Jeder redet von datengetriebenen Entscheidungen, aber wie aufwendig und nervig das Sammeln der Daten wirklich ist, wird oft ausgeblendet. Wer schon mal Daten händisch zusammengetragen hat, weiß, wie viel Zeit dabei draufgeht. Ich habe schon viele Firmen gesehen, die mit ihren datenbasierten Strategien nicht vorankommen – meistens, weil die Datenerhebung einfach zu langsam und umständlich läuft. Kommt dir das bekannt vor? Dann findest du hier frische Ansätze und Lösungen.
💡 In diesem Beitrag tauchen wir tief in die Welt des Data Scraping ein und zeigen, wie neue Technologien die Spielregeln verändern. Wir schauen uns die Schwächen klassischer Methoden an, erklären die Vorteile von KI-gestützten Data Scraping Tools und geben dir praktische Tipps für den Alltag.
Was steckt hinter Data Scraping?
Data Scraping – auch als bekannt – meint das automatisierte Herausziehen von strukturierten Infos aus Webseiten mit speziellen Tools (oft als Tabellen aufbereitet). So kannst du in kurzer Zeit riesige Datenmengen einsammeln. Beispiele gefällig? Du kannst öffentlich verfügbare Daten von für die Lead-Generierung nutzen, Produktinfos von für Preisvergleiche oder Marktanalysen ziehen oder Kundenbewertungen von für Insights auswerten.
Wie sich Data Scraping technisch verändert
Früher war Datensammeln eher was für IT-Cracks – oder bedeutete stundenlanges Copy & Paste. Aber 2025 sieht das ganz anders aus: Künstliche Intelligenz übernimmt immer mehr Aufgaben. Data Scraping ist längst nicht mehr nur was für Programmierer oder simple Automatisierungen.
Warum klassische Methoden oft nicht mehr reichen
Moderne Webseiten bringen neue Herausforderungen: dynamische Inhalte (z.B. durch React/Vue-Frameworks), immer mehr verschiedene Datentypen (Text, Video, Bilder) und chaotische Strukturen (mehrere Templates auf einer Seite). Studien zeigen drei große Probleme bei :
-
Hoher Wartungsaufwand Klassische Web-Scraper brauchen ständig manuelle Anpassungen (im Schnitt 3–5 Stunden pro Website und Monat). Ändert sich das Frontend oder das Framework, funktionieren 60% der XPath-Selektoren nicht mehr. KI-Tools mit Sprachmodellen und Codeverständnis passen sich automatisch an 90% der Strukturänderungen an und senken so die Wartungskosten um 60–80%. Gerade bei modernen Seiten mit React/Vue bleibt das Data Scraping durch semantisches Verständnis stabil – auch wenn sich Klassennamen ändern.
-
Begrenzte Datenerfassung Klassische Methoden holen meist nur klar strukturierte Daten und lassen wertvolle Infos liegen, wie zum Beispiel:
- Daten, die in Bildern stecken
- Textinhalte in Artikeln
- Unstrukturierte Daten ohne HTML-Tags
-
Probleme bei der Datenqualität Dynamische Inhalte bringen klassische Scraper schnell an ihre Grenzen – das Ergebnis: unvollständige oder fehlerhafte Daten.
- Bei paginierten Daten (z.B. Produktlisten) erfassen klassische Tools oft nur 30–50% der Inhalte auf der ersten Seite.
- Bei unendlichem Scrollen (z.B. Social Feeds) gehen über 60% der relevanten Daten verloren.
- Hohe Fehlerquote beim Zuordnen unstrukturierter Daten (z.B. Listen mit abweichender Struktur).
Hier kommen KI-basierte Tools wie Thunderbit ins Spiel. Die Vorteile zeige ich dir gleich.
KI hebt Data Scraping auf ein neues Level
Bis 2025 haben KI-Modelle, vor allem große Sprachmodelle (LLMs), einen riesigen Sprung gemacht. Sie verstehen und generieren natürliche Sprache, analysieren komplexe Daten und bieten viel effizientere Lösungen. Viele Data Scraping Tools setzen mittlerweile auf LLMs, um die Schwächen klassischer Methoden zu umgehen. Nach dem Test von 13 in den letzten Monaten empfehle ich den .
Das macht Thunderbit besonders:
-
Super einfache Bedienung: Du gibst einfach in Alltagssprache ein, was du brauchst – das System erstellt automatisch einen Scraping-Plan. So sparst du im Vergleich zu klassischen Tools bis zu 87% der Einrichtungszeit.
-
Vorteile als lokale Erweiterung: Als Browser-Add-on bietet Thunderbit:
- Sofortiges Data Scraping
- Extraktion von dynamischen und unendlich scrollenden Seiten
- Zugriff auf Seiten mit Login
-
Starke Multimodalität: Thunderbit verarbeitet verschiedene Datentypen, darunter:
- Textinhalte aus Artikeln
- Finanzdaten aus PDF-Tabellen
- Infos aus mehreren Bildern, die zu Tabellen zusammengeführt werden
- Video-Untertitel extrahieren und zusammenfassen
Mit Thunderbit meisterst du verschiedenste Datenszenarien ganz easy. So läuft’s ab:
So funktioniert Data Scraping mit KI
In vier Schritten nutzt du die starken von Thunderbit:
-
Browser-Erweiterung installieren Geh auf die Thunderbit-Website und hol dir die Erweiterung aus dem Chrome Web Store. Nach der Installation kannst du sie in deiner Browserleiste anpinnen.
-
Registrieren und Gratis-Credits sichern Melde dich direkt in der Erweiterung an und schnapp dir kostenlose Test-Credits. Damit kannst du Kernfunktionen wie KI-Web-Scraping, automatisches Ausfüllen von Formularen und smarte Zusammenfassungen ausprobieren. Teste die Features am besten erstmal kostenlos im Playground, bevor du Credits einsetzt.
-
Smart Scraping starten Starte eine Vorlage aus der Thunderbit-Seitenleiste. Beschreibe in Alltagssprache, welche Daten und Formate du brauchst, passe die Einstellungen an und klicke auf „Scrape“, um loszulegen.
Erweiterte Scraping-Funktionen (Pro-Tarif)
Mit dem (oder einer kostenlosen Testphase) schaltest du diese Features frei:

-
Multimodale Datenverarbeitung Meistern komplexe Szenarien wie (z.B. Finanzberichte, Produktanleitungen), Bilderkennung (Preisschilder, Spezifikationen) und Video-Untertitel-Extraktion. Unstrukturierte Daten werden automatisch standardisiert.
-
Tiefes Subpage-Scraping Greife auf alle Unterseiten einer Seite zu (z.B. oder Bewertungsseiten), erkenne zusammengehörige Daten intelligent und führe sie automatisch in einer Haupttabelle zusammen. Perfekt für Produktkataloge, Immobilienlisten und mehr.
-
Vorlagen-Bibliothek Nutze sofort optimierte für über 30 Plattformen wie , oder . Die Vorlagen passen sich automatisch an Seitenänderungen an. Neue Nutzer sparen im Schnitt 83% der Einrichtungszeit.
-
Massen-Scraping Starte mehrere Scraping-Aufgaben parallel und importiere URL-Listen für das Batch-Scraping.
-
Intelligente Paginierung Erkennt und extrahiert automatisch paginierte Inhalte (inklusive „Mehr laden“-Buttons und Navigation), auch bei unendlichem Scrollen. Getestet mit über 200 Seiten Produktlisten.
Thunderbit Praxis-Guide
Szenario 1: Immobiliendaten erfassen
Egal ob Makler oder Investor – wer Immobilienangebote von Zillow analysieren will, braucht einen zuverlässigen Web-Scraper. Mit Thunderbits KI-Web-Scraper holst du dir relevante Immobiliendaten von Zillow im Handumdrehen und bleibst immer up to date. Hier gibt’s ein Video-Tutorial zum Scraping von Zillow mit Thunderbit.
Szenario 2: Talente und Kunden finden
Ob Recruiting oder Vertrieb – ein starker Web-Scraper ist ein echter Gamechanger. Thunderbit macht es möglich, gezielt wichtige Daten von zu extrahieren und so die Suche nach Talenten oder potenziellen Kunden zu beschleunigen. Nach dem Einsatz wirst du merken: Zeitraubende manuelle Recherche und Copy & Paste sind Geschichte. Hier gibt’s ein Tutorial zum LinkedIn-Scraping mit Thunderbit.
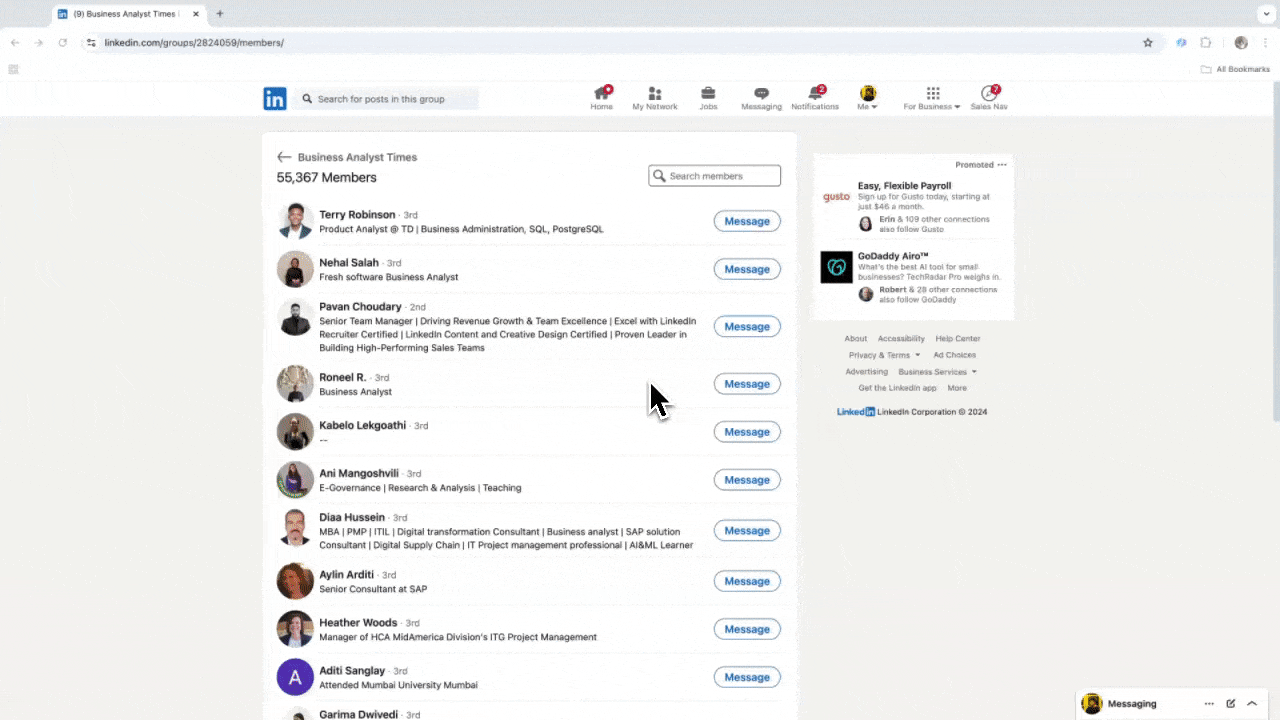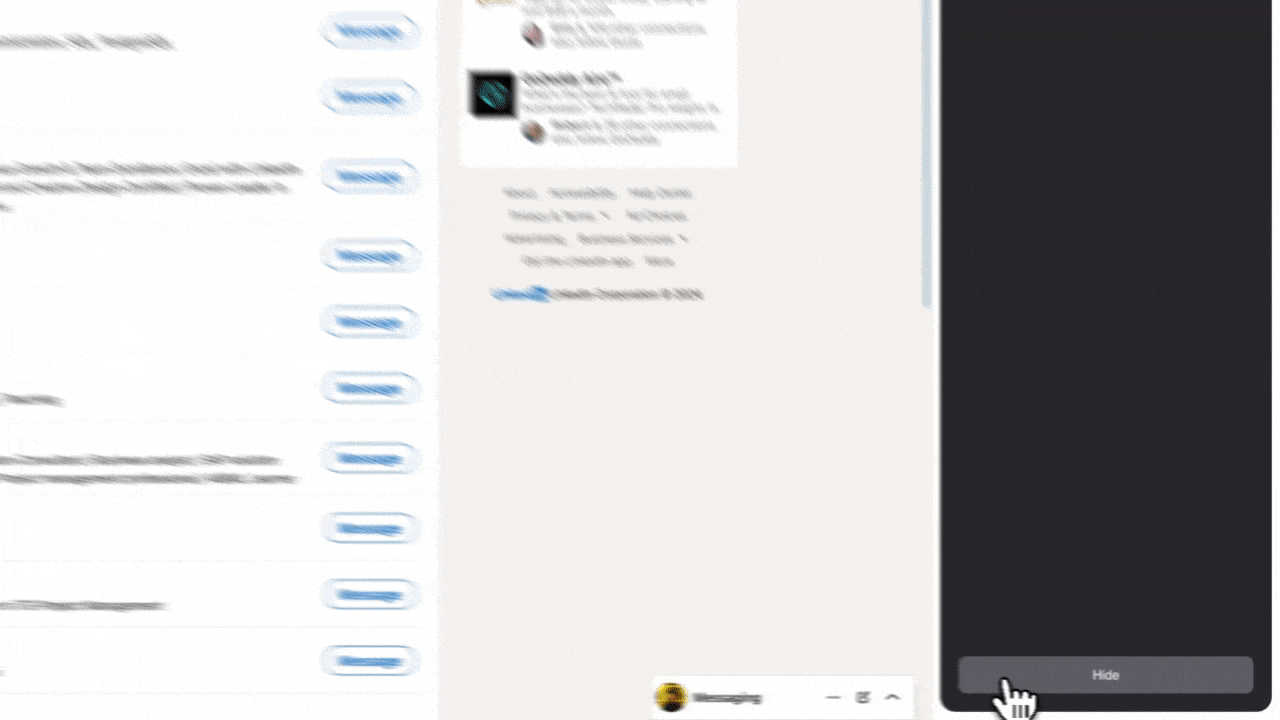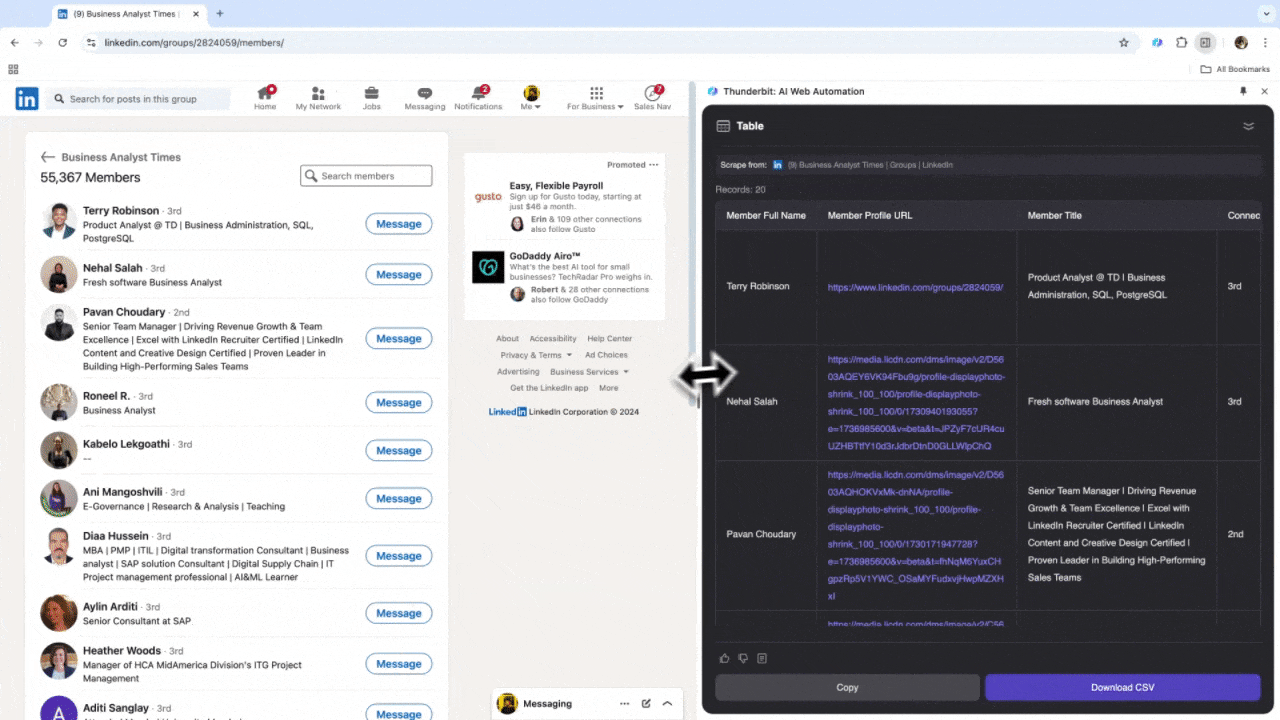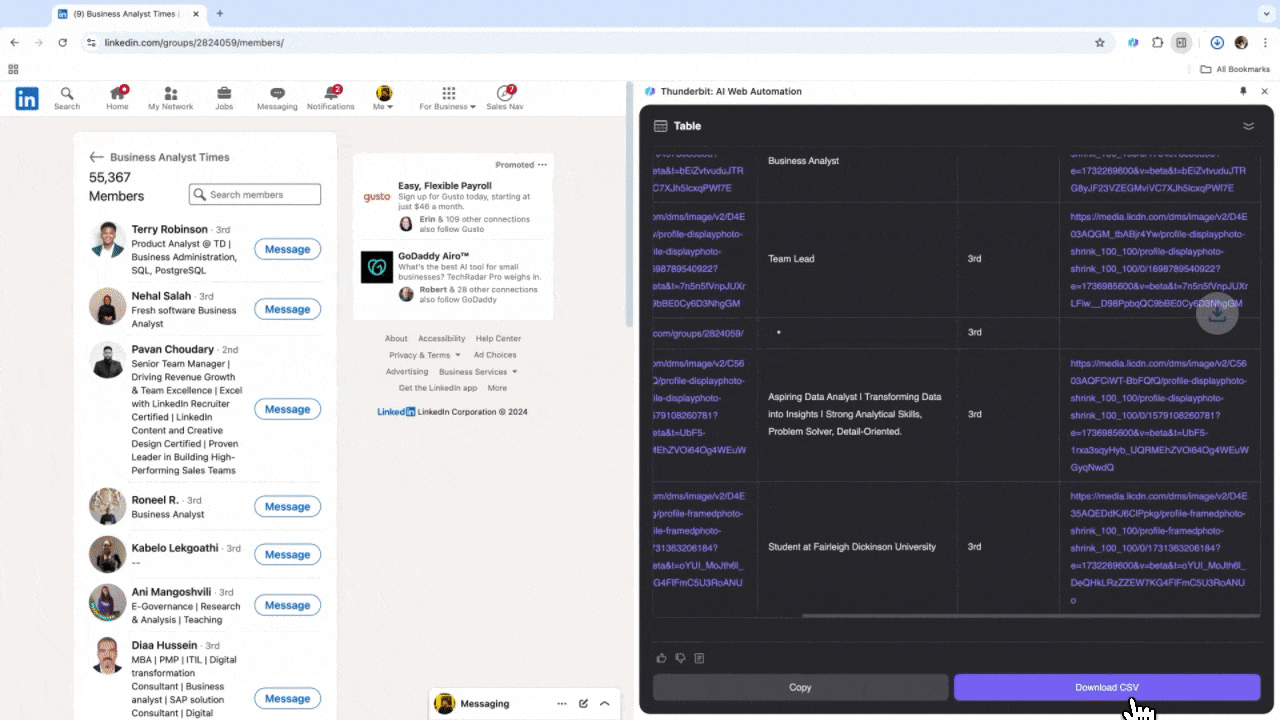
Szenario 3: Marktanalyse und Zielgruppenansprache
Wer als Unternehmer standortbasierte Daten für die Marktanalyse sammelt oder als Vertriebler lokale Leads sucht, profitiert enorm von einem Web-Scraper. Thunderbit extrahiert gezielt relevante Daten von und hilft dir, fundierte Entscheidungen zu treffen und deine Akquise zu optimieren.
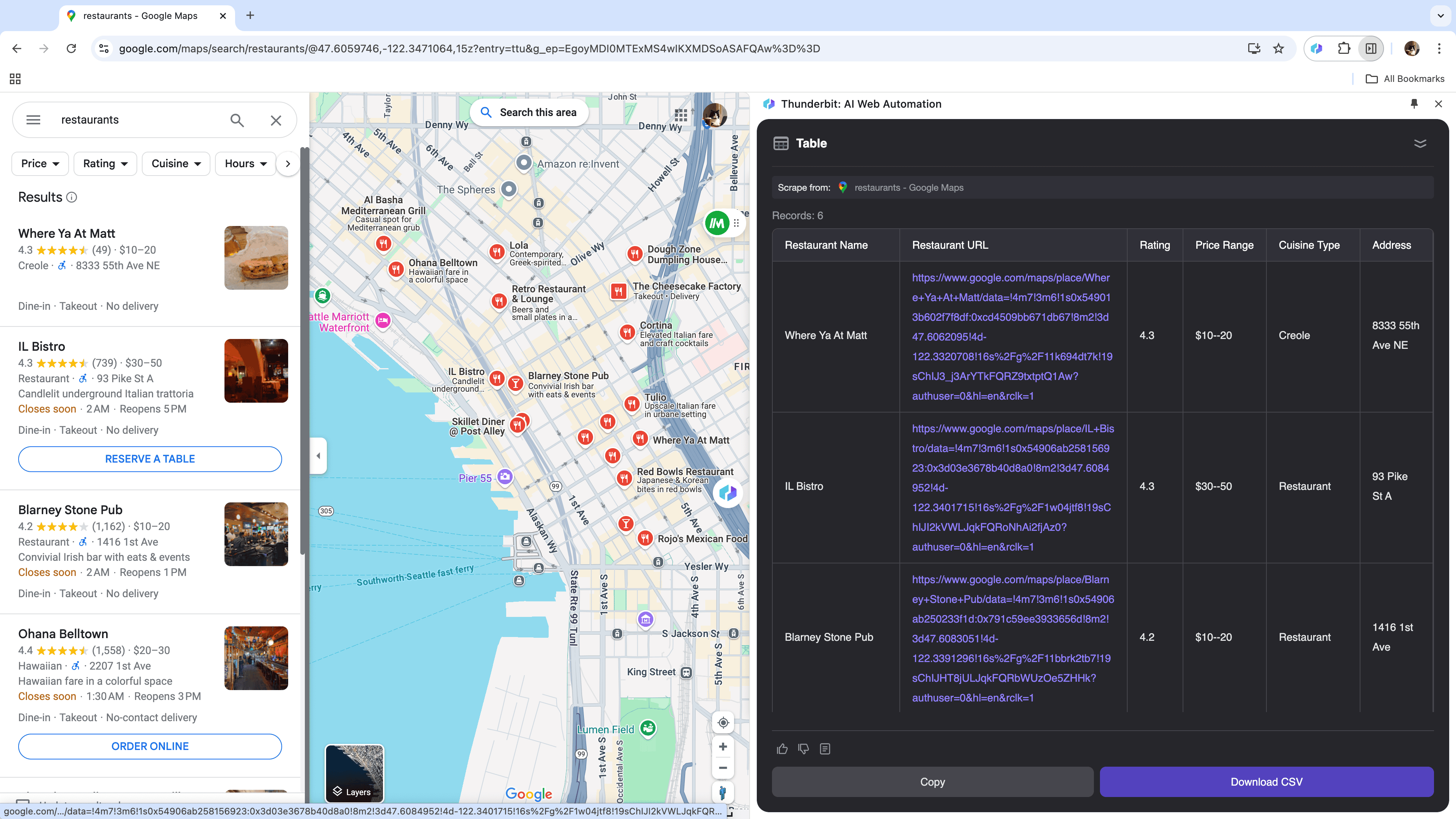
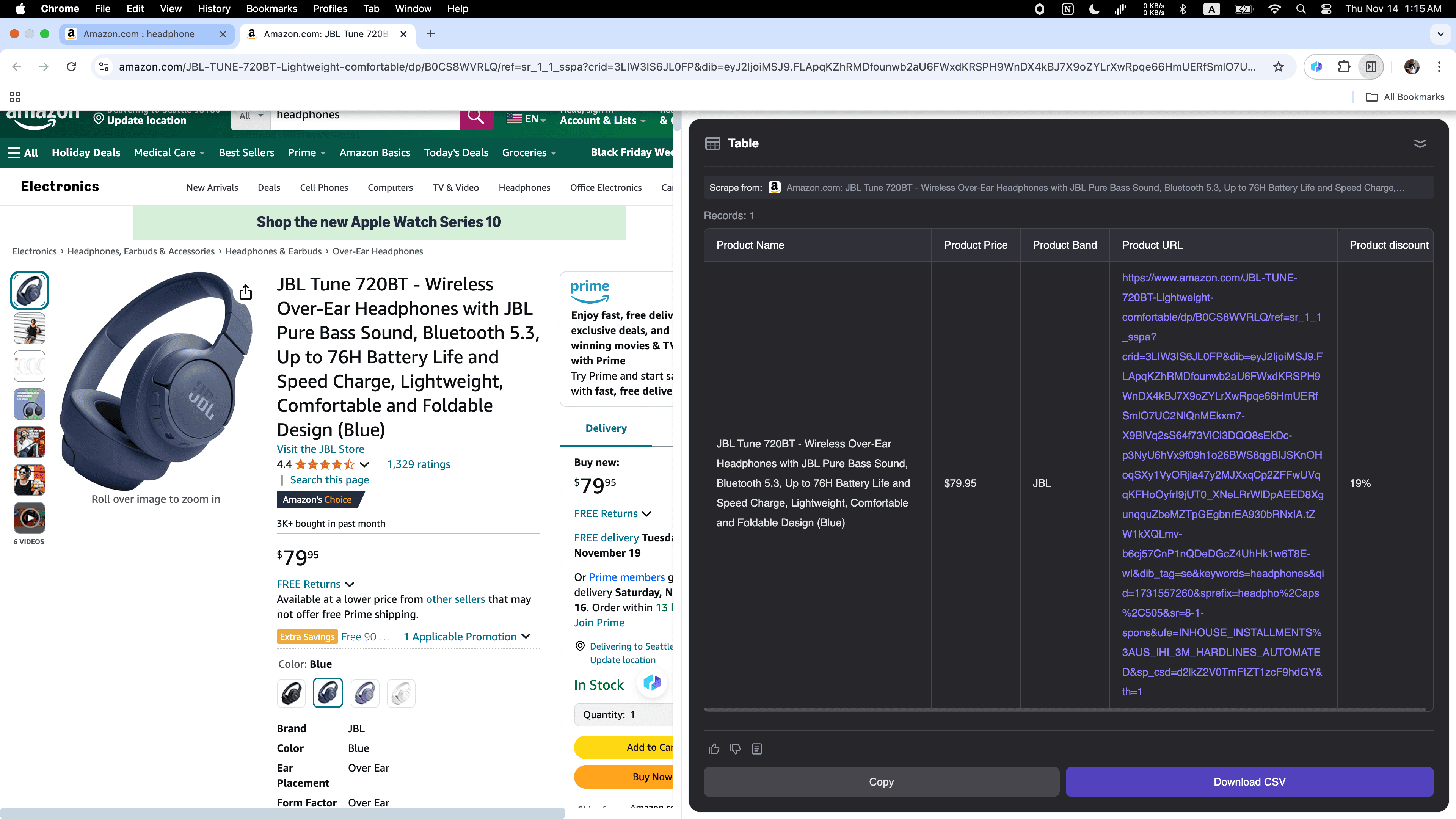
Szenario 4: E-Commerce-Datenanalyse
Ob Online-Händler oder Gründer – mit Thunderbit hast du das perfekte Tool, um Wettbewerber zu analysieren oder Markttrends zu verfolgen! Du kannst verschiedenste Produktdaten von erfassen, inklusive detaillierter Beschreibungen, Preise und .
Der Thunderbit KI-Web-Scraper macht die Datensammlung für Unternehmen so einfach, schnell und effizient wie nie zuvor. Egal ob Immobilien, Talente, potenzielle Kunden oder E-Commerce-Trends – KI-Web-Scraper sparen dir unzählige Stunden und Nerven. Nutze die Power der KI für dein Data Scraping und erlebe, wie deine Produktivität durch die Decke geht. Bereit? Starte jetzt mit Thunderbit und bring dein Data Scraping aufs nächste Level.
Exklusive Tipps zur Datenbereinigung
Mit klassischen Scraping-Tools fängt die eigentliche Arbeit oft erst nach dem Extrahieren an – beim Aufräumen der Daten. Thunderbits KI übernimmt die Datenbereinigung schon während des Scrapings mithilfe von LLMs und spart dir so bis zu 83% Aufwand – dank dieser Funktionen:
Tipp 1: Intelligente Feldzuordnung
Bei unterschiedlichen Datenquellen (z.B. gleichzeitiges Scraping von LinkedIn und Zillow) erkennt Thunderbits KI automatisch semantische Zusammenhänge:
- Automatische Zuordnung von Feldern über verschiedene Quellen hinweg (z.B. „price“ ↔ „售价“ ↔ „Price“)
- Intelligentes Zusammenführen ähnlicher Felder (z.B. „area“ und „square feet“)
- Plattformübergreifende Standardisierung (z.B. „aktuelle Position“ bei LinkedIn und „Immobilienstatus“ bei Zillow als gemeinsame Tags)
Tipp 2: Kontextbasierte Vervollständigung
Dank Kontextverständnis der LLMs erreicht Thunderbit eine branchenführende Daten-Vervollständigungsrate von 99%:
- Adressvervollständigung: Automatische Ergänzung von Stadt/Bundesland anhand der Postleitzahl (z.B. 10001 → New York City, NY)
- Karrierepfad-Prognose: Schlägt mögliche Berufserfahrungen basierend auf LinkedIn-Ausbildung vor
Tipp 3: Datenoptimierung
- Mehrsprachige Übersetzung (Echtzeit-Übersetzung in 12 Sprachen, darunter Deutsch, Englisch, Chinesisch, Japanisch)
- Intelligente Zusammenfassung (fasst z.B. eine 500-Wörter-Produktbeschreibung auf drei Kernpunkte zusammen)
- Einheitenumrechnung (automatische Umrechnung von Quadratfuß ↔ Quadratmeter, Fahrenheit ↔ Celsius)
- Formatvereinheitlichung (z.B. Datumsformat auf JJJJ-MM-TT, Währungen auf USD)
Tipp 4: Qualitätsprüfung
- Intelligente Fehlerkorrektur: Automatische Korrektur von Formatfehlern (z.B. Telefonnummer +01 138-1234-5678 → +113812345678)
- Logische Validierung: Prüft, ob „Baujahr“ vor „letzter Renovierung“ liegt
Tipp 5: KI-Tagging
Automatische Generierung von Tags durch natürliche Sprachverarbeitung:
- Sentiment-Analyse (Kundenbewertungen werden automatisch als positiv/negativ/neutral markiert)
- Business-Value-Tags (z.B. „High-Potential-Kunde“ oder „Objekt mit Nachfassbedarf“)
- Branchen-Tags (z.B. LinkedIn-Profile automatisch mit „Tech|Finance|Healthcare“ versehen)
Herausforderungen beim Data Scraping
So wertvoll Data Scraping auch ist, es gibt auch Stolpersteine: Rechtliche Vorgaben wie DSGVO oder CCPA stellen hohe Anforderungen an den Datenschutz und müssen unbedingt beachtet werden. Viele Websites setzen außerdem Schutzmechanismen wie Cloudflare ein, die Scraping-Aktivitäten durch IP-Blockaden erkennen und verhindern können.
Die Zukunft des Data Scraping im KI-Zeitalter
Mit KI wird Web Scraping zur intuitiven Lösung für Unternehmen. Stell dir vor, du gibst einfach eine Domain (z.B. zillow.com) und deinen Wunsch (z.B. „alle Immobilienangebote in New York City extrahieren“) ein – und die KI erkennt automatisch alle relevanten Datenpunkte, von Objektdetails bis zu Preistrends, ganz ohne manuelle Konfiguration. Die Systeme integrieren die extrahierten Daten direkt in deine Geschäftsprozesse, z.B. werden LinkedIn-Kontakte automatisch ins CRM übernommen oder E-Commerce-Kennzahlen in Dashboards eingespielt. Fortschrittliche Mustererkennung ermöglicht sogar vorausschauendes Scraping, etwa zur Überwachung von Lagerbeständen oder neuen Markttrends. Und: KI sorgt für dynamische Compliance, passt Scraping-Parameter in Echtzeit an neue Vorschriften an und dokumentiert alles transparent.
Dieser KI-getriebene Wandel macht Business Intelligence für alle zugänglich und verändert grundlegend, wie Unternehmen mit Webdaten arbeiten. Wer früh auf KI-gestütztes Scraping wie Thunderbit setzt, verschafft sich einen klaren Vorsprung bei datenbasierten Entscheidungen.
FAQs
-
Was ist Thunderbit? ist eine clevere Browser-Erweiterung auf Basis großer Sprachmodelle (LLM), entwickelt für moderne Datenerfassung. Sie bietet nicht nur , sondern auch multimodale Datenverarbeitung – von dynamischen Webseiten über PDFs bis hin zu Bildern und Videos. Als lokale Browser-Lösung kann Thunderbit auch Login-geschützte Seiten (wie LinkedIn) direkt verarbeiten und passt sich automatisch an moderne Frontend-Änderungen an.
-
Wie funktioniert der KI-Web-Scraper von Thunderbit? Thunderbits KI-Web-Scraper nutzt künstliche Intelligenz, um strukturierte Daten von Websites zu extrahieren. Nutzer können auf „AI Suggest Columns“ klicken, damit die KI die passenden Spalten vorschlägt, und dann mit „Scrape“ die Daten erfassen. So lassen sich Daten von jeder Website, PDF oder Bild mit nur zwei Klicks extrahieren.
-
Was ist der Unterschied zwischen Listenscraping und Subpage-Scraping? Listenscraping ist für paginierte Szenarien (z.B. Produktlisten) optimiert, erkennt automatisch die Paginierungslogik und extrahiert tausende Einträge. Subpage-Scraping nutzt eine Baumstruktur (z.B. Immobilienliste → Detailseite → Grundriss) und erstellt automatisch Haupt- und Untertabellen durch semantische Verknüpfung.
-
Können auch Nicht-Programmierer Thunderbit nutzen? Thunderbit setzt auf eine natürliche Sprachsteuerung: Nutzer beschreiben einfach, welche Daten sie brauchen („Name, E-Mail, Telefon“), und das System erstellt automatisch einen Scraping-Plan. Unsere Tests zeigen: 85% der Nutzer schaffen ihre erste Datenerfassung in unter 10 Minuten – ganz ohne Programmierkenntnisse.
-
Welche Datentypen kann Thunderbit verarbeiten? Thunderbit erkennt viele Datentypen intelligent:
- Strukturierte Daten: Tabellen, Listen (z.B. Amazon-Produktspezifikationen)
- Unstrukturierte Daten: Bewertungstexte, PDF-Dokumente (automatische Erkennung)
- Multimodale Daten: Preisschilder in Bildern, Video-Untertitel
- Dynamische Daten: Unendlich scrollende Inhalte, Lazy-Loading-Bilder
- Verknüpfte Daten: Beziehungen über mehrere Seiten hinweg (z.B. LinkedIn-Kontakte → Unternehmensinfos)
-
Wie starte ich mit Thunderbit? Erfahre mehr über unsere oder entdecke unsere , um direkt loszulegen.
Mehr erfahren: