
The web in 2025 is a wild place—half the traffic you see isn’t even human. That’s right: bots and crawlers now account for over 50% of all internet activity (), and only a fraction of those are the “good” bots you want: search engines, social media previewers, and analytics helpers. The rest? Well, let’s just say they’re not always here to help. As someone who’s spent years building automation and AI tools at , I’ve seen firsthand how the right (or wrong) crawler can make or break your SEO, skew your analytics, drain your bandwidth, or even trigger a full-blown security incident.
If you’re running a business, managing a website, or just trying to keep your digital house in order, knowing who’s knocking on your server’s door is more important than ever. That’s why I’ve put together this 2025 guide to the most important crawlers—what they do, how to spot them, and how to keep your site open to the good bots while keeping the bad ones at bay.
What Makes a Crawler “Known”? User-Agent, IPs, and Verification
Let’s start with the basics: what exactly is a “known” crawler? In the simplest terms, it’s a bot that identifies itself with a consistent user-agent string (like Googlebot/2.1 or bingbot/2.0) and, ideally, crawls from published IP ranges or ASN blocks that you can verify (). The big players—Google, Microsoft, Baidu, Yandex, DuckDuckGo—publish documentation about their bots and, in many cases, provide tools or JSON files listing their official IPs (, , ).
But here’s the catch: relying on user-agent alone is risky. Spoofing is rampant—malicious bots often pretend to be Googlebot or Bingbot just to sneak past your defenses (). That’s why the gold standard is dual verification: check both the user-agent and the IP address (or ASN), using reverse DNS lookups or published lists. If you’re using a tool like , you can automate this process—extracting logs, matching user-agents, and cross-referencing IPs to build a real-time, trustworthy list of who’s crawling your site.
How to Use This List of Crawlers
So, what do you actually do with a list of known crawlers? Here’s how I recommend putting it to work:
- Allowlisting: Make sure the bots you want (search engines, social media previewers) are never accidentally blocked by your firewall, CDN, or WAF. Use their official IPs and user-agents for precise allowlisting.
- Analytics Filtering: Filter out bot traffic from your analytics so your numbers reflect real human visitors—not just Googlebot and AhrefsBot doing laps around your site ().
- Bot Management: Set crawl-delay or throttling rules for aggressive SEO tools, and block or challenge unknown or malicious bots.
- Automated Log Analysis: Use AI tools (like Thunderbit) to extract, classify, and label crawler activity in your logs, so you can spot trends, identify imposters, and keep your policies up to date.
Keeping your crawler list current isn’t a “set it and forget it” task. New bots pop up, old ones change behavior, and attackers get sneakier every year. Automating updates—by scraping official docs or GitHub repos with Thunderbit—can save you hours and headaches.
1. Thunderbit: AI-Powered Crawler Identification and Data Management
isn’t just an AI Web Scraper—it’s a data assistant for teams who want to understand and manage crawler traffic. Here’s what sets Thunderbit apart:

- Semantic Pre-Processing: Before extracting data, Thunderbit converts web pages and logs into Markdown-style structured content. This “semantic-level” pre-processing means the AI can actually understand the context, fields, and logic of what it’s reading. It’s a lifesaver on complex, dynamic, or JavaScript-heavy pages (think Facebook Marketplace or long comment threads) where traditional DOM-based scrapers fall flat.
- Dual Verification: Thunderbit can quickly gather official crawler IP docs and ASN lists, then match them against your server logs. The result? A “trusted crawler allowlist” you can actually rely on—no more manual cross-checking.
- Automated Log Extraction: Feed Thunderbit your raw logs, and it’ll turn them into structured tables (Excel, Sheets, Airtable), labeling high-frequency visitors, suspicious paths, and known bots. From there, you can pipe the results into your WAF or CDN for automated blocking, throttling, or CAPTCHA challenges.
- Compliance and Audit: Thunderbit’s semantic extraction keeps a clear audit trail—who accessed what, when, and how you handled it. That’s a huge help for GDPR, CCPA, and other compliance needs.
I’ve seen teams use Thunderbit to cut their crawler management workload by 80%—and finally get a handle on which bots are helping, which are hurting, and which are just faking it.
2. Googlebot: The Search Engine Standard
is the gold standard for web crawlers. It’s responsible for indexing your site for Google Search—block it, and you might as well hang a “Closed” sign on your digital storefront.
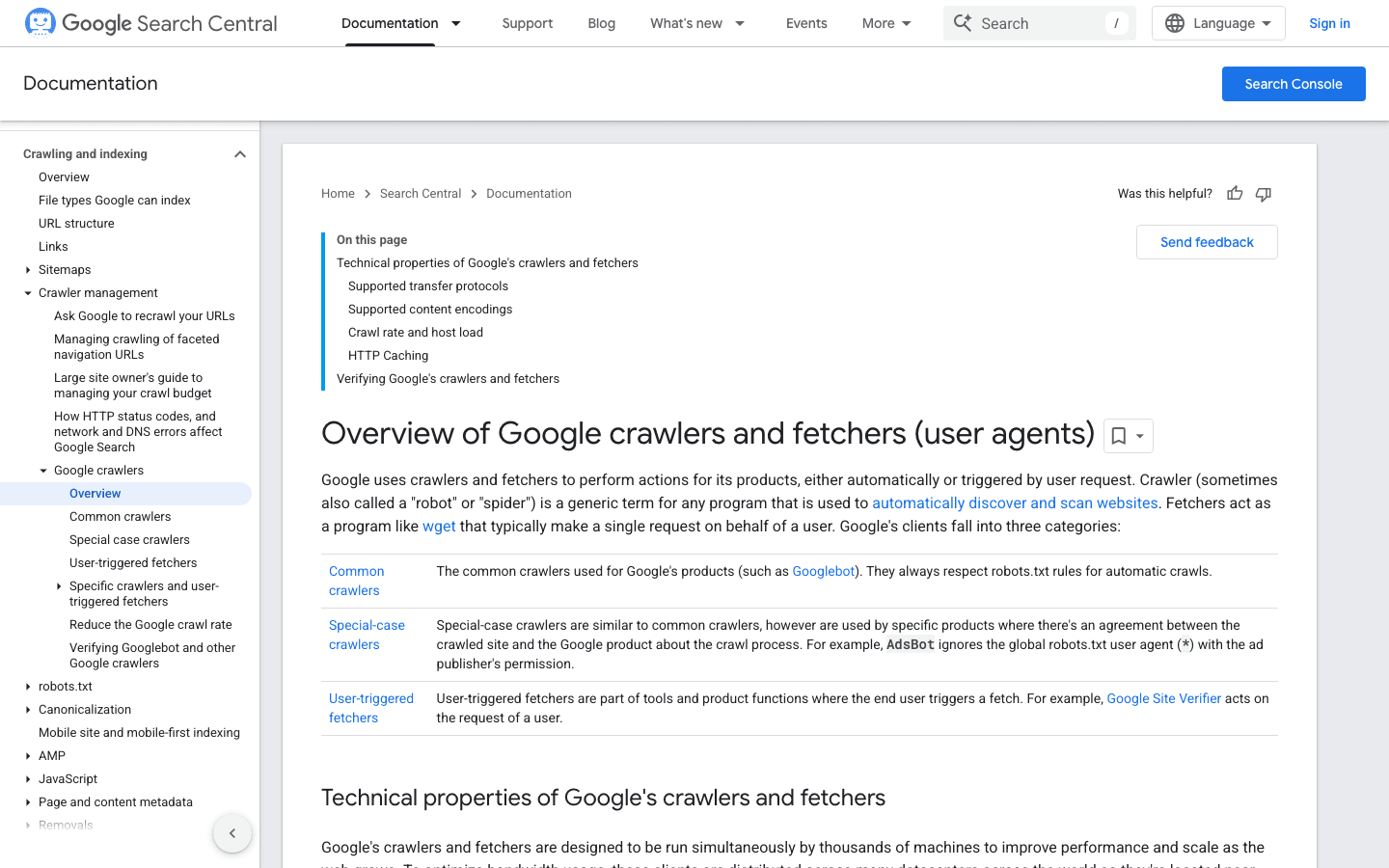
- User-Agent:
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) - Verification: Use or the .
- Management Tips: Always allow Googlebot. Use robots.txt to guide (not block) its crawling, and adjust crawl rate in Google Search Console if needed.
3. Bingbot: Microsoft’s Web Explorer
powers Bing and Yahoo search results. It’s the second most important crawler for most sites.
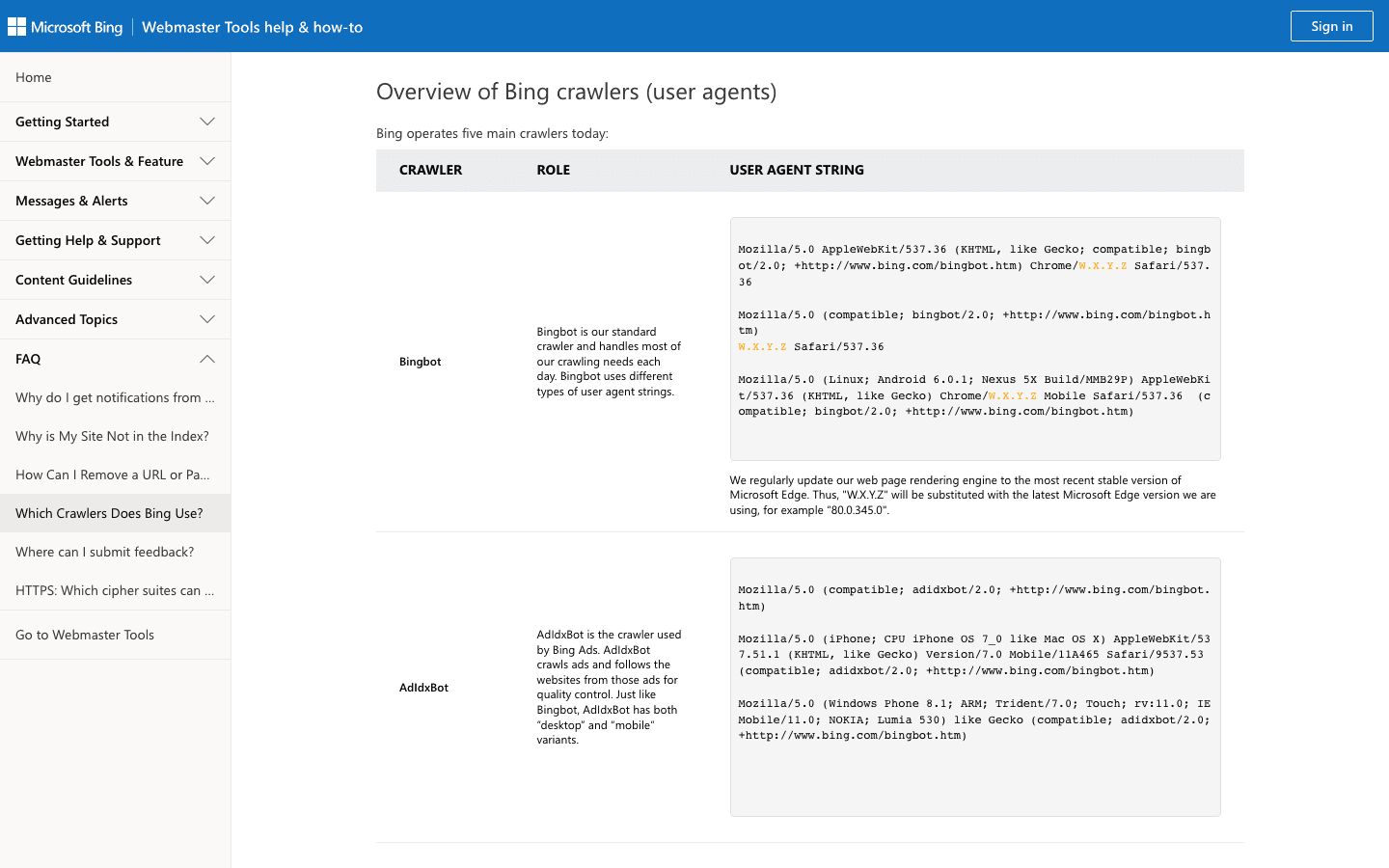
- User-Agent:
Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) - Verification: Use and .
- Management Tips: Allow Bingbot, manage crawl rate in Bing Webmaster Tools, and use robots.txt for fine-tuning.
4. Baiduspider: China’s Leading Search Crawler
is the gateway to Chinese search traffic.
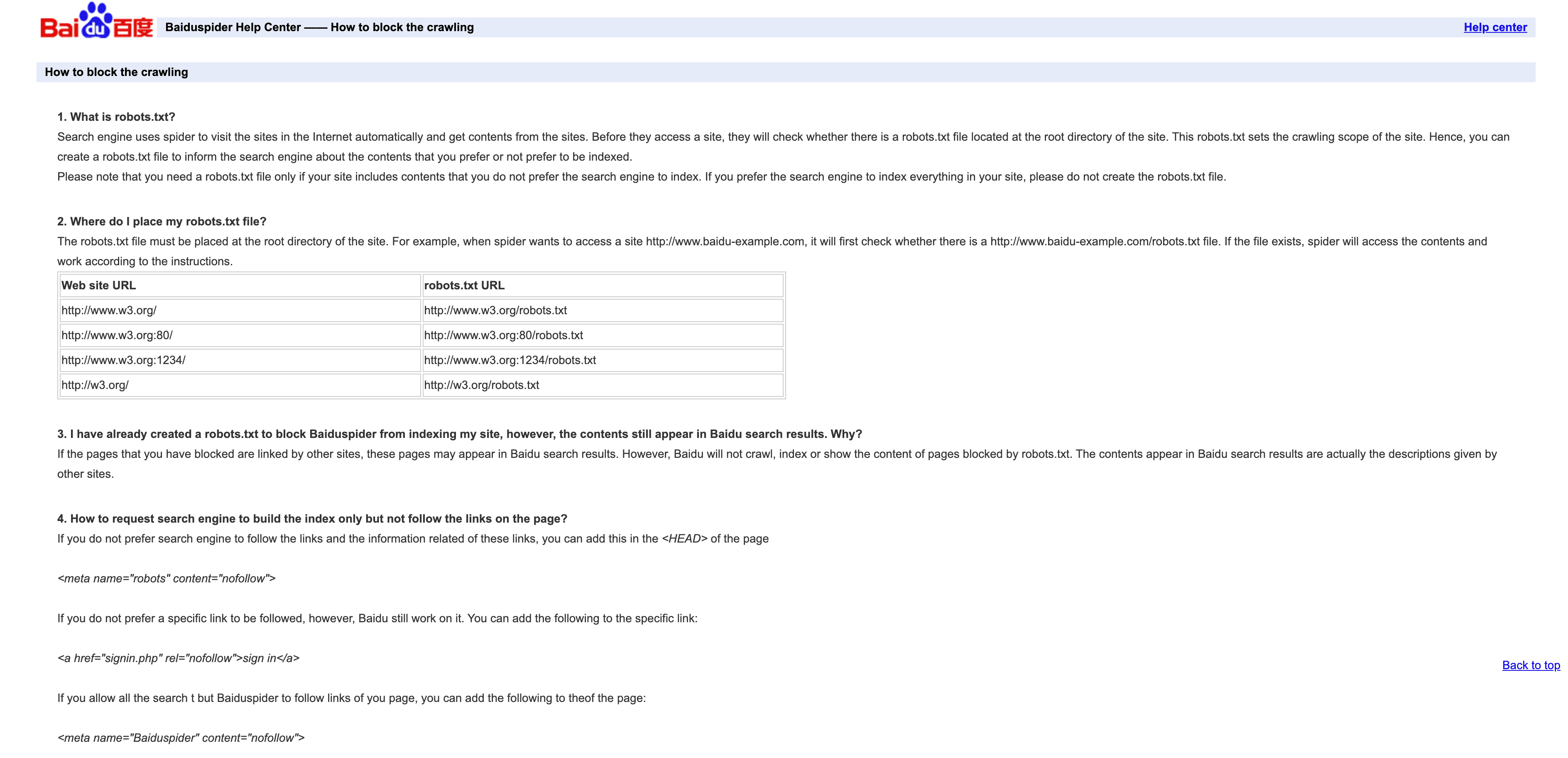
- User-Agent:
Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html) - Verification: No official IP list; check for
.baidu.comin reverse DNS, but be aware of limitations. - Management Tips: Allow if you want Chinese traffic. Use robots.txt to set rules, but note Baiduspider sometimes ignores them. If you don’t need Chinese SEO, consider throttling or blocking to save bandwidth.
5. YandexBot: Russia’s Search Engine Crawler
is essential for Russian and CIS markets.
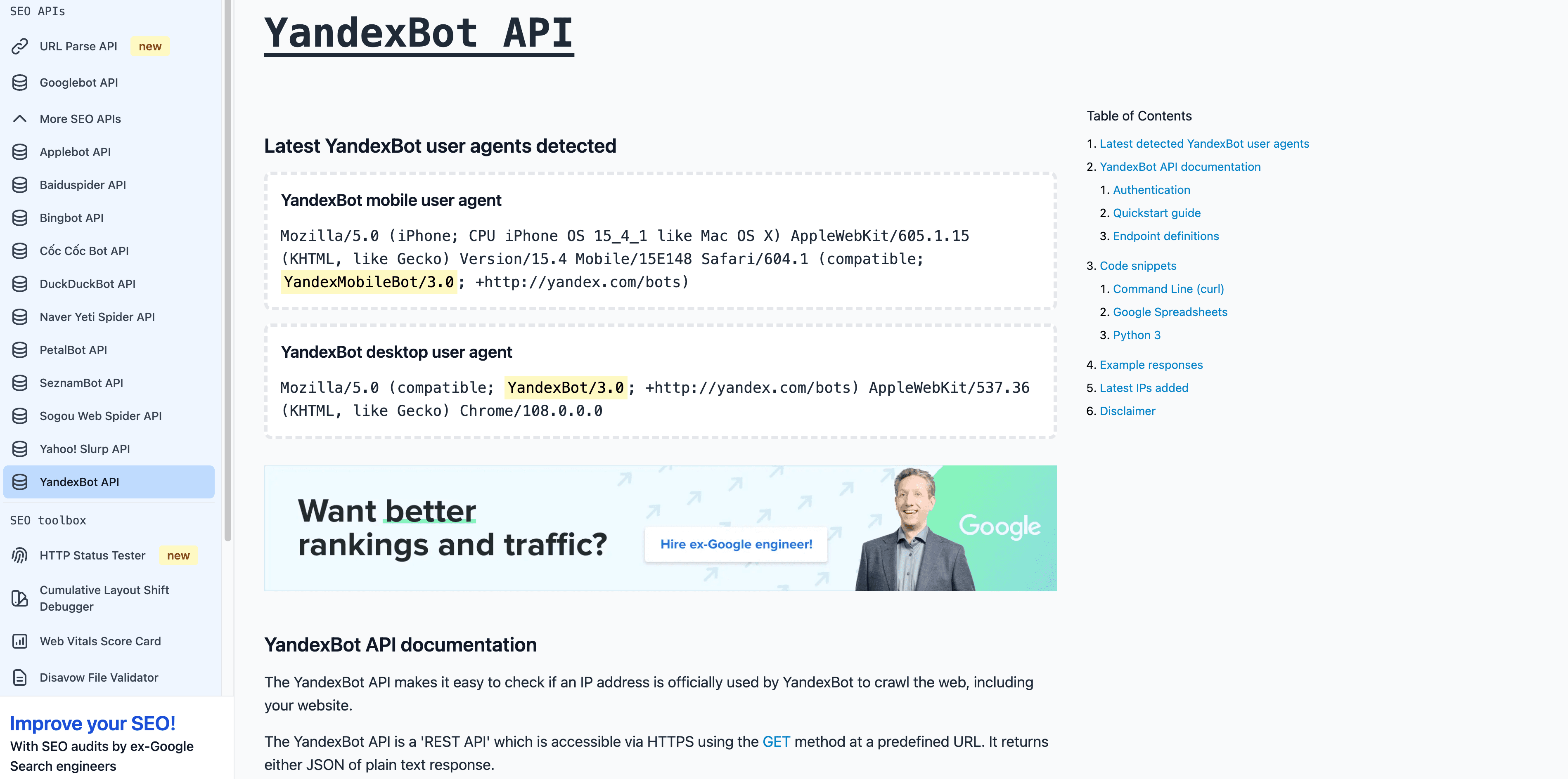
- User-Agent:
Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) - Verification: Reverse DNS should end in
.yandex.ru,.yandex.net, or.yandex.com. - Management Tips: Allow if targeting Russian-speaking users. Use Yandex Webmaster for crawl control.
6. DuckDuckBot: Privacy-Focused Search Crawler
powers DuckDuckGo’s privacy-centric search.
- User-Agent:
DuckDuckBot/1.1; (+http://duckduckgo.com/duckduckbot.html) - Verification: .
- Management Tips: Allow unless you have zero interest in privacy-focused users. Low crawl load, easy to manage.
7. AhrefsBot: SEO and Backlink Analysis
is a top SEO tool crawler—great for backlink analysis, but can be bandwidth-heavy.
- User-Agent:
Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/) - Verification: No public IP list; verify by UA and reverse DNS.
- Management Tips: Allow if you use Ahrefs. Use robots.txt for crawl-delay or blocking. You can .
8. SemrushBot: Competitive SEO Insights
is another major SEO crawler.
- User-Agent:
Mozilla/5.0 (compatible; SemrushBot/1.0; +http://www.semrush.com/bot.html)(plus variants likeSemrushBot-BA,SemrushBot-SI, etc.) - Verification: By user-agent; no public IP list.
- Management Tips: Allow if you use Semrush, otherwise throttle or block with robots.txt or server rules.
9. FacebookExternalHit: Social Media Preview Bot
fetches Open Graph data for Facebook and Instagram link previews.
- User-Agent:
facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php) - Verification: By user-agent; IPs belong to Facebook’s ASN.
- Management Tips: Allow for rich social previews. Blocking means no thumbnails or summaries on Facebook/Instagram.
10. Twitterbot: X (Twitter) Link Preview Crawler
fetches Twitter Card data for X (Twitter).
- User-Agent:
Twitterbot/1.0 - Verification: By user-agent; Twitter ASN (AS13414).
- Management Tips: Allow for Twitter previews. Use Twitter Card meta tags for best results.
Compare Table: List of Crawlers at a Glance
| Crawler | Purpose | User-Agent Example | Verification Method | Business Impact | Management Tips |
|---|---|---|---|---|---|
| Thunderbit | AI log/crawler analysis | N/A (tool, not a bot) | N/A | Data management, bot classification | Use for log extraction, allowlist building |
| Googlebot | Google Search indexing | Googlebot/2.1 | DNS & IP list | Critical for SEO | Always allow, manage via Search Console |
| Bingbot | Bing/Yahoo Search | bingbot/2.0 | DNS & IP list | Important for Bing/Yahoo SEO | Allow, manage via Bing Webmaster Tools |
| Baiduspider | Baidu Search (China) | Baiduspider/2.0 | Reverse DNS, UA string | Key for China SEO | Allow if targeting China, monitor bandwidth |
| YandexBot | Yandex Search (Russia) | YandexBot/3.0 | Reverse DNS to .yandex.ru | Key for Russia/Eastern Europe | Allow if targeting RU/CIS, use Yandex tools |
| DuckDuckBot | DuckDuckGo Search | DuckDuckBot/1.1 | Official IP list | Privacy-focused audience | Allow, low impact |
| AhrefsBot | SEO/backlink analysis | AhrefsBot/7.0 | UA string, reverse DNS | SEO tool, can be bandwidth-heavy | Allow/throttle/block via robots.txt |
| SemrushBot | SEO/competitive analysis | SemrushBot/1.0 (plus variants) | UA string | SEO tool, can be aggressive | Allow/throttle/block via robots.txt |
| FacebookExternalHit | Social link previews | facebookexternalhit/1.1 | UA string, Facebook ASN | Social media engagement | Allow for previews, use OG tags |
| Twitterbot | Twitter link previews | Twitterbot/1.0 | UA string, Twitter ASN | Twitter engagement | Allow for previews, use Twitter Card tags |
Managing Your List of Crawlers: Best Practices for 2025
- Update Regularly: The crawler landscape changes fast. Schedule quarterly reviews, and use tools like Thunderbit to scrape and compare official lists ().
- Verify, Don’t Trust: Always check both user-agent and IP/ASN. Don’t let imposters sneak in and skew your analytics or scrape your data ().
- Allowlist Good Bots: Make sure search and social crawlers are never blocked by anti-bot rules or firewalls.
- Throttle or Block Aggressive Bots: Use robots.txt, crawl-delay, or server rules for SEO tools that hit too hard.
- Automate Log Analysis: Use AI-powered tools (like Thunderbit) to extract, classify, and label crawler activity—saving you time and catching trends you might miss.
- Balance SEO, Analytics, and Security: Don’t block the bots that drive your business, but don’t let the bad ones run wild.
Conclusion: Keeping Your Crawler List Up-to-Date and Actionable
In 2025, managing your list of crawlers isn’t just an IT chore—it’s a business-critical task that touches SEO, analytics, security, and compliance. With bots now making up the majority of web traffic, you need to know who’s visiting, why, and what to do about it. Keep your list current, automate where you can, and use tools like to stay ahead of the curve. The web’s only getting busier—and a smart, actionable crawler strategy is your best defense (and offense) in the bot-powered world.
FAQs
1. Why is it important to maintain an up-to-date list of crawlers?
Because bots now account for over half of all web traffic, and only a small portion are beneficial. Keeping your list current ensures you allow the good bots (for SEO and social previews) and block or throttle the bad ones, protecting your analytics, bandwidth, and data security.
2. How can I tell if a crawler is genuine or a fake?
Don’t trust user-agent alone—always verify the IP address or ASN using official lists or reverse DNS lookups. Tools like Thunderbit can automate this process by matching logs against published bot IPs and user-agents.
3. What should I do if an unknown bot is crawling my site?
Investigate the user-agent and IP. If it’s not on your allowlist and doesn’t match a known bot, consider throttling, challenging, or blocking it. Use AI tools to classify and monitor new crawlers as they appear.
4. How does Thunderbit help with crawler management?
Thunderbit uses AI to extract, structure, and classify crawler activity from logs, making it easy to build allowlists, spot imposters, and automate policy enforcement. Its semantic pre-processing is especially robust for complex or dynamic sites.
5. What’s the risk of blocking a major crawler like Googlebot or Bingbot?
Blocking search engine crawlers can remove your site from search results, killing your organic traffic. Always double-check your firewall, robots.txt, and anti-bot rules to ensure you’re not accidentally shutting out the bots that matter most.
Learn More: