「データはあっても情報は持てるが、データなしに情報を持つことはできない。」 — *
最近の推計では、インターネット上には15億以上のがあり、毎日およそ200万件の新しい投稿が公開されているそうです。この膨大なデータの中には、意思決定に効く貴重な洞察がたっぷり眠っています。ただし、ひとつ大きな課題が。およそは非構造化データで、そのままでは使えず、追加の処理が要るんです。そこで力を発揮するのがウェブスクレイピングツール。オンラインのデータを活用したい人にとっては、もう手放せない存在になっています。
ウェブスクレイピングが初めてだと、 や といった言葉に、ちょっと身構えてしまうかもしれません。でも、AI時代の今は、このハードルもずっと越えやすくなりました。今のAI搭載スクレイピングツールなら、深い技術知識がなくても始められます。コードを書かずに、データをサクッと収集・処理できるんです。
最適なウェブスクレイピングツールとソフトウェア
- — 使いやすいAIウェブスクレイパー。仕上がりも優秀
- — リアルタイム監視と一括データ抽出向け
- — 豊富なアプリ連携を備えたノーコード自動化向け
- — より本格的なビジュアル型ウェブスクレイピング向け
- — IPブロックやボット検知を回避しながら使える、強力なノーコードスクレイピング向け
- — 高度なAIデータ抽出APIとナレッジグラフ向け
AIを使ってウェブスクレイピングを試す
ぜひ触ってみてください。クリックしながら、操作を見て、ワークフローを実行できます。
ウェブスクレイピングって、どう動いてる?
ウェブスクレイピングとは、要するに「ウェブサイトからデータを取り出すこと」。ツールに一連の指示を渡すと、ページ上のテキストや画像など、必要な情報を表形式できれいに抽出してくれます。ECサイトの価格追跡から、調査データの収集、ExcelやGoogle スプレッドシートの整理まで、出番はとにかく広いです。
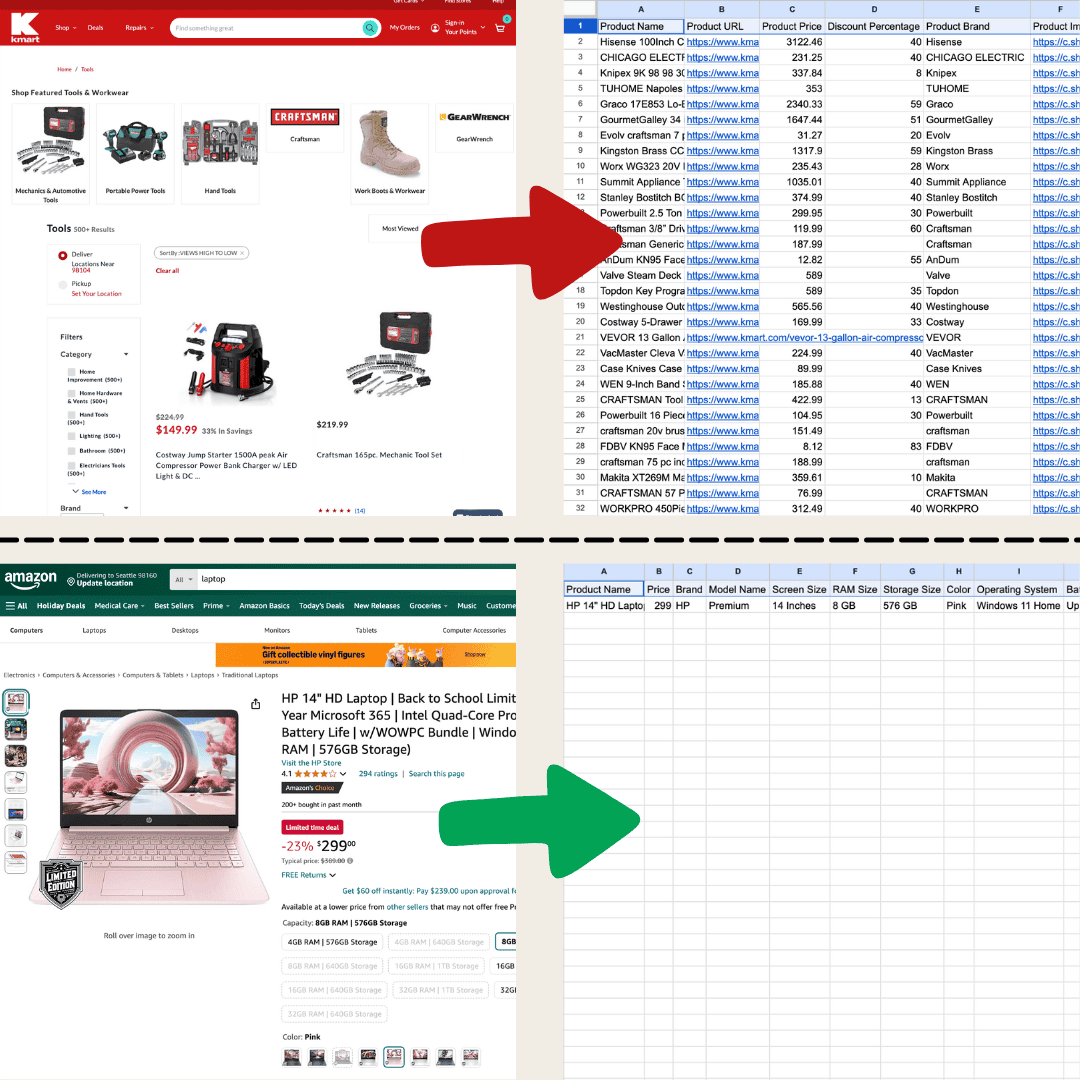 これはThunderbitのAIウェブスクレイパーで作成しました。
これはThunderbitのAIウェブスクレイパーで作成しました。
やり方はいくつもあります。いちばん原始的なのは手作業でコピー&ペーストする方法ですが、データ量が多くなると正直キツい。なので多くの人は、従来型のウェブスクレイパー、AIウェブスクレイパー、カスタムコード——この3つのどれかに落ち着きます。
従来型のウェブスクレイパーは、ページの構造をベースに、「どのデータをどう取るか」を細かいルールで指定して動きます。たとえば「この特定のHTMLタグから商品名と価格だけ取って」と設定できる、というイメージ。ページ構成があまり変わらないサイトには向いていますが、レイアウトが少しでもブレると、スクレイパーをまた調整する羽目になります。
 従来型スクレイパーは習得に時間がかかり、設定完了までに何十回もクリックすることだってあります。
従来型スクレイパーは習得に時間がかかり、設定完了までに何十回もクリックすることだってあります。
AIウェブスクレイパーは、ざっくり言うとChatGPTがサイト全体を読み取って、必要に応じて中身を抽出してくれる仕組みです。データ抽出、翻訳、要約を同時にこなせるのも強み。自然言語処理を使ってサイト構造を理解するので、サイトの変更にも比較的しなやかに追従できます。ページの配置が少し変わっても、AIウェブスクレイパーなら書き直しなしで合わせ込んでくれる、ということが普通にあります。だからこそ、更新頻度が高いサイトや、構造が複雑なサイトに向いています。
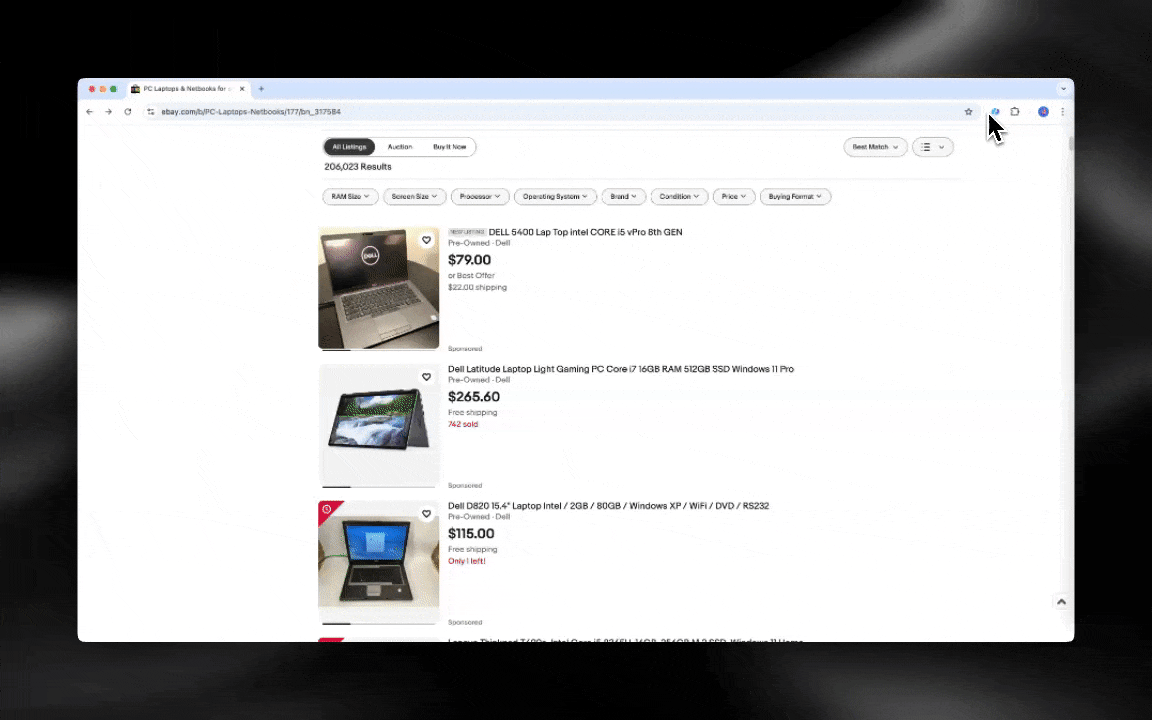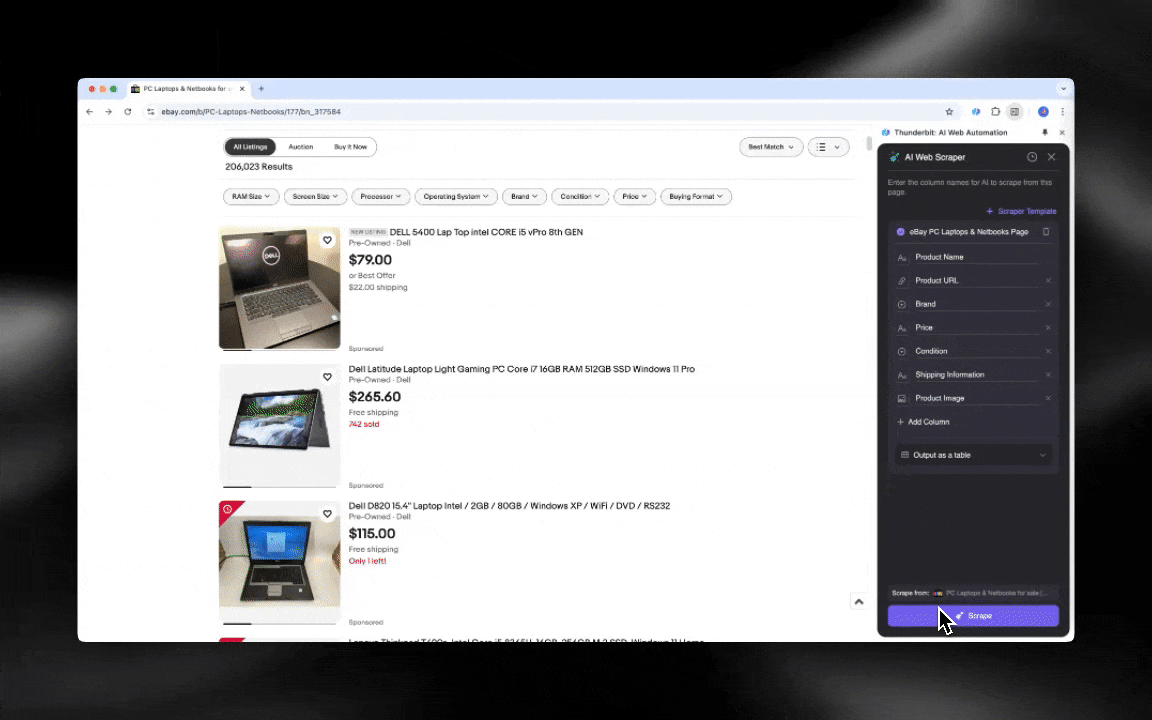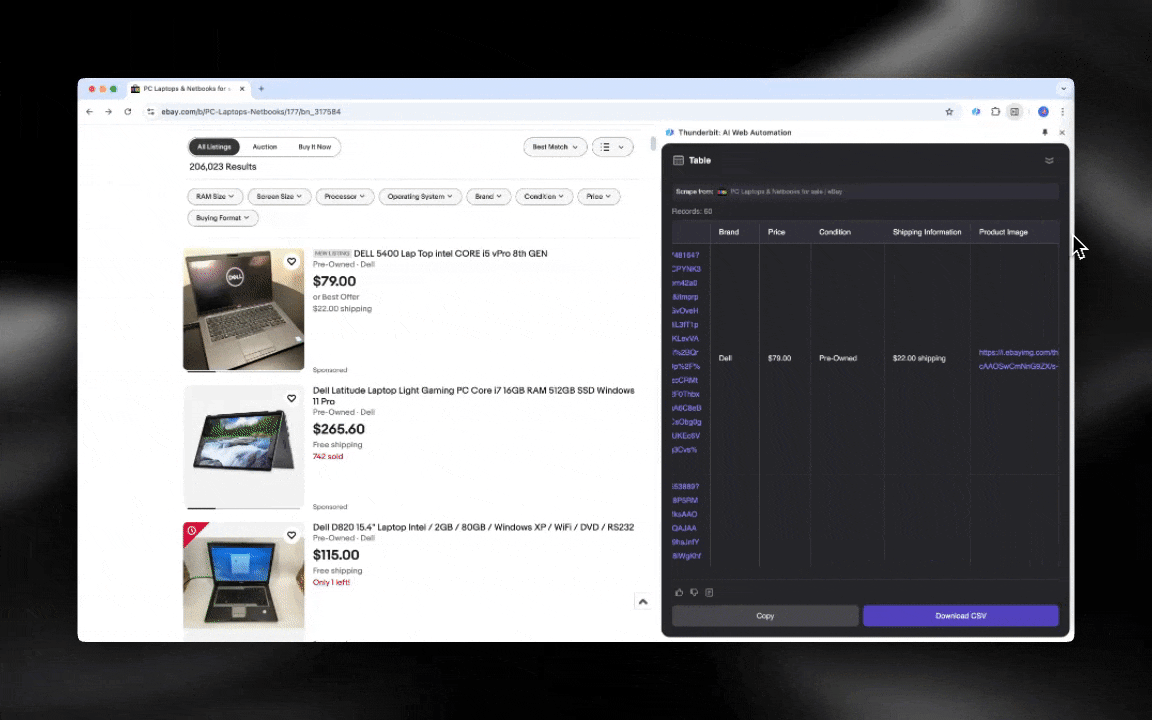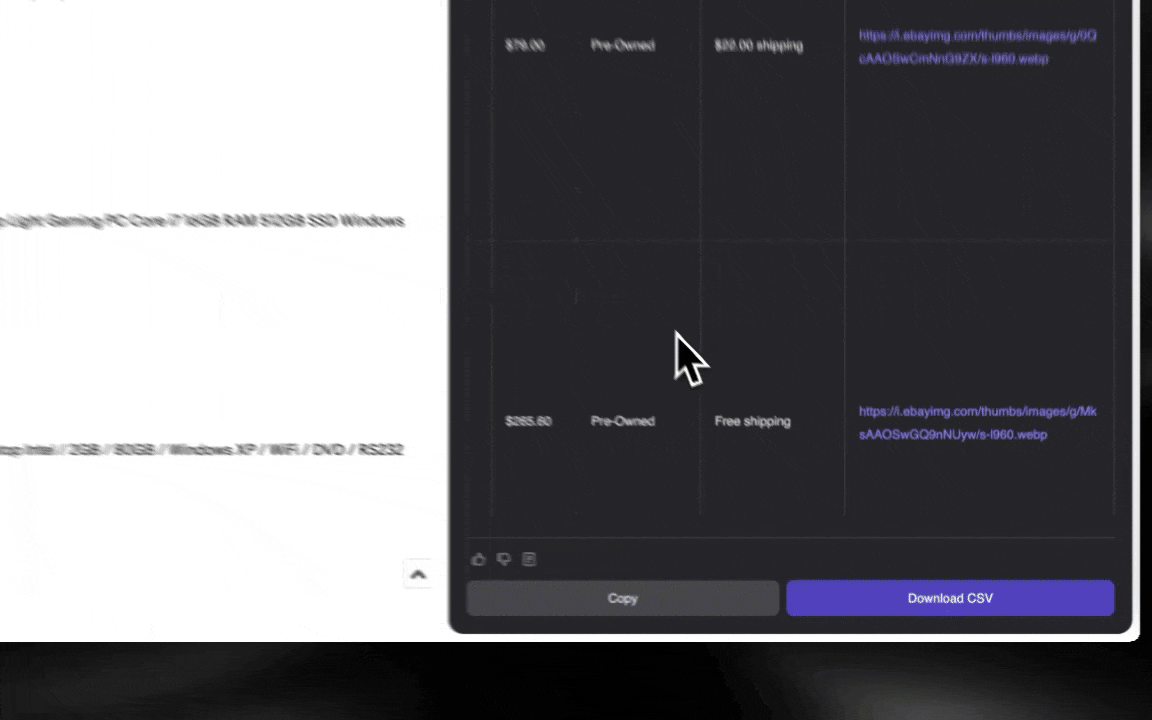 AIウェブスクレイパーはすぐ始められて、数クリックで詳細データが取れる!
AIウェブスクレイパーはすぐ始められて、数クリックで詳細データが取れる!
どちらを選ぶべき? それは場合によります。コードをいじるのが苦じゃない方、有名サイトから大量のデータを集めたい方には、従来型スクレイパーはとても効率的。一方、ウェブスクレイピングが初めての方、サイトの更新に柔軟に追随できるものが欲しい方には、たいていAIウェブスクレイパーのほうがハマります。より詳しいケース別の使い分けは、下の表をどうぞ。
| シナリオ | 最適な選択 |
|---|---|
| ディレクトリ、ショッピングサイト、一覧形式のページなどで軽めにスクレイピングしたい場合 | AIウェブスクレイパー |
| ページ内のデータが200行未満で、従来型ウェブスクレイパーでスクレイパーを作るのに時間がかかりすぎる場合 | AIウェブスクレイパー |
| 抽出したデータを別の場所へアップロードするため、特定の形式に整える必要がある場合。たとえば、HubSpotにアップロードする連絡先情報の抽出など。 | AIウェブスクレイパー |
| 数万件規模のAmazon商品ページやZillowの物件一覧のように、大規模に広く使われているサイト | 従来型ウェブスクレイパー |
一目で分かる最適なウェブスクレイピングツールとソフトウェア
| ツール | 料金 | 主な機能 | 長所 | 短所 |
|---|---|---|---|---|
| Thunderbit | 月額9ドルから、無料プランあり | AIウェブスクレイパー、自動検出とデータ整形、複数形式対応、ワンクリックエクスポート、使いやすいUI。 | コード不要、AIサポート、Google スプレッドシートなどのアプリ連携 | 大規模スクレイピングは遅くなることがある、高度な機能は追加費用がかかる場合あり |
| Browse AI | 月額48.75ドルから、無料プランあり | ノーコードUI、リアルタイム監視、一括データ抽出、ワークフロー連携。 | 使いやすい、Google スプレッドシートやZapierと連携可能 | 複雑なページでは追加設定が必要、一括スクレイピングはタイムアウトの原因になることがある |
| Bardeen AI | 月額60ドルから、無料プランあり | ノーコード自動化、130以上のアプリと連携、MagicBoxでタスクをワークフロー化。 | 連携が豊富、ビジネス向けに拡張しやすい | 初心者には学習曲線が急、初期設定に時間がかかる |
| Web Scraper | ローカル利用は無料、クラウドは月額50ドル | ビジュアル型のスクレイピング、動的サイト対応、クラウドスクレイピング。 | 動的サイトでうまく動作する、ローカル利用は無料 | 最適に設定するには技術的な知識が必要、変更時には複雑なテストが必要 |
| Octoparse | 月額119ドルから、無料プランあり | ノーコード操作、スマート自動検出、クラウドスクレイピング、豊富なテンプレートライブラリ。 | 強力な機能で動的サイトに対応しやすい、スクレイピング制限への対策がある | 複雑なサイト構造では設定に時間がかかる、初心者は使い方を覚えるのに時間が必要 |
| Diffbot | 月額299ドルから、無料プランあり | ルール不要のデータ抽出API、自然言語処理API、ナレッジグラフ。 | 強力な抽出機能と高い柔軟性、豊富なAPI連携、エンタープライズ向けに適している | 非技術者には学習時間が必要、APIを呼び出すためのプログラム作成が必要 |
AI時代に最適なウェブスクレイパー
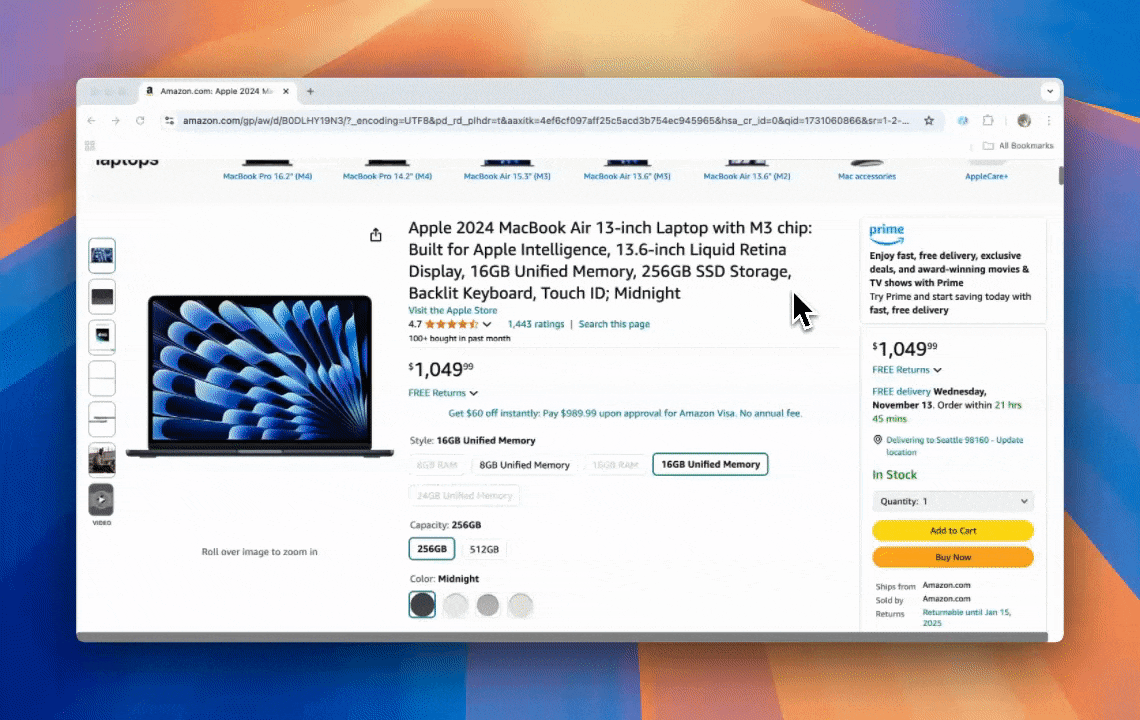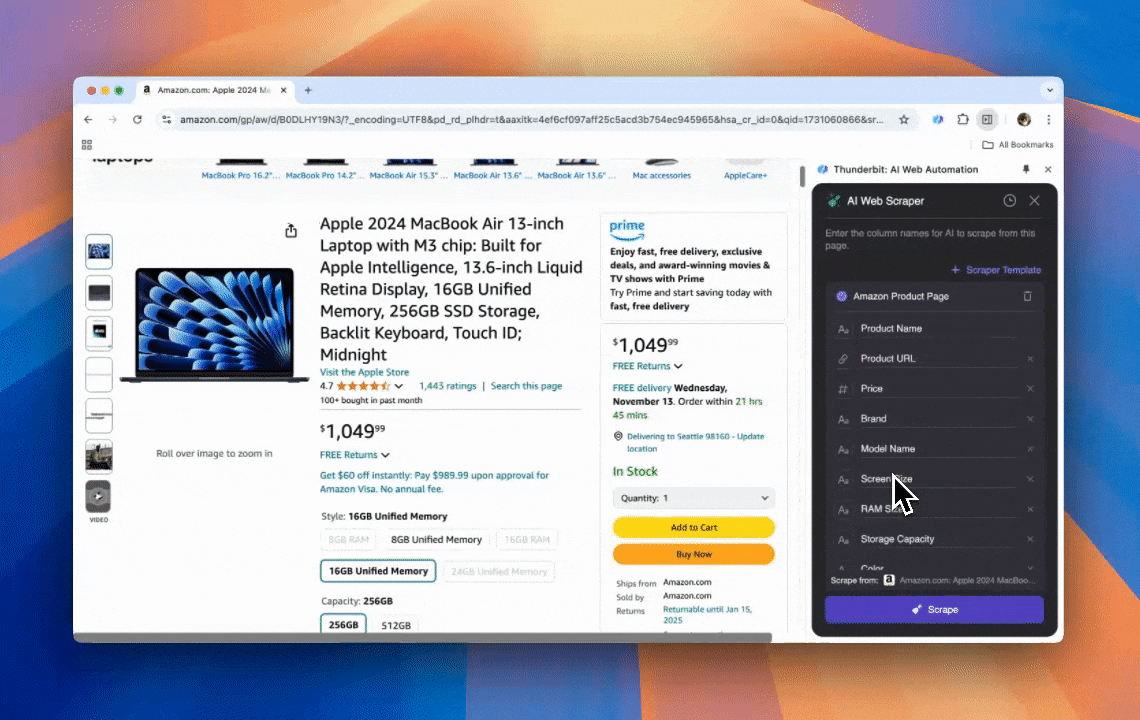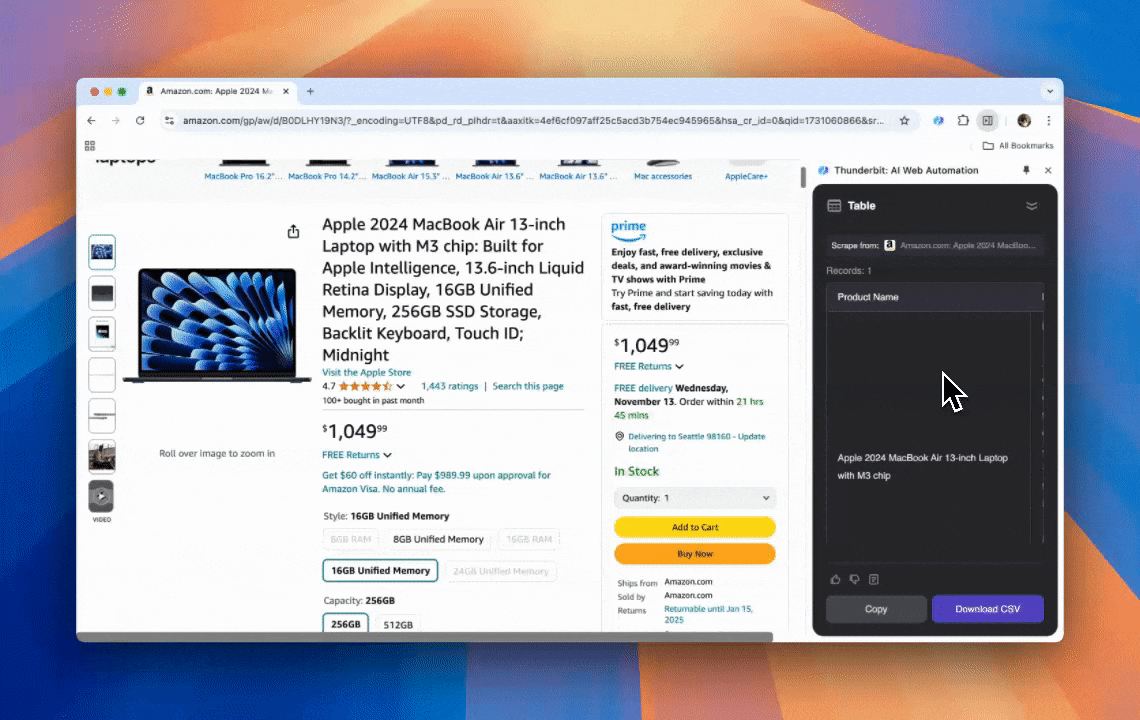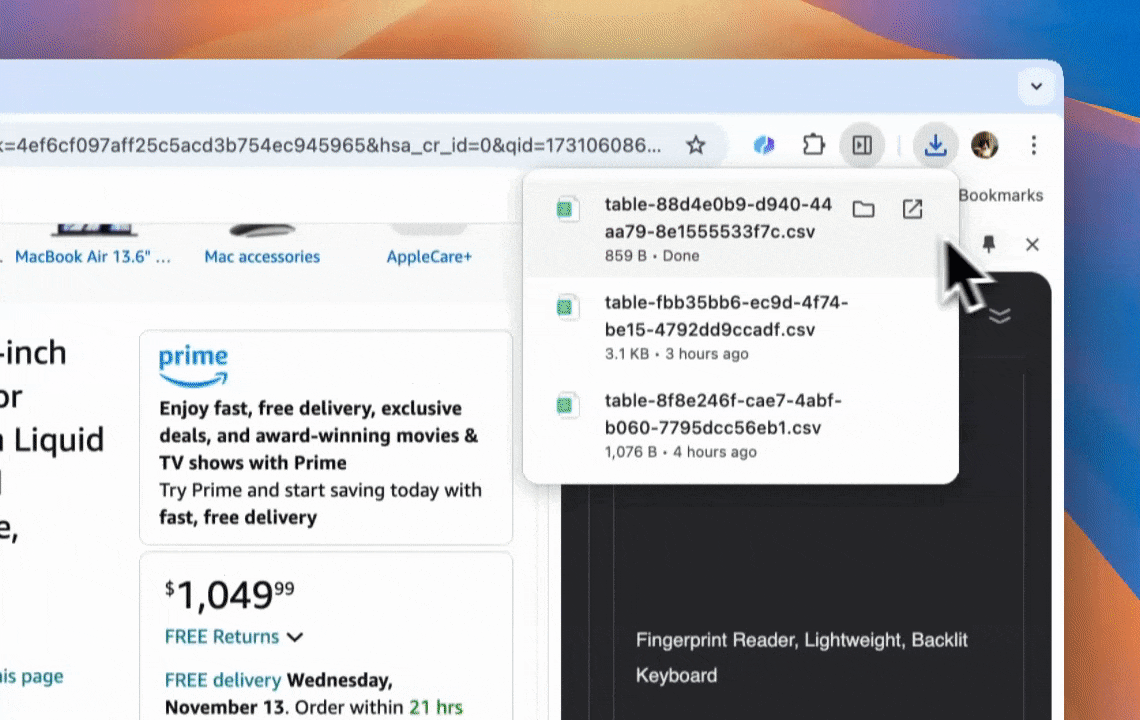
Thunderbitは、コード不要で使える強力かつ手触りのいいAIウェブ自動化ツール。プログラミング経験がなくても、データを抽出して整理するのがとにかく簡単になります。 を入れれば、Thunderbitの がデータ抽出をぐっと楽にしてくれて、ウェブ要素を手作業でいじったり、ページごとに別々のスクレイパーを用意したりする必要はありません。
主な機能
- AIによる柔軟性: ThunderbitのAIウェブスクレイパーはウェブデータを自動で検出・整形します。CSSセレクタは不要。
- 最も簡単なスクレイピング体験: 必要なのは「抽出したいページで『AIで列を提案』をクリック → そのあと『スクレイプ』をクリック」。これだけ。
- さまざまなデータ形式に対応: URLや画像をスクレイピングでき、取得したデータは複数の形式で表示可能。
- 自動データ処理: ThunderbitのAIは、要約、分類、指定形式への翻訳など、データをその場で再整形できます。
- 簡単なデータエクスポート: Google スプレッドシート、Airtable、Notionへワンクリック出力。データ管理がぐっと楽に。
- 使いやすいインターフェース: 直感的なUIで、どのレベルのユーザーにも馴染みやすい設計です。
料金
Thunderbitには段階的なプランがあり、5,000クレジットの月額9ドルから。最上位は240,000クレジットで199ドル。年額プランでは、クレジットが最初にまとめて付与されます。
長所:
- 強力なAIサポートで、データ抽出と処理がシンプルに。
- コード不要で、あらゆるスキルレベルのユーザーが使いやすい。
- ディレクトリやショッピングサイトなど、軽量なスクレイピングにぴったり。
- 主要アプリへ直接出力できる、高い連携性。
短所:
- 大規模データのスクレイピングは、精度を確保するために少し時間がかかることがあります。
- 一部の高度な機能は有料サブスクリプションが必要なケースも。
もっと知りたい方は まずはするか、Thunderbitで をご覧ください。
データ監視と一括抽出に最適なウェブスクレイパー
Browse AI
Browse AIは、コードを書かずにデータを抽出・監視できるよう設計された堅牢なノーコードデータスクレイピングツール。AI機能もありますが、本格的なAIスクレイピングほどではありません。それでも、立ち上がりの早さは魅力です。
主な機能
- ノーコードUI: クリック操作だけで独自のワークフローを作れます。
- リアルタイム監視: ボットでページの変更を追跡し、更新情報を届けてくれます。
- 一括データ抽出: 一度に最大50,000件のデータを処理できます。
- ワークフロー連携: 複数のボットをつないで、より複雑なデータ処理が可能。
料金
月額48.75ドルから、2,000クレジット込み。無料プランもあり、基本機能を試すために毎月50クレジットが付きます。
長所:
- Google スプレッドシートやZapierと連携できます。
- 事前構築済みのボットで、よくある抽出作業をサクッとこなせます。
短所:
- 複雑なページでは追加設定が必要になることがあります。
- 一括スクレイピングの速度は安定せず、タイムアウトが出ることも。
ワークフロー連携に最適なウェブスクレイパー
Bardeen AI
Bardeen AIは、さまざまなアプリをつないでワークフローを効率化するためのノーコード自動化ツール。AIで独自の自動化を作れますが、本格的なAIスクレイピングツールほどの柔軟性はありません。
主な機能
- ノーコード自動化: クリック操作でワークフローを設定。
- MagicBox: タスクを自然な言葉で説明すると、Bardeen AIがそれをワークフローに変換してくれます。
- 幅広い連携オプション: Google スプレッドシート、Slack、LinkedInを含む130以上のアプリと連携。
料金
月額60ドルから、1,500クレジット(およそ1,500行分のデータ)込み。無料プランでは、基本機能を試すために毎月100クレジットが使えます。
長所:
- 連携先が豊富で、さまざまなビジネスニーズに対応できます。
- 柔軟で、規模の大小を問わず導入しやすい。
短所:
- 新規ユーザーは、プラットフォーム全体を理解するまでに時間がかかることがあります。
- 初期設定にひと手間。
経験者向けの最適なビジュアル型ウェブスクレイパー
Web Scraper
その名のとおり、ツール名は「Web Scraper」。ChromeとFirefoxで使える人気のブラウザ拡張機能で、コードを書かずにデータを抽出できる、ビジュアル型のスクレイピングツールです。とはいえ、このツールを完全に使いこなすには、上のチュートリアルを見ながら数日かけて学ぶ必要があるかも。頭をあまり使わずにスクレイピングしたいなら、AIウェブスクレイパーを選びましょう。
主な機能
- ビジュアル作成: ウェブ要素をクリックするだけで、スクレイピングタスクを設定できます。
- 動的サイト対応: AJAXリクエストやJavaScriptを使う動的サイトにも対応可能。
- クラウドスクレイピング: Web Scraper Cloudでタスクをスケジュールし、定期的にスクレイピングできます。
料金
ローカル利用は無料。クラウド機能の有料プランは月額50ドルから。
長所:
- 動的サイトでうまく動作します。
- ローカル利用は無料。
短所:
- 最適に設定するには技術的な知識が必要です。
- 変更時には複雑なテストが必要になります。
IPブロックとボット検知を回避しやすい最適なウェブスクレイパー
Octoparse
Octoparseは、より技術寄りのユーザーがコードなしで特定のウェブデータを収集・監視するための多機能ソフトウェア。大規模なデータ収集に強いです。Octoparseはユーザーのブラウザに依存せず、クラウドサーバーを使ってデータをスクレイピングするため、IPブロックやボット検知を回避するためのさまざまな手法も用意されています。
主な機能
- ノーコード操作: コードを書かずにスクレイピングタスクを作成でき、さまざまな技術レベルのユーザーが扱いやすい設計。
- スマート自動検出: ページ上のデータを自動検出し、抽出可能な要素をすばやく見つけて、設定を簡単に。
- クラウドスクレイピング: 24時間365日のクラウドデータスクレイピングに対応し、スケジュール実行もOK。柔軟にデータを取得できます。
- 豊富なテンプレートライブラリ: 数百種類の事前設定テンプレートがあり、複雑な設定なしで人気サイトのデータにすぐアクセス。
料金
Octoparseの料金プランは月額119ドルから、100タスク込み。基本機能を試せる、月10タスクの無料プランもあります。
長所:
- 強力な機能で、動的サイトのスクレイピングを高い柔軟性でサポート。
- スクレイピング制限や動的コンテンツの問題に対処するための手段が用意されています。
短所:
- 複雑なサイト構造では、設定に時間がかかることが。
- 初心者は使い方を覚えるのに時間が必要です。
高度なAI搭載データ抽出APIに最適なウェブスクレイパー
Diffbot
Diffbotは、AIを使って非構造化のウェブコンテンツを構造化データへ変換する高度なウェブデータ抽出ツール。強力なAPIとナレッジグラフを備え、Web上の情報の抽出、分析、管理を支援してくれます。さまざまな業界や用途で活躍します。
主な機能
- データ抽出API: Diffbotはルール不要のデータ抽出APIを提供。URLを渡せば自動抽出してくれて、サイトごとに個別ルールを設定する必要がありません。
- 自然言語処理API: 非構造化テキストから、構造化されたエンティティ、関係性、感情を抽出し、独自のナレッジグラフ作成を支援します。
- ナレッジグラフ: Diffbotは最大級のナレッジグラフのひとつを擁し、人名や組織情報を含む豊富なエンティティデータをつないでいます。
料金
Diffbotの料金プランは月額299ドルから、250,000クレジット(おおよそ250,000回のAPIベースのウェブページ抽出に相当)込み。
長所:
- ルール不要で使える強力な抽出機能。柔軟性も高め。
- 既存システムに組み込みやすい、豊富なAPI連携オプション。
- 大規模なデータスクレイピングに対応していて、エンタープライズ用途にも向きます。
短所:
- 技術者でないユーザーは、初期設定にある程度の学習時間が必要です。
- 利用には、APIを呼び出すためのプログラム作成が必要です。
スクレイパーって、何に使える?
ウェブスクレイピングが初めてなら、まずはよく使われる用途から知ると入りやすいです。多くの人は、Amazonの商品一覧を取得したり、Zillowから不動産データを集めたり、Google マップから事業者情報を集めたりするために、スクレイパーを使っています。でも、ここはまだ入口にすぎません。Thunderbitの を使えば、ほぼあらゆるウェブサイトからデータを集められるようになり、日々の作業を効率化して時間を生み出せます。調査、価格追跡、データベース構築——ウェブスクレイピングは、インターネットのデータをあなたの仕事に活かす無数の選択肢を開いてくれます。
よくある質問
-
ウェブスクレイピングは合法ですか?
一般的には合法です。ただし、ウェブサイトの利用規約とアクセスするデータの性質には従う必要があります。必ず関連ポリシーを確認し、法的ガイドラインを守ってください。
-
ウェブスクレイピングツールを使うのにプログラミングスキルは必要ですか?
ここで紹介したツールの多くはプログラミングスキルを必要としませんが、OctoparseやWeb Scraperのようなツールは、ウェブ構造の基本知識やプログラミング的な考え方があると、よりうまく使えます。
-
無料のウェブスクレイピングツールはありますか?
はい。BeautifulSoup、Scrapy、Web Scraperのような無料ツールがあり、機能を制限した無料プランを提供しているツールもあります。
-
ウェブスクレイピングでよくある課題は何ですか?
よくある課題には、動的コンテンツ、CAPTCHA、IPブロック、複雑なHTML構造への対応があります。高度なツールや手法を使えば、これらの問題に効果的に対処できます。
さらに詳しく読む:
-
手間をかけずにAIを活用しましょう。