
Haben Sie schon einmal von Ihrem Vorgesetzten einen Stapel PDF-Dateien bekommen und sollten daraus Daten herausziehen, die am Ende perfekt formatiert und korrekt sein müssen? Das manuell zu erledigen, ist ein sicherer Weg, um bis spät in die Nacht zu sitzen. Daten aus PDFs zu extrahieren kann ziemlich mühsam sein, denn anders als Webdaten sind PDFs oft uneinheitlich aufgebaut. Manche PDFs enthalten Tabellen, andere sind nur Bilder oder gescannte Dokumente, was die direkte Extraktion deutlich kniffliger macht.
Wenn Sie zum Beispiel E-Mail-Adressen aus einem PDF extrahieren möchten, können manche im Bildformat vorliegen, während andere in komplexen Zeichenkodierungen versteckt sind. Nehmen Sie dieses Beispiel: {john.doe,jane.doe}@example.com. Das steht tatsächlich für zwei separate E-Mails: john.doe@example.com und jane.doe@example.com. Und dann gibt es noch {first.last}@example.com, wobei Sie "first" und "last" jeweils durch Vor- und Nachnamen des Autors ersetzen. Herkömmliche Texterkennungstools reichen hier einfach nicht aus. Genau hier kommt ein praktisches Tool ins Spiel: der PDF-Scraper, der den Tag rettet.
Was ist ein PDF-Scraper
Ein PDF-Scraper ist ein praktisches Tool, das Daten automatisch aus PDF-Dateien extrahiert und Inhalte wie Tabellen und Text in die Formate umwandelt, die Sie benötigen, etwa Excel, CSV oder JSON. Kurz gesagt: Aus mühsamem Copy-and-paste wird eine Lösung mit nur einem Klick.
Stellen Sie sich vor, Sie haben einen Stapel Rechnungen, Verträge, wissenschaftliche Arbeiten oder sogar gescannte PDFs, die Sie sonst von Hand abtippen müssten — das würde Stunden dauern. Mit einem PDF-Scraper laden Sie die Datei einfach hoch, und innerhalb weniger Sekunden werden die Daten extrahiert. Das spart Zeit und Aufwand und sorgt gleichzeitig für Genauigkeit. Schluss mit lästiger manueller Dateneingabe.
Wenn Ihr PDF verschiedene Datentypen wie Tabellen, Links und Bilder enthält, lassen Sie einen KI-PDF-Scraper die Arbeit erledigen. KI-PDF-Scraper nutzen große Sprachmodelle (LLM), die Text, Bilder und Tabellen gleichzeitig verarbeiten können und beeindruckende Ergebnisse liefern.
Die Vorteile eines KI-PDF-Scrapers gehen über Effizienz und Genauigkeit hinaus; seine Anpassungsfähigkeit macht ihn zu einer stressfreien Wahl. Ob gescannte Dokumente, Bilder oder mehrsprachige PDFs – KI kommt damit mühelos zurecht. Es gibt viele starke KI-Tools wie , und , jedes mit eigenen Funktionen für unterschiedliche Anforderungen. Egal, ob Sie Daten schnell extrahieren oder komplexe Dokumente analysieren möchten: Das richtige Tool kann Ihre Arbeit leichter und effizienter machen.
Probieren Sie es aus: Daten aus PDFs mit KI extrahieren
Probieren Sie es aus! Sie können klicken, erkunden und den Workflow direkt selbst ausführen.
So wählen Sie den richtigen PDF-Scraper aus
Einen PDF-Scraper auszuwählen ist wie ein Auto zu kaufen: Der beste ist der, der zu Ihren Bedürfnissen passt. Hier sind einige Punkte, die Sie berücksichtigen sollten:
| Funktion | Beschreibung |
|---|---|
| Genauigkeit und Stabilität | Prüfen Sie, ob das Tool Daten präzise extrahiert, besonders bei kritischen Informationen. |
| Ausgabeformate | Stellen Sie sicher, dass das Tool die von Ihnen benötigten Ausgabeformate unterstützt, etwa Excel, CSV oder JSON. |
| Integration mit anderen Tools | Wenn Sie es mit den Systemen Ihres Unternehmens verbinden müssen, achten Sie auf eine nahtlose Integrationsunterstützung. |
| Benutzerfreundliche Oberfläche | Ein benutzerfreundliches Tool ist für allgemeine Nutzer besser geeignet, während komplexere Tools eher für Tech-Teams passen. |
Verschiedene Tools haben unterschiedliche Stärken, und die richtige Wahl kann Ihre Produktivität deutlich steigern. Hier sind drei beliebte PDF-Scraper mit jeweils eigenen Funktionen für unterschiedliche Anforderungen:
| Tool | Vorteile | Nachteile |
|---|---|---|
| Thunderbit | Schnelle Extraktion; einfach als Browser-Erweiterung zu nutzen; ideal für Teamarbeit | Begrenzter Umfang bei der Datenverarbeitung |
| ChatPDF | Einfach zu verwenden, Extraktion im Chat-Stil | Weniger genau bei komplexen Dateien |
| ChatGPT | Flexibel bei komplexen Bedeutungen, breit einsetzbar | Erfordert jedes Mal manuelle Eingabe eines Prompts |
Erste Schritte mit dem KI-PDF-Scraper
Thunderbit
Möchten Sie schnell Daten aus PDFs extrahieren, ohne viel Zeit und Aufwand zu investieren? Thunderbit ist dafür genau das richtige Tool. Es ist einfach zu bedienen, und mit nur einem Klick erledigen Sie alles. Folgen Sie diesen Schritten, um komplexe PDF-Daten ganz leicht in das gewünschte Format zu überführen und Ihre Effizienz deutlich zu steigern:
-
Thunderbit zu Chrome hinzufügen und registrieren:
Besuchen Sie die und fügen Sie die -Erweiterung zu Ihrem Chrome-Browser hinzu. Registrieren Sie sich mit Ihrem Google-Konto oder einer anderen E-Mail-Adresse.

-
Das PDF in Chrome öffnen:
Öffnen Sie die PDF-Datei, aus der Sie Daten extrahieren möchten, in Chrome und klicken Sie oben rechts auf das Thunderbit-Symbol.
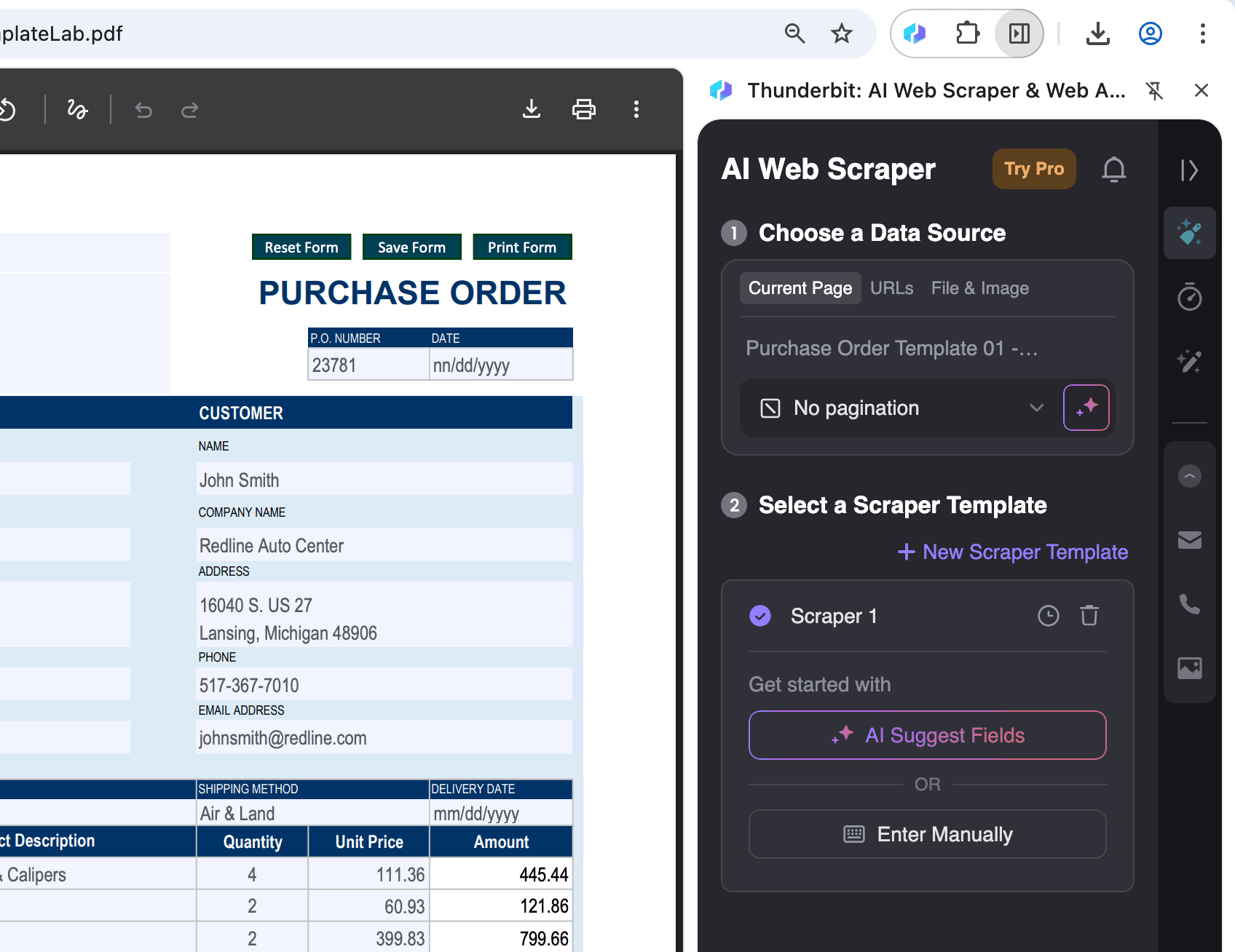
-
Ausgabeformat wählen und exportieren:
Nachdem Sie „KI-Spalten vorschlagen“ ausgewählt haben, können Sie die Daten bei Bedarf filtern oder anpassen. Wählen Sie dann das gewünschte Exportformat (CSV, Google Sheets, Airtable oder Notion) und klicken Sie auf Scrape, um die Daten zu exportieren.
 Die exportierten Daten können direkt mit , oder verbunden werden, damit die Zusammenarbeit im Team ganz einfach ist.
Die exportierten Daten können direkt mit , oder verbunden werden, damit die Zusammenarbeit im Team ganz einfach ist.
Thunderbit ist ein unkompliziertes Tool zur Extraktion von PDF-Daten, mit dem Sie die benötigten Informationen schnell aus PDF-Dateien holen und in ein nutzbares Format umwandeln können. Ob für den persönlichen Gebrauch oder die Zusammenarbeit im Team – Thunderbit kann Ihre Produktivität deutlich steigern und die Datenextraktion einfacher und bequemer machen.
ChatPDF
Wenn Sie PDFs stapelweise verarbeiten und nur bestimmte Schlüsselinformationen statt aller Daten extrahieren möchten, ist eine große Hilfe. Es ermöglicht die Extraktion von Daten in einer dialogartigen Form und eignet sich daher besonders für Einsteiger.
So extrahieren Sie PDF-Daten mit ChatPDF:
- Die ChatPDF-Website aufrufen: Öffnen Sie die -Website oder die entsprechende Plattformseite.
- PDF-Dateien hochladen: Klicken Sie auf die Schaltfläche „Datei hochladen“, um das PDF-Dokument per Drag & Drop hochzuladen oder auszuwählen, das Sie analysieren möchten. Unterstützt werden verschiedene Dateitypen, etwa Verträge, Fachartikel oder Finanzberichte.
- Das PDF analysieren: Nach dem Hochladen parst ChatPDF den Dateiinhalt automatisch und erzeugt eine strukturierte Zusammenfassung des Dokuments. Anschließend können Sie die extrahierten Schlüsselinformationen einsehen.
- Interaktive Abfrage: Verwenden Sie das Eingabefeld, um Fragen zu stellen wie „Was ist das Fazit dieses Berichts?“ oder „Wie hoch ist der im Rechnungsdokument erfasste Gesamtbetrag?“. ChatPDF extrahiert die relevanten Inhalte basierend auf Ihrer Anfrage.
- Ergebnisse exportieren: Falls nötig, können Sie die extrahierten Informationen als CSV-, Excel- oder JSON-Datei exportieren, um sie leichter zu organisieren und weiterzuverwenden.
ChatPDF bietet ein interaktives Erlebnis und eignet sich besonders gut, um schnell Informationen in Dokumenten zu finden, etwa wichtige Details oder eine Zusammenfassung des Inhalts.
ChatGPT
ist besonders stark im Umgang mit komplexen semantischen Daten, etwa beim Auslesen von Klauseln in juristischen Dokumenten. Das Tool ist sehr flexibel und erlaubt es Ihnen, Prompts anzupassen, um bestimmte Daten zu extrahieren oder Inhalte zu analysieren. Allerdings müssen Sie für ähnliche Aufgaben immer wieder denselben Prompt verwenden, und ein gutes Verständnis für Prompt-Design ist nötig.
Hier ist ein vorgefertigter Prompt, den Sie für Ihre Bedürfnisse anpassen können (denken Sie daran, die Spalten durch die Informationen zu ersetzen, die Sie extrahieren möchten):
1Sie sind jetzt ein PDF-Scraper. Ihre Aufgabe ist es, bei einem gegebenen PDF den Inhalt anhand der vom Nutzer vorgegebenen Spalten zu extrahieren. Ihre Ausgabe sollte eine CSV-Datei sein.
2Hier sind die Spalten:
31. Name
42. E-Mail
53. Telefonnummer
64. ...- Registrieren oder anmelden: Öffnen Sie die -Website und erstellen Sie ein Konto. Wenn Sie bereits ein Konto haben, melden Sie sich einfach an.
- PDF hochladen und Anfrage eingeben: Geben Sie Ihre Anfrage direkt in das Eingabefeld ein – je spezifischer, desto besser. Zum Beispiel: „Dieses PDF-Dokument enthält drei Diagramme, exportieren Sie sie als Tabellen.“
- Ergebnisse prüfen und anpassen: Prüfen Sie, ob die Antwort Ihren Erwartungen entspricht. Falls nötig, verfeinern Sie die Ergebnisse, indem Sie Rückfragen stellen oder den Prompt anpassen.
- Daten als Excel oder CSV exportieren: Wenn die von ChatGPT extrahierten Daten passen, geben Sie ins Eingabefeld ein: „Exportieren Sie diese Daten als Excel oder CSV.“
- Ergebnisse speichern: Klicken Sie auf den von ChatGPT bereitgestellten Dateilink, um die Datei herunterzuladen.
Praxisbeispiele für den Einsatz von KI-PDF-Scrapern
Ein KI-PDF-Scraper ist im Arbeitsalltag wie ein vielseitiger Assistent – ganz gleich, ob Sie mit Rechnungen, Verträgen, Finanzberichten oder Bestellungen arbeiten. Hier sind einige praktische Anwendungsfälle, in denen er besonders glänzt:
Verarbeitung von Rechnungen und Belegen
Verarbeiten Sie Firmenrechnungen und Belege stapelweise und extrahieren Sie wichtige Informationen wie Beträge und Daten für Klassifizierung und Archivierung.
- starten, auf KI-Web-Scraper klicken und dann auf Mehrere Seiten
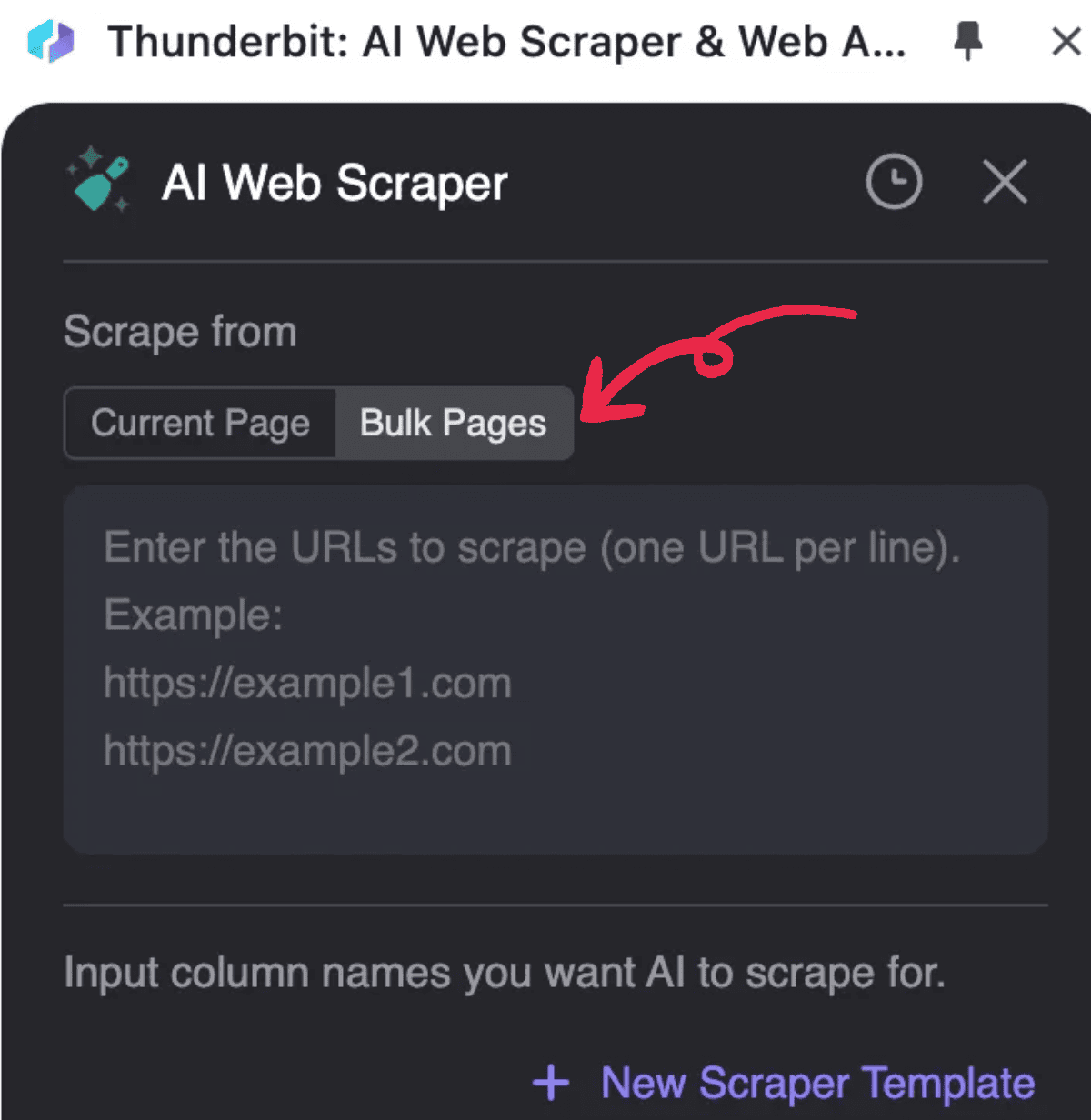 2. Die PDF-URLs eingeben, die Sie verarbeiten möchten, eine URL pro Zeile
2. Die PDF-URLs eingeben, die Sie verarbeiten möchten, eine URL pro Zeile
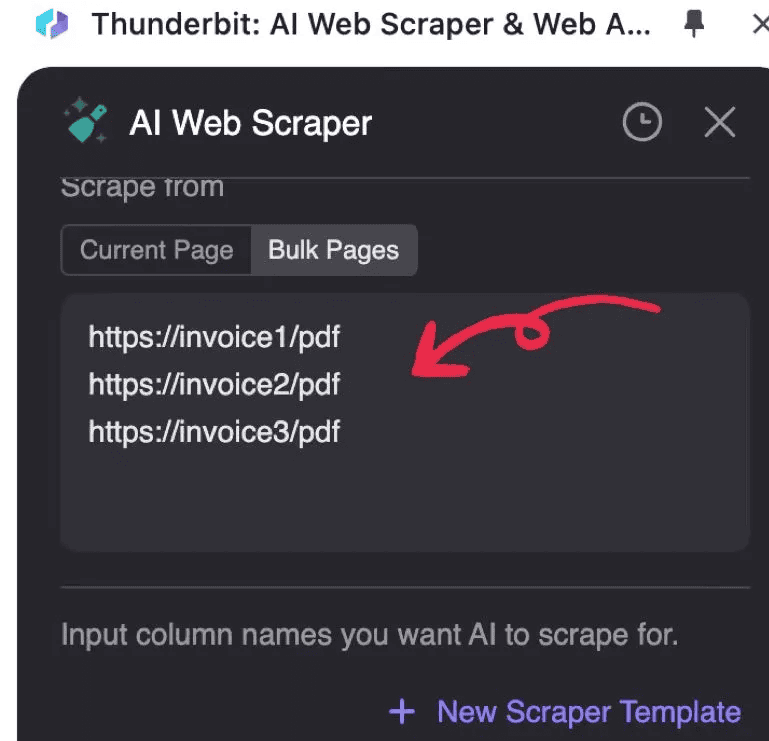 3. Auf „KI-Spalten vorschlagen“ klicken (die KI liest das PDF und schlägt eine Datenstruktur vor)
4. Auf Scrape klicken und die Daten exportieren
3. Auf „KI-Spalten vorschlagen“ klicken (die KI liest das PDF und schlägt eine Datenstruktur vor)
4. Auf Scrape klicken und die Daten exportieren
Verarbeitung von Bestellungen
Identifizieren Sie automatisch Positionen, Mengen und Stückpreise in Bestellungen, erzeugen Sie standardisierte Datensätze und extrahieren Sie Daten aus PDFs, um manuelle Arbeit zu sparen.
- Die Bestellung in Chrome öffnen und starten
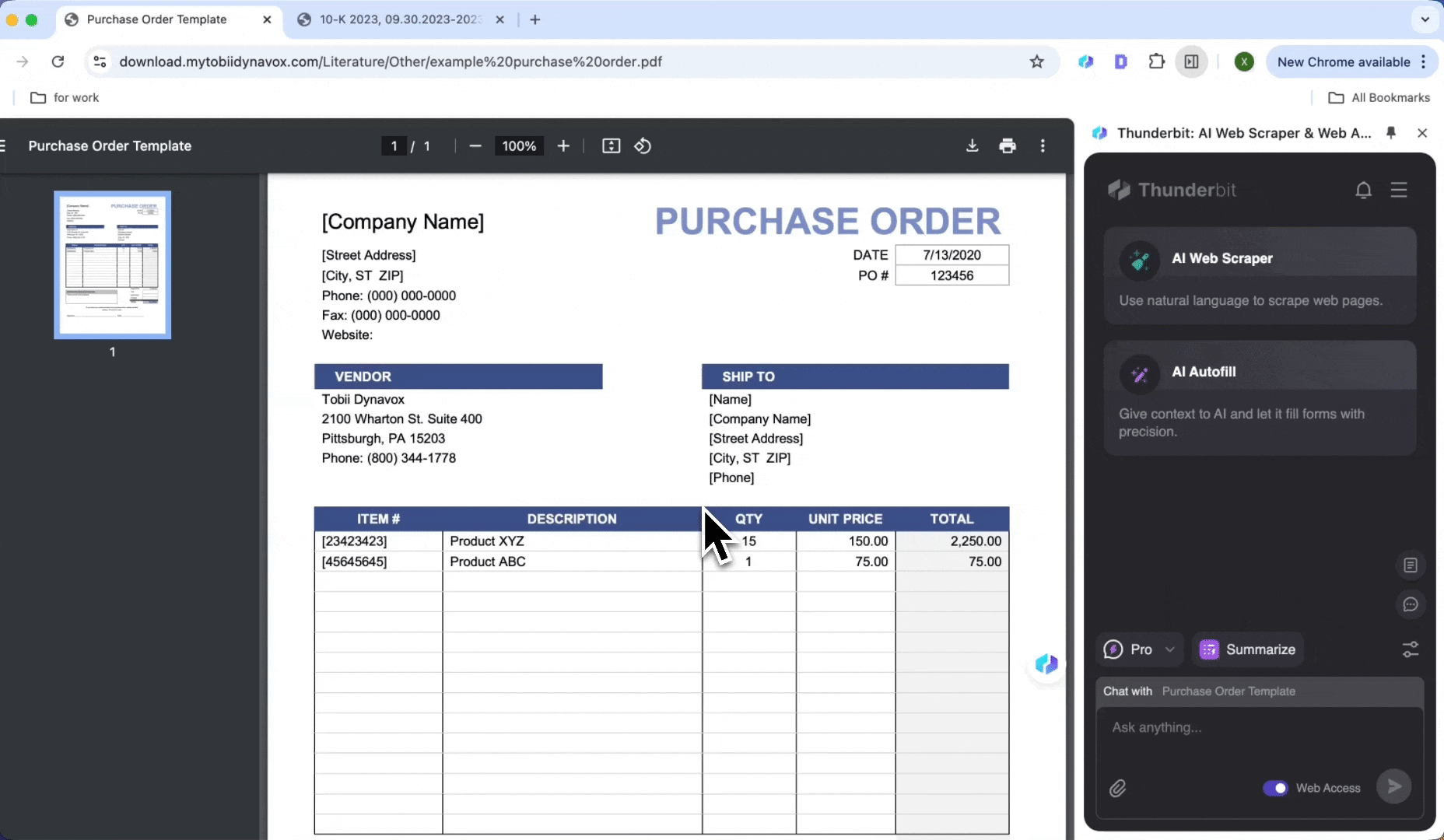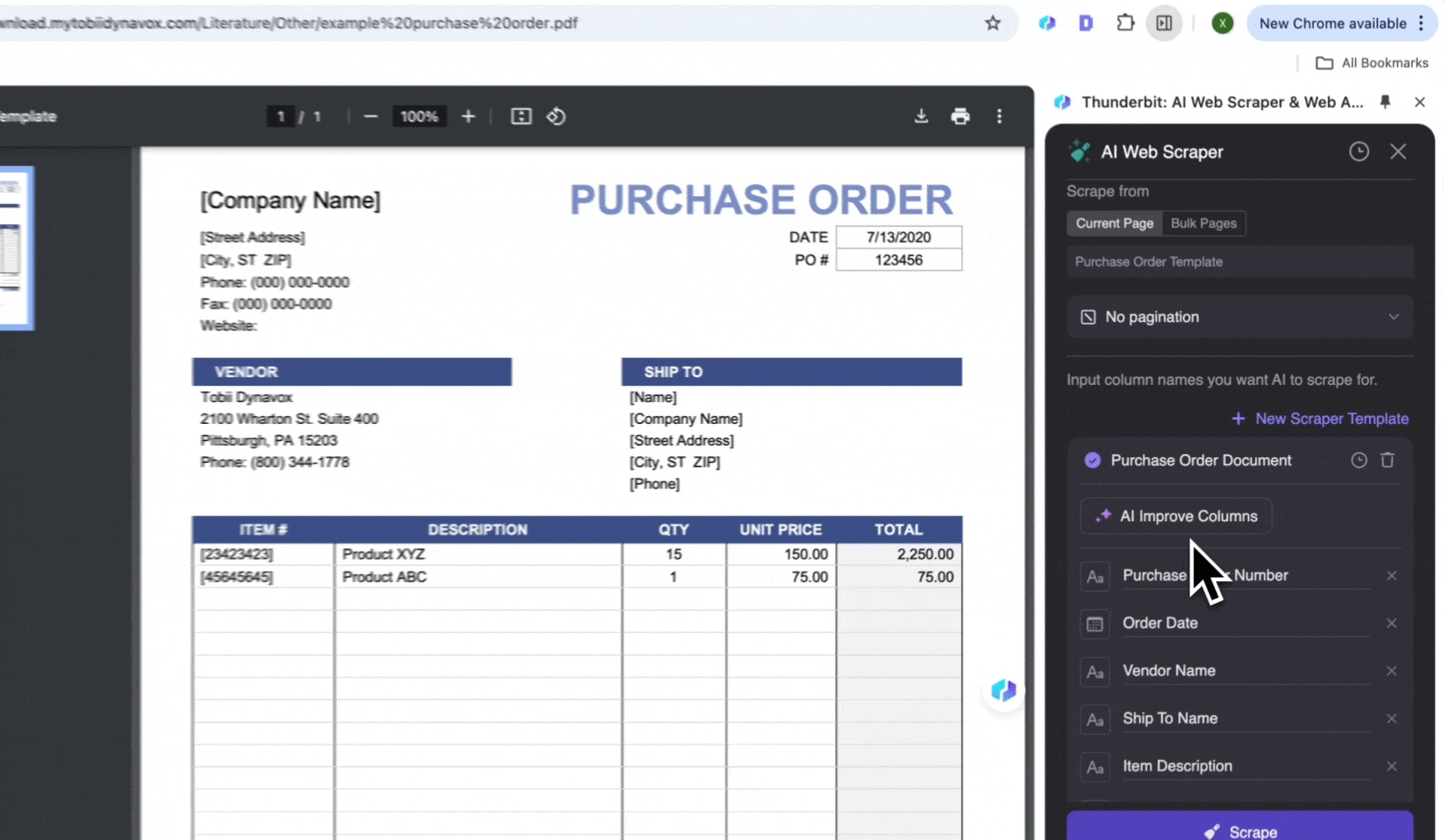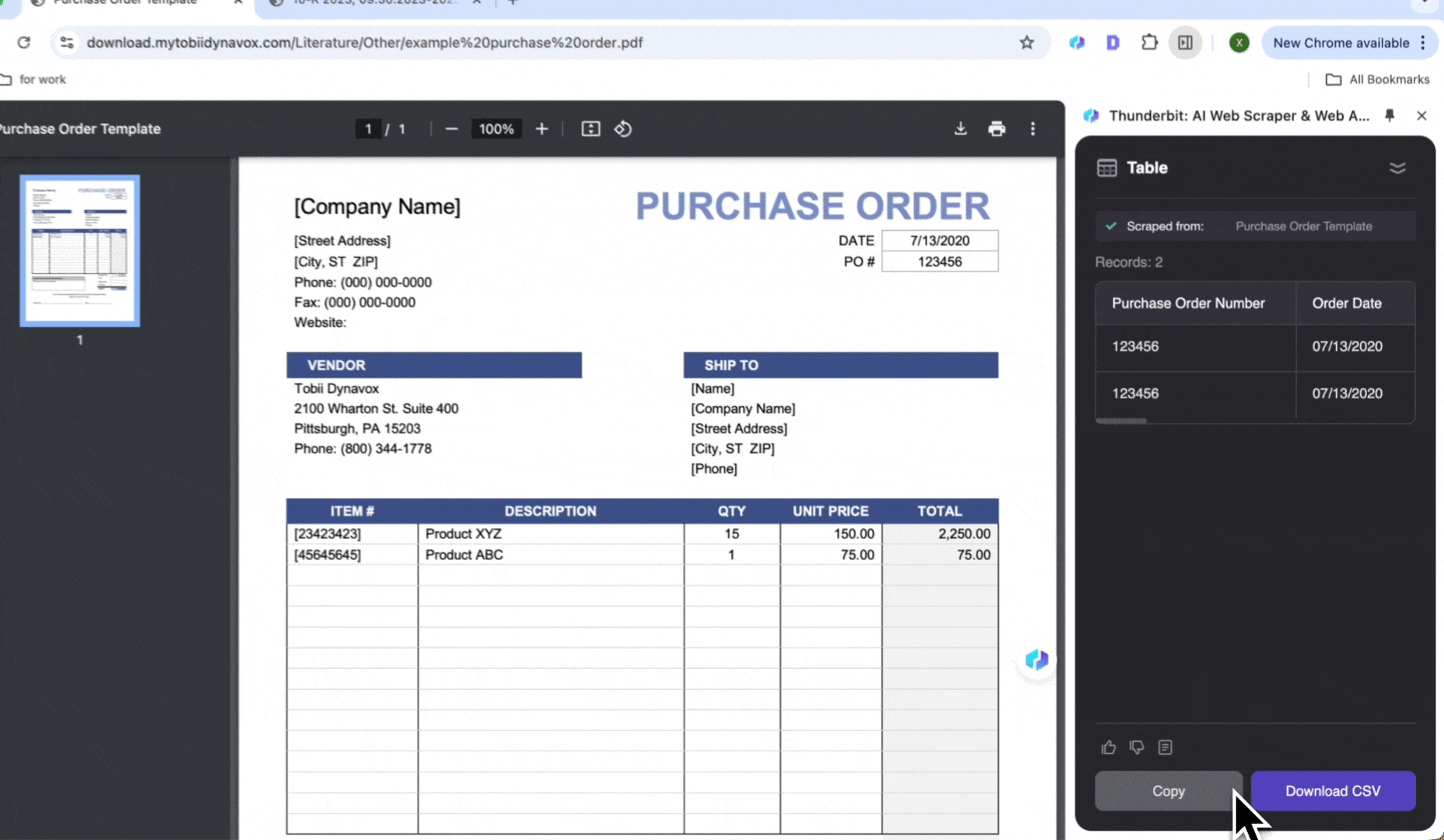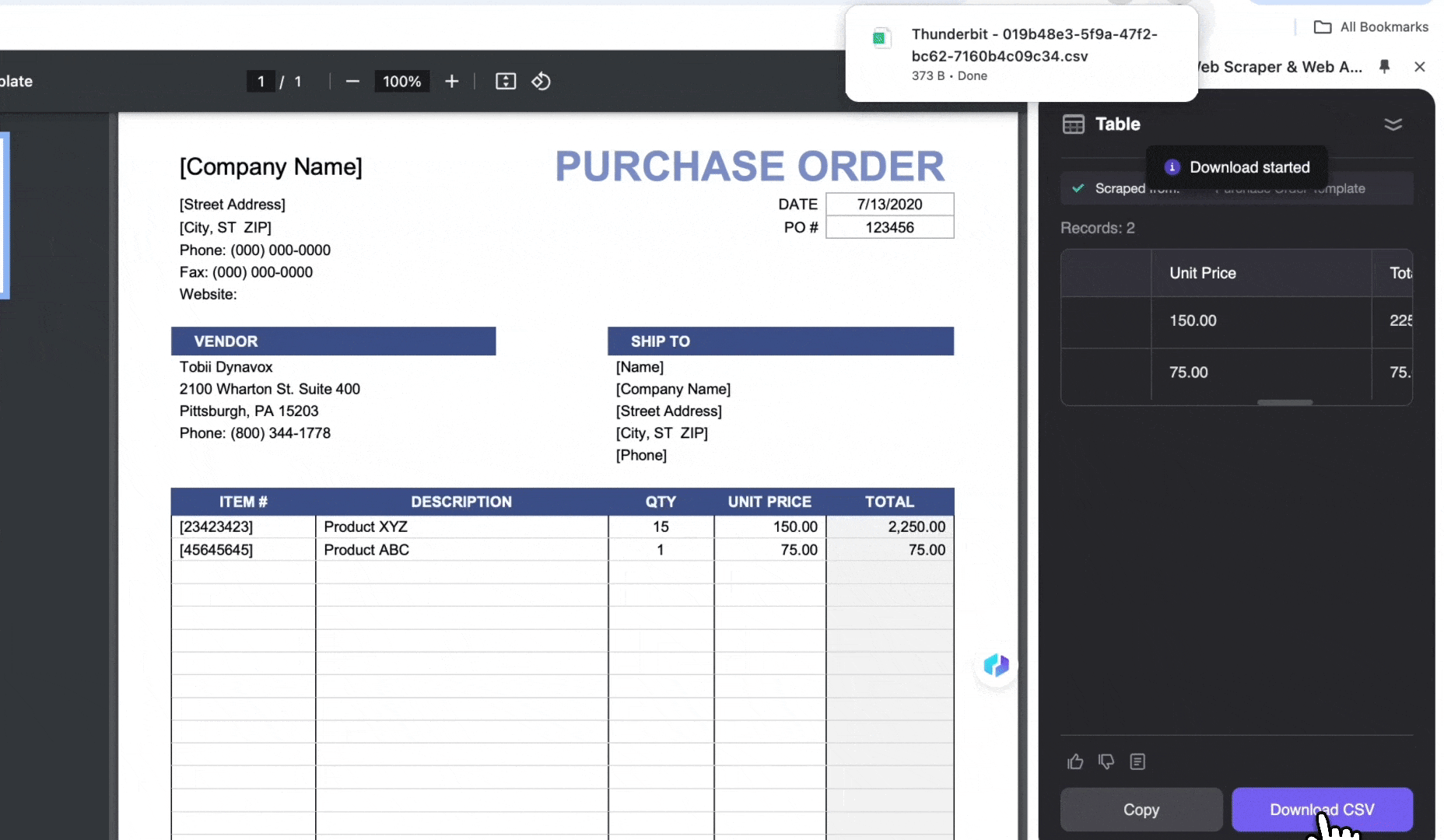
- Auf KI-Web-Scraper und dann auf KI-Spalten vorschlagen klicken
- Die erzeugte Liste prüfen und auf Scrape klicken
- Auf CSV herunterladen klicken
Extraktion von Finanzdaten
Extrahieren Sie mit nur einem Klick Daten aus Finanzberichten, etwa Gewinnmargen und Umsatzzahlen, und ersparen Sie sich die mühsame manuelle Durchsicht.
- Den Finanzbericht in Chrome öffnen und starten
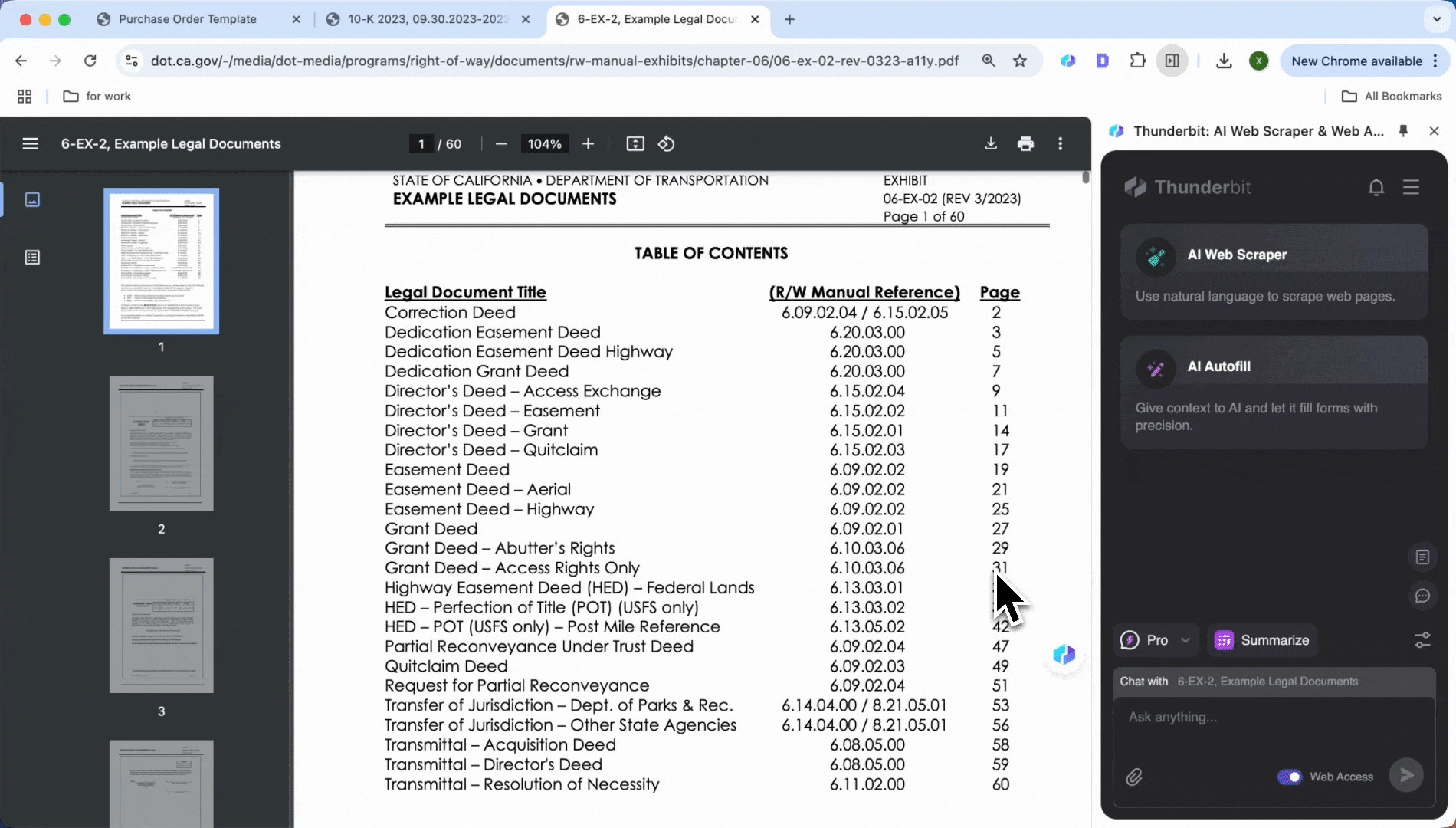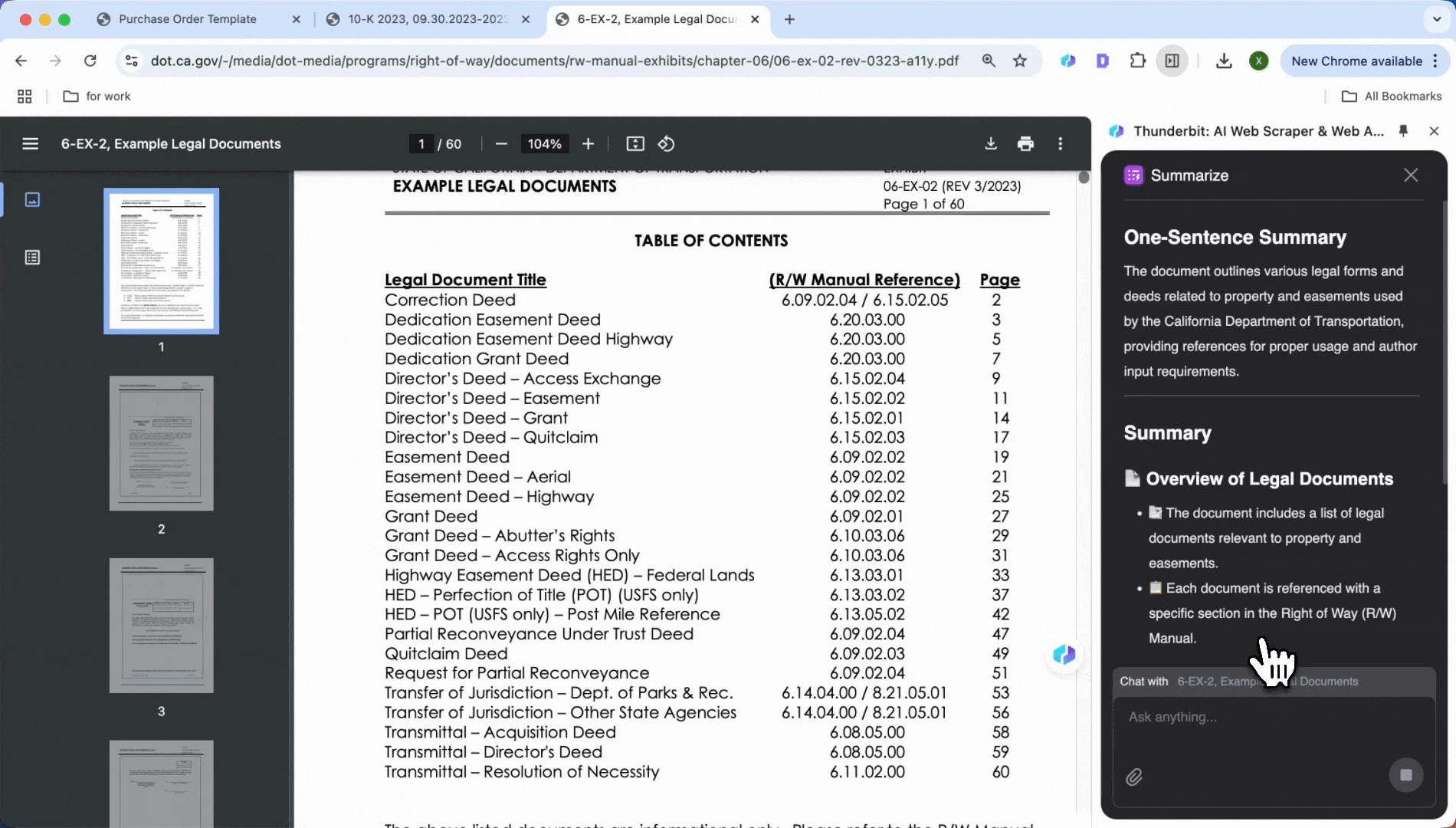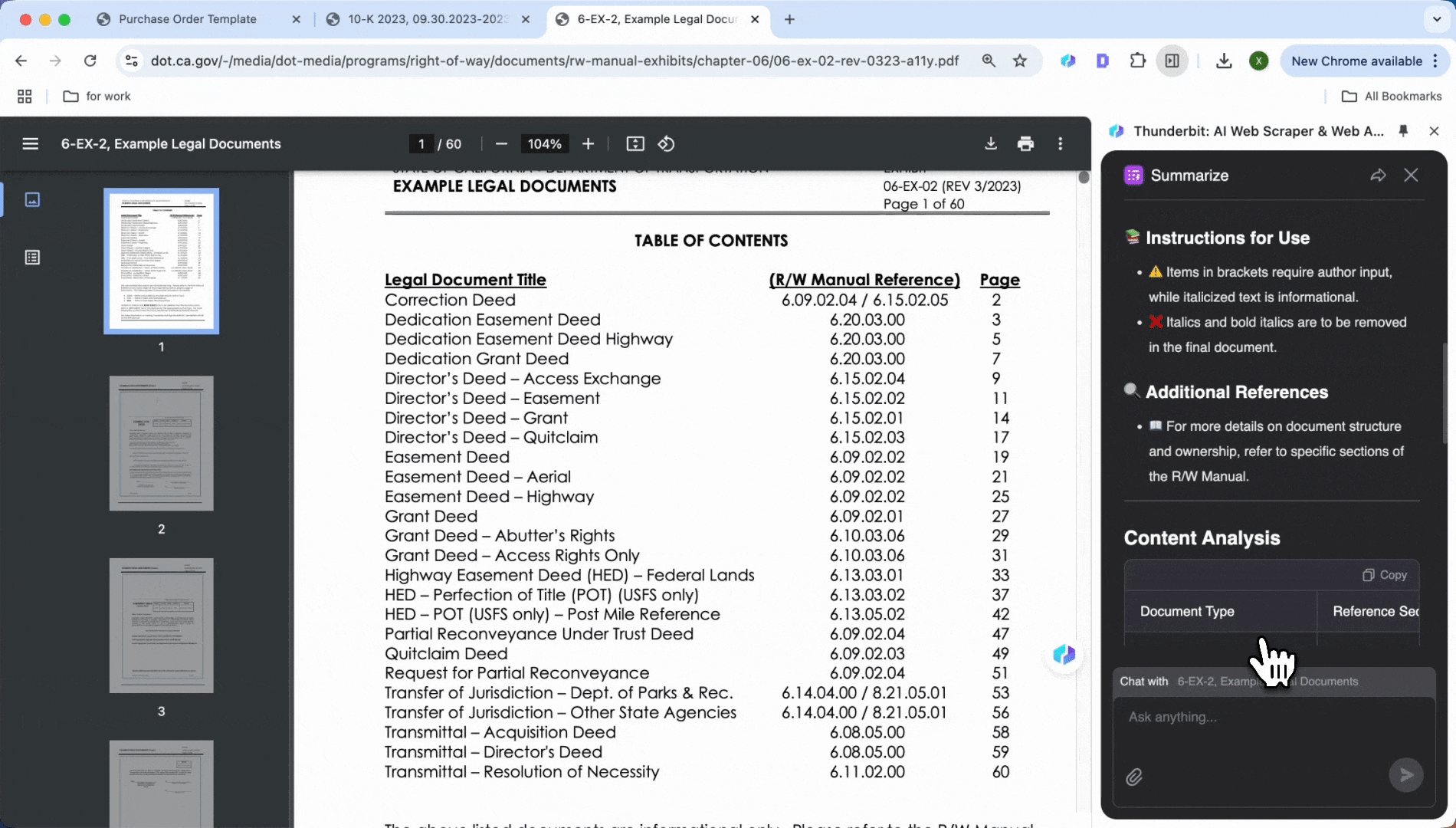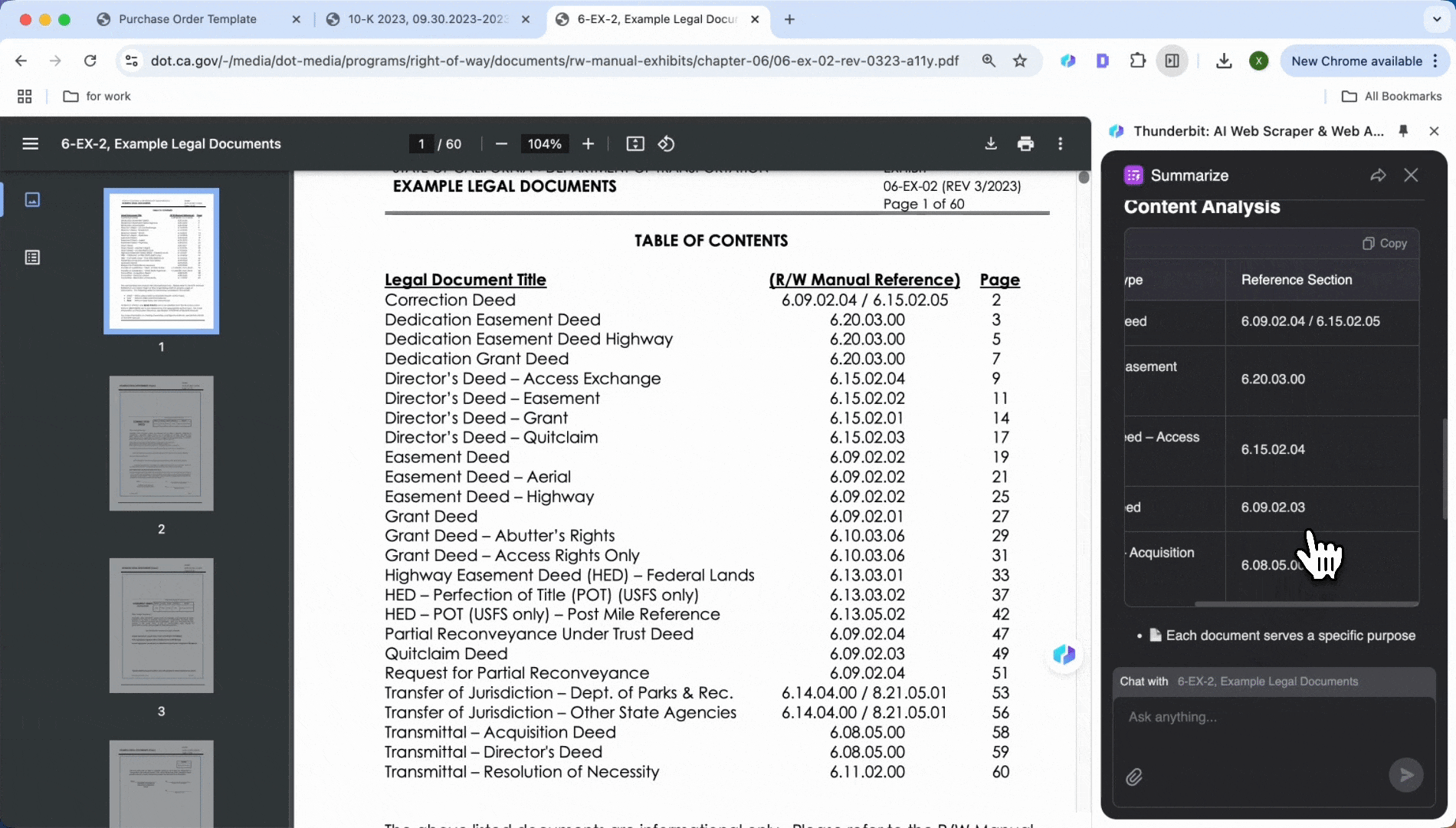
- Auf Zusammenfassen klicken
- Automatisch eine Zusammenfassung der wichtigsten Informationen erzeugen, einschließlich Text- und Tabelleninhalten
Nicht zufrieden mit der automatisch erzeugten Zusammenfassung? Sie können die gewünschten Projektdaten auch manuell eingeben.
- Den Finanzbericht in Chrome öffnen und starten
- Auf KI-Web-Scraper klicken und die gewünschten Projektnamen eingeben, etwa Net Income, Sales usw.
- Auf Scrape klicken, Ausgabe als Tabelle
Analyse juristischer Dokumente
Sie haben Schwierigkeiten mit Klauseln in Verträgen und Vereinbarungen? KI-Tools können Zahlungsbedingungen, Verstöße, Vertragslaufzeiten und andere wichtige Punkte schnell identifizieren. Mit einem Klick extrahieren Sie sie, um eine prägnante Zusammenfassung oder eine Liste von Klauseln zu erstellen, sparen Zeit und stellen sicher, dass keine Details übersehen werden.
Ähnlich wie bei der Extraktion wichtiger Informationen aus Finanzberichten können Sie das PDF öffnen und auf „Zusammenfassen“ klicken, um Zahlungsbedingungen, Vertragsstrafen, Vertragslaufzeiten und andere wichtige Informationen mit nur einem Klick anzuzeigen.
FAQs
-
Kann ich Daten aus mehreren PDFs gleichzeitig extrahieren?
Ja, fortgeschrittene PDF-Scraping-Tools ermöglichen es Nutzern, Daten aus mehreren PDFs gleichzeitig zu extrahieren. Diese Stapelverarbeitung beschleunigt den Arbeitsablauf im Vergleich zu manuellen Extraktionsmethoden erheblich.
-
Ist PDF-Scraper kostenlos?
Ja, es gibt mehrere kostenlose PDF-Scraper-Tools. Viele Online-Tools wie und bieten kostenlose Funktionen zur Seiten- und Datenextraktion. Während für einige erweiterte Funktionen eine Zahlung erforderlich sein kann, sind die grundlegenden Datenextraktionsfunktionen in der Regel kostenlos.
-
Sind Programmierkenntnisse erforderlich, um einen PDF-Scraper zu verwenden?
Nein, viele KI-PDF-Scraper wie sind für Nutzer ohne Programmierkenntnisse entwickelt. Sie bieten benutzerfreundliche Oberflächen, mit denen Sie Dateien hochladen und Daten mit nur wenigen Klicks extrahieren können.
-
Welche Arten von Dokumenten können mit einem PDF-Scraper verarbeitet werden?
PDF-Scraper können verschiedene Dokumenttypen verarbeiten, darunter Rechnungen, Verträge, Finanzberichte, wissenschaftliche Arbeiten und alle anderen strukturierten oder halbstrukturierten Inhalte in PDF-Dateien.
-
Sind meine Daten bei der Verwendung eines PDF-Scrapers sicher?
Seriöse PDF-Scraping-Tools legen großen Wert auf die Sicherheit der Nutzer und halten sich oft an Vorschriften wie die DSGVO. In der Regel speichern sie Ihre Daten auf verschlüsselten Servern und greifen nicht ohne Ihre Erlaubnis darauf zu.
-
Gibt es noch andere Möglichkeiten, Daten aus PDFs zu extrahieren?
Es gibt neben der manuellen Eingabe und Python-Skripten mehrere weitere Methoden, um Daten aus PDF-Dateien zu extrahieren. Dazu gehören PDF-Konverter, die Dateien in Formate wie Excel oder CSV umwandeln, spezialisierte Tools zur PDF-Datenextraktion wie Tabula und Excalibur für strukturierte Dokumente, KI-gestützte Lösungen mit optischer Zeichenerkennung (OCR) für native und gescannte PDFs sowie Open-Source-Tools wie Extractous und PymuPDF4llm für eine effiziente Datenextraktion. Jede Methode hat ihre Vor- und Nachteile; die Wahl hängt daher von den jeweiligen Anforderungen und dem technischen Know-how ab.
Mehr erfahren