

웹은 더 이상 '오른쪽 클릭해서 저장'만으로 끝나는 곳이 아니에요. 요즘 사이트는 동적 콘텐츠, 숨은 링크, 팝업, 겹겹의 메뉴로 가득해 미로 같죠. 이커머스 사이트에서 상품 정보를 다 모으거나 부동산 포털 매물을 한 번에 긁어보려 했다면, 기본 스크래퍼로는 벽에 부딪힌다는 걸 이미 느꼈을 거예요. 그래서 '딥 크롤러'가 나왔어요. 더 깊고 넓게 긁어오도록 만든 차세대 웹 스크래핑 도구죠.
그럼 딥 크롤러가 정확히 뭘까요? 왜 요즘 기업들이, 영업팀부터 시장조사팀까지 여기에 주목할까요? 그리고 Thunderbit 같은 도구가 코딩 없이 딥 크롤링을 클릭 몇 번으로 끝내는 비결은요? 기본 개념부터 비즈니스 영향까지 쉽게 풀어드릴게요.
딥 크롤러란? 기본 개념부터 알아보기
AI로 모든 웹사이트에서 데이터 추출하기 Get Started Free
딥 크롤러는 복잡하고 여러 층에 동적으로 변하는 사이트에서 데이터를 꼼꼼히 훑어 추출하는 데 특화된 웹 크롤러예요. 기존 크롤러가 메인 페이지에 보이는 정보만 후딱 긁었다면, 딥 크롤러는 링크를 따라가며 여러 단계 내비게이션을 거치고, 탭이나 확장 영역에 숨은 콘텐츠까지 샅샅이 모아요.
기존 크롤러가 도서관 입구에서 책 제목만 훑는 사람이라면, 딥 크롤러는 서가를 누비며 책을 펼쳐 보고, 각주까지 확인하고, '직원 전용' 문 뒤까지(잠겨 있지 않다면) 들여다보는 사람이죠.
딥 크롤러가 웹 스크래핑에서 할 수 있는 일은 이래요.
- 웹사이트의 여러 계층을 탐색 (카테고리, 하위 카테고리, 상세 페이지 등)
- 자바스크립트로 동적 로드되거나 사용자 상호작용 뒤에 숨은 콘텐츠 추출
- 복잡한 페이지네이션 및 무한 스크롤 처리
- 내부 링크를 추적하고 방문해서 중요한 데이터를 빠짐없이 수집
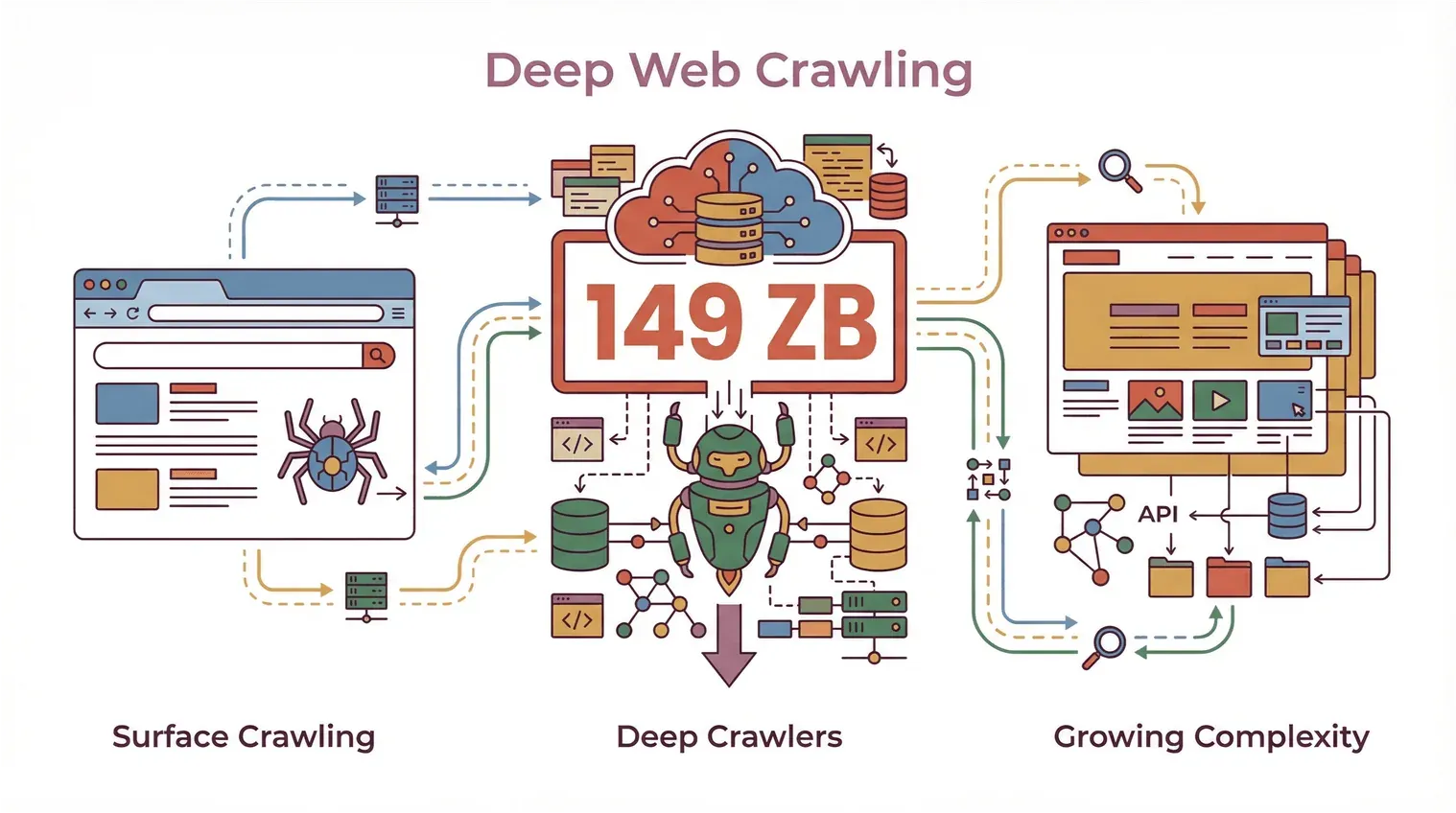 2024년 기준, 전 세계 웹 데이터는 149제타바이트까지 불어났고, 웹사이트 복잡성도 해마다 두 배씩 늘고 있어요. 이런 환경에서 딥 크롤러는 표면만 긁는 수준을 넘어, 진짜 필요한 데이터를 얻기 위한 필수 도구가 되고 있어요.
2024년 기준, 전 세계 웹 데이터는 149제타바이트까지 불어났고, 웹사이트 복잡성도 해마다 두 배씩 늘고 있어요. 이런 환경에서 딥 크롤러는 표면만 긁는 수준을 넘어, 진짜 필요한 데이터를 얻기 위한 필수 도구가 되고 있어요.
딥 크롤러 vs. 전통적 크롤러: 뭐가 다를까?
좀 더 구체적으로, 딥 크롤러와 기존 크롤러의 차이는 뭘까요?
전통적 크롤러: 표면만 훑는 방식
전통적 웹 크롤러('얕은 크롤러')는 속도와 범위에 집중해요. 메인 페이지를 빠르게 스캔하고, 보이는 정보만 긁은 뒤 바로 다음 사이트로 넘어가죠. 검색 엔진 대부분이 이 방식이에요. 되도록 많은 페이지를 빨리 인덱싱하는 게 목적이라, 구석구석 깊이 파진 않아요.
전통적 크롤러의 한계:
- 내비게이션, 탭, 동적 요소 뒤에 숨은 데이터는 놓치기 쉽다
- 자바스크립트 기반 사이트나 페이지 로딩 이후 나타나는 콘텐츠는 잘 못 다룬다
- 여러 단계의 내비게이션이나 복잡한 페이지 구조는 대응이 어렵다
- 데이터가 불완전하거나 조각난 채로 수집될 수 있다
딥 크롤러: 표면을 넘어 깊이 파고들다
딥 크롤러는 사이트를 완전히 탐색해요. 관련 링크를 다 따라가고, 페이지네이션을 클릭하며, 하위 페이지·팝업·동적 콘텐츠까지 꼼꼼히 추출하죠. 속도보다 완전성과 정확성이 우선이에요.
딥 크롤러의 주요 특징:
- 고급 내비게이션: 링크를 재귀적으로 따라가고, 다단계 사이트 구조를 파악하며, 중복 페이지나 막다른 길을 피함 (SEO-Wiki).
- 동적 콘텐츠 추출: 자바스크립트와 상호작용하고, 숨은 영역을 펼쳐 사용자 행동 이후 나타나는 데이터까지 수집 (Scientific Reports).
- 효율성 향상: 사이트 핵심 영역에 집중해 중복·불필요한 데이터는 줄이고, 중요한 정보는 빠짐없이 확보 (Medium).
- 데이터 완전성: 메인 목록, 상세 페이지, 관련 문서 등 모든 계층 정보를 한 번에 수집
상품 리뷰 전체를 긁거나, 부동산 포털에서 중개인 정보까지 다 모으려다 기존 크롤러의 한계를 느꼈다면, 딥 크롤러가 바로 그 답이에요.
딥 크롤러의 데이터 완전성 & 고급 페이지 탐색 방식
딥 크롤러는 어떻게 이런 마법을 부릴까요? 핵심은 링크 추적, 재귀적 탐색, 그리고 동적 콘텐츠의 스마트한 처리예요.
하위 페이지 스크래핑과 다층 내비게이션
딥 크롤러는 첫 페이지에서 멈추지 않아요. 이런 과정을 거쳐요.
- 내부 링크 식별 (예: '상세보기', '다음 페이지', '더 보기' 등)
- 이 링크들을 따라가 하위 페이지, 상세 뷰, 팝업으로 이동
- 각 계층에서 데이터 추출 후, 모든 정보를 하나의 구조화된 데이터셋으로 통합
이 방식은 '재귀 크롤링' 또는 '다단계 스크래핑'이라고도 불러요. 정보가 여러 페이지에 흩어진 사이트(예: 상품 목록과 별도의 상세 페이지, 클릭해야 보이는 연락처 등)에 특히 유용하죠.
페이지네이션 및 동적 콘텐츠 처리
요즘 웹사이트는 '더 보기' 버튼, 무한 스크롤, 자바스크립트 탭으로 데이터를 숨기는 경우가 많아요. 딥 크롤러는 이걸 해요.
- 페이지네이션 컨트롤을 감지하고 상호작용
- 동적 요소를 클릭하거나 스크롤
- 콘텐츠가 완전히 로드될 때까지 기다린 뒤 데이터 추출
이렇게 하면 페이지가 처음 뜰 때 안 보이는 정보까지 완벽하게 수집할 수 있어요 (Thunderbit Blog).
딥 링크 추적 및 다층 스크래핑
딥 크롤링에서 가장 까다로운 건 숨은 데이터나 중첩된 정보를 놓치지 않는 거예요. 딥 크롤러는 이런 알고리즘을 써요.
- 방문한 링크 추적 (중복 수집이나 무한 루프 방지)
- 중요 페이지 우선순위 지정 (상세 뷰, 다운로드 문서 등)
- 예외 상황 처리 (팝업, 확장 영역, AJAX로 로드되는 콘텐츠 등)
비즈니스 현장에선 연락처 하나, 제품 사양 하나 놓쳐도 기회 손실이나 분석 오류로 이어질 수 있어서, 이런 꼼꼼함이 정말 중요해요 (Simplescraper).
Thunderbit: AI 기반 딥 크롤링, 누구나 쉽게
예전엔 딥 크롤링이 개발자나 데이터 엔지니어만의 영역이었어요. 직접 스크립트를 짜고, 예외를 처리하고, 사이트가 바뀔 때마다 코드를 고쳐야 했죠. 하지만 Thunderbit는 이 복잡함을 걷어내, 코딩 경험이 전혀 없어도 누구나 딥 크롤링을 하게 만들었어요.
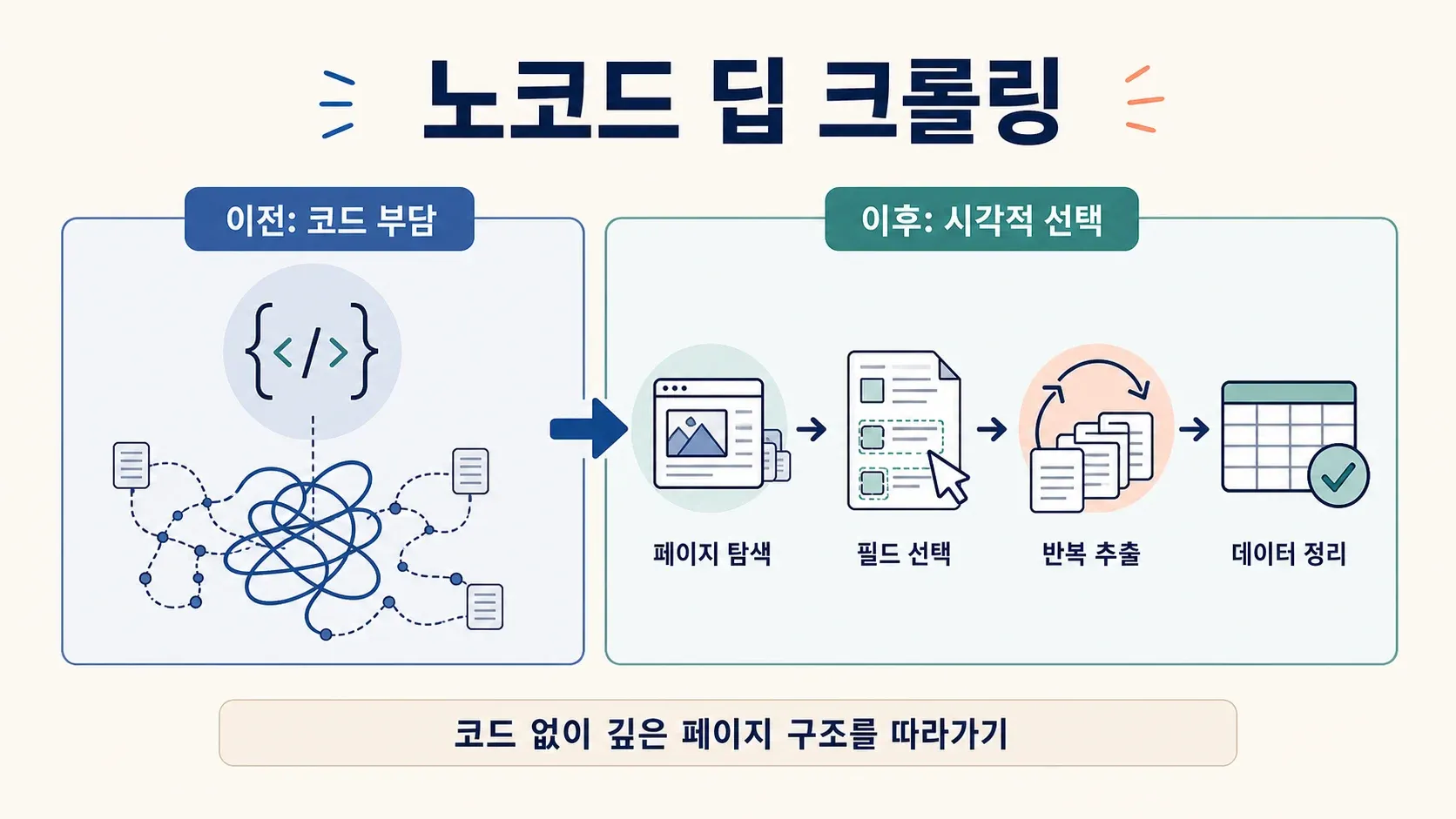 Thunderbit 딥 크롤러의 주요 기능
Thunderbit 딥 크롤러의 주요 기능
Thunderbit가 딥 크롤링을 얼마나 쉽게 만들어주는지 한번 볼까요?
- AI 필드 추천: 'AI 필드 추천' 버튼만 누르면, Thunderbit의 AI가 페이지를 분석해 추출할 컬럼을 제안하고, 각 필드에 맞는 프롬프트까지 알아서 만들어줘요.
- 하위 페이지 스크래핑: 더 많은 정보가 필요하면? Thunderbit가 알아서 각 하위 페이지(예: 상품 상세, 중개인 프로필, 리뷰 탭 등)를 돌며 추가 데이터를 테이블에 채워줘요.
- 동적 콘텐츠 처리: 페이지네이션, 무한 스크롤, 동적 요소까지 Thunderbit가 직접 상호작용해요. 별도 설정 없이 바로 써요.
- 노코드, 2단계 프로세스: 원하는 데이터를 설명하고 '스크래핑'을 누르면 끝. 추출한 데이터는 Excel, Google Sheets, Notion, Airtable로 바로 내보내요. 추가 비용이나 제한도 없고요 (Thunderbit Blog).
실전 예시: Thunderbit로 딥 크롤링하기
예를 들어 부동산 사이트에서 모든 매물과 중개인 연락처(하위 페이지에 숨은 정보까지)를 모으고 싶다면 이렇게 해요.
- 크롬에서 매물 목록 페이지를 엽니다.
- Thunderbit 확장 프로그램을 클릭합니다.
- 'AI 필드 추천'을 사용해 Thunderbit가 '매물명', '가격', '주소', '중개인 링크' 같은 컬럼을 알아서 제안하게 합니다.
- '스크래핑'을 클릭하면 메인 목록이 수집됩니다.
- '하위 페이지 스크래핑'을 클릭하면 Thunderbit가 중개인 프로필마다 들어가 전화번호, 이메일 같은 추가 정보를 뽑아 메인 테이블에 합칩니다.
- 데이터를 Google Sheets나 Excel로 내보내면 영업팀이나 운영팀이 바로 활용할 수 있어요.
코드도, 템플릿도, 복잡한 설정도 필요 없어요. 사이트 구조가 바뀌어도 Thunderbit의 AI가 알아서 적응하고요 (Thunderbit Docs).
비즈니스에서 딥 크롤러가 만드는 변화: 영업·마케팅 혁신
딥 크롤러가 멋져 보이긴 한데, 실제 비즈니스엔 어떤 가치를 줄까요? 여기서 진짜 힘이 드러나요.
이커머스, 부동산, 경쟁사 사이트에서 인사이트 확보
영업·마케팅팀에게 딥 크롤러는 데이터 금광이에요. 예를 들면 이래요.
- 이커머스 사이트에서 모든 상품, 가격, 리뷰를 계층 구조나 탭 뒤에 숨어 있어도 빠짐없이 추출
- 부동산 매물 통합 (숨은 중개인 정보, 상세 매물 정보까지 포함)
- 경쟁사 웹사이트 모니터링 (신제품 출시, 가격 변동, 시장 변화를 실시간 파악) (GetMonetizely)
- 리드 리스트 고도화 (디렉터리, 이벤트 사이트, 틈새 포털에서 연락처 등 핵심 정보 수집)
딥 크롤링을 쓰면 데이터 양만 느는 게 아니에요. 실제 비즈니스 의사결정에 바로 쓸 수 있는 고품질 데이터를 확보하게 돼요.
경쟁 정보 확보를 위한 딥 스크래핑
예를 들어 영업팀이 신제품을 낸 기업을 타겟팅하고 싶다면, 딥 크롤러가 이걸 해줘요.
- 경쟁사 사이트에서 신제품 페이지 탐색
- 보도자료, 투자자 업데이트 같은 관련 링크 추적
- 주요 정보 추출 (출시일, 가격, 기능 등)
- 이 데이터를 CRM이나 분석 도구로 연동
결국 더 빠르고 똑똑한 의사결정이 가능해지고, 표면 데이터만 보는 경쟁사보다 한발 앞서가게 돼요.
딥 크롤러 사용 시 주의할 점: 준수와 책임
강력한 도구엔 그만한 책임이 따라요. 딥 크롤러로 데이터를 많이 모을 수 있지만, 닥치는 대로 긁는 건 금물이에요. 꼭 기억하세요.
데이터 프라이버시와 저작권
- 웹사이트 이용약관 준수: 많은 사이트가 TOS에 크롤링 허용 범위를 밝혀둬요. 이를 어기면 법적 문제가 생길 수 있어요 (Apify Blog).
- 개인정보나 기밀 데이터는 허가 없이 수집 금지
- 저작권 유의: 모은 콘텐츠를 재배포하거나 팔기 전엔 반드시 권리를 확인하세요.
책임 있는 크롤링
- 요청 속도 조절: 한 번에 너무 많은 요청을 보내 사이트에 부담 주지 마세요.
- robots.txt 확인: 법적 강제력은 없지만, 사이트의 크롤링 정책을 존중하는 게 예의예요.
- 관련 법규 숙지: 개인정보보호법(PIPA), GDPR, CCPA처럼 데이터 수집·활용에 영향을 주는 규정을 늘 확인하세요 (Octoparse).
더 자세한 내용은 2025년 웹 스크래핑 합법성 가이드를 참고하세요.
내 비즈니스에 맞는 딥 크롤러 선택법
Thunderbit 요금제 보기 모든 규모의 팀을 위한 합리적인 딥 크롤링 솔루션. Get Started Free
딥 크롤러를 고를 땐 뭘 봐야 할까요?
- 사용 편의성: 비전문가도 쉽게 쓸 수 있나? (Thunderbit: YES)
- 확장성: 대형 사이트, 수많은 페이지, 동적 콘텐츠도 무리 없이 처리하나?
- 준수 도구: 법적 리스크를 줄여주는 기능이 있나?
- 연동성: Excel, Sheets, Notion, Airtable 같은 기존 업무 도구와 쉽게 붙나?
- 유지보수: 사이트 구조가 바뀌어도 알아서 적응하나, 아니면 매번 스크립트를 고쳐야 하나?
Thunderbit는 이 조건을 다 충족해요. 전 세계 3만 명 이상이 쓰고 있고, 소규모 기업도 월 15달러(약 2만 원)부터 부담 없이 시작할 수 있어요.
핵심 요약: 비즈니스 데이터 전략의 미래, 딥 크롤링
정리하면 이래요.
- 딥 크롤러는 복잡하고 동적인 웹사이트에서 완전하고 정확한 데이터 추출에 필수예요.
- 기존 크롤러와 달리 다층 내비게이션, 동적 콘텐츠, 숨은 데이터까지 다 처리해요.
- 비즈니스팀은 딥 크롤러로 인사이트 확보, 영업·마케팅 강화, 경쟁사 모니터링, 빠른 의사결정을 해내요.
- 준수는 필수: 늘 책임 있게 스크래핑하고, 프라이버시와 규정을 지키세요.
- Thunderbit는 AI 기반, 노코드, 손쉬운 데이터 내보내기로 딥 크롤링을 누구에게나 열어줘요.
이제 표면만 긁는 스크래핑에서 벗어나, Thunderbit 크롬 확장 프로그램을 다운로드해 딥 크롤링의 새로운 세계를 경험해보세요. 더 많은 팁과 가이드는 Thunderbit 블로그에서 확인할 수 있어요.
자주 묻는 질문(FAQ)
1. 딥 크롤러란 무엇이며, 일반 웹 크롤러와 어떻게 다른가요?
딥 크롤러는 웹사이트의 여러 계층을 탐색하며, 하위 페이지, 동적 콘텐츠, 숨은 영역까지 데이터를 추출하는 웹 스크래핑 도구입니다. 기존 크롤러가 표면만 훑는 반면, 딥 크롤러는 링크를 따라가고 복잡한 구조도 완벽하게 수집합니다.
2. 2025년에 기업이 딥 크롤러가 필요한 이유는?
웹사이트가 점점 복잡해지면서, 데이터가 내비게이션, 탭, 동적 요소 뒤에 숨는 경우가 많아졌습니다. 딥 크롤러는 영업, 마케팅, 리서치, 경쟁 정보 분석에서 완전한 데이터셋을 확보하게 해줍니다.
3. Thunderbit는 비전문가도 딥 크롤링을 쉽게 할 수 있게 해주나요?
Thunderbit는 AI로 필드를 추천하고, 하위 페이지 스크래핑과 동적 콘텐츠 처리를 모두 노코드 인터페이스로 제공합니다. 원하는 데이터를 설명하고 '스크래핑'만 누르면 결과를 원하는 도구로 내보낼 수 있습니다.
4. 딥 크롤러 사용 시 어떤 준수 이슈를 고려해야 하나요?
늘 웹사이트 이용약관을 준수하고, 허가 없이 개인정보나 기밀 데이터를 수집하지 마세요. 개인정보보호법(PIPA), GDPR, CCPA 같은 프라이버시 규정도 반드시 확인해야 합니다. 책임 있는 크롤링과 데이터 활용이 중요합니다.
5. 딥 크롤러가 영업·마케팅 성과 향상에 도움이 되나요?
물론입니다. 딥 크롤러는 이커머스, 부동산, 경쟁사 사이트에서 더 풍부하고 실질적인 데이터를 확보해 리드 생성, 시장 분석, 빠른 의사결정에 큰 도움을 줍니다. Thunderbit 같은 도구를 쓰면 비전문가도 쉽게 인사이트를 얻을 수 있습니다.
Thunderbit로 AI 딥 크롤러 체험하기 Get Started Free
더 알아보기




