
スクロールするとコンテンツが読み込まれるサイト、ログインしないと価格が見えないサイト、あるいは数週間ごとにレイアウトが変わるようなサイトからデータを取ろうとしたことがあるなら、その大変さはよくわかるはずです。静的なスクレイパーだけでは、もう対応しきれません。実際、が今では代替データの取得にウェブスクレイピングを活用しており、が競合価格の監視を自動化しています。とはいえ、ここが肝心なのですが、その多くのデータはJavaScriptで読み込まれ、ユーザー操作の裏に隠れた動的サイトに存在しています。そこで役立つのが、ヘッドレスブラウザの自動化、そしてPuppeteerのようなツールです。
自動化やAIツールの開発に長年携わってきた身として、そして営業やオペレーションチーム向けにかなりの数のサイトをスクレイピングしてきた立場から言えば、Puppeteerが従来のスクレイパーでは拾えないデータを引き出せることを、私は何度も目の当たりにしてきました。ただし、コーディングの手間がビジネスユーザーにとっては大きな壁になることも知っています。そこでこのガイドでは、Puppeteerスクレイパーとは何か、ウェブスクレイピングにどう使うのか、そしてもっと簡単な方法――たとえば、コード不要のAI搭載ウェブスクレイパーである――を選ぶべきタイミングまで、順を追って解説します。
Puppeteerスクレイパーとは? 簡単に解説
 まずは基本から始めましょう。は、Googleが提供するオープンソースのNode.jsライブラリで、JavaScriptを使ってヘッドレスChromeまたはChromiumブラウザを操作できます。平たく言えば、ウェブページを開く、ボタンをクリックする、フォームに入力する、スクロールする、そして何よりデータを抽出する、といった作業を、画面に何も表示せずにこなしてくれるロボットのようなものです。
まずは基本から始めましょう。は、Googleが提供するオープンソースのNode.jsライブラリで、JavaScriptを使ってヘッドレスChromeまたはChromiumブラウザを操作できます。平たく言えば、ウェブページを開く、ボタンをクリックする、フォームに入力する、スクロールする、そして何よりデータを抽出する、といった作業を、画面に何も表示せずにこなしてくれるロボットのようなものです。
Puppeteerの何が特別なのか?
- 動的コンテンツを描画できるため、実際のユーザーと同じようにJavaScriptの読み込みを待てます。
- ユーザー操作を再現できるので、クリック、入力、スクロール、ポップアップ対応までこなせます。
- ECサイトの商品一覧、SNSのフィード、ダッシュボードのように、操作後に初めてデータが表示されるサイトのスクレイピングに最適です。
他のツールと比べるとどうか?
- Selenium:ブラウザ自動化の定番です。多くのブラウザや言語に対応していますが、やや重く、少し旧世代の印象があります。クロスブラウザのテストには強い一方で、Chrome/Node.jsプロジェクトではPuppeteerのほうが軽快です。
- Thunderbit:ここが私の一番ワクワクするポイントです。Thunderbitは、ブラウザ上で動くコード不要のAIウェブスクレイパーです。スクリプトを書く代わりに、「AIでフィールドを提案」をクリックするだけで、AIが何を抽出すべきか判断してくれます。コードを書かずに結果を出したいビジネスユーザーにぴったりです(詳しくはこのあと説明します)。
要するに、Puppeteer = 最大限の制御力(コードを書けるなら)。Thunderbit = 最大限の手軽さ(コードを書きたくないなら)。
なぜPuppeteerによるウェブスクレイピングがビジネスユーザーに重要なのか
はっきり言うと、ウェブスクレイピングはもはやハッカーやデータサイエンティストだけのものではありません。営業、オペレーション、マーケティング、さらには不動産チームまで、ウェブデータを使って成果を上げています。そして、ビジネスに欠かせない情報の多くが動的サイトの裏に隠れている今、Puppeteerはそれを引き出す鍵になることが多いのです。
実際の活用例を見てみましょう。
| 用途 | 恩恵を受ける人 | 効果 / ROI |
|---|---|---|
| リード獲得 | 営業、Biz Dev | 見込み顧客リスト作成を自動化し、1人あたり週8時間以上を節約 (case study) |
| 価格監視 | EC、商品オペレーション | 競合をリアルタイムで追跡。ある企業は年間380万ドルを節約 (source) |
| 市場調査 | マーケティング、戦略、財務 | 投資アドバイザーの67%がウェブスクレイピングデータを活用。ケースによっては最大890%のROI (source) |
| 不動産データ集約 | エージェント、アナリスト | 50件以上の物件ページを、数時間ではなく数分でスクレイピング (source) |
| コンプライアンス追跡 | オペレーション、法務 | 監視を自動化し、ある保険会社は5,000万ドルの罰則を回避 (source) |
さらに、が、データ収集のような反復作業に週の4分の1を費やしています。ウェブスクレイピングでこれを自動化するのは、単なる便利機能ではなく、競争優位そのものです。
はじめ方:Puppeteerスクレイパーのセットアップ
さあ、実際に手を動かす準備はできましたか? ここでは、少しJavaScriptに慣れている前提で、10分以内にPuppeteerを動かす方法を紹介します。
1. Node.jsをインストールする
PuppeteerはNode.js上で動きます。最新のLTS版をからダウンロードしてください。
2. 新しいプロジェクトフォルダを作成する
ターミナルを開いて、次を実行します。
1mkdir puppeteer-scraper-demo
2cd puppeteer-scraper-demo
3npm init -y3. Puppeteerをインストールする
1npm install puppeteerこれで、互換性のあるChromiumも一緒にダウンロードされます(約100MB)。
4. 最初のスクリプトを作成する
scrape.js というファイルを作成します。
1const puppeteer = require('puppeteer');
2(async () => {
3 const browser = await puppeteer.launch();
4 const page = await browser.newPage();
5 await page.goto('https://example.com', { waitUntil: 'domcontentloaded' });
6 const title = await page.title();
7 console.log('ページタイトル:', title);
8 await browser.close();
9})();次のコマンドで実行します。
1node scrape.js「ページタイトル: Example Domain」と表示されたら、おめでとうございます。Chromeの自動化に成功です。
最初のPuppeteerウェブスクレイピングスクリプトを作る
では、実践に入ってみましょう。たとえば、(スクレイピング用のデモサイト)から名言を抽出したいとします。
ステップ1:ページに移動する
1await page.goto('http://quotes.toscrape.com', { waitUntil: 'networkidle0' });ステップ2:データを抽出する
1const quotes = await page.evaluate(() => {
2 return Array.from(document.querySelectorAll('.quote')).map(node => ({
3 text: node.querySelector('.text')?.innerText.trim(),
4 author: node.querySelector('.author')?.innerText.trim(),
5 tags: Array.from(node.querySelectorAll('.tag')).map(tag => tag.innerText.trim())
6 }));
7});
8console.log(quotes);ステップ3:ページネーションを処理する
1let hasNext = true;
2let allQuotes = [];
3while (hasNext) {
4 // 上と同じように名言を抽出
5 const quotes = await page.evaluate(/* ... */);
6 allQuotes.push(...quotes);
7 const nextButton = await page.$('li.next > a');
8 if (nextButton) {
9 await Promise.all([
10 page.click('li.next > a'),
11 page.waitForNavigation({ waitUntil: 'networkidle0' })
12 ]);
13 } else {
14 hasNext = false;
15 }
16}ステップ4:JSONに保存する
1const fs = require('fs');
2fs.writeFileSync('quotes.json', JSON.stringify(allQuotes, null, 2));これで、移動して、抽出して、ページ送りして、保存まで行う基本的なPuppeteerスクレイパーが完成です。
高度なPuppeteerスクレイパーのテクニック:動的コンテンツへの対応
実際のサイトの多くは、単純な静的リストほど簡単ではありません。難所に対処する方法を見ていきましょう。
1. 動的要素が読み込まれるのを待つ
1await page.waitForSelector('.product-list-item');これで、取得したいコンテンツが読み込まれてから処理を始められます。
2. ユーザー操作を再現する
- ボタンをクリックする:
await page.click('#load-more'); - 入力欄に文字を入れる:
await page.type('#search', 'laptop'); - 無限スクロールを処理する:
1// 注意: page.waitForTimeout は Puppeteer v22 で削除されました。代わりに通常のPromiseを使ってください。 2const sleep = (ms) => new Promise(r => setTimeout(r, ms)); 3let previousHeight = await page.evaluate('document.body.scrollHeight'); 4while (true) { 5 await page.evaluate('window.scrollTo(0, document.body.scrollHeight)'); 6 await sleep(1500); 7 const newHeight = await page.evaluate('document.body.scrollHeight'); 8 if (newHeight === previousHeight) break; 9 previousHeight = newHeight; 10}
1**3. ログインに対応する**
2```javascript
3await page.goto('https://exampleshop.com/login');
4await page.type('#login-username', 'myusername');
5await page.type('#login-password', 'mypassword');
6await page.click('#login-button');
7await page.waitForNavigation({ waitUntil: 'networkidle0' });4. AJAXで読み込まれるデータへの対処 データがDOM内にあるのではなく、API呼び出しで取得されることもあります。その場合は、次のようにネットワーク応答をフックできます。
1page.on('response', async response => {
2 if (response.url().includes('/api/products')) {
3 const data = await response.json();
4 // データを処理する
5 }
6});実例:ECサイトから商品データをスクレイピングする
ここまでを全部つなげてみましょう。ログイン後の(デモ)ECサイトから、商品名、価格、画像を取得したいとします。
1const puppeteer = require('puppeteer');
2const fs = require('fs');
3(async () => {
4 const browser = await puppeteer.launch({ headless: true });
5 const page = await browser.newPage();
6 // ステップ1:ログインする
7 await page.goto('https://exampleshop.com/login');
8 await page.type('#login-username', 'myusername');
9 await page.type('#login-password', 'mypassword');
10 await page.click('#login-button');
11 await page.waitForNavigation({ waitUntil: 'networkidle0' });
12 // ステップ2:カテゴリページへ移動する
13 await page.goto('https://exampleshop.com/category/laptops', { waitUntil: 'networkidle0' });
14 // ステップ3:商品を抽出する
15 const products = await page.evaluate(() => {
16 return Array.from(document.querySelectorAll('.product-item')).map(item => ({
17 name: item.querySelector('.product-title')?.innerText.trim() || '',
18 price: item.querySelector('.product-price')?.innerText.trim() || '',
19 image: item.querySelector('img.product-image')?.src || ''
20 }));
21 });
22 // ステップ4:JSONに保存する
23 fs.writeFileSync('products.json', JSON.stringify(products, null, 2));
24 await browser.close();
25})();このスクリプトは、ログインして、移動して、スクレイピングして、保存までをすべて自動で行います。さらに高度な用途では、ページネーションのループを追加したり、各商品をクリックして詳細を取得したりすることもできます。
Thunderbit:AIでPuppeteerスクレイパーをもっと簡単にする
ここまで読んで、「それはすごいけど、新しいデータセットが必要になるたびに毎回コードを書くのはちょっと……」と思ったなら、あなただけではありません。まさにそのために私たちはを作りました。
Thunderbitの何が違うのか?
- コード不要: をインストールし、スクレイピングしたいページを開いて、「AIでフィールドを提案」をクリックするだけです。
- AIによるフィールド検出:Thunderbitがページを読み取り、「商品名」「価格」「画像」など、抽出すべき最適な列を提案します。
- 動的コンテンツにも対応:無限スクロール、ポップアップ、サブページも? ThunderbitのAIなら、ページネーションを処理したり、各商品の詳細ページを見に行ってデータを補完したりできます。
- 即時エクスポート:データをExcel、Googleスプレッドシート、Notion、Airtableへワンクリックで送信できます。エクスポートに追加料金はかかりません。
- 人気サイト向けテンプレート:Amazon、Zillow、LinkedInをスクレイピングしたい? Thunderbitには即利用できるテンプレートがあります。設定は不要です。
- クラウドまたはブラウザでスクレイピング:大量の作業では、Thunderbitはクラウド上で一度に最大50ページをスクレイピングできます。
私は、ユーザーが「このデータが取れたらいいのに」から「はい、スプレッドシートです」へ、5分以内に変わるのを何度も見てきました。そして一番いいのは、サイトが変わるたびにスクリプトが壊れる心配がなくなることです。ThunderbitのAIが、その場で適応してくれます。
Puppeteer vs. Thunderbit:最適なウェブスクレイピングツールを選ぶ
では、どちらを使うべきでしょうか? チーム向けに整理すると、私はこう考えます。
| 比較項目 | Puppeteer(コード) | Thunderbit(ノーコード、AI) |
|---|---|---|
| 使いやすさ | JavaScriptとDOMの知識が必要 | クリック操作だけで、AIがフィールドを提案 |
| セットアップ速度 | 複雑な作業だと数時間〜数日 | 数分。インストールしてすぐ使える |
| 制御力 / 柔軟性 | 最大。任意のロジックを書け、他のコードとも統合可能 | 標準的な用途では高いが、非常に独自性の高いワークフローにはやや不向き |
| 動的コンテンツ対応 | 待機、クリック、スクロールを手動で実装 | 組み込みAIが動的コンテンツ、ページネーション、サブページを自動処理 |
| 保守 | スクリプトは自分で管理。サイト変更時は更新が必要 | AIがレイアウト変更に適応。ユーザー側の保守負担は少ない |
| データ出力 | 自分でエクスポート処理を書く | Excel、Sheets、Notion、Airtable、CSV、JSONへワンクリックで出力 |
| 最適な用途 | 開発者、高度にカスタマイズしたスクレイピング、大規模処理 | ビジネスユーザー、短納期の案件、非技術系チーム |
| コスト | 無料(ただし時間とインフラ費用は別) | 無料プランあり。クレジット制の有料プランもあり (Thunderbitの料金) |
結論:
- Puppeteerを使うべき場合:完全な制御が必要、コーディングリソースがある、あるいはスクレイピングを大きなアプリに組み込みたい。
- Thunderbitを使うべき場合:すばやく結果が欲しい、コードを書きたくない、非技術系メンバーにも使わせたい。
正直に言うと、両方を使い分けているチームもよく見ます。Thunderbitは素早い成果や試作に、Puppeteerは深い統合や特殊ケースに、という使い方です。
ステップバイステップのチェックリスト:Puppeteerで成功するウェブスクレイピングプロジェクトを回す
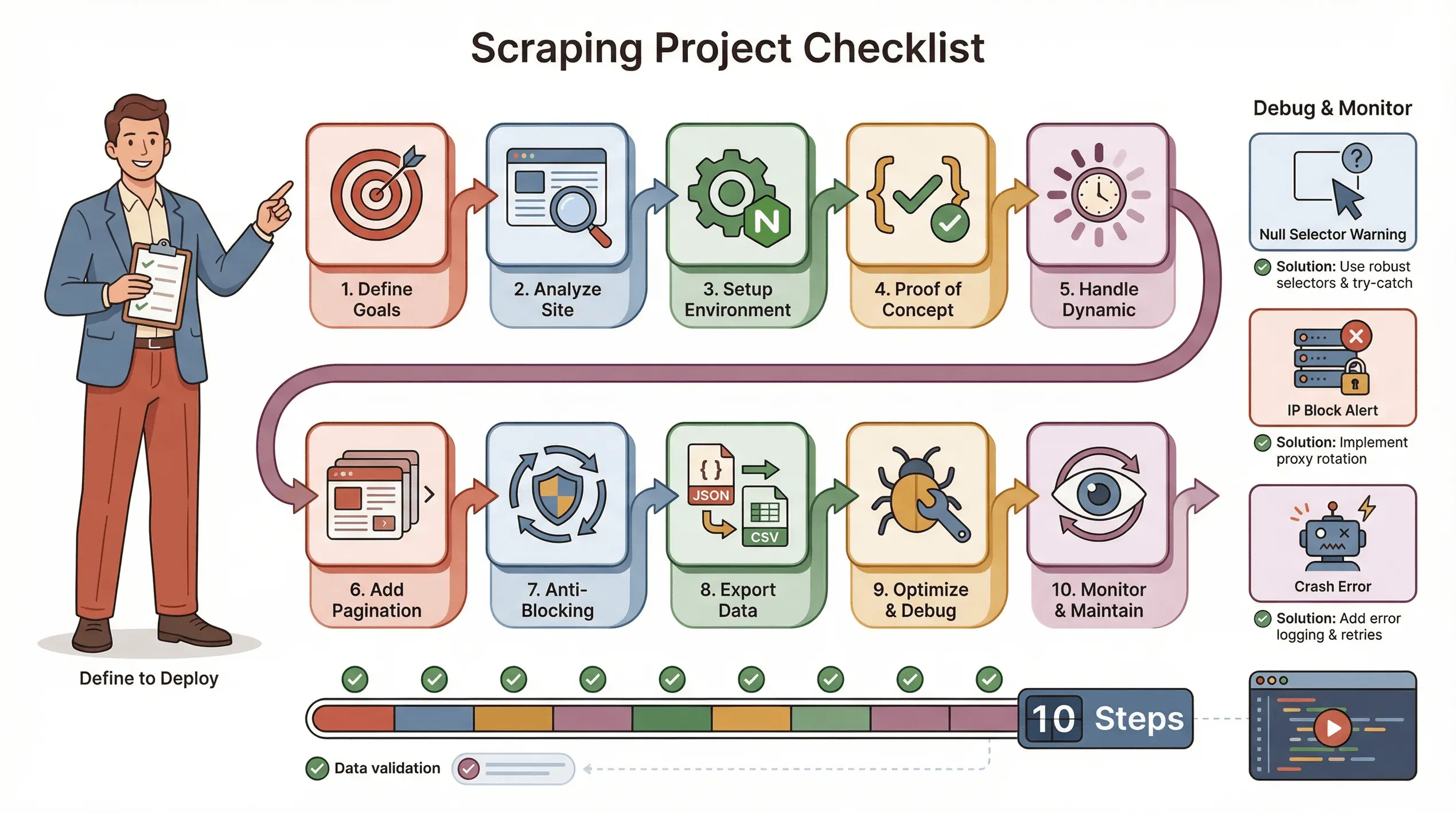 スムーズにPuppeteerスクレイピングを進めるための、私のお気に入りチェックリストはこちらです。
スムーズにPuppeteerスクレイピングを進めるための、私のお気に入りチェックリストはこちらです。
- 目的を定義する:どんなデータが必要か? それはどこにあるか?
- サイトを分析する:動的か? ログインが必要か? ボット対策はあるか?
- 環境を整える:Node.js、Puppeteer、必要なヘルパーライブラリを用意する。
- 試作版を作る:まずは1ページから始め、セレクタを正しく取る。
- 動的コンテンツを処理する:
waitForSelectorを使い、必要に応じてクリックやスクロールを再現する。 - ページネーションやループを追加する:1ページだけでなく、全ページをスクレイピングする。
- ブロック回避の対策を入れる:待機時間をランダム化し、実際のUser-Agentを設定し、必要ならプロキシを使う。
- データを出力して検証する:JSON/CSVに保存し、漏れがないか確認する。
- 最適化とエラー処理を行う:try/catchを追加し、進捗を記録し、欠損データは丁寧に扱う。
- 監視と保守を続ける:サイトは変わるもの。スクリプトを更新できるようにしておく。
トラブルシューティングのヒント:
- セレクタがnullを返す場合は、HTMLを再確認し、待機処理を入れてください。
- ブロックされる場合は、速度を落とし、IPをローテーションするか、ステルス系プラグインを使いましょう。
- スクリプトが落ちる場合は、メモリリークや未処理例外を確認してください。
まとめと重要ポイント
ウェブスクレイピングは、データドリブンなチームにとって必須スキルになりました。Puppeteerは、JavaScriptが多用された非常に動的なサイトからでもデータを抽出できる強力な手段ですが、そのぶんコーディング力と継続的な保守が必要です。コードを飛ばしてすぐデータを取りたいビジネスユーザーには、Thunderbitが、速くて柔軟で、驚くほど堅牢なAI搭載・ノーコードの代替手段を提供します。
私ならこう勧めます:
- 技術寄りで、細かいカスタマイズが必要なら、Puppeteerから始める。
- 速度、シンプルさ、保守の少なさを求めるなら、を試してみる(は最適な出発点です)。
- ほとんどのチームでは、両方を組み合わせることでウェブデータのニーズの99%をカバーできます。
こうしたガイドをもっと見たいですか? では、チュートリアル、比較記事、AI搭載ウェブスクレイピングの最新情報を紹介しています。
FAQ
1. Puppeteerスクレイパーとは何ですか? また、なぜウェブスクレイピングに使われるのですか?
Puppeteerは、JavaScriptを使ってヘッドレスChromeブラウザを操作できるNode.jsライブラリです。動的コンテンツを読み込めること、ユーザー操作を再現できること、従来のスクレイパーでは扱えないサイトからデータを抽出できることから、ウェブスクレイピングに使われます。
2. PuppeteerはSeleniumやThunderbitと比べてどうですか?
Seleniumは複数のブラウザや言語に対応していますが、やや重めです。PuppeteerはChrome/Node.js向けに最適化されており、多くのスクレイピング作業でより高速です。一方、Thunderbitはコード不要のAI搭載ツールで、非技術ユーザーでも数クリックでデータを取得できます。
3. Puppeteerによるウェブスクレイピングの主なビジネス上の利点は何ですか?
データ収集を自動化することで、時間を節約し、ミスを減らし、営業、マーケティング、オペレーションなどにリアルタイムの洞察をもたらします。用途は、リード獲得から価格監視、市場調査まで多岐にわたります。
4. Puppeteerスクレイピングで最も大きな課題は何ですか?
主な課題は、動的コンテンツへの対応、ボット対策によるブロック回避、そしてサイト変更時のスクリプト保守です。待機処理、操作の再現、エラー処理を行うためのコードが必要になります。
5. PuppeteerではなくThunderbitを使うべきなのはどんなときですか?
コードを書きたくない、すぐに結果が欲しい、非技術系メンバーにも使わせたい、という場合はThunderbitがおすすめです。標準的なスクレイピング作業、短納期の案件、あるいはExcelやGoogleスプレッドシートへ手軽にエクスポートしたいときに最適です。
もっと賢いスクレイピング方法を試してみませんか? するか、 のガイドでさらに深く学んでみてください。スクレイピングを楽しんで!
さらに詳しく