GitHubで「tiktok scraper」を検索すると、が見つかります。そのうち約は1年以上更新されておらず、少なくともです。
人気のTikTokスクレイパーリポジトリをクローンして、依存関係と1時間格闘した末に、結果が何も出なかった——そんな経験があるなら、あなただけではありません。GitHubで最も★の多いTikTokスクレイパーである drawrowfly/tiktok-scraper は、今でも5,000以上のスターを集めています。とはいえ、Issueトラッカーには や のような、出力がゼロだったという報告が並んでいます。私はThunderbitで何か月もTikTokスクレイピング系リポジトリの状態を追ってきましたが、その傾向は明白です。これらのツールはすぐ壊れ、ほとんどは修正されません。この記事は、私がこうしたリポジトリを最初に評価し始めたときに欲しかった、実践的な生存ガイドです。生きているもの、死んでいるもの、代わりに何をすべきか、そして見つけた時点ですでに動かなくなっているコードに何時間も無駄にしない方法を解説します。
GitHub上のTikTokスクレイパーが壊れる理由(そして壊れ続ける理由)
TikTokは、一般的なスクレイピング対象ではありません。Web側の仕様が頻繁に変わります。静的なEC商品ページやディレクトリ一覧と違い、TikTokはエンドポイントを入れ替え、ボット対策のフィンガープリントを更新し、ページのレンダリング方法を変え、セッションやトークンの要件を追加します。しかも、前回の変更から数週間でそうなることもあります。
オープンソースのメンテナはボランティアです。TikTokの更新でスクレイパーのリクエスト経路が壊れても、リポジトリは数日、数週間、あるいは永久に放置されることがあります。これはメンテナを責めているのではなく、動きの速い巨額資金を持つプラットフォームと、本業のある無給の開発者との構造的なミスマッチです。
優秀なTikTokスクレイパーのリポジトリでさえ、修正と障害対応の繰り返しです。使うなら、評価・トラブルシュート・代替案の準備という戦略が必要です。
TikTokのボット対策:相手にしているもの
- レート制限。 TikTokのでは、承認済み連携であってもリクエスト上限が明記されています。非公式スクレイパーは、もっと早くこの制限に当たります。
- Cookieとセッションのゲート。 のような最近のリポジトリでは
ms_tokenが必要です。 のような古いリポジトリでは、例にtt_webid_v2が登場します。 はmsToken、ttwid、X-Bogus、A_Bogusをドキュメント化しています。TikTokは、そのリクエストが本物の閲覧セッション由来に見えるかを確認しています。 - ブラウザフィンガープリント。 では、サイトがヘッダー、Cookie、TLSシグネチャ、JavaScript経由で取得できるブラウザ特性を実ユーザーの通信と比較する理由を説明しています。では、Canvas、WebGL、WebRTC、フォント、ランタイムシグナルが扱われています。フィンガープリントは、TikTokがブラウザの身分証を確認しているようなものです。ブラウザ、Cookie、タイミング、ネットワークのシグネチャが一致しなければ、コンテンツが返る前に不正リクエストと見なされます。
- 行動検知。 TikTokスクレイピングに関するでは、新規のPlaywrightセッションがCAPTCHAを引き起こすという話が頻繁に出ます。のコミュニティ投稿では、IPの使い回しだけでなく、操作のタイミングやインタラクションの質まで見られていると説明されることが増えています。
- 暗号化/署名付きリクエストパラメータ。 Evil0ctalは
X-BogusとA_Bogusを文書化しています。古いコミュニティのGistでは、URL署名やトークン生成が中心でした。TikTokは、独自のブラウザ/アプリ通信と同じ「印」が付いたリクエストを求める傾向を強めています。 - CAPTCHAと検証フロー。 や、の存在が、CAPTCHAが今もボット対策の一部であることを示しています。
なぜオープンソースのメンテナは追いつけないのか
流れはいつも同じです。開発者がTikTokスクレイパーを作る。GitHubで話題になる。TikTokが対策する。メンテナが直すか、そこで終わる。
このパターンを端的に示す2つのリポジトリがあります。
- drawrowfly/tiktok-scraper は今でも5,052スター、889フォークがありますが、です。GitHubで最も★の多い「tiktok scraper」という完全一致リポジトリですが、今見ると歴史資料のようなものです。可視性は高く、信頼も高い。でも、現役のメンテナンスはありません。
- davidteather/TikTok-Api は、です。を見ると、2025年4月、2025年7月、2025年10月、2026年4月に意味のある更新があり、ユーザー動画の取得や新しいプロキシ/セッション制御の修正も含まれています。それでも、この比較的健全なプロジェクトでさえ、TikTokがリクエストをブロックすることがあるため、プロキシ、Playwright、独自のセッションロジックが必要になると明言しています。
パターンは単純です。
- 古いTikTokスクレイパーリポジトリは、たぶんもう死んでいます。
- 活発なTikTokスクレイパーリポジトリも、たぶんまだ壊れやすいです。
- 本当の違いは、今月の不具合をまだ誰かが直してくれるかどうかだけです。
60秒でできるリポジトリ健全性チェック:GitHub上のTikTokスクレイパーをどう見極めるか
何かをクローンする前に、このチェックリストを回してください。1分もかからず、何時間ものイライラを防げます。
| サイン | 🟢 健全 | 🟡 リスクあり | 🔴 死んでいる |
|---|---|---|---|
| 最後の意味のあるpush | 3か月以内 | 3〜12か月前 | 12か月以上前 |
| Open issue数 | 少なく、最近のIssueには回答あり | Issueが増えており、メンテナ対応は一部のみ | 「壊れた/ブロックされた/動かない」という未回答報告が多い |
| 最近のユーザー苦情 | 主にセットアップ質問 | セットアップと不具合報告が混在 | 「出力ゼロ」「403」「まだ動く?」が繰り返される |
| 現在の認証/セッションモデル | セッション/Cookieの流れが文書化されている | トークン依存だが文書あり | 古いWebエンドポイントに依存し、現在の認証ガイドがない |
| インストールのしやすさ | 再現可能で、検証済みのセットアップ | 手動手順がいくつかある | 古い依存関係、現代的なセットアップ説明なし |
| CI/テスト | テストがあり、最新である | テストはあるがカバレッジが不明 | テストなし、またはActionsが古い |
| データ範囲の適合 | 実際の用途に合っている | 用途の一部しか対応しない | そもそも別問題を解いている |
各サインを60秒以内で確認する方法
- 最後のpush日時:GitHubのリポジトリヘッダーを見ます。「last pushed 2 years ago」と出ていたら、その時点で終了です。
- Open issues:Issuesタブを開き、直近のタイトルをざっと見ます。
not working、403、blocked、captcha、zero outputを検索します。 - ユーザー苦情:上位5件のOpen issueが全部「もう動かない」の言い換えなら、それが答えです。
- 認証/セッションモデル:READMEを開きます。
ms_token、Playwrightの設定、プロキシの注意など、現在の案内があるか確認します。READMEが2023年のエンドポイントを参照しているなら、次へ進んでください。 - インストールのしやすさ:requirementsファイル、Docker対応、明確なセットアップ手順があるか確認します。READMEが「npm install」だけで、最後にテストされたNodeが14なら、苦労を覚悟してください。
- CI/テスト:Actionsタブを見ます。テストが失敗しているか、そもそも存在しなければ、壊れているかどうかは推測になります。
- データ範囲:必要なデータ型(プロフィール、動画メタデータ、コメント、ハッシュタグ)を本当に説明していますか。動画ダウンロードしかできず、構造化データ抽出ができないリポジトリも多いです。
「ここは見切り」のレッドフラッグ
- リポジトリがアーカイブされている。
- READMEに「no longer maintained」とある。
- 最後のコミットが、2年以上前のTikTok APIバージョンを参照している。
- Issueが「動かない」報告であふれていて、メンテナが何か月も反応していない。
- スター数は多いのに、最近のフォークやプルリクエストがない。
コツ:Issuesタブで is:issue is:open "not working" または is:issue is:open "403" を検索してください。結果が多く、しかも最近のものばかりなら、そのリポジトリはおそらく壊れています。
人気のTikTokスクレイパーGitHubリポジトリ:正直な現状確認(2026年)
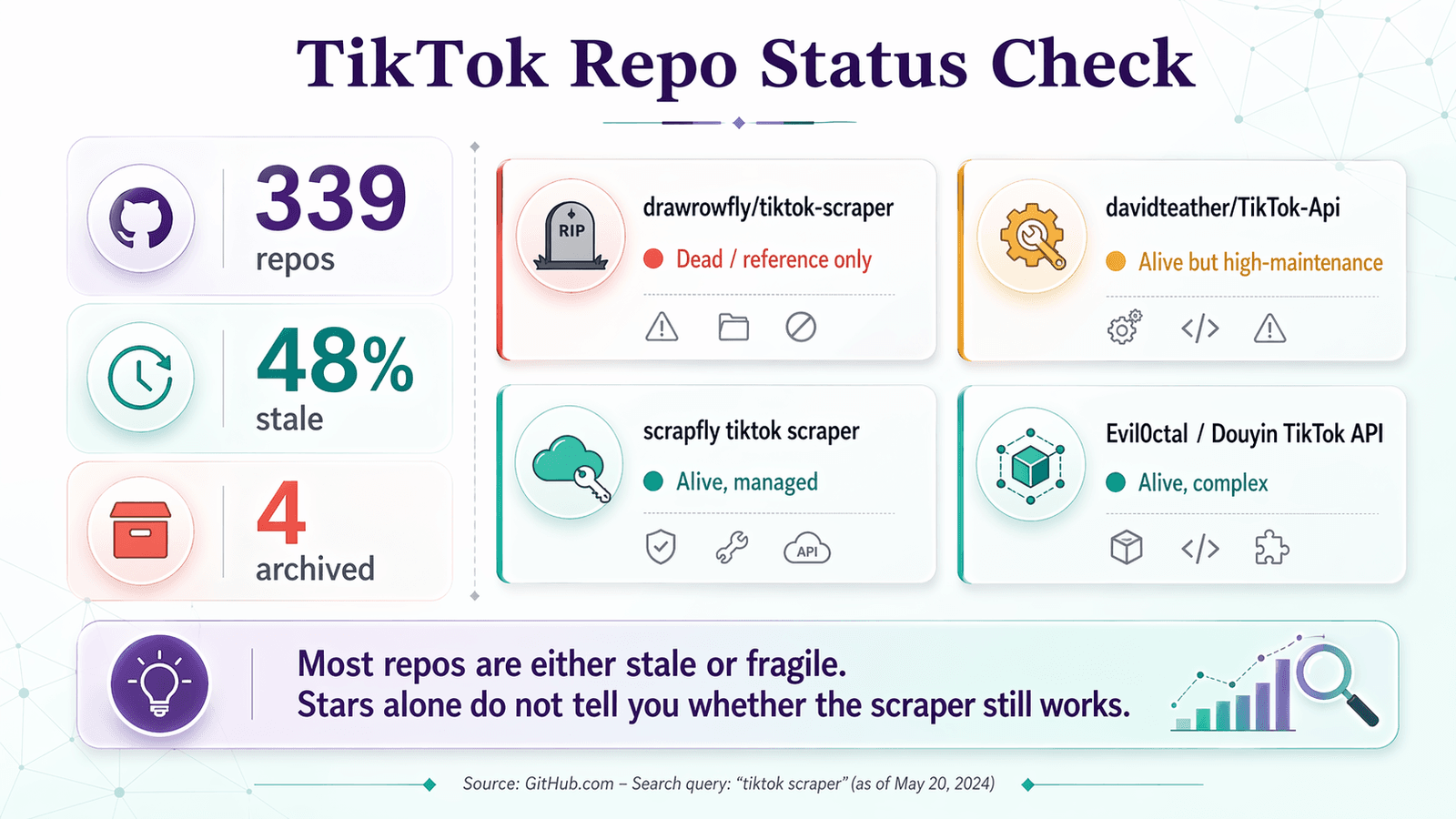
GitHubで「tiktok scraper」と検索したときに実際に見つかるリポジトリに、上の健全性チェックを当てはめてみました。
| リポジトリ | 最後のpush | スター数 | Open issues | 判定 | 補足 |
|---|---|---|---|---|---|
| drawrowfly/tiktok-scraper | 2023-05-19 | 5,052 | 58 | 🔴 死んでいる/参考用のみ | まだ有名だが、2026年の実運用には古すぎる |
| davidteather/TikTok-Api | 2026-04-01 | 6,301 | 134 | 🟡 生きているが保守負荷が高い | OSSとして最有力。Playwright、トークン、しばしばプロキシを前提にする |
| scrapfly/scrapfly-scrapers/tiktok-scraper | 2026-04-21 | 938(親リポジトリ) | 約0(モノレポ) | 🟡 生きているが純粋なOSSではない | 現在も使えるが、ScrapFlyのAPIキーが必要 |
| Evil0ctal/Douyin_TikTok_Download_API | 2025-10-12 | 17,397 | 135 | 🟡 生きていて、広範だが複雑 | 機能豊富なマルチプラットフォームプロジェクト。上級者向けプラットフォームに近い |
| naseif/tiktok-scraper | 2024-07-26 | 107 | 13 | 🟡 リスクあり | ユーザー情報やハッシュタグ処理に関する不満が出ている小規模リポジトリ |
| loewehancara1rmyv/Tiktok-scraper | 2026-01-12 | 4 | 0 | 🔴 まだ新しすぎて信用しにくい | コミュニティで実証されたものではなく、見本用のリポジトリ |
drawrowfly/tiktok-scraper
長年にわたり、このTypeScript製スクレイパー/ダウンローダーは「tiktok scraper github」の定番回答でした。ユーザー、トレンド、ハッシュタグ、音楽フィードを扱っていました。2026年時点では、歴史的資料として見るのが最適です。で、Issueキューには2023〜2025年の未解決の と の報告が残っています。この記事を、このリポジトリをクローンしたのに何も取れなかったから読んでいるなら、それはあなただけではありません。
davidteather/TikTok-Api
2026年時点でも、最も信頼できるオープンソースのTikTokデータ用ラッパーです。今もアクティブで、があり、Playwrightのセットアップ、非同期利用、トークン処理、プロキシ対応、セッション復旧機能を明示的に文書化しています。ただし、これは「クローンしてすぐ使える」ツールではありません。READMEには EmptyResponseException は通常TikTokによるブロックを意味すると書かれており、には ms_token、壊れたコメント取得、KeyError: 'ItemModule'、エンドポイント固有の失敗に関する悩みが繰り返し見られます。結論としては、生きていて、便利で、開発者向けで、保守負荷は高いです。
その他の注目リポジトリ
- :最新で技術的にも有用ですが、READMEでは
SCRAPFLY_KEYが必要です。これは管理型スクレイピング基盤向けのコード例であって、無料の単体ツールではありません。 - :TikTokとDouyinの両方をカバーし、署名ロジック(
X-Bogus、A_Bogus、msToken)を文書化し、コメント、フォロワー、プレイリストなどをサポートします。技術的に難度が高く、有料APIへの参照とだんだん密接に結びついています。Issueトラッカーには2026年時点でも、動画リンクやユーザー情報エンドポイントに関する不具合報告が続いています。生きていて機能は豊富ですが、複雑です。 - :規模は小さく、公開されている不満もあります。本番利用にはリスクがあります。
- :スター4、Issue0、まだ新しすぎて信用しにくいです。これを宣伝したMedium記事も、批判なしに紹介していました。
TikTok公式API vs GitHubスクレイパー vs ノーコードツール:意思決定フレームワーク

競合記事の多くは、TikTokの公式アクセス経路を無視するか、「GitHubを使おう」から「うちのサービスを買ってください」へ飛びます。ここでは3つの選択肢を中立的に比較します。
| 要素 | TikTok Research API | GitHubスクレイパー | ノーコードツール(例:Thunderbit) |
|---|---|---|---|
| アクセスの壁 | 学術/業務用途の申請が必要。承認まで約4週間 | Git clone+セットアップ | ブラウザ拡張のインストール |
| データ範囲 | 承認済みエンドポイントのみ(アカウント、動画、コメント、ショップ) | 広い(プロフィール、動画、コメント、ハッシュタグ、ショップ) | 画面上で見えるデータ(プロフィール、動画、エンゲージメント、ハッシュタグ) |
| 保守負荷 | 低い(公式で安定) | 高い(TikTok更新で壊れやすい) | なし(AIがレイアウト変更に適応) |
| BANリスク | なし(許可済み) | 高い | 低い(ブラウザベースで実ユーザーに近い) |
| コスト | 無料(承認されれば) | 無料(ただし時間コストが大きい) | 無料プランあり;月額15ドルからのクレジット制プラン |
| コーディングの必要性 | あり(Python/R) | あり(Python/Node.js) | なし |
| 最適な対象 | 研究者、学術機関、承認済み組織 | 保守に慣れた開発者 | マーケター、営業、オペレーション、非開発者 |
TikTok Research APIが向いているケース
条件を満たすなら、TikTokのが最もクリーンな公式ルートです。米国、欧州、ブラジルのは、公開コンテンツとアカウントデータの調査を申請できます。利用可能なデータカテゴリには、アカウント、フォロワー/フォロー中、いいね済み動画、固定動画、再投稿動画、コンテンツ、コメント、ショップが含まれます。では、video_description、view_count、like_count、comment_count、share_count といった項目や、コメントレベルの text、reply_count、create_time などのフィールドが公開されています。
ただし、対象は学術機関や、特定地域の適格な非営利/独立研究者、さらにに限られます。成長チームや代理店がすぐに運用データを欲しいなら、この道ではありません。
TikTokにはもあり、広告や広告主コンテンツのデータに使えます。透明性調査には便利ですが、一般的なスクレイピング用途ではありません。
まだGitHubスクレイパーが向いているケース
公式APIの承認条件を超える非公式の公開データが必要で、かつスタックの保守を引き受けられる開発者には、GitHubスクレイパーにも意味があります。たとえば、表示されているプロフィールグリッド、ハッシュタグ、コメント、プレイリスト、動画メタデータを、自分のパイプラインで取得したい場合です。リポジトリをフォークして修正できるなら、なおさらです。
正直な注意点として、これは一度セットアップして終わりではありません。2026年でもっとも信頼性が高い部類の でさえ、Playwright、Cookie/トークン、プロキシ、独自のページ/セッション生成が必要かもしれないと案内しています。
Thunderbitのようなノーコードツールが向いているケース
開発者ではない、あるいは壊れては直すループに疲れた開発者なら、ブラウザベースのAIツールが構造化TikTokデータへの最短ルートです。
私たちは を、Chrome拡張として動くAIウェブスクレイパーとして作りました。TikTok上では、表示されている任意のページ(プロフィール、動画、ハッシュタグ、検索結果)を読み取り、「AIで項目を提案」で列を提案し、「スクレイプ」をクリックするだけで構造化データを抽出できます。 では、投稿日、動画の長さ、いいね数、シェア数、保存数、コメント数、閲覧数、ハッシュタグなどの項目を案内しています。 では、投稿サムネイル、URL、キャプション、作成者ハンドル、エンゲージメント指標をプロフィールページから収集する方法を示しています。 では、動画URL、作成者ユーザー名、説明文、投稿時刻、閲覧数、いいね数、コメント数、シェア数、音源、カバー画像URLを扱います。
サブページスクレイピングを使えば、プロフィール一覧から各動画ページへ進み、エンゲージメント指標、キャプション、ハッシュタグまで補完できます。インフルエンサーデータベースを作るマーケターや、競合コンテンツ監査を行う人に便利です。
保守不要、インストールの切り分け不要、ボット対策の設定不要。AIがレイアウト変更に自動で適応します。Googleスプレッドシート、Excel、Airtable、Notion、CSV、JSONへのエクスポートは無料です。
壊れたGitHubリポジトリに何時間も費やしたなら、これはちゃんとした代替案であって、無理に売り込む商品ではありません。
インストールの切り分け:TikTokスクレイパーGitHubセットアップ失敗のよくある5つの原因を直す
インストール失敗はTikTokスクレイピング界隈で3番目に多い悩みですが、主要なガイドは実際には解決に役立ちません。何が起きているのかを整理します。
Node.jsのバージョン衝突
問題: 古いTikTokスクレイパーの多く(特に drawrowfly/tiktok-scraper)は Node.js 14〜16 向けに作られています。Node 20以降で動かすと、npm install が静かに失敗したり、非互換バイナリを生成したりします。
解決策: nvm(Node Version Manager)で適切なバージョンを入れて切り替えます。
1nvm install 16
2nvm use 16
3npm installリポジトリがNodeのバージョンを明記していない場合は、package.json の engines フィールドを見るか、CI設定を確認してください。
Python依存関係の問題とPlaywrightのセットアップ
問題: は と、特定のブラウザバイナリを伴うPlaywrightを必要とします。ユーザーは「browser not found」や依存関係の衝突といったエラーに遭遇します。
解決策: 必ず仮想環境を使い、そのうえでPlaywrightのブラウザを明示的に入れます。
1python -m venv .venv
2source .venv/bin/activate # Windowsでは: .venv\Scripts\activate
3pip install TikTokApi
4python -m playwright installplaywright install が失敗する場合は、OSのパッケージマネージャで不足しているシステム依存関係(Ubuntuなら libnss3 など)を確認してください。
Linux/Ubuntuの権限エラー
問題: sudo pip install を使うとシステムのPython環境が壊れ、依存関係の問題が連鎖します。
解決策: sudo pip install は絶対に使わず、先に仮想環境を作ります。
1python3 -m venv .venv
2source .venv/bin/activate
3pip install -r requirements.txtこれで、スクレイパーの依存関係をシステムPythonから分離できます。
Windowsのパスとエンコーディングの問題
問題: WindowsのCMDは文字エンコーディングの問題やパス長制限があり、スクレイパーのインストールが壊れることがあります。特にPlaywrightがブラウザバイナリを深い階層にダウンロードすると顕著です。
解決策: CMDの代わりにWSL(Windows Subsystem for Linux)かGit Bashを使います。WSLなら、Windowsの中にフルのLinux環境を作れます。
1wsl --install
2# その後、WSLターミナルを開いてLinuxのセットアップ手順に従うDockerで一気に回避する方法:依存関係の問題をまるごと飛ばす
問題: 上記すべて。
解決策: Dockerに慣れているなら、スクレイパー環境をコンテナ化してください。PythonベースのTikTokスクレイパー向けの基本的なDockerfileはこんな感じです。
1FROM python:3.11-slim
2RUN apt-get update && apt-get install -y libnss3 libatk-bridge2.0-0 libdrm2 libxcomposite1 libxdamage1 libxrandr2 libgbm1 libasound2
3RUN pip install TikTokApi playwright && python -m playwright install --with-deps chromium
4WORKDIR /app
5COPY . .
6CMD ["python", "scrape.py"]これで、ホストOSに関係なく再現可能な環境が保証されます。Dockerでは動くのにDocker外では失敗するなら、それはコードではなく環境の問題です。
トラブルシューティングの流れ:
- リポジトリ自身のサンプルは成功するか? → 失敗するなら実行時バージョンを確認。
- 実行時バージョンは正しいか? → ブラウザ/Playwrightのインストールを確認。
- ブラウザは入っているか? → トークン/Cookieを確認。
- トークン/Cookieは有効か? → TikTokがセッションをブロックしていないか確認。
- ここまで全部失敗する? → ユーザー側ではなくリポジトリの破損を疑い、ツールを切り替える。
TikTokスクレイピングのボット対策ベストプラクティス(プロキシにお金を払わずに)
フォーラムでは、BANや検知についての不満が何度も出ています。「アカウントがBANされて余計な出費になる」「Apifyや高額な有料APIを使わずに済ませたい」といった声です。ここでは、有料プロキシ契約なしで使える無料の実用的な回避策を紹介します。

| 対策 | 難易度 | 費用 | 効果 |
|---|---|---|---|
| ランダムなリクエスト遅延(2〜8秒のジッター) | 簡単 | 無料 | 中程度 |
| セッション/Cookieのローテーション | 中 | 無料 | 中程度 |
| ログアウト状態の公開ページだけを対象にする | 簡単 | 無料 | 中程度 |
robots.txt とレート制限ヘッダーを尊重する | 簡単 | 無料 | 基本ライン |
| ヘッドレスブラウザのフィンガープリントをランダム化する(Playwright) | 中 | 無料 | 高い |
| TikTokのモバイルAPIエンドポイントを使う(検知されにくい) | 難しい | 無料 | 高い |
| 住宅用プロキシのローテーション | 中 | 月20〜100ドル | 高い |
実際に役立つ無料テクニック
ランダムなリクエスト遅延。 リクエストを短いループで連発しないでください。各リクエストの間に2〜8秒のランダムな揺らぎを入れます。これは最も簡単で効果的な対策の1つです。
1import time, random
2time.sleep(random.uniform(2, 8))セッションとCookieの再利用。 リクエストごとに新しいセッションを作らないでください。複数のリクエストでCookieとセッション状態を再利用し、その後でローテーションします。最近のリポジトリが stateless なスクレイピングを約束せず、ms_token を求めるのはそのためです。
ログアウト状態の公開ページを取得する。 ユーザー認証済みルートをサポートせず、ログアウト時に見えるデータでのみ動くとしています。ログイン済みセッションよりも、ログアウト状態のスクレイピングのほうが検知されにくいです。
robots.txt を尊重する。 TikTokの は多くのエージェントを完全にブロックし、一般的なクロールには限られた公開パスしか許可していません。積極的なスクレイピングの許可ではありませんが、これに従えば即時のIPブラックリスト化の可能性を下げられます。
成功率を上げる中級テクニック
ヘッドレスブラウザのフィンガープリントをランダム化する。 Playwrightを使うなら、セッションごとにビューポートサイズ、User-Agent文字列、タイムゾーン、ロケールを変えます。これで、同じボットが新しいIPで来ているのではなく、別々の実ユーザーに見えやすくなります。
TikTokのモバイルAPIエンドポイントを使う。 一部のコミュニティメンバーは、Webフロントエンドではなくモバイル向けのエンドポイントを狙うと検知率が下がると報告しています。実装は難しく、文書も少なめですが、上級者には実際に使える手法です。
プロキシが必要になる場面と、比較的手頃な選択肢
規模が大きくなると、無料の手法だけでは足りません。大量のTikTokスクレイピングでは、住宅用プロキシのローテーションが標準的な方法です。ここでは特定の有料プロキシサービスは推しませんが、一般論としては、データセンタープロキシは避け、TikTokが強くフラグを立てにくい住宅用またはモバイル用のプロキシプールで、リクエストごとのローテーションができるものを探すべきです。
あるいは、 のようなブラウザベースのツールなら、あなた自身のブラウザセッション内で動くため、プロキシ問題を丸ごと回避できます。大規模な用途では検知されないわけではありませんが、一般的なマーケティングや調査用途(数十〜数百ページ、数百万ページではない)なら、ずっとシンプルです。
実際にはどんなデータが取れるのか?TikTokスクレイパーの実例
ツールを選ぶ前に、実際にどんなデータが取れるのか知りたいはずです。多くのガイドはここを飛ばします。以下は、ソースドキュメントに基づく代表的なフィールド構成です。
プロフィールデータ
| ユーザー名 | 表示名 | フォロワー数 | フォロー数 | 総いいね数 | 自己紹介 | 認証済み | プロフィールURL |
|---|---|---|---|---|---|---|---|
| @examplecreator | Jane Doe | 1,240,000 | 312 | 48,700,000 | "料理+コメディ 🍳" | ✅ | tiktok.com/@examplecreator |
| @travelwithmark | Mark S. | 890,000 | 150 | 22,100,000 | "旅のVlogger 🌍" | ❌ | tiktok.com/@travelwithmark |
| @fitnessmaya | Maya L. | 2,100,000 | 88 | 91,300,000 | "ワークアウトとウェルネス" | ✅ | tiktok.com/@fitnessmaya |
取得元: GitHubスクレイパー(TikTok-Api、Evil0ctal)、Research API、Thunderbit(表示されているプロフィールページから)。
動画メタデータ
| 動画URL | キャプション | 閲覧数 | いいね数 | コメント数 | シェア数 | 音楽 | ハッシュタグ | 投稿日 | 長さ |
|---|---|---|---|---|---|---|---|---|---|
| tiktok.com/@ex/video/123 | "史上最高のパスタのコツ 🍝" | 4,200,000 | 312,000 | 8,400 | 21,000 | "Italian Vibes – DJ Marco" | #pasta #cooking #hack | 2026-03-15 | 0:42 |
| tiktok.com/@ex/video/456 | "POV:猫に見下されるあなた" | 9,100,000 | 1,100,000 | 23,000 | 55,000 | "Original Sound" | #cat #pov #funny | 2026-04-01 | 0:18 |
| tiktok.com/@ex/video/789 | "誰も求めていない朝のルーティン" | 1,800,000 | 98,000 | 3,200 | 7,500 | "Chill Morning – LoFi" | #routine #morning | 2026-04-10 | 1:02 |
取得元: GitHubスクレイパー(TikTok-Api、Evil0ctal)、(video_description、view_count、like_count、comment_count、share_count、music_id、hashtag_names、video_duration など)、Thunderbit()。
コメントデータ
| 投稿者 | コメント本文 | いいね数 | タイムスタンプ | 返信数 |
|---|---|---|---|---|
| @user_abc | "これを試したら本当に動いた 😂" | 1,200 | 2026-03-16T08:12:00Z | 14 |
| @chef_dan | "次はガーリックを足して、信じていい" | 890 | 2026-03-16T09:45:00Z | 7 |
| @randomfan99 | "こういうコンテンツを見に来たんだ" | 340 | 2026-03-16T11:30:00Z | 2 |
取得元: GitHubスクレイパー(TikTok-Api、Evil0ctal)、(text、like_count、reply_count、create_time など)、Thunderbit(表示されているコメント欄から)。
ハッシュタグと検索データ
| ハッシュタグ | 上位動画URL | 総閲覧数 | トレンド中 |
|---|---|---|---|
| #pasta | tiktok.com/@ex/video/123 | 4,200,000 | はい |
| #cooking | tiktok.com/@chef/video/321 | 11,000,000 | はい |
| #hack | tiktok.com/@tips/video/654 | 2,900,000 | いいえ |
取得元: GitHubスクレイパー(リポジトリによって異なる)、Thunderbit()。
注意:1つのリポジトリですべての項目が常に取れるわけではありません。TikTokのレスポンス構造は変わり続けており、メンテナもそれを警告しています。ここでの例は、あくまで代表例として見てください。
Thunderbitを使って2クリックでTikTokデータを抽出する方法(ステップごと)
壊れては直すループに疲れましたか? ここではノーコードの道を紹介します。GitHubリポジトリで失敗してきた人のための脱出口です。
- をインストールします。
- 抽出したいTikTokページへ移動します — プロフィール、検索結果ページ、ハッシュタグページ、個別動画のいずれでも構いません。
- 「AIで項目を提案」をクリックします。 ThunderbitのAIがページを読み取り、ユーザー名、フォロワー数、動画キャプション、いいね数、ハッシュタグなどの列を提案します。
- 必要なら項目を調整してから、「スクレイプ」をクリックします。 データが構造化された表に入ります。
- サブページスクレイピングでデータを補完します。 プロフィール一覧から各動画を開き、完全なキャプション、音楽情報、コメント数、シェア数などを取得します。
- Googleスプレッドシート、Excel、Airtable、Notionへエクスポート — すべて無料です。
保守不要、インストールの切り分け不要、ボット対策設定不要。AIがTikTokのレイアウト変更に自動で適応します。
サブページスクレイピングでTikTokデータを拡張する
プロフィールやハッシュタグページから動画一覧を抽出したら、「サブページをスクレイプ」をクリックすると、AIが各動画ページを訪れて追加項目を取得します。インフルエンサーデータベースを作るマーケターや、競合コンテンツ監査を行う人に特に便利です。何十ページも手でクリックせずに、動画レベルのエンゲージメントデータをまとめて取れます。
TikTokデータのエクスポートと活用
Thunderbitは Googleスプレッドシート、Excel、Airtable、Notion、CSV、JSON に無料でエクスポートできます。よくある活用例は次のとおりです。
- データをスプレッドシートに入れてエンゲージメント分析をする。
- Airtableに送って、CRM風のインフルエンサートラッカーを作る。
- Notionに入れて、チームでコンテンツ調査を共同作業する。
ThunderbitがWebデータ抽出をどう扱うかをもっと詳しく知りたいなら、 を見るか、 のチュートリアルをご覧ください。
法的に安全に進める:TikTokの利用規約とスクレイピングのコンプライアンス
TikTokの法的立場は明確です。プラットフォームの では、利用規約が、情報収集や無許可でのサービス操作を行う自動スクリプトを禁止していること、さらにアクセス制限の回避を明示的に禁じていることが説明されています。TikTokの でも、自動スクリプトやWebクロールを使って情報を不正に取得しようとする試みは禁止されています。
実務上の指針は次のとおりです。
- 公開されているデータだけに絞る。 非公開コンテンツやログイン必須コンテンツは取得しない。
- レート制限を守る。 TikTokのサーバーに負荷をかけすぎない。
- データ保護法を順守する。 個人データを収集・保存・分析するなら、GDPRやCCPAが適用されます。
- 対象ならResearch APIを使う。 コンプライアンスの面ではこれが最も安全です。
- これは法律相談ではありません。 個別の状況は専門家に相談してください。
法的な全体像については、 のガイドもご覧ください。
TikTokスクレイパーのGitHubリポジトリが死んだらどうするか
要点だけまとめると次の通りです。
- GitHubのTikTokスクレイパーをクローンする前に、必ず60秒のリポジトリ健全性チェックを実行する。 ほとんどのリポジトリはすでに死んでいます。
- 選択肢を理解する。 公式API、GitHubスクレイパー、ノーコードツールは、それぞれ別のユーザーと用途に向いています。
- GitHub路線を選ぶなら、 インストールのトラブルシュートとボット対策設定に時間を見積もる。継続的な保守が前提です。
- 実際にどんなデータが取れるかを把握してから、 ツールを使い始める。スター数だけでなく、出力項目を確認してください。
- 開発者でないなら(あるいは壊れたリポジトリに疲れているなら)、 のようなノーコードツールを試す。2クリックで、構造化データ、無料エクスポート。
必要なTikTokデータは、きちんと取得できます。問題は、スクレイパーの保守に時間を使いたいのか、それともデータを実際に使いたいのかです。自分のスキルと用途に合う方法を選び、死んだGitHubリポジトリにこれ以上午後を奪われないようにしましょう。
よくある質問
2026年でもGitHubで動くTikTokスクレイパーはありますか?
はい、ありますが、数は多くありません。 は、2026年4月時点で現役のメンテナンスがある、最も信頼できるオープンソースの選択肢です。 も生きていますが、より複雑です。最もスターの多い drawrowfly/tiktok-scraper は2023年5月以降更新されておらず、実質的には終了しています。どのリポジトリに時間を使う前にも、必ずリポジトリ健全性チェックを実行してください。
TikTokをスクレイピングするのは合法ですか?
TikTokの利用規約は、自動スクレイピングを明示的に禁止しています。公開されて見えるデータは、法域によって扱いが異なるグレーゾーンです。対象研究者なら、公式の が最も安全です。公開データを取得する場合でも、公開アクセス可能なコンテンツに限定し、レート制限を守り、GDPR/CCPAに準拠してください。これは法律相談ではありません。個別事情は専門家に相談してください。
コーディングなしでTikTokをスクレイピングできますか?
はい。 のようなブラウザベースのAIツールを使えば、コードを書かずに構造化されたTikTokデータ(プロフィール、動画メタデータ、ハッシュタグ、エンゲージメント指標)を取得できます。TikTok Research APIも、承認された申請者にとっては最小限のコーディングで使えます。非開発者にとっては、ノーコードツールが最速で最も安定した選択肢です。
TikTokスクレイパーでどんなデータが取れますか?
一般的なデータ型には、プロフィール情報(ユーザー名、フォロワー数、自己紹介、認証済みかどうか)、動画メタデータ(キャプション、閲覧数、いいね数、コメント数、シェア数、音楽、ハッシュタグ、長さ、投稿日)、コメント(本文、いいね数、タイムスタンプ、返信)、ハッシュタグ/検索データ(上位動画、総閲覧数、トレンド中かどうか)があります。実際に取れる項目はツールと方法によって異なります。詳細は上の出力例セクションを参照してください。
なぜ私のTikTokスクレイパーはいつもブロックされるのですか?
TikTokは、レート制限、Cookie/セッションのゲート、ブラウザフィンガープリント、行動検知、暗号化されたリクエストパラメータ、CAPTCHAフローなど、複数層のボット対策を使っています。ブロックの主な原因は、リクエストを速く送りすぎること、毎回きれいな新規セッションを使うこと、デフォルトのフィンガープリントのヘッドレスブラウザを使うこと、データセンタープロキシを使うことです。無料・有料の回避策は、上のボット対策ベストプラクティスのセクションをご覧ください。