

In Büros überall passiert gerade etwas Stilles, aber Folgenreiches. Es hat nichts mit Tischkicker oder Kombucha-Zapfhahn zu tun. Gemeint ist der Durchbruch des „einfachen Web-Extrahierens“: Plötzlich kann nicht mehr nur die IT-Abteilung, sondern praktisch jeder in Minuten brauchbare Daten aus dem Netz ziehen, wo früher Tage vergingen. Sie kennen das vielleicht: Da steht eine Website voller Namen, Preise oder E-Mail-Adressen, und Sie wünschen sich nichts sehnlicher, als das Ganze in eine Tabelle zu übernehmen. Damit sind Sie keineswegs allein. In Gesprächen mit Vertrieb, Marketing und Operations höre ich immer denselben Satz: „Warum ist das eigentlich noch so kompliziert?“
Fakt ist: Der Bedarf an einfachen Wegen zum Web-Scraping wächst rasant. Laut McKinseys State of AI 2025 setzen 71 % der Unternehmen generative KI mittlerweile in mindestens einem Geschäftsbereich ein (Anfang 2024 waren es noch 65 %), und die Extraktion von Webdaten gehört zu den am schnellsten wachsenden Anwendungsfällen. Der Markt für Web-Scraping bewegt sich auf 1,17 Milliarden US-Dollar im Jahr 2026 zu und soll bis 2031 auf 2,23 Milliarden US-Dollar klettern. Getrieben wird das von Business-Anwendern, oft ohne technischen Hintergrund, die sich Tools wünschen, mit denen Datenextraktion so leicht von der Hand geht wie Kopieren und Einfügen. Aber was genau steckt hinter „einfachem Web-Extrahieren“, und wie machen Sie sich das für Ihren Arbeitsalltag zunutze? Genau das klären wir hier.
Einfaches Web-Extrahieren mit Thunderbit testen (kostenlos)
Einfaches Web-Extrahieren für Nicht-Techniker: Kein Code, kein Kopfzerbrechen
Beginnen wir mit der Grundfrage: Was bedeutet „einfaches Web-Extrahieren“ überhaupt? Im Kern geht es darum, das unübersichtliche, ständig wechselnde Web in saubere, strukturierte Tabellen zu überführen, ohne eine einzige Zeile Code. Für nicht-technische Anwender ist das ein echter Wendepunkt. Niemand muss mehr die IT um Hilfe bitten, sich mit Python-Skripten herumschlagen oder kapitulieren, weil eine Website über Nacht ihr Layout umgestellt hat.
Warum ausgerechnet jetzt? Weil das Web dynamischer ist denn je. Infinite Scroll, Pop-ups und verschachteltes JavaScript hebeln klassische Scraper reihenweise aus. Gleichzeitig wächst der Druck auf Business-Teams, schnell Ergebnisse zu liefern, immer weiter. Im Einzelhandel und E-Commerce bezeichnen 98 % der Unternehmen öffentliche Webdaten als entscheidend oder sehr wichtig für ihre Abläufe, und mehr als die Hälfte greift täglich darauf zu.
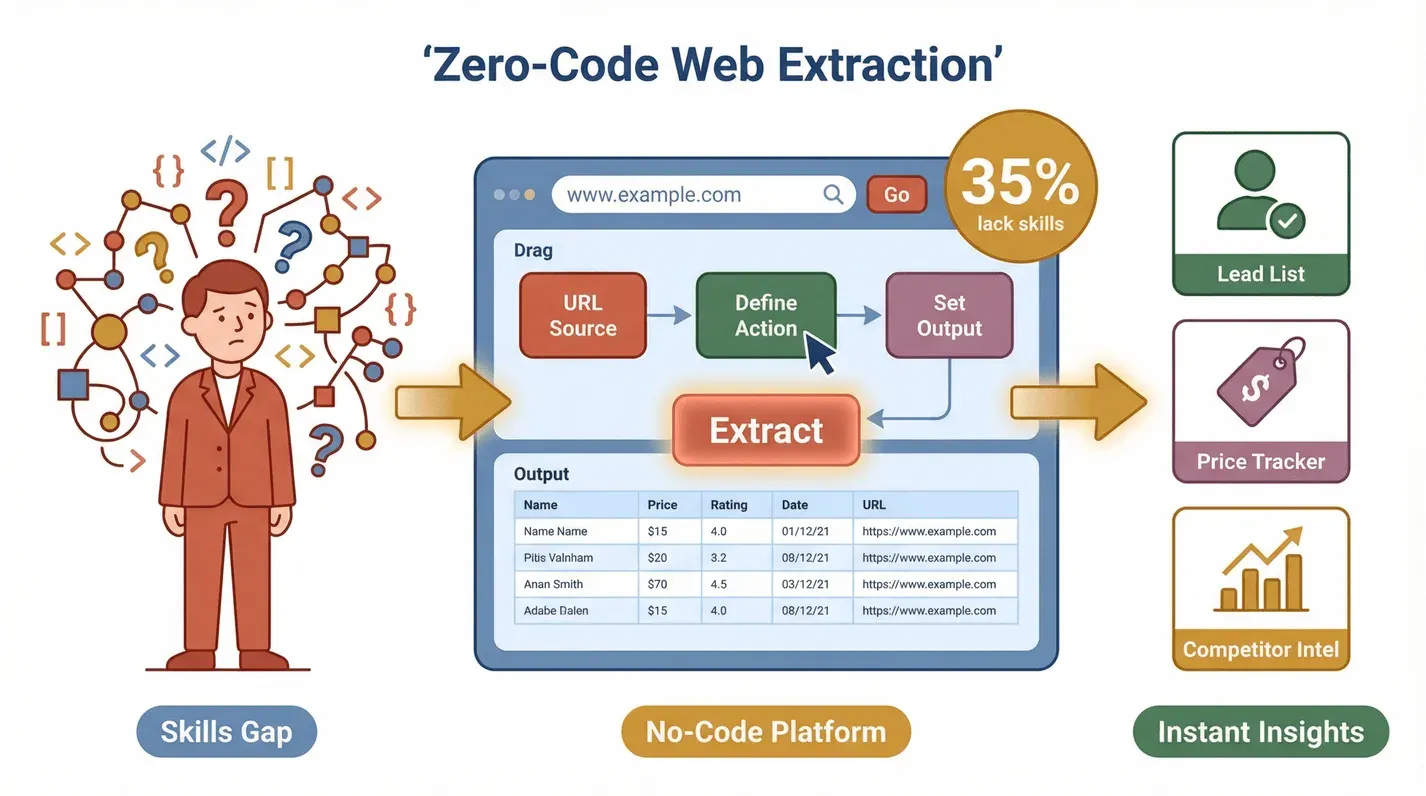
Der Knackpunkt: Die meisten dieser Teams arbeiten nicht technisch. Eine aktuelle Umfrage zeigt, dass 35 % der Unternehmen die nötigen Fähigkeiten für die Webdaten-Extraktion fehlen und 33 % nicht über die passenden Tools verfügen. Darin liegt eine enorme Chance für No-Code-Lösungen. Wenn wirklich jeder Webdaten erschließen und verwenden kann, eröffnen sich ganz neue Produktivitätsebenen, ob beim Aufbau einer Lead-Liste, bei der Wettbewerbsbeobachtung oder beim Preis-Monitoring.
Die No-Code-/Low-Code-Bewegung: Warum sie wichtig ist
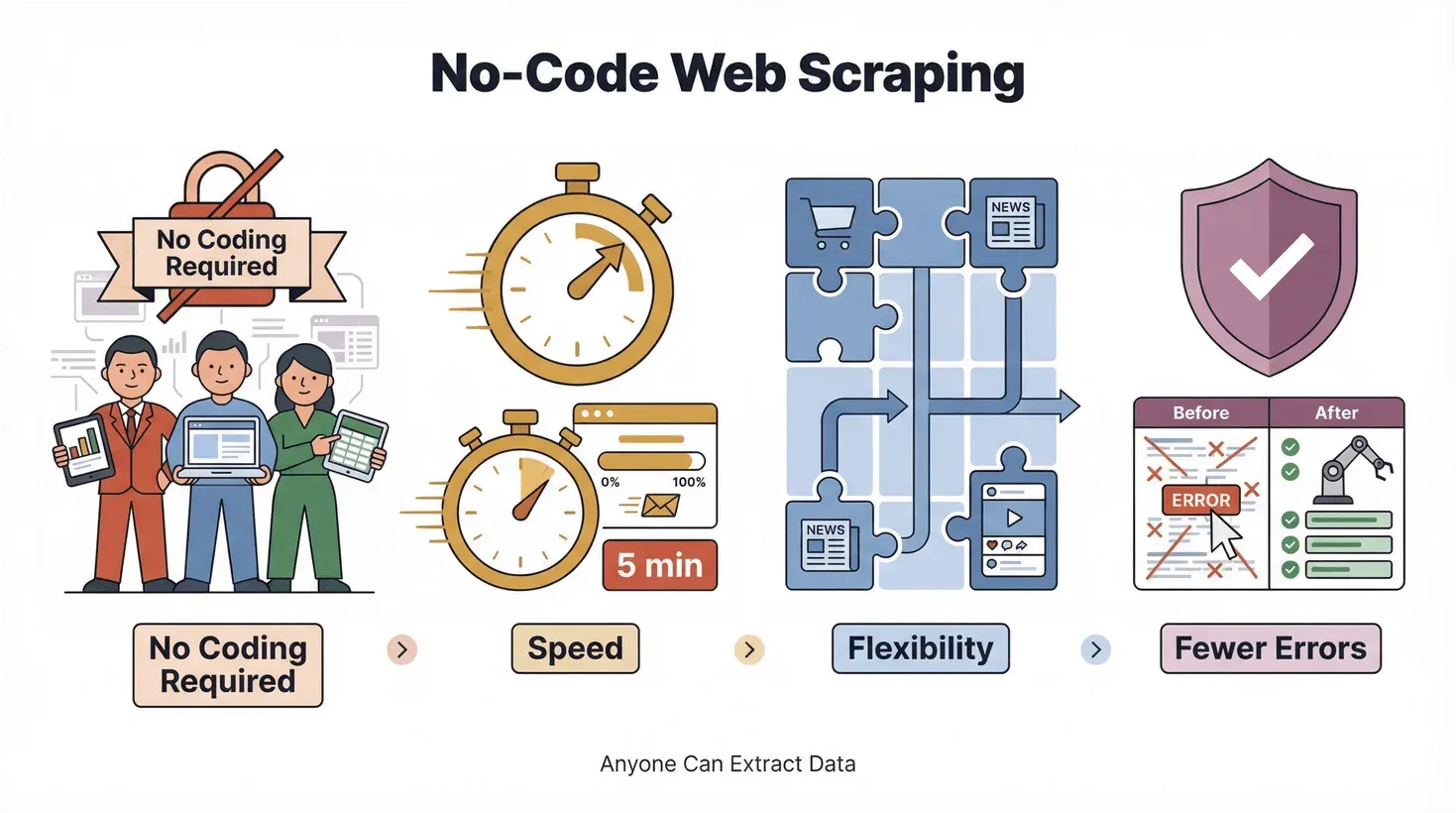
Der Aufstieg von No-Code- und Low-Code-Werkzeugen demokratisiert Technologie. Das ist kein hohles Silicon-Valley-Schlagwort, sondern verändert handfest, wie Arbeit erledigt wird. Fürs Web-Scraping heißt das konkret:
- Kein Programmieren nötig: Daten extrahiert jeder, nicht nur Entwickler.
- Tempo: Ergebnisse in Minuten statt Tagen.
- Flexibilität: Neue Websites und Datenanforderungen lassen sich sofort abdecken.
- Weniger Fehler: Automatisierung verhindert die typischen Copy-Paste-Patzer.
Dabei müssen Sie kein Tech-Genie werden, um mitzumachen.
Warum traditionelle Web-Scraping-Tools so frustrierend sind
Klassische Web-Scraping-Tools wirken oft, als hätten Entwickler sie für Entwickler gebaut – nicht für Business-Anwender. Ich habe es selbst beobachtet: Ein Team startet voller Tatendrang in ein Projekt und läuft prompt gegen eine Wand, sobald das Tool CSS-Selektoren, XPath oder reguläre Ausdrücke verlangt. Es folgen ratlose Blicke und die E-Mail mit dem Betreff „vielleicht nächstes Quartal“.
Diese Punkte gehen typischerweise schief:
- Programmierung vorausgesetzt: Die meisten Legacy-Tools erwarten Skripte oder komplexe Vorlagenkonfigurationen.
- Aufwendige Einrichtung: Jedes Feld muss gemappt, Login-Flows behandelt und Proxys konfiguriert werden, damit Sie nicht gesperrt werden.
- Brüchige Logik: Eine Layout-Änderung genügt, und der Scraper streikt. Statt Ihrer eigentlichen Arbeit debuggen Sie dann Code.
- Hoher Wartungsaufwand: Bei jedem Seiten-Update fangen Sie wieder von vorn an.
Wenig überraschend melden dieselben Teams, die einen Skill-Mangel beklagen, auch einen Tool-Mangel: Bright Datas Umfrage 2024 ergab, dass 35 % der Unternehmen die richtigen Fähigkeiten und 33 % die richtigen Tools für die Arbeit mit öffentlichen Webdaten fehlen. Selbst versierte Teams kämpfen zusätzlich mit IP-Sperren, dynamischen Inhalten und CAPTCHAs.
Dabei wollen Business-Anwender nur eines: einen unkomplizierten, verlässlichen Weg, Daten in ihre Tabellen oder CRMs zu bekommen. Genau an dieser Stelle kommen einfaches Web-Extrahieren und unkomplizierte Scraping-Methoden ins Spiel.
Wie Thunderbit einfaches Web-Extrahieren möglich macht
Daten von jeder Website mit KI extrahieren Get Started Free
Bei diesem Thema werde ich gern etwas leidenschaftlich – denn genau dieses Problem wollten wir bei Thunderbit lösen. Unser Anspruch: Web-Scraping so einfach machen, dass es wirklich jeder hinbekommt, unabhängig vom technischen Vorwissen.
Thunderbit ist eine KI-Web-Scraper-Chrome-Erweiterung, die aus der Web-Extraktion einen Zwei-Klick-Vorgang macht. So läuft es ab:
- Beschreiben Sie Ihr Ziel: Sagen Sie Thunderbit in natürlicher Sprache, welche Daten Sie brauchen – etwa: „Extrahiere alle Produktnamen und Preise von dieser Seite.“
- Klicken Sie auf „KI-Felder vorschlagen“: Die KI liest die Seite und empfiehlt die sinnvollsten Spalten – „Name“, „Preis“, „E-Mail“ oder „Bild“.
- Klicken Sie auf „Scrapen“: Den Rest übernimmt Thunderbit, inklusive Pagination, Unterseiten und – bei Bedarf – geschützter Inhalte nach dem Login.
Mehr ist es nicht. Kein Code, keine Vorlagen, kein Einrichtungsstress. Die Oberfläche ist auf Business-Anwender zugeschnitten – Vertrieb, Marketing, E-Commerce, Immobilien –, also auf Menschen, die schlicht Ergebnisse wollen.
Thunderbits KI-gestützter Workflow: Intelligenter statt aufwendiger
Der eigentliche Clou steckt in der KI. Thunderbit rät nicht, was Sie wollen. Es liest die Seite, erfasst den Kontext und strukturiert die Daten von selbst. Wer es ausgefeilter mag, hinterlegt pro Feld eigene Anweisungen (etwa „diese Spalte kategorisieren“ oder „ins Deutsche übersetzen“); die meisten klicken aber einfach drauf und legen los.
Dieser KI-Ansatz bringt:
- Weniger Fehler: Die KI stellt sich auf unterschiedliche Layouts ein, sodass die Ergebnisse auch bei Website-Änderungen konsistent bleiben.
- Schnellere Einrichtung: Keine Vorlagen bauen, keine Skripte schreiben.
- Direkt verwendbare Daten: Thunderbit kann beim Scrapen beschriften, kategorisieren und sogar anreichern.
Tiefer einsteigen können Sie über die Thunderbit-Dokumentation oder unseren Blogbeitrag zur automatisierten Datenextraktion. Weitere Anleitungen finden Sie im Thunderbit Blog, etwa Wie man mit KI jede Website scrapt und Was ist Data Scraping und wie geht es 2025?.
Thunderbits einzigartige Funktionen für einfache Methoden zum Web-Scraping
Was Thunderbit heraushebt, ist nicht allein die KI, sondern der gesamte Workflow, der konsequent an echten Geschäftsanforderungen ausgerichtet ist. Diese Funktionen schätzen unsere Nutzer besonders:
- Automatische Pagination: Thunderbit verarbeitet mehrseitige Websites und Infinite Scroll ohne jede Einrichtung.
- Unterseiten-Scraping: Sie brauchen mehr Details? Thunderbit ruft jede Unterseite auf (etwa Produktdetails oder LinkedIn-Profile) und reichert Ihren Datensatz automatisch an.
- Überall exportieren: Schicken Sie Ihre Daten direkt nach Excel, Google Sheets, Airtable, Notion – oder laden Sie sie als CSV/JSON. Schluss mit Copy-Paste-Marathons.
- Funktioniert hinter dem Login: Scrapen Sie Daten von Seiten, die einen Login erfordern – Thunderbit läuft in Ihrem Browser und sieht, was Sie sehen.
- KI-gestützte Beschriftung und Kategorisierung: Hinterlegen Sie Anweisungen, um Daten schon beim Extrahieren zu klassifizieren, zu taggen oder zu übersetzen.
- Geplantes Scraping: Richten Sie wiederkehrende Jobs ein, damit Ihre Daten frisch bleiben – ideal fürs Preis-Monitoring oder Lead-Tracking.
Und ja: All das steckt in einem Tool, dem weltweit über 100.000 Nutzer vertrauen.
Automatische Pagination und Extraktion von Unterseiten
Eine der größten Hürden beim Web-Scraping sind paginierte Listen und verschachtelte Detailseiten. Bei Thunderbit müssen Sie sich darum nicht kümmern. Die KI erkennt Pagination – egal ob „Weiter“-Button oder Infinite Scroll – und folgt Links zu Unterseiten ganz von selbst. So extrahieren Sie Hunderte oder Tausende Datensätze in einem Rutsch, ohne einen einzigen Klick von Hand.
Scrapen Sie etwa Produktlisten auf Amazon, erfasst Thunderbit alle Produkte über mehrere Seiten hinweg und steigt anschließend in jede Produktseite ein, um Bewertungen, Rezensionen oder Verkäuferinformationen zu holen. Die Extraktion läuft dabei zuverlässig durch, ohne dass Sie eingreifen müssen.
Export in mehreren Formaten und CRM-Integration
Daten nützen nur, wenn Sie sie auch verwenden können. Thunderbit exportiert in genau dem Format, das Ihr Team braucht – Excel, Google Sheets, Airtable, Notion oder CSV/JSON. Sie können Daten sogar direkt in Ihr CRM oder in Workflow-Tools übergeben, damit Vertrieb und Operations stets auf dem aktuellen Stand sind.
Diese direkte Anbindung spart enorm viel Zeit. Kein mühsames Aufräumen von Exporten, kein Umsortieren von Spalten: Das übernimmt Thunderbits KI für Sie.
Praxisnahe Anwendungsfälle für einfaches Web-Extrahieren
Wo entfaltet einfaches Web-Extrahieren also die größte Wirkung? Hier ein paar reale Szenarien aus dem Alltag von Thunderbit-Nutzern:
Lead-Extraktion für den Vertrieb
Vertriebsteams leben von ihren Lead-Listen. Mit Thunderbit scrapen Sie Kontaktdaten aus LinkedIn, Google Maps oder Branchenverzeichnissen in Minuten. Seite öffnen, „KI-Felder vorschlagen“ klicken – und Thunderbit überträgt Namen, E-Mail-Adressen, Telefonnummern und Firmeninfos in eine sofort nutzbare Tabelle.
Ein Vertriebsleiter erzählte mir, sein Team habe früher Woche für Woche Stunden mit dem Kopieren von Leads verbracht. Heute baut es mit Thunderbit zielgenaue Listen in einem Bruchteil der Zeit und kann sich wieder auf die Ansprache statt auf Dateneingabe konzentrieren.
E-Commerce und Marktbeobachtung
E-Commerce-Teams verfolgen mit Thunderbit Wettbewerber-SKUs, Preise und Bewertungen auf Amazon, Shopify und anderen Plattformen. Sie wollen Preisänderungen oder neue Produkteinführungen im Blick behalten? Richten Sie einen geplanten Scrape ein und finden Sie jeden Morgen frische Daten in Ihrem Google Sheet.
Besonders praktisch ist hier das Unterseiten-Scraping: Produktdetails, Bilder und sogar Kundenbewertungen erfassen Sie, ohne selbst Hand anzulegen.
Erfassung von Immobiliendaten
Immobilienprofis sammeln mit Thunderbit Objektangebote, Preise und Maklerinformationen von Portalen wie Zillow oder Realtor.com. Pagination und Unterseiten übernimmt die KI, sodass Sie einen vollständigen, aktuellen Marktüberblick erhalten – ideal für Analysen oder Kundenberichte.
Ein Immobilienanalyst berichtete mir, dass das, wofür er früher einen ganzen Nachmittag brauchte, heute nur noch ein paar Klicks kostet. Genau das ist die Stärke unkomplizierter Scraping-Methoden.
Vergleich traditioneller und einfacher Methoden zum Web-Scraping
Stellen wir alles übersichtlich gegenüber:
| Funktion | Traditionelle Scraper | Einfaches Web-Extrahieren (Thunderbit) |
|---|---|---|
| Programmierung erforderlich | Ja (Skripte, Selektoren) | Nein (KI + natürliche Sprache) |
| Einrichtungszeit | Hoch (Vorlagen, Konfiguration) | Gering (2 Klicks) |
| Wartung | Häufig (bricht bei Seitenänderungen) | Minimal (KI passt sich an) |
| Pagination | Manuelle Einrichtung | Automatisch |
| Extraktion von Unterseiten | Komplexe Logik | 1 Klick |
| Exportformate | Oft eingeschränkt | Excel, Sheets, Airtable, Notion, CSV, JSON |
| Funktioniert auf Seiten mit Login | Manchmal (mit Konfiguration) | Ja (browserbasiert) |
| Datenbeschriftung/Kategorisierung | Manuelle Nachbearbeitung | KI-gestützt, integriert |
| Planung/Monitoring | Manchmal (fortgeschritten) | Ja (einfache Einrichtung) |
Der Unterschied ist deutlich. Mit Thunderbit erschließt, ordnet und nutzt jeder Webdaten, ganz ohne technische Kenntnisse.
Zukunftstrends bei einfachem Web-Extrahieren und einfachen Methoden zum Web-Scraping
Der Ausblick fürs einfache Web-Extrahieren ist vielversprechend. Die KI wird immer leistungsfähiger, und der Bedarf an No-Code-Tools steigt schnell. Laut McKinseys State of AI 2025 nutzen 88 % der Unternehmen KI inzwischen regelmäßig in mindestens einer Funktion (nach 78 % im Vorjahr), und agentische Systeme, also KI-Tools für mehrstufige Web-Workflows, gewinnen an Boden.
Was bedeutet das für Business-Anwender? Mehr Leistung bei weniger Aufwand. Mit der nächsten KI-Generation ist zu erwarten:
- Noch präzisere Felderkennung: Die KI erfasst komplexere Daten und Zusammenhänge.
- Bessere Integration: Direkte Verbindungen zu mehr Business-Tools und Plattformen.
- Höhere Zuverlässigkeit: Weniger Ausfälle, konsistentere Ergebnisse – auch auf dynamischen oder geschützten Seiten.
- Mehr Zugänglichkeit: Web-Extraktion wird für alle zur Standardfähigkeit, nicht nur für Tech-Profis.
Und natürlich gestaltet Thunderbit diese Entwicklung aktiv mit.
Fazit und wichtigste Erkenntnisse
Thunderbit-Tarife und Credits ansehen Get Started Free
Das Web ist die größte Datenbank der Welt, doch bis vor Kurzem hatten nur Entwickler echten Zugriff darauf. Das ändert sich gerade in hohem Tempo. Mit einfachem Web-Extrahieren verwandelt heute jeder Websites in Minuten in nutzbare Daten.
Das nehme ich aus den letzten Jahren mit – und das gebe ich Ihnen mit auf den Weg:
- No-Code-Web-Extraktion bleibt: Tools wie Thunderbit machen es möglich, Webdaten ohne technisches Vorwissen zu sammeln und zu nutzen.
- KI ist der entscheidende Hebel: Indem sie Feldauswahl, Pagination, Unterseiten-Extraktion und Beschriftung automatisiert, spart KI-gestütztes Scraping Zeit und senkt die Fehlerquote.
- Der geschäftliche Nutzen ist real: Vertriebs-, E-Commerce- und Immobilien-Teams verzeichnen schon heute Produktivitätsgewinne, aktuellere Daten und bessere Entscheidungen.
- Die Zukunft wird noch besser: Mit der Reife von KI und No-Code-Tools wird Webdatenextraktion so selbstverständlich wie das Verschicken einer E-Mail.
Wenn Sie das manuelle Kopieren satthaben, sich über brüchige Scraper ärgern oder einfach wissen wollen, was geht: Probieren Sie Thunderbit aus. Sie können die Chrome-Erweiterung herunterladen und sofort kostenlos mit der Datenextraktion starten – ohne Einrichtung, ohne Code, ohne Aufwand.
Und wer noch tiefer einsteigen möchte, findet im Thunderbit Blog weitere Anleitungen, Tipps und Praxisbeispiele.
FAQs
1. Was ist „einfaches Web-Extrahieren“ und für wen ist es gedacht?
Einfaches Web-Extrahieren steht für No-Code-Methoden des KI-gestützten Web-Scrapings, mit denen jeder – vor allem nicht-technische Business-Anwender – strukturierte Daten schnell und unkompliziert von Websites zieht. Ideal für Vertriebs-, Marketing-, E-Commerce- und Operations-Teams, die verwertbare Daten ohne technischen Aufwand brauchen.
2. Wie unterscheidet sich Thunderbit von traditionellen Web-Scraping-Tools?
Thunderbit automatisiert per KI die Feldauswahl, Pagination und Unterseiten-Extraktion. Anders als klassische Scraper, die Programmierung oder komplexe Vorlagen verlangen, beschreiben Sie Ihre Anforderungen im Klartext und extrahieren Daten mit nur zwei Klicks.
3. Kann Thunderbit dynamische oder mehrseitige Websites verarbeiten?
Ja. Thunderbit erkennt und verarbeitet Pagination automatisch – Infinite Scroll eingeschlossen – und folgt Links zu Unterseiten für eine tiefere Extraktion. Alles bei minimaler Einrichtung.
4. Welche Exportoptionen unterstützt Thunderbit?
Thunderbit exportiert direkt nach Excel, Google Sheets, Airtable, Notion, CSV oder JSON. Zusätzlich lässt es sich mit CRMs und anderen Workflow-Tools verbinden, damit Ihre Prozesse nahtlos ineinandergreifen.
5. Ist es sicher und ethisch, Tools wie Thunderbit für einfaches Web-Extrahieren zu nutzen?
Thunderbit setzt auf verantwortungsvolles, ethisches Web-Scraping. Beachten Sie stets die Nutzungsbedingungen der jeweiligen Website, verzichten Sie ohne Einwilligung auf das Scrapen personenbezogener Daten und halten Sie über Rate Limiting den Betrieb stabil – Letzteres ist auch im Sinne der DSGVO. Mehr zu Best Practices steht in Thunderbits Leitfaden zum Web-Scraping.
Sie wollen das Potenzial von Webdaten erschließen? Testen Sie Thunderbit noch heute und erleben Sie, wie einfaches Web-Extrahieren Ihren Workflow verändert.
Thunderbit für einfaches Web-Extrahieren testen
Thunderbit KI-Web-Scraper testen Get Started Free
Mehr erfahren




