Stell dir vor, wir sind im Jahr 2026 – egal ob du im Vertrieb, in der Orga oder in einer anderen Abteilung unterwegs bist: Das Internet ist deine wichtigste Infoquelle, aber auch ein echter Zeitfresser. Noch nie gab es so viele wertvolle Daten – von Leads über Preise bis hin zu Bewertungen und Wettbewerbsanalysen. Aber wie bekommst du diese Infos schnell und ordentlich in eine Tabelle oder ein Dashboard? Viele Teams verschwenden immer noch Stunden mit Copy & Paste – das Ergebnis: chaotische, veraltete Daten und Frust mit Tabellen.

Die gute Nachricht: Inhalte von anderen Webseiten extrahieren ist längst nicht mehr nur was für Entwickler oder Daten-Nerds. Dank KI-gestützter No-Code-Tools wie können jetzt auch Leute ohne Technik-Know-how die benötigten Daten schnell, präzise und stressfrei einsammeln. In diesem Guide erfährst du, was Web Scraping wirklich bedeutet, warum es für moderne Unternehmen unverzichtbar ist und wie du 2026 effizient (und rechtssicher) Inhalte von Webseiten extrahierst. Egal ob du gerade erst startest oder deinen Workflow verbessern willst – hier bist du richtig.
Was heißt eigentlich "Inhalte von anderen Webseiten extrahieren"?
Kurz gesagt: Inhalte von anderen Webseiten extrahieren bedeutet, dass du mit einer Software automatisch Infos von Webseiten abgreifst und sie in eine strukturierte Form bringst – zum Beispiel als Tabelle, Datenbank oder Excel-Liste. Statt Produktinfos, Kontaktdaten oder Bewertungen mühsam per Hand zu kopieren, übernimmt ein Web-Scraper diese Arbeit für dich ().
Stell dir vor, du bist in einer Bibliothek. Anstatt aus jedem Buch Notizen zu machen, hast du einen Roboter, der die Seiten scannt und dir eine übersichtliche Zusammenfassung liefert. Genau das macht Web Scraping im Netz.
Warum extrahieren Leute Inhalte von Webseiten?
- Lead-Generierung: Namen, E-Mails und Telefonnummern aus Branchenverzeichnissen oder Firmenlisten sammeln.
- Wettbewerbsanalyse: Preise, Produktneuheiten oder Bewertungen auf E-Commerce-Seiten beobachten.
- Marktforschung: Nachrichten, Blogbeiträge oder Forendiskussionen bündeln, um Trends zu erkennen.
- Content-Aggregation: Artikel oder Ressourcen für Newsletter oder interne Wissensdatenbanken zusammenstellen.
Der Unterschied zwischen manueller Datenerfassung und automatisiertem Scraping ist riesig: Scraping ist schneller, genauer und verarbeitet tausende Seiten in wenigen Minuten ().
Warum das Extrahieren von Inhalten für Unternehmen so wichtig ist
Wer immer noch auf manuelle Recherche setzt, verpasst die Geschwindigkeit und Cleverness, mit der moderne Teams heute arbeiten. Datengetriebene Unternehmen , und bis 2026 werden komplett datenbasiert arbeiten.
So bringt das Extrahieren von Inhalten echten Mehrwert für dein Business:
| Anwendungsfall | Was wird extrahiert | Vorteil |
|---|---|---|
| Lead-Generierung | Firmenverzeichnisse, LinkedIn, Gelbe Seiten | Zielgerichtete Kontaktlisten, schneller Pipeline-Aufbau |
| Preisüberwachung | Wettbewerber-Produktlisten, E-Commerce-Seiten | Preisstrategie in Echtzeit anpassen |
| Kunden-Insights | Bewertungen, Social Media, Foren | Feedback analysieren, Trends erkennen, Produkte verbessern |
| Content-Aggregation | News-Seiten, Blogs, Branchenforen | Branchennews kuratieren, Content-Marketing stärken |
Mit Automatisierung sparst du nicht nur Zeit – du triffst auch bessere Entscheidungen und dein Team kann sich auf die wirklich wichtigen Aufgaben konzentrieren ().
Das richtige Web-Scraping-Tool auswählen: Einsteiger-Guide
Wenn du neu beim Extrahieren von Inhalten bist, stehst du erstmal vor der Tool-Frage. Aus Erfahrung: Die Wahl hängt davon ab, wie technikaffin du bist, wie komplex die Zielseiten sind und wie schnell du Ergebnisse brauchst.
Die wichtigsten Tool-Typen:
- Code-basierte Tools (z. B. Python mit BeautifulSoup oder Scrapy): Maximale Flexibilität, aber du musst programmieren können. Ideal für Entwickler oder IT-Teams.
- No-Code-Tools (z. B. ParseHub, Octoparse): Visuelle Oberflächen, Vorlagen und Klick-Workflows. Perfekt für Nicht-Programmierer, bei sehr komplexen Seiten manchmal etwas tricky.
- Browser-Erweiterungen (z. B. Thunderbit, Web Scraper): Direkt in Chrome, super easy zu installieren, ideal für schnelle, gezielte Extraktionen.
Gerade für Einsteiger und Business-User zählt vor allem die einfache Bedienung. Deshalb empfehle ich, mit einer Browser-Erweiterung wie zu starten. Sie ist für Nicht-Techniker gemacht und nutzt KI, um die Einrichtung zu vereinfachen.
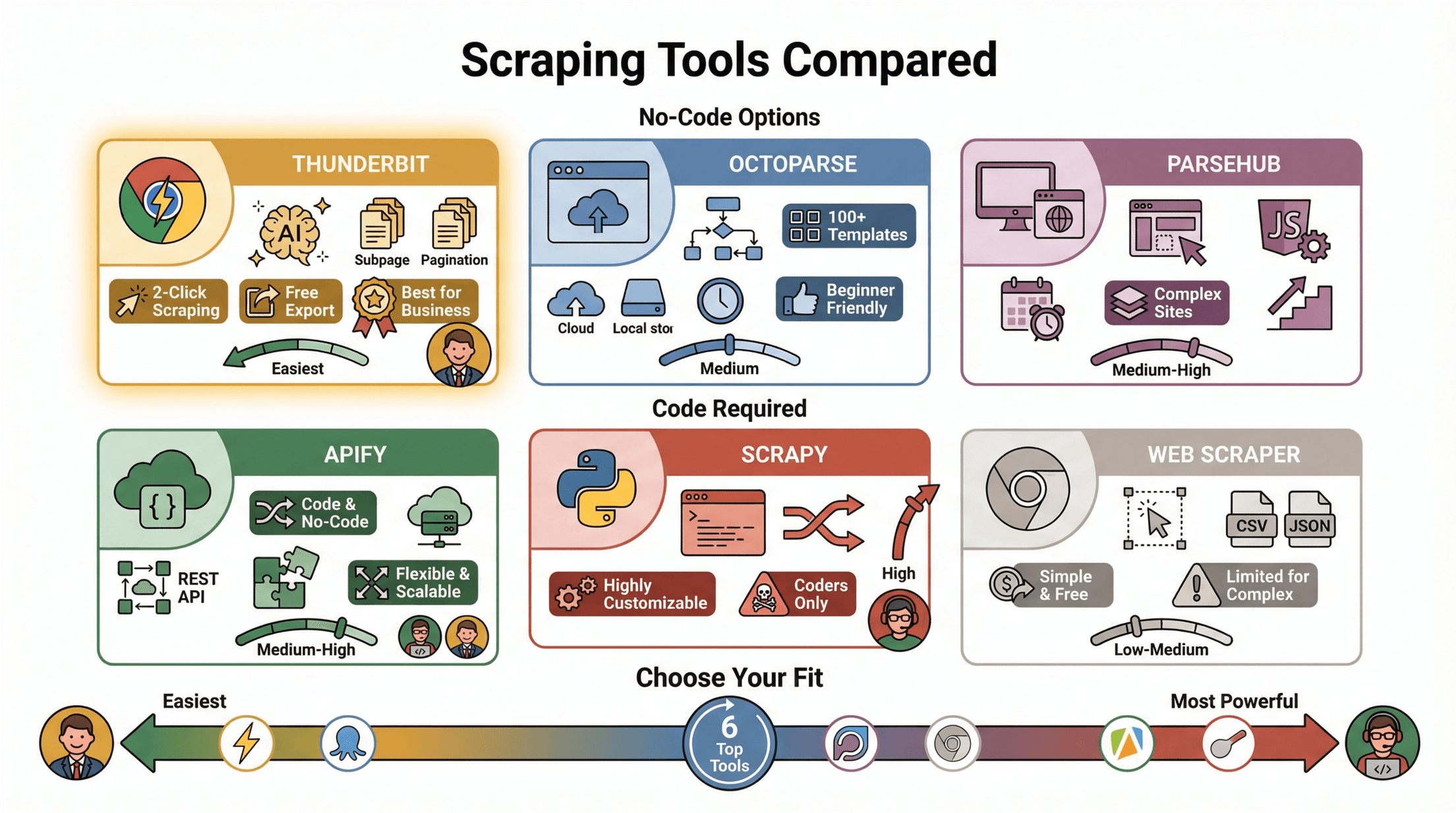
Vergleich beliebter Web-Scraping-Tools
So schlagen sich die wichtigsten Tools beim Extrahieren von Inhalten:
| Tool | Typ | Hauptfunktionen | Vorteile / Nachteile |
|---|---|---|---|
| Thunderbit | Chrome-Erweiterung, KI | 2-Klick-Scraping, KI-Feldvorschläge, Subseiten & Paginierung, kostenloser Export | Sehr einfach, kein Code, ideal für Business-Anwender |
| Octoparse | Desktop-App, No-Code | Visueller Workflow, 100+ Vorlagen, Cloud/Lokal, Zeitplanung | Einsteigerfreundlich, aber Gratis-Version eingeschränkt |
| ParseHub | Desktop/Web, No-Code | Visueller Builder, für dynamische/JS-Seiten, Zeitplanung | Gut für komplexe Seiten, aber steilere Lernkurve |
| Apify | Cloud/Code/No-Code | Code & No-Code, serverlos, REST API, Integrationen | Flexibel, skalierbar, etwas Technikkenntnis nötig |
| Scrapy | Python-Bibliothek, Code | Asynchrones Crawling, hochgradig anpassbar | Sehr mächtig, aber nur für Entwickler |
| Web Scraper | Chrome-Erweiterung, No-Code | Visuelle Auswahl, Export als CSV/JSON | Einfach, kostenlos, aber limitiert bei komplexen Seiten |
Für die meisten Business-User sind Thunderbit und Octoparse der einfachste Einstieg ().
Thunderbits besondere Stärken beim Extrahieren von Inhalten
Jetzt mal ehrlich: Was besonders macht, ist der Fokus auf Einsteiger und Business-User.
Das macht Thunderbit einzigartig:
- Natürliche Sprache: Einfach beschreiben, was du brauchst („Alle Produktbewertungen und Sterne von dieser Seite“), und die KI erledigt den Rest.
- KI-Feldvorschläge & Feldverbesserung: Thunderbit scannt die Seite und schlägt die besten Spalten vor – Namen, Preise, E-Mails usw. Kein Gefummel mit Selektoren oder Code.
- 2-Klick-Workflow: „KI-Felder vorschlagen“ klicken, dann „Extrahieren“. Fertig. Selbst meine Mutter würde das hinbekommen (und die denkt, „Cloud“ ist nur schlechtes Wetter).
- Unterstützung für Subseiten und Paginierung: Thunderbit folgt automatisch Links zu Detailseiten (z. B. einzelne Produktbewertungen) und verarbeitet mehrseitige Listen.
- Sofort-Export: Daten direkt nach Excel, Google Sheets, Airtable oder Notion exportieren – ohne Zusatzaufwand oder Kosten.
Beispiel: Du willst Produktbewertungen aus einem Online-Shop extrahieren. Einfach die Bewertungsseite öffnen, auf das Thunderbit-Icon klicken, „KI-Felder vorschlagen“ wählen – Thunderbit schlägt Spalten wie „Name des Bewerters“, „Bewertung“ und „Text“ vor. Mit „Extrahieren“ bist du fertig. Für mehr Details kannst du Subseiten-Scraping nutzen.
User berichten regelmäßig, dass Thunderbit „auch bei langen Seiten zuverlässig funktioniert“ und „dynamische Seiten problemlos extrahiert“ ().
Inhalte von komplexen Webseiten extrahieren: Paginierung und Subseiten
Hand aufs Herz: Viele Webseiten machen es einem nicht leicht, an die gewünschten Daten zu kommen. Online-Shops, Verzeichnisse und Bewertungsportale nutzen oft Paginierung (mehrere Seiten) oder verschachtelte Subseiten (z. B. Detailseiten für jedes Produkt).
Das Problem: Herkömmliche Scraper übersehen oft Daten hinter „Weiter“-Buttons oder auf Subseiten. Manuell? Da klickst du dich dumm und dämlich.
Thunderbits Lösung: Die KI erkennt Paginierungs-Links oder Endlos-Scrollen und extrahiert alle Daten automatisch. Bei Subseiten kann Thunderbit jeden Link in deiner Tabelle besuchen (z. B. jedes Produkt) und zusätzliche Felder erfassen – alles wird direkt zusammengeführt.
Schritt-für-Schritt: Mehrseitige und verschachtelte Inhalte extrahieren
So gehst du bei komplexen Seiten mit Thunderbit vor:
- Öffne die Hauptübersicht (z. B. eine Kategorie im Online-Shop oder ein Branchenverzeichnis).
- Thunderbit-Icon anklicken und „KI-Felder vorschlagen“ wählen. Thunderbit schlägt Spalten wie „Produktname“, „Preis“, „Link“ vor.
- „Extrahieren“ klicken. Thunderbit sammelt alle Einträge auf der aktuellen Seite – und folgt automatisch der Paginierung.
- Mehr Details nötig? „Subseiten extrahieren“ wählen. Thunderbit besucht jede Detailseite und holt weitere Infos (z. B. Bewertungen, Spezifikationen, Kontaktdaten).
- Daten prüfen und exportieren – fertig ist dein vollständiger, angereicherter Datensatz.
Tipp: Subseiten-Scraping lohnt sich immer dann, wenn du Links zu „Details“, „Bewertungen“ oder „Kontakt“ siehst – ideal für Online-Shops, Gelbe Seiten oder Immobilienportale.
Extrahierte Daten organisieren und analysieren: Tags, Kategorien & Export
Das Extrahieren ist nur der erste Schritt. Damit du wirklich was von den Daten hast, musst du sie strukturieren, analysieren und teilen.
Thunderbit macht das easy:
- Tags und Kategorien: Verteile Tags oder Kategorien für Felder (z. B. „Produkttyp“, „Region“, „Lead-Status“), um später gezielt zu filtern und auszuwerten.
- Feld-KI-Prompts: Du willst SKUs kategorisieren oder Bewertungen übersetzen? Einfach eine Anweisung zum Feld hinzufügen – Thunderbits KI macht das beim Extrahieren.
- Exportmöglichkeiten: Daten direkt nach Excel, Google Sheets, Airtable oder Notion schicken. Oder als CSV oder JSON runterladen.
Best Practices für die Datenorganisation:
- Klare, einheitliche Spaltennamen nutzen.
- Tags oder Kategorien für einfaches Filtern verwenden.
- Rohdaten archivieren und bereinigte Datensätze separat speichern.
- Für laufende Projekte regelmäßige Exporte oder geplante Scrapes einrichten.
Vertriebsteams können Leads nach Quelle oder Status labeln, Operations-Teams Produkte nach Lieferant oder Region sortieren. Ziel: Deine extrahierten Daten sollen nutzbar und leicht teilbar sein.
Rechtliche Hinweise: Was beim Extrahieren von Inhalten zu beachten ist
Bevor du loslegst, ein wichtiger Punkt: Das Extrahieren öffentlicher Daten ist in der Regel erlaubt, wenn du ein paar Grundregeln beachtest (, ).
Wichtige Compliance-Tipps:
- Nur öffentlich zugängliche Inhalte extrahieren. Keine Logins, Paywalls oder Sicherheitsmechanismen umgehen.
- robots.txt und Nutzungsbedingungen beachten. Die zeigen, was Website-Betreiber erlauben.
- Keine urheberrechtlich geschützten oder persönlichen Daten extrahieren. Bleib bei Fakten (Namen, Preise, Spezifikationen) und veröffentliche keine großen Text- oder Bildmengen.
- Quellen angeben, wenn du extrahierte Daten weiterverwendest.
- Anfragen drosseln, damit Webseiten nicht überlastet werden.
Checkliste für risikofreies Scraping:
- ✅ Nur öffentliche Seiten (keine Logins)
- ✅ robots.txt und AGB prüfen
- ✅ Keine urheberrechtlich geschützten oder persönlichen Daten
- ✅ Quellen angeben
- ✅ Nicht zu schnell extrahieren
Thunderbit unterstützt verantwortungsvolles Scraping, indem du gezielt nur die benötigten Daten extrahierst und für interne Zwecke exportierst.
Schritt-für-Schritt-Anleitung: Inhalte mit Thunderbit extrahieren
Du willst es selbst ausprobieren? So extrahierst du Inhalte mit :
- Thunderbit Chrome-Erweiterung installieren: und kostenlos registrieren.
- Zielseite öffnen: Geh auf die gewünschte Seite (z. B. Produktliste, Branchenverzeichnis, Bewertungsseite).
- Thunderbit-Icon anklicken: In der Chrome-Leiste Thunderbit öffnen.
- „KI-Felder vorschlagen“ nutzen: Thunderbit scannt die Seite und schlägt passende Spalten vor (z. B. „Name“, „Preis“, „E-Mail“).
- Spalten anpassen: Benenne, füge hinzu oder entferne Felder nach Bedarf. Du kannst auch eigene KI-Prompts für Labels oder Kategorien ergänzen.
- „Extrahieren“ klicken: Thunderbit sammelt die Daten der aktuellen Seite – und folgt bei Bedarf der Paginierung.
- Subseiten extrahieren (optional): Für mehr Details „Subseiten extrahieren“ wählen, um verlinkte Seiten zu erfassen.
- Daten prüfen und exportieren: Vorschau anzeigen, dann nach Excel, Google Sheets, Airtable, Notion exportieren oder als CSV/JSON herunterladen.
Häufige Probleme und Lösungen:
- Login-Seiten: Nutze Thunderbits Browser-Scraping-Modus, während du eingeloggt bist.
- Blockierte oder langsame Seiten: Versuch es zu Randzeiten oder teile den Extraktionsvorgang in kleinere Abschnitte.
- Dynamische Inhalte werden nicht geladen: Seite komplett scrollen oder Thunderbits Browser-Modus nutzen.
- Layout-Änderungen: „KI-Felder vorschlagen“ erneut ausführen, damit die KI sich anpasst.
Bei Fragen hilft die oder der Support gerne weiter.
Fazit & wichtigste Erkenntnisse
Das Extrahieren von Inhalten ist längst kein Geheimtipp für Entwickler mehr, sondern ein Muss für moderne Unternehmen. 2025 – mit der Datenflut im Web und KI-gestützten No-Code-Tools – kann jeder die benötigten Infos schnell, präzise und ohne Stress einsammeln.
Das solltest du mitnehmen:
- Inhalte von Webseiten zu extrahieren ist essenziell für Lead-Generierung, Marktforschung und Wettbewerbsfähigkeit.
- Moderne Tools wie machen Web Scraping für alle zugänglich – mit natürlicher Sprache, KI-Feldvorschlägen und Sofort-Export.
- Dank Paginierung, Subseiten-Scraping und Datenorganisation meisterst du auch komplexe Seiten.
- Bleib rechtssicher: Nur öffentliche Daten extrahieren, Regeln der Seite beachten, keine urheberrechtlich geschützten oder persönlichen Inhalte nutzen.
- Der Einstieg ist so einfach wie eine Chrome-Erweiterung installieren und ein paar Klicks.
Bereit, Copy & Paste hinter dir zu lassen? und spar dir Zeit (und Nerven) bei deinem nächsten Webdaten-Projekt. Mehr Tipps und Anleitungen findest du im .
Häufige Fragen (FAQ)
1. Ist es legal, Inhalte von anderen Webseiten zu extrahieren?
In der Regel ja – solange du nur öffentlich zugängliche Daten nutzt, robots.txt und Nutzungsbedingungen respektierst und keine urheberrechtlich geschützten oder persönlichen Infos extrahierst. Schau dir immer die Regeln der jeweiligen Seite an und geh verantwortungsvoll mit den Daten um ().
2. Muss ich programmieren können, um Inhalte von Webseiten zu extrahieren?
Nein! Tools wie sind für Nicht-Techniker gemacht. Du kannst Daten mit wenigen Klicks und KI-gestützten Feldvorschlägen extrahieren.
3. Welche Webseiten kann ich mit Thunderbit extrahieren?
Thunderbit funktioniert auf vielen Seiten – von Online-Shops über Verzeichnisse bis zu Bewertungsportalen und Immobilienangeboten. Paginierung, Subseiten und dynamische Inhalte werden meist problemlos unterstützt.
4. Wie organisiere und analysiere ich die extrahierten Daten?
Mit Thunderbit kannst du Daten beim Extrahieren taggen, kategorisieren und labeln. Der Export nach Excel, Google Sheets, Airtable oder Notion ermöglicht weitere Analyse und Zusammenarbeit.
5. Was tun, wenn eine Webseite meinen Scraper blockiert oder das Layout ändert?
Versuch es langsamer, nutze Thunderbits Browser-Scraping-Modus oder führe „KI-Felder vorschlagen“ erneut aus, um dich an neue Layouts anzupassen. Bei Problemen hilft die oder der Support.
Viel Erfolg beim Extrahieren – und auf stets saubere, strukturierte und einsatzbereite Daten!
Mehr erfahren