियर उपलब्ध | AI वेब स्क्रैपर, डेटा अपने-आप पहचानता और फ़ॉर्मैट करता है, कई फ़ॉर्मैट सपोर्ट, एक-क्लिक एक्सपोर्ट, उपयोगकर्ता-अनुकूल इंटरफ़ेस। | बिना कोड, AI सपोर्ट, Google Sheets जैसे ऐप्स के साथ इंटीग्रेशन | बड़े पैमाने पर स्क्रैपिंग धीमी हो सकती है, उन्नत सुविधाओं की कीमत अधिक हो सकती है |
| Browse AI | $48.75/महीने से शुरू, मुफ़्त टियर उपलब्ध | नो-कोड इंटरफ़ेस, रीयल-टाइम मॉनिटरिंग, बड़े पैमाने पर डेटा एक्सट्रैक्शन, वर्कफ़्लो इंटीग्रेशन। | उपयोग में आसान, Google Sheets और Zapier के साथ इंटीग्रेट करता है | जटिल पेजों के लिए अतिरिक्त सेटअप चाहिए, बड़े पैमाने पर स्क्रैपिंग से टाइमआउट हो सकते हैं |
| Bardeen AI | $60/महीने से शुरू, मुफ़्त टियर उपलब्ध | नो-कोड ऑटोमेशन, 130+ ऐप्स के साथ इंटीग्रेशन, MagicBox कार्यों को वर्कफ़्लोज़ में बदलता है। | व्यापक इंटीग्रेशन, व्यवसायों के लिए स्केलेबल | नए उपयोगकर्ताओं के लिए सीखने की प्रक्रिया कठिन, सेटअप समय लेने वाला |
| Web Scraper | स्थानीय उपयोग के लिए मुफ़्त, क्लाउड के लिए $50/महीना | विज़ुअल टास्क क्रिएशन, डायनेमिक साइट्स (AJAX/JavaScript) सपोर्ट, क्लाउड स्क्रैपिंग। | डायनेमिक साइट्स पर अच्छी तरह काम करता है | बेहतरीन सेटअप के लिए तकनीकी ज्ञान चाहिए |
| Octoparse | $119/महीने से शुरू, मुफ़्त टियर उपलब्ध | नो-कोड स्क्रैपिंग, पेज एलिमेंट्स की ऑटो-डिटेक्शन, शेड्यूल्ड टास्क के साथ क्लाउड स्क्रैपिंग, आम वेबसाइटों के लिए टेम्पलेट लाइब्रेरी। | डायनेमिक साइट्स के लिए शक्तिशाली फीचर्स, प्रतिबंधों को संभालता है | जटिल साइटों के लिए सीखना पड़ता है |
| Diffbot | $299/महीने से शुरू | डेटा एक्सट्रैक्शन API, बिना नियम वाला API, असंरचित टेक्स्ट के लिए NLP, व्यापक नॉलेज ग्राफ़। | मज़बूत AI एक्सट्रैक्शन, व्यापक API इंटीग्रेशन, बड़े पैमाने की स्क्रैपिंग | गैर-तकनीकी उपयोगकर्ताओं के लिए सीखने की प्रक्रिया, सेटअप समय |
AI युग में सर्वश्रेष्ठ वेब स्क्रैपर
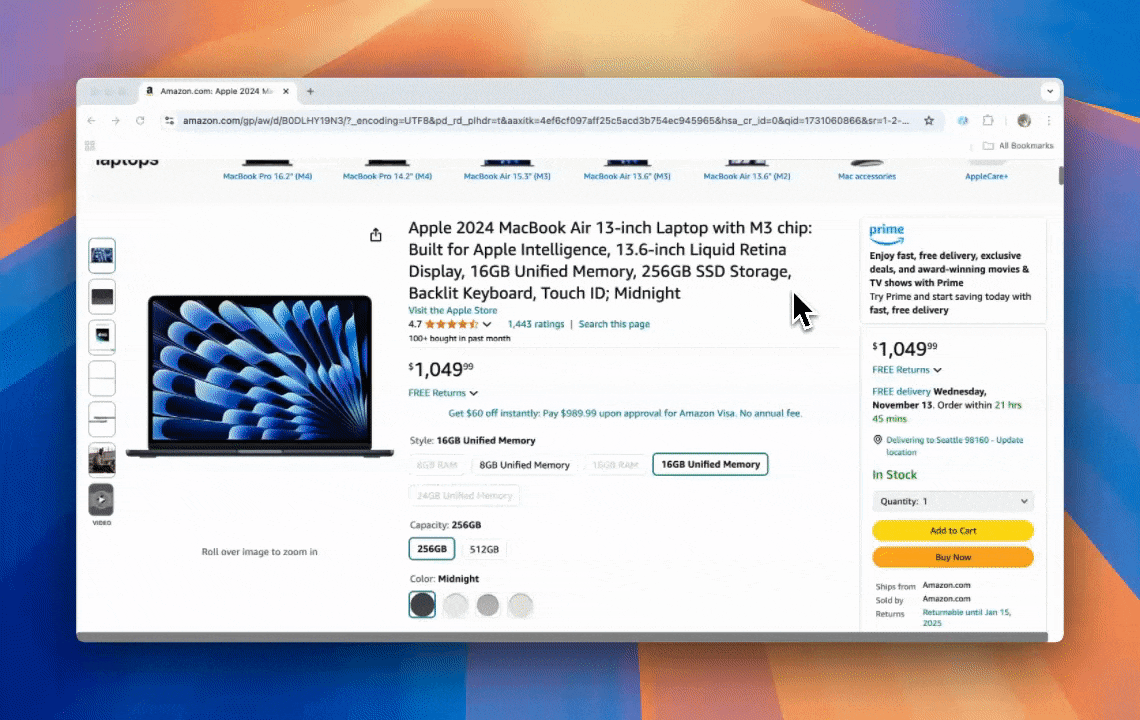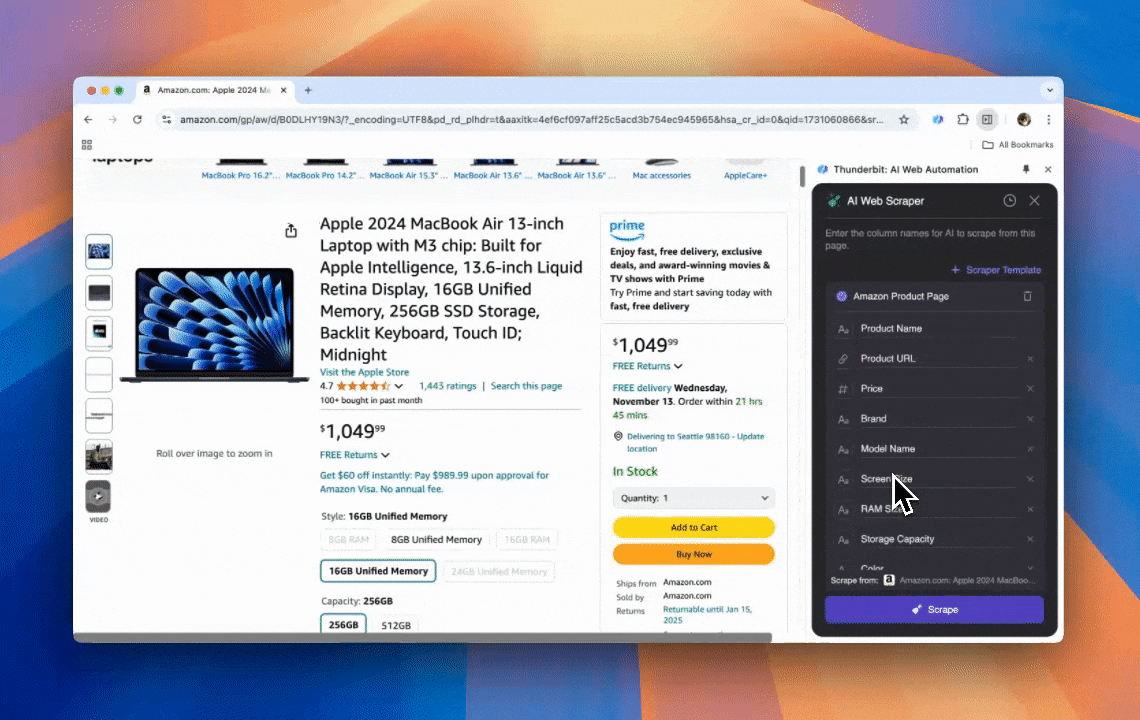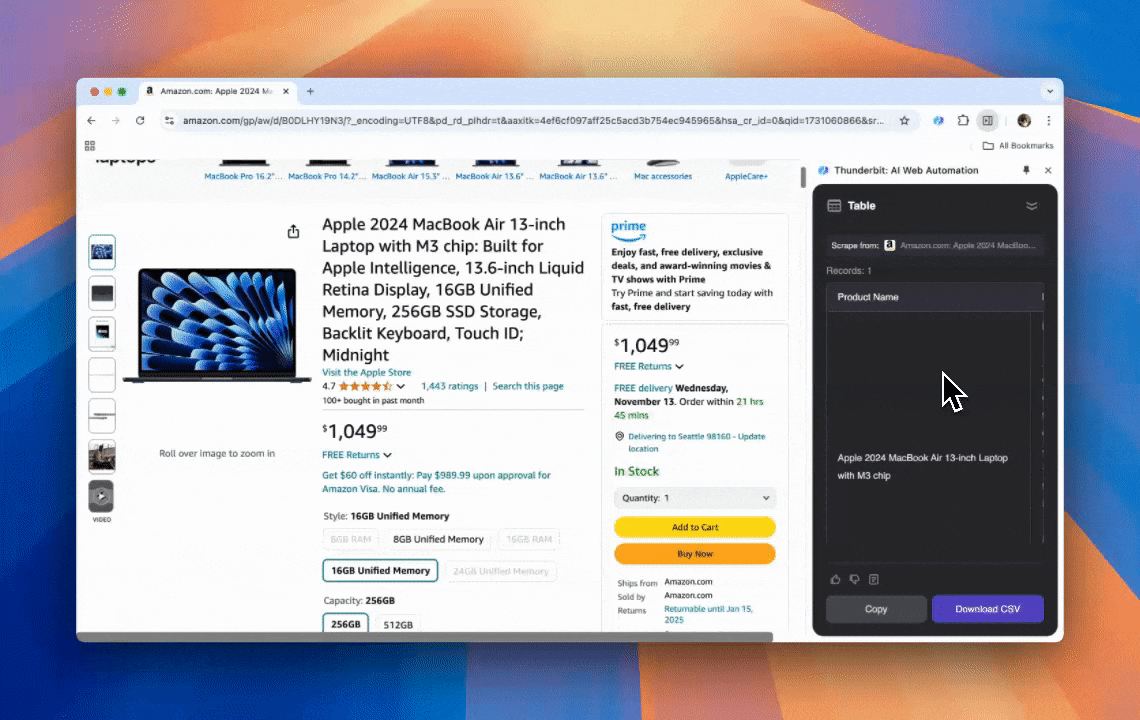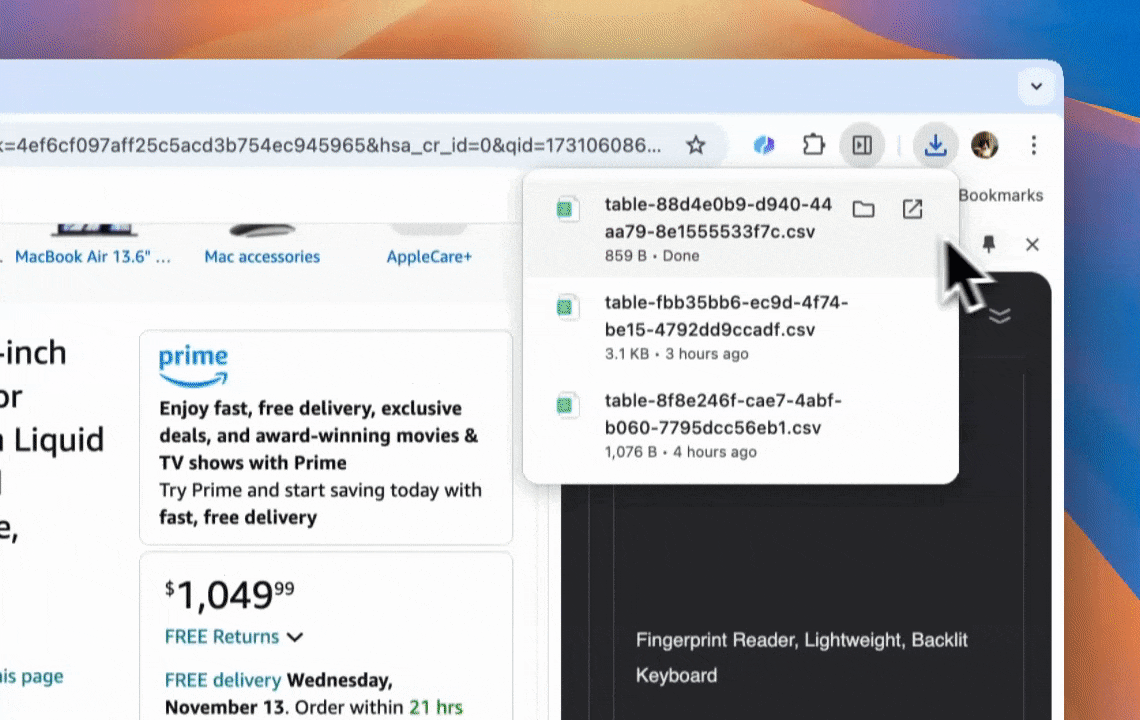
Thunderbit एक शक्तिशाली, उपयोगकर्ता-अनुकूल AI वेब ऑटोमेशन टूल है, जो बिना कोडिंग कौशल वाले उपयोगकर्ताओं को आसानी से डेटा निकालने और व्यवस्थित करने देता है। इसके के साथ, Thunderbit का डेटा स्क्रैपिंग को आसान बना देता है—उपयोगकर्ता वेब एलिमेंट्स के साथ हाथ से इंटरैक्ट किए बिना या अलग-अलग पेज लेआउट के लिए अलग स्क्रैपर सेट किए बिना तेज़ी से वेब डेटा खींच सकते हैं।
मुख्य विशेषताएँ
- AI-संचालित लचीलापन: Thunderbit का AI Web Scraper वेब डेटा को अपने-आप पहचानता और फ़ॉर्मैट करता है, जिससे CSS selectors की ज़रूरत नहीं रहती।
- सबसे आसान स्क्रैपिंग अनुभव: आपको बस उस पेज पर “AI suggest column” पर क्लिक करना है, फिर “Scrape” पर क्लिक करना है। बस इतना ही।
- विभिन्न डेटा फ़ॉर्मैट्स का समर्थन: Thunderbit URLs, इमेज और कैप्चर किए गए डेटा को कई फ़ॉर्मैट्स में दिखा सकता है।
- स्वचालित डेटा प्रोसेसिंग: Thunderbit का AI चलते-चलते डेटा को दोबारा फ़ॉर्मैट कर सकता है, जिसमें उसका सारांश बनाना, वर्गीकृत करना और ज़रूरत के फ़ॉर्मैट में अनुवाद करना शामिल है।
- आसान डेटा एक्सपोर्ट: Google Sheets, Airtable या Notion में एक क्लिक से डेटा एक्सपोर्ट करें, जिससे डेटा प्रबंधन आसान हो जाता है।
- उपयोगकर्ता-अनुकूल इंटरफ़ेस: सहज इंटरफ़ेस इसे हर स्तर के उपयोगकर्ताओं के लिए सुलभ बनाता है।
मूल्य
Thunderbit में टियर-आधारित प्लान हैं, जो 5,000 क्रेडिट्स के लिए $9/माह से शुरू होते हैं। यह 240,000 क्रेडिट्स के लिए $199 तक जाता है। साथ ही, वार्षिक प्लान में आपको सारे क्रेडिट्स शुरुआत में ही मिल जाते हैं।
फायदे:
- मज़बूत AI सपोर्ट डेटा एक्सट्रैक्शन और प्रोसेसिंग को सरल बनाता है।
- बिना कोड, हर कौशल स्तर के उपयोगकर्ताओं के लिए सुलभ।
- डायरेक्टरी, शॉपिंग वेबसाइटों आदि जैसी हल्की स्क्रैपिंग के लिए आदर्श।
- लोकप्रिय ऐप्स में सीधे एक्सपोर्ट के लिए बेहतर इंटीग्रेशन क्षमता।
कमियाँ:
- बड़े पैमाने पर डेटा स्क्रैपिंग में सटीकता सुनिश्चित करने के लिए थोड़ा समय लग सकता है।
- कुछ उन्नत सुविधाओं के लिए पेड सब्सक्रिप्शन चाहिए हो सकता है।
और जानकारी चाहिए? Thunderbit से शुरुआत करें, या Thunderbit के साथ देखें।
डेटा मॉनिटरिंग और बड़े पैमाने पर एक्सट्रैक्शन के लिए सर्वश्रेष्ठ वेब स्क्रैपर
Browse AI
Browse AI एक मज़बूत नो-कोड डेटा स्क्रैपिंग टूल है, जिसे उपयोगकर्ताओं को बिना कोड लिखे डेटा निकालने और मॉनिटर करने में मदद करने के लिए बनाया गया है। Browse AI में कुछ AI सुविधाएँ हैं, लेकिन यह पूरी तरह AI स्क्रैपिंग के स्तर तक नहीं पहुँचता। फिर भी, यह शुरुआत करने वालों के लिए काम आसान ज़रूर कर देता है।
मुख्य विशेषताएँ
- नो-कोड इंटरफ़ेस: उपयोगकर्ता साधारण क्लिकों से कस्टम वर्कफ़्लोज़ बना सकते हैं।
- रीयल-टाइम मॉनिटरिंग: वेबपेज बदलावों पर नज़र रखने और अपडेटेड जानकारी देने के लिए बॉट्स का उपयोग करता है।
- बड़े पैमाने पर डेटा एक्सट्रैक्शन: एक बार में 50,000 तक डेटा एंट्रीज़ संभाल सकता है।
- वर्कफ़्लो इंटीग्रेशन: अधिक जटिल डेटा प्रोसेसिंग के लिए कई बॉट्स को जोड़ता है।
मूल्य
$48.75 प्रति माह से शुरू, जिसमें 2,000 क्रेडिट्स शामिल हैं। एक मुफ़्त टियर उपलब्ध है, जो इसकी बुनियादी सुविधाएँ आज़माने के लिए हर महीने 50 क्रेडिट्स देता है।
फायदे:
- Google Sheets और Zapier के साथ इंटीग्रेशन देता है।
- पहले से बने बॉट्स आम डेटा एक्सट्रैक्शन कार्यों को आसान बनाते हैं।
कमियाँ:
- जटिल पेजों के लिए अतिरिक्त कॉन्फ़िगरेशन चाहिए हो सकता है।
- बड़े पैमाने पर स्क्रैपिंग की गति बदल सकती है, जिससे कभी-कभी टाइमआउट हो जाते हैं।
वर्कफ़्लो इंटीग्रेशन के लिए सर्वश्रेष्ठ वेब स्क्रैपर
Bardeen AI
Bardeen AI एक नो-कोड ऑटोमेशन टूल है, जिसे विभिन्न ऐप्स को जोड़कर वर्कफ़्लोज़ को आसान बनाने के लिए डिज़ाइन किया गया है। यह कस्टम ऑटोमेशन बनाने के लिए AI का उपयोग करता है, लेकिन एक पूर्ण AI स्क्रैपिंग टूल जैसी लचीलापन इसमें नहीं है।
मुख्य विशेषताएँ
- नो-कोड ऑटोमेशन: उपयोगकर्ताओं को क्लिकों के ज़रिए वर्कफ़्लोज़ सेट करने देता है।
- MagicBox: कार्यों को सरल भाषा में बताइए, और Bardeen AI उन्हें वर्कफ़्लोज़ में बदल देता है।
- विस्तृत इंटीग्रेशन विकल्प: Google Sheets, Slack और LinkedIn सहित 130 से अधिक ऐप्स के साथ इंटीग्रेट करता है।
मूल्य
$60 प्रति माह से शुरू, 1,500 क्रेडिट्स के साथ (लगभग 1,500 डेटा पंक्तियाँ)। बुनियादी सुविधाएँ आज़माने के लिए हर महीने 100 क्रेडिट्स वाला मुफ़्त टियर मिलता है।
फायदे:
- व्यापक इंटीग्रेशन विकल्प विविध व्यावसायिक ज़रूरतों को सपोर्ट करते हैं।
- सभी आकार के व्यवसायों के लिए लचीला और स्केलेबल।
कमियाँ:
- नए उपयोगकर्ताओं को पूरे प्लेटफ़ॉर्म को सीखने में समय लग सकता है।
- शुरुआती सेटअप में समय लग सकता है।
अनुभव रखने वाले लोगों के लिए सर्वश्रेष्ठ विज़ुअल वेब स्क्रैपर
Web Scraper
हाँ, आपने सही सुना: इस टूल का नाम ही "Web Scraper" है। Web Scraper Chrome और Firefox के लिए एक लोकप्रिय ब्राउज़र एक्सटेंशन है, जो बिना कोड के डेटा निकालने देता है और स्क्रैपिंग टास्क बनाने का विज़ुअल तरीका प्रदान करता है। हालांकि, इस टूल में पूरी महारत हासिल करने के लिए आपको ऊपर दिए गए ट्यूटोरियल्स देखकर कुछ दिन लगाने पड़ सकते हैं। अगर आप स्क्रैपिंग को अपने दिमाग के लिए आसान बनाना चाहते हैं, तो AI Web Scraper चुनें।
मुख्य विशेषताएँ
- विज़ुअल क्रिएशन: उपयोगकर्ताओं को वेब एलिमेंट्स पर क्लिक करके स्क्रैपिंग टास्क सेट करने देता है।
- डायनेमिक वेबसाइट सपोर्ट: डायनेमिक साइट्स के लिए AJAX रिक्वेस्ट और JavaScript को संभाल सकता है।
- क्लाउड स्क्रैपिंग: नियमित स्क्रैपिंग के लिए Web Scraper Cloud के ज़रिए टास्क शेड्यूल करें।
मूल्य
स्थानीय उपयोग के लिए मुफ़्त; पेड प्लान क्लाउड सुविधाओं के लिए $50/महीने से शुरू होते हैं।
फायदे:
- डायनेमिक साइट्स पर अच्छी तरह काम करता है।
- स्थानीय उपयोग के लिए मुफ़्त है।
कमियाँ:
- सर्वोत्तम सेटअप के लिए तकनीकी ज्ञान चाहिए।
- बदलावों के लिए जटिल परीक्षण करना पड़ता है।
IP ब्लॉकिंग और बॉट डिटेक्शन से बचाने वाला सर्वश्रेष्ठ वेब स्क्रैपर
Octoparse
Octoparse ज़्यादा तकनीकी उपयोगकर्ताओं के लिए बना एक बहुमुखी सॉफ़्टवेयर है, जो बिना कोड के विशिष्ट वेब डेटा इकट्ठा करने और मॉनिटर करने में मदद करता है और बड़े पैमाने की डेटा ज़रूरतों के लिए आदर्श है। Octoparse उपयोगकर्ता के ब्राउज़र पर निर्भर नहीं रहता; इसके बजाय, यह डेटा स्क्रैपिंग के लिए क्लाउड सर्वरों का उपयोग करता है। इसलिए यह IP ब्लॉकिंग और कुछ वेबसाइटों की बॉट डिटेक्शन को पार करने के लिए कई तरीके प्रदान कर सकता है।
मुख्य विशेषताएँ
- नो-कोड ऑपरेशन: उपयोगकर्ता बिना कोड लिखे स्क्रैपिंग टास्क बना सकते हैं, जिससे यह अलग-अलग तकनीकी स्तर वाले उपयोगकर्ताओं के लिए सुलभ होता है।
- स्मार्ट ऑटो-डिटेक्शन: यह पेज डेटा को अपने-आप पहचानता है, स्क्रैपिंग के लिए उपलब्ध एलिमेंट्स को तेज़ी से ढूँढता है, और सेटअप को आसान बनाता है।
- क्लाउड स्क्रैपिंग: 24/7 क्लाउड डेटा स्क्रैपिंग को शेड्यूल्ड टास्क्स के साथ सपोर्ट करता है, जिससे डेटा प्राप्ति में लचीलापन मिलता है।
- विस्तृत टेम्पलेट लाइब्रेरी: सैकड़ों तैयार टेम्पलेट्स देता है, जिससे उपयोगकर्ता बिना जटिल सेटअप के लोकप्रिय वेबसाइटों से जल्दी डेटा ले सकते हैं।
मूल्य
Octoparse की मूल्य योजना $119 प्रति माह से शुरू होती है, जिसमें 100 टास्क शामिल हैं। इसकी बुनियादी कार्यक्षमता को परखने के लिए प्रति माह 10 टास्क वाला मुफ़्त टियर भी उपलब्ध है।
फायदे:
- शक्तिशाली फीचर्स उच्च अनुकूलता के साथ डायनेमिक साइट स्क्रैपिंग को सपोर्ट करते हैं।
- स्क्रैपिंग प्रतिबंधों और डायनेमिक कंटेंट समस्याओं को संभालने के समाधान देता है।
कमियाँ:
- जटिल वेबसाइट संरचनाओं को सेटअप करने में ज़्यादा समय लग सकता है।
- नए उपयोगकर्ताओं को इस्तेमाल की तकनीकें सीखने में समय लग सकता है।
उन्नत AI-संचालित डेटा एक्सट्रैक्शन API के लिए सर्वश्रेष्ठ वेब स्क्रैपर
Diffbot
Diffbot एक उन्नत वेब डेटा एक्सट्रैक्शन टूल है, जो AI का उपयोग करके असंरचित वेब सामग्री को संरचित डेटा में बदलता है। शक्तिशाली APIs और नॉलेज ग्राफ़ के साथ, Diffbot उपयोगकर्ताओं को वेब से जानकारी निकालने, उसका विश्लेषण करने और उसे प्रबंधित करने में मदद करता है, जो विभिन्न उद्योगों और उपयोग मामलों के लिए उपयुक्त है।
मुख्य विशेषताएँ
- डेटा एक्सट्रैक्शन API: Diffbot एक बिना-नियम वाला डेटा एक्सट्रैक्शन API देता है, जिससे उपयोगकर्ता बस एक URL प्रदान करते हैं और डेटा अपने-आप निकल जाता है; हर वेबसाइट के लिए कस्टम नियम बनाने की ज़रूरत नहीं रहती।
- प्राकृतिक भाषा प्रसंस्करण API: असंरचित टेक्स्ट से संरचित एंटिटीज़, संबंध और भावना निकालता है, जिससे उपयोगकर्ताओं को अपना नॉलेज ग्राफ़ बनाने में मदद मिलती है।
- नॉलेज ग्राफ़: Diffbot के पास सबसे बड़े नॉलेज ग्राफ़्स में से एक है, जो व्यक्तियों और संगठनों की जानकारी सहित व्यापक एंटिटी डेटा को जोड़ता है।
मूल्य
Diffbot की मूल्य योजना $299 प्रति माह से शुरू होती है, जिसमें 250,000 क्रेडिट्स शामिल हैं (लगभग 250,000 API-आधारित वेबपेज एक्सट्रैक्शन के बराबर)।
फायदे:
- मज़बूत बिना-नियम डेटा एक्सट्रैक्शन क्षमताएँ और उच्च अनुकूलता।
- मौजूदा सिस्टम्स के साथ आसान इंटीग्रेशन के लिए व्यापक API विकल्प।
- बड़े पैमाने पर डेटा स्क्रैपिंग को सपोर्ट करता है, जो एंटरप्राइज़-स्तरीय अनुप्रयोगों के लिए उपयुक्त है।
कमियाँ:
- शुरुआती सेटअप में गैर-तकनीकी उपयोगकर्ताओं को सीखने में समय लग सकता है।
- उपयोग के लिए API कॉल करने वाला प्रोग्राम लिखना होगा।
आप स्क्रैपर्स का उपयोग किसलिए कर सकते हैं?
अगर आप वेब स्क्रैपिंग में नए हैं, तो शुरुआत करने में मदद के लिए यहाँ कुछ लोकप्रिय उपयोग दिए गए हैं। बहुत-से लोग Amazon प्रोडक्ट लिस्टिंग निकालने, Zillow से रियल एस्टेट डेटा खींचने, या Google Maps से बिज़नेस डिटेल्स इकट्ठा करने के लिए स्क्रैपर्स का इस्तेमाल करते हैं। लेकिन यह तो बस शुरुआत है—आप Thunderbit का उपयोग लगभग किसी भी वेबसाइट से डेटा इकट्ठा करने के लिए कर सकते हैं, जिससे काम आसान होता है और आपकी रोज़मर्रा की वर्कफ़्लो में समय बचता है। चाहे रिसर्च हो, कीमतों पर नज़र रखना हो, या डेटाबेस बनाना हो, वेब स्क्रैपिंग इंटरनेट के डेटा को अपने काम में लगाने के अनगिनत रास्ते खोलती है।
अक्सर पूछे जाने वाले सवाल
-
क्या वेब स्क्रैपिंग कानूनी है?
वेब स्क्रैपिंग आम तौर पर कानूनी होती है, लेकिन इसे वेबसाइट की सेवा शर्तों और एक्सेस किए जा रहे डेटा की प्रकृति का पालन करना चाहिए। हमेशा संबंधित नीतियों की समीक्षा करें और कानूनी दिशानिर्देशों का अनुपालन करें।
-
क्या वेब स्क्रैपिंग टूल्स इस्तेमाल करने के लिए प्रोग्रामिंग कौशल चाहिए?
यहाँ दिखाए गए ज़्यादातर टूल्स को प्रोग्रामिंग कौशल की ज़रूरत नहीं होती, लेकिन Octoparse और Web Scraper जैसे टूल्स का सर्वोत्तम उपयोग करने के लिए उपयोगकर्ताओं को वेब संरचनाओं की बुनियादी समझ और प्रोग्रामिंग जैसी सोच का लाभ मिल सकता है।
-
क्या मुफ़्त वेब स्क्रैपिंग टूल्स उपलब्ध हैं?
हाँ, BeautifulSoup, Scrapy और Web Scraper जैसे मुफ़्त टूल्स उपलब्ध हैं, और कुछ टूल्स सीमित सुविधाओं वाले मुफ़्त प्लान भी देते हैं।
-
वेब स्क्रैपिंग में आम चुनौतियाँ क्या हैं?
आम चुनौतियों में डायनेमिक कंटेंट, CAPTCHA, IP ब्लॉकिंग और जटिल HTML संरचनाएँ संभालना शामिल है। उन्नत टूल्स और तकनीकें इन समस्याओं को प्रभावी ढंग से हल कर सकती हैं।
और जानें:
-
बिना मेहनत AI का उपयोग करें।