
先週、あるユーザーから「SuperPagesのプラマー一覧をスプレッドシートに手作業で3時間かけて47件も打ち込んだ」と聞きました。手首は痛くなるし、データには টাইポが入り、しかもメールアドレスはまだ取れていない。まさにそんな話でした。私自身も同じような苦労をしてきたので、この手の悩みを解決するためにを作ったんです。
SuperPagesは、Thryvが運営する米国向けの老舗ローカルビジネスディレクトリのひとつです。主要都市や幅広い業種をカバーしており、配管業者、歯科医院、弁護士、HVAC業者など、さまざまな事業者を見つけられます。古い技術資料では、1,100万件以上の掲載情報を持つ全国規模のイエローページデータベースとして紹介されていました。今でもサイト上では、密度の高いローカルカテゴリを検索できます。難しいのは一覧を見つけることではありません。それをきれいに整理し、情報を補完した見込み顧客リストへ変換することです。しかも、気が遠くなることなく、午後を丸ごと失わずに済む形で。
HubSpotの2024年Sales Trendsレポートによると、営業担当者が実際に販売活動に使える時間は1日あたり約2時間しかなく、残りはデータ入力やリサーチに消えていきます。また、営業のプロの81%が、AIは手作業を減らす助けになると答えています。このガイドでは、SuperPagesから見込み顧客を抽出する3つの方法を紹介します。ノーコードのAIからPythonまで、あなたのスキルに合った方法を選び、売上につながる仕事にすぐ戻れるようにしましょう。
SuperPagesとは?営業チームが見込み顧客探しに使う理由
SuperPagesは、米国のローカルビジネスを中心に掲載するオンラインディレクトリです。企業名、連絡先、カテゴリ、評価などがまとめて載っており、昔ながらの電話帳のデジタル版のような存在です。しかも今は、カテゴリや地域で検索でき、1件あたりの情報量も豊富です。
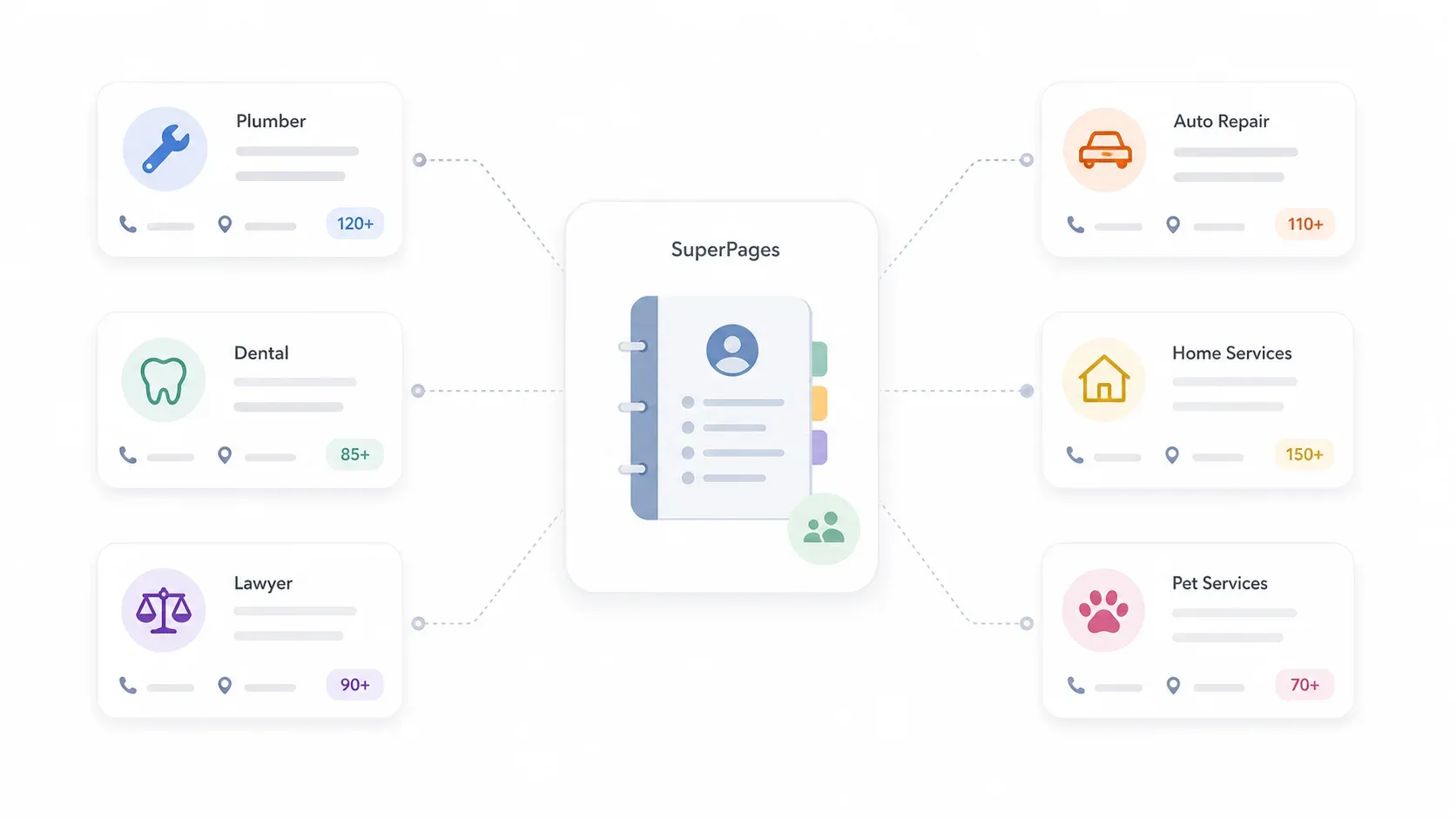
SuperPagesの一般的な掲載情報には、次のような項目が含まれます。
- 事業者名
- 電話番号
- 住所
- WebサイトURL(ある場合)
- カテゴリ(例:配管、家族法、HVAC)
- 評価とレビュー
- 営業時間(通常は詳細ページ)
- 説明文(詳細ページ)
SuperPagesのトップページでは、Home Services、Plumbers、Electricians、Dentists、Legal Services、Auto Repair、Restaurants、Pet Servicesといった人気カテゴリが目立ちます。実はこれらは、営業チーム、代理店、地域向けサービス事業者がアウトバウンド営業で狙う業種そのものです。
要するに、SuperPagesは米国のローカル事業者を探すうえで非常に有力な情報源です。データは構造化されていて範囲も広く、実際の営業施策にそのまま落とし込みやすいのが魅力です。
なぜSuperPagesをスクレイピングして見込み顧客を取るのか?主な活用例
SuperPagesを手で見て、データをスプレッドシートにコピペするのは、生産性を食い尽くす作業です。スクレイピングなら、その流れを自動化でき、何時間もかかる作業を数分でターゲット化された構造データに変えられます。さらに、検索条件を自分で決められるので(カテゴリ+都市+キーワード)、市販の一般的なリードリストよりも関連性の高い結果になりやすいのも利点です。
ユーザーから特によく聞く活用例は次のとおりです。
| 活用例 | 恩恵を受ける人 | 例 |
|---|---|---|
| 地域リード獲得 | 営業チーム、代理店 | ダラスの配管業者リストを作ってコールドアウトリーチする |
| 競合調査 | オペレーション、マーケティング | 競合各社の評価やサービス内容を比較する |
| 市場マッピング | 事業開発 | 新製品投入向けに、郵便番号単位で歯科医院を洗い出す |
| 仕入先探索 | 購買、オペレーション | ある地域のサプライヤーを電話番号+Webサイト付きで探す |
| ローカルSEOの営業開拓 | 代理店 | Webサイトを持たない、または掲載情報が弱い事業者を見つける |
| 営業エリア設計 | フィールドセールス | 施工業者を都市、郵便番号、サービスエリアごとに分類する |
米国のB2Bリードジェネレーション市場は2024年に85億ドル規模と推定され、2034年には182億ドルに達すると見込まれています。つまり、この種のデータ需要は今後も続くということです。カテゴリと地域を絞って新しく抽出したリストは、一般的な購入リストよりもターゲット精度が高い場合があります。ただし、実際の営業前には検証と重複排除が必要です(その点は後ほど説明します)。
最終的な出力イメージ:SuperPagesから抽出したサンプルデータ
方法の説明に入る前に、最終的にどんなデータが手元に残るのかを見せておきます。多くのガイドはこの部分を飛ばしますが、時間を使うなら、どんな成果物になるのか知っておくべきです。
以下はサンプル出力です(架空データですが、実際の形式に近いものです)。
| 事業者名 | 電話 | 住所 | Webサイト | カテゴリ | 評価 | 営業時間 | メールアドレス(補完後) |
|---|---|---|---|---|---|---|---|
| Sunset Pipe & Drain Co. | +1 213-555-0148 | 1842 W 7th St, Los Angeles, CA 90057 | sunsetpipe.example | Plumbing | 4.6 | Mon-Fri 7a-6p | service@sunsetpipe.example |
| Arroyo HVAC Pros | +1 626-555-0182 | 72 N Fair Oaks Ave, Pasadena, CA 91103 | arroyohvac.example | HVAC | 4.8 | Mon-Sat 8a-7p | hello@arroyohvac.example |
| Wilshire Family Dental | +1 323-555-0119 | 4100 Wilshire Blvd, Los Angeles, CA 90010 | wilshiredental.example | Dentists | 4.4 | Mon-Thu 9a-5p | appointments@wilshiredental.example |
| Pacific Legal Aid Group | +1 310-555-0173 | 11845 W Olympic Blvd, Los Angeles, CA 90064 | Legal Services | 4.2 | Mon-Fri 8:30a-5:30p | intake@pacificlegal.example | |
| Valley Auto Repair Center | +1 818-555-0198 | 14422 Ventura Blvd, Sherman Oaks, CA 91423 | valleyautorepair.example | Auto Repair | 4.7 | Mon-Sat 8a-6p | info@valleyautorepair.example |
| Echo Park Pet Grooming | +1 213-555-0166 | 1511 Sunset Blvd, Los Angeles, CA 90026 | echoparkpets.example | Pet Grooming | 4.9 | Tue-Sun 9a-5p | booking@echoparkpets.example |
ここで押さえておきたい点は次のとおりです。
- 検索結果ページから取得できるもの:事業者名、電話番号、途中までの住所、カテゴリ、評価、掲載URL
- 事業者詳細ページ(サブページ)から取得できるもの:完全な住所、営業時間、説明文、レビュー、場合によってはWebサイト
- 補完で加えられるもの:メールアドレス(多くは事業者自身のサイト、または補完ツールで取得)
- クレンジングで整えるもの:電話番号のE.164形式、州/郵便番号の正規化、重複排除キー、元URL、スクレイプ日時
このような出力があれば、CRM、Google Sheets、Airtableにそのまま入れて、すぐに活用できます。
SuperPagesを見込み顧客抽出する3つの方法:簡単比較

技術的な慣れや、作業に使える忍耐力は人それぞれです。そこで、選びやすいように3つの方法を並べて比較します。
| 比較項目 | Thunderbit(AIノーコード) | ビジュアルスクレイパー(例:Octoparse) | Python(Requests + BS4) |
|---|---|---|---|
| 初期設定時間 | 約2分(拡張機能を入れるだけ) | 約15分(ワークフロー作成) | 約30分(ライブラリ導入+コーディング) |
| コーディングの必要性 | なし | なし | あり(Python) |
| ページ送り対応 | 標準搭載(クリック/スクロール) | 設定が必要 | 手動で実装 |
| サブページ補完 | 1クリックでサブページスクレイピング | 別ワークフロー/ループが必要 | 別スクリプトが必要 |
| ブロック対策 | Cloud Scrapingが処理 | プランやプロキシ追加に依存 | 自前対応(プロキシ、ヘッダー、レート制限) |
| 出力形式 | Excel、Google Sheets、Airtable、Notion、CSV、JSON | CSV、Excel、データベース | コード次第 |
| 向いている人 | 営業、代理店、非エンジニア | やや技術寄りのユーザー | 自由度を重視する開発者 |
私のおすすめは、今すぐ2分以内に始めたいなら方法1、見た目で操作したいが多少の設定は気にしないなら方法2、完全な自由度が必要でPythonに慣れているなら方法3です。
方法1:ThunderbitでSuperPagesを抽出する(AI、ノーコード)
これは、「SuperPagesで検索した」状態から「見込み顧客リストができた」状態へ最短で進む方法です。コーディング不要、ワークフロー作成不要、プロキシ設定も不要。私たちはThunderbitを作った側なので少し肩入れしていますが、何が起きるのかを正確にお伝えするので、ぜひ自分で判断してください。
難易度:初級
所要時間:カテゴリ/都市単位の抽出で約5分
必要なもの:Chromeブラウザ、Thunderbit Chrome拡張機能(無料枠あり)
ステップ1:Thunderbitを入れてSuperPagesを開く
にアクセスして、Thunderbit拡張機能をインストールします。1分ほどで完了します。インストール後、SuperPagesの検索結果ページへ移動してください。たとえば superpages.com で「Plumbers in Los Angeles, CA」を検索します。
ブラウザのツールバーにThunderbitのアイコンが表示され、サイドバーが使える状態になっているはずです。
ステップ2:「AI Suggest Fields」をクリックして列を自動判別する
Thunderbitのサイドバーを開き、「AI Suggest Fields」をクリックします。ThunderbitのAIがページ内容を読み取り、見つかった情報をもとに列を自動提案します。一般的には、事業者名、電話番号、住所、Webサイト、カテゴリ、評価、掲載URLなどが候補になります。
抽出前に、列の追加・削除・調整ができます。「Webサイトの有無」や「サービスエリア」のようなカスタム列も追加したい場合は、Field AI Promptに自然文で指示するだけです。たとえば、「電話番号を +1XXXXXXXXXX 形式に整える」や「住宅向けか法人向けかを分類する」といった指示ができます。
ここまでで、Thunderbitのパネル内に列設定済みの表プレビューが見えているはずです。
ステップ3:「Scrape」を押してデータを取得する
青い「Scrape」ボタンを押します。Thunderbitが現在ページ上の一覧をすべて抽出し、行ごとに表へ埋めていきます。一般的なSuperPagesの結果ページなら、30〜45秒ほどで完了します。
Thunderbitはページ送りも自動で処理します。「Next」ボタンや無限スクロールを検出し、ページがなくなるか上限に達するまで続けます。大量の結果(たとえば都市圏全体の配管業者)を抽出する場合は、Cloud Scrapingモードに切り替えると、ブラウザを占有せずに最大50ページまで同時処理できます。
ステップ4:サブページスクレイピングで各掲載情報を補完する
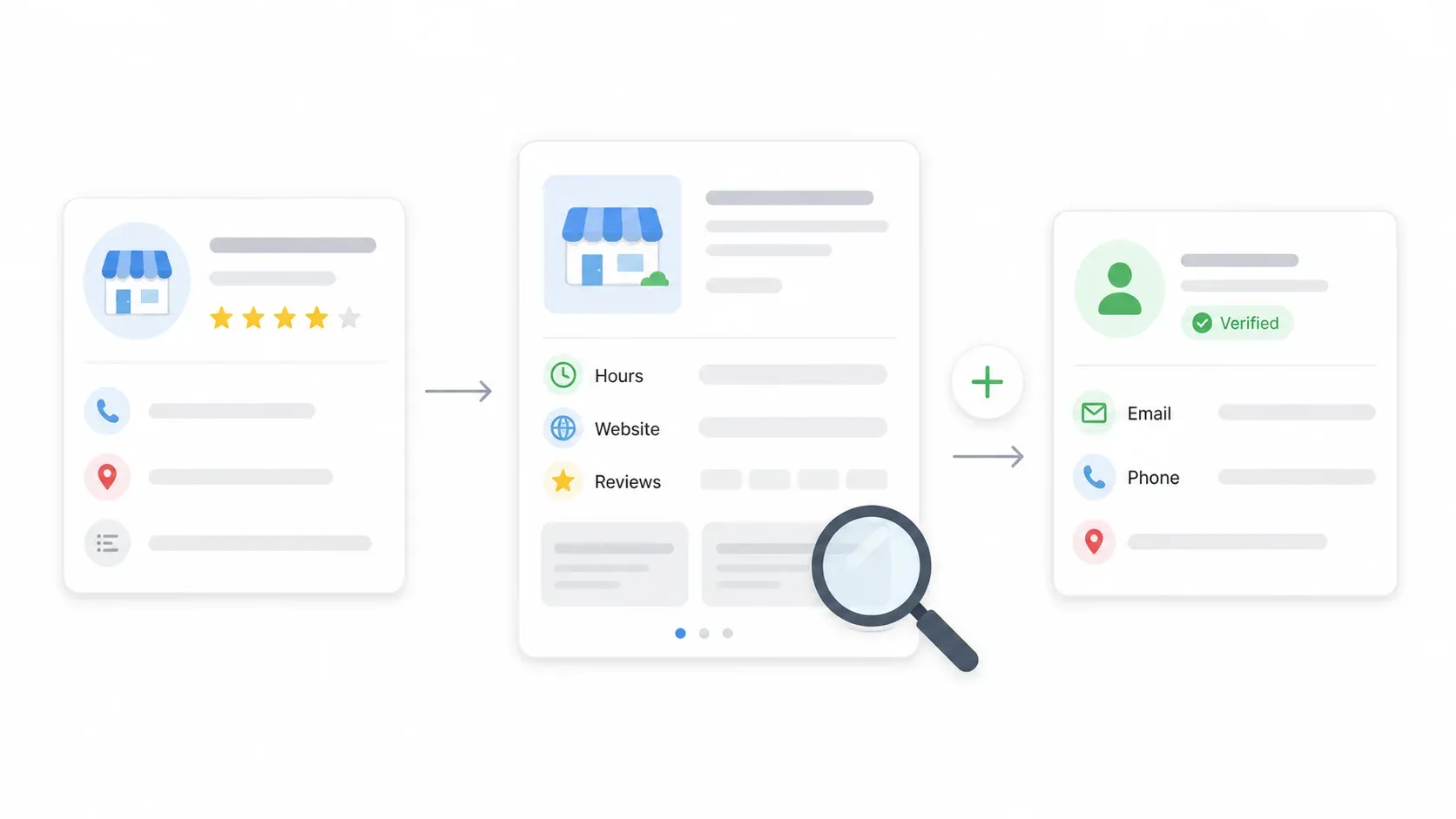
検索結果ページで取れるのは基本情報ですが、本当に価値があるのは詳細ページにあります。営業時間、詳細な説明、レビュー、場合によってはメールアドレスなどです。「Scrape Subpages」をクリックすると、Thunderbitが各掲載の詳細ページを巡回し、営業時間、説明文、WebサイトURL、ページ上で見える連絡先情報などを補完列として取得します。
これはワンクリックで完了します。別ワークフローも設定不要です。補完されたデータは、既存の表にそのまま追加されます。
ステップ5:Excel、Google Sheets、Airtable、Notionへ書き出す
データに満足したら、Exportをクリックします。Thunderbitでは、以下に直接エクスポートできます。
- Google Sheets(CRM準備や共有に便利)
- Airtable(軽量な管理表に向く)
- Notion(リサーチ用データベース)
- Excel / CSV(CRM取り込み用)
- JSON(開発者向け)
すべてのエクスポート形式は無料です。HubSpotやSalesforceに見込み顧客を流し込むなら、CSVまたはGoogle Sheetsが最短ルートです。
ワンポイント:州全体の広い検索よりも、カテゴリ+都市で絞るほうが良い結果になります。たとえば「emergency plumbers Dallas TX」のほうが「plumbers Texas」より、ずっと精度が高く使いやすいリストになります。さらに、「Source URL」と「Scraped At」列を加えておくと、後で追跡しやすくなります。
方法2:ビジュアルスクレイピングツールでSuperPagesを抽出する(Octoparseの例)
Octoparseのようなビジュアルスクレイパーは、ThunderbitとPythonの中間にある選択肢です。コーディング不要ですが、Thunderbitよりは設定が必要です。Octoparseには、簡単な用途向けにSuperPagesのテンプレートも用意されています。
難易度:中級
所要時間:設定+抽出で約20〜30分
必要なもの:Octoparseアカウント(無料プランあり、制限あり)
ステップ1:新しいタスクを作ってSuperPagesのURLを読み込む
Octoparseを開き、「New Task」をクリックして、SuperPagesの検索URLを貼り付けます(例:「https://www.superpages.com/los-angeles-ca/plumbers」)。内蔵ブラウザでページが読み込まれます。
ステップ2:データ項目を自動検出するか、手動で選ぶ
「Auto-detect」をクリックすると、Octoparseがページを解析し、関連がありそうなデータ項目をハイライトします。Data Previewパネルで確認しましょう。私の経験では、自動検出は多くの項目を拾ってくれますが、広告ラベルやナビゲーション文字まで拾ってしまうことがあり、逆に一部の項目を見落とすこともあります。そのため、いくつかの項目は手動で追加・削除することになるでしょう。
Octoparseのヘルプによると、自動検出ではページ送りとデータ抽出を含む基本的なワークフローが作られますが、足りないデータはユーザーが手動で補う必要があります。
ステップ3:ワークフローを作成し、ページ送りを設定する
「Create workflow」をクリックすると、Octoparseが手順付きのアクション列を生成します。ページ送りのステップを確認し、「Next」を正しくクリックするか、追加結果を取得できているかをチェックしてください。各事業者の詳細ページ(営業時間、メール、説明文)も取りたい場合は、ワークフロー内に詳細ページループやサブページ処理を追加する必要があります。ここはThunderbitのワンクリック補完より少し複雑です。
ステップ4:タスクを実行してデータを書き出す
小規模ならローカルで実行し、大規模や定期実行ならOctoparseのクラウドで実行します(クラウドは有料機能です)。完了したら、CSV、Excel、JSON形式でエクスポートします。
知っておきたい制限:Octoparseの無料プランには、10タスク、月50,000行まで、ローカル抽出のみという制約があります。クラウド実行、IPローテーション、CAPTCHA対応、一部の連携機能には有料プランが必要です(年払いで月額約69ドルから)。
方法3:PythonでSuperPagesを抽出する(Requests + BeautifulSoup)
これは開発者向けの方法です。自由度は最大ですが、その分すべて自分で責任を持つ必要があります。Pythonスクリプトの作成と保守に慣れているなら、柔軟性は最も高い一方で、手間も最も多くなります。
難易度:上級
所要時間:約30〜60分(セットアップ+コーディング+デバッグ)
必要なもの:Python 3.x、pip、requests、beautifulsoup4、lxml、コードエディタ
ステップ1:Python環境を整える
1python -m venv .venv
2source .venv/bin/activate
3pip install requests beautifulsoup4 lxml pandasステップ2:SuperPagesのHTML構造を確認する
SuperPagesの検索結果ページで開発者ツール(F12)を開きます。事業者名、住所、電話番号、Webサイト、詳細ページリンクのCSSセレクタを特定してください。なお、HTML構造は予告なく変わることがあり、その場合セレクタが壊れる可能性があります。
ステップ3:一覧取得スクリプトを書き、ページ送りに対応する
以下は簡略版です。重要な注意点として、私のテストではSuperPagesへの直接リクエストでCloudflareの「Attention Required」ブロックページが返されました。単純なRequestsスクリプトは大規模運用で失敗する可能性があるため、ブラウザセッションの文脈、レート制限、リトライ、または正規の代替手段が必要になることがあります。
1import csv, time
2from urllib.parse import urljoin
3import requests
4from bs4 import BeautifulSoup
5BASE_URL = "https://www.superpages.com"
6HEADERS = {
7 "User-Agent": (
8 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
9 "AppleWebKit/537.36 (KHTML, like Gecko) "
10 "Chrome/125.0 Safari/537.36"
11 )
12}
13def fetch(url):
14 resp = requests.get(url, headers=HEADERS, timeout=20)
15 resp.raise_for_status()
16 if "Attention Required" in resp.text or "Cloudflare" in resp.text:
17 raise RuntimeError("Blocked. Slow down or switch to browser/cloud scraping.")
18 return BeautifulSoup(resp.text, "lxml")
19def parse_listing(card):
20 name_el = card.select_one(".business-name, a.business-name, h2 a, h3 a")
21 phone_el = card.select_one(".phones, .phone, [class*=phone]")
22 address_el = card.select_one(".street-address, .adr, [class*=address]")
23 website_el = card.select_one("a.track-visit-website, a[href*='http']")
24 rating_el = card.select_one(".rating, [class*=rating]")
25 detail_url = urljoin(BASE_URL, name_el.get("href")) if name_el and name_el.get("href") else ""
26 return {
27 "business_name": name_el.get_text(" ", strip=True) if name_el else "",
28 "phone": phone_el.get_text(" ", strip=True) if phone_el else "",
29 "address": address_el.get_text(" ", strip=True) if address_el else "",
30 "website": website_el.get("href", "") if website_el else "",
31 "rating": rating_el.get_text(" ", strip=True) if rating_el else "",
32 "detail_url": detail_url,
33 }
34def scrape_search(search_url, pages=3):
35 all_rows = []
36 for page in range(1, pages + 1):
37 page_url = f"\{search_url\}?page=\{page\}"
38 soup = fetch(page_url)
39 cards = soup.select(".result, .organic, [class*=result]")
40 if not cards:
41 break
42 for card in cards:
43 all_rows.append(parse_listing(card))
44 time.sleep(5)
45 return all_rows
46if __name__ == "__main__":
47 rows = scrape_search("https://www.superpages.com/los-angeles-ca/plumbers", pages=2)
48 with open("superpages_leads.csv", "w", newline="", encoding="utf-8") as f:
49 writer = csv.DictWriter(f, fieldnames=sorted({k for row in rows for k in row}))
50 writer.writeheader()
51 writer.writerows(rows)ステップ4:詳細ページを巡回して情報を補完する
各詳細ページURLを訪問し、営業時間、メールアドレス、説明文、レビューを抽出する別関数を書きます。つまり、レート制限、エラー処理、場合によってはプロキシの管理まで、すべて自分でやる必要があります。
ステップ5:CSVまたはJSONとして保存する
Pythonのcsvモジュールやjsonモジュールを使います。さらに、重複排除、整形、エクスポート処理も自分で書く必要があります。
よくある落とし穴:
- SuperPagesはCloudflareなどのボット対策でリクエストをブロックすることがあります(私のテストでも確認済みです)。
- ここでセレクタを広めにしているのは、SuperPagesのマークアップが変わる可能性があるためです。
- 検索結果ページにメールアドレスがあると思わないでください。ほとんど表示されません。
- 本番向けのスクレイパーには、robots/TOSの確認、レート制限、リトライ/バックオフ、構造化ログ、エラー記録が必要です。
Pythonでのスクレイピングをさらに深く学びたい方は、Web scraping with PythonのガイドやBeautifulSoupチュートリアルも参考にしてください。
生データを実際の見込み顧客に変える:全体パイプライン(抽出→整形→検証→CRM)
多くのスクレイピング記事はここで終わります。でも本当に価値が生まれるのはここからです。スクレイピングで得られるのはあくまで素材。実際に使える見込み顧客リストにするには、もう少し工程が必要です。
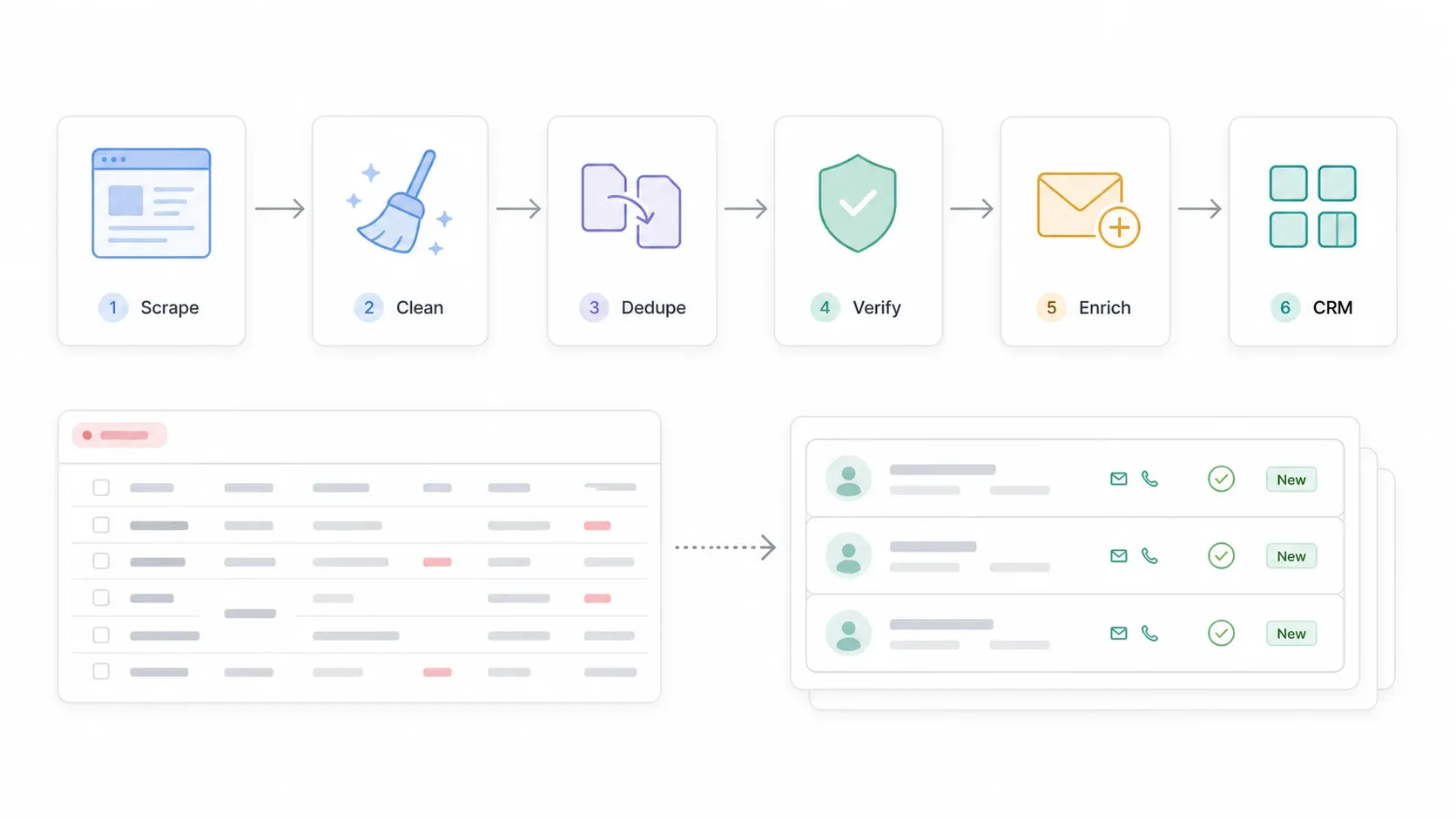
全体の流れは次のとおりです。
SuperPages検索 → 一覧を抽出 → 詳細ページ/Webサイトを抽出 → Google SheetsまたはCSVへ出力 → 電話番号・住所・カテゴリを整形 → 重複排除 → メール/電話を検証 → 不足している連絡先を補完 → CRMへ取り込み → コンプライアンスに沿って営業
重複排除:同じ事業者の重複を消す
SuperPagesでは、同じ事業者が複数カテゴリに出てくることがあります。同じ都市で「plumbers」と「drain cleaning」を抽出すると、重複が発生します。
- 主キー:正規化した電話番号+正規化した住所
- 次点:ドメイン+都市名
- 最終手段:事業者名+ZIPコード(フランチャイズは手作業で確認)
Google Sheetsなら、完全一致の行を消すには =UNIQUE(A:H) を使えます。あるいは、近い重複を拾うために =LOWER(REGEXREPLACE(B2&C2,"[^a-zA-Z0-9]","")) のような補助列を作る方法もあります。Excelなら「データ」>「重複の削除」を使います。
データクレンジング:電話番号、住所、表記を統一する
- 電話番号はE.164形式に揃える(米国なら +1 の後に10桁)。多くのCRMやダイヤラーがこの形式を前提にしています。Thunderbitでは、Field AI Promptを使って抽出時に自動整形できます。
- 住所を正規化する:略語を展開し、足りないZIPコードを補い、必要なら番地/都市/州/ZIPに分割する
- URLからHTMLの残骸、余計な空白、トラッキング用クエリを削除する
- 追跡用に
source_directory、source_url、scraped_atを追加する
営業前のメール・電話番号検証
抽出したすべてのメールアドレスに一斉送信するのは避けましょう。検証を入れることで、送信者評価を守り、バウンス率を低く保てます。
- メール検証:ZeroBounce(2,000クレジットで約39ドルから、毎月100クレジット無料)や Bouncer(1,000クレジットで8ドル、クレジットは失効しない)が有力です。
- 電話番号検証:Twilio Lookupなら整形と検証が無料で使え、Caller IDは1リクエスト0.01ドルです。
- Thunderbitの無料Email ExtractorとPhone Number Extractorを使えば、掲載ページで取りこぼした連絡先も拾えます。
補完:SuperPagesにメールがない場合の探し方
SuperPagesの掲載情報には、メールアドレスがまったく載っていないことがよくあります。特に検索結果ページではほぼ見つかりません。そんなときは次の方法を試しましょう。
- 事業者のWebサイトのContact、About、フッターをスクレイピングする。ThunderbitのSubpage ScrapingやEmail Extractorなら一括処理できます。
- Apollo、BetterContact、Icypeas、Prospeoのような補完ツールを使う。ただし、小規模ローカル事業者(従業員2人の配管店、個人経営の歯科医院など)では、大規模B2Bデータベースが空振りすることも多いです。こうしたケースでは、Webサイト起点の抽出のほうがうまくいきやすいです。
- 複数ディレクトリを組み合わせる。SuperPages、Yellow Pages、Google Mapsを同じカテゴリ/都市で抽出し、後で結合して重複排除すると、情報の抜けが減ります。
ローカルSMBのリストをApolloに流したら、空欄ばかりだった、という経験があるなら、あなただけではありません。だからこそ、この対象ではWebサイト起点のアプローチが大切なのです。
CRM取り込み:HubSpot、Salesforce、Google Sheetsへ入れる
- HubSpot:Data Management > Data Integration > Import data > Quick import(contacts only)へ進みます。.csvまたは.xlsxをアップロードしてください。HubSpotのインポートガイドにフィールドマッピングの手順があります。
- Salesforce:Data Import Wizardを使います。CSVを準備し、元の列をSalesforceの項目にマッピングして取り込みます。
- Google Sheets / Airtable / Notion:Thunderbitなら3つすべてに直接エクスポートできます。CSVを経由する必要はありません。
ヒント:取り込み前に、抽出列をCRM項目に対応付けておきましょう。数分のマッピングで、後から何時間もの手作業を省けます。
SuperPagesと他のローカルビジネスディレクトリ比較:良い見込み顧客はどこにいる?
SuperPagesは有力な出発点ですが、スクレイピング対象はそれだけではありません。比較すると次のようになります。
| ディレクトリ | 件数の多さ | 取得できる項目 | 情報の新しさ | スクレイピング難易度 | 向いている用途 |
|---|---|---|---|---|---|
| SuperPages | 多い(米国中心) | 名前、電話、住所、Webサイト、カテゴリ、評価 | 中程度 | 中 | ホームサービス、施工業者、中小企業 |
| Yellow Pages | 多い(米国中心) | SuperPagesに近い | 中程度 | 中 | 一般的な地域営業 |
| Google Maps | 非常に多い(世界規模) | 名前、電話、住所、Webサイト、レビュー、営業時間、写真 | 高い(オーナー更新) | 高い(強力なボット対策) | 最新のローカルデータ |
| Yelp | 多い(米国中心) | 名前、電話、住所、レビュー、価格帯 | 高い | 高い | 飲食、小売、サービス業 |
| Manta | 中程度 | 名前、電話、住所、売上推定、従業員数 | 中程度 | 低 | B2B開拓(売上/従業員情報あり) |
| BBB | 中程度 | 名前、電話、住所、認定、苦情情報 | 中程度 | 低 | 信頼性の高い事業者 |
出典:SuperPagesホームページ、VLDBのSuperPages論文、Google Places APIドキュメント、Yelp Places APIドキュメント、Mantaホームページ、BBBガイド。
Thunderbitはこれらすべてに対応しており、Google MapsやSuperPagesのような人気サイト向けのInstant Templatesもあります。同じワークフローを複数ソースに適用し、リードリストを統合できます。私の経験では、同じカテゴリ/都市について2〜3のディレクトリを抽出して重複排除する方法が最も効果的です。重なりが抜けを埋めてくれ、より完全な一覧になります。
他のディレクトリをスクレイピングする方法については、、、もご覧ください。
SuperPagesの見込み顧客抽出に関する法的・倫理的なポイント
私は弁護士ではないので、これは法的助言ではありません。ただ、この分野に長くいると、コンプライアンスを無視するのは危険だとわかります。実務上の要点をまとめます。
公開された事業データと個人データの違い
会社名、事業用電話番号、事業所住所、Webサイトといった掲載情報は、一般的に公開された商業データと見なされます。これはGDPRやCCPAの個人消費者データとは別物です。ただし、「公開されている」からといって「何をしてもよい」わけではありません。必ずサイトの利用規約を確認してください。
SuperPagesの利用規約(2019年7月更新)には「Data Mining Prohibited」という条項があり、Thryvの事前承諾なしに、bot、クローラー、スパイダー、または同様のツールを使ってデータを収集・抽出することを禁じています。この記事では方法やワークフローを紹介していますが、実運用で大規模に抽出する前に、これらの規約を確認し、必要に応じて許可を得てください。
アウトリーチ時のコンプライアンス:CAN-SPAMとTCPAの基本
抽出したメールアドレスでコールドアウトリーチを行うなら、FTCのCAN-SPAMガイドに従って以下を守る必要があります。
- 虚偽または誤解を招くヘッダーを使わない
- だまし目的の件名を使わない
- 必要に応じて広告であることを明示する
- 有効な住所を記載する
- 明確な配信停止手段を用意し、速やかに対応する
抽出した電話番号で営業電話をかける場合は、National Do Not Call Registryを確認し、TCPA規則を守ってください。特に、自動発信、録音メッセージ、SMSには注意が必要です。FTCは2024年に、欺瞞的なB2BテレマーケティングやAIを悪用した詐欺電話に対する保護を強化する変更を発表しました。
すぐ使えるコンプライアンスチェックリスト
- ✅ 公開されている事業データのみを抽出する
- ✅ SuperPagesの利用規約を確認し、必要なら許可を得る
- ✅ 営業前に連絡先を検証する
- ✅ メールには配信停止方法を入れる
- ✅ robots.txtとレート制限を尊重する
- ✅ DNCリストとメール配信停止リストを管理する
- ⚠️ 個人・消費者データの抽出は避ける
- ⚠️ 生の抽出データをそのまま転売しない(法務確認なしではNG)
方法を選んで、リードリスト作成を始めよう
SuperPagesから見込み顧客を抽出するのは、単にWebページから行を抜き出す作業ではありません。本当に重要なのは、抽出、整形、重複排除、検証、補完、取り込み、そして法令順守のアウトリーチまで含めた全体の流れです。
要点をもう一度まとめると、次のとおりです。
- Thunderbitは、営業チーム、代理店、非エンジニアにとって最速の方法です。2クリックで抽出、1クリックでサブページ補完、Google Sheets、Airtable、Notion、Excelへ無料出力できます。まずは無料で試せます。
- Octoparseは、設定を細かく調整したい中級ユーザー向けの、しっかりしたビジュアルワークフロー型ツールです。
- Pythonは、開発者に最大の自由度を与えますが、保守、ブロック対策、補完機能のなさという負担があります。
- そして忘れてはいけないのが、このワークフローはYellow Pages、Google Maps、Yelp、Manta、BBBにもそのまま使えるということです。複数ソースを抽出し、統合し、重複排除すれば、最も完成度の高いローカルリードリストが手に入ります。
Thunderbitの実際の動きを見たい方は、の解説動画をご覧ください。または、でチームに合うプランを確認できます。
さあ、ディレクトリのページをパイプラインに変えていきましょう。電話番号は正しく整形され、メールアドレスは常に検証済みでありますように。
よくある質問
SuperPagesを見込み顧客獲得のためにスクレイピングするのは合法ですか?
公開されている事業ディレクトリデータをB2Bリサーチ目的で抽出するのは一般的ですが、SuperPagesの利用規約では、Thryvの事前承諾なしのデータマイニングを禁じています。必ずサイトの規約を確認し、必要に応じて許可を得て、CAN-SPAMやTCPAなどのアウトリーチ規制も守ってください。この記事は教育目的で方法とワークフローを紹介するものであり、適法に使う責任は利用者にあります。
SuperPagesからどんなデータが取れますか?
一般的な抽出項目は、事業者名、電話番号、住所、Webサイト、カテゴリ、評価、営業時間、説明文です。メールアドレスは検索結果ページではほとんど表示されません。通常は、詳細ページや事業者自身のWebサイトを訪れる必要があります(サブページスクレイピングやメール抽出ツールが役立ちます)。
コーディングなしでSuperPagesをスクレイピングできますか?
はい。Thunderbit(AI Chrome拡張機能)やOctoparse(ビジュアルスクレイパー)のようなツールを使えば、一行もコードを書かずにSuperPagesを抽出できます。最速なのはThunderbitです。拡張機能を入れて、SuperPages検索を開き、「AI Suggest Fields」、続いて「Scrape」をクリックするだけです。
SuperPagesのページ送りはどう処理すればいいですか?
Thunderbitならページ送りは自動処理されます。「Next」ボタンや無限スクロールを検出して続けてくれます。Octoparseでは、ワークフロー内でページ送りステップを設定する必要があります。Pythonでは、ページ番号を増やすループや最終ページの判定ロジックを自分で書く必要があります。
SuperPagesの掲載情報からメールアドレスをどう取得しますか?
多くのSuperPages掲載では、検索結果ページにメールアドレスは表示されません。ThunderbitのSubpage Scrapingで各詳細ページを巡回するか、事業者のWebサイトで無料のEmail Extractorを使ってください。まだ足りない場合は、Apollo、BetterContact、Prospeoのような補完ツールも試せます。ただし、小規模なローカル事業者では、大規模B2BデータベースよりもWebサイト起点の抽出のほうがうまくいくことが多いです。
さらに詳しく知る