ウェブサイトから必要なデータだけを抜き出そうとして、思いどおりにいかなかった経験はありませんか。競合価格の一覧だったり、商品カタログだったり、新たな営業リードのリストだったり。標準的なスクレイピングツールなら全体の80%まではうまくいきますが、最後の20%こそが魔法であり、同時にいちばん厄介な部分です。データ主導の今の時代、「だいたい合っている」では済まされません。カスタム抽出とデータ抽出サービスは現代の業務の土台になっており、世界のウェブスクレイピング市場は2024年の7億5,400万ドルからへと急成長すると予測されています。データ戦略にカスタムスクレイピングが入っていないなら、すでに市場で存在感を失っているかもしれません。
私は何年もかけて、気合いで回すスタートアップから大企業まで、コピペ地獄や壊れやすい汎用ツールの先へ進む手助けをしてきました。その差は何か。それは、カスタムデータ抽出を使いこなせるかどうかです。このガイドでは、カスタム抽出の本当の意味、なぜ重要なのか、(私たちのチームが開発したAIウェブスクレイパー)がそれをどれだけ簡単にするのか、そして自社に合ったデータ抽出サービスの選び方まで、順を追って解説します。ついでに、データ好きならではの失敗談も少し紹介します。誰しも、ひとつやふたつはありますから。
カスタム抽出とは?用途に合わせたデータ抽出サービスの力を引き出す
 まず基本から見ていきましょう。カスタム抽出とは、ビジネスにとって重要なウェブサイトから、必要なデータを必要な形式で、ぴったり取り出すことです。手に入りやすいものや目に見えるものを何でも拾う標準的なスクレイピングツールとは違い、カスタムデータ抽出は正確で、柔軟で、そして複雑なサイトや動的なサイト、レイアウトが数週間おきに変わるようなサイトにも強いのが特徴です。
まず基本から見ていきましょう。カスタム抽出とは、ビジネスにとって重要なウェブサイトから、必要なデータを必要な形式で、ぴったり取り出すことです。手に入りやすいものや目に見えるものを何でも拾う標準的なスクレイピングツールとは違い、カスタムデータ抽出は正確で、柔軟で、そして複雑なサイトや動的なサイト、レイアウトが数週間おきに変わるようなサイトにも強いのが特徴です。
既製品ではなく、オーダーメイドのスーツを仕立てるようなものだと考えてください。カスタム抽出なら、「標準」の項目やテンプレートに縛られません。たとえば、次のようなことができます。
- 商品仕様、レビュー、連絡先情報など、特定のデータだけを取り出す
- 複数ステップの移動に対応する(ページ送り、サブページ、ログインなど)
- 動的コンテンツに対応する(無限スクロール、JavaScriptで読み込まれるデータなど)
- 取得しながらデータを整形・クリーニング・変換する
なぜ重要なのでしょうか。実際のビジネス要件は、たいてい単純ではないからです。商品一覧を取得したあと、各リンクをたどって詳細仕様やレビューも集めたいことがあるかもしれません。あるいは、競合の価格を何十ページにもわたって監視したいが、対象は特定のSKUだけ、というケースもあるでしょう。標準ツールでは壊れたり、データを取りこぼしたり、半ばHTML探偵のような作業を求められたりします。一方、カスタム抽出サービスは、こうした場面に対応するために作られており、多くの場合AIや自然言語処理の力を活用しています。
カスタムスクレイピングと標準スクレイピングの違いをさらに深掘りしたい方は、をご覧ください。
カスタムデータ抽出サービスがビジネス成長に重要な理由
少し実務的に考えてみましょう。なぜカスタムデータ抽出に注目すべきなのでしょうか。単なる技術アップグレードではなく、ビジネスを加速させる手段だからです。カスタム抽出サービスは、次のように実際の成果につながります。
| ビジネスニーズ | カスタムデータスクレイピングの解決策 | 一般的な成果 / ROI |
|---|---|---|
| リード獲得 | ディレクトリ、LinkedIn、レビューサイトから最新の連絡先を抽出 | 手作業での調査時間を最大80%削減。より大規模で、より関連性の高いリードリストを作成 |
| 競合価格の監視 | 動的レイアウトでも、競合サイトの価格や在庫を追跡 | 動的価格設定で売上を4%以上向上。粗利を最大15%改善 |
| 市場インテリジェンス & 調査 | ニュース、レビュー、規制関連の提出書類を大規模に集約 | データ活用率が50%以上向上。意思決定がより速く、より的確に |
| 商品カタログ更新 | 複数ソースから商品情報を取得し、サブページやバリエーションにも対応 | 常に最新のカタログを維持。誤りと手作業更新を削減 |
| 業務自動化 | レポート、コンプライアンス、在庫管理のために定期スクレイプを設定 | データの市場投入までの時間を85%短縮。収集コストを73%削減 |
(, )
要するに、カスタム抽出は贅沢品ではなく、競争に勝つための必需品です。これを使いこなしている企業は、競合より素早く動き、市場変化に機敏に対応し、成長につながる洞察を見つけています。
Thunderbitのアプローチ:カスタムデータ抽出をシンプルに
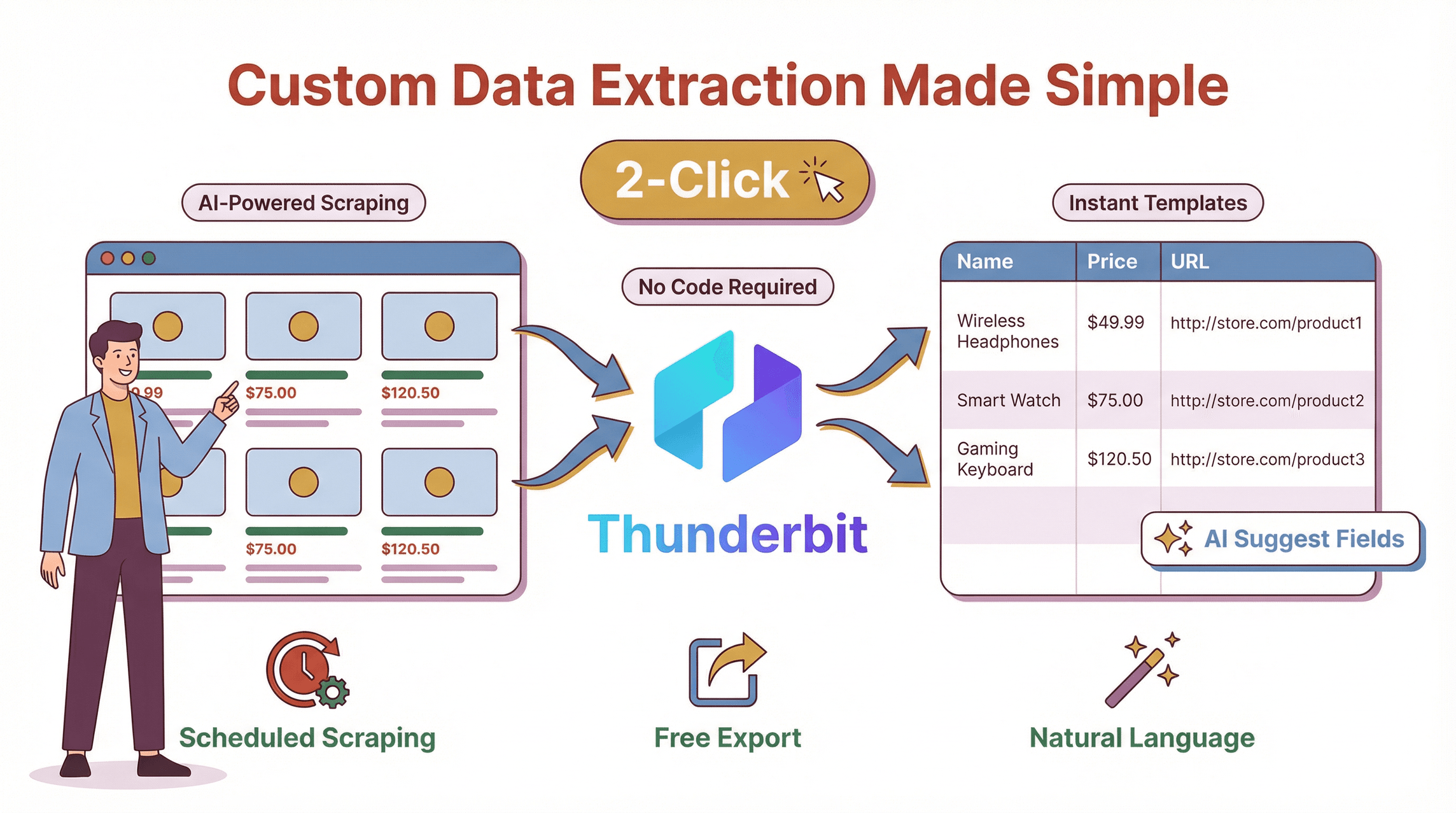
正直に言うと、私がThunderbitを作った理由は、壊れるたびにサイト側のせいでもないのに苦労する、面倒でコードだらけのスクレイパーにチームが振り回されているのを見るのにうんざりしていたからです。Thunderbitはで、開発者だけでなく、誰でもカスタムデータ抽出を使えるようにするために作られています。
Thunderbitの違いは次のとおりです。
- AIによる項目提案: 「AIで項目を提案」をクリックすると、Thunderbitがページを解析し、「商品名」「価格」「画像URL」「メールアドレス」など、抽出に最適な列を提案します。もう推測したり、セレクタをいじったりする必要はありません。
- 自然言語での指示: 日付を抽出したい、説明文を翻訳したい、項目を分類したい。そんなときは、普通の英語でそのまま伝えるだけ。AIがやり方を判断します。
- 2クリックでスクレイピング: 対象サイトに移動してThunderbitを開き、「スクレイプ」を押すだけ。これで完了です。コードもテンプレートも不要(使いたければ使えます)。面倒な作業はありません。
- 複雑なページにも対応: Thunderbitはページ送り、無限スクロール、サブページ、さらにはJavaScriptで読み込まれる動的コンテンツにも対応できます。サイトが変わっても適応します。
- サブページスクレイピング: 各項目の詳細がもっと必要ですか。Thunderbitが各サブページ(商品詳細ページなど)を自動で巡回し、表をさらに充実させます。
- 定期スクレイピング: 「毎週月曜の9時」のような自然な表現で定期取得を設定すれば、あとはThunderbitに任せられます。
- すぐ使えるテンプレート: Amazon、Zillow、LinkedInのような人気サイト向けに、1クリックテンプレートを用意しています。設定は不要です。
- 無料のデータエクスポート: Excel、Google Sheets、Airtable、Notion、CSV、JSONへエクスポート可能。課金の壁も、制限もありません。
Thunderbitの使命はシンプルです。ビジネスユーザーは欲しいものを言葉で伝え、技術的に重い作業はAIに任せる。それだけです。疲れ知らずで、コーヒーの文句も言わない、AI搭載のリサーチアシスタントがいるようなものです。
ステップバイステップ:Thunderbitでカスタムデータスクレイピングを使う
Thunderbitを使った実際のカスタム抽出の流れを見ていきましょう。ここでは商品カタログを例にしますが、リード、レビュー、その他何でも手順はほぼ同じです。
ステップ1:Thunderbitをインストールする
にアクセスして、ブラウザに追加します。無料プランはクレジットカード不要で、無料アカウントに登録できます。
ステップ2:対象のウェブサイトを開く
スクレイプしたいページ(たとえば、商品一覧があるカテゴリページ)に移動します。
ステップ3:Thunderbitを起動して「AIで項目を提案」を使う
Thunderbitのアイコンをクリックし、「AIで項目を提案」を押します。ThunderbitのAIがページを解析し、「商品名」「価格」「画像URL」などの列を提案してくれます。必要に応じて、項目名の変更、追加、削除が可能です。
ステップ4:項目ごとのAIプロンプトでカスタマイズする
特定の情報だけを取り出したい場合は、各項目にカスタム指示を追加できます。たとえば、「日付をYYYY-MM-DD形式で抽出する」「説明をスペイン語に翻訳する」といった指示です。ThunderbitのAIが抽出時にそのルールを適用します。
ステップ5:必要に応じてページ送りやサブページスクレイピングを有効にする
データが複数ページにまたがる場合は、ページ送りをオンにします。サブページ(商品詳細ページなど)から詳細が必要なら、サブページスクレイピングを使います。Thunderbitが各リンクを巡回し、追加情報を表に取り込みます。
ステップ6:「スクレイプ」をクリックしてデータが流れるのを見る
Thunderbitがナビゲーションや整形を自動で処理しながら、データを抽出します。動作中はプレビュー表が表示されます。
ステップ7:データをエクスポートする
結果に満足したら、へ直接エクスポートできます。CSVやJSONでのダウンロードも可能です。
これで完了です。コードも、テンプレートも(使いたければ使えます)、そして「なんで動かないの?」というイライラもありません。詳しくはをご覧ください。
Thunderbitと他のデータ抽出サービスの比較
少しマニアックな話をしましょう。Thunderbitは、Azure AI Document Intelligenceや従来型スクレイパーのような他のデータ抽出サービスと比べてどうでしょうか。
| 機能 / 比較項目 | Thunderbit | Azure AI Document Intelligence | 従来型スクレイパー(例:Octoparse、Scrapy) |
|---|---|---|---|
| 使いやすさ | ノーコード、AI主導、2クリックで開始 | 開発者向け、APIベース | 学習コストが高く、コードが必要なことが多い |
| カスタム抽出 | 自然言語プロンプト、AIによる項目提案 | 文書向けのカスタムMLモデル | 手動設定、セレクタ、スクリプト |
| ウェブページ対応 | 対応(HTML、動的ページ、サブページ) | 非対応(文書/PDFに特化) | 対応するが、動的サイトは苦手 |
| 文書/PDF対応 | 対応(ブラウザ/PDFモード経由) | 対応(OCR、ML) | 場合によるが、制限あり |
| 適応性 | AIがレイアウト変更に適応 | MLが新しい文書に適応 | サイト変更で壊れやすく、更新が必要 |
| スケジューリング | 標準搭載、自然言語で設定 | API経由、連携が必要 | 場合によるが、複雑 |
| エクスポート先 | Sheets、Excel、Airtable、Notion、CSV、JSON | API/JSON、開発連携が必要 | CSV、Excel、DBなど、さまざま |
| サポート | モダンなSaaS、対応が迅速 | エンタープライズ向け、正式サポート | コミュニティまたはベンダー次第 |
| 価格 | 無料枠あり、従量課金のクレジット制 | 従量課金、エンタープライズ向け | 無料(オープンソース)または月額プラン |
Thunderbitの強みは、痛みなく使える、ビジネスユーザー向けのウェブデータ抽出です。Azureは大規模な文書処理には優れていますが、ウェブサイトのクロールには向いていません。従来型スクレイパーは使いこなせば強力ですが、技術スキルと継続的なメンテナンスが必要です。
さらに詳しい比較は、をご覧ください。
自分に合ったカスタムデータ抽出サービスの選び方
データ抽出サービスを選ぶときは、機能だけでなく、自社との相性が重要です。判断のためのチェックリストを紹介します。
- データ品質と信頼性: 正確で、きれいで、欠けのないデータを提供できますか。対象サイトで試せますか。
- 柔軟性とカスタマイズ性: 特定のサイト、動的コンテンツ、ログイン、サブページに対応できますか。カスタム項目や変換を定義できますか。
- 法令遵守と倫理: 法的・倫理的なガイドラインに従っていますか。プライバシー法やサイト規約を尊重していますか。
- 拡張性と性能: 必要なデータ量や頻度に対応できますか。クラウドスクレイピングや並列処理はありますか。
- 連携とワークフロー: Sheets、Excel、CRMなどのツールへデータをエクスポートできますか。スケジューリングや自動化をサポートしていますか。
- サポートとドキュメント: 迅速なサポートと分かりやすいドキュメントはありますか。チュートリアルやナレッジベースはありますか。
- セキュリティ: データを安全に扱えますか。ログイン情報は暗号化されますか。コンプライアンス認証はありますか。
- コスト: 価格体系は透明で、ニーズに対して費用対効果がありますか。隠れた料金や課金の壁はありませんか。
候補はすべて実際に試してみましょう。本番に近いサイトでスクレイプし、データを書き出し、業務フローにどれだけ合うか確認してください。さらに詳しいヒントは、をご覧ください。
カスタムデータスクレイピングを業務フローに組み込む
データを抽出するだけでは半分しか終わっていません。本当の価値は、それを日々の業務に組み込んでこそ生まれます。自社の業務にカスタムデータ抽出を取り入れる方法は次のとおりです。
- 定常業務を自動化する: 定期スクレイピングを使って、価格チェックを毎日、リード更新を毎週、というようにデータを新鮮に保ちます。
- データを各種ツールへ流し込む: へ直接エクスポートします。さらにZapier、Make、n8nを使えば、CRMへの新規リード登録なども自動化できます。
- アラートを設定する: Slackやメールと連携して、競合の値下げや新商品の発売など、重要な変化を通知させます。
- クラウドで共同作業する: 共有データベース(Airtable、Notion)を使えば、抽出したデータをチーム全体で扱えます。
- エンドツーエンドで自動化する: スクレイピングをBIツール(Tableau、Power BI)と組み合わせてライブダッシュボードを作ったり、抽出データに応じて価格改定などのアクションを起こしたりできます。
参考として、もご覧ください。
カスタムデータ抽出サービスの価値を最大化するベストプラクティス
カスタム抽出を最大限に活用したいですか。私が学んだことを、少し痛い失敗談も交えて共有します。
- 明確な目標を定める: 何のデータが必要で、なぜ必要なのかをはっきりさせましょう。できるからやる、ではなく、目的を持って抽出します。
- 小さく始めて、こまめに検証する: 小規模に試し、データを確認し、自信がついてから拡大します。
- データ品質を監視する: 定期的に結果をサンプリングして確認します。異常検知のルールやアラートを設定しましょう。
- 頻度を最適化する: 必要な回数だけ抽出し、やりすぎないこと。過剰なスクレイピングはブロックされる原因になり、IT部門の反感も買います。
- 倫理と法令遵守を徹底する: サイト規約、個人情報保護法、倫理ガイドラインを尊重しましょう。機微情報や制限されたデータはスクレイプしないでください。
- 項目プロンプトを活用する: AIプロンプトを使って、抽出中にデータを整えたり、形式をそろえたり、付加情報を加えたりします。
- データを守る: 認証情報や抽出データは丁寧に扱い、暗号化とアクセス制御を使いましょう。
- 手順を記録する: 何を、どこから、どの頻度でスクレイプしているのかを記録しておくと、後でかなり楽になります。
- 改善を重ねる: カスタム抽出は進化し続けるものとして扱いましょう。要件の変化に合わせて手法を磨いていきます。
ベストプラクティスの詳細は、をご覧ください。
結論と重要ポイント:カスタム抽出でデータ戦略を格上げする
カスタムデータ抽出やデータスクレイピングサービスは、データオタクだけのものではありません。素早く動き、競争力を保ち、より賢く意思決定したいすべてのビジネスにとって必須のツールです。手作業のコピペや壊れやすいスクリプトの時代は終わりました。のようなAI搭載ツールがあれば、誰でもカスタム抽出を使いこなせます。コードは不要です。
覚えておきたいポイントは次のとおりです。
- カスタム抽出 = 必要なデータを取ること。 量より関連性です。
- ビジネス価値は実証済み。 営業、運用、市場調査まで、カスタムスクレイピングは確かなROIをもたらします。
- 使いやすさはもう実現している。 Thunderbitのようなツールが、データ抽出を誰にでも開放します。
- 連携がすべて。 抽出したデータを単発の成果物ではなく、日々の業務フローの一部にしましょう。
- 賢く選ぶ。 ツールは自分の要件に合わせ、試し、比較し、改善しましょう。
- ベストプラクティスが勝ち筋。 明確な目標、品質チェック、倫理基準が、データ戦略を強く保ちます。
データ活用を次のレベルに進める準備はできましたか。して、実際のビジネス課題でカスタムスクレイプを試してみてください。もっと深掘りしたいなら、で詳しい解説、チュートリアル、AI搭載データ抽出の最新情報をチェックできます。
ウェブは洞察の宝庫です。カスタム抽出は、その宝を掘り出すためのツルハシ。では、よいスクレイピングを!
よくある質問
1. カスタムデータ抽出とは何ですか。標準的なスクレイピングとどう違うのですか。
カスタムデータ抽出とは、複雑なサイトや動的なサイトであっても、必要なデータを必要な形式で、任意のウェブサイトからぴったり取り出せるようにスクレイピングを調整することです。手に入りやすいものを何でも拾う標準ツールとは違い、カスタム抽出は業務要件や変化するサイト構造に合わせて柔軟に対応します。
2. カスタムデータ抽出サービスの恩恵を最も受けるのは誰ですか。
営業チーム(リード獲得)、マーケティング(競合追跡)、運用部門(自動化)、プロダクトマネージャー(カタログ更新)、市場調査担当(インテリジェンス)などは、特に標準ツールでは足りない場面で、カスタム抽出の大きな恩恵を受けます。
3. Thunderbitは、どうしてカスタム抽出を簡単にできるのですか。
ThunderbitはAIを使って項目を提案し、複雑な移動(ページ送り、サブページ)に対応し、欲しい内容を自然な英語でそのまま説明できるようにします。コード不要、テンプレート不要(必要なら利用可)、そしてお気に入りのツールへすぐエクスポートできます。
4. データ抽出サービスを選ぶとき、何を重視すべきですか。
データ品質、柔軟性、法令遵守、拡張性、連携オプション、サポート、セキュリティ、コストに注目してください。導入前に、実際の業務要件で試すことが大切です。
5. カスタムデータスクレイピングを業務フローにどう組み込めばよいですか。
定常業務を自動化し、データをSheets/Excel/Notionへ出力し、アラートを設定し、Zapierやn8nのようなワークフローツールを使います。目指すのは、ウェブデータを単発の案件ではなく、日々の業務の生きた一部にすることです。
自社でカスタム抽出が何を実現できるか見てみませんか。して、ウェブの混乱をビジネスの明確さへ変え始めましょう。
詳しくはこちら