HTML पार्सर
क्या बड़ी मात्रा में डेटा स्क्रैप करना है? Thunderbit मुफ़्त में आज़माएँ।








AI से वेबसाइट डेटा निकालें
Thunderbit से HTML कैसे पार्स करें



Raw HTML को पढ़ने योग्य स्ट्रक्चर में पार्स करना सीखें
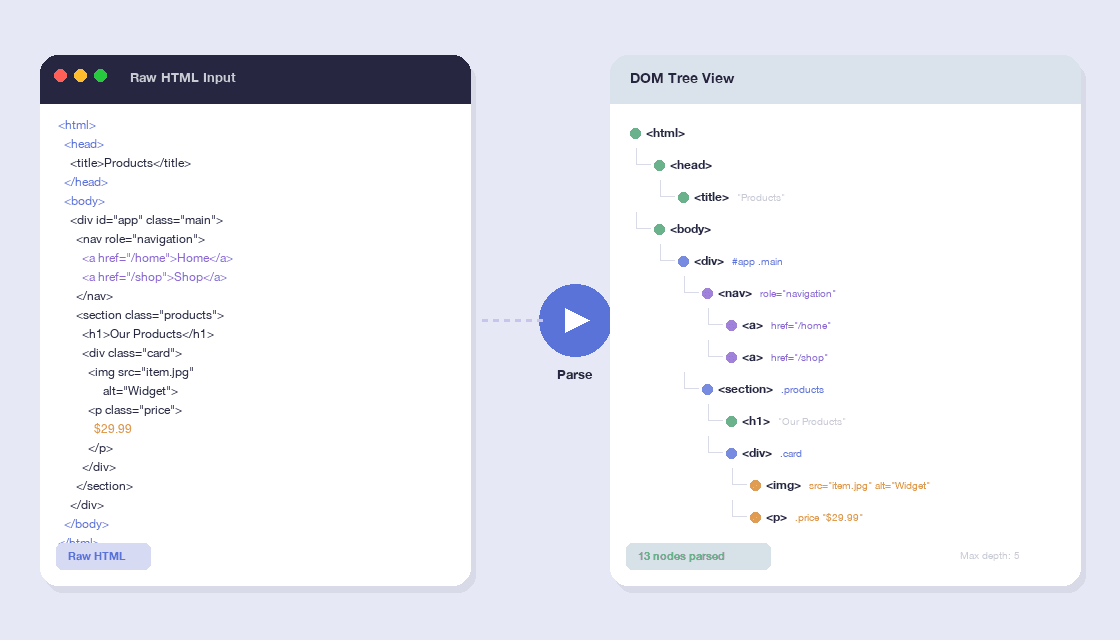
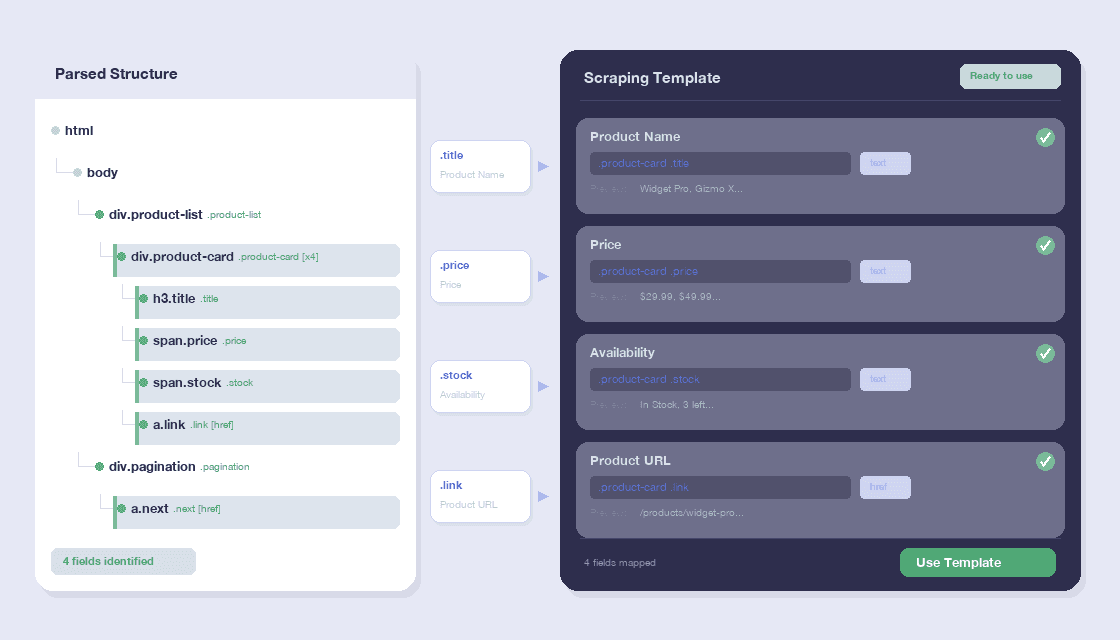
HTML को ट्री व्यू में पार्स करें
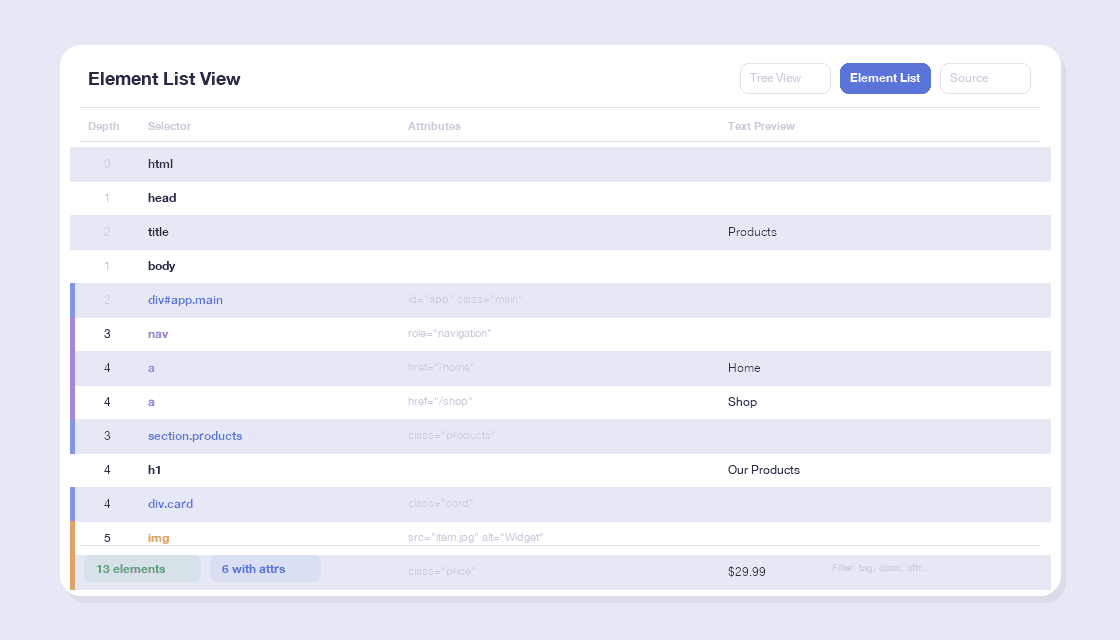
सेलेक्टर्स और एट्रिब्यूट्स के साथ एलिमेंट्स की सूची देखें
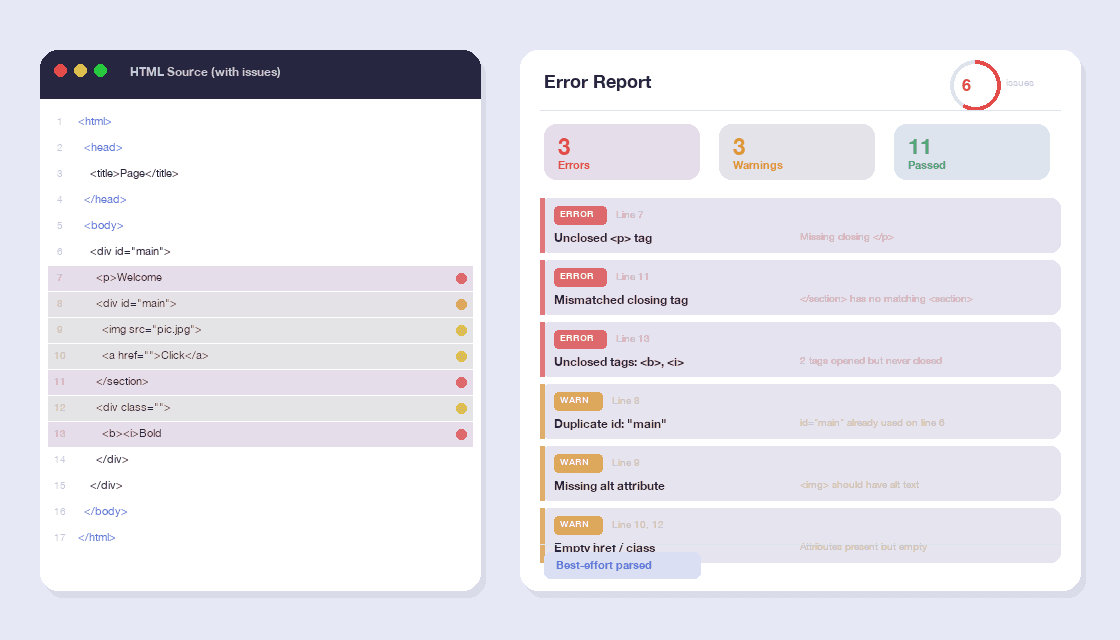
मार्कअप समस्याएँ और संदिग्ध पैटर्न पहचानें
स्क्रैपिंग और डेटा एक्सट्रैक्शन वर्कफ़्लो के लिए HTML तैयार करें
और मुफ़्त टूल्स खोजें
HTML से टेबल कन्वर्टर
HTML टेबल कोड को एक साफ़, संपादनयोग्य टेबल में बदलें, जिसे आप कॉपी या एक्सपोर्ट कर सकें। पेस्ट किए गए मार्कअप को स्प्रेडशीट और डॉक्यूमेंट के लिए संरचित डेटा में बदलने में समय बचाएँ।
बारकोड / UPC लुकअप
बारकोड या UPC कोड डालकर उत्पाद से जुड़ी जानकारी तुरंत देखें। नाम, ब्रांड, निर्माता और श्रेणी जैसी जानकारियाँ पाकर आइटम की पुष्टि करें और प्रोडक्ट रिसर्च की रफ्तार बढ़ाएँ।
डिस्काउंट कैलकुलेटर
मूल कीमत और डिस्काउंट रेट से बचत और अंतिम कीमत निकालें—या अंतिम कीमत से उल्टा हिसाब लगाकर डिस्काउंट प्रतिशत पता करें। दो दशमलव तक सटीक, साफ़-सुथरे टोटल्स के साथ खरीदारी के फैसले तेज़ करें।
ROI कैलकुलेटर
लागत और शुद्ध लाभ के आधार पर निवेश पर रिटर्न (ROI) निकालें। अवसरों की तुलना और प्रोजेक्ट परफॉर्मेंस का आकलन करने के लिए स्पष्ट ROI प्रतिशत पाएं।
वैट चेकर
आधिकारिक डेटाबेस के आधार पर VAT नंबर की पुष्टि करें और उसकी वैधता जांचें। जहाँ उपलब्ध हो, इनवॉइसिंग और कंप्लायंस जोखिम कम करने के लिए रजिस्टर्ड कंपनी की जानकारी—जैसे नाम और पता—भी प्राप्त करें।
ब्रेक-ईवन कैलकुलेटर
कुल लागत कवर करने के लिए आवश्यक बिक्री मात्रा की गणना करें। ब्रेक-ईवन यूनिट्स जानने के लिए स्थिर लागत, प्रति यूनिट परिवर्ती लागत, और प्रति यूनिट मूल्य दर्ज करें। आत्मविश्वास के साथ मूल्य निर्धारण और लक्ष्य तय करें।
नौकरी पोस्टिंग स्क्रैपर
जॉब बोर्ड्स और करियर पेजों से नौकरी लिस्टिंग्स को एक साफ-सुथरी तालिका में स्क्रैप करें, ताकि ट्रैकिंग और विश्लेषण आसान हो। शीर्षक, कंपनियाँ, स्थान, तारीखें और विवरण एक ही एक्सपोर्ट में इकट्ठा करके समय बचाएँ।
Pinterest स्क्रैपर
पिन, बोर्ड, प्रोफ़ाइल और खोज परिणामों से संरचित Pinterest डेटा निकालें। शोध, ट्रेंड ट्रैकिंग और कंटेंट संग्रह के लिए साफ़-सुथरे परिणाम पाएँ।
JSON से Excel कन्वर्टर
JSON को एक साफ़ Excel फ़ाइल में बदलें, ताकि विश्लेषण और साझा करना आसान हो। API रिस्पॉन्स और डेटा एक्सपोर्ट को कुछ ही सेकंड में व्यवस्थित स्प्रेडशीट में बदलें।
यूआरएल एक्सट्रैक्टर और बैच डाउनलोडर
किसी भी पेज से सभी वेबसाइट लिंक निकालें और उन्हें CSV के रूप में डाउनलोड करें। रिसर्च, विश्लेषण, या डेटा संग्रह कार्यों के लिए URL जल्दी इकट्ठा करें।
एचटीएमएल से सीएसवी
एचटीएमएल टेबल मार्कअप को साफ़ सीएसवी में बदलें, जिसे आप स्प्रेडशीट में पेस्ट कर सकें। एक या अधिक टेबलों से पंक्तियाँ और कॉलम सटीक रूप से निकालें, ताकि डेटा का दोबारा उपयोग तेज़ हो।
सीएसवी फ़ाइल मर्जर
कई CSV फ़ाइलों को एक साफ़ डेटासेट में मर्ज करें। मिलते-जुलते या अलग-अलग कॉलम जोड़ें, हेडर नियंत्रित करें, और डुप्लिकेट हटाएँ। कुछ ही सेकंड में एक एकीकृत CSV डाउनलोड करें।
MX रिकॉर्ड लुकअप
किसी डोमेन के Mail Exchange (MX) रिकॉर्ड देखकर ईमेल रूटिंग, प्राथमिकता (Priority) और DNS सेटअप की पुष्टि करें—ताकि ट्रबलशूटिंग तेज़ हो सके।
Indeed जॉब डेटा एक्सट्रैक्टर
किसी भी Indeed जॉब लिस्टिंग पेज से कंपनी के नाम, जॉब टाइटल, पोस्टिंग URL, लोकेशन और जॉब टाइप निकालें। विश्लेषण या आउटरीच के लिए संरचित जॉब डेटा इकट्ठा करने में समय बचाएँ।
BIN चेकर
कार्ड का BIN खोजकर जारी करने वाला बैंक, ब्रांड, प्रकार और देश पहचानें। भुगतान विवरण सत्यापित करके गलतियाँ कम करें और जोखिमभरे लेन-देन जल्दी पकड़ें।
ईएसपी खोजक
किसी ईमेल या डोमेन के पीछे कौन-सा Email Service Provider (ESP) है, यह पहचानें। प्रोवाइडर की जानकारी, MX रिकॉर्ड्स और कॉन्फिडेंस स्कोर देखकर आउटरीच और IT वेरिफिकेशन को सपोर्ट करें।