Zara स्क्रैपर

प्रमुख कंपनियों के पेशेवरों का भरोसा














Thunderbit के साथ Zara डेटा अनलॉक करें
तुरंत साफ़ Zara डेटा पाएँ
सटीक डेटा, जैसे प्रोडक्ट नाम, कीमतें और रंग, के लिए Zara के प्रोडक्ट पेजों में छानबीन करना काफ़ी झंझट भरा हो सकता है। Thunderbit आपके स्क्रैप किए गए डेटा को निकालते ही अपने आप साफ़ और संरचित कर देता है। अब हाथ से फ़ॉर्मैटिंग की ज़रूरत नहीं — Google Sheets, Notion या Airtable में जो एक्सपोर्ट करें, वह तुरंत विश्लेषण के लिए तैयार रहता है.
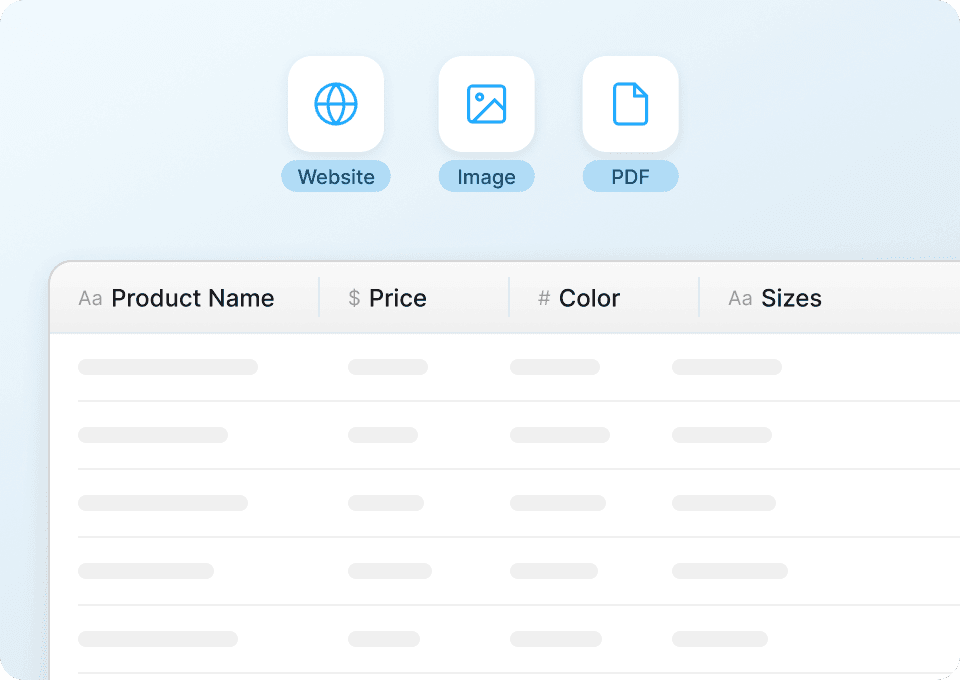
Zara से बल्क डेटा एक्सट्रैक्शन
Zara प्रोडक्ट डिटेल्स को एक-एक करके मैन्युअली स्क्रैप करना बहुत समय लेता है। Thunderbit एक साथ सैकड़ों Zara प्रोडक्ट पेज स्क्रैप कर सकता है। बस उसे URLs की एक सूची दें, और वह प्रोडक्ट नाम, कीमतें, मूल कीमतें, छूट प्रतिशत, प्रोडक्ट IDs, रंग और बहुत कुछ एक ही बार में निकाल देगा।

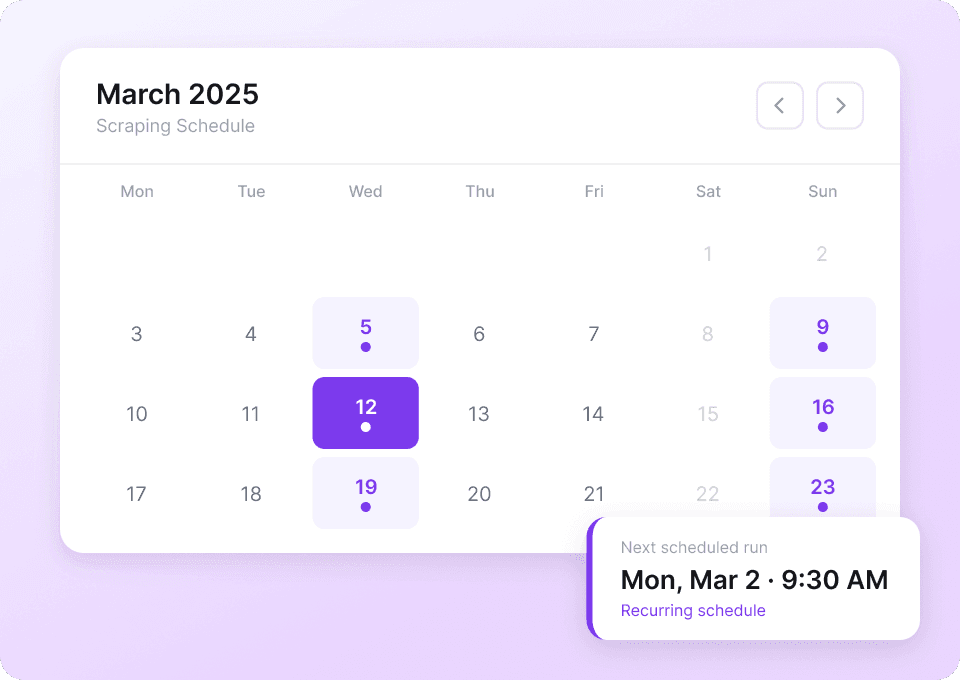
Zara डेटा की ऑटोमेटेड मॉनिटरिंग
Zara की कीमतें और प्रोडक्ट उपलब्धता लगातार बदलती रहती हैं, इसलिए मैन्युअल ट्रैकिंग लगभग असंभव है। Thunderbit को शेड्यूल पर Zara स्क्रैप करने के लिए सेट करें, और यह अपने आप Google Sheets, Notion या Airtable को नवीनतम डेटा से अपडेट करता रहेगा। उंगली उठाए बिना प्राइस ड्रॉप या नए प्रोडक्ट रिलीज़ की सूचना पाएँ।
Zara को प्रभावी ढंग से स्क्रैप करने में दिक्कत हो रही है?
देखें कि Thunderbit पारंपरिक स्क्रैपिंग का सबसे आसान विकल्प क्यों है।
पारंपरिक स्क्रैपर
काम करने का पुराना तरीकाThunderbit
ज़्यादा स्मार्ट तरीकासिर्फ हमारी बात पर भरोसा मत करें
देखें Thunderbit के बारे में हमारे उपयोगकर्ता क्या कहते हैं।






अक्सर पूछे जाने वाले प्रश्न
संबंधित उपयोग के मामले
Thunderbit के वेब स्क्रैपर के और उपयोग के मामले देखें।
सबस्टैक स्क्रैपर
सबस्टैक के सब्सक्राइबर काउंट, लेख शीर्षक और प्रकाशन विवरण एक साफ़ स्प्रेडशीट में लाएँ — कोड की ज़रूरत नहीं, AI खुद संरचना बना देता है।
और जानें ->
Steam Scraper
बस कुछ ही क्लिक में Steam से ऐप के नाम, कीमतें और यूज़र रिव्यू प्रतिशत निकालें—कोडिंग की ज़रूरत नहीं।
और जानें ->
Priceline स्क्रेपर
Thunderbit की AI की मदद से बस कुछ क्लिक में Priceline से होटल के नाम, कीमतें और रेटिंग निकालें।
और जानें ->PeopleWhiz स्क्रैपर
Thunderbit PeopleWhiz स्क्रैपर आपको AI-संचालित फ़ील्ड सुझावों के साथ PeopleWhiz खोज परिणामों और प्रोफाइलों से डेटा निकालने देता है। शोध, मार्केटिंग या लीड जनरेशन के लिए नाम, संपर्क विवरण, स्थान और भी बहुत कुछ इकट्ठा करें। PeopleWhiz डेटा को संरचित डेटासेट में जल्दी और कुशलता से बदलें।
और जानें ->वीडियो स्क्रैपर
Thunderbit का Video Scraper आपको AI की मदद से सिर्फ कुछ क्लिक में वीडियो और क्रिएटर डेटा निकालने देता है। वीडियो लिस्टिंग, परफॉर्मेंस मेट्रिक्स और प्रोफ़ाइल डिटेल्स स्क्रैप करें, फिर ट्रैकिंग और इन्फ्लुएंसर रिसर्च के लिए डेटा को Excel, Google Sheets, Airtable या Notion में एक्सपोर्ट करें।
और जानें ->
United Airlines Scraper
United Airlines की फ्लाइट जानकारी जैसे फ्लाइट नंबर, आगमन समय और प्रस्थान हवाई अड्डा — बस पॉइंट और क्लिक करें, बाकी काम Thunderbit AI अपने आप संभाल लेता है।
और जानें ->क्या आप अपने डेटा एक्सट्रैक्शन को तेज़ करने के लिए तैयार हैं?
100,000+ पेशेवरों से जुड़ें जो पहले से ही Thunderbit का उपयोग अपने वेब स्क्रैपिंग वर्कफ़्लो को ऑटोमेट करने के लिए कर रहे हैं।
मुफ्त ट्रायल 8 वेबपेजों के लिए असीमित क्रेडिट देता है।