Wikipedia Search Result Scraper
क्या आप बल्क में डेटा स्क्रैप करना चाहते हैं? Thunderbit को मुफ्त में आज़माएँ।








Collect Wikipedia Search Results Fast
How to Extract Wikipedia Results Using Thunderbit



Learn how to extract structured data from Wikipedia search results
Collect Topic Data from Wikipedia Search Pages

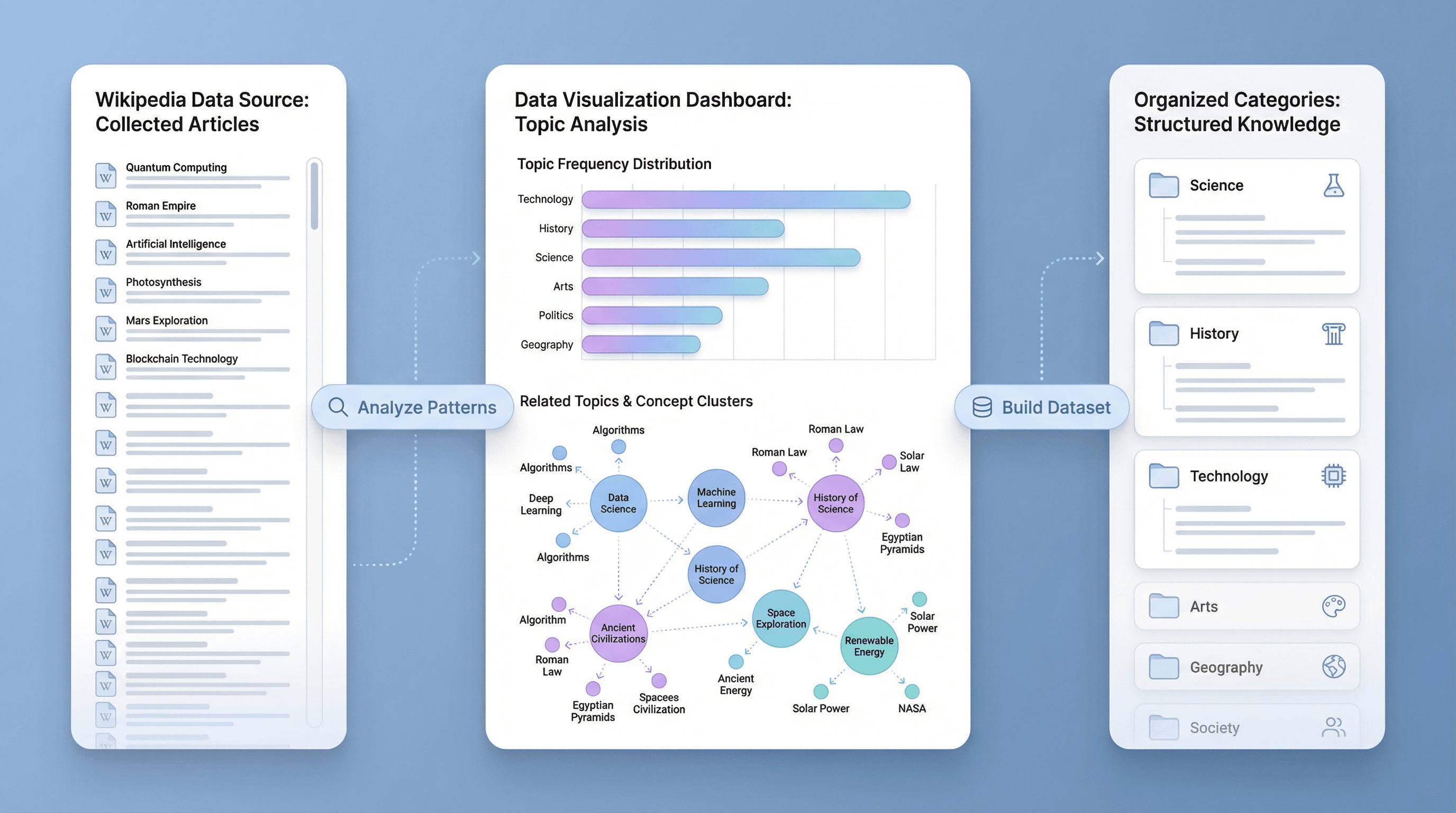
Analyze and Organize Large Sets of Wikipedia Results
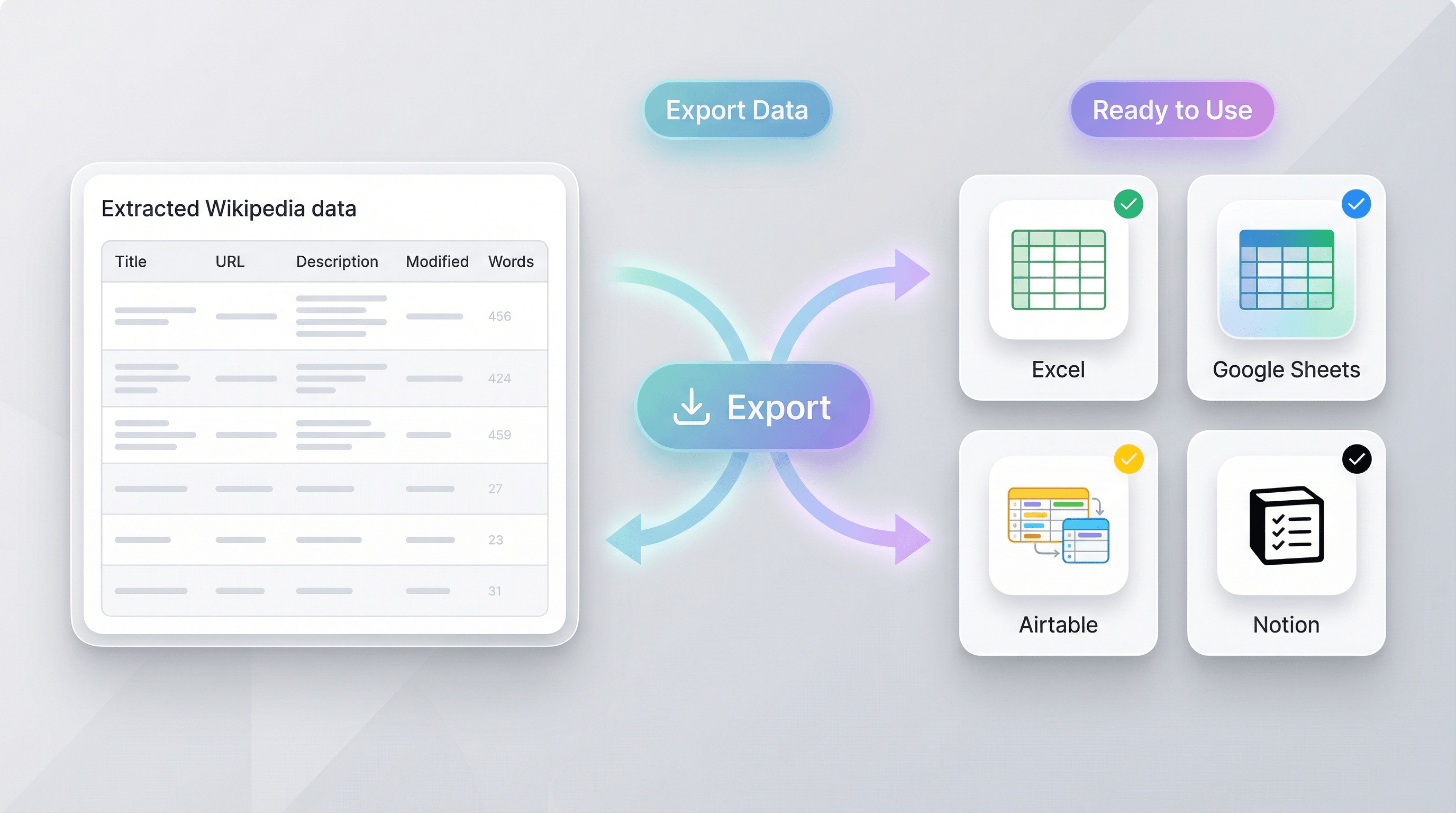
Export Wikipedia Data to Spreadsheets and Databases
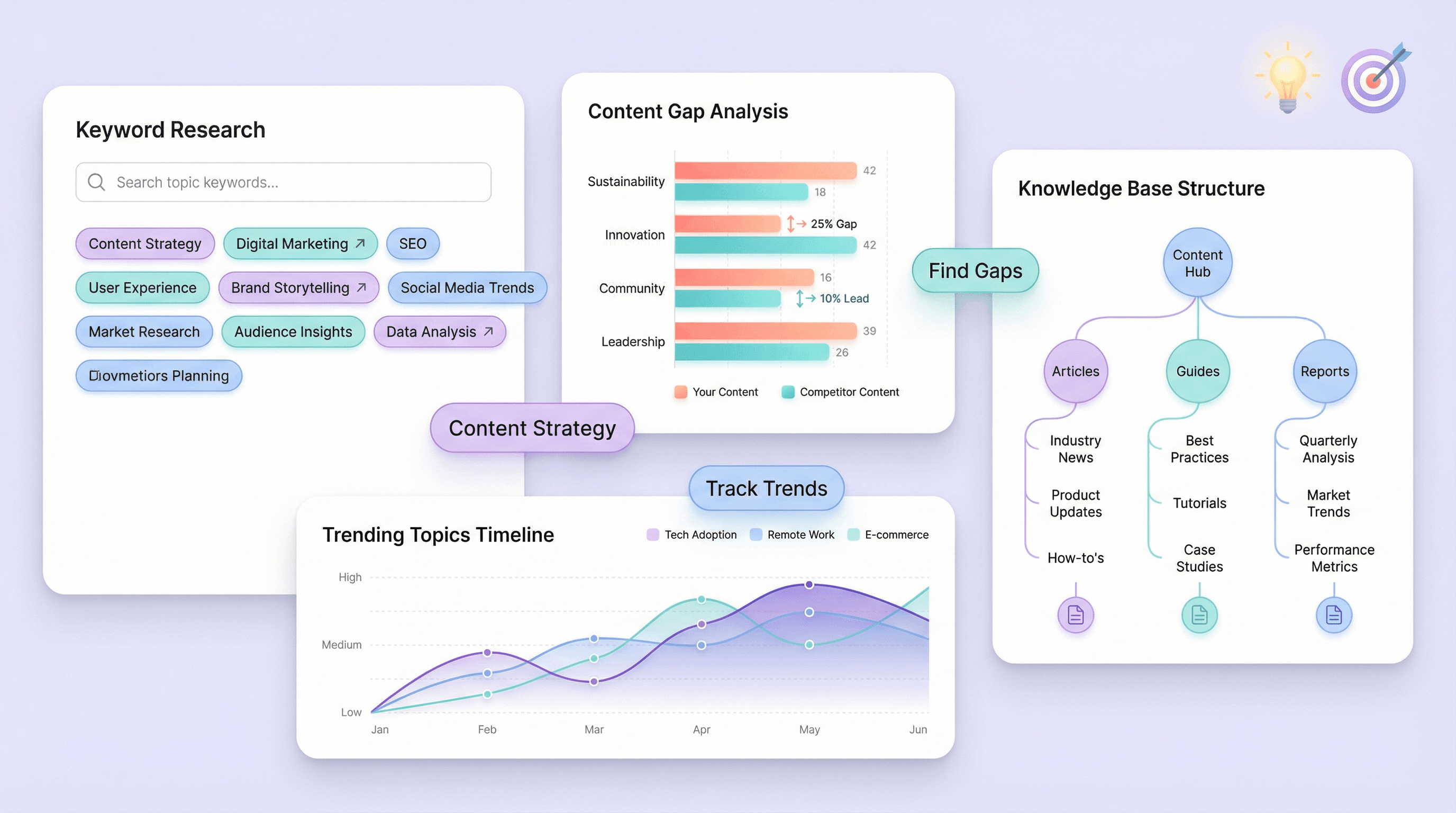
Support Content Strategy and SEO Research
और मुफ्त टूल्स देखें
साइटमैप एक्सट्रैक्टर
एक XML साइटमैप URL को पार्स करके हर पेज लिंक को एक साफ़ टेबल में सूचीबद्ध करें। SEO और QA के लिए साइट संरचना का तेज़ी से ऑडिट करें और गुम या अपेक्षित से अलग URLs ढूँढें।
वेबसाइट से इमेज एक्सट्रैक्टर
किसी भी वेबपेज से सभी इमेज तुरंत निकालें और उन्हें पल भर में डाउनलोड करें। पूरी तरह मुफ़्त, तेज़, और एक्सपोर्ट करना बेहद आसान।
टेक्स्ट से फ़ोन नंबर एक्सट्रैक्टर
टेक्स्ट में वैध फ़ोन नंबरों को स्कैन करके एक साफ़, सुव्यवस्थित सूची देता है। मैन्युअल जाँच में समय बचाएँ और ज़रूरी नंबर आसानी से कॉपी करें।
सूची क्रॉलर
किसी भी वेबपेज URL से क्रमबद्ध और अक्रमबद्ध सूची आइटम निकालें। समूहित सूचियों को सादे टेक्स्ट में देखें और मुख्य बिंदुओं को तेज़ी से पकड़ें।
Google Scholar स्क्रैपर
Google Scholar पेज से शैक्षणिक परिणाम निकालें और तेज़ रिसर्च के लिए पेपर शीर्षक, उद्धरण, लेखक, और प्रकाशन विवरण CSV में निर्यात करें।
वेबसाइट से ईमेल मुफ़्त में निकालें
किसी वेबपेज पर मौजूद वैध ईमेल पतों को स्कैन करें और आउटरीच या संपर्क शोध के लिए एक साफ़ सूची पाएँ।
G2 Software Product Scraper
Extract structured insights from any G2 software page, including ratings, reviews, and product details, to streamline competitor analysis and market research.
यूआरएल एक्सट्रैक्टर और बैच डाउनलोडर
किसी भी पेज से सभी वेबसाइट लिंक निकालें और उन्हें CSV के रूप में डाउनलोड करें। रिसर्च, विश्लेषण या डेटा संग्रह कार्यों के लिए यूआरएल जल्दी इकट्ठा करें।
Text Extractor
Extracts text from images and lets you download the results. Quickly convert scanned documents or pictures into editable text for easy use.
ऑनलाइन टेक्स्ट से ईमेल निकालें
कोई भी टेक्स्ट पेस्ट करें और मान्य ईमेल पतों को एक साफ़ सूची में निकालें। नोट्स, संदेशों और दस्तावेज़ों को साफ़ करने में समय बचाएँ।
एआई ईमेल विषय पंक्ति जनरेटर
एक छोटी-सी जानकारी के आधार पर आकर्षक ईमेल विषय पंक्तियाँ बनाएं। AI-संचालित सुझावों से ओपन रेट बढ़ाएँ। तेज़, आसान और बिना साइन-अप के।
Amazon प्रोडक्ट्स स्क्रैपर
Amazon उत्पादों के URL पेस्ट करके उनसे प्रोडक्ट जानकारी निकालें। शीर्षक, कीमत, रेटिंग और अन्य विवरणों को एक व्यवस्थित टेबल में पाएं, ताकि आप उन्हें जल्दी से एक्सपोर्ट और रिव्यू कर सकें।
AI Sales Email Generator
Create personalized sales emails in seconds with the free AI Sales Email Generator. Perfect for sales teams and entrepreneurs. Try it now and boost your outreach with Thunderbit’s suite of AI tools.
फ़ोन नंबर एक्सट्रैक्टर
वेबपेजों, फ़ाइलों या टेक्स्ट को तेज़ी से स्कैन करके फ़ोन नंबर खोजें। कुछ ही सेकंड में साफ़, निर्यात योग्य सूची पाएँ—कॉन्टैक्ट लिस्ट बनाने या डेटा सत्यापित करने के लिए आदर्श।
छवि से एक्सेल कनवर्टर
तालिकाओं, रसीदों या सूचियों वाली छवियों को संरचित JSON ऐरे में बदलें ताकि उन्हें आसानी से Excel में निर्यात किया जा सके। मैन्युअल डेटा एंट्री में समय बचाएँ और सटीकता सुनिश्चित करें।
ईमेल एक्सट्रैक्टर और वेरिफ़ायर
वेबपेज, पीडीएफ़, या टेक्स्ट से Email Extractor के साथ ईमेल पते खोजें और निकालें। तेज़, सटीक, और कभी भी एक्सपोर्ट करने के लिए तैयार।