शियाओहोंगशु स्क्रैपर

प्रमुख कंपनियों के पेशेवरों का भरोसा














दो क्लिक में शियाओहोंगशु डेटा अनलॉक करें
दो क्लिक में आसान डेटा निष्कर्षण
शियाओहोंगशु डेटा निकालने के लिए जटिल कोड और अंतहीन सेटअप से परेशान हैं? Thunderbit आपको note_id, author_id, author_nickname, note_title, note_content, और like_count जैसे महत्वपूर्ण डेटा फ़ील्ड एक भी कोड लाइन लिखे बिना निकालने देता है। बस ज़रूरी डेटा पर पॉइंट करें, और Thunderbit अपने आप फ़ील्ड पहचानकर एक क्लिक में निकाल देता है।
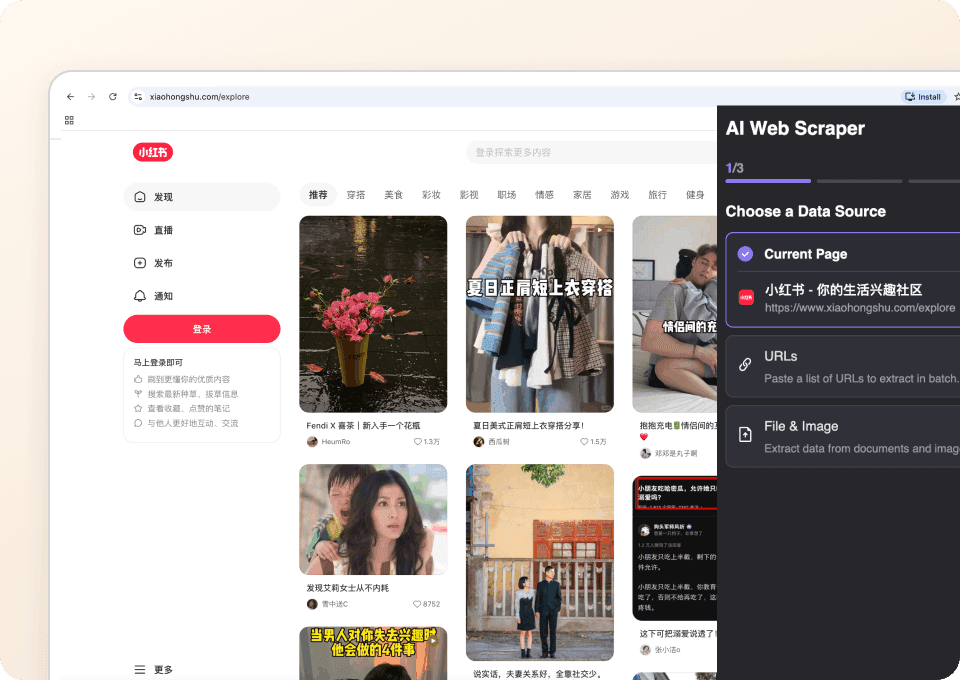
पूरी कहानी, अपने आप हासिल करें
शियाओहोंगशु लिस्टिंग पेज आपको सिर्फ़ एक झलक देते हैं। Thunderbit के साथ आप हर नोट के सबपेज पर अपने आप जा सकते हैं और सीधे विस्तृत जानकारी निकाल सकते हैं। हर प्रासंगिक विवरण को स्क्रैप करके छिपी हुई जानकारियाँ सामने लाएँ और पूरी तस्वीर पाएँ, जिसे आपके चुने हुए गंतव्य में नए कॉलम के रूप में जोड़ा जाता है।
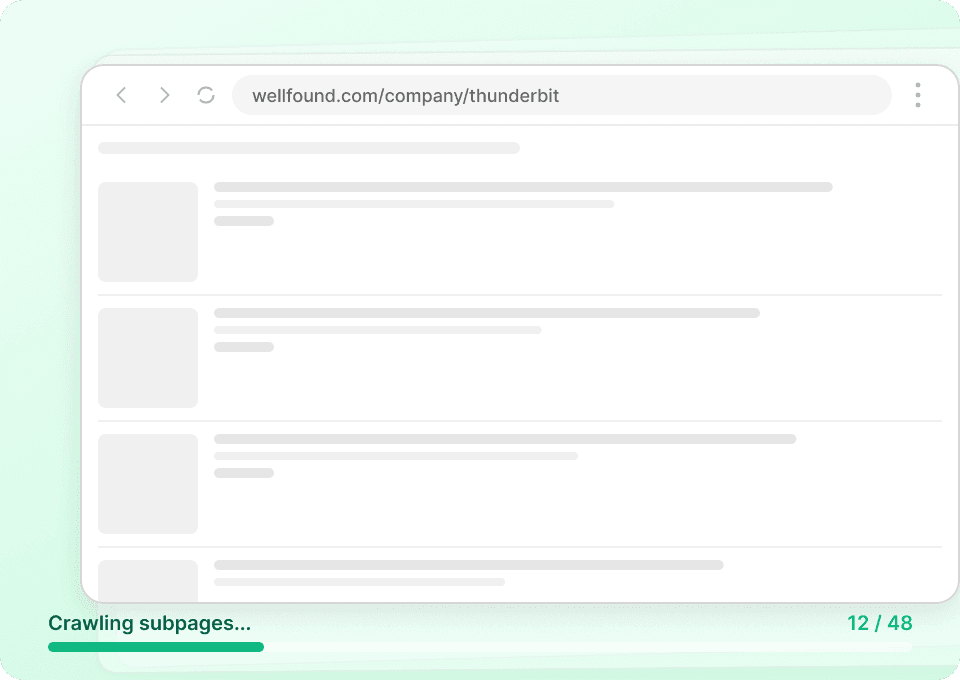
अपने शियाओहोंगशु डेटा मॉनिटरिंग को ऑटोमेट करें
शियाओहोंगशु डेटा लगातार बदलता रहता है। हर दिन मैन्युअल रूप से स्क्रैप करना एक झंझट है। Thunderbit की शेड्यूल्ड स्क्रैपिंग आपको like_count जैसे डेटा को ऑटोपायलट पर अपने आप निकालने के लिए आवर्ती टास्क सेट करने देती है। बिना उंगली उठाए ताज़ा जानकारियाँ सीधे Google Sheets, Notion, या Airtable में पाएँ।
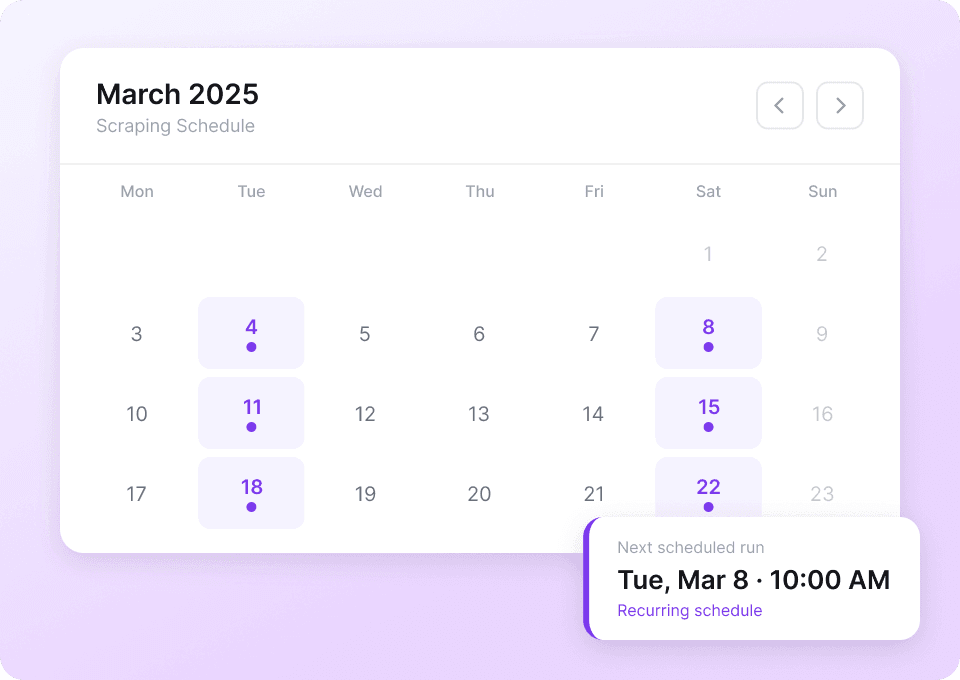
शियाओहोंगशु को प्रभावी ढंग से स्क्रैप करने में परेशानी हो रही है?
देखें कि शियाओहोंगशु डेटा निकालने का Thunderbit क्यों ज़्यादा स्मार्ट तरीका है।
Traditional Scrapers
The old way of doing thingsThunderbit AI
The smarter approachसिर्फ हमारी बात पर भरोसा मत करें
देखें Thunderbit के बारे में हमारे उपयोगकर्ता क्या कहते हैं।






अक्सर पूछे जाने वाले प्रश्न
संबंधित उपयोग के मामले
Thunderbit के वेब स्क्रैपर के और उपयोग के मामले देखें।

United Airlines Scraper
United Airlines की फ्लाइट जानकारी जैसे फ्लाइट नंबर, आगमन समय और प्रस्थान हवाई अड्डा — बस पॉइंट और क्लिक करें, बाकी काम Thunderbit AI अपने आप संभाल लेता है।
और जानें ->
Carousell स्क्रैपर
बिना किसी जटिल सेटअप या कोड के, Carousell से आइटम टाइटल, डिस्क्रिप्शन और कीमत जैसी जानकारी आसानी से निकालें।
और जानें ->
HKTVmall Scraper
बस कुछ ही क्लिक में HKTVmall लिस्टिंग से प्रोडक्ट के नाम, कीमतें और ग्राहक रेटिंग तक निकालें — किसी जटिल सेटअप की ज़रूरत नहीं।
और जानें ->
PubMed Scraper
Thunderbit का PubMed Scraper आपको AI की मदद से PubMed के सर्च रिज़ल्ट्स और आर्टिकल पेजों से व्यवस्थित (structured) डेटा निकालने में मदद करता है। ट्रेंडिंग मेडिकल रिसर्च, क्लिनिकल ट्रायल से जुड़े प्रमाण, एब्स्ट्रैक्ट, लेखक, संस्थागत संबद्धताएँ, प्रकाशन तिथियाँ और लिंक स्क्रैप करें—और फिर डेटा को Excel, Google Sheets, Airtable या Notion में एक्सपोर्ट करें।
और जानें ->Elgiganten Scraper
Thunderbit के AI की मदद से सिर्फ दो क्लिक में Elgiganten से प्रोडक्ट नाम, कीमतें और उपलब्धता का डेटा निकालें — बाकी भारी काम AI कर देगा।
और जानें ->
Spokeo Scraper
Spokeo डेटा को मैन्युअल रूप से कॉपी करना बंद करें — Thunderbit का इस्तेमाल करके सिर्फ़ कुछ क्लिक में नाम, उम्र, पते और बहुत कुछ निकालें।
और जानें ->क्या आप अपने डेटा एक्सट्रैक्शन को तेज़ करने के लिए तैयार हैं?
100,000+ पेशेवरों से जुड़ें जो पहले से ही Thunderbit का उपयोग अपने वेब स्क्रैपिंग वर्कफ़्लो को ऑटोमेट करने के लिए कर रहे हैं।
मुफ्त ट्रायल 8 वेबपेजों के लिए असीमित क्रेडिट देता है।