ウェブ上のデータ量は爆発的に増え続けていて、それに追いつかなきゃというプレッシャーもどんどん強くなっていますよね。営業やオペレーションの現場を見ていると、意思決定そのものより、スプレッドシートの整形とかサイトからのコピペに時間を吸われてるケースを何度も見てきました。Salesforceによると、営業担当者は今やに使っていて、Asanaもだと報告しています。つまり、手作業のデータ収集にとんでもない時間が溶けているってこと。その時間があれば、商談を前に進めたり、キャンペーンを回したりできるはずです。
ここで朗報。ウェブスクレイピングはもう当たり前の手法になってきていて、必ずしも開発者じゃなくても大丈夫です。Rubyは昔からウェブデータ抽出の自動化で人気の言語ですが、みたいな最新のAIウェブスクレイパーと組み合わせると、「コードでガッツリ作り込みたい人」も「ノーコードでサクッと結果が欲しい人」も、どっちにとってもめちゃ理想的な形になります。マーケター、EC運用担当、あるいは終わりの見えないコピペ地獄にうんざりしてる人でも、このガイドを読めばRuby ウェブスクレイピングとAIでウェブスクレイピングを使いこなせます。しかも、スクレイピング用のコードは不要です。
Rubyで行うウェブスクレイピングとは?自動データ収集への入口
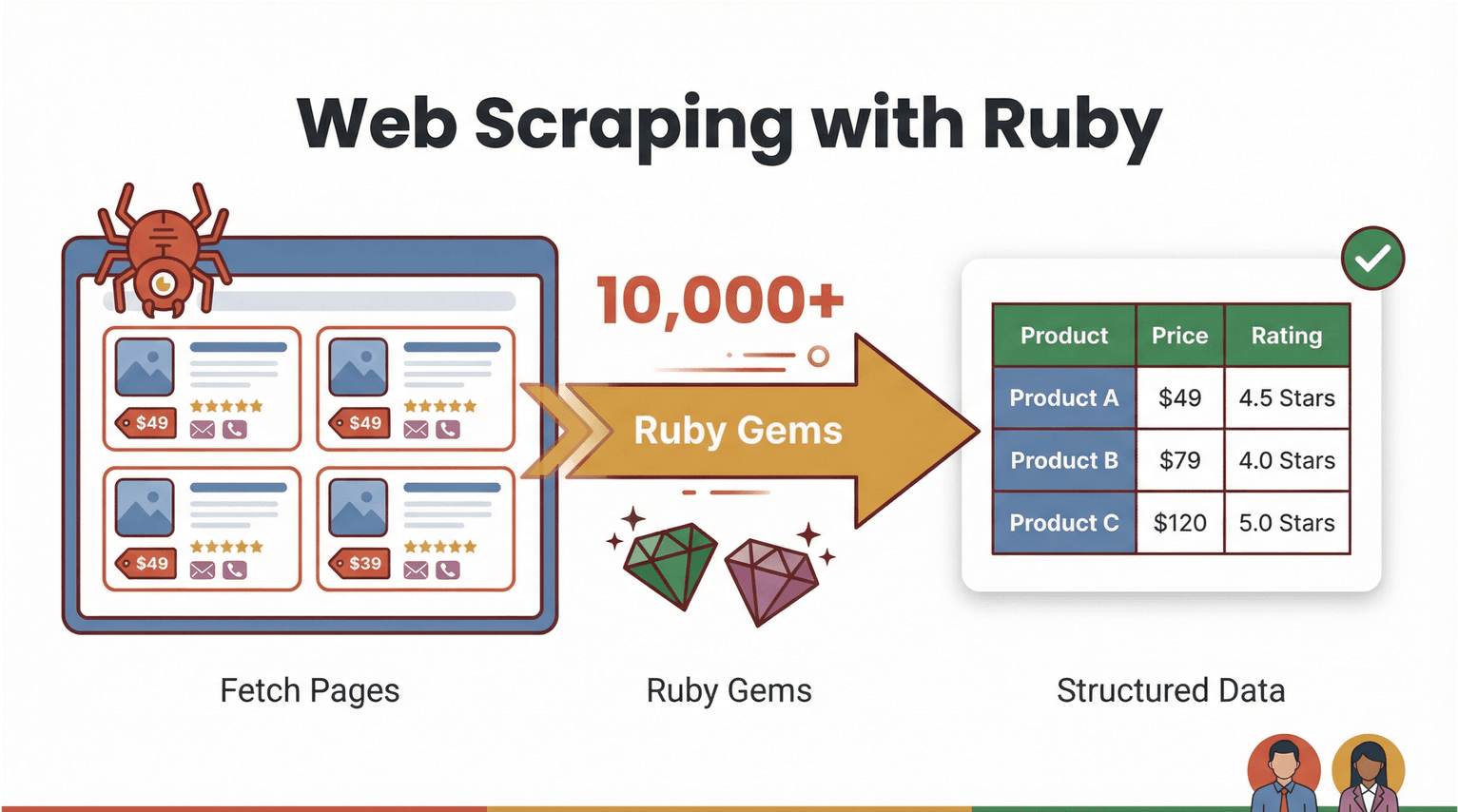
まずは基本からいきましょう。ウェブスクレイピングっていうのは、ソフトウェアでWebページを取得して、商品価格・連絡先・レビューみたいに必要な情報だけを抜き出し、CSVやExcelみたいな扱いやすい形に整える作業のことです。Rubyは読みやすい文法と、豊富な「gem」(ライブラリ)のおかげで、自動化に取り組みやすい言語として知られています()。
じゃあ「Ruby ウェブスクレイピング」って具体的に何をするの?というと、たとえばECサイトから商品名と価格を集めたい場合、Rubyのスクリプトでだいたいこんな流れを作れます。
- Webページをダウンロードする(など)
- HTMLを解析して欲しいデータを見つける()
- スプレッドシートやデータベースに出力する
ただ、今いちばん面白いのはここ。必ずしもコードを書く必要がないんです。みたいなAI搭載のノーコード ウェブスクレイパーなら、ページの読み取り、項目の自動判定、整った表形式での出力までを数クリックでやってくれます。Rubyはカスタムワークフローの「自動化の接着剤」として今でも優秀だけど、AIウェブスクレイパーの登場で、ビジネスユーザー側の使いやすさが一気に上がりました。
なぜRubyのウェブスクレイピングがビジネスチームに効くのか

正直、誰だって一日中コピペなんてやりたくないですよね。ウェブデータ抽出の自動化ニーズが急増してるのには、ちゃんと理由があります。Ruby(+AIツール)によるウェブスクレイピングが、業務をどう変えるのか見ていきましょう。
- リード獲得: ディレクトリやLinkedInから連絡先情報をまとめて収集し、営業パイプラインに投入。
- 競合価格モニタリング: 数百SKUの価格変動を追跡。手動チェックは不要。
- 商品カタログ作成: 商品情報や画像を集約し、自社ストアやマーケットプレイスに反映。
- 市場調査: レビュー、評価、ニュース記事を収集してトレンド分析。
投資対効果はかなり分かりやすいです。ウェブデータ収集を自動化すれば、週あたりの作業時間を削れて、ミスも減って、より新鮮で信頼できるデータが手に入ります。たとえば製造業では、データ量がたった2年で倍増しているのに、を続けています。自動化の伸びしろ、めちゃくちゃ大きいです。
RubyのウェブスクレイピングとAIツールがもたらす価値を、ざっくりまとめるとこんな感じ。
| 用途 | 手作業のつらさ | 自動化のメリット | よくある成果 |
|---|---|---|---|
| リード獲得 | メールを1件ずつコピペ | 数千件を数分で抽出 | リード数10倍、単純作業を削減 |
| 価格モニタリング | 毎日のサイト確認 | スケジュール実行で自動取得 | リアルタイムの価格インテリジェンス |
| カタログ作成 | 手入力で登録 | 一括抽出&整形 | 立ち上げが速い、ミスが減る |
| 市場調査 | レビューを手で読み込む | 大量収集して分析 | より深く、鮮度の高い洞察 |
しかも、単に速いだけじゃありません。自動化はミスを減らして、データの一貫性も上げてくれます。実際、にもなります。
ウェブスクレイピング手段を比較:Rubyスクリプト vs AIウェブスクレイパー
じゃあ、Rubyで自作するべき?それともAI搭載のノーコード ウェブスクレイパーを使うべき?ここを整理していきます。
Rubyスクリプト:自由度は最大、保守は必要
Rubyにはスクレイピング向けのgemがしっかり揃っています。
- : HTML/XML解析の定番。
- : WebページやAPI取得に便利。
- : Cookie、フォーム送信、画面遷移が必要なサイト向け。
- / : 実ブラウザ操作(JavaScript主体のサイトに強い)。
Rubyで作れば、独自ロジック、データ整形、社内システム連携など、やりたいことは基本なんでもできます。その一方で、サイトのレイアウト変更でスクリプトが壊れる…みたいな保守コストは避けられません。コードに慣れてない場合は学習コストもそれなりにかかります。
AIウェブスクレイパー&ノーコード:速い・簡単・変化に強い
みたいなノーコード ウェブスクレイパーは発想が逆。コードを書く代わりに、こんな手順で進めます。
- Chrome拡張を開く
- 「AI Suggest Fields」をクリックして、抽出項目をAIに提案させる
- 「Scrape」を押してデータを出力する
Thunderbitはページ構造の変化に強く、商品詳細みたいなサブページにも対応し、Excel/Google Sheets/Airtable/Notionへ直接エクスポートできます。面倒なく結果が欲しいビジネスユーザーにはかなり相性がいいです。
比較表はこちら。
| 手法 | メリット | デメリット | 向いている人 |
|---|---|---|---|
| Rubyスクリプト | 完全に制御できる、独自ロジック、柔軟 | 学習コストが高い、保守が必要 | 開発者、上級ユーザー |
| AIウェブスクレイパー | ノーコード、導入が速い、変更に強い | 細部の制御は弱め、制限がある場合も | ビジネスユーザー、運用チーム |
サイトが複雑になって、対スクレイピング対策も強くなる中で、多くの業務ではAIウェブスクレイパーが第一候補になりつつあります。
はじめの一歩:Rubyでスクレイピングする環境を整える
Rubyでスクリプトを試したい人向けに、環境構築を進めましょう。Rubyは導入が簡単で、Windows/macOS/Linuxに対応しています。
Step 1: Rubyをインストール
- Windows: をダウンロードして案内に従います。Nokogiriなどのネイティブ拡張に必要なMSYS2も含めて入れておくのがポイントです。
- macOS/Linux: バージョン管理にはが便利です。ターミナルで以下を実行します。
1brew install rbenv ruby-build
2rbenv install 4.0.1
3rbenv global 4.0.1(最新の安定版はで確認してください。)
Step 2: Bundlerと必須gemを入れる
Bundlerで依存関係を管理します。
1gem install bundlerプロジェクトにGemfileを作成します。
1source 'https://rubygems.org'
2gem 'nokogiri'
3gem 'httparty'続けて実行します。
1bundle installこれで、スクレイピングに必要な環境が揃います。
Step 3: 動作確認
IRB(Rubyの対話シェル)で次を試します。
1require 'nokogiri'
2require 'httparty'
3puts Nokogiri::VERSIONバージョン番号が表示されればOKです。
手順で理解:はじめてのRubyウェブスクレイパーを作る
実例として、スクレイピング練習用サイトから商品データを取得してみます。
以下は、書籍タイトル・価格・在庫状況を抽出するシンプルなRubyスクリプトです。
1require "net/http"
2require "uri"
3require "nokogiri"
4require "csv"
5BASE_URL = "https://books.toscrape.com/"
6def fetch_html(url)
7 uri = URI.parse(url)
8 res = Net::HTTP.get_response(uri)
9 raise "HTTP #\{res.code\} for #\{url\}" unless res.is_a?(Net::HTTPSuccess)
10 res.body
11end
12def scrape_list_page(list_url)
13 html = fetch_html(list_url)
14 doc = Nokogiri::HTML(html)
15 products = doc.css("article.product_pod").map do |pod|
16 title = pod.css("h3 a").first["title"]
17 price = pod.css(".price_color").text.strip
18 stock = pod.css(".availability").text.strip.gsub(/\s+/, " ")
19 { title: title, price: price, stock: stock }
20 end
21 next_rel = doc.css("li.next a").first&.[]("href")
22 next_url = next_rel ? URI.join(list_url, next_rel).to_s : nil
23 [products, next_url]
24end
25rows = []
26url = "#\{BASE_URL\}catalogue/page-1.html"
27while url
28 products, url = scrape_list_page(url)
29 rows.concat(products)
30end
31CSV.open("books.csv", "w", write_headers: true, headers: %w[title price stock]) do |csv|
32 rows.each { |r| csv << [r[:title], r[:price], r[:stock]] }
33end
34puts "Wrote #\{rows.length\} rows to books.csv"このスクリプトは、各ページを取得→HTML解析→データ抽出→CSV出力までをまとめてやります。books.csvはExcelやGoogle Sheetsで開けます。
よくあるつまずきポイント:
- gemが見つからないエラーが出たら、Gemfileを確認して
bundle installを実行してください。 - JavaScriptでデータを読み込むサイトでは、SeleniumやWatirなどのブラウザ自動化が必要になります。
ThunderbitでRubyスクレイピングを加速:AIウェブスクレイパーの実力
ここからは、でスクレイピングをもう一段引き上げる方法を紹介します。もちろんコード不要です。
Thunderbitは、任意のサイトから構造化データを「ほぼ2クリック」で抽出できるです。流れはこんな感じ。
- 抽出したいページでThunderbit拡張を開く
- **「AI Suggest Fields」**をクリック(例:商品名、価格、在庫などの列を提案)
- **「Scrape」**をクリック(ページネーション対応、必要ならサブページも追跡)
- Excel/Google Sheets/Airtable/Notionへエクスポート
Thunderbitの強みは、複雑で動的なページでも、壊れやすいセレクタやコードに頼らず抽出できるところ。さらに、Thunderbitで抽出したデータをRubyで加工・分析する、みたいな併用もできます。
プロの小技: Thunderbitのサブページスクレイピングは、ECや不動産チームに特に便利です。商品一覧のリンクを抽出して、各詳細ページに自動でアクセスし、仕様・画像・レビューなどを追加取得して、データセットを自動でリッチ化できます。
実務例:RubyとThunderbitでECの商品・価格データを収集する
ECチーム向けに、実際の運用フローとしてまとめます。
想定シーン: 競合の価格と商品情報を、数百SKU規模で継続的に監視したい。
Step 1: Thunderbitで商品一覧を抽出
- 競合サイトの商品一覧ページを開く
- Thunderbitで「AI Suggest Fields」(例:商品名、価格、URL)
- 「Scrape」→CSVでエクスポート
Step 2: サブページで情報を追加取得
- Thunderbitの「Scrape Subpages」で各商品の詳細ページにアクセスし、説明文・在庫・画像など追加項目を抽出
- リッチ化されたテーブルをエクスポート
Step 3: Rubyで加工・分析
- Rubyスクリプトでデータを整形・変換・分析します。たとえば:
- 価格を共通通貨に換算
- 在庫切れを除外
- 集計指標を作成
在庫ありだけを抽出する簡単な例です。
1require 'csv'
2rows = CSV.read('products.csv', headers: true)
3in_stock = rows.select { |row| row['stock'].include?('In stock') }
4CSV.open('in_stock_products.csv', 'w', write_headers: true, headers: rows.headers) do |csv|
5 in_stock.each { |row| csv << row }
6end結果:
生のWebページから、分析や施策に使える整ったデータ表へ。しかも、スクレイピング用のコードは1行も書かずに実現できます。
ノーコードでOK:誰でもできるウェブデータ抽出の自動化
Thunderbitの魅力は、非エンジニアでも使えるところです。RubyやHTML、CSSの知識は不要。拡張機能を開いてAIに任せて、出力するだけ。
学習コスト: RubyスクリプトはプログラミングとWeb構造の基礎が必要です。一方Thunderbitは、セットアップが「数日」じゃなく「数分」で終わります。
連携: Thunderbitは、ビジネスチームが普段使うExcel/Google Sheets/Airtable/Notionへ直接出力できます。定期実行(スケジュール)で継続監視も可能です。
現場の使われ方: マーケ、営業オペ、EC運用などが、リードリスト作成から価格追跡までをITに頼らず自動化しているのをよく見かけます。
ベストプラクティス:Ruby×AIウェブスクレイパーでスケールする自動化へ
堅牢で拡張性のある運用にするためのポイントです。
- サイト変更への備え: ThunderbitのようなAIウェブスクレイパーは自動で追従しやすい一方、Rubyスクリプトはサイト変更時にセレクタ更新が必要です。
- 定期実行: Thunderbitのスケジュール機能で定期取得。Rubyならcronやタスクスケジューラを使います。
- バッチ処理: 大量データは分割して取得し、ブロック回避や負荷軽減を。
- データ整形: 分析前に必ずクリーニングと検証を。Thunderbitは構造化済みですが、Rubyの独自処理では追加チェックが必要なこともあります。
- コンプライアンス: 公開情報のみを対象にし、
robots.txtを尊重し、プライバシー法に注意(EUではされます)。 - 代替手段: ブロックが厳しい場合は、公式APIや別データソースも検討しましょう。
使い分けの目安:
- フルコントロールや社内連携、独自ロジックが必要ならRuby。
- 速さ・手軽さ・変化耐性を重視するならThunderbit(単発でも定期でも)。
- 高度な運用は併用が最適:Thunderbitで抽出し、Rubyで加工・品質チェック・連携を行う。
まとめ:重要ポイント
Ruby ウェブスクレイピングは、データ収集を自動化する強力な手段でした。そして今は、ThunderbitのようなAIウェブスクレイパーによって、そのパワーが誰にでも手の届くものになっています。開発者は柔軟性を、ビジネスユーザーは手軽さを手に入れて、手作業を減らしながら、より速く・より良い意思決定につなげられます。
持ち帰ってほしいポイントは次の通りです。
- Rubyはウェブスクレイピングと自動化に強い(NokogiriやHTTPartyなどのgemが充実)。
- ThunderbitのようなAIウェブスクレイパーなら非エンジニアでも抽出できる(「AI Suggest Fields」やサブページ抽出が便利)。
- Ruby×Thunderbitの併用で最強:ノーコードで素早く抽出し、Rubyで加工・分析・自動化を追加。
- 営業・マーケ・ECにとって自動化は勝ち筋:手作業削減、精度向上、新しい洞察の獲得。
始める準備はできましたか?して、簡単なRubyスクリプトも試してみてください。節約できる時間にびっくりするはず。さらに深掘りしたい人は、でガイドや実例をチェックしてみてください。
よくある質問(FAQs)
1. Thunderbitでウェブスクレイピングするのにコーディングは必要ですか?
不要です。Thunderbitは非技術者向けに設計されています。拡張機能を開いて「AI Suggest Fields」を押すだけで、AIが抽出を進めます。Excel/Google Sheets/Airtable/Notionへそのまま出力でき、コードは一切いりません。
2. Rubyでウェブスクレイピングする主なメリットは?
NokogiriやHTTPartyなど強力なライブラリを使って、柔軟でカスタム性の高いワークフローを組める点です。完全な制御、独自ロジック、他システム連携が必要な開発者に向いています。
3. Thunderbitの「AI Suggest Fields」はどう動きますか?
ThunderbitのAIがページを解析し、商品名・価格・メールなど重要度の高い項目を自動検出して、表形式のカラム案として提示します。必要に応じて列を調整してから抽出できます。
4. ThunderbitとRubyを組み合わせて高度な運用はできますか?
もちろん可能です。複雑・動的なサイトはThunderbitで抽出し、その後Rubyで加工や分析を行うチームは多いです。カスタムレポートやデータのリッチ化に向いたハイブリッド運用です。
5. ビジネス利用でウェブスクレイピングは合法で安全ですか?
公開情報を取得し、サイトの利用規約やプライバシー法を守る範囲であれば一般に合法です。robots.txtを確認し、特にEUではGDPRの観点から、同意なく個人データを収集しないよう注意してください。
ウェブスクレイピングで業務がどう変わるか、試してみませんか?Thunderbitの無料枠を使うか、Rubyスクリプトで実験してみてください。困ったときはやにチュートリアルが揃っています。コード不要のウェブデータ自動化を、今日から始められます。
Learn More