

“Você pode ter dados sem informação, mas não pode ter informação sem dados.” — Daniel Keys Moran*
Estima-se que existam hoje mais de 1,5 bilhão de sites na internet, com cerca de 2 milhões de novas publicações todos os dias. Esse oceano de dados guarda insights valiosos para orientar decisões, mas há um detalhe: cerca de 80% dele é não estruturado, o que significa que precisa de processamento extra para ser útil. É aí que entram as ferramentas de web scraping, que se tornam essenciais para quem quer aproveitar dados online.
Se você está começando com web scraping, termos como componentes web e HTML podem parecer um pouco intimidador. Mas, na era da IA, esses desafios ficam muito mais fáceis de superar. As ferramentas de scraping com IA de hoje ajudam você a começar sem exigir conhecimento técnico profundo. Elas tornam possível coletar e processar dados rapidamente, sem precisar saber programar.
As Melhores Ferramentas e Softwares de Web Scraping
- Thunderbit para um Raspador Web IA fácil de usar e com os melhores resultados
- Browse AI para monitoramento em tempo real e extração em massa de dados
- Bardeen AI para automação sem código com integrações extensas com apps
- Web Scraper para uma experiência de web scraping visual mais profissional
- Octoparse para scraping poderoso sem código, evitando bloqueio de IP e detecção de bots
- Diffbot para API avançada de extração de dados com IA e grafos de conhecimento
Experimente usar IA para Web Scraping
Tente! Você pode clicar, explorar e executar o fluxo de trabalho enquanto assiste.
Como Funciona o Web Scraping?
Web scraping consiste, basicamente, em recolher dados de sites. Você dá a uma ferramenta um conjunto de instruções, e ela vai buscar texto, imagens ou o que precisar, montando tudo numa tabela a partir de uma página. Isso pode ser útil para tudo, desde acompanhar preços em sites de e-commerce até reunir dados de pesquisa ou até montar uma boa planilha no Excel ou no Google Sheets.
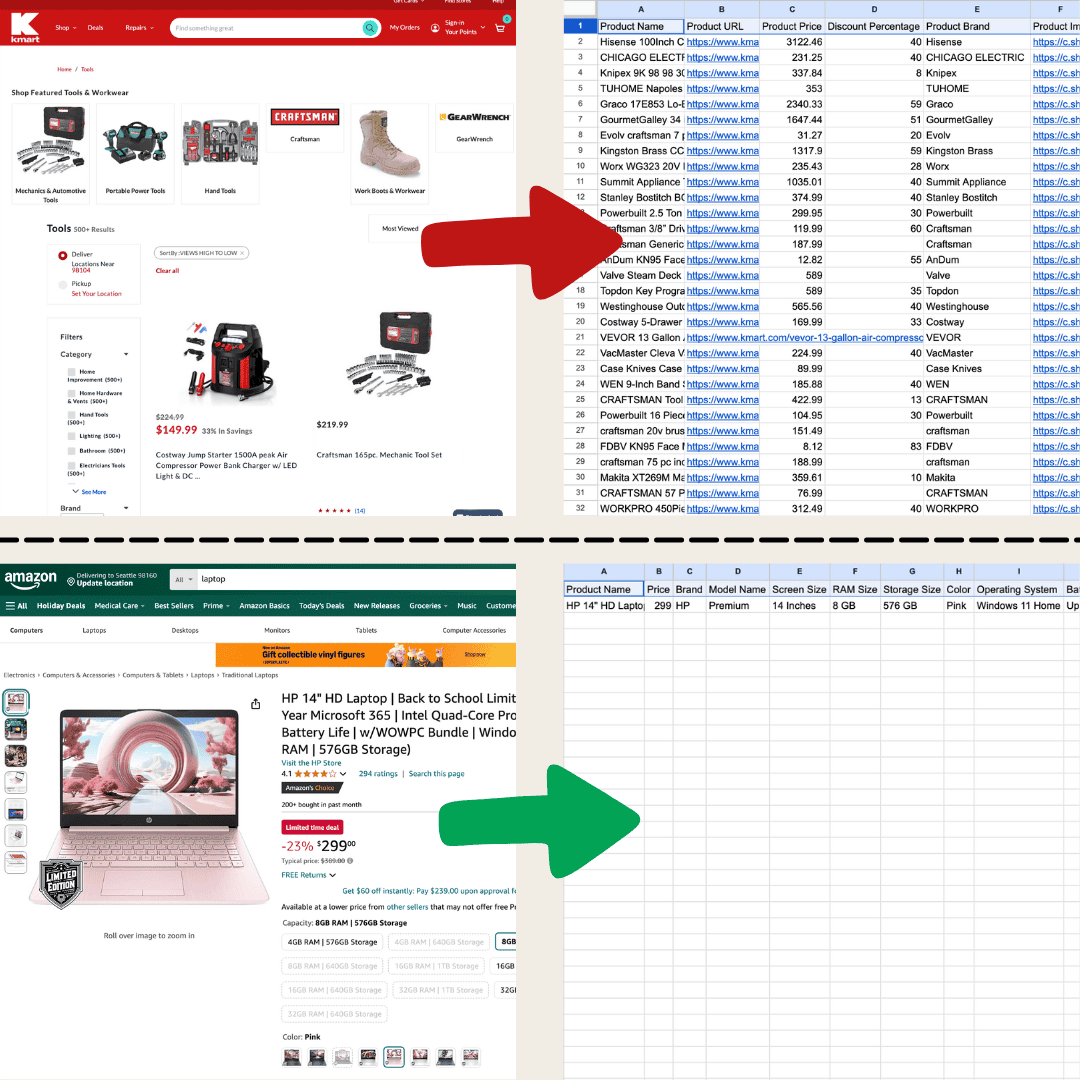 Fiz isso com Thunderbit usando o Raspador Web IA.
Fiz isso com Thunderbit usando o Raspador Web IA.
Existem algumas maneiras de fazer isso. No nível mais simples, você poderia apenas copiar e colar tudo manualmente, mas isso dá muito trabalho quando há uma grande quantidade de dados. Por isso, a maioria das pessoas usa um entre três métodos: raspadores web tradicionais, raspadores web com IA ou código personalizado.
Raspadores web tradicionais funcionam definindo regras específicas sobre quais dados extrair com base na estrutura da página. Por exemplo, você pode configurá-lo para coletar nomes de produtos ou preços a partir de certas tags HTML. Eles funcionam melhor em sites que não mudam com tanta frequência, já que qualquer ajuste no layout exige voltar e adaptar o raspador.
 Usar um raspador tradicional leva bastante tempo para aprender e provavelmente exigirá dezenas de cliques para concluir a configuração.
Usar um raspador tradicional leva bastante tempo para aprender e provavelmente exigirá dezenas de cliques para concluir a configuração.
Extraia dados de qualquer site usando IA Get Started Free
Raspadores web com IA basicamente significam: o ChatGPT lê o site inteiro e depois extrai o conteúdo com base no que você precisa. Ele pode lidar com extração de dados, tradução e resumo ao mesmo tempo. Essas ferramentas usam processamento de linguagem natural para analisar e entender o layout do site, o que significa que conseguem lidar melhor com mudanças na página. Se o site reorganizar um pouco suas seções, um Raspador Web IA pode se ajustar sem que você precise reescrever nada. Por isso, são ótimos para sites que mudam com frequência ou têm estruturas mais complexas.
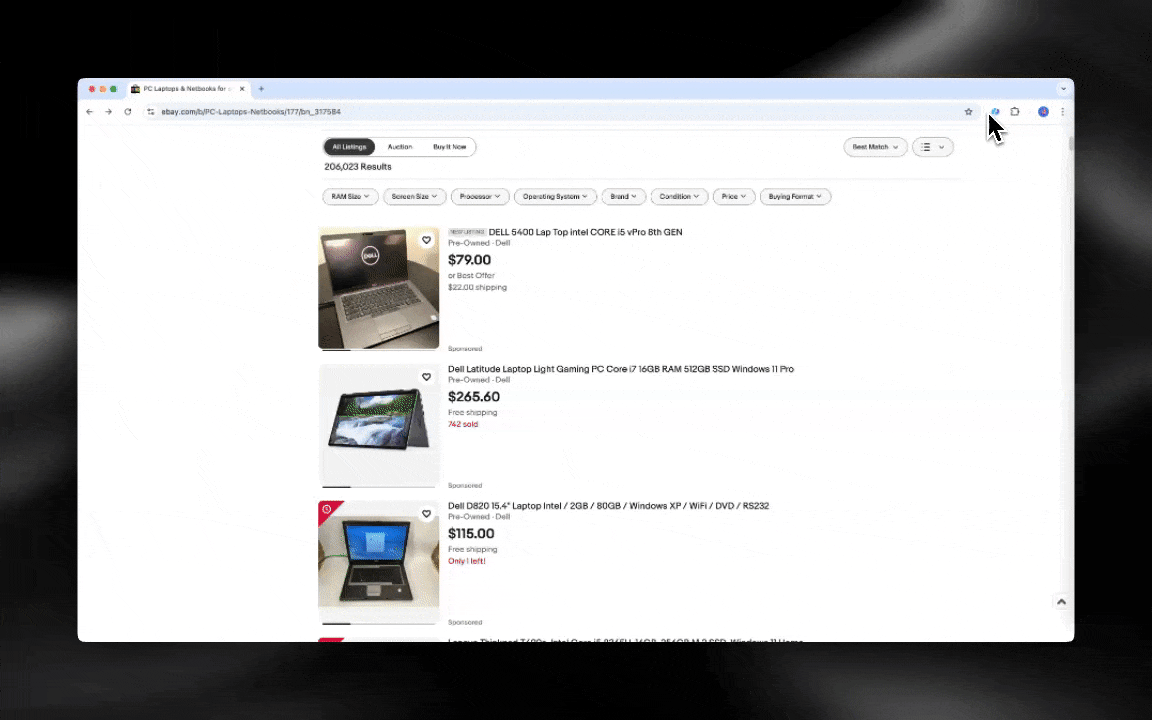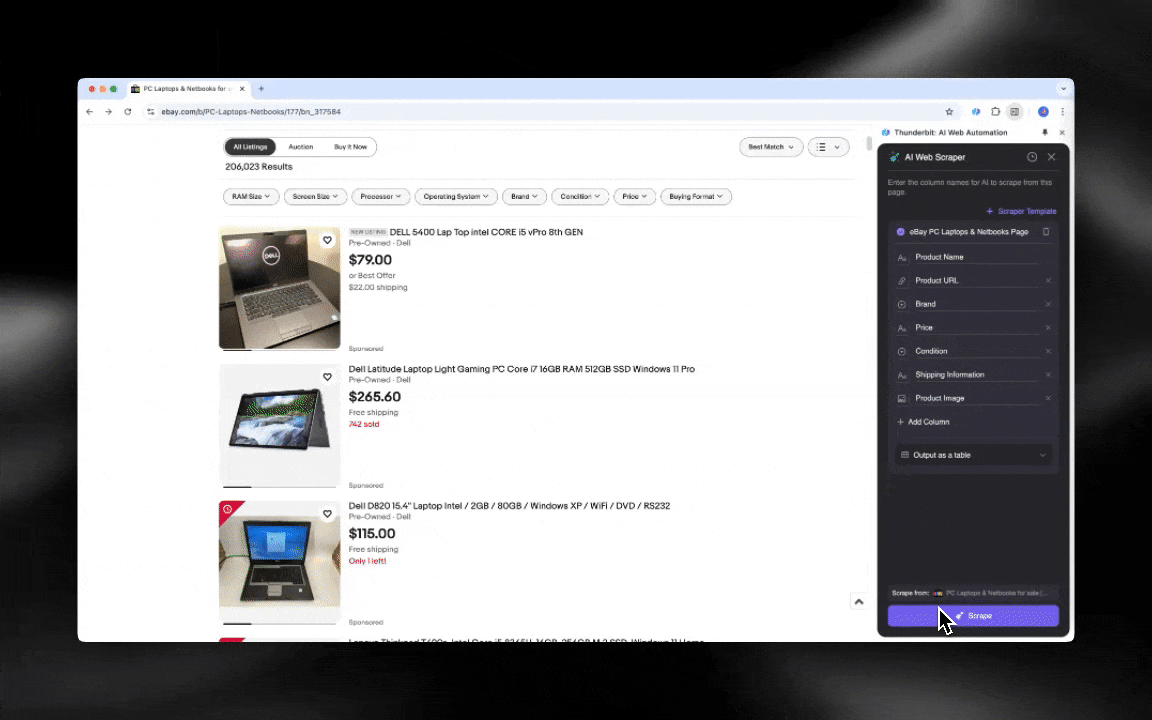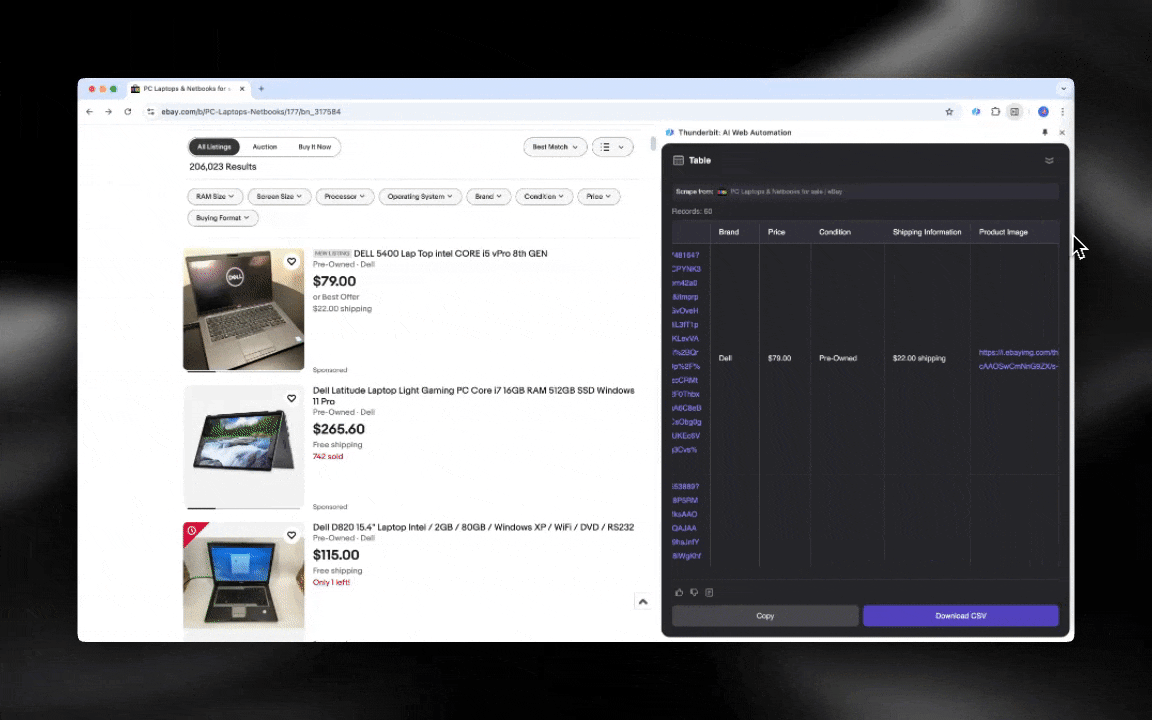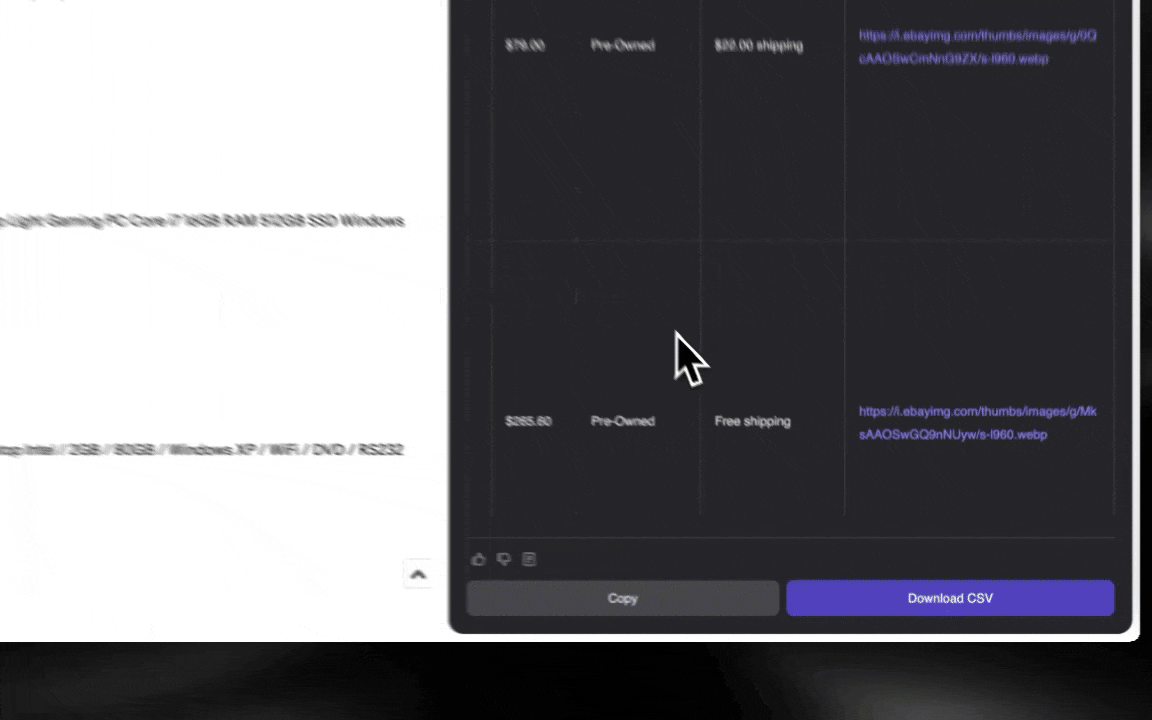 O Raspador Web IA é fácil de começar a usar e entrega dados detalhados em apenas alguns cliques!
O Raspador Web IA é fácil de começar a usar e entrega dados detalhados em apenas alguns cliques!
Qual deles você deve escolher? Depende. Se você se sente à vontade para mexer com código ou precisa coletar grandes volumes de dados em um site popular, raspadores tradicionais podem ser muito eficientes. Mas, se você está começando com web scraping ou quer algo que acompanhe as atualizações do site, os Raspadores Web IA costumam ser a melhor escolha. Confira a tabela abaixo para cenários mais detalhados!
| Cenário | Melhor escolha |
|---|---|
| Extração leve em páginas como diretórios, sites de compras ou qualquer site com listas | Raspador Web IA |
| A página tem menos de 200 linhas de dados, e criar um raspador com um raspador web tradicional leva tempo demais | Raspador Web IA |
| Os dados que você precisa extrair exigem um formato específico para enviar para outro lugar. Por exemplo: extrair informações de contato para enviar ao HubSpot. | Raspador Web IA |
| Sites amplamente usados em escala, como dezenas de milhares de páginas de produtos da Amazon ou listagens de imóveis do Zillow. | Raspador Web Tradicional |
As Melhores Ferramentas e Softwares de Web Scraping em Resumo
| Ferramenta | Preços | Principais recursos | Vantagens | Desvantagens |
|---|---|---|---|---|
| Thunderbit | A partir de US$ 9/mês, com plano gratuito disponível | Raspador Web IA, detecta e formata dados automaticamente, suporta vários formatos, exportação com um clique, interface amigável. | Sem código, com suporte de IA, integrações com apps como Google Sheets | A extração em grande escala pode ser lenta; recursos avançados podem custar mais |
| Browse AI | A partir de US$ 48,75/mês, com plano gratuito disponível | Interface sem código, monitoramento em tempo real, extração em massa de dados, integração com fluxos de trabalho. | Fácil de usar, integra com Google Sheets e Zapier | Páginas complexas precisam de configuração extra; o scraping em massa pode causar timeouts |
| Bardeen AI | A partir de US$ 60/mês, com plano gratuito disponível | Automação sem código, integra com mais de 130 apps, o MagicBox transforma tarefas em fluxos de trabalho. | Integrações extensas, escalável para empresas | Curva de aprendizado acentuada para novos usuários, configuração demorada |
| Web Scraper | Grátis para uso local, US$ 50/mês para a nuvem | Criação visual de tarefas, suporta sites dinâmicos (AJAX/JavaScript), scraping na nuvem. | Funciona bem em sites dinâmicos | Exige conhecimento técnico para a melhor configuração |
| Octoparse | A partir de US$ 119/mês, com plano gratuito disponível | Scraping sem código, detecção automática de elementos da página, scraping na nuvem com tarefas agendadas, biblioteca de modelos para sites comuns. | Recursos poderosos para sites dinâmicos, lida com restrições | Sites complexos exigem aprendizado |
| Diffbot | A partir de US$ 299/mês | API de extração de dados, API sem regras, PLN para texto não estruturado, grafo de conhecimento extenso. | Extração forte com IA, ampla integração via API, scraping em grande escala | Curva de aprendizado para usuários sem perfil técnico, tempo de configuração |
O Melhor Web Scraper na Era da IA
Thunderbit
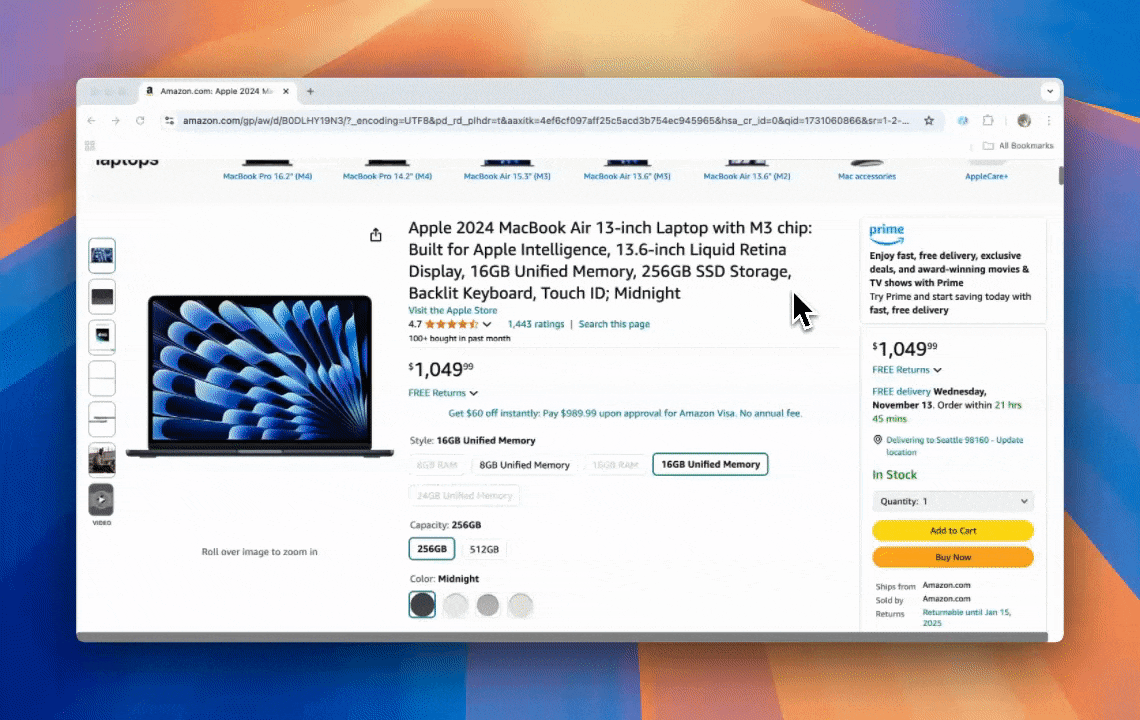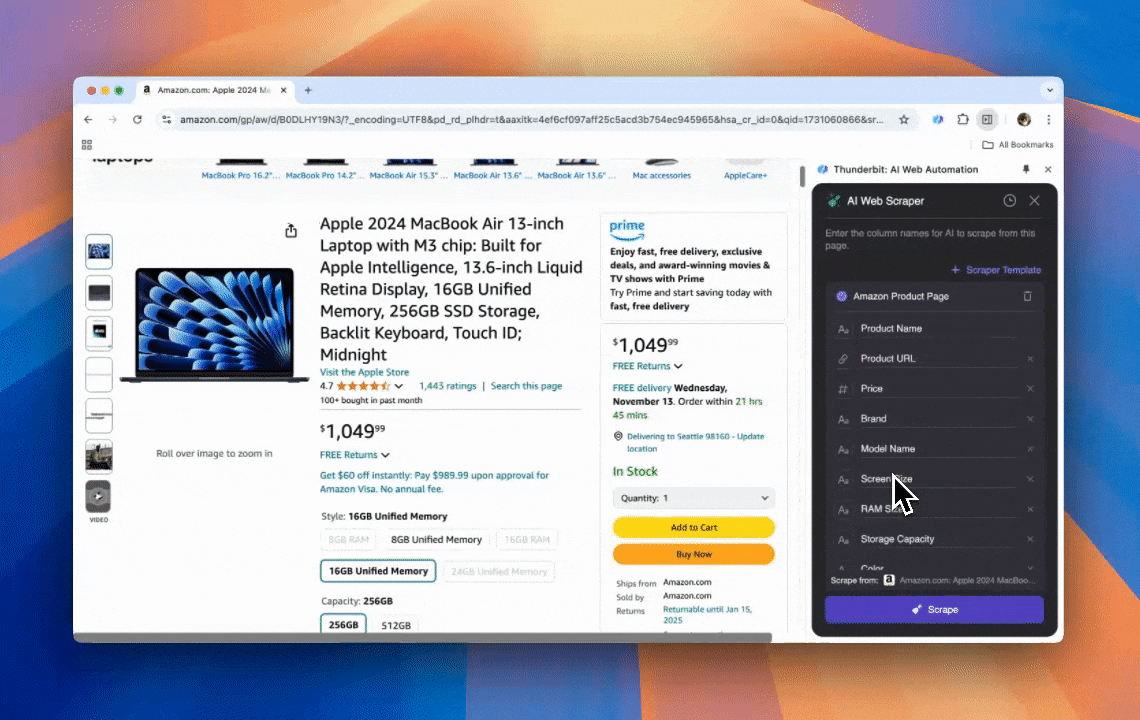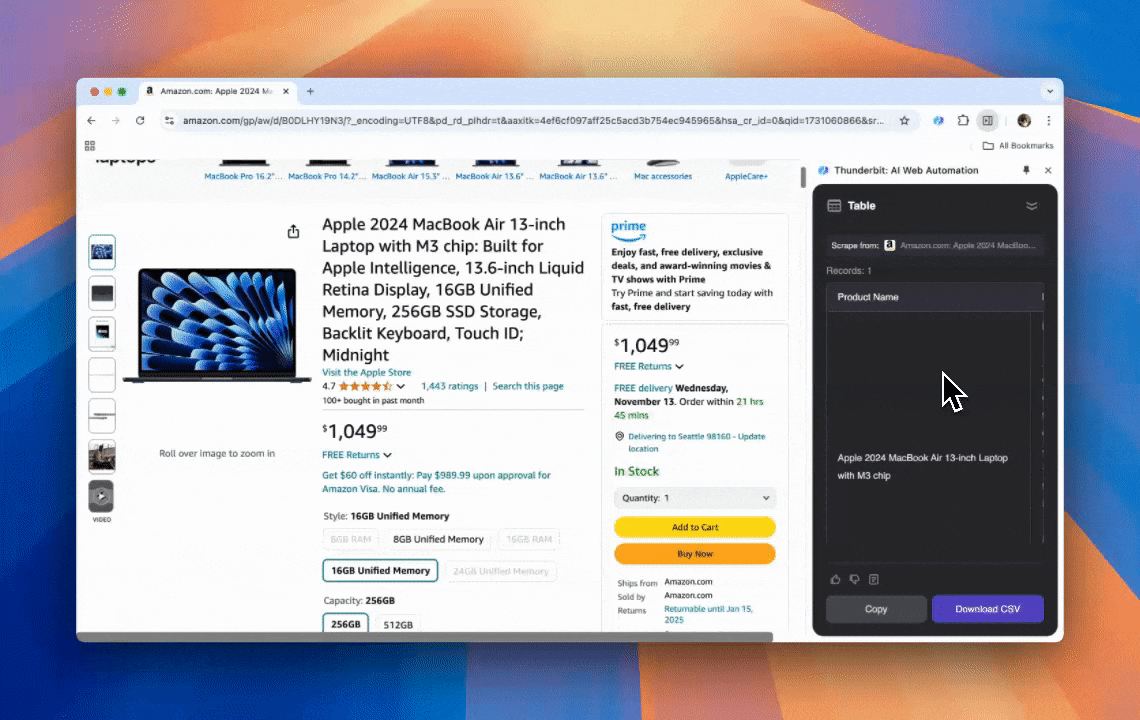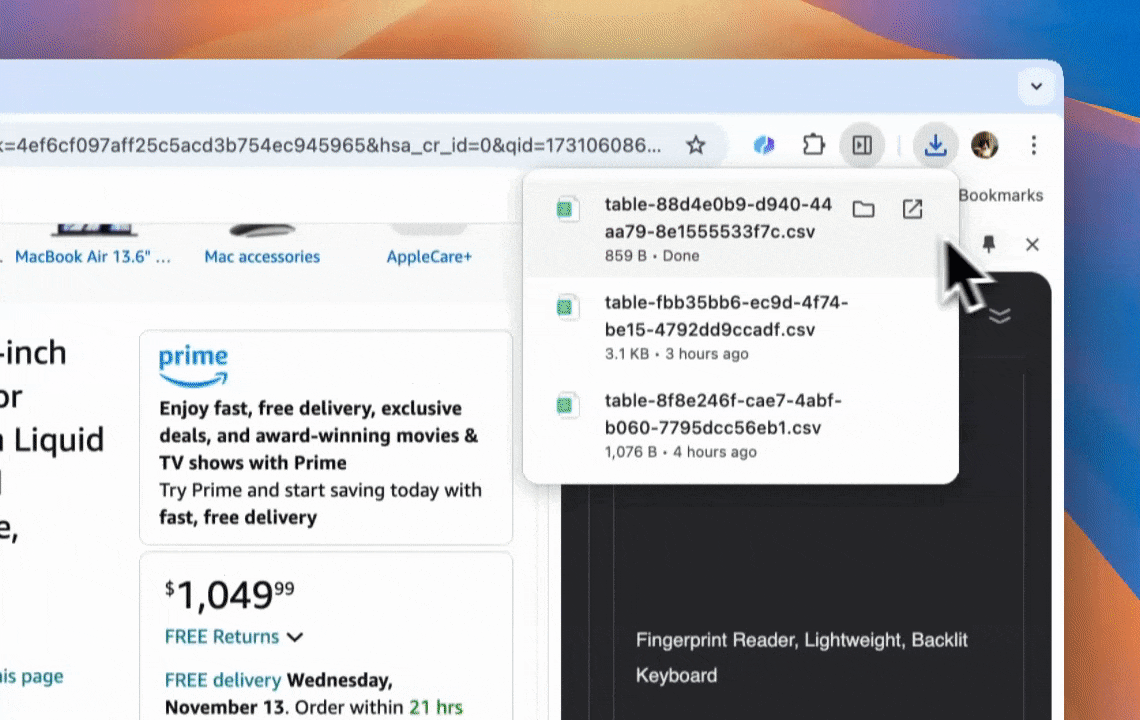
Thunderbit é uma ferramenta poderosa e fácil de usar de automação web com IA, que permite a usuários sem habilidades de programação extrair e organizar dados com facilidade. Com sua extensão para Chrome, o Raspador Web IA da Thunderbit simplifica a coleta de dados — os usuários podem extrair dados da web rapidamente, sem interagir manualmente com elementos da página ou configurar raspadores individuais para diferentes layouts.
Principais recursos
- Flexibilidade com IA: o Raspador Web IA da Thunderbit detecta e formata dados da web automaticamente, eliminando a necessidade de seletores CSS.
- A experiência de scraping mais fácil: tudo o que você precisa fazer é clicar em “AI suggest column” e depois em “Scrape” na página de onde deseja extrair os dados. É só isso.
- Suporte para vários formatos de dados: Thunderbit pode extrair URLs, imagens e exibir os dados capturados em vários formatos.
- Processamento automatizado de dados: a IA da Thunderbit pode reformatar dados em tempo real, incluindo resumir, categorizar e traduzi-los para o formato necessário.
- Exportação fácil de dados: exporte dados para Google Sheets, Airtable ou Notion com um clique, simplificando a gestão de dados.
- Interface amigável: uma interface intuitiva torna a ferramenta acessível para usuários de todos os níveis.
Preço
Thunderbit oferece planos em camadas, a partir de US$ 9 por mês para 5.000 créditos. O plano vai até US$ 199 para 240.000 créditos. Além disso, no plano anual, você recebe todos os créditos antecipadamente.
Vantagens:
- Forte suporte de IA que simplifica a extração e o processamento de dados.
- Sem código, acessível para usuários de todos os níveis.
- Perfeito para extrações leves, como diretórios, sites de compras etc.
- Grande capacidade de integração para exportação direta para apps populares.
Desvantagens:
- A extração de dados em grande escala pode levar algum tempo para garantir precisão.
- Alguns recursos avançados podem exigir uma assinatura paga.
Quer mais informações? Comece instalando o Thunderbit ou descubra como extrair sites facilmente com a Thunderbit.
Melhor Web Scraper para Monitoramento de Dados e Extração em Massa
Browse AI
Browse AI é uma ferramenta robusta de coleta de dados sem código, criada para ajudar os usuários a extrair e monitorar dados sem escrever código. O Browse AI tem alguns recursos de IA, mas ainda não chega ao nível de um scraping totalmente baseado em IA. Ainda assim, ele facilita bastante para quem está começando.
Principais recursos
- Interface sem código: permite criar fluxos de trabalho personalizados com poucos cliques.
- Monitoramento em tempo real: usa bots para acompanhar mudanças nas páginas e entregar informações atualizadas.
- Extração em massa de dados: é capaz de lidar com até 50.000 entradas de dados de uma vez.
- Integração com fluxos de trabalho: conecta vários bots para processamento de dados mais complexo.
Preço
A partir de US$ 48,75 por mês, incluindo 2.000 créditos. Há um plano gratuito, que oferece 50 créditos por mês para testar os recursos básicos.
Vantagens:
- Oferece integrações com Google Sheets e Zapier.
- Bots prontos simplificam tarefas comuns de extração de dados.
Desvantagens:
- Pode exigir configuração extra para páginas complexas.
- A velocidade do scraping em massa pode variar, às vezes resultando em timeouts.
Melhor Web Scraper para Integração de Fluxos de Trabalho
Bardeen AI
Bardeen AI é uma ferramenta de automação sem código criada para simplificar fluxos de trabalho conectando vários apps. Embora use IA para criar automações personalizadas, ela não tem a adaptabilidade de uma ferramenta completa de scraping com IA.
Principais recursos
- Automação sem código: permite que os usuários configurem fluxos de trabalho com cliques.
- MagicBox: descreve tarefas em linguagem simples, que o Bardeen AI converte em fluxos de trabalho.
- Amplas opções de integração: integra com mais de 130 apps, incluindo Google Sheets, Slack e LinkedIn.
Preço
A partir de US$ 60 por mês, com 1.500 créditos (cerca de 1.500 linhas de dados). O plano gratuito oferece 100 créditos por mês para testar os recursos básicos.
Vantagens:
- As amplas opções de integração atendem a diversas necessidades de negócios.
- Flexível e escalável para empresas de todos os tamanhos.
Desvantagens:
- Novos usuários podem precisar de tempo para aprender toda a plataforma.
- A configuração inicial pode ser demorada.
Melhor Web Scraper Visual para Quem Já Tem Experiência
Web Scraper
Sim, você leu certo: a ferramenta se chama "Web Scraper". Web Scraper é uma extensão de navegador popular para Chrome e Firefox que permite aos usuários extrair dados sem programar, oferecendo uma forma visual de criar tarefas de scraping. No entanto, talvez você precise passar alguns dias assistindo e aprendendo com os tutoriais acima para dominar totalmente essa ferramenta. Se quiser deixar o scraping mais fácil para o seu cérebro, escolha o Raspador Web IA.
Principais recursos
- Criação visual: permite configurar tarefas de scraping clicando em elementos da página.
- Suporte a sites dinâmicos: consegue lidar com requisições AJAX e JavaScript em sites dinâmicos.
- Scraping na nuvem: agenda tarefas por meio do Web Scraper Cloud para extrações periódicas.
Preço
Grátis para uso local; os planos pagos começam em US$ 50/mês para recursos em nuvem.
Vantagens:
- Funciona bem em sites dinâmicos.
- Gratuito para uso local.
Desvantagens:
- Exige conhecimento técnico para uma configuração ideal.
- Mudanças exigem testes complexos.
Melhor Web Scraper para Evitar Bloqueio de IP e Detecção de Bots
Octoparse
Octoparse é um software versátil para usuários mais técnicos coletarem e monitorarem dados específicos da web sem código, ideal para necessidades de dados em grande escala. O Octoparse não depende do navegador do usuário para funcionar; em vez disso, usa servidores em nuvem para extração de dados. Assim, pode oferecer vários métodos para contornar bloqueio de IP e certas detecções de bots em sites.
Principais recursos
- Operação sem código: os usuários podem criar tarefas de scraping sem escrever código, o que o torna acessível para usuários com diferentes níveis de conhecimento técnico.
- Detecção automática inteligente: detecta automaticamente os dados da página, identificando rapidamente os elementos disponíveis para scraping, o que simplifica a configuração.
- Scraping na nuvem: suporta coleta de dados 24/7 na nuvem com tarefas agendadas, oferecendo recuperação flexível de dados.
- Biblioteca extensa de modelos: oferece centenas de modelos prontos, permitindo acesso rápido a dados de sites populares sem configuração complexa.
Preço
O plano do Octoparse começa em US$ 119 por mês, incluindo 100 tarefas. Também há um plano gratuito com 10 tarefas por mês para testar as funções básicas.
Vantagens:
- Recursos poderosos suportam scraping de sites dinâmicos com alta adaptabilidade.
- Oferece soluções para lidar com restrições de scraping e problemas de conteúdo dinâmico.
Desvantagens:
- Estruturas complexas de sites podem exigir mais tempo de configuração.
- Novos usuários podem precisar de tempo para aprender as técnicas de uso.
Melhor Web Scraper para API Avançada de Extração de Dados com IA
Diffbot
Diffbot é uma ferramenta avançada de extração de dados da web que usa IA para transformar conteúdo não estruturado em dados estruturados. Com APIs poderosas e um grafo de conhecimento, o Diffbot ajuda os usuários a extrair, analisar e gerenciar informações da web, sendo adequado para vários setores e aplicações.
Principais recursos
- API de extração de dados: o Diffbot oferece uma API de extração de dados sem regras, permitindo que os usuários simplesmente forneçam uma URL para a extração automática de dados, eliminando a necessidade de definir regras personalizadas para cada site.
- API de processamento de linguagem natural: extrai entidades estruturadas, relacionamentos e sentimento de textos não estruturados, ajudando os usuários a construir seus próprios grafos de conhecimento.
- Grafo de conhecimento: o Diffbot tem um dos maiores grafos de conhecimento, conectando uma ampla quantidade de dados de entidades, incluindo detalhes sobre indivíduos e organizações.
Preço
O plano do Diffbot começa em US$ 299 por mês, incluindo 250.000 créditos (equivalente a aproximadamente 250.000 extrações de páginas da web via API).
Vantagens:
- Fortes recursos de extração de dados sem regras, com alta adaptabilidade.
- Ampla variedade de opções de integração via API para conectar facilmente aos sistemas existentes.
- Suporta extração de dados em grande escala, adequada para aplicações de nível empresarial.
Desvantagens:
- A configuração inicial pode exigir algum tempo de aprendizado para usuários sem perfil técnico.
- É preciso escrever um programa para chamar a API e usá-la.
Para Que Você Pode Usar Raspadores?
Se você está começando com web scraping, aqui estão alguns casos de uso populares para ajudar a dar os primeiros passos. Muitas pessoas usam raspadores para obter listagens de produtos da Amazon, extrair dados imobiliários do Zillow ou reunir informações de empresas no Google Maps. Mas isso é só o começo — você pode usar o Raspador Web IA da Thunderbit para coletar dados de praticamente qualquer site, simplificando tarefas e economizando tempo no seu fluxo de trabalho diário. Seja para pesquisa, monitoramento de preços ou construção de bancos de dados, o web scraping abre inúmeras maneiras de colocar os dados da internet para trabalhar a seu favor.
Perguntas frequentes
-
Web scraping é legal?
Web scraping normalmente é legal, mas deve seguir os termos de uso do site e a natureza dos dados acessados. Sempre revise as políticas relevantes e cumpra as diretrizes legais.
-
Preciso de habilidades de programação para usar ferramentas de web scraping?
A maioria das ferramentas apresentadas aqui não exige programação, mas ferramentas como Octoparse e Web Scraper podem se beneficiar de usuários com conhecimento básico de estruturas web e uma mentalidade de programação para uso ideal.
-
Existem ferramentas de web scraping gratuitas?
Sim, há ferramentas gratuitas como BeautifulSoup, Scrapy e Web Scraper, e algumas ferramentas também oferecem planos gratuitos com recursos limitados.
-
Quais são os desafios comuns no web scraping?
Desafios comuns incluem lidar com conteúdo dinâmico, CAPTCHAs, bloqueio de IP e estruturas HTML complexas. Ferramentas e técnicas avançadas podem lidar com esses problemas de forma eficaz.
Saiba mais:
Use IA para trabalhar sem esforço. Get Started Free




