Datenextraktionssoftware ist im Jahr 2026 längst keine Kategorie mehr mit nur einem typischen Käuferprofil. Manche Teams brauchen ein browserbasiertes Tool, das Websites in wenigen Minuten in Tabellen verwandelt. Andere brauchen Crawl-APIs, Proxy-Infrastruktur oder eine verwaltete Pipeline, die ein Data Warehouse speist. All diese Anforderungen ohne Kontext in ein einziges Ranking zu packen, ist genau der Weg, wie Käufer Zeit verschwenden und am Ende zu viel einkaufen.
Dieses aktualisierte jährliche Roundup hat ein klares Ziel: Ihnen dabei zu helfen, schnell eine Shortlist zusammenzustellen. Die 15 Tools unten decken weiterhin die meisten realen Kaufwege im Markt ab, lösen aber sehr unterschiedliche Probleme. Wenn Sie Website-Daten schnell und mit minimalem Setup extrahieren müssen, sollte Ihre Shortlist ganz anders aussehen als die eines Teams, das ELT und Governance einkauft.
Hinweis zur Prüfung: Dieses jährliche Roundup wurde am 7. Mai 2026 überprüft. Nächste verantwortliche Redaktion: Thunderbit-Redaktionsteam.
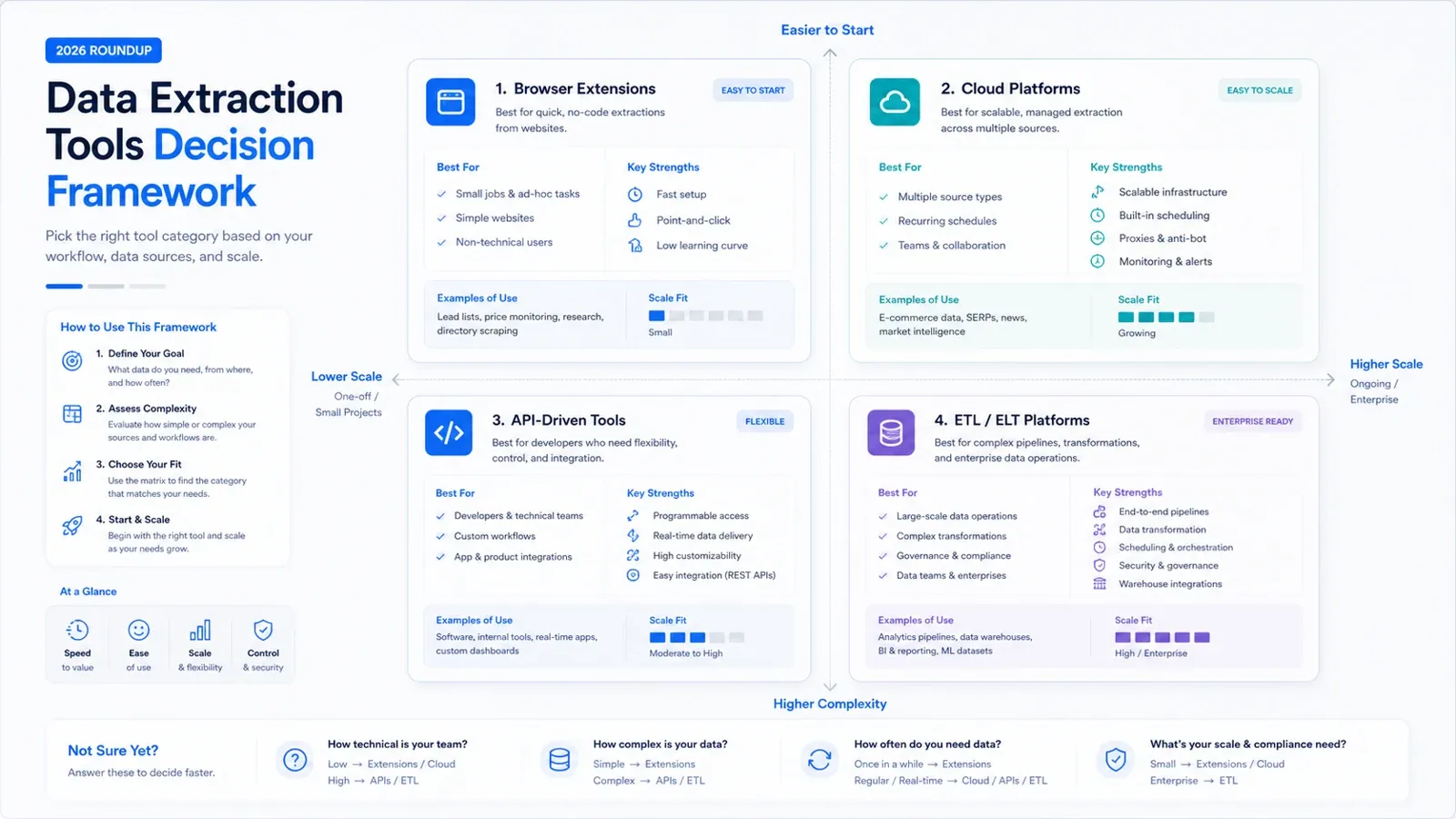
Beginnen Sie mit dem richtigen Tool-Typ
Bevor Sie Anbieter vergleichen, sollten Sie entscheiden, welche Aufgabe Sie eigentlich lösen wollen:
- Sie brauchen Website-Daten schnell in einer Tabelle, ohne Scraping-Infrastruktur aufzusetzen: Starten Sie mit KI- oder No-Code-Browser-Tools wie Thunderbit, Octoparse, Data Miner oder Browse AI.
- Sie brauchen gerenderte Seiten, API-Auslieferung oder Anti-Bot-Infrastruktur für Produktteams: Schauen Sie sich ScrapingBee, Diffbot, Bright Data oder Captain Data an.
- Sie müssen Daten aus SaaS-Apps, APIs und Datenbanken zentral in ein Data Warehouse bringen: Konzentrieren Sie sich auf Airbyte, Hevo, Fivetran, Talend, Matillion oder Integrate.io.
Schnellvergleich: Die besten Tools zur Datenextraktion im Jahr 2026
| Tool | Am besten geeignet für | Was heraussticht | Preismodell |
|---|---|---|---|
| Thunderbit | Business-Anwender, die schnell Website-Daten benötigen | KI-Feldvorschläge, Unterseiten, Paginierung, Tabellenexporte | Freemium; bezahltes Abo + Credits |
| Diffbot | Teams, die strukturierte Web-Datenprodukte aufbauen | Extraktions-API, Crawlbot, Knowledge Graph | Kostenlose Testphase; bezahlte API-Credits; Enterprise-Konditionen |
| Captain Data | Growth- und Ops-Teams, die Outbound-Workflows automatisieren | No-Code-Workflows mit mehreren Schritten über Websites und SaaS-Tools hinweg | Nutzungsbasiert / vertriebsgeführt |
| ScrapingBee | Entwickler, die JS-lastige Seiten scrapen | Headless-Rendering, Proxy-Rotation, einfache API-Ausgabe | Kostenlose Testphase; bezahlte API-Pläne |
| Octoparse | Analysten, die visuelles Scraping plus Cloud-Ausführungen wollen | Point-and-Click-Task-Builder, Vorlagen, geplante Cloud-Jobs | Freemium; bezahlte Pläne |
| Data Miner | Browser-Nutzer, die Listen und Tabellen bei Bedarf extrahieren | Browser-Extraktion auf Rezeptbasis mit schnellem Export | Freemium; bezahlte Pläne |
| Browse AI | Teams mit Fokus auf Monitoring und Änderungswarnungen | Trainierte Roboter, geplantes Monitoring, Ausgabe an Sheets/Zapier | Freemium; bezahlte Pläne |
| Bardeen | Nutzer, die Scraping mit Browser-Automatisierung kombinieren | KI-Playbooks, Browser-Automatisierungen, App-Integrationen | Freemium; bezahlte Pläne |
| Bright Data | Datenerfassung im Enterprise-Maßstab | Proxy-Netzwerk, Unlocker, Datensätze, Scraping-Plattform | Nutzungsbasiert / Vertrag |
| Airbyte | Engineering-Teams, die Warehouse-Pipelines bauen | Offene Konnektoren, Self-Managed-Option, Fokus auf Data Warehouses | Kostenlos self-managed; Cloud- und Enterprise-Tiers |
| Talend / Qlik Talend Cloud | Unternehmen mit stark governance-orientierter Integration | Integration, Qualität, Governance, Enterprise-Kontrollen | Abo nach Angebot |
| Matillion | Cloud-Datenteams, die mit modernen Warehouses arbeiten | Cloud-natives ELT und Transformation innerhalb des Warehouses | Verbrauchsbasiert |
| Integrate.io | Mid-Market-Teams, die verwaltete Pipelines wollen | Verwaltete Integrationen über SaaS und Datenbanken hinweg | Vertriebsgeführtes Abo |
| Hevo Data | Teams, die eine nahezu Echtzeit-Synchronisierung wollen | Verwaltete Konnektoren, Echtzeit-Fokus, geringer Setup-Aufwand | Freemium; bezahlte Pläne |
| Fivetran | Teams, denen Zuverlässigkeit wichtiger ist als Anpassbarkeit | Verwaltete Konnektoren, Schema-Handling, operative Einfachheit | Kostenloser Plan; nutzungsbasierte MAR-Preise |
Was sich 2026 verändert hat
Drei Entwicklungen sind heute wichtiger als allgemeine „Automatisierung“-Floskeln:
- KI-first-Extraktion ist Mainstream. Käufer erwarten zunehmend, dass ein Tool Felder ableitet, grundlegende Seitenvarianten verarbeitet und saubere Tabellen ohne Selektor-Setup exportiert.
- Infrastruktur hat sich von Workflow-Tools getrennt. Manche Produkte kauft man am besten als API- oder Proxy-Schicht, andere als vollständige Workflows für Business-Anwender.
- Jährliche Käufer schauen genauer auf die Wartungskosten. Ein Tool, das auf dem Papier günstiger ist, kann trotzdem schlechter sein, wenn Ihr Team jede Woche Selektoren, Warehouse-Syncs oder Anti-Bot-Umgehungen pflegen muss.
Deshalb ist diese Seite nach Betriebsmodell aufgeteilt, statt so zu tun, als würden alle Tools direkt gegeneinander antreten.
Die besten KI- und No-Code-Tools zur Datenextraktion
1.
Thunderbit bleibt die stärkste Wahl für nicht-technische Teams, die Website-Daten schnell in strukturierter Tabellenform brauchen. Der Kernvorteil ist nicht nur, dass das Tool No-Code ist, sondern dass das Produkt darauf ausgelegt ist, den Einrichtungsaufwand so klein wie möglich zu halten. Sie öffnen eine Seite, lassen sich von der KI Felder vorschlagen, passen die Tabelle bei Bedarf an und exportieren.
- Am besten geeignet für: Sales Ops, E-Commerce-Ops, Recruiting, Research und alle, die von der Browserseite in eine Tabelle wechseln.
- Was heraussticht: KI-Feldvorschläge, Extraktion von Unterseiten, Paginierungs-Unterstützung, Export nach Sheets / Excel / Airtable / Notion.
- Preise: Freemium verfügbar; kostenpflichtige Pläne skalieren über Abo und Credit-Nutzung.
2.
Octoparse gehört weiterhin zu den etabliertesten No-Code-Scraping-Produkten für Teams, die einen klaren visuellen Task-Builder wollen. Es braucht mehr Einrichtung als Thunderbit, aber dafür bekommen Nutzer, die den Workflow modellieren möchten, mehr Kontrolle über ihre Aufgaben.
- Am besten geeignet für: Analysten, Researchers und Ops-Teams, die wiederkehrende Datensätze in moderatem Umfang scrapen.
- Was heraussticht: visuelles Task-Design, Cloud-Zeitplanung, Task-Vorlagen, Login- und Dynamic-Page-Unterstützung.
- Preise: Freemium plus bezahlte Pläne für Cloud-Kapazität und Teamfunktionen.
3.
Data Miner ist weiterhin nützlich für taktische Browser-Extraktion. Besonders stark ist es, wenn jemand schnell eine Liste, ein Verzeichnis oder eine Tabelle erfassen möchte und mit Recipes arbeiten oder sie anpassen kann.
- Am besten geeignet für: browsernative Extraktion von Tabellen, Verzeichnissen und wiederkehrenden Seitenelementen.
- Was heraussticht: große Recipe-Bibliothek, schneller Browser-Workflow, vertraute CSV-/Tabellenexport-Muster.
- Preise: Freemium mit bezahlten Upgrades für intensivere Nutzung.
4.
Browse AI ist besonders stark, wenn es nicht nur um Extraktion, sondern um Monitoring geht. Wenn ein Käufer einen Roboter will, der eine Seite regelmäßig erneut besucht, auf Änderungen achtet und Ergebnisse weiterleitet, bleibt Browse AI relevant.
- Am besten geeignet für: wiederkehrendes Monitoring, Änderungswarnungen und einfache geplante Extraktion.
- Was heraussticht: trainierte Roboter, wiederkehrende Läufe, Alert-ähnliche Workflows, Ausgabe an Sheets und Automatisierungstools.
- Preise: Freemium plus bezahlte Pläne auf Basis der Laufkapazität.
5.
Bardeen bewegt sich an der Schnittstelle zwischen Extraktion und Browser-Workflow-Automatisierung. Es ist weniger ein reiner Scraper und eher eine Browser-Produktivitätsschicht, die Daten sammeln und in den Rest eines Workflows einspeisen kann.
- Am besten geeignet für: Teams, die wiederkehrende Browser-Aufgaben rund um Scraping, Enrichment und Übergaben automatisieren.
- Was heraussticht: KI-Playbooks, Browser-Automatisierungen, tiefe App-Integrationen.
- Preise: Freemium plus bezahlte Pläne.
Die besten API-, Workflow- und infrastrukturbasierten Extraktionstools
6.
Diffbot ist weiterhin eine der klarsten Optionen, wenn der Käufer Extraktion als API-Produkt statt als Browser-Workflow möchte. Das Tool ist für strukturiertes Web-Verständnis im großen Maßstab gebaut und bleibt stärker entwickler- und datenproduktorientiert als die No-Code-Tools oben.
- Am besten geeignet für: Teams, die Datenprodukte, Enrichment-Systeme oder groß angelegte strukturierte Web-Pipelines aufbauen.
- Was heraussticht: Extraktions-APIs, Crawlbot, Knowledge Graph, entitätsorientierte Datenprodukte.
- Preise: kostenlose Testphase und bezahlte API-Credits, mit Enterprise-Optionen.
7.

Captain Data bleibt relevant, weil es Extraktion als einen Schritt in einem breiteren Go-to-Market-Workflow versteht. Besonders nützlich ist es, wenn die eigentliche Aufgabe nicht „eine Seite scrapen“ lautet, sondern „Leads ziehen, anreichern, weiterleiten und Downstream-Systeme aktualisieren“.
- Am besten geeignet für: Growth-, Outbound- und Revenue-Operations-Teams.
- Was heraussticht: Workflows mit mehreren Schritten, Enrichment-Aktionen, CRM-Übergabe, Automatisierung von Outbound-Prozessen.
- Preise: nutzungsbasiert und vertriebsgeführt.
8.
ScrapingBee bleibt eine praktische API-Wahl für Entwickler, die Unterstützung für gerenderte Seiten und Infrastruktur-Abstraktion wollen, ohne ein komplettes Scraping-Setup von Grund auf selbst aufzubauen.
- Am besten geeignet für: Produktteams und Entwickler, die Scraping in Apps oder interne Tools einbetten.
- Was heraussticht: JavaScript-Rendering, Proxy-Handling, einfaches Request-Modell, API-Struktur für Entwickler.
- Preise: bezahlte API-Pläne mit Testzugang.
9.
Bright Data ist weiterhin die Option für den Enterprise-Maßstab, wenn die Herausforderung nicht ein einzelner Workflow ist, sondern Datenmenge, Geografie, Unblocking-Infrastruktur und compliance-intensive Betriebsanforderungen.
- Am besten geeignet für: Web-Datenerfassung im Enterprise-Maßstab, proxy-lastige Workloads und fortgeschrittene Akquisitionsprogramme.
- Was heraussticht: Proxy-Netzwerk, Unlocker-Tools, Datenprodukte und Erfassungsinfrastruktur im Enterprise-Maßstab.
- Preise: nutzungsbasiert und vertraglich.
Die besten ELT- und Datenpipeline-Plattformen mit Extraktionsfunktionen
10.
Airbyte ist die richtige Wahl für die Shortlist, wenn die Aufgabe über Website-Extraktion hinausgeht und das Team Konnektoren, Datenbewegung ins Warehouse und Kontrolle über die Pipeline-Architektur möchte. Es ist kein Ersatz für einen Web-Scraper, aber eine der besseren Antworten, wenn SaaS-, API- und Datenbankdaten zentralisiert werden sollen.
- Am besten geeignet für: engineering-getriebene Teams, die offene Konnektoren und Warehouse-first-Kontrolle wollen.
- Was heraussticht: offenes Ökosystem, Self-Managed-Option, Cloud-Angebot, Flexibilität bei Konnektoren.
- Preise: kostenloser self-managed Pfad plus Cloud- und Enterprise-Tiers.
11.

Talend bleibt eine Enterprise-Integrationsoption für Organisationen, denen gesteuerte Datenbewegung, Qualität, Lineage und Kontrolle wichtiger sind als eine leichte Einrichtung.
- Am besten geeignet für: Unternehmen mit Anforderungen an Governance, Qualität und systemübergreifende Integration.
- Was heraussticht: Enterprise-Governance, Qualitätstools, Integrationsbreite, verwaltete Cloud-Ausrichtung unter Qlik.
- Preise: Abo nach Angebot.
12.
Matillion passt weiterhin zu Cloud-Datenteams, die ELT eng an moderne Warehouses und Transformationen innerhalb des Warehouses ausrichten wollen.
- Am besten geeignet für: Snowflake-, Databricks-, BigQuery- und moderne Warehouse-Teams.
- Was heraussticht: cloud-natives ELT, warehouse-zentrierte Transformation, Team-Workflows für Analytics Engineering.
- Preise: verbrauchsabhängig.
13.
Integrate.io bleibt relevant für Teams, die eine verwaltete Integrationsschicht wollen, ohne selbst einen breiteren, engineering-lastigen Pipeline-Stack aufbauen und pflegen zu müssen.
- Am besten geeignet für: Mid-Market-Teams, die verwaltete Integrationen über SaaS-Apps und Datenbanken hinweg bevorzugen.
- Was heraussticht: verwalteter Implementierungsansatz, Anbindung von Geschäftssystemen, Betriebsmodell mit wenig Reibung.
- Preise: vertriebsgeführtes Abo.
14.
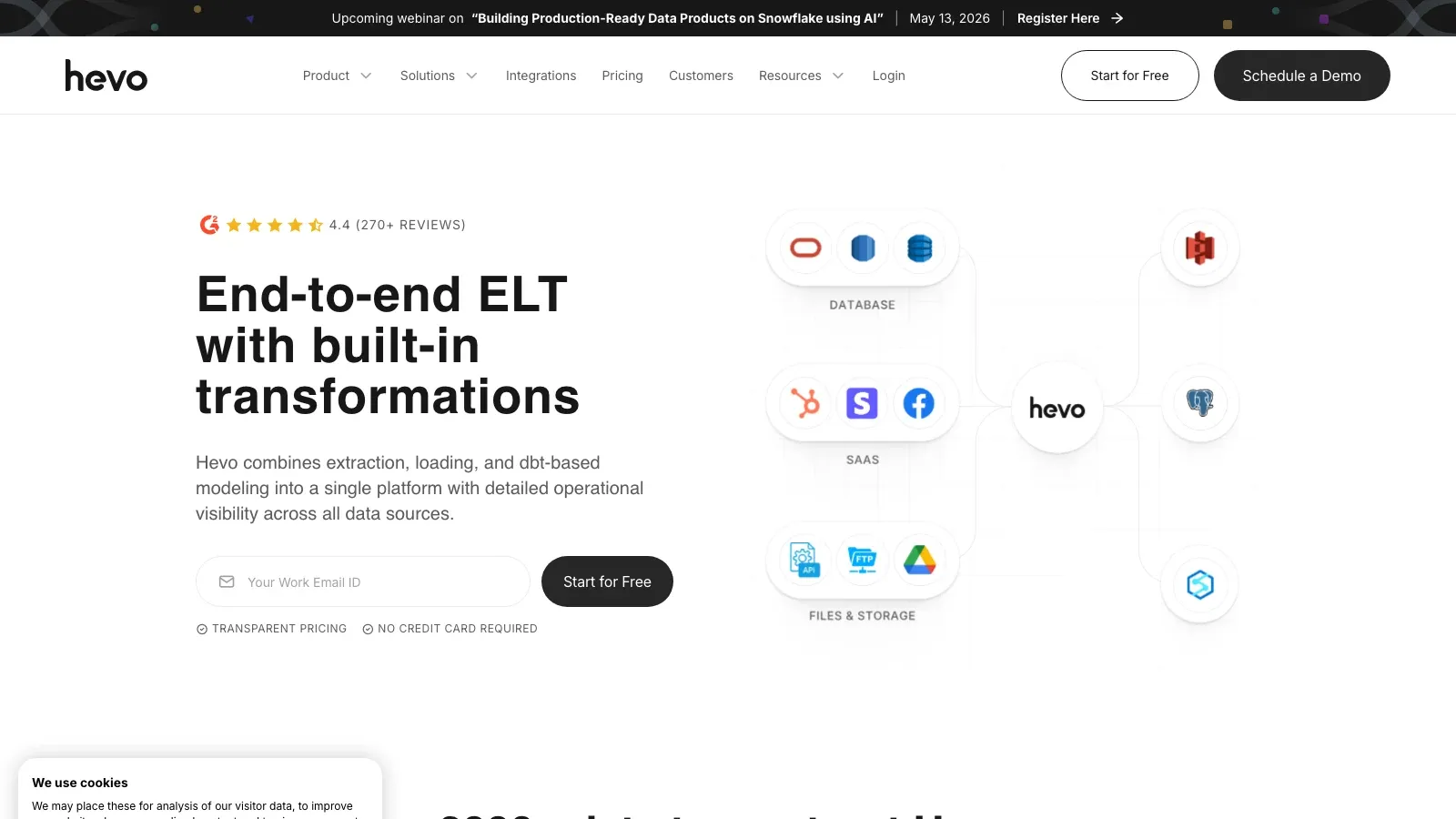
Hevo Data bleibt attraktiv für Teams, die eine einfach einzurichtende, verwaltete Pipeline mit nahezu Echtzeit-Synchronisierung und relativ geringem Betriebsaufwand möchten.
- Am besten geeignet für: Analytics-Teams, die Daten schnell von operativen Systemen ins Warehouse verschieben wollen.
- Was heraussticht: verwaltete Konnektoren, nahezu Echtzeit-Synchronisierung, zugängliches Setup.
- Preise: Freemium und bezahlte Pläne.
15.
Fivetran gehört weiterhin zu den sichersten Shortlist-Kandidaten, wenn dem Käufer Zuverlässigkeit, Wartung der Konnektoren und operative Einfachheit wichtiger sind als Kostenoptimierung oder Anpassungsfreiheit.
- Am besten geeignet für: Datenteams, die einen verwalteten Konnektor-Standard wollen und dafür auch zahlen möchten.
- Was heraussticht: verwaltete Konnektoren, Schema-Handling, hohe operative Reife, wartungsarmer Ansatz.
- Preise: kostenloser Plan plus nutzungsbasierte MAR-Preise.
Wie Sie wählen, ohne zu viel einzukaufen
Der schnellste Weg zur richtigen Entscheidung ist, das falsche Problem gar nicht erst zu lösen.

- Wenn Sie hauptsächlich Website-Daten in eine Tabelle bringen müssen, beginnen Sie nicht mit einer ELT-Plattform.
- Wenn Sie eine gesteuerte Warehouse-Pipeline brauchen, machen Sie keinen Browser-Scraper zur Datenplattform.
- Wenn der schwierigste Teil des Workflows JavaScript-Rendering, Blocking oder API-Auslieferung ist, vergleichen Sie zuerst Infrastruktur-Tools.
- Wenn der schwierigste Teil die Akzeptanz im Team und die Geschwindigkeit beim Setup ist, vergleichen Sie zuerst KI- und No-Code-Tools.
Eine nützliche Kaufregel für 2026 lautet: Kaufen Sie mit so wenig Komplexität wie Ihr echter Workflow es zulässt. Wartungskosten summieren sich schneller als Einsparungen beim Listenpreis.
Finale Shortlist nach Teamtyp
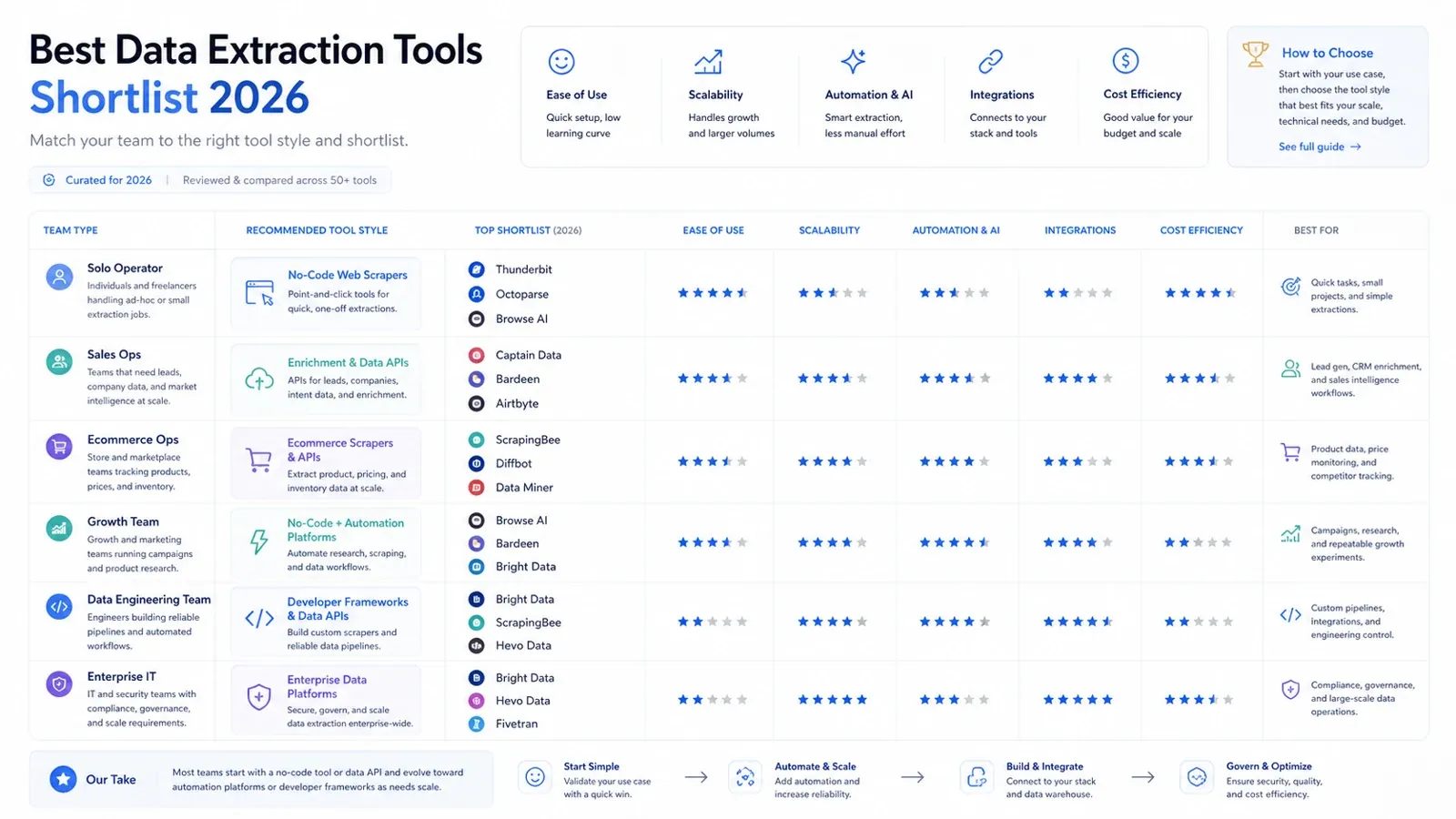
Hier ist die praktische Shortlist-Version:
- Solo-Operator oder Business-Anwender: Thunderbit, Data Miner, Browse AI.
- Sales-Ops- oder Growth-Workflow-Team: Thunderbit, Captain Data, Bardeen.
- E-Commerce-Ops-Team: Thunderbit, Octoparse, Bright Data.
- Data-Engineering-Team: Airbyte, Fivetran, Matillion, Hevo.
- Enterprise-IT / Käufer mit Governance-Fokus: Talend, Fivetran, Integrate.io, Bright Data.
- Entwickler, der Datenprodukte baut: Diffbot, ScrapingBee, Bright Data.
Wenn ich diesen gesamten Markt für die meisten Käufer im Jahr 2026 auf die kürzeste sinnvolle Startliste reduzieren müsste, wäre sie:
- Thunderbit für schnelle, KI-gestützte Website-Extraktion durch nicht-technische Teams.
- ScrapingBee für Entwickler, die eine API-Infrastruktur für gerenderte Seiten brauchen.
- Bright Data für Datenerfassung im Enterprise-Maßstab und Unblocking-Infrastruktur.
- Airbyte für engineering-getriebene Warehouse-Pipelines mit hoher Flexibilität.
- Fivetran für zuverlässige verwaltete Konnektoren.
FAQs
F1: Sind Tools zur Datenextraktion und ETL-Tools dasselbe?
Nein. Ein Tool zur Datenextraktion kann sich auf Websites, PDFs oder strukturierte Erfassung auf Seitenebene konzentrieren, während sich eine ETL- oder ELT-Plattform auf das Verschieben und Transformieren von Daten zwischen Systemen in ein Data Warehouse konzentriert. Manche Käufer brauchen beides, sollten sie aber nicht so bewerten, als würden sie dasselbe erste Problem lösen.
F2: Was ist 2026 die beste Wahl für ein nicht-technisches Team?
Für schnelle Website-Extraktion mit minimalem Setup bleiben KI- und No-Code-Tools der beste Einstiegspunkt. Thunderbit, Octoparse, Browse AI und Data Miner sind die relevantesten ersten Shortlist-Kandidaten, je nachdem, wie viel Kontrolle versus Geschwindigkeit Ihr Team möchte.
F3: Welche Tools eignen sich am besten für Entwickler- oder Enterprise-Use-Cases?
Für Entwickler sind ScrapingBee und Diffbot starke Ausgangspunkte, je nachdem, ob Sie Rendering-Infrastruktur oder APIs für strukturierte Webdaten möchten. Für Datenerfassung im Enterprise-Maßstab oder compliance-intensive Infrastruktur bleibt Bright Data ein wichtiger Shortlist-Kandidat. Für gesteuerte interne Pipelines passen Airbyte, Fivetran, Talend, Matillion, Hevo und Integrate.io besser.