

A Amazon tem quase 2 milhões de parceiros de vendas e centenas de milhões de itens no catálogo. Se já tentou copiar manualmente títulos de produtos, preços, avaliações e ASINs para uma folha de cálculo, sabe que a dor é real — e escala depressa.
Trabalho na Thunderbit, onde desenvolvemos um Raspador Web IA, por isso passo muito tempo a pensar em como as pessoas extraem dados de sites. Mas, para este artigo, quis fazer algo que nenhum outro resumo parece fazer: reunir sete extensões reais do Chrome que pode instalar e usar na Amazon, testá-las nas mesmas páginas e dar uma resposta direta sobre o que funciona, o que não funciona e onde cada ferramenta se enquadra. Avaliei cada extensão com base em oito critérios que estão diretamente ligados às frustrações que vejo em fóruns e entre os nossos próprios utilizadores — coisas como deteção de campos por IA, raspagem de subpáginas, risco de bloqueio, planos gratuitos e opções de exportação. Quer seja vendedor na Amazon, profissional de marketing ou apenas alguém farto de copiar e colar, este guia é para si.
Experimente o Thunderbit para raspar a Amazon
Por que raspar dados de produtos da Amazon em primeiro lugar?
Então, quem é que realmente raspa a Amazon — e porquê?
A resposta curta é: praticamente toda a gente que vende, faz marketing ou pesquisa produtos online. A Amazon diz que mais de 60% das vendas na loja vêm de vendedores independentes, e esses vendedores estão constantemente de olho uns nos outros. Estes são os casos de uso mais comuns que vejo:
| Caso de uso | Quem usa | O que obtém |
|---|---|---|
| Monitorização de preços da concorrência | Vendedores, equipas de pricing, agências | Dados em tempo real sobre preço e disponibilidade de produtos rivais |
| Pesquisa de produtos e acompanhamento de tendências | Vendedores da Amazon, investigadores de mercado | Identificação de categorias em alta, novos entrantes e mudanças na procura |
| Análise de sentimento de avaliações | Vendedores de marca própria, equipas de marca | Queixas recorrentes, lacunas de funcionalidades e oportunidades |
| Geração de leads (contactos de vendedores) | Equipas de grossistas, agências | Nomes de vendedores, montras e informações de contacto |
| Monitorização de catálogo e stock | Operações de ecommerce, proteção de marca | Acompanhamento dos níveis de stock, mudanças nos anúncios e vendedores não autorizados |
| Otimização de palavras-chave e anúncios | Donos de marca, operadores de marketplace | Dados de termos de pesquisa, texto do anúncio e palavras-chave da concorrência |
O ROI é tangível. Os próprios estudos de caso da Amazon mostram que as vendas trimestrais da thefitguy subiram mais de 40% depois de otimizar para os principais termos de pesquisa com dados estruturados. E uma pesquisa da Parseur concluiu que os trabalhadores gastam mais de 9 horas por semana em introdução de dados repetitiva. Se conseguir automatizar nem que seja uma parte disso, já está a libertar tempo a sério para decisões de valor.
O que faz uma excelente extensão Chrome de Amazon Scraper? (Os meus critérios de teste)
Nem todas as extensões Chrome são iguais — e a maioria dos artigos comparativos mete APIs, apps desktop e extensões de browser no mesmo saco, como se fossem intercambiáveis. Não são. Aqui está o framework que usei, e por que razão cada critério importa:
- Facilidade de configuração - Um utilizador sem conhecimentos técnicos consegue resultados em menos de 5 minutos? (Os fóruns confirmam que esta é uma preocupação central.)
- Deteção de campos com IA - A ferramenta deteta automaticamente os campos do produto ou é preciso configurar seletores manualmente? (Nenhum artigo concorrente sequer trata isto como categoria.)
- Raspagem de subpáginas / páginas de detalhe - É possível enriquecer os dados do anúncio com informações da página de detalhe do produto num único fluxo?
- Tratamento de anti-bot / risco de bloqueio - Como lida com a deteção agressiva de bots da Amazon? (O principal ponto de dor nos fóruns de utilizadores.)
- Suporte à paginação - Consegue raspar várias páginas de resultados automaticamente?
- Plano gratuito / preço - O que recebe realmente sem pagar? (Os utilizadores perguntam explicitamente por opções grátis, e nenhum concorrente responde a isto de forma prática.)
- Opções de exportação - CSV, Excel, Google Sheets, Airtable, Notion?
- Agendamento e automação - É possível programar para correr de forma recorrente?
Testei cada extensão nos resultados de pesquisa da Amazon dos EUA e nas páginas de detalhe dos produtos, com as mesmas pesquisas e as mesmas condições.

Raspagem com IA vs. baseada em seletores: por que isto importa na Amazon
Há uma distinção que nenhum outro resumo de Amazon scraper faz — e ela é o fator mais importante na quantidade de manutenção que o seu scraper vai exigir.
A maioria das extensões Chrome para scraping funciona mapeando seletores CSS para campos de dados. Você (ou o template da ferramenta) aponta para o elemento HTML de “preço” ou “título”, e o scraper recolhe o que estiver ali. O problema? A Amazon muda o HTML e o CSS subjacentes todos os dias para quebrar scrapers. Utilizadores de fóruns descrevem nomes de classes hash ou mutáveis como um modo de falha comum.
Veja como as três abordagens principais se comparam:
| Abordagem | Como funciona | Quando a Amazon muda o layout |
|---|---|---|
| Baseada em seletores (tradicional) | O utilizador mapeia manualmente seletores CSS para campos | Quebra — o utilizador tem de reconfigurar |
| Baseada em template | Receitas prontas para páginas da Amazon | Quebra até o programador atualizar o template |
| Com IA (ex.: Thunderbit) | A IA lê o conteúdo da página e deteta os campos automaticamente | Adapta-se automaticamente — sem manutenção |
Das sete extensões que testei, só uma — Thunderbit — usa deteção de campos por IA como caminho padrão de configuração. As restantes dependem de seletores ou templates, o que significa mais manutenção quando a Amazon inevitavelmente ajusta as páginas. Perceber esta diferença vai poupar-lhe muita frustração lá à frente.
1. Thunderbit - A extensão Chrome de Amazon Scraper com IA
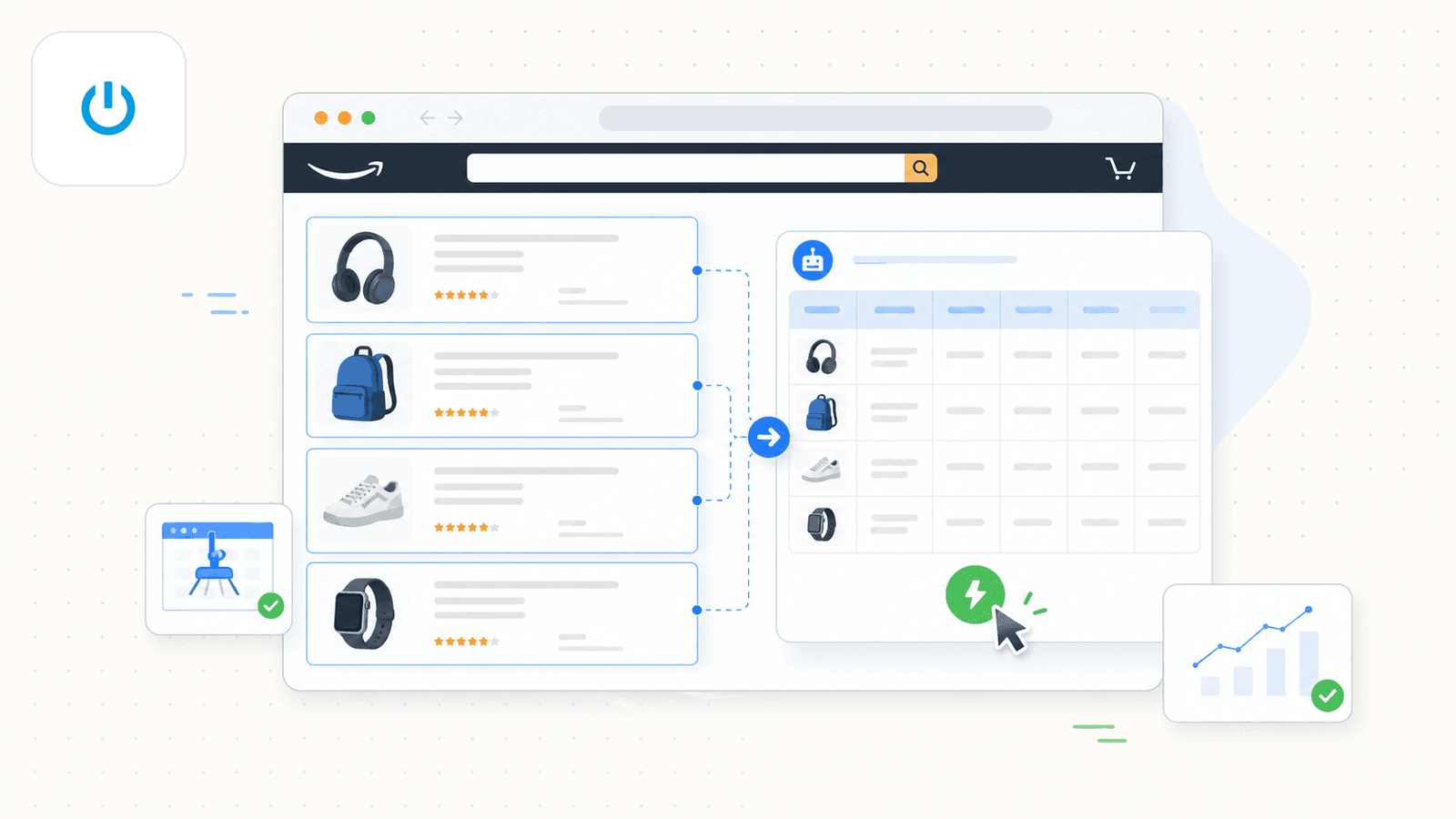
Thunderbit é a ferramenta que construímos na nossa empresa, por isso vou ser transparente quanto a isso. Mas também acredito genuinamente que é a melhor opção para utilizadores sem conhecimentos técnicos que querem dados da Amazon rápidos e precisos sem lutar com seletores ou código.
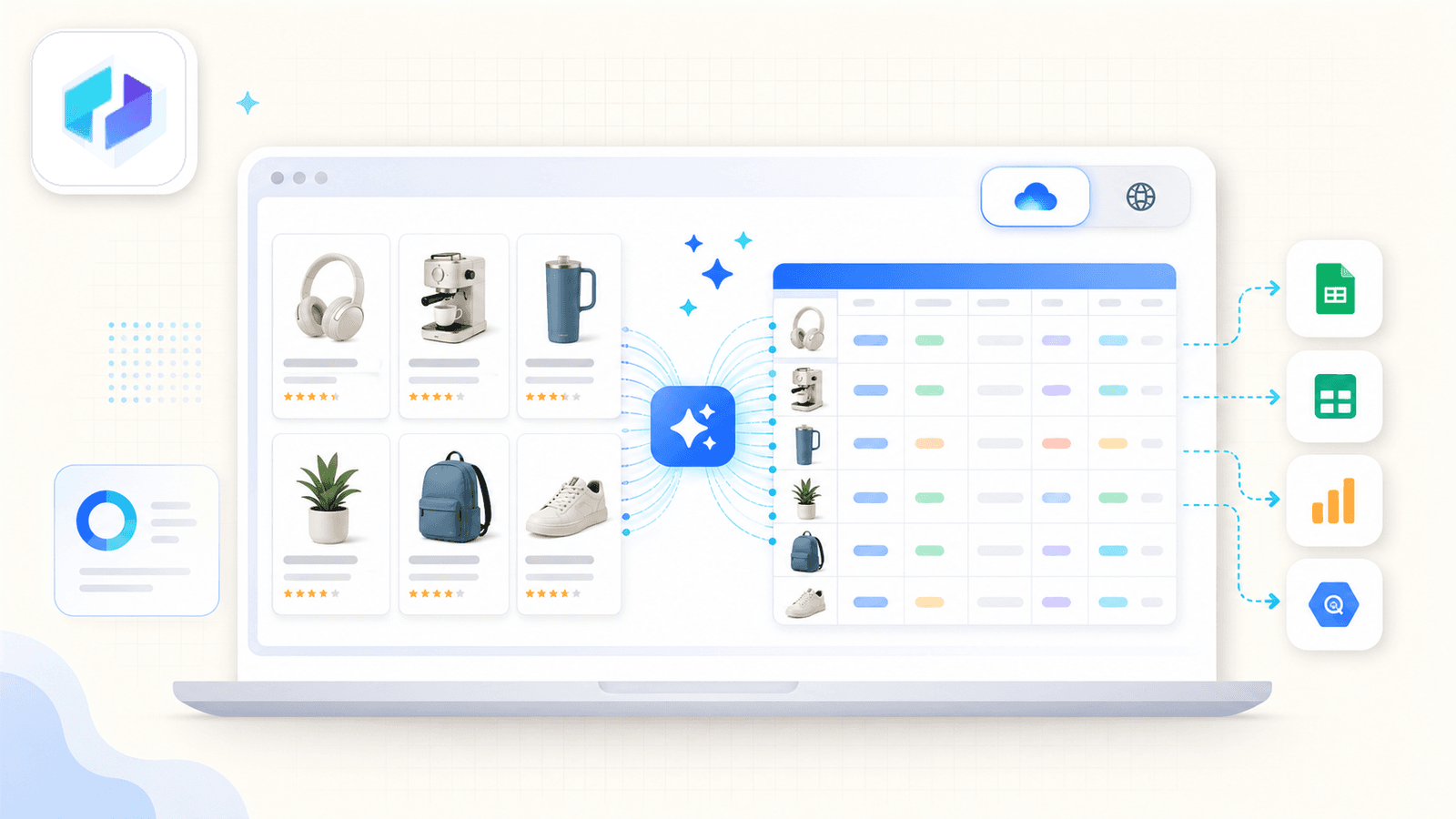
O grande diferencial é o AI Suggest Fields. Quando abre uma página de resultados da Amazon e clica no botão, a IA da Thunderbit lê a página e sugere nomes de colunas — título, preço, avaliação, ASIN, número de avaliações, URL do produto e muito mais. Não precisa de configurar nada. A IA identifica o que está na página e sugere os campos e os tipos de dados corretos.
Veja como é uma sessão típica de raspagem na Amazon:
- Instale a extensão Chrome do Thunderbit e abra uma página de resultados de pesquisa da Amazon.
- Clique em AI Suggest Fields — a IA deteta e propõe as colunas.
- Clique em Scrape — os dados aparecem de imediato.
- Para páginas populares da Amazon, também pode usar o Modelo de Scraper da Amazon pronto, para uma experiência real de 1 clique.
O que realmente distingue o Thunderbit é a raspagem de subpáginas. Depois de raspar a página de listagem, clique em Scrape Subpages — o Thunderbit visita cada URL de produto e adiciona campos detalhados (descrições completas, bullets, informações do vendedor, URLs de imagens) à mesma tabela. A maioria das extensões concorrentes simplesmente não oferece isto.
Também há um alternador entre nuvem e browser. O modo nuvem raspa até 50 páginas em simultâneo para anúncios públicos. O modo browser usa a sua própria sessão do Chrome — ideal quando está autenticado no Seller Central ou precisa de passar mais despercebido.
O agendamento é em linguagem simples: descreva o intervalo de tempo, e a IA converte isso num agendamento.
As opções de exportação incluem Excel, Google Sheets, Airtable, Notion, CSV e JSON — tudo incluído no plano gratuito.
Prós e contras do Thunderbit
Prós:
- A IA deteta campos automaticamente — sem configuração de seletores, sem manutenção quando a Amazon muda o layout
- Enriquecimento de subpáginas em 1 clique
- Alternância entre nuvem e browser para flexibilidade e menor risco de bloqueio
- Maior variedade de exportação (Sheets, Airtable, Notion, Excel, CSV, JSON)
- Agendamento em linguagem natural
- Modelo da Amazon pronto a usar de imediato
Contras:
- Sistema baseado em créditos significa que utilizadores intensivos vão precisar de um plano pago
- A deteção de campos por IA acrescenta uma pequena etapa de processamento (alguns segundos)
- Ferramenta mais recente, por isso tem menos documentação da comunidade do que opções mais antigas
Preços do Thunderbit
- Plano gratuito: 6 páginas (10 com bónus de teste), inclui funcionalidades de IA e todos os formatos de exportação
- Planos pagos: A partir de cerca de US$ 9/mês (anual) para 500 créditos; 1 crédito = 1 linha de saída
- Veja Preços do Thunderbit para os detalhes mais recentes
Raspe páginas da Amazon com IA Get Started Free
2. Instant Data Scraper - A opção gratuita e sem floreados
Instant Data Scraper é uma extensão Chrome que deteta automaticamente dados tabulares em páginas web usando algoritmos heurísticos. Existe há anos e continua a ser uma das extensões gratuitas mais transferidas na Chrome Web Store.
Na Amazon, ativa a extensão numa página de resultados de pesquisa, e ela tenta detetar automaticamente a tabela de dados. Às vezes, é preciso clicar em “try another table” se a primeira deteção não acertar. Para raspagens simples e pontuais, funciona de forma razoável.
Há, no entanto, uma ressalva importante para 2026: a página oficial agora informa que o Instant Data Scraper já não é propriedade, desenvolvido ou suportado pela Web Robots. Isso significa sem atualizações, sem correções de bugs e sem novas funcionalidades. Numa thread no Reddit, um utilizador relatou que a ferramenta lidava com páginas gerais, mas bloqueava quando eram necessários cliques ao nível do detalhe.
Prós e contras do Instant Data Scraper
Prós:
- 100% gratuito, sem necessidade de conta
- Leve e rápido para tabelas simples
- Suporta paginação básica (clicar no botão “Next”)
Contras:
- Sem deteção de campos por IA (depende de correspondência por padrão, o que pode interpretar mal o layout complexo da Amazon)
- Sem raspagem de subpáginas
- Exportação apenas em CSV/Excel
- Sem agendamento, sem opção na nuvem
- Já não é mantido — quebra quando a Amazon muda o layout, e ninguém corrige
3. Web Scraper - A extensão veterana para configuração manual
Web Scraper é uma das extensões Chrome para scraping mais consolidadas, construída em torno de um criador visual de sitemap. Abre o DevTools, cria um “sitemap” apontando e clicando para definir seletores, configura paginação e pode seguir links para páginas de detalhe dos produtos.
O Web Scraper também oferece um template Amazon Products Listings Scraper no marketplace, que trata da navegação, paginação e extração de páginas de produtos. O guia passo a passo mostra um processo de configuração em 8 etapas — instalar, gerar seletores, configurar paginação, seguir links de produtos, executar localmente ou na nuvem.
A versão na nuvem acrescenta agendamento, acesso à API, rotação de proxies, bypass de CAPTCHA e integração com Google Sheets.

Prós e contras do Web Scraper
Prós:
- Maduro, bem documentado e com suporte da comunidade
- Extensão de browser gratuita (uso local ilimitado)
- Templates do marketplace para Amazon
- Opção na nuvem para escala (agendamento, rotação de IP, integrações)
- Suporta seguir links para páginas de detalhe dos produtos (enriquecimento parcial de subpáginas)
Contras:
- Exige configuração manual de seletores — curva de aprendizagem mais alta para utilizadores sem conhecimentos técnicos
- Sem deteção automática de campos por IA
- Os templates podem quebrar quando a Amazon atualiza o layout
- Funcionalidades avançadas presas aos planos pagos na nuvem
Preços do Web Scraper
- Grátis: Extensão Chrome, scraping local ilimitado
- Planos na nuvem: A partir de US$ 50/mês (Project), US$ 100/mês (Professional), de US$ 200/mês (Scale)
4. Octoparse - A plataforma rica em funcionalidades (com uma ressalva na extensão Chrome)
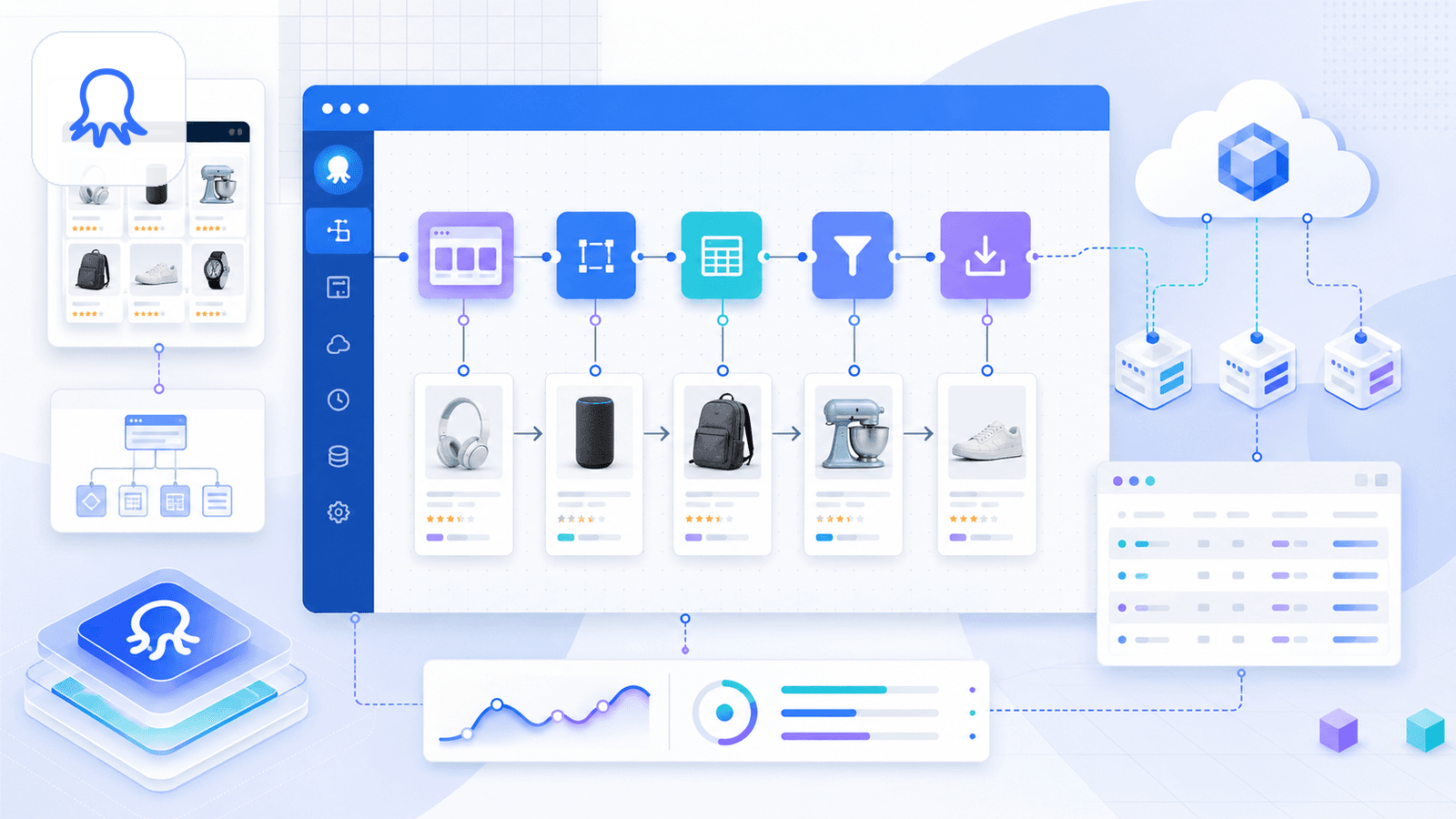
Octoparse é uma plataforma poderosa de scraping sem código, com templates prontos para Amazon para detalhes de produtos, pesquisa por palavras-chave e avaliações. Suporta scraping na nuvem, agendamento e fluxos de trabalho em várias etapas.
Há, no entanto, uma nuance importante: a extensão da Octoparse na Chrome Web Store aparece atualmente como Octoparse AI Web Automation, e o texto deixa claro que só funciona em conjunto com o Octoparse AI Bot no Windows. Ou seja, a experiência real de scraping está centrada na plataforma, não na extensão. Se procura um fluxo puramente de “instalar e raspar no Chrome”, a Octoparse é mais uma app desktop com um assistente de browser.
Ainda assim, os templates são excelentes. Introduz uma URL de pesquisa, a Octoparse extrai automaticamente os dados do produto, e pode criar fluxos personalizados com seletores de apontar e clicar, paginação e navegação por links para páginas de detalhe.
Prós e contras da Octoparse
Prós:
- Conjunto robusto de funcionalidades com templates para Amazon
- Nós na nuvem para velocidade, agendamento e extração de subpáginas através de fluxos de trabalho
- Lida bem com paginação
- Boa para pipelines complexos e com várias etapas
Contras:
- Para tirar partido de todo o potencial, é preciso usar a app desktop — não é uma experiência puramente de extensão Chrome
- Não há campos de sugestão automática por IA (existe um produto separado chamado Chat4Data, mas é outra extensão)
- O plano gratuito limita a exportação a cerca de 50 mil dados por mês, com 10.000 linhas por exportação
- A interface pode parecer complexa para principiantes
Preços da Octoparse
- Grátis: Limitado (extração local, limite de 50 mil exportações)
- Standard: Cerca de US$ 75–83/mês
- Professional: Cerca de US$ 208–249/mês
- Complementos: rotação de IP por US$ 3/GB, resolução de CAPTCHA por US$ 2–US$ 2,50 por 1.000
5. Axiom.ai - O construtor de bots sem código
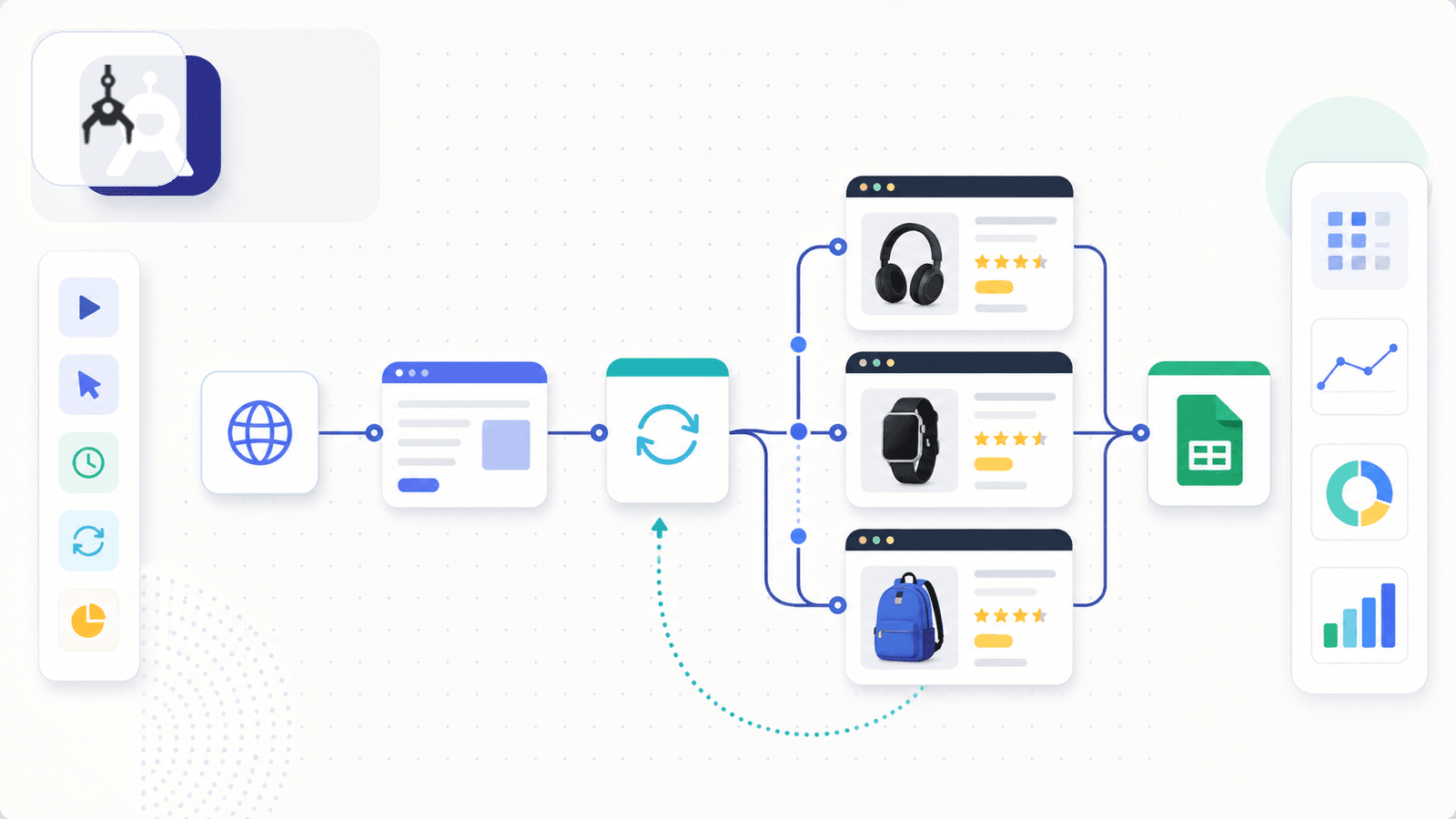
Axiom.ai é uma extensão Chrome para criar bots de automação de browser com um construtor visual sem código. É mais uma ferramenta de automação de uso geral do que um scraper dedicado, mas tem templates de scraping para Amazon e guias de extração de ASIN.
Cria um bot (ou usa um template) que percorre URLs de produtos numa folha de cálculo Google, visita cada página, extrai os dados com seletores de apontar e clicar e grava os resultados de volta na folha. O agendamento está disponível nos planos pagos, e agora há execuções na nuvem, começando com 1 bot na nuvem no Starter e no Pro, até 20 bots simultâneos na nuvem no Ultimate.
Prós e contras do Axiom.ai
Prós:
- Automação sem código versátil (não só scraping)
- Integração nativa com Google Sheets
- Agendamento e execuções na nuvem nos planos pagos
- Templates para Amazon
- Boa para fluxos de trabalho com várias etapas além da extração de dados
Contras:
- Configuração mais pesada para uma raspagem simples (exige desenhar o bot, configurar a folha de cálculo Google, testar loops)
- Sem deteção de campos por IA
- Sem enriquecimento de subpáginas em 1 clique (é preciso criar uma etapa separada no bot)
- Exportação limitada a Google Sheets ou CSV
Preços do Axiom.ai
- Grátis: 2 horas de tempo de execução
- Starter: US$ 15/mês
- Pro: US$ 50/mês
- Pro Max: US$ 150/mês
- Ultimate: US$ 250/mês
6. Data Miner - A extensão orientada por receitas
Data Miner é uma extensão Chrome focada em extrair dados usando “recipes” — templates de scraping predefinidos ou personalizados. Pode procurar uma receita existente de Amazon na biblioteca pública ou criar a sua própria selecionando elementos da página.
O Data Miner suporta paginação através da funcionalidade Next Page Automation, e também oferece um fluxo Crawl Scrape para visitar URLs de detalhe e aplicar uma segunda receita. Portanto, não é “sem raspagem de subpáginas” — mas é um processo manual e em várias etapas, em vez de um enriquecimento com um clique.
A grande limitação está no plano gratuito: 500 páginas por mês, e alguns domínios são restritos no plano grátis. As receitas são específicas do site, e a própria documentação do Data Miner avisa que, se o site mudar e o HTML de referência mudar, a receita não funcionará.
Prós e contras do Data Miner
Prós:
- Fácil de executar uma receita existente
- Biblioteca comunitária de receitas
- Suporta paginação e crawling de páginas de detalhe (configuração manual)
- Interface simples
Contras:
- Plano gratuito limitado a 500 páginas/mês
- Sem deteção de campos por IA
- As receitas quebram quando a Amazon muda o layout
- Sem scraping na nuvem, sem agendamento em documentos públicos
- Exportação: CSV, Excel, área de transferência; Google Sheets nos planos pagos
Preços do Data Miner
- Grátis: 500 páginas/mês
- Pago: US$ 19,99, US$ 49, US$ 99, US$ 200/mês, com limites e funcionalidades crescentes
7. Helium 10 - A suíte de inteligência para vendedores da Amazon
Helium 10 é um conjunto completo de ferramentas para vendedores da Amazon, não um web scraper de uso geral. A extensão Chrome (Xray) sobrepõe dados diretamente nos resultados de pesquisa da Amazon — mostrando estimativas de vendas, receita, tendências de avaliações, BSR e muito mais. Foi pensada para vendedores que fazem pesquisa de produtos, não para extrair dados brutos de páginas.
A Helium 10 tem um plano gratuito em 2026, embora o acesso à extensão Chrome seja limitado no plano grátis. A extensão pode exportar resultados em CSV ou Excel e também suporta fluxos de trabalho com área de transferência.
Prós e contras do Helium 10
Prós:
- Insights profundos específicos da Amazon (estimativas de vendas, dados de palavras-chave, tendências de BSR)
- Confiado por vendedores profissionais
- Dados e agendamento na nuvem para acompanhamento de palavras-chave/rank
- Plano gratuito disponível (limitado)
Contras:
- Não é um scraper geral — não consegue extrair campos personalizados de páginas arbitrárias
- Caro em comparação com ferramentas focadas em scraping
- Formatos de exportação limitados (CSV, Excel)
- Sem deteção de campos por IA, sem enriquecimento de subpáginas no sentido de scraping
Preços do Helium 10
- Grátis: Acesso limitado, incluindo a extensão Chrome
- Starter: US$ 49/mês
- Platinum: US$ 229/mês
- Diamond: US$ 359/mês
Comparando as extensões Chrome de Amazon Scraper: o lado a lado completo
Aqui está a tabela de comparação honesta. Corrigi algumas suposições de rascunhos anteriores após testes práticos e verificação de 2026:
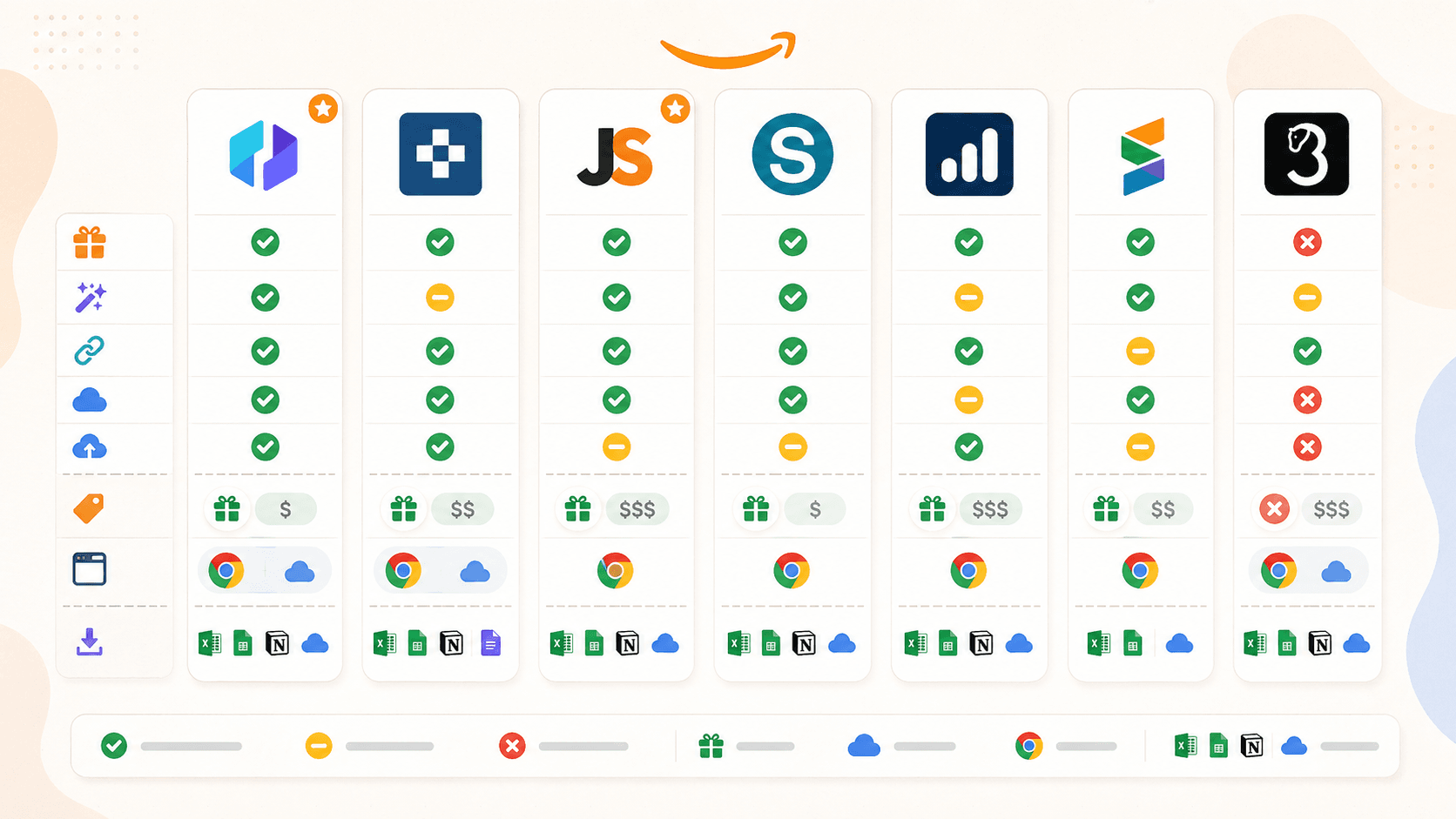
| Recurso | Thunderbit | Instant Data Scraper | Web Scraper | Octoparse | Axiom.ai | Data Miner | Helium 10 |
|---|---|---|---|---|---|---|---|
| Categoria principal | Extensão de scraper com IA | Scraper heurístico gratuito | Scraper baseado em seletores/templates | Plataforma de scraping sem código | Construtor de bots de automação de browser | Extensão de scraper baseada em receitas | Camada de inteligência para vendedores |
| Campos de sugestão automática por IA | Sim | Não | Não | Não (Chat4Data separado) | Não | Não | Não |
| Enriquecimento de subpáginas | Sim (1 clique) | Não | Sim (sitemap manual) | Sim (workflow) | Sim (etapa manual do bot) | Sim (crawl manual) | N/A |
| Scraping na nuvem | Sim | Não | Sim (pago) | Sim (pago) | Sim (pago) | Não | Analytics com suporte na nuvem |
| Agendamento | Sim | Não | Sim (pago) | Sim (pago) | Sim (pago) | Não | Sim (acompanhamento de palavras-chave/rank) |
| Plano gratuito | Sim (6-10 páginas) | Sim (totalmente grátis) | Sim (apenas browser) | Sim (limitado) | Sim (2 horas de execução) | Sim (500 páginas/mês) | Sim (limitado) |
| Template pré-pronto da Amazon | Sim | Não | Sim | Sim | Sim (guias) | Biblioteca de receitas | N/A |
| Exportação para Sheets/Airtable/Notion | Sim (todos) | Apenas CSV/Excel | CSV, Excel, JSON; Sheets via nuvem | CSV, Excel, JSON, mais | Google Sheets, CSV | CSV, Excel; Sheets no pago | CSV, Excel |
Algumas coisas saltam à vista. O Thunderbit é a única extensão com deteção de campos por IA e a maior variedade de exportação no plano gratuito. O Instant Data Scraper é a opção gratuita mais simples, mas já não é mantido. Web Scraper e Octoparse são poderosos para utilizadores dispostos a investir em configuração, mas nenhum deles é uma experiência pura de “instale e use”. Axiom.ai é melhor para automação em várias etapas além da raspagem. Data Miner é fácil para correr receitas existentes, mas o plano gratuito é apertado. Helium 10 é uma ferramenta de inteligência para vendedores, não um scraper geral.
Scraping na nuvem vs. browser para Amazon: o que precisa de saber sobre risco de bloqueio
Este é o elefante na sala. A Amazon deteta e bloqueia ativamente scraping automatizado. Utilizadores no Reddit relatam CAPTCHAs a aparecerem até para scrapers de baixo volume, e os próprios Termos de Utilização da Amazon dizem explicitamente que a licença não inclui “qualquer uso de data mining, robôs ou ferramentas semelhantes de recolha e extração de dados”.
Então, qual é a diferença prática entre scraping no browser e na nuvem?
- Scraping no browser corre na sua própria sessão do Chrome — cookies reais, estado autenticado, comportamento natural de navegação. Parece mais humano em baixo volume, mas prende o seu browser.
- Scraping na nuvem usa servidores remotos para ganhar velocidade (o Thunderbit processa 50 páginas de cada vez no modo nuvem), mas precisa de limitação de taxa e rotação de proxies para evitar deteção.
Aqui está a matriz de decisão que uso:
| Cenário | Modo recomendado | Porquê |
|---|---|---|
| Raspar 20 páginas de produto para pesquisa | Browser | Baixo volume, comportamento natural |
| Monitorizar 500 SKUs concorrentes semanalmente | Nuvem | A velocidade importa, dados públicos |
| Raspar enquanto está autenticado no Seller Central | Browser | Precisa da sua sessão de login |
| Exportação em massa única de uma categoria | Nuvem | Scraping paralelo para ganhar velocidade |
Entre as sete extensões, o scraping na nuvem está disponível no Thunderbit, Web Scraper (pago), Octoparse (pago), Axiom.ai (pago) e Helium 10 (para os seus analytics). Instant Data Scraper e Data Miner funcionam apenas no browser.
Dicas práticas para reduzir o risco de bloqueio: mantenha intervalos de pedidos razoáveis, evite raspar em horas de pico e alterne user agents se a ferramenta permitir. E nunca se prometa “risco zero” — apenas administre esse risco.
Da página de listagem à página de detalhe do produto: como funciona a raspagem de subpáginas na Amazon
Este fluxo é subestimado — e nenhum artigo concorrente o demonstra de ponta a ponta.
Quando raspa uma página de resultados da Amazon, obtém dados resumidos: títulos de produtos, preços, avaliações, ASINs e URLs dos produtos. Mas muitas vezes também precisa dos dados da página de detalhe — descrições completas, bullets, URLs de imagens, informações do vendedor, detalhamento das avaliações. É aí que entra a raspagem de subpáginas.
Com o Thunderbit, o fluxo é:
- Raspe a página de resultados de pesquisa da Amazon -> obtenha uma tabela de produtos (título, preço, avaliação, ASIN, URL do produto).
- Clique em “Scrape Subpages” -> o Thunderbit visita cada URL de produto e adiciona campos detalhados (descrição, número de avaliações, nome do vendedor, URLs de imagens etc.) à mesma tabela.
- Exporte a tabela enriquecida para Google Sheets, Airtable, Notion ou Excel.
A IA deteta a estrutura da subpágina e enriquece a tabela automaticamente — sem configuração manual. Na minha experiência, isto poupa pelo menos uma hora por lote em comparação com abrir cada página de produto e copiar os campos manualmente.
Outras ferramentas também conseguem fazer isto, mas com mais esforço:
- Web Scraper: configura um sitemap para seguir links de produtos e define seletores para cada campo de detalhe. Funciona, mas é um processo manual em várias etapas.
- Octoparse: cria um fluxo de trabalho com etapas de seguir links. Poderoso, mas não é um clique só.
- Axiom.ai: projeta um loop de bot que visita cada URL e extrai os dados. Flexível, mas exige habilidade para criar bots.
- Data Miner: usa a funcionalidade Crawl Scrape para visitar URLs guardados e aplicar uma segunda receita. Manual e dependente da receita.
- Instant Data Scraper e Helium 10: sem fluxo de enriquecimento de subpáginas.
Se precisa regularmente de dados da Amazon tanto ao nível da listagem como ao nível do detalhe, a ferramenta escolhida deve tornar esse fluxo fácil — não apenas possível.
O resumo honesto do plano gratuito: o que recebe realmente sem pagar
Os utilizadores em fóruns perguntam isto mais do que qualquer outra coisa, e nenhum artigo concorrente responde com transparência.
| Extensão | Plano gratuito | O que recebe grátis | Quando precisa de atualizar |
|---|---|---|---|
| Thunderbit | Sim (6 páginas, 10 com teste) | Sugestão de campos por IA, todos os formatos de exportação (Excel, Sheets, Airtable, Notion), extratores de e-mail/telefone | Precisa de mais páginas ou scraping agendado |
| Instant Data Scraper | Sim (totalmente grátis) | Deteção básica de tabelas, exportação CSV/Excel | N/A (não há plano pago, mas também não há atualizações) |
| Web Scraper | Sim (apenas browser) | Scraping no browser, exportação CSV | Scraping na nuvem, agendamento, integrações |
| Octoparse | Sim (limitado) | Cerca de 50 mil exportações/mês, extração local | Mais registos, nós na nuvem |
| Axiom.ai | Sim (2 horas de execução) | Automações básicas, Google Sheets | Mais execuções, agendamento, nuvem |
| Data Miner | Sim (500 páginas/mês) | Receitas, CSV/Excel, Next Page Automation | Mais páginas, Sheets, funcionalidades de crawl |
| Helium 10 | Sim (limitado) | Acesso limitado à extensão Chrome | Xray completo, ferramentas de palavras-chave, agendamento |
A principal conclusão: o plano gratuito do Thunderbit inclui funcionalidades de IA e todos os formatos de exportação — a maioria dos concorrentes bloqueia exportações avançadas ou IA atrás de planos pagos. O Instant Data Scraper é totalmente grátis, mas não tem IA, subpáginas nem agendamento. O Helium 10 tem plano gratuito, mas o acesso à extensão é limitado e não é um scraper geral.
A minha recomendação por cenário:
- “Só estou a testar as águas” -> Instant Data Scraper (totalmente grátis) ou o plano gratuito do Thunderbit
- “Preciso de scraping regular e fiável” -> Thunderbit ou planos pagos do Web Scraper
- “Vendedor da Amazon que precisa de inteligência de mercado” -> Helium 10
Que extensão Chrome de Amazon Scraper deve escolher?
Depois de testar todas as sete, a minha opinião honesta é:
- Melhor para utilizadores sem conhecimentos técnicos que querem resultados rápidos com IA: Thunderbit. A IA deteta campos automaticamente, faz enriquecimento de subpáginas em 1 clique, oferece a maior variedade de exportação e alterna entre nuvem e browser. Se quer ir da página da Amazon para a folha de cálculo em menos de dois minutos, esta é a escolha.
- Melhor opção totalmente grátis para raspagens rápidas e pontuais: Instant Data Scraper. Sem custo, sem conta, mas com funcionalidades limitadas e sem manutenção.
- Melhor para utilizadores confortáveis com configuração manual: Web Scraper. Construtor de sitemap flexível, boa opção na nuvem, bem documentado.
- Melhor para pipelines de scraping complexos e em várias etapas: Octoparse (desktop + extensão) ou Axiom.ai (bots de browser). Ambos são poderosos, mas nenhum é uma extensão Chrome pura de “instalar e começar a usar”.
- Melhor para extração simples baseada em receitas: Data Miner. Fácil de usar receitas existentes, mas plano gratuito limitado e sem IA.
- Melhor para inteligência de vendedor da Amazon (não scraping geral): Helium 10. Feito para isso, com dados proprietários profundos, mas caro e não é um scraper geral.
Se quiser ver como é, na prática, o scraping da Amazon com IA, experimente o plano gratuito do Thunderbit. Acho que vai surpreender-se com o quanto dá para fazer em apenas alguns cliques. E, se o Thunderbit não for o ajuste perfeito, teste algumas outras opções desta lista — nunca houve melhor altura para parar de copiar e colar e começar a raspar de forma mais inteligente.
Para mais dicas de scraping na Amazon, consulte os nossos guias sobre como raspar produtos e avaliações da Amazon, raspagem de preços da Amazon e extração e análise de dados de vendas da Amazon. Também pode assistir a tutoriais no canal da Thunderbit no YouTube.
Experimente o scraping da Amazon com IA da Thunderbit Get Started Free
FAQs
1. É legal raspar dados de produtos da Amazon?
Raspar dados visíveis publicamente geralmente é permitido, mas os Termos de Utilização da Amazon proíbem explicitamente data mining e extração automatizada sem consentimento por escrito. Este artigo não constitui aconselhamento jurídico — reveja sempre os termos da Amazon antes de raspar em grande escala.
2. A Amazon consegue detetar e bloquear scrapers de extensão Chrome?
Sim. A Amazon tem sistemas anti-bot que podem acionar CAPTCHAs, limitar pedidos ou bloquear IPs. Usar taxas de pedido razoáveis, scraping baseado em browser para tarefas pequenas e scraping na nuvem com limitação de taxa para tarefas maiores pode reduzir o risco. Veja a secção de nuvem vs. browser acima para uma matriz prática de decisão.
3. Que dados pode raspar da Amazon com uma extensão Chrome?
Os campos mais comuns incluem títulos de produtos, preços, avaliações, contagem de avaliações, ASINs, nomes de vendedores, descrições, URLs de imagens, disponibilidade e informações de envio. Ferramentas com IA como o Thunderbit conseguem detetar e sugerir estes campos automaticamente, sem configuração manual.
4. Preciso de saber programar para usar uma extensão Chrome de Amazon scraper?
Não — as sete ferramentas testadas foram pensadas para utilizadores sem conhecimentos técnicos. Algumas exigem mais configuração (Web Scraper, Octoparse, Axiom.ai), enquanto outras quase não precisam de ajustes (Thunderbit, Instant Data Scraper). A troca costuma ser entre flexibilidade e facilidade de uso.
5. Que extensão Chrome de Amazon scraper tem o melhor plano gratuito?
O plano gratuito do Thunderbit inclui deteção de campos por IA e todos os formatos de exportação (Sheets, Airtable, Notion, Excel, CSV, JSON), que a maioria dos concorrentes bloqueia atrás de planos pagos. O Instant Data Scraper é totalmente grátis, mas não tem IA, subpáginas nem agendamento. O Data Miner oferece 500 páginas gratuitas por mês. O plano gratuito do Helium 10 é limitado e focado em pesquisa para vendedores, não em scraping geral.
Saiba mais




