
What is Amazon Web Scraper
An Amazon Web Scraper is a nifty tool or software designed to automatically pull data from Amazon.com. This data can include product details, prices, reviews, stock status, and more. The main aim of using an Amazon Web Scraper is to gather large amounts of data for market research, price comparison, or competitive analysis. You can also collect user reviews for keyword research to get a handle on the pros and cons of products.
Key Features of Amazon Web Scraper
- Automated Data Extraction: Say goodbye to the tedious task of manually copying and pasting information. A web scraper can automatically grab the data you need from web pages.
- Customizable Scraping: You can tweak the scraper to pull specific data tags according to your needs, allowing for targeted analysis.
- Data Export: Easily export the scraped data into popular formats like Excel, CSV, or JSON for further analysis using various data tools.
- Regular Updates: Set intervals for scraping to keep your Amazon product database up-to-date, ensuring your data remains current.
- Review Scraping: More often than not, you need to extract the pros and cons from the review session for competitive analysis.

Why Use an Amazon Web Scraper
Amazon is a big player in the global e-commerce scene, known for its vast product selection, competitive pricing, and smooth shopping experience. It provides a platform for businesses to reach potential customers worldwide, expanding their market reach. Consumers trust Amazon as a primary online shopping destination, offering a reliable sales environment for merchants. Plus, Amazon's logistics network allows businesses to leverage fast and efficient delivery services, enhancing customer satisfaction. Amazon also offers various marketing tools to boost product visibility and sales, such as sponsored product ads and brand promotions.
For e-commerce businesses, analyzing sales data on Amazon is crucial. By using an Amazon Web Scraper, businesses can collect data to gain insights into market trends and consumer behavior, optimizing product strategies and inventory management. This can help businesses scale effectively on the Amazon platform, increasing sales and brand recognition for sustained growth. Here's how you can use an Amazon Web Scraper for analysis:
Market Research
-
SKU Selection
Picking the right SKU (Stock-Keeping Unit) is key for e-commerce success, impacting product assortment, supply chain efficiency, and inventory management. With an Amazon Web Scraper, you can extract precise data from millions of products to analyze sales trends and customer preferences. For instance, by scraping Amazon's Product Detail Pages, you can easily access key information like product prices, review counts, and seller ratings for in-depth market analysis. This data helps determine if an SKU has market potential and reveals which products perform best. By comparing products within the same category, businesses can optimize their product selection, increase inventory for popular SKUs, and reduce stock for slow-moving items, improving inventory turnover rates.
-
Identify Customer Trends
By scraping a large volume of product reviews, ratings, and customer feedback, a web scraper can help you quickly identify shifts in consumer demand. For example, by analyzing review data, you can pinpoint the features consumers value most in a product, such as "affordable pricing" or "durability." This information is crucial for product development, pricing strategy, and marketing strategy. Additionally, scraping data on purchase frequency and sales trends over time can help you predict seasonal sales fluctuations and plan inventory and marketing activities in advance.

Competitive Analysis
-
Price Monitoring
In a competitive environment, price monitoring is essential for e-commerce businesses. An Amazon Web Scraper can help you scrape real-time product data to track competitors' price changes, ensuring your pricing remains competitive. This feature is particularly valuable for implementing dynamic pricing strategies. By collecting price information on similar products, businesses can create flexible pricing models that automatically adjust prices based on market demand, inventory levels, and competitor pricing to maximize profits.
-
Review Scraping
Customer reviews not only influence product sales but also reflect market demand changes. An Amazon Web Scraper can help businesses collect a large volume of customer feedback. AI-based web scrapers can assist in summarizing and conducting sentiment analysis to gain insights into user opinions on your products and competitors, allowing you to adjust product design or marketing strategies promptly.
Cost Comparison
Using an Amazon Web Scraper, businesses can collect data on similar products' prices, shipping costs, and promotions for comprehensive cost comparison. Analyzing this data helps businesses optimize their cost structure, avoid unnecessary expenses, and increase profit margins. For businesses seeking vendors on Amazon, it also provides insights into different vendors' shipping fees and sales prices, reducing costs and ensuring competitive pricing in the market, ultimately improving gross profit margins.
Try Using AI for Web Scraping
Try it! You can click, explore, and run the workflow as you watch.
Why Use AI to Scrape Amazon Product Data
With the rapid advancement of AI, AI-driven Amazon Web Scraper tools are leading a new era of data scraping, offering numerous conveniences to traditional web scraping processes. AI not only makes data collection more efficient and accurate but also significantly lowers the technical barrier, providing more innovative opportunities for e-commerce businesses.
User-Friendly for Non-Techies
For users without a technical background, AI-supported Amazon Web Scraper tools offer great convenience. Unlike traditional scrapers that require manual coding and API calls, users simply provide scraping requirements and select desired column names. AI automatically generates suitable scraping plans and suggestions, eliminating the hassle of programming and complex settings. This user-friendly feature helps e-commerce teams efficiently obtain data without professional technical personnel, enhancing team productivity and enabling non-technical staff to easily use advanced data collection tools.
Fast and Efficient
Scrape data from any website using AI Get Started Free
AI Web Scraper automates the data extraction process, significantly increasing the speed and efficiency of data scraping. They can quickly handle complex website structures and dynamic content, accurately capturing target data, reducing manual intervention, and improving overall scraping accuracy. Additionally, AI Web Scraper can greatly reduce operational costs and optimize workflows, allowing businesses to obtain high-quality data at a lower cost, providing more accurate support for decision-making.
Intelligent Analysis and Suggestion
Compared to traditional web scrapers, AI web scraper offer the advantage of intelligent workflow automation. AI tools can automatically categorize data, summarize data, and provide data insights. For example, businesses can use AI to automatically categorize different products into predefined categories or analyze large volumes of review data to extract keywords and sentiment trends, helping businesses better understand consumer feedback and optimize products. AI can also generate customized reports based on scraped data, automatically generating market analysis to help businesses quickly identify popular product features and potential market opportunities.
Smart Output and Export Options
Using an AI-based Amazon web scraper allows for smarter data output. Traditional coding methods typically only output CSV files, while AI tools support CSV format and can automatically export scraped data to collaboration platforms like Google Sheets and Notion, greatly facilitating data analysis and sharing. For example, you can directly import data into Google Sheets for real-time analysis or integrate it into team collaboration tools, ensuring seamless information flow between departments. This intelligent data export method enables teams to make decisions faster, improving overall business flexibility and responsiveness.
Scraping with Thunderbit: The AI Web Scraper
Thunderbit is a newly launched, powerful, and comprehensive AI-driven web scraper tool designed to meet your data needs. With Thunderbit, users can easily collect data from Amazon, whether it's product details, price dynamics, or customer reviews, and quickly turn it into valuable business insights. Here's how Thunderbit can help e-commerce businesses enhance their competitiveness.
First, visit the Thunderbit website and add the Thunderbit web scraper extension to your Chrome browser. Log in using your Google account or another email.
 Next, you can use Thunderbit's built-in pre-built web scraper or AI web scraper to scrape Amazon product data and reviews. Here's how:
Next, you can use Thunderbit's built-in pre-built web scraper or AI web scraper to scrape Amazon product data and reviews. Here's how:
Option 1: Use Thunderbit’s Pre-Built Web Scraper
Thunderbit has designed and optimized various pre-built web scraper tools based on user needs, including a scraper module specifically for Amazon. These tools have pre-established templates for Amazon's complex data structure and collected large amounts of data, eliminating the need to design scraping logic yourself and speeding up the scraping process for quicker and more efficient data collection.
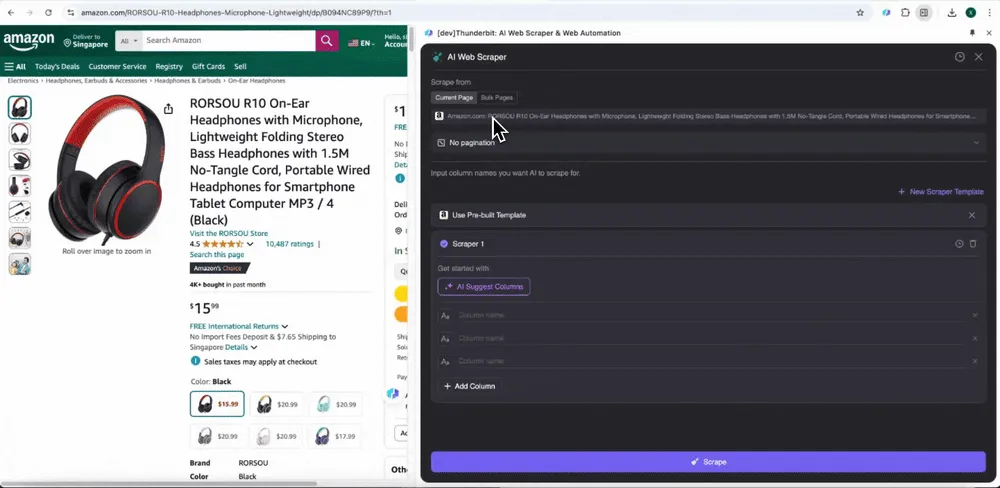
When you open any page on Amazon, open the Thunderbit extension's web scraper. You'll see two pre-built scrapers with rich column names. Simply check the column names you want to extract, and Thunderbit will handle the rest.
-
Amazon Collect SKU Reviews
This tool provides pre-built column names like product name, product URL, overall product rating, detailed rating breakdown, product rating count, review title, author name, review content, review country, and keywords. You can check the boxes next to the column names you want to extract, click scrape, and quickly obtain the SKU review data you need for product review analysis.
-
Amazon Collect SKU Details
This tool offers pre-built column names like product name, product URL, brand, manufacturer, initial price, final price, description, rating, categories, delivery options, and seller URL. Check the boxes next to the column names you want to extract, click scrape, and quickly obtain the SKU detail data you need. Whether you're comparing vendors, manufacturers, and delivery options, conducting market research, assessing your SKU's price competitiveness, or understanding the latest sales trends, these SKU detail data can help with your analysis.
Option 2: Use Thunderbit’s AI Web Scraper
Step 1: Open Amazon.com and click on “AI Web Scraper” in the sidebar
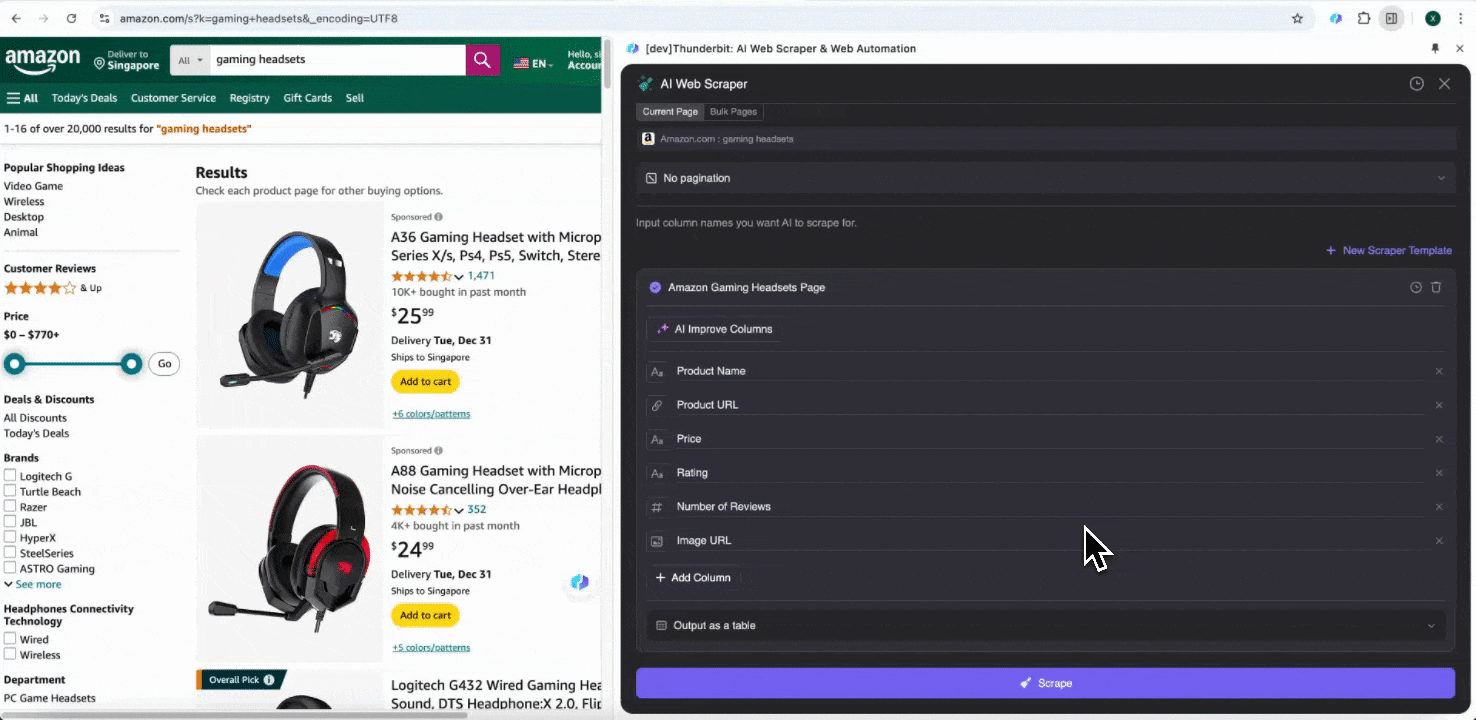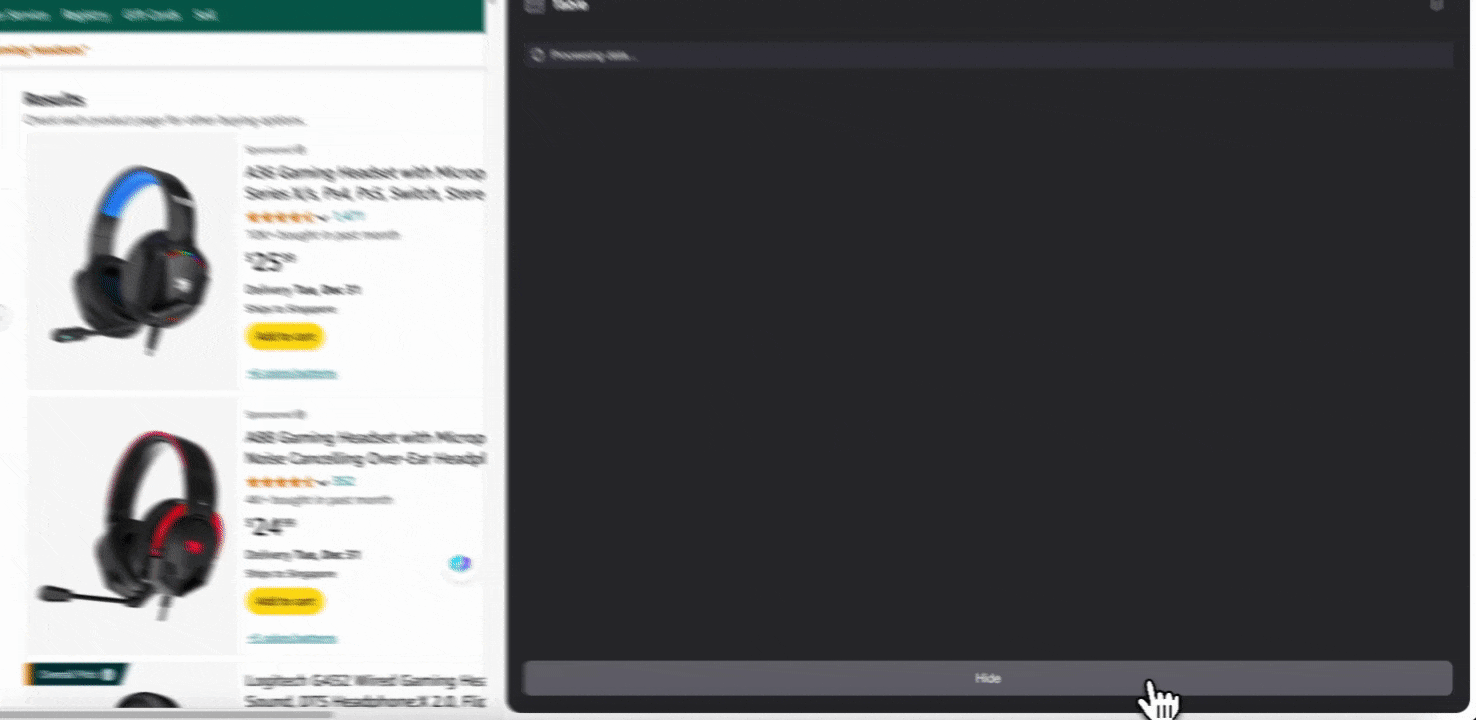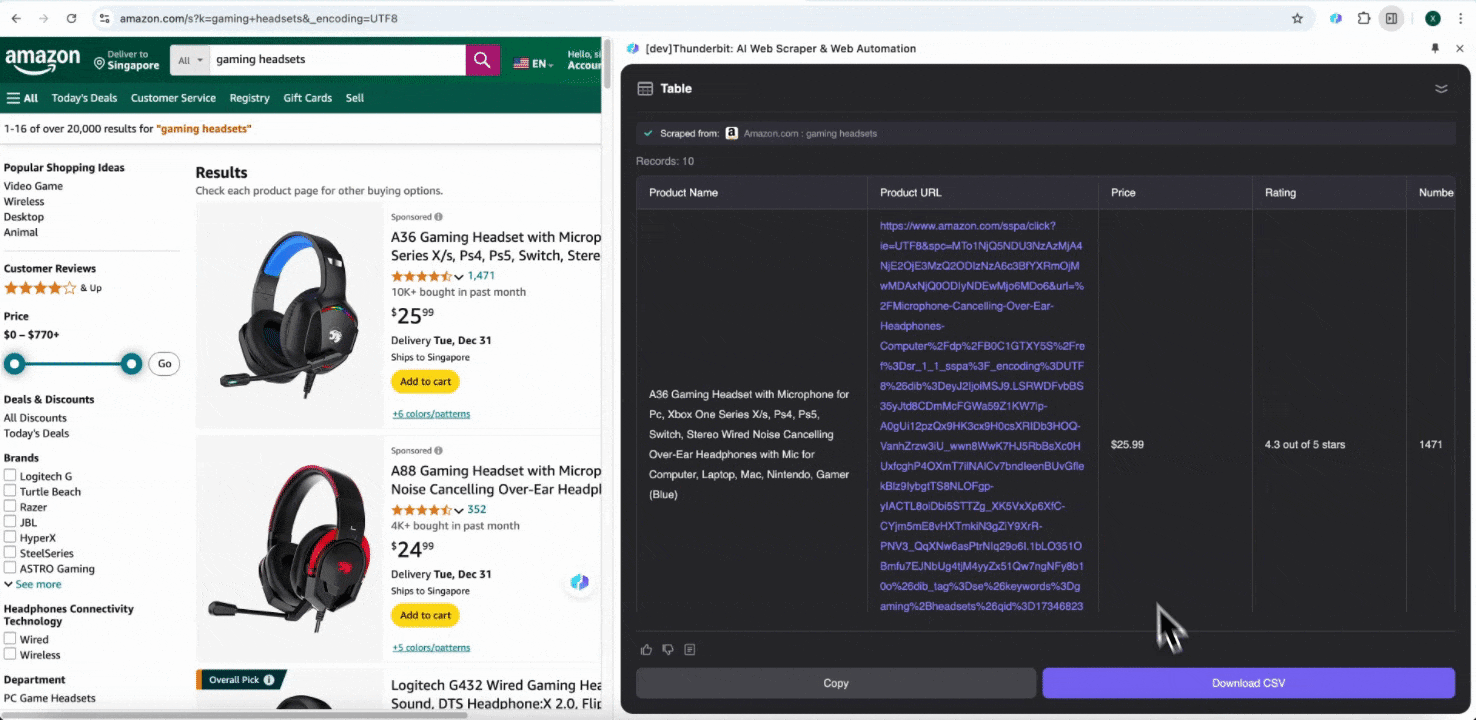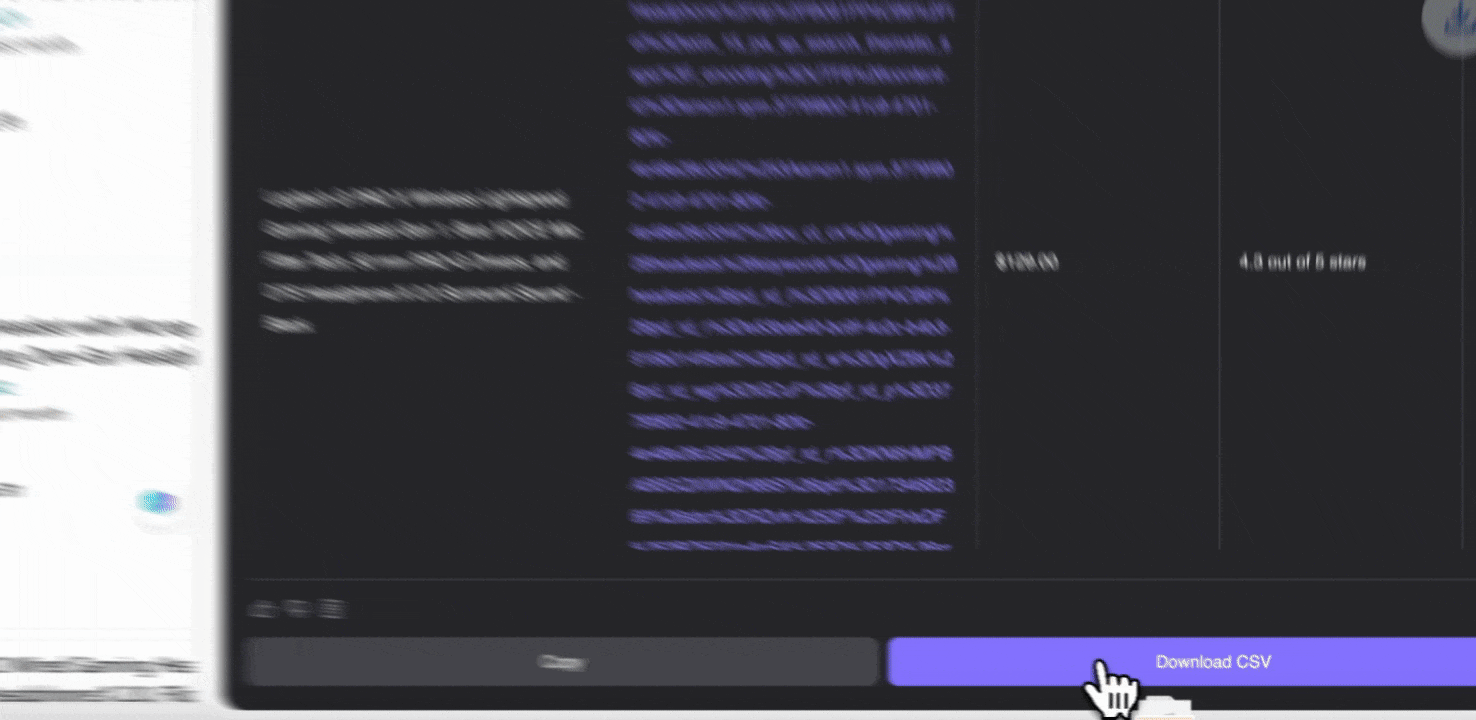
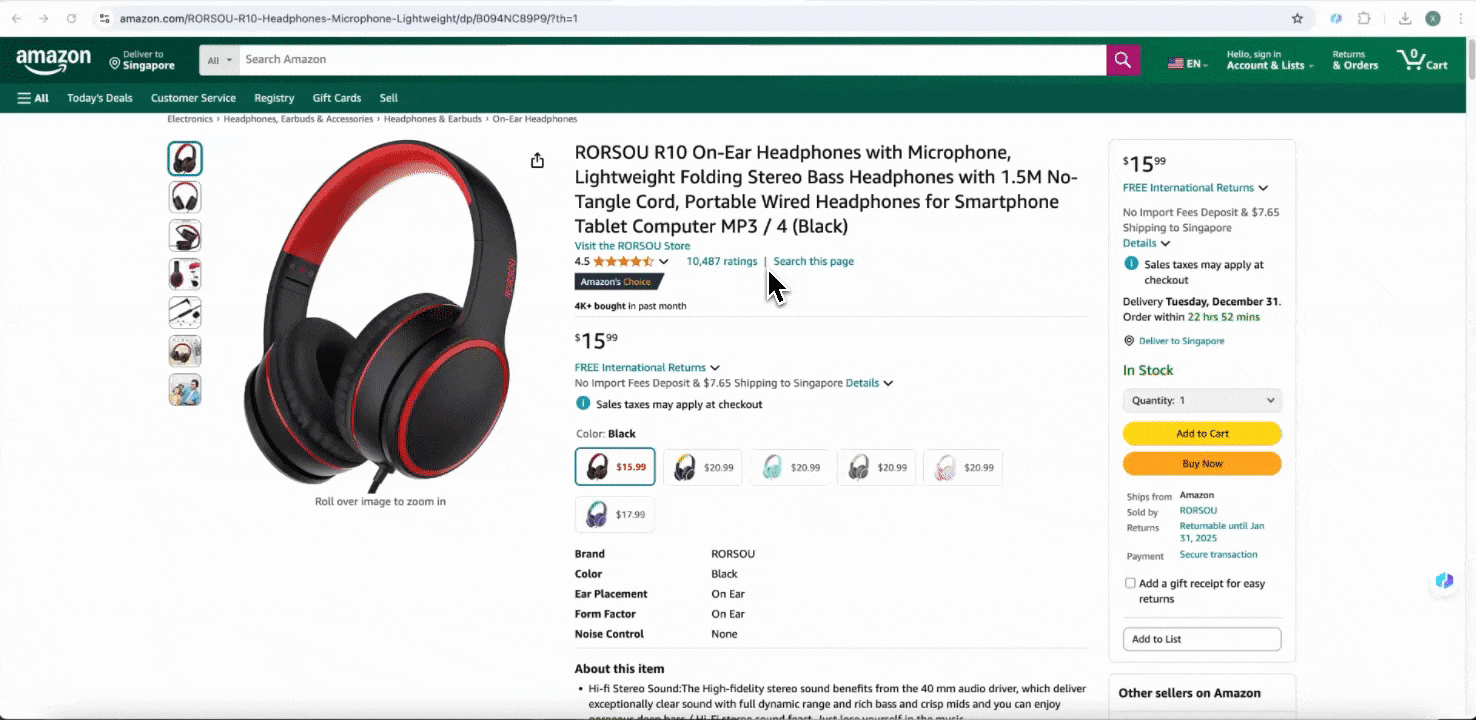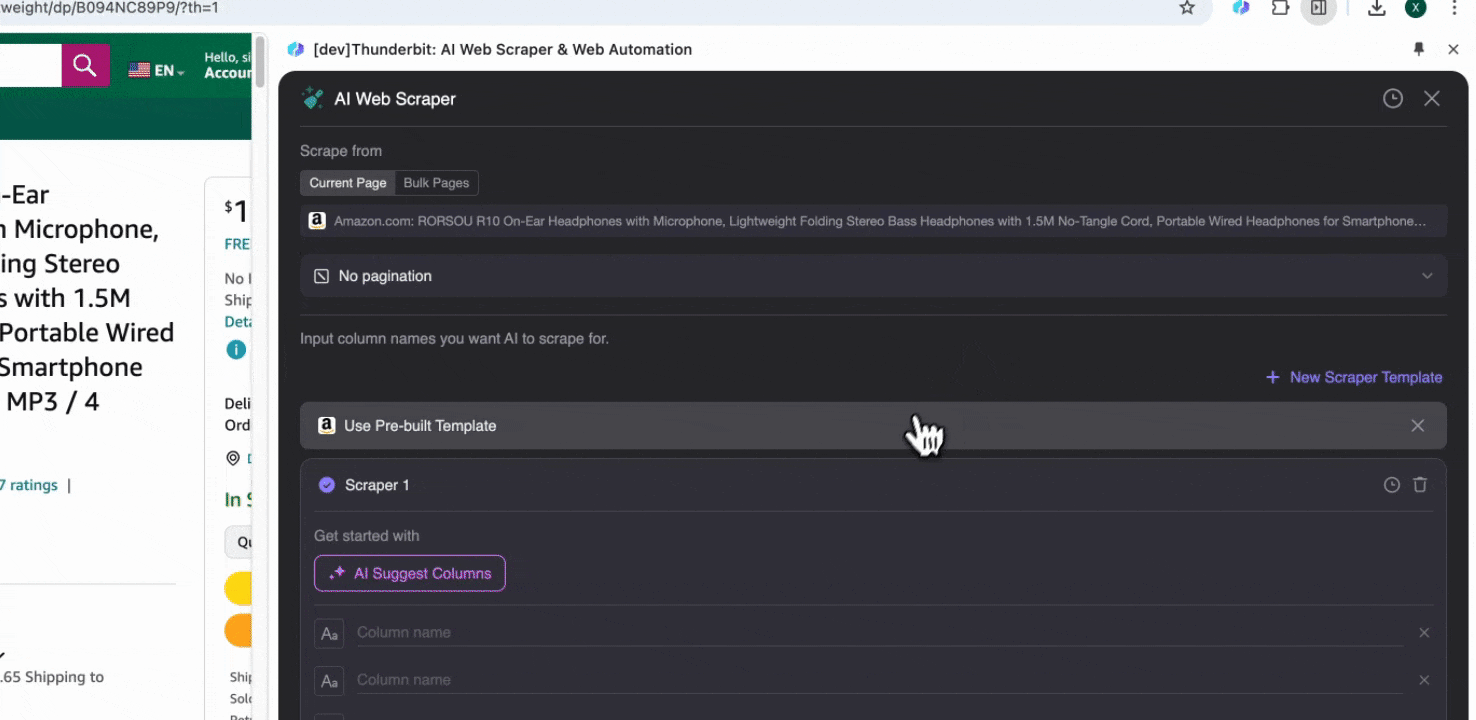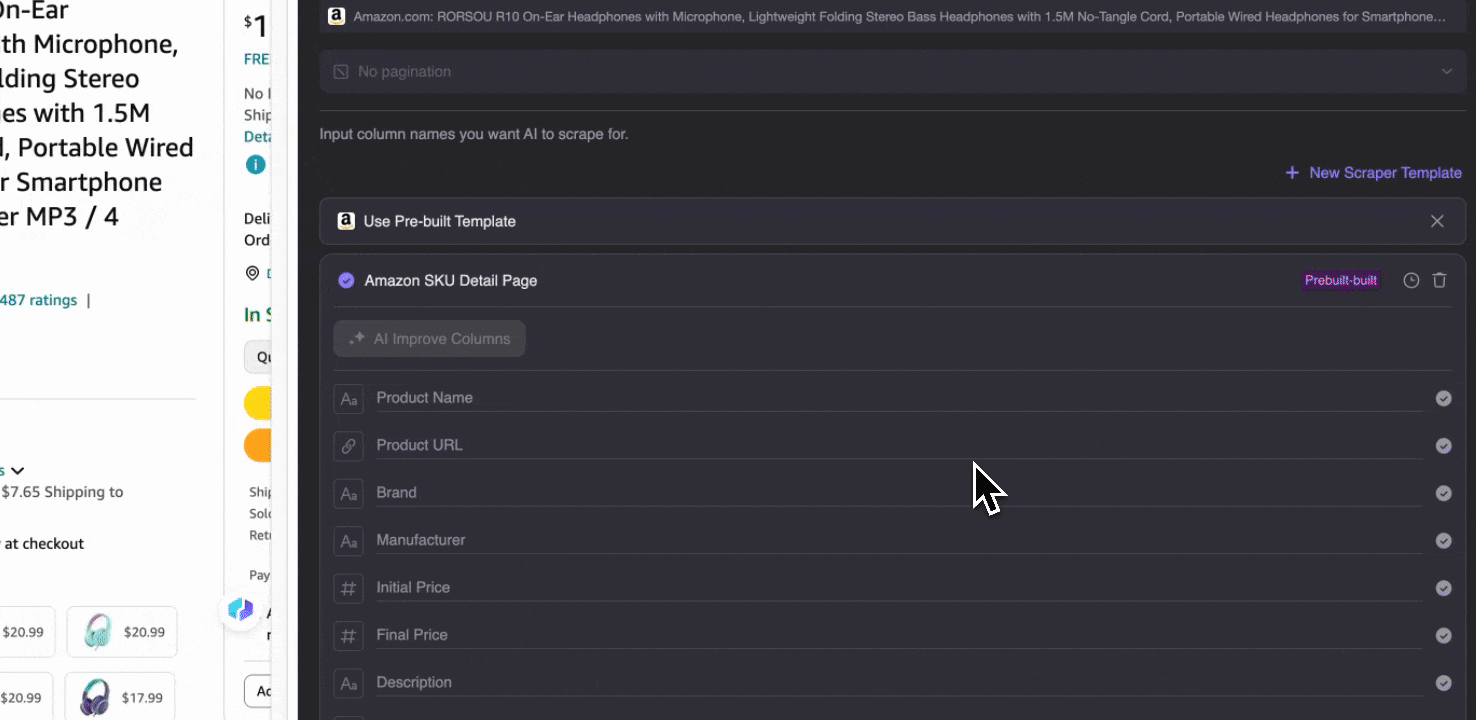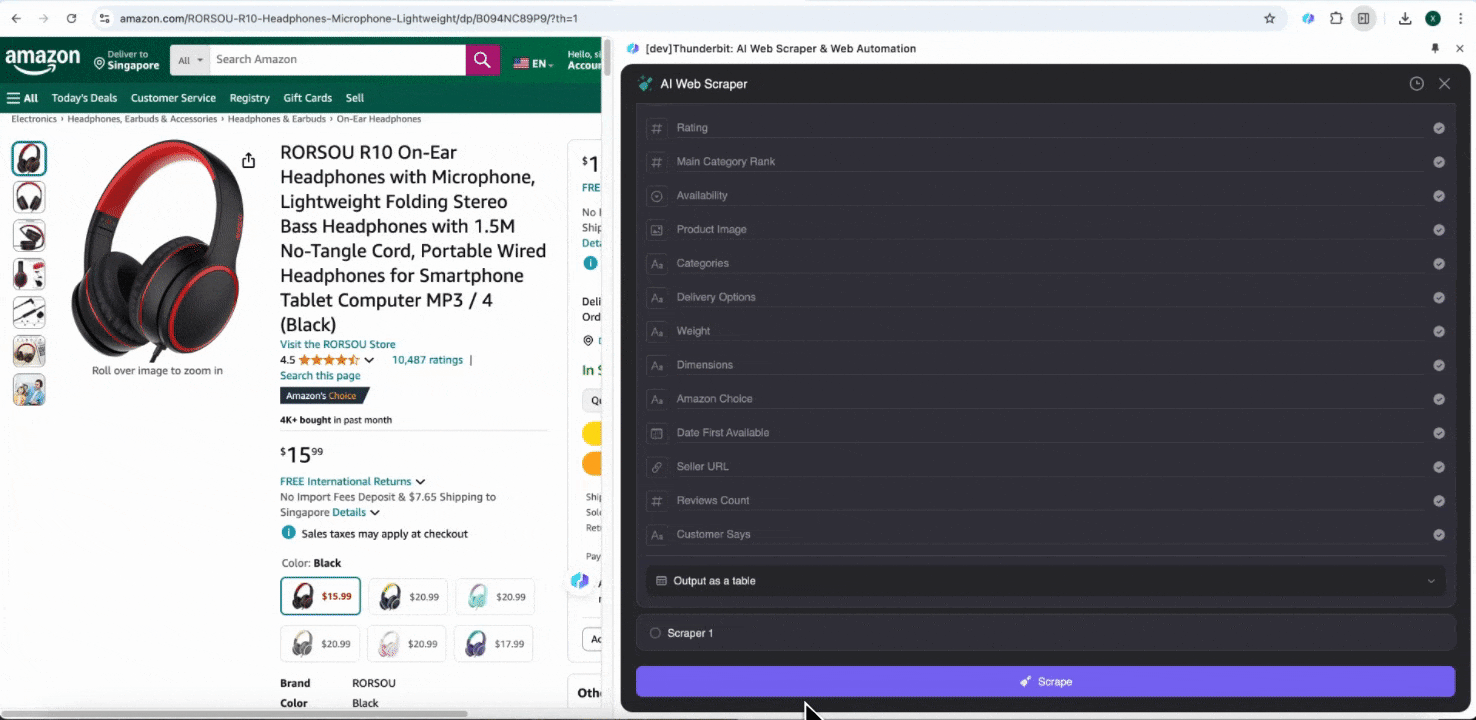
Open the Amazon website in your Chrome browser, search or browse to find the page you want to extract data from, then click the Thunderbit icon in the top right corner of your Chrome browser to open the Thunderbit extension and click "AI Web Scraper."
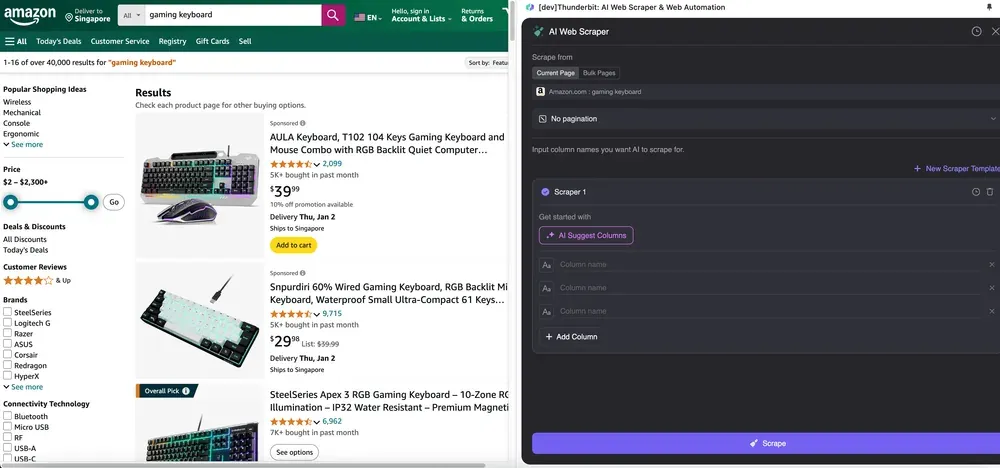
Step 2: Customize the Data Fields You Want to Extract
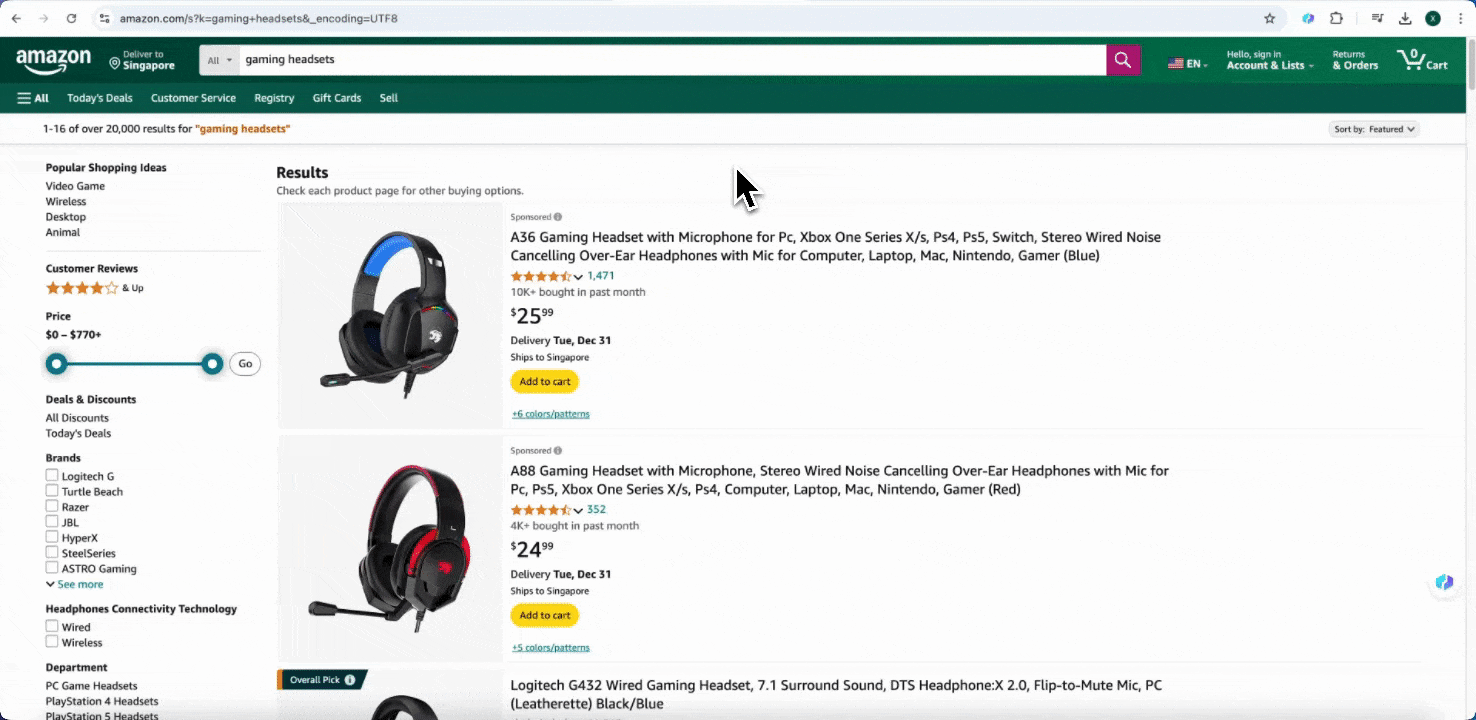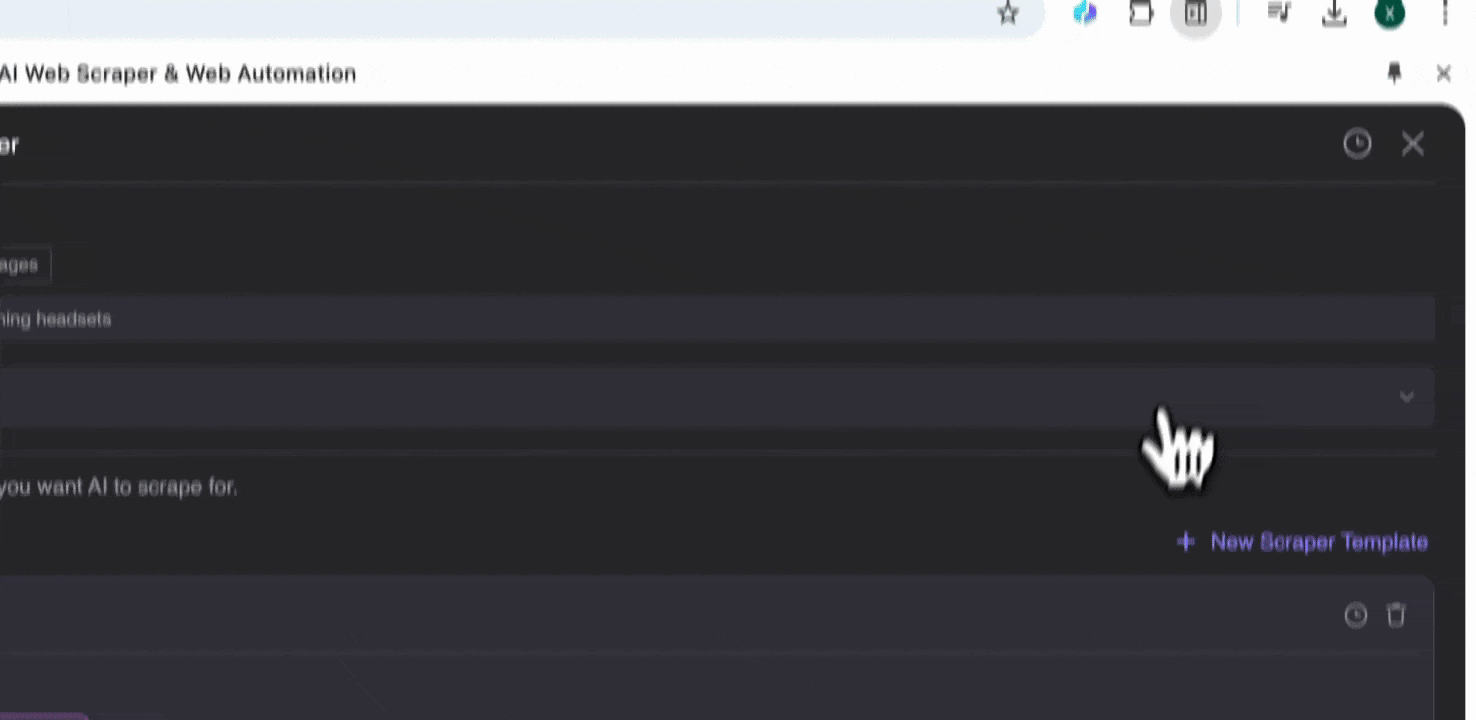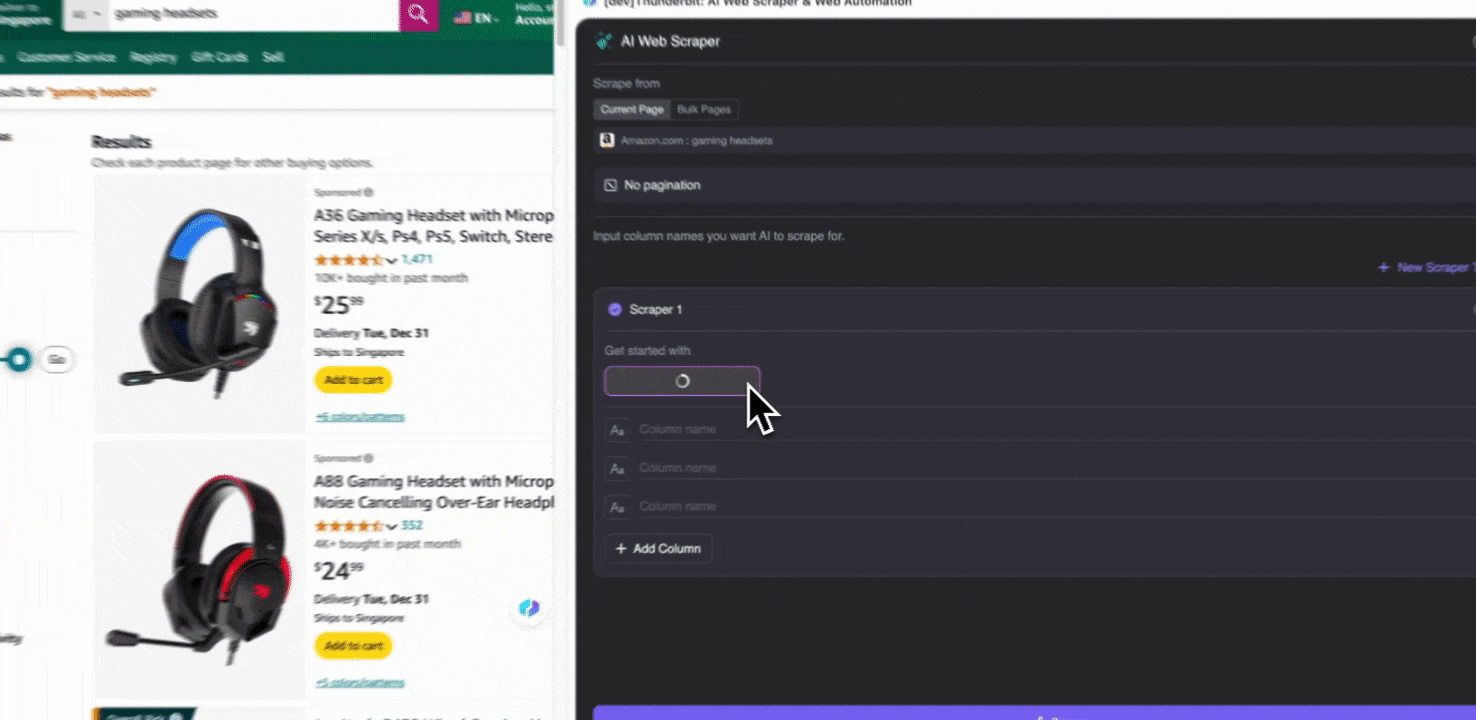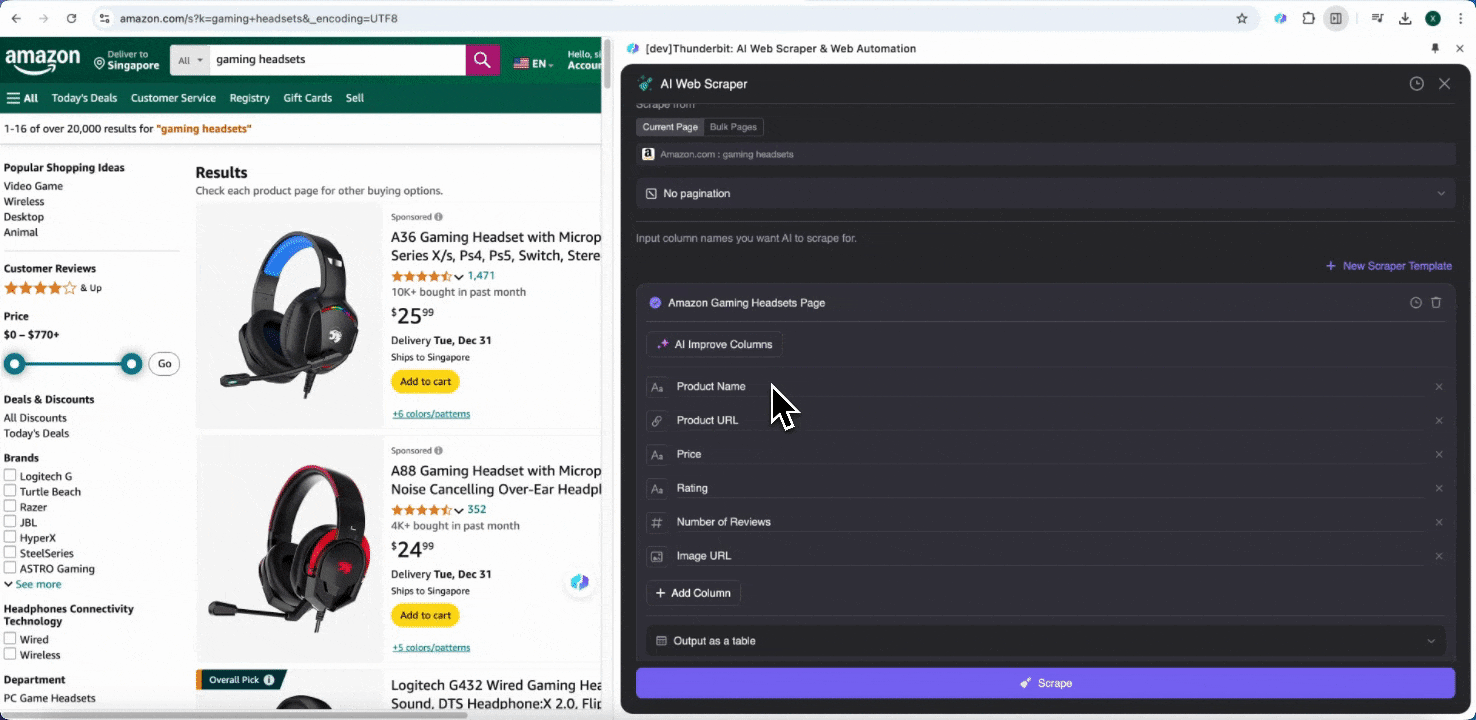
If you're unsure about the data tags you want, click AI Suggest Columns to let Thunderbit's AI automatically generate reliable column names. You can also describe the data labels you want in natural language and fill them in the column name field. Choose icons to switch the data type you want, whether it's image, URL, text, number, or other data types, and scrape the corresponding data.
After filling in the initial column names, you can choose AI Improve Columns to let AI further optimize your entries. You can also add column detailed instructions to customize your needs. For example, you can request that the product type column categorizes products into men's, women's, children's, and other categories. Thunderbit will categorize each data entry in that column into the four categories you defined. You can also ask Thunderbit to convert all prices in the price column to your desired currency type using the current exchange rate, easily obtaining the values you want for analysis without worrying about currency inconsistencies.
Finally, you can customize the amount of data you want. For Amazon product pages, you can choose click pagination and select the number of pages you want to scrape. Thunderbit will automatically turn pages and extract all data from each page.
Step 3: Download the Scraped Data or Export As a Table
With the Thunderbit web scraper extension, you can export scraped data in various ways. Choose output as a table, then download the CSV file locally, or select save to Google Sheets, Notion, or Airtable. Log in to your account and export directly to these online file management collaboration platforms.
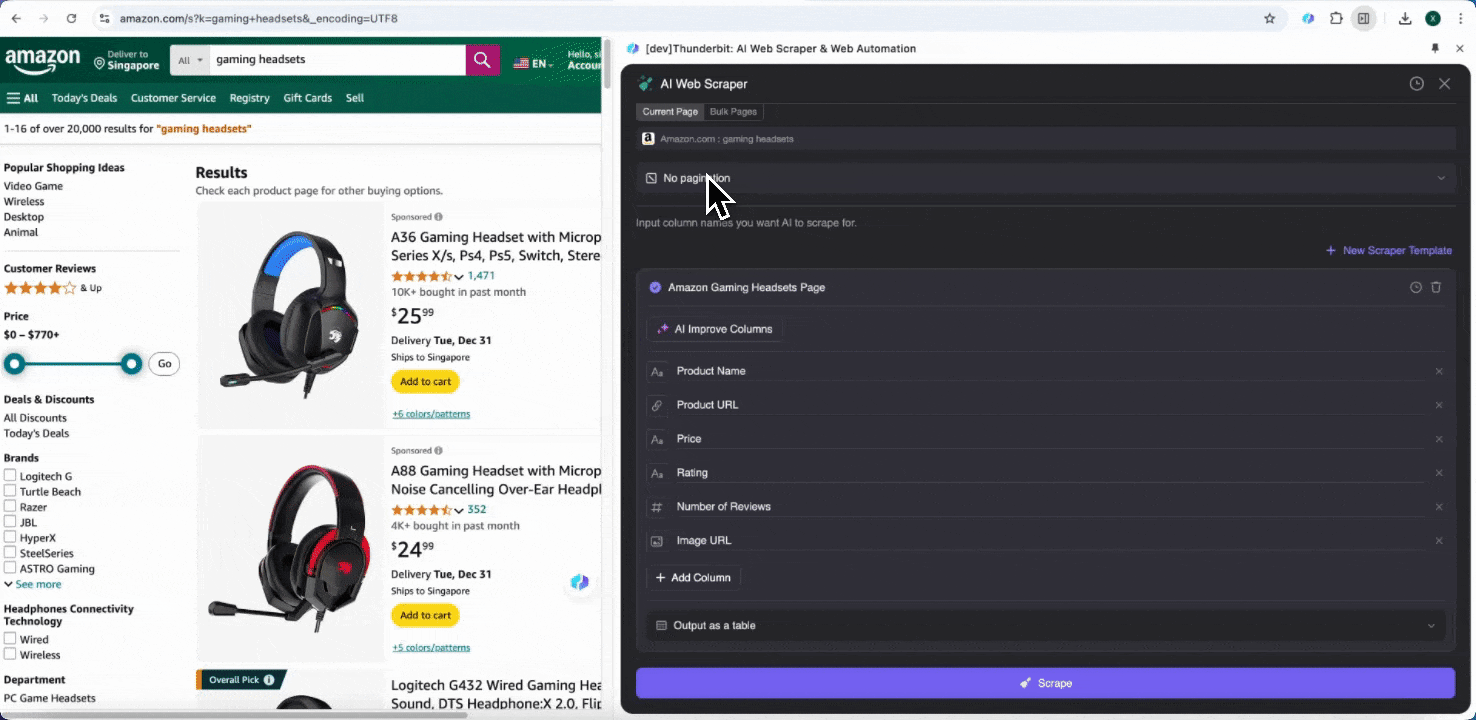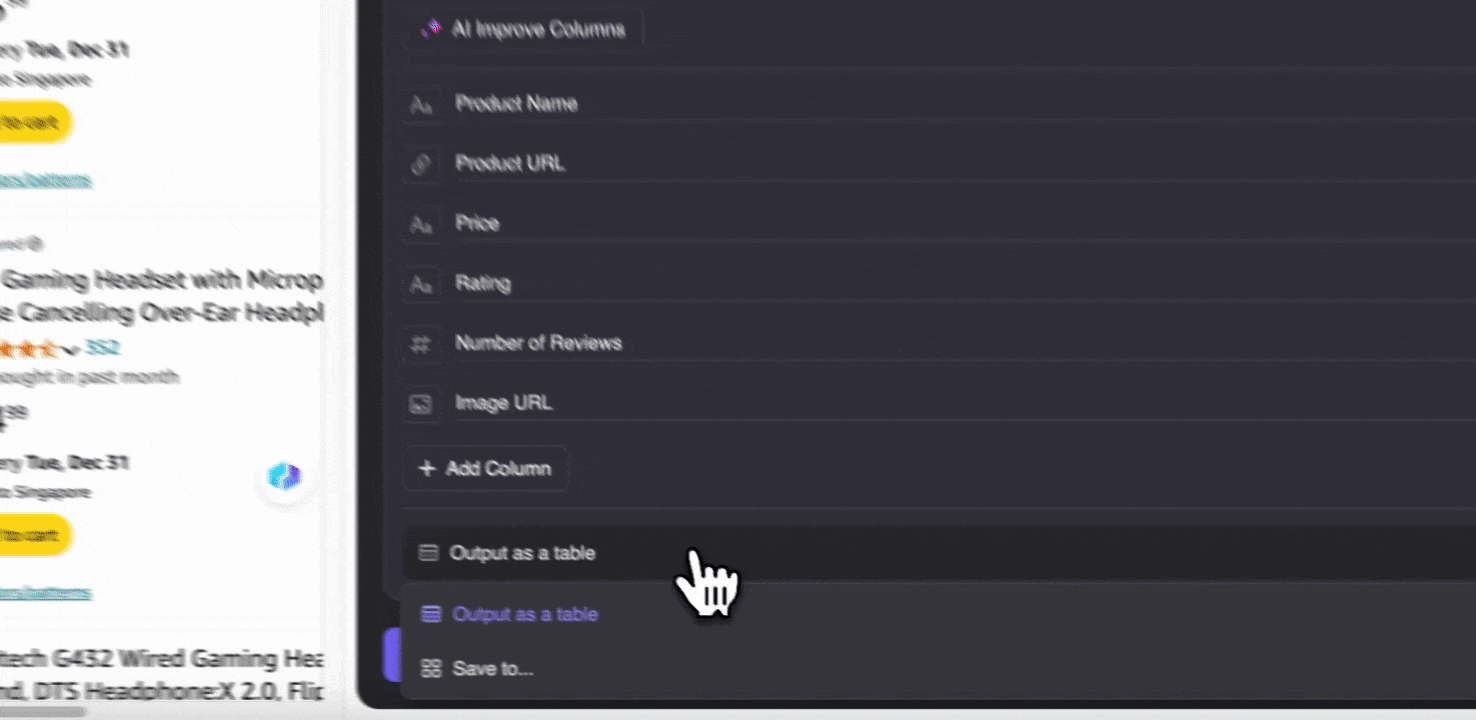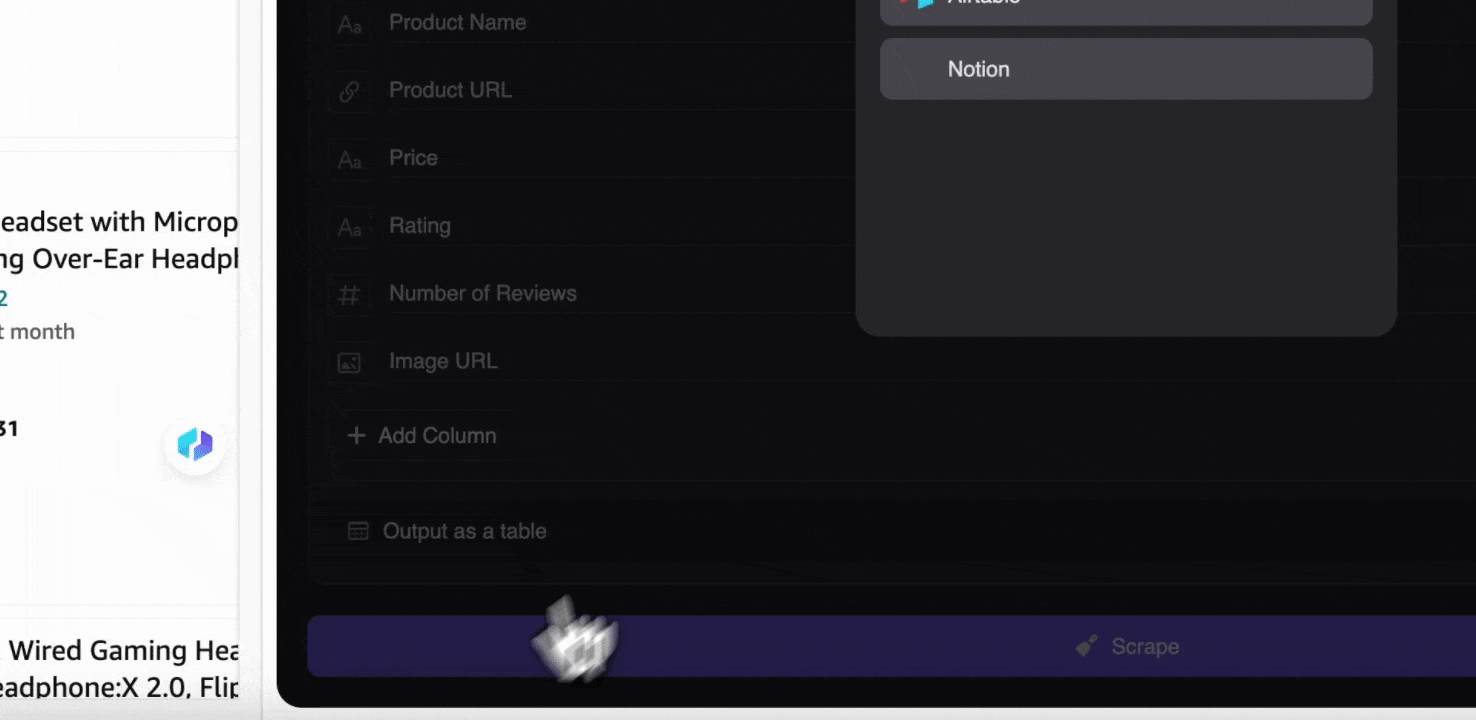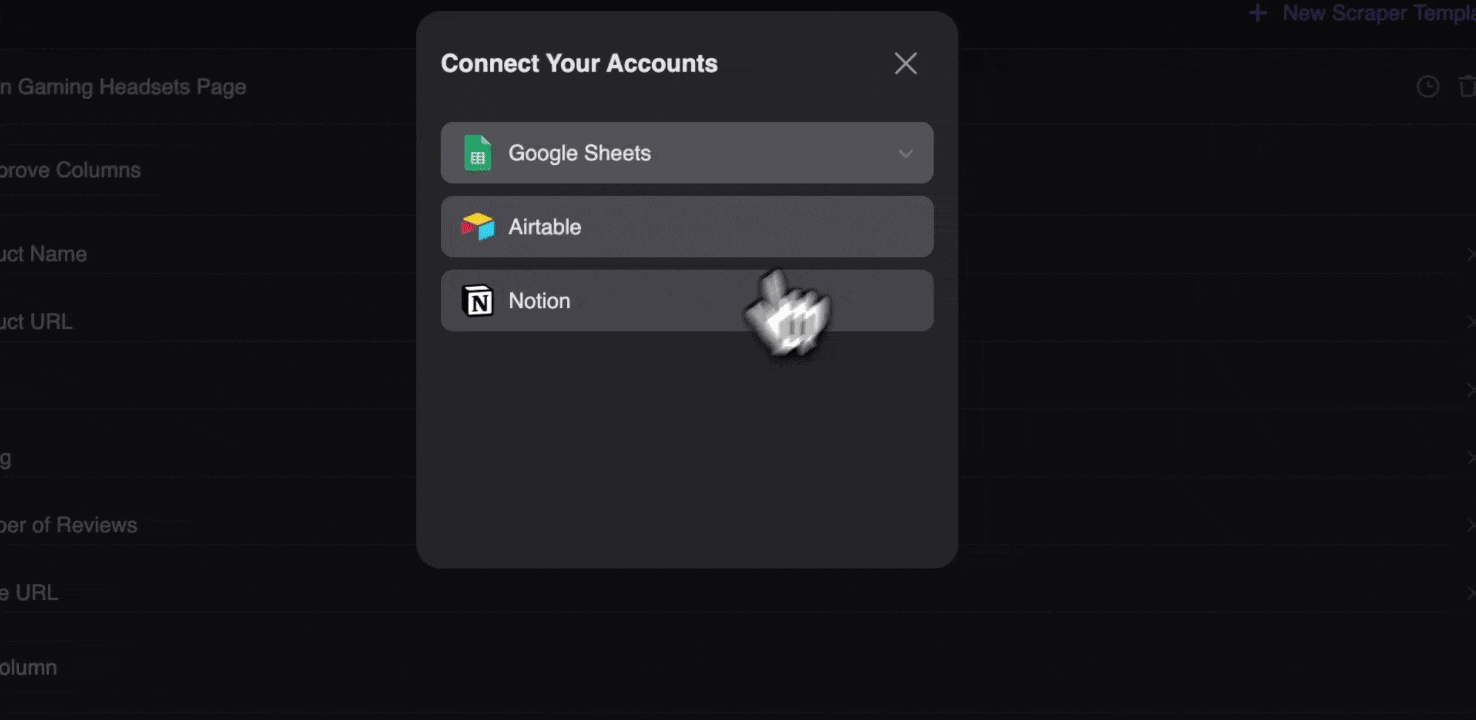
Scrape Amazon SKU Data with AI in 2 clicks
Scraping with Traditional Web Scraper
Besides the latest AI tools, you can also use traditional web scraper tools with lightweight code and APIs to scrape Amazon product data.
ScraperAPI: Retrieve Amazon product data in JSON format with API
ScraperAPI offers an efficient Amazon data collection API that helps you scrape product details, reviews, search results, and pricing information from Amazon and returns it in a structured JSON format. Here's how to use the API for scraping.
Step 1: Set Up Python Environment
First, ensure you have Python 3.8 or later installed. Then, install common analysis libraries like Pandas and web scraping libraries like requests and BeautifulSoup. These libraries help you easily extract data from web pages.
Step 2: Create a ScraperAPI Account
Visit the ScraperAPI website to create a free account and get your API key. You can use this key to access ScraperAPI in your code.
Step 3: Prepare the Code
Create a dedicated directory locally and write a Python script to implement data scraping. Here's a basic workflow:
- Get Amazon Search URL: Search for your desired product on Amazon and copy the search results page URL.
- Build Requests: ScraperAPI will automatically loop through the first five pages of search results. Each page's URL is constructed by adding &page= and the corresponding page number to the base URL.
- Send Requests and Parse Data: Use the get() method to send requests to ScraperAPI. If the request is successful (returns status code 200), parse the page content to extract the desired ASIN (Amazon Standard Identification Number).
- Get Detailed Product Data: By calling the structured data endpoint, you can obtain detailed product information for each ASIN for further data analysis.
Step 4: Refer to More Tutorials
For more detailed usage guides, refer to the ScraperAPI official blog tutorial for more details.
ScrapFly: Prevent Being Blocked and Scrape at Scale
When scraping Amazon data, anti-scraping techniques like IP blocking, CAPTCHAs, and dynamic content loading often pose challenges for scraper developers. ScrapFly provides a powerful API to help bypass these anti-scraping mechanisms, ensuring smooth data scraping.
ScrapFly's core features include:
- Rotating Residential Proxies: Automatically switch IP addresses to prevent IP blocking.
- JavaScript Rendering: Handle dynamic content loading and scrape JavaScript-rendered web pages.
- Full Browser Automation: Control browsers to scroll, input, and click on objects.
- Format Conversion: Scrape as HTML, JSON, Text, or Markdown.
With just a few lines of code, you can use ScrapFly to scrape Amazon data. Here's a simple example:
import scrapfly_sdk
# Create a client
client = scrapfly_sdk.ScraperClient(api_key="your_api_key")
# Send a request
response = client.scrape(url="<https://www.amazon.com/s?k=product_name>")
# Get the returned data
print(response.json())
By using ScrapFly, your scraper can handle Amazon's various anti-scraping mechanisms, increasing the success rate of data scraping. Whether it's simple product information scraping or complex review analysis, ScrapFly is a highly practical tool. For more detailed usage guides, refer to ScrapFly's official tutorial.
Scraping with Python: Traditional Coding Methods
For tech-savvy individuals familiar with coding, you can also try writing Python code to scrape Amazon product data. Here's a simple example for your reference.
Step 1: Set Up the Prerequisites
First, create a dedicated folder for your project.
mkdir amazonscraper
Then, install the necessary libraries in this folder.
pip install beautifulsoup4
pip install requests
Now, create a Python file with any name you wish. This will be the main file where we will keep our code. I am naming it amazon.py.
Step 2: Make a GET Request to the Target Page
Let's make a GET request to our target page using the requests library.
import requests
from bs4 import BeautifulSoup
target_url = "<https://www.amazon.com/s?k=gaming+headsets&_encoding=UTF8>"
headers = {
"accept-language": "en-US,en;q=0.9",
"accept-encoding": "gzip, deflate, br",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7"
}
response = requests.get(target_url, headers=headers)
Step 3: Scrape Amazon Products Data
Now we need to decide what we are going to extract from the target page.
# Check if the request was successful
if response.status_code == 200:
# Parse the page content
soup = BeautifulSoup(response.content, 'html.parser')
# Find all product listings
products = soup.find_all('div', {'data-component-type': 's-search-result'})
# Iterate over each product and extract details
for product in products:
# Extract product title
title = product.h2.text.strip()
# Extract product price
price = product.find('span', 'a-price')
if price:
price = price.find('span', 'a-offscreen').text.strip()
else:
price = "Price not available"
# Extract product rating
rating = product.find('span', 'a-icon-alt')
if rating:
rating = rating.text.strip()
else:
rating = "Rating not available"
# Print product details
print(f"Title: {title}")
print(f"Price: {price}")
print(f"Rating: {rating}")
print("-" * 40)
else:
print(f"Failed to retrieve the page. Status code: {response.status_code}")
FAQs
1. Is it legal to scrape amazon.com?
Yes, scraping Amazon’s public data is legal! Like many other websites, Amazon makes its product listings and other public information available for anybody to browse. You can scrape and collect that freely available data without violating Amazon’s terms of service.
2. Can I try Thunderbit for free?
Yes, Thunderbit offers free page extraction and data extraction features. While some advanced functionalities may require payment, the basic data extraction capabilities are typically free.
3. What data can I scrape from Amazon?
You can scrape a variety of data from Amazon, including product titles, prices, descriptions, reviews, ratings, and seller information. This data can be valuable for market research, price monitoring, and competitive analysis.
4. How frequently should I scrape Amazon data?
The frequency depends on the type of data you're after. If you're monitoring prices or competitor activity, you might want to scrape data daily or weekly. For more static information like product details, monthly scraping might suffice.
Learn More
- How to Scrape Website Data into Excel using AI
- 6 Best Twitter (x.com) Scrapers in 2025
- How to Scrape Data from PDF using AI
Try AI Web Scraper Get Started Free




