

If you need web data in 2026, the hard part is no longer "can this be scraped?" It is "which layer of tooling gets me usable data with the least wasted setup, maintenance, and infra cost?" That is why this page is organized around fit first: AI web scrapers for speed, no-code tools for repeatable browser jobs, APIs for scale and anti-bot work, and Python libraries for teams that want full control.
The Quick Answer
- Choose an AI web scraper if you want the fastest route from page to spreadsheet with minimal setup.
- Choose a no-code scraper if you need more explicit pagination, scheduling, login handling, or repeatable task control.
- Choose a scraping API if rendering, anti-bot protection, concurrency, and unblock rate matter more than interface simplicity.
- Choose a Python library if your team wants full ownership of requests, parsing, browser automation, retries, and deployment.
For most business teams, the mistake is moving down-stack too early. Start with the lightest tool that can do the job reliably, then move from AI to no-code to APIs to code only when your workflow forces that upgrade.
Download the full visual pack here: website scraping tools visual pack.
Quick Comparison Table: Website Scraping Tools at a Glance
Pricing signals below were checked against official product, pricing, or documentation pages on May 12, 2026. Where vendors use custom or usage-based billing, I describe the pricing model instead of forcing a fake apples-to-apples monthly number.
| Tool | Category | Best Fit | Why It Made This 2026 List | Pricing Signal (checked May 2026) |
|---|---|---|---|---|
| Thunderbit | AI web scraper | Sales, ops, ecommerce, real estate | Fastest non-technical path from web page to structured table | Free plan, paid tiers, business pricing |
| Kadoa | AI extraction platform | Data teams and larger recurring programs | Strong fit for self-healing, agent-style extraction workflows | Free evaluation, usage-based and enterprise plans |
| Octoparse | No-code scraper | Analysts and recurring operations jobs | Mature cloud scraping and visual task builder | Free plan, Standard from $69/month, higher tiers |
| ParseHub | Low-code scraper | Technical non-coders and researchers | Flexible navigation logic for harder sites | Free plan, paid plans from $189/month |
| Web Scraper | Browser no-code scraper | Beginners and lightweight repeatable jobs | Straightforward sitemap model with optional cloud layer | Free extension, Cloud from $50/month |
| Browse AI | No-code robot scraper | Monitoring and spreadsheet-first teams | Strong for repeatable monitoring and change alerts | Free plan, paid plans, managed tier |
| Bardeen | AI browser automation | GTM and revops automation | Best when scraping is one step inside a larger workflow | Free plan, Basic from $10/month, Premium and Enterprise |
| ScrapeStorm | AI-assisted visual scraper | Users who want quick visual setup | Useful bridge between manual selectors and AI assistance | Free trial, paid plans, enterprise pricing |
| ScraperAPI | Scraping API | Developers scaling request volume | Simple API plus proxy, CAPTCHA, and rendering offload | 7-day trial, paid from $49/month |
| Bright Data Web Scraper | Enterprise scraping platform | Procurement-heavy and compliance-focused programs | Broadest data collection stack in the group | Product-based and usage-based pricing |
| Zyte | API + anti-bot stack | Developer and data teams | Strong browser actions, JS rendering, and IP rotation | $5 free trial credit, usage-based plans |
| ZenRows | Scraping API | Startups and developer teams | Clean anti-bot API with lower-friction adoption | Free trial, Developer from $69/month |
| ScrapingBee | Scraping API | Teams scraping JS-heavy sites | Useful when rendering is the main pain point | Free trial, paid from $49/month |
| Selenium | Open-source browser automation | QA-style flows and interaction-heavy scraping | Still relevant where exact user interaction matters | Free and open-source |
| Beautiful Soup | Python parsing library | Lightweight Python scraping | Easiest parser in the stack for messy HTML | Free and open-source |
| Playwright | Modern browser automation | Modern web apps and developer teams | Best modern choice for scripted browser scraping | Free and open-source |
| urllib3 | Python HTTP library | Developers who want low-level request control | Useful foundation when you want to own transport behavior directly | Free and open-source |
How to Choose the Right Website Scraping Tool
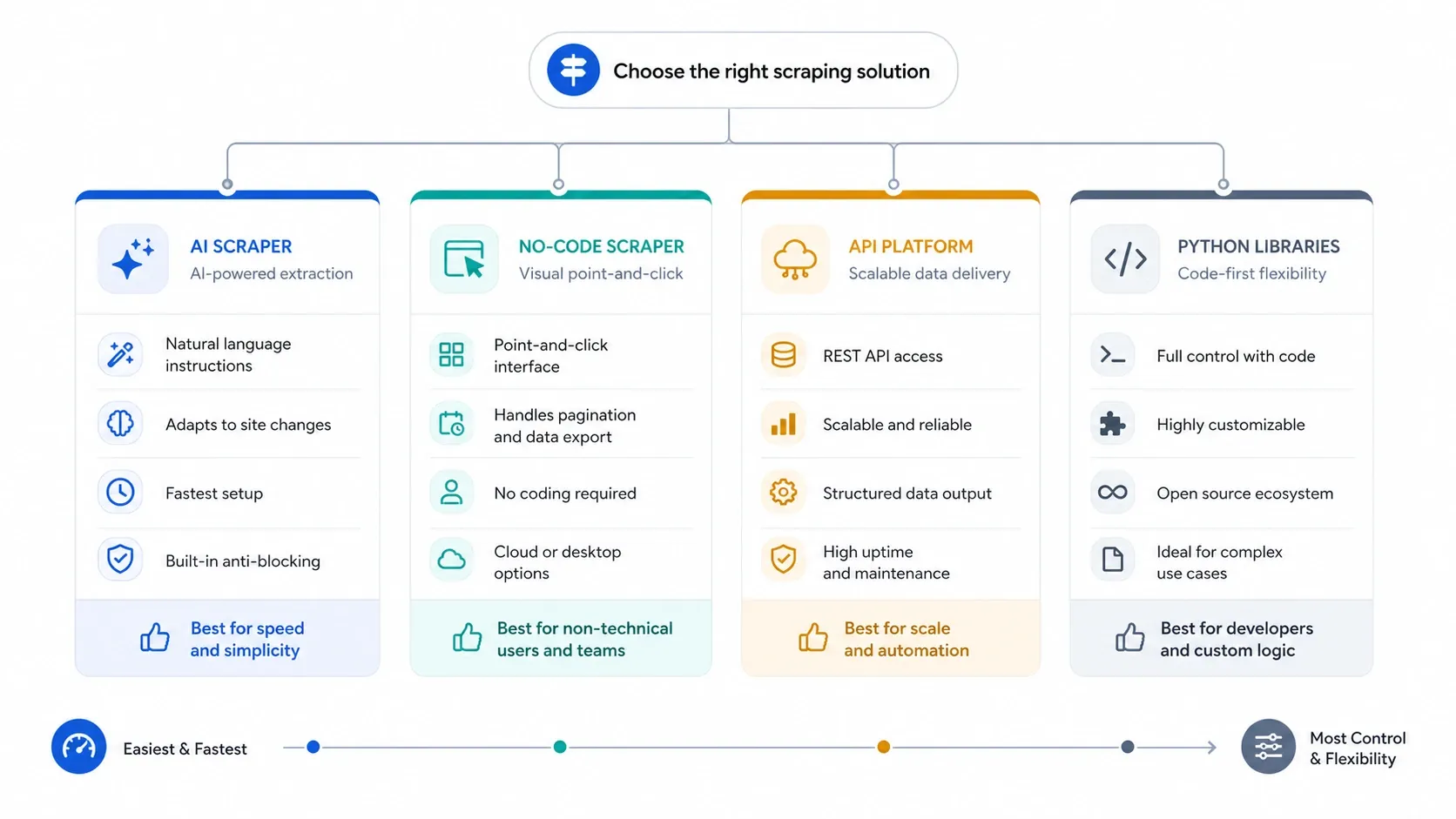
Use four filters before comparing brands:
- Time to first useful output
If the tool cannot get a real table out quickly, it is already losing for most business cases. - Maintenance burden
A cheap scraper that breaks every time the layout changes is not actually cheap. - Scale ceiling
A browser extension can be perfect for 50 pages a week and terrible for 5 million monthly requests. - Workflow fit
The best scraper for revops is rarely the best one for a platform engineer.
The decision framework is usually simpler than teams make it:
- If you want to scrape leads, listings, or product pages without touching selectors, start with AI.
- If you need repeatable tasks, cloud runs, and more explicit control, move to no-code visual builders.
- If anti-bot, JavaScript rendering, and concurrency are the real problem, jump to APIs.
- If you want to own every layer yourself, use Python libraries and accept the maintenance burden.
Best AI Web Scrapers for Fast Business Workflows
This is the first category I would test if the output you want is spreadsheet-ready data with as little configuration as possible.
1. Thunderbit
Thunderbit is still the easiest starting point here for non-coders. The core advantage is not just "AI" in the abstract; it is that the product compresses the setup loop. You open a page, ask AI to suggest fields, enrich via subpages when needed, and send the result straight to the tools your team already uses.
- Best for: sales prospecting, ecommerce monitoring, real estate collection, and ops teams living inside the browser.
- Why it stands out: fastest path from messy page to structured table.
- Watchout: if you need crawler-grade logic or highly custom engineering flows, you will eventually move to APIs or code.
- Pricing signal: free plan, self-serve paid tiers, and business pricing.
This walkthrough is still the fastest way to judge whether AI-first scraping is enough for your workflow:
Try Thunderbit AI Web Scraper for Free
2. Kadoa
Kadoa is the more infrastructure-oriented AI option in this group. It makes sense when you want self-healing extraction and recurring jobs at a larger operational scale than most browser extensions are built to handle.
- Best for: data teams, internal intelligence programs, and larger recurring extraction workloads.
- Why it stands out: agent-like orchestration and a stronger story around maintenance reduction.
- Watchout: it is heavier than what most business users need for quick one-off scraping.
- Pricing signal: free evaluation, usage-based and enterprise plans.
Best No-Code Website Scraping Tools for Repeatable Jobs
Once the scraping job becomes recurring, visual workflow builders and cloud execution start to matter more than pure one-click speed.
3. Octoparse
Octoparse remains one of the most credible no-code tools when the job is bigger than a browser extension but not yet a custom engineering project. Its value is in the combination of cloud runs, templates, and a mature visual task builder.
- Best for: analysts, pricing teams, and recurring collection jobs with real operational importance.
- Why it stands out: more depth than browser plugins, without forcing you into code.
- Watchout: you pay for that flexibility with a steeper learning curve than AI-first tools.
- Pricing signal: free plan, Standard from $69/month, higher paid tiers.
If you want to evaluate a more traditional no-code workspace before buying into AI-first tooling, this official Octoparse overview is still useful:
4. ParseHub
ParseHub is still relevant because there are plenty of teams that want more step-by-step task logic than a lightweight AI scraper provides. It is not the prettiest product in the category, but it remains flexible.
- Best for: researchers, journalists, and technical non-coders who can tolerate more setup.
- Why it stands out: stronger conditional logic and navigation control than many beginner tools.
- Watchout: slower to learn and less modern-feeling than newer entrants.
- Pricing signal: free plan, paid plans from $189/month.
5. Web Scraper
Web Scraper is one of the cleaner "learn the basics without buying a platform" options. If you like the sitemap model, it is still a reasonable on-ramp.
- Best for: beginners, hobby projects, and smaller browser-led jobs.
- Why it stands out: straightforward setup and easy progression from local extension to cloud plans.
- Watchout: it becomes limiting when you need more adaptive logic or stronger unblock handling.
- Pricing signal: free extension, Cloud from $50/month.
6. Browse AI
Browse AI remains a strong choice when scraping and monitoring matter equally. Its robot model is intuitive for business users who think in terms of "watch this page and tell me what changed."
- Best for: competitor monitoring, price tracking, and spreadsheet-first teams.
- Why it stands out: polished onboarding, recurring monitoring, and automation-friendly outputs.
- Watchout: complex high-volume jobs can become expensive faster than API-first stacks.
- Pricing signal: free plan, paid plans, managed tier.
For teams evaluating page monitoring rather than one-time extraction, this short official overview is still a good signal check:
7. Bardeen
Bardeen is less about pure scraping depth and more about what happens after the scrape. It is strongest when web extraction is one step inside a larger browser automation workflow.
- Best for: GTM ops, lead routing, CRM handoff, and browser-native automation.
- Why it stands out: strong workflow automation story around the scrape itself.
- Watchout: not the cleanest choice when extraction accuracy is the only thing that matters.
- Pricing signal: free plan, Basic from $10/month, Premium and Enterprise tiers.
8. ScrapeStorm
ScrapeStorm still fills a useful middle ground for users who want AI assistance but also expect a more traditional visual scraping environment.
- Best for: directory scraping, ecommerce page collection, and visually configured recurring jobs.
- Why it stands out: easier to start with than many older visual tools.
- Watchout: it is less polished than the category leaders and can feel narrower on harder sites.
- Pricing signal: free trial, paid plans, enterprise pricing.

Best Scraping APIs When Scale and Anti-Bot Handling Matter
This is the category to move into when the real constraint is no longer "how do I select the data?" and becomes "how do I keep this reliable under load?"
9. ScraperAPI
ScraperAPI remains one of the most accessible API-first products for developers who want to stop thinking about proxies and request success rates.
- Best for: developers who need to scale from prototype to production quickly.
- Why it stands out: straightforward API plus proxy, CAPTCHA, and rendering support.
- Watchout: you still own parsing, retries, and downstream data quality.
- Pricing signal: 7-day trial, paid from $49/month.
10. Bright Data Web Scraper
Bright Data is the heavyweight choice when unblock capability, proxy inventory, compliance posture, and managed options matter more than simplicity.
- Best for: enterprise-scale collection and compliance-sensitive programs.
- Why it stands out: the broadest stack in this comparison, from proxies to managed collection products.
- Watchout: easy to overbuy if your team still has a fairly simple workflow.
- Pricing signal: product-based and usage-based pricing.
11. Zyte
Zyte remains a serious option for developer teams that want browser actions, JS rendering, rotating IPs, and anti-bot posture under one platform story.
- Best for: engineering-led scraping programs and repeatable extraction systems.
- Why it stands out: strong anti-detection stack and API-first workflows.
- Watchout: better for teams with engineering ownership than for business users.
- Pricing signal: $5 free trial credit, usage-based plans.
12. ZenRows
ZenRows is one of the cleaner developer experiences in the API category if you want anti-bot handling without an enterprise-style buying process.
- Best for: startups, developers, and lean internal tools teams.
- Why it stands out: relatively low-friction adoption plus strong anti-bot positioning.
- Watchout: still an API product, so you keep the application logic and QA burden.
- Pricing signal: free trial, Developer from $69/month.
13. ScrapingBee
ScrapingBee makes sense when your real need is a rendered page and less infrastructure work, especially for JS-heavy sites.
- Best for: developers scraping dynamic sites who want rendering offload.
- Why it stands out: simple API around headless browsing and proxies.
- Watchout: it removes infra work, not the need for good scraping logic.
- Pricing signal: free trial, paid from $49/month.
Best Python Web Scraping Libraries for Custom Stacks
This group is still the right answer when control matters more than convenience and your team is ready to own maintenance.
14. Selenium
Selenium is not the newest browser tool, but it is still relevant where user interaction fidelity matters more than raw scraping throughput.
- Best for: interaction-heavy flows, QA overlap, and sites where browser behavior is the core challenge.
- Why it stands out: mature ecosystem and broad browser support.
- Watchout: heavier and slower than newer automation stacks for many scraping workloads.
- Pricing signal: free and open-source.
15. Beautiful Soup

Beautiful Soup remains the easiest parser in the Python scraping stack. It is not a complete scraping platform, but it is still the simplest way to turn messy HTML into usable structure.
- Best for: lightweight Python jobs, static HTML pages, and quick prototypes.
- Why it stands out: low cognitive load and forgiving parsing.
- Watchout: pair it with
requests, a browser layer, or a crawler; on its own it only parses. - Pricing signal: free and open-source.
16. Playwright
Playwright is my default modern recommendation for developer teams that need robust browser automation on today’s web.
- Best for: JavaScript-heavy sites, modern browser automation, and teams already comfortable writing code.
- Why it stands out: strong waiting behavior, multi-browser support, and clean APIs.
- Watchout: you still own concurrency, selectors, browser infra, and data validation.
- Pricing signal: free and open-source.
17. urllib3
urllib3 belongs on the list because some teams want direct control of transport behavior rather than a higher-level abstraction. It is not a beginner-friendly scraper, but it is a useful foundational library when you are building your own stack.
- Best for: developers who want tight control over retries, proxies, sessions, and HTTP behavior.
- Why it stands out: lightweight, reliable, and widely used as infrastructure.
- Watchout: you are building most of the stack yourself.
- Pricing signal: free and open-source.
Free Website Scraping Tools Worth Testing First
If you want to test before buying, the best free starting points in this list are Thunderbit, Octoparse, ParseHub, Web Scraper, Browse AI, Bardeen, Selenium, Beautiful Soup, Playwright, and urllib3. The free experience is good enough to learn what kind of scraper you actually need, which is usually more important than obsessing over a perfect feature checklist on day one.
My Shortlist by Team Type

- Sales, ops, and ecommerce teams: start with Thunderbit, then compare Browse AI if monitoring matters more than subpage enrichment.
- Analysts and recurring manual operators: Octoparse first, then ParseHub if you need more custom task logic.
- GTM automation teams: Bardeen if the scrape needs to flow directly into CRM, Sheets, or browser workflows.
- Developer teams building internal tooling: ScraperAPI, ZenRows, Zyte, or Playwright depending on how much stack ownership you want.
- Enterprise data programs: Bright Data and Zyte are the more serious infrastructure conversations here, with Kadoa as an AI-led alternative when maintenance reduction is the main goal.
When to Move Down-Stack
Use this upgrade path:
- Stay with AI web scrapers until you hit repeatability or edge-case limits.
- Move to no-code builders when scheduling, pagination, and cloud execution matter more than one-click simplicity.
- Move to APIs when unblock rate, rendering, and concurrency become the bottleneck.
- Move to Python libraries when vendor abstraction costs more than owning the whole system yourself.
Most teams do this in the wrong order. They overbuild first and only later realize a lighter tool could have solved the real workflow.
Final Take
The best website scraping tool in 2026 is not the one with the longest feature list. It is the one that gets accurate data into the next workflow with the least maintenance overhead for your team. That is why AI-first tools keep winning for operators, no-code tools remain valuable for repeatable browser jobs, APIs dominate when scale and blocking matter, and Python libraries still own the high-control end of the stack.
If your goal is to get useful data this week, start simple. If your workload is already telling you that unblock rate, browser rendering, and engineering control are the real problem, move down-stack deliberately instead of by habit.
Start with the Lightest Scraper That Can Actually Do the Job Get Started Free
FAQs
1. What is the best website scraping tool for non-technical users in 2026?
For most non-technical teams, AI-first tools like Thunderbit and Browse AI are still the fastest path because they reduce setup time, selector work, and maintenance overhead.
2. What should I choose for JavaScript-heavy or anti-bot-protected sites?
That is usually where ScraperAPI, Bright Data, Zyte, ZenRows, ScrapingBee, Playwright, or Selenium start to make more sense than browser extensions.
3. Are no-code scraping tools still relevant now that AI scrapers are better?
Yes. Octoparse, ParseHub, Web Scraper, and Browse AI still matter when you need more explicit task control, recurring runs, or browser-visible debugging.
4. Which tools make the most sense for developer teams?
ScraperAPI, Zyte, ZenRows, ScrapingBee, Playwright, Selenium, Beautiful Soup, and urllib3 are the most natural fits when engineering owns the workflow.
Related Reading




