Substackスクレイパー

大手企業のプロフェッショナルに選ばれています










ThunderbitでSubstackデータを解放しましょう
Substackデータをアプリへ直接送信
著者名、記事タイトル、購読者数などのSubstackの公開情報を、手作業でコピー&ペーストするのはやめましょう。Thunderbitなら、1回クリックするだけで抽出したデータをGoogle Sheets、Notion、Airtableへ直接送信できます。面倒な手作業なしで、公開トレンドやコンテンツのパフォーマンスを分析できます。
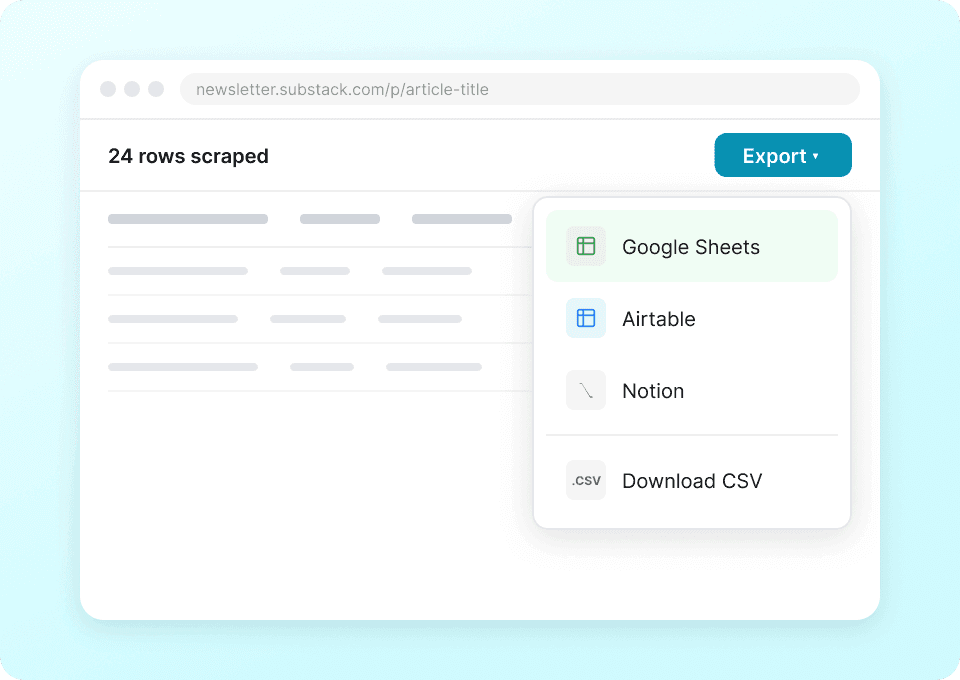
Substackにも対応する万能スクレイパー
サイトごとに別のスクレイパーを使い分ける必要はありません。ThunderbitはSubstackにそのまま対応しており、ほかの人気プラットフォーム向けの事前構築テンプレートも50以上用意されています。公開情報の説明文、記事コンテンツなどを抽出し、同じツールでほかのあらゆるサイトからもデータを収集できます。
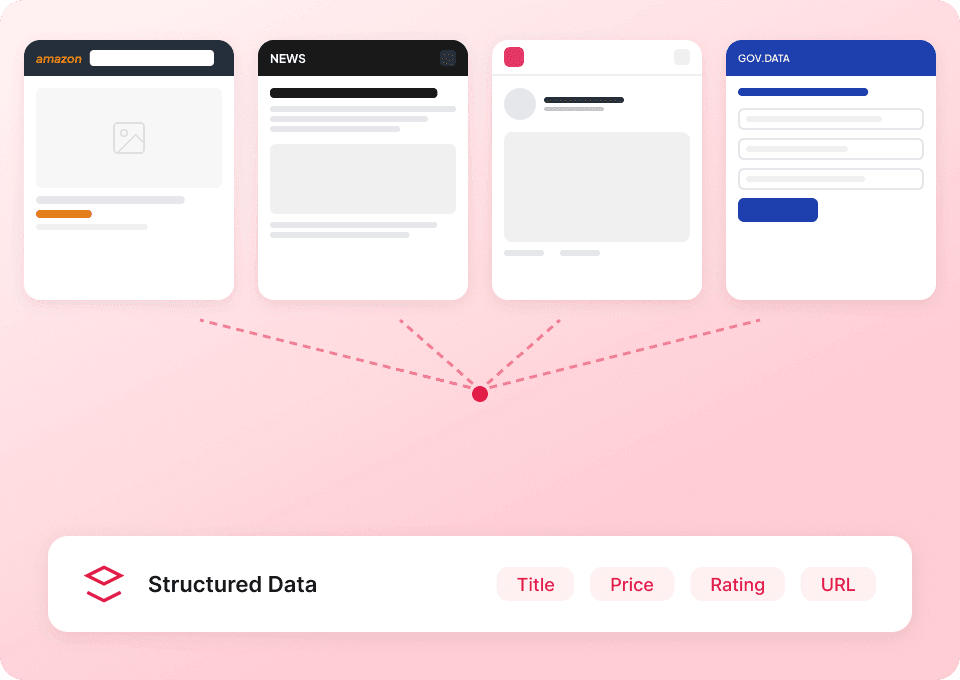
Substackの全体像を把握
Substackの公開一覧ページには要約しか表示されません。Thunderbitは各記事のサブページを自動で訪問し、全文を抽出するため、完全なデータセットを取得できます。記事タイトル、著者名、公開名、記事本文を一度にまとめて取得しましょう。
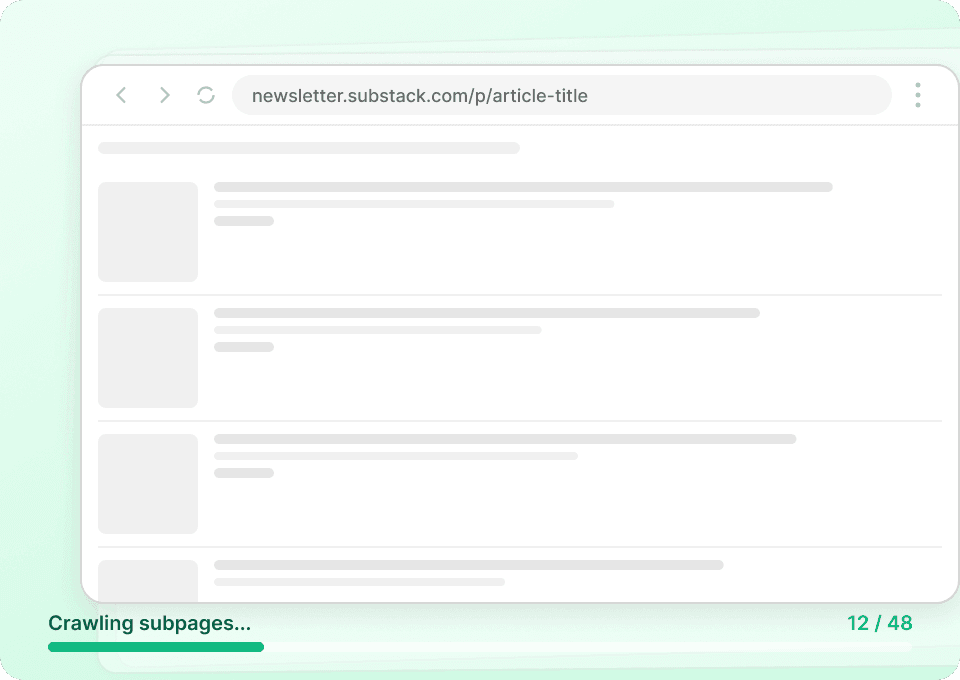
Substackをうまくスクレイピングできずに困っていませんか?
Substackデータで、Thunderbitが従来のスクレイパーより優れている理由をご覧ください。
従来のスクレイパー
昔ながらのやり方Thunderbit
より賢いアプローチ言葉だけでなく、実際の声をご覧ください
Thunderbitに対するユーザーの声をご覧ください。







よくある質問
関連 活用例
ThunderbitのWebスクレイパーの活用例をさらに見る

ユナイテッド航空スクレイパー
United Airlines のフライト番号、到着時刻、出発空港などのデータを、指差しとクリックだけで収集。あとは Thunderbit の AI にお任せください。
詳しく見る ->
TripAdvisor ビジネスリスティングスクレイパー
ThunderbitのTripAdvisorビジネスリストスクレイパーを使えば、TripAdvisorのビジネスリスト、リソースハブ、オーナーフォーラムからデータを抽出できます。AIによるフィールド提案機能で、リソース名、URL、説明文、フォーラムトピック、投稿者、投稿内容などを素早く収集でき、リサーチやマーケティング、分析に活用できます。
詳しく見る ->
ホワイトページスクレイパー
ThunderbitのWhite Pagesスクレイパーは、AIによるフィールド自動提案機能でWhite Pagesの電話帳やビジネスリストからデータを抽出できます。リード獲得やマーケティング、リサーチに役立つ名前・電話番号・住所・ウェブサイトURLを数クリックでまとめて取得可能です。
詳しく見る ->
Trustpilotスクレイパー
Trustpilotのページを、レビュー、評価、レビュアー名が整理されたスプレッドシートに変換します。各ページはThunderbitが読み取るので、コードもコピペも不要です。
詳しく見る ->
Amarillas.com スクレイパー
ThunderbitのAmarillas.comスクレイパーは、Amarillas.comに掲載されているモーテルやレストランなどの構造化データを抽出できるツールです。AIによるフィールド提案機能で、ビジネス名・所在地・連絡先・評価・レビューなどを素早く収集でき、リサーチやマーケティング、リード獲得に活用できます。
詳しく見る ->
Herold スクレイパー
ThunderbitのHeroldスクレイパーを使えば、Heroldの企業や人物検索結果からわずか2クリックでデータを抽出できます。AIによるフィールド提案機能で、企業名、住所、電話番号、メールアドレスなど、リード獲得やリサーチ、マーケティングに役立つ情報を効率的に収集可能。営業チームやマーケター、リサーチャーがHeroldの構造化データを手軽に取得したいときに最適なツールです。
詳しく見る ->データ抽出をさらに加速する準備はできた?
すでに10万人以上のプロがThunderbitを使ってWebスクレイピング業務を自動化しています。
無料トライアルでは8ページ分の無制限クレジットを利用できます。