

トレンドに乗り遅れないため、私はかつて200超のニュースソースに目を光らせていました。手作業でやれば、それだけでフルタイムの仕事。では従来型スクレイパーに頼れば? いいえ、レイアウトが少し動くたびに崩れるのが現実でした。
転機はAI記事スクレイパーを試した日。ワンクリックでクリーンなデータが手に入り、CSSセレクタともおさらば。世界がまるで違って見えました。
ジャーナリスト、SEO担当、リサーチャーとして記事を大量に集めるなら、この比較が試行錯誤をぐっと短縮します。昔ながらのノーコードスクレイパーとAI搭載型を両方回したうえで、本当に使えるのはどれかをお伝えします。
AIであらゆるウェブサイトをスクレイピング Get Started Free
要点だけ先に
| メリット | デメリット | 最適な用途 | |
|---|---|---|---|
| AI記事スクレイパー | - 複数サイトを高精度でスクレイピングできる - ノイズを自動で除去 - ウェブ構造の変化に適応できる - 動的コンテンツの読み込みに対応 - データクレンジングコストが低い | - 計算コストが高い - 処理時間が長い - 一部ページでは手動介入が必要 - スクレイピング対策に引っかかる場合がある | - ニュースポータルやSNSなど、複雑または動的なサイトの取得 - 大規模なデータ収集 |
| 従来型ノーコード記事スクレイパー | - 実行が速い - コストが低い - サーバーやローカルのリソース消費が少ない - コントロールしやすい | - ウェブ構造の変化により頻繁なメンテナンスが必要 - 複数サイトを同時に取得できない - 動的コンテンツに対応できない - データクレンジングコストが高い | - 単純な静的ページを短時間で大規模にスクレイピングしたい場合 - 計算資源や予算が限られている場合 |
記事スクレイパーとは? なぜAI記事スクレイパーが重要なのか?
記事スクレイパーはウェブスクレイパーの一種で、ニュースサイトから見出し、著者名、公開日、本文、キーワード、画像、動画といった情報を取得し、JSON、CSV、Excelのような構造化フォーマットへ整えます。
ここで従来型のノーコード記事スクレイパーは、ページのHTML構造を手がかりにコンテンツを抜くため、CSSセレクタを使います。ところが、このやり方には穴があります。
- 汎用性が低い: ウェブ構造が異なればサイトごとに個別のCSSセレクタが要り、構造が変わると使えなくなって頻繁な更新が必要です。
- 動的コンテンツに対応できない: 多くのサイトはAJAXやJavaScriptで読み込みますが、CSSセレクタでは直接スクレイピングできません。
- データ処理が限定的: CSSセレクタで取れるのはHTMLの断片だけで、その後のクレンジング、整形、意味解析、感情分析には対応できません。
 ここで主役に躍り出るのがAI記事スクレイパーです。
ここで主役に躍り出るのがAI記事スクレイパーです。
-
この技術はLLMでウェブページを理解し、次の機能を提供します。
- インテリジェントな認識: 見出し、著者名、要約、本文を識別します。
- ノイズの自動除去: 本文とナビゲーション、広告、関連記事を見分けて分離し、データ品質と効率を高めます。
- ウェブ変化への適応: ウェブ構造やスタイルが変わっても、意味理解と視覚的特徴をもとにスクレイピングを続けられます。
- サイト横断の汎用性: 従来型スクレイパーと違い、手動調整なしで異なるサイトに適用できます。
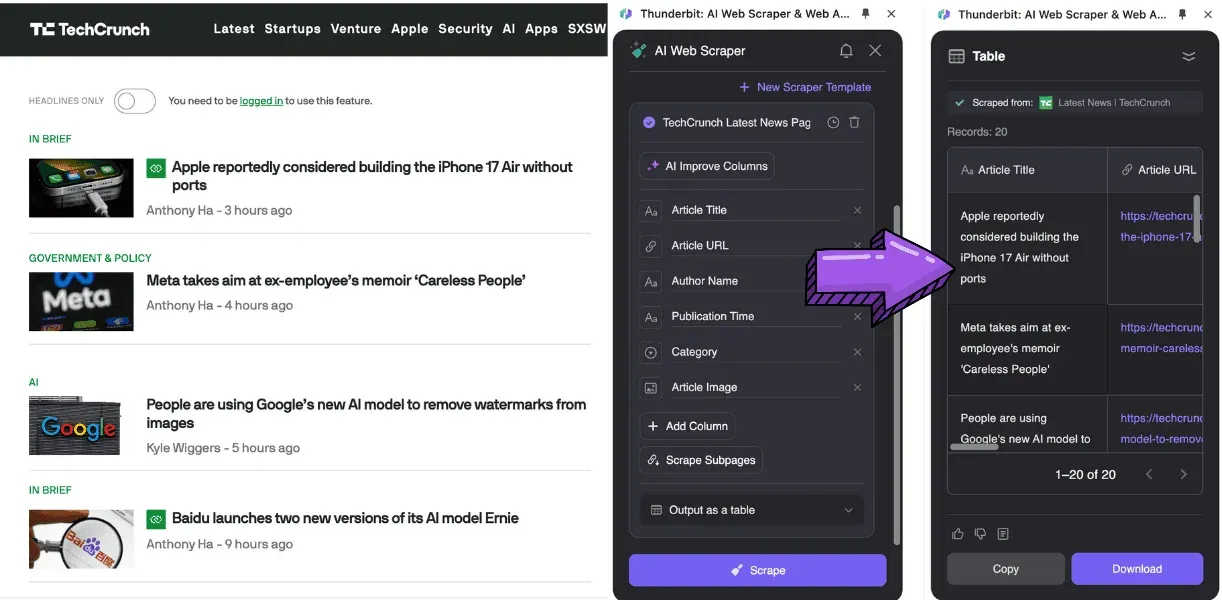
- NLPと深層学習との統合: 翻訳、要約、感情分析などの作業までこなせます。
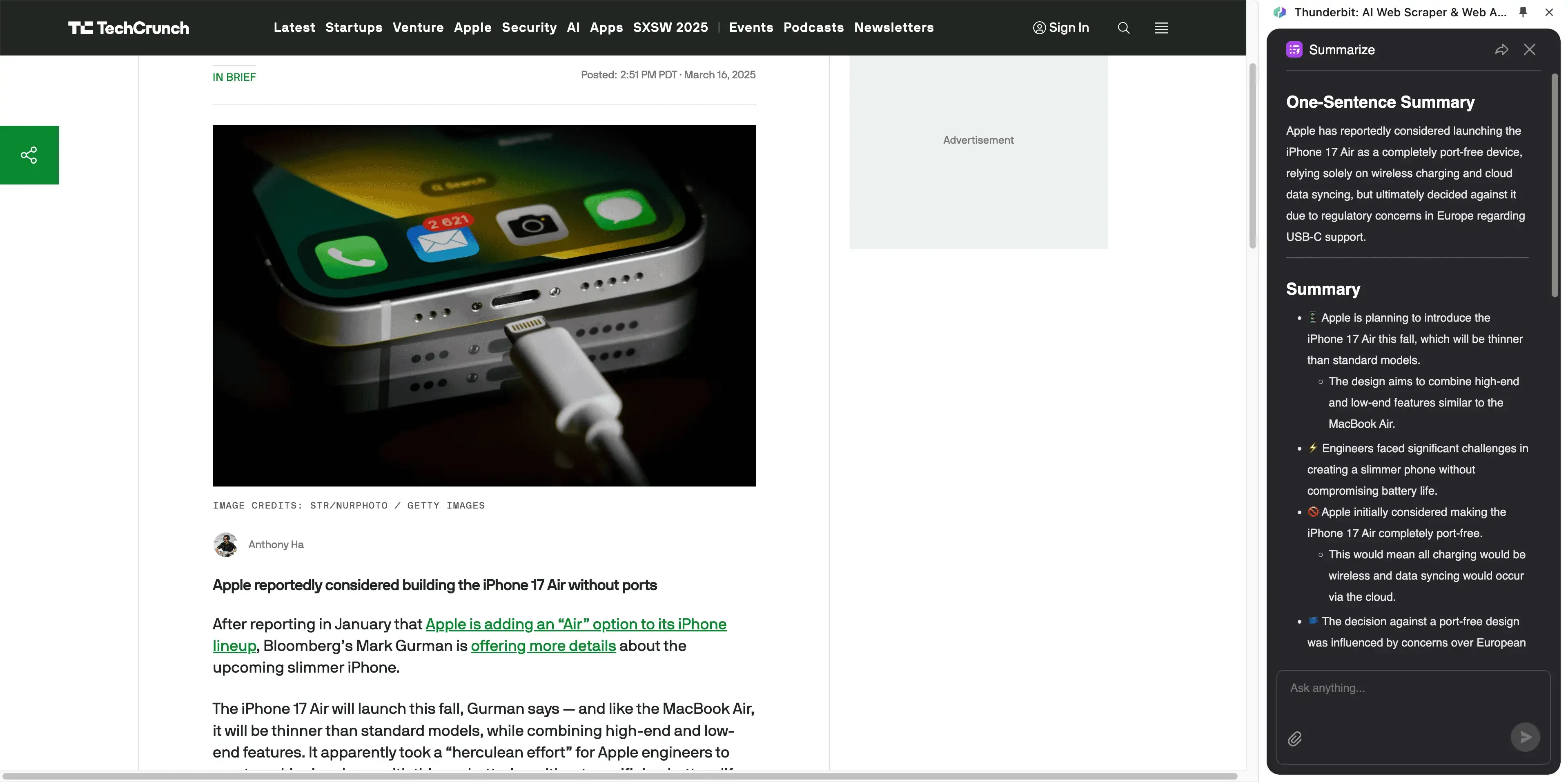
2026年に最適な記事スクレイパーとは?
優れた記事スクレイパーは、性能、コスト、使いやすさ、柔軟性、拡張性がうまく釣り合っています。2026年に最適な一本を見極める判断軸が、以下です。

- 使いやすさ: 直感的な操作画面で、コーディング不要。
- 記事抽出の精度: 広告やナビゲーションを除き、関連情報を正確に識別。
- ウェブ変化への適応力: 頻繁な保守なしで、構造や見た目の変化に自動対応。
- さまざまなウェブへの対応力: 多様なウェブ構造で動作。
- 動的コンテンツ対応: JavaScriptやAJAXによる動的読み込みに対応。
- マルチメディア対応: 画像、動画、音声を認識。
- スクレイピング対策への対応: IPローテーション、CAPTCHA対策、プロキシで回避。
- リソース使用のバランス: メモリや計算資源を過剰に消費しない。
ベストな記事・ニューススクレイパー一覧
| ツール | 主な機能 | 最適な用途 | 料金 |
|---|---|---|---|
| Thunderbit | AI搭載スクレイパー; 事前構築テンプレート; PDF、画像、ドキュメントのスクレイピング対応; 高度なデータ処理機能 | 技術知識がないまま複数のニッチサイトをスクレイピングしたいユーザー | 7日間無料トライアル、月額9ドルから(年額プラン) |
| WebScraper.io | ブラウザ拡張機能; 動的コンテンツ対応; プロキシ統合なし | 複雑なページや高度な機能を必要としないユーザー | 7日間無料トライアル、月額40ドルから(年額プラン) |
| Browse.ai | ノーコードのウェブスクレイパー兼モニター; 事前構築ロボット; 仮想ブラウザ; 各種ページネーション方式; 強力な連携機能 | 大規模で複雑なサイトをスクレイピングしたい企業 | 月額19ドル(年額プラン) |
| Octoparse | CSSセレクタベースのノーコードスクレイパー; 自動検出とスクレイピングワークフロー生成; 事前構築の記事スクレイパーテンプレート; 仮想ブラウザ; スクレイピング対策回避機能 | 複雑なサイトをスクレイピングしたい企業 | 月額99ドルから(年額プラン) |
| Bardeen | 包括的なウェブ自動化機能; 事前構築テンプレート; ノーコードスクレイパー; ワークスペースとのシームレスな連携 | 記事スクレイピングを既存ワークフローに組み込みたいGTMチーム | 7日間無料トライアル、月額99ドルから(年額プラン) |
| PandaExtract | 使いやすいUI; 自動検出とラベリング | 複雑な設定なしで、すばやくワンクリック抽出したいユーザー | 49ドルの買い切り |
ビジネスユーザー向けの最も強力なAI記事スクレイパー
- メリット:
- 自然言語でAIを呼び出し、CSSセレクタなしでウェブ情報を認識・分析できる
- 形式変換、要約、分類、翻訳、タグ付けなどのAI支援分析に対応
- 事前構築の記事テンプレートで、記事一覧と本文をワンクリック取得できる
- 価格が手頃でコスパが高い
- デメリット:
- 現在はChrome拡張機能のみ
- 大規模データのスクレイピングには向かない
- 複数ページでは速度がやや遅いが、バックグラウンド実行で結果を早められる
企業向けのAI搭載記事スクレイパー
Browse.ai
- メリット:
- ノーコードの記事スクレイパー兼モニター
- スクレイピング対策を引き起こしにくい仮想ブラウザ操作に対応
- Googleニュース、Medium、Hacker Newsなどをワンクリック取得できる豊富な事前構築ロボット
- ZapierやMakeなどと深く連携し、ツールをつなげられる
- デメリット:
- ディープ抽出には2つのロボットが必要で、手順が複雑
- CSSセレクタの精度がニッチサイトでは不十分
- 料金が高く、継続的な大規模スクレイピング向き
小規模データ抽出向けのノーコードスクレイパー
PandaExtract
- メリット:
- 使いやすいインターフェースで、記事一覧と詳細を自動識別
- 一覧、詳細、メール、画像を抽出でき、小規模な構造化データに適する
- 買い切りで半永久的に利用可能
- デメリット:
- ブラウザ拡張機能のみで、クラウド実行は不可
- 無料版はコピーのみで、CSVやJSONへのエクスポートは不可
組織向けのオールインワン記事スクレイパー
Octoparse
- メリット:
- ウェブ構造の認識とワークフロー生成を自動で行うノーコード記事スクレイパー
- 豊富な事前構築テンプレートですぐ使える
- 仮想ブラウザ、IPローテーション、CAPTCHA対策、プロキシでスクレイピング対策を回避
- デメリット:
- 自動検出は依然CSSセレクタのロジック依存で、精度は平均的
- 高度な機能には学習と技術スキルが必要
- 大規模スクレイピングではコストが高い
GTMチーム向けの最も包括的な自動化
Bardeen
- メリット:
- LLMによるワンクリック自動化ができるノーコードの記事スクレイパー
- Googleスプレッドシート、Slack、Zoomを含む100以上のアプリと連携
- データ取得後のAI分析に使える強力なウェブ自動化ツール
- 既存ワークフローへの組み込みに最適
- デメリット:
- 事前構築プレイブックへの依存が強く、カスタムワークフローは試行錯誤が要る
- ノーコードでも、複雑な自動化の理解と設定に非技術者の学習時間が要る場合がある
- サブページ抽出の設定が複雑
- 非常に高価
即時データ抽出向けの軽量記事スクレイパー
Webscraper.io
- メリット:
- ポイント&クリック型のノーコードスクレイパー
- 動的コンテンツの読み込みに対応
- クラウドベースで動作
- Dropbox、Googleスプレッドシート、Amazonと連携
- デメリット:
- 事前構築テンプレートがなく、カスタムサイトマップが必要
- CSSセレクタに不慣れだと学習コストがある
- ページネーションやサブページ抽出の設定が複雑
- クラウド版は高価
エンジニア向けのさらに高度な選択肢
技術的な素地がある方なら、記事スクレイパーAPIという道も開けます。この種のソリューションの強みは、次のとおりです。
- 柔軟性: カスタムスクレイピングのために直接APIを呼べ、動的レンダリングやIPローテーションに対応
- 拡張性: 企業向けの高頻度・大規模需要に合わせ、独自のデータパイプラインへ組み込める
- 保守コストの低さ: プロキシプールやスクレイピング対策を管理せずに済み、運用時間を節約できる
APIソリューション一覧
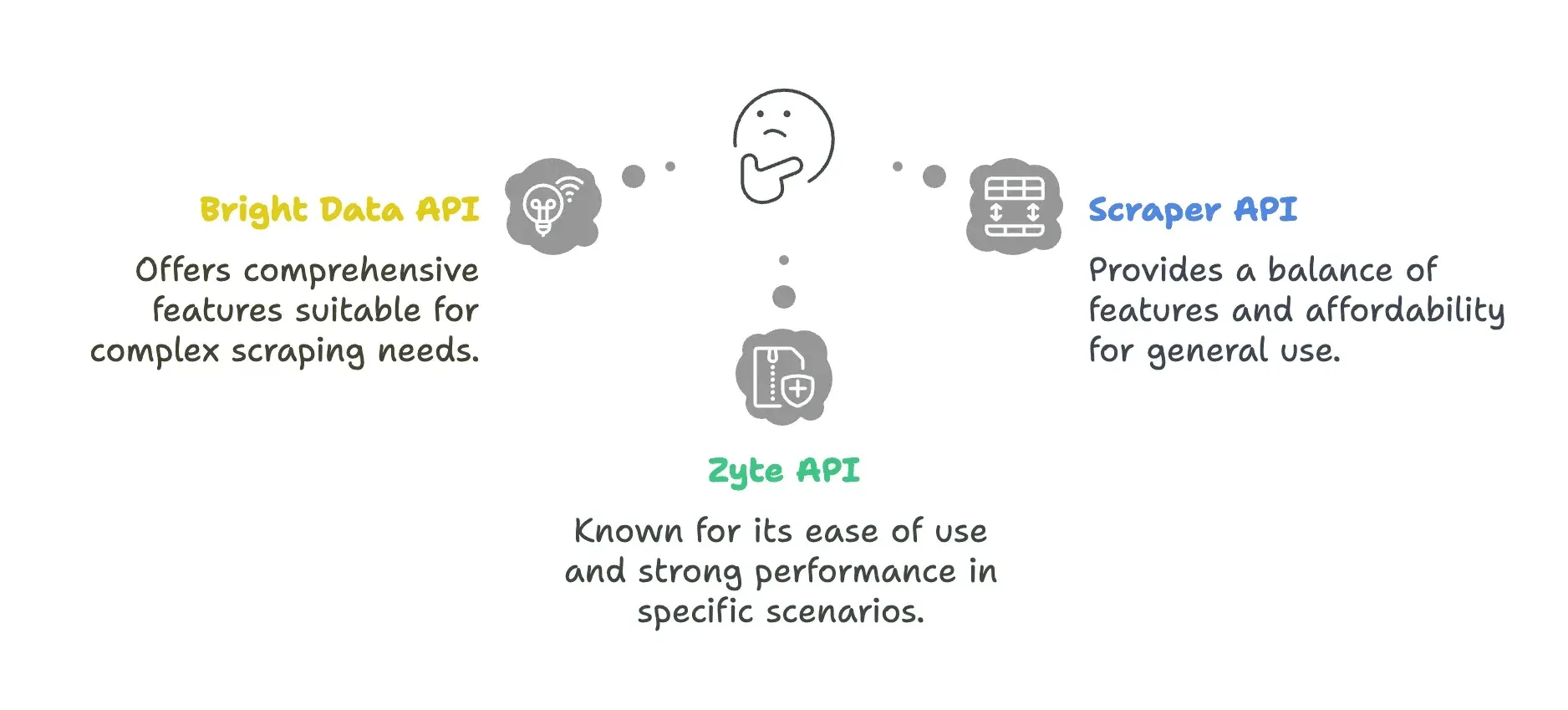
| API | メリット | デメリット |
|---|---|---|
| Bright Data API | - 広範なプロキシネットワーク(195か国で7,200万以上のIP) - 都市/郵便番号レベルまで対応する高度なジオターゲティング - IPローテーション用の強力なProxy Manager | - 応答速度が遅め(平均22.08秒) - 料金が高く、小規模チームには不向き - 設定の学習コストが高い |
| ScraperAPI | - 49ドルから始めやすい - 自動データ抽出のAutoparse機能 - テスト用のWeb UIプレーヤー | - ブロックされたリクエストにも課金されることが多い - JavaScriptレンダリング機能が限定的 - プレミアムパラメータでコストが膨らむ可能性がある |
| Zyte API | - AIによる解析機能 - 失敗したリクエストには課金されない | - 初期コストが高い(約月450ドル) - クレジットは翌月に繰り越されない |
- Bright Data Web Scraper API
- Scraper API
- メリット:
- 世界中で4,000万のプロキシ、自動のデータセンター/住宅IP切り替え、Cloudflare認証の回避、2CaptchaなどのCAPTCHA対策連携に対応
- 構造化エンドポイントと非同期スクレイパーで高速に取得できる
- デメリット:
- 動的ページのレンダリングには追加料金が要り、複雑なAJAXサイトへの対応は限定的
- メリット:
- Zyte API
- メリット:
- AI搭載の自動抽出で、サイトごとに抽出ルールを開発・保守する必要がない
- 柔軟な従量課金制
- デメリット:
- セッション管理やスクリプト実行可能ブラウザなどの高度な機能には学習が要る
- メリット:
記事・ニューススクレイパーの選び方
記事・ニューススクレイパーを選ぶときは、業務要件、技術的な土台、予算の3点を天秤に。

- ページごとにスクレイパーを作り込まず複数のニッチサイトを取得したい、しかも予算がある——そんなケースでは、Thunderbitが筆頭候補です。CSSセレクタに依存せず、AIがウェブ構造を読み解き、取得後のAI分析まで面倒を見ます。Thunderbit AIから見れば、どのサイトも区別はありません。記事全体を高精度で吸い上げます。
- ウォール・ストリート・ジャーナルやGoogleニュースのような大規模サイトから取得するには、強力なスクレイピング対策と事前構築テンプレートを備えた記事スクレイパーが欠かせません。Browse.aiやOctoparseがそれです。ただ、いちばんのおすすめはThunderbitのようなChrome拡張機能。ブラウザを開いてコピペするのに近い感覚で取れるので、込み入った設定なしにログイン情報まで扱えます。
- 大規模かつ継続的に集めたいなら、Octoparseのようなスケジュール機能を備えたツールが相性良好です。
- チーム利用や既存ワークフローへのスムーズな組み込みを重視するなら、Bardeenが最適。記事スクレイピングの枠を超えた幅広いウェブ自動化ツールを備えます。
- 学習に時間を割かず、小規模なデータ抽出をこなす軽量な一本が欲しいなら、PandaExtractのようなポイント&クリック型を。
- 技術的な背景がある、あるいは企業向けの記事スクレイパーを自前で組むなら、これらのノーコードスクレイパーに加えて、APIツールや自作スクレイパーも視野に入れてください。
結論
この記事では、記事・ニューススクレイパーという概念と、その活躍するビジネスシーンを取り上げました。従来型スクレイパーはCSSセレクタを土台にするため、込み入った操作ほどウェブのHTMLやCSSの知識が要ります。対照的に、新世代のAI搭載記事スクレイパーはAIの意味理解と視覚認識だけを拠り所とし、ウェブ構造の変化への適応、サイト横断の汎用性、動的コンテンツ対応、取得後のクレンジングと分析のいずれでも従来型を凌駕します。
さらに、開発者に便利な記事・ニューススクレイパーとAPIツールを6つ取り上げ、長所と短所、適したデータ規模、ウェブ機能、対象ユーザーを比べました。記事・ニュースのスクレイピングでは、性能とコストの兼ね合いを見ながら、自社のニーズにいちばん合うものを選んでください。
よくある質問
1. AI記事スクレイパーとは何ですか? どう動作しますか?
- AIでウェブページを解析し、CSSセレクタなしでコンテンツを抽出します。
- 見出し、著者名、公開日、本文を高精度で識別します。
- 広告、ナビゲーションメニュー、その他の不要要素を自動で除去します。
- ウェブ構造の変化に適応し、異なるサイトでも動作します。
2. 従来型スクレイパーと比べて、AI搭載記事スクレイパーを使う利点は何ですか?
- 1つのツールで複数サイトからコンテンツを抽出できます。
- JavaScriptやAJAXで読み込まれる動的コンテンツにも対応します。
- CSSベースより手動設定と保守が少なくて済みます。
- 要約、翻訳、感情分析などの追加機能も使えます。
3. コーディング不要でThunderbitを使ってAI記事スクレイピングできますか?
- はい。Thunderbitは、技術知識がないユーザー向けのシンプルなノーコードUIを備えます。
- AIが記事コンテンツを自動で検出・抽出します。
- 事前構築テンプレートで、素早く効率的にスクレイピングできます。
- CSV、JSON、Googleスプレッドシートなど、さまざまな形式へエクスポートできます。
さらに詳しく:
AIウェブスクレイパーを試す Get Started Free




