

Thunderbit का PubMed Scraper AI की मदद से PubMed पेजों को साफ़, व्यवस्थित डेटासेट में बदल देता है। आप ट्रेंडिंग मेडिकल रिसर्च, क्लिनिकल ट्रायल से जुड़े प्रमाण, एब्स्ट्रैक्ट, लेखक, संबद्धताएँ, प्रकाशन तिथियाँ, PMID और आर्टिकल लिंक निकाल सकते हैं—और फिर Excel, Google Sheets, Airtable या Notion में एक्सपोर्ट कर सकते हैं। बस Chrome में PubMed खोलें, AI से बेहतरीन कॉलम सुझवाएँ, और स्क्रैप कर लें।
🧬 PubMed Scraper क्या है
PubMed Scraper एक AI Web Scraper है, जो के लिए बनाया गया है। (AI web scraper Chrome extension) के साथ आप किसी भी PubMed रिज़ल्ट पेज पर जाएँ, AI Suggest Columns पर क्लिक करें, फिर Scrape दबाकर बिना कोड लिखे structured डेटा निकाल लें।
🔎 PubMed से आप क्या-क्या स्क्रैप कर सकते हैं
PubMed में बायोमेडिकल मेटाडेटा बहुत समृद्ध होता है, लेकिन वह हमेशा सीधे विश्लेषण के लिए तैयार नहीं होता। Thunderbit का AI Web Scraper (https://thunderbit.com/) आपको PubMed लिस्टिंग्स को इकट्ठा करके व्यवस्थित करने में मदद करता है—और Subpage Scraping के जरिए हर आर्टिकल पेज खोलकर एब्स्ट्रैक्ट, संबद्धताएँ, DOI आदि जैसे अतिरिक्त फ़ील्ड भी जोड़ सकता है।
नीचे दो आम वर्कफ़्लो दिए गए हैं, जिन्हें आप कुछ ही मिनटों में चला सकते हैं।
📈 PubMed ट्रेंडिंग मेडिकल रिसर्च मॉनिटरिंग स्क्रैप करें
इस वर्कफ़्लो से आप PubMed के ट्रेंडिंग पेज पर मेडिकल रिसर्च में क्या चल रहा है, उसे मॉनिटर कर सकते हैं। यह अपडेटेड रहने, इंटरनल डाइजेस्ट बनाने, प्रतिस्पर्धियों के प्रकाशन ट्रैक करने, या लिटरेचर मॉनिटरिंग पाइपलाइन को फीड करने में उपयोगी है।
Destination page example:
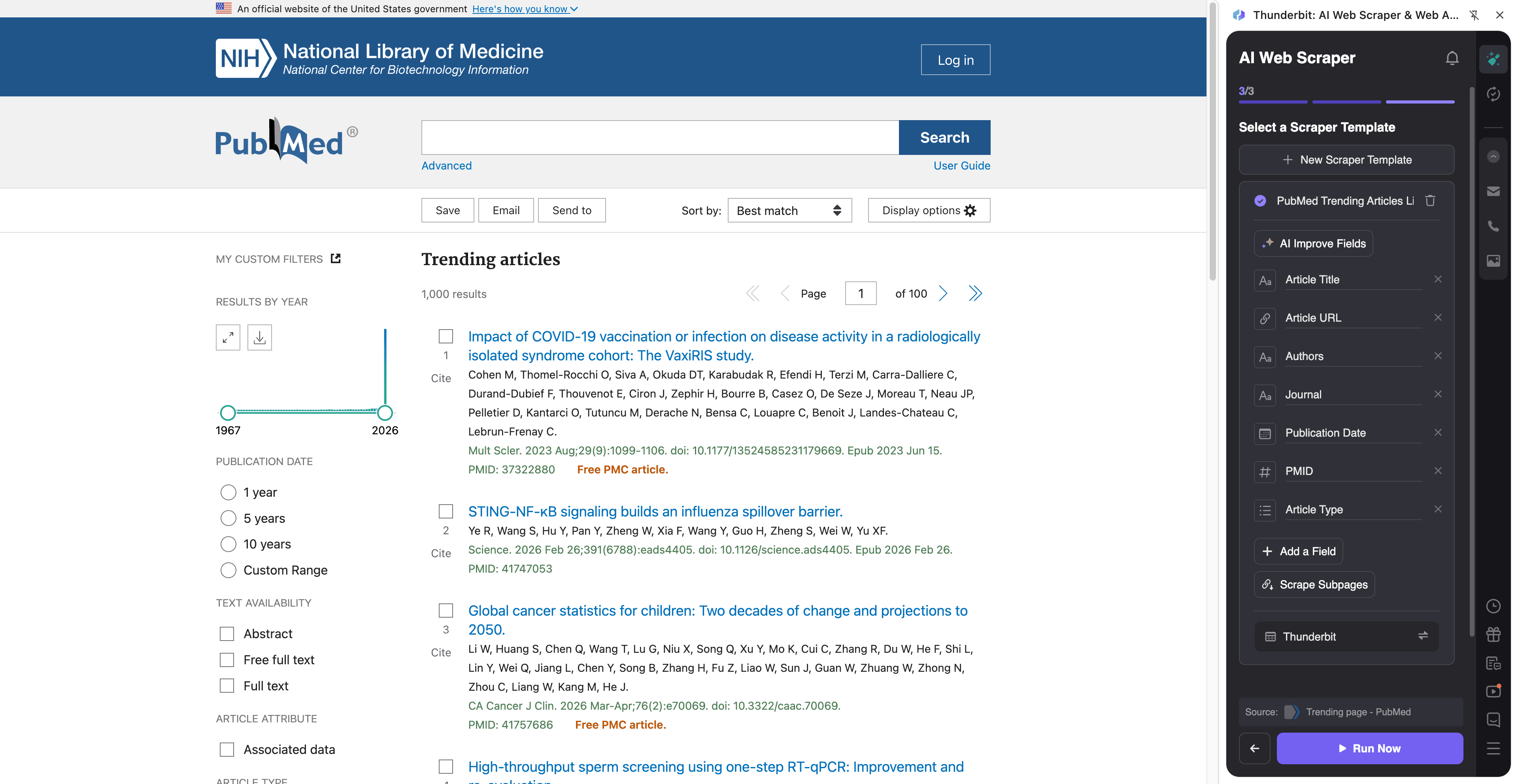
Steps:
- डाउनलोड करें और अकाउंट रजिस्टर करें।
- डेस्टिनेशन पेज पर जाएँ, जैसे: .
- AI Suggest Columns पर क्लिक करें ताकि AI सबसे अच्छे कॉलम नाम और डेटा टाइप सुझा सके।
- Scrape पर क्लिक करके डेटा निकालें, फिर Excel, Google Sheets, Airtable या Notion में एक्सपोर्ट करें।
Column names
| Column | Description |
|---|---|
| 🧾 Article Title | ट्रेंडिंग PubMed आर्टिकल का शीर्षक। |
| 🔗 Article URL | PubMed रिकॉर्ड पेज का डायरेक्ट लिंक। |
| 🆔 PMID | रिकॉर्ड का PubMed आइडेंटिफ़ायर (स्थिर key के रूप में उपयोगी)। |
| 🏛️ Journal | जिस जर्नल में आर्टिकल प्रकाशित हुआ है उसका नाम। |
| 📅 Publication Date | लिस्टिंग में दिखाई गई प्रकाशन तिथि। |
| ✍️ Authors | रिज़ल्ट कार्ड पर दिखने वाली लेखक सूची (string)। |
| 🧪 Article Type | उपलब्ध होने पर प्रकाशन प्रकार (जैसे Review, Clinical Trial)। |
| 🏷️ Keywords / Topics | लिस्टिंग पर दिखने वाले टॉपिक टैग/कीवर्ड (यदि मौजूद हों)। |
| 📝 Snippet / Summary | लिस्टिंग में दिखने वाला छोटा स्निपेट/सार (यदि मौजूद हो)। |
| 🧷 DOI | उपलब्ध होने पर DOI (अक्सर subpage scraping से बेहतर मिलता है)। |
| 🧑🔬 Affiliations | लेखक की संबद्धताएँ (आमतौर पर subpage scraping से निकाली जाती हैं)। |
| 📄 Abstract | एब्स्ट्रैक्ट टेक्स्ट (आमतौर पर subpage scraping से निकाला जाता है)। |
🧫 PubMed क्लिनिकल ट्रायल एविडेंस एक्सट्रैक्शन स्क्रैप करें
इस वर्कफ़्लो से आप PubMed सर्च रिज़ल्ट्स से क्लिनिकल ट्रायल से जुड़ा प्रमाण/एविडेंस निकाल सकते हैं, और फिर हर रो को आर्टिकल पेज पर जाकर एब्स्ट्रैक्ट, ट्रायल संकेत (signals) और रिव्यू के लिए ज़रूरी मेटाडेटा से समृद्ध कर सकते हैं।
Destination page example:
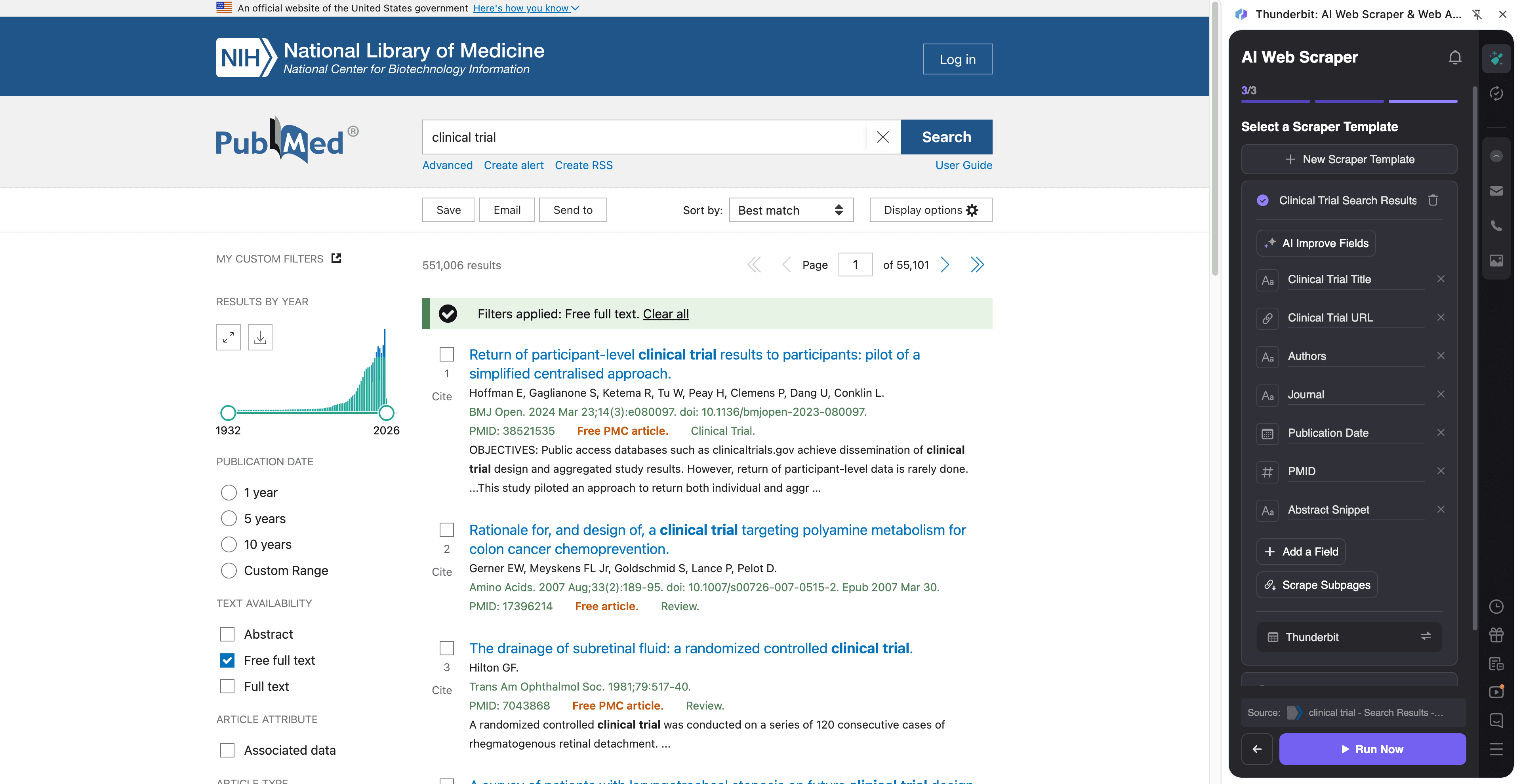
Steps:
- डाउनलोड करें और अकाउंट रजिस्टर करें।
- डेस्टिनेशन पेज पर जाएँ, जैसे: .
- AI Suggest Columns पर क्लिक करके सुझाए गए फ़ील्ड बनवाएँ (आप चाहें तो नाम बदल सकते हैं या अपने फ़ील्ड जोड़ सकते हैं)।
- Scrape पर क्लिक करके रिज़ल्ट्स इकट्ठा करें, फिर Scrape Subpages से हर रो में एब्स्ट्रैक्ट, संबद्धताएँ, DOI आदि जोड़ें।
Column names
| Column | Description |
|---|---|
| 🧾 Title | सर्च रिज़ल्ट्स में दिखने वाला आर्टिकल शीर्षक। |
| 🔗 PubMed URL | subpage enrichment के लिए PubMed आर्टिकल पेज का लिंक। |
| 🆔 PMID | डीडुप्लिकेशन और रेफरेंसिंग के लिए PubMed आइडेंटिफ़ायर। |
| 🧑⚕️ Authors | रिज़ल्ट स्निपेट में सूचीबद्ध लेखक। |
| 🏛️ Journal | रिज़ल्ट्स में दिखने वाला जर्नल नाम और citation जानकारी। |
| 📅 Date | लिस्टिंग में दिखने वाली प्रकाशन तिथि (या ePub date)। |
| 🧪 Publication Type | संकेत जैसे Clinical Trial, Randomized Controlled Trial, Meta-Analysis (अक्सर आर्टिकल पेज पर अधिक स्पष्ट)। |
| 🧾 Abstract | पूरा एब्स्ट्रैक्ट टेक्स्ट (subpage scraping से सबसे अच्छा)। |
| 🧬 MeSH Terms | उपलब्ध होने पर Medical Subject Headings (अक्सर आर्टिकल पेज पर)। |
| 🧷 DOI | पब्लिशर पेज और रेफरेंस मैनेजर से लिंक करने के लिए DOI। |
| 🏥 Affiliations | संस्थान विश्लेषण के लिए लेखक संबद्धताएँ (subpage scraping)। |
| 🌍 Country / Institution | Field AI Prompts से संबद्धताओं से पार्स किया गया (वैकल्पिक)। |
| 🔍 Clinical Trial Keywords | AI-लेबल्ड संकेत जैसे “randomized”, “double-blind”, “placebo” (Field AI Prompt से वैकल्पिक)। |
| 📎 Full Text Links | उपलब्ध होने पर पब्लिशर या फ्री फुल-टेक्स्ट के आउटबाउंड लिंक। |
🎯 PubMed टूल क्यों इस्तेमाल करें
PubMed स्क्रैप करने का मतलब है तेज़ी, एकरूपता, और रिसर्च डेटा को आपके वर्कफ़्लो में उपयोगी बनाना। एक-एक citation कॉपी करने के बजाय, आप एक structured डेटासेट बना सकते हैं जिसे फ़िल्टर, टैग और शेयर करना आसान हो।
टीमें PubMed स्क्रैप क्यों करती हैं:
- Medical affairs & pharma teams: किसी therapeutic area में नए प्रकाशन ट्रैक करना, competitor trials मॉनिटर करना, और इंटरनल रिव्यू के लिए evidence tables बनाना।
- Biotech & clinical operations: ट्रायल-संबंधित प्रकाशन इकट्ठा करना, संस्थानों/इन्वेस्टिगेटर्स को मैप करना, और एक living bibliography बनाए रखना।
- Healthcare marketing & content teams: ट्रेंडिंग टॉपिक्स, हाई-इम्पैक्ट जर्नल्स, और उभरते कीवर्ड पहचानकर कंटेंट प्लानिंग करना।
- Academic researchers & librarians: लिटरेचर रिव्यू डेटासेट बनाना, PMID से डीडुप्लिकेट करना, और स्क्रीनिंग के लिए स्प्रेडशीट में एक्सपोर्ट करना।
- Data teams: आगे की analytics, dashboards, या internal knowledge bases के लिए structured इनपुट तैयार करना।
Thunderbit खास तौर पर तब मददगार है जब आपको सिर्फ लिस्टिंग पेज से आगे जाना हो। Subpage Scraping के साथ आप बड़े पैमाने पर एब्स्ट्रैक्ट, संबद्धताएँ, DOI, MeSH terms और full-text links निकाल सकते हैं।
🧩 PubMed Chrome Extension कैसे इस्तेमाल करें
- Thunderbit Chrome Extension इंस्टॉल करें: इसे से लें और अपना अकाउंट बनाएं।
- किसी PubMed पेज पर जाएँ: , जैसा ट्रेंडिंग पेज, या जैसी क्वेरी खोलें।
- AI-पावर्ड स्क्रैपर एक्टिवेट करें: AI Suggest Columns पर क्लिक करके फ़ील्ड जनरेट करें, डेटा टाइप (text/date/url) एडजस्ट करें, और वैकल्पिक Field AI Prompts जोड़ें (labeling, formatting, या trial signals निकालने के लिए)।
- Scrape और export करें: Scrape पर क्लिक करें। अगर आपको abstracts/affiliations/MeSH चाहिए, तो Scrape Subpages चलाकर हर रो को enrich करें, फिर Excel, Google Sheets, Airtable या Notion में एक्सपोर्ट करें।
अगर आप repeatable workflow बना रहे हैं, तो ये पढ़ना उपयोगी रहेगा:
💳 PubMed के लिए Pricing
Thunderbit एक सरल क्रेडिट सिस्टम इस्तेमाल करता है:
- 1 credit = results table में 1 output row (उदाहरण: एक PubMed रिकॉर्ड)।
- डेटा एक्सपोर्ट मुफ़्त है: CSV/JSON डाउनलोड करें या Excel, Google Sheets, Airtable, या Notion में भेजें।
आप शुरुआत कर सकते हैं:
- Free tier: प्रति माह 6 पेज स्क्रैप करें (Free में पेज-आधारित allowance)।
- Free trial: 10 पेज मुफ़्त स्क्रैप करें—PubMed ट्रेंडिंग पेज और कुछ क्लिनिकल ट्रायल रिज़ल्ट पेज टेस्ट करने के लिए बढ़िया।
अगर आप नियमित रूप से स्क्रैप करते हैं (साप्ताहिक मॉनिटरिंग, evidence updates, या बड़े queries), तो paid plans में अधिक credits मिलते हैं। Yearly plan आमतौर पर अधिक किफायती होता है क्योंकि month-to-month भुगतान की तुलना में इसमें डिस्काउंट शामिल होता है।
विकल्प देखने के लिए: .
❓ FAQ
-
AI Powered PubMed Scraper क्या है?
AI Powered PubMed Scraper, Thunderbit के अंदर एक वर्कफ़्लो है जो PubMed सर्च रिज़ल्ट्स और आर्टिकल पेजों से structured डेटा निकालता है। आप AI से कॉलम सुझवा सकते हैं, लिस्टिंग्स स्क्रैप कर सकते हैं, और आर्टिकल subpages पर जाकर abstracts, affiliations, DOI आदि जोड़कर हर रो को enrich कर सकते हैं। -
Thunderbit क्या है?
एक AI web scraper Chrome extension है, जिसे बिज़नेस और रिसर्च वर्कफ़्लो के लिए बनाया गया है जहाँ वेबसाइटों से structured डेटा चाहिए होता है। यह आपको स्क्रिप्ट बनाए/मेंटेन किए बिना तेज़ी से डेटा निकालने, लेबल करने और एक्सपोर्ट करने में मदद करता है। -
क्या PubMed के trending pages और सामान्य search results दोनों स्क्रैप किए जा सकते हैं?
हाँ। आप पेज, सामान्य keyword searches, और filtered result pages (जैसे clinical trial-focused queries) स्क्रैप कर सकते हैं। Thunderbit का AI अलग-अलग लेआउट को पढ़कर उपयुक्त फ़ील्ड प्रस्तावित कर देता है। -
क्या Thunderbit abstracts, affiliations और MeSH terms निकाल सकता है?
हाँ—और यही वह जगह है जहाँ Subpage Scraping सबसे ज़्यादा काम आता है। पहले आप results list स्क्रैप करते हैं, फिर Thunderbit हर PubMed रिकॉर्ड पेज खोलकर abstract text, affiliations, MeSH terms, DOI और अन्य मेटाडेटा उसी टेबल में जोड़ देता है। -
PubMed पर pagination और infinite scroll कैसे काम करते हैं?
Thunderbit pagination scraping सपोर्ट करता है, जिसमें “next page” जैसी नेविगेशन भी शामिल है। अगर PubMed रिज़ल्ट लोड करने का तरीका बदल दे, तो AI-आधारित extraction आम तौर पर rigid selectors की तुलना में अधिक resilient रहता है, क्योंकि यह हर रन में पेज स्ट्रक्चर को दोबारा पढ़ता है। -
PubMed डेटा किन फ़ॉर्मैट्स में एक्सपोर्ट कर सकते हैं?
आप CSV या JSON में एक्सपोर्ट कर सकते हैं, या डेटासेट को Excel, Google Sheets, Airtable, या Notion में भेज सकते हैं। यह screening workflows, evidence tables, dashboards, और collaborators के साथ शेयरिंग के लिए उपयोगी है। -
मैं मुफ़्त में कितने PubMed रिकॉर्ड स्क्रैप कर सकता/सकती हूँ?
Free tier में आप प्रति माह 6 पेज स्क्रैप कर सकते हैं, जो छोटे मॉनिटरिंग टास्क के लिए अक्सर पर्याप्त होता है। Free trial में आप 10 पेज मुफ़्त स्क्रैप करके अपने कॉलम सेटअप और subpage enrichment रणनीति को validate कर सकते हैं। -
क्या मैं evidence extraction की जरूरत के हिसाब से कॉलम कस्टमाइज़ कर सकता/सकती हूँ?
हाँ। आप कॉलम के नाम बदल सकते हैं, डेटा टाइप (text/date/url) सेट कर सकते हैं, और Field AI Prompts जोड़कर trial design keywords, population, intervention, comparator, outcomes, या affiliations से country जैसी जानकारी निकाल/लेबल कर सकते हैं। इससे आप raw scraping से आगे बढ़कर structured evidence prep कर पाते हैं। -
क्या PubMed स्क्रैप करना ठीक है?
PubMed एक सार्वजनिक संसाधन है, और कई टीमें रिसर्च व विश्लेषण के लिए bibliographic metadata इकट्ठा करती हैं। फिर भी, लागू कानूनों का पालन करें, साइट की शर्तों का सम्मान करें, और जिम्मेदार scraping practices अपनाएँ—खासकर जब आप बड़े और बार-बार चलने वाले जॉब्स रन कर रहे हों।
📚 Learn More
- एक्सटेंशन लें:
- गाइड्स देखें:
- बेसिक्स सीखें:
- लिस्ट वर्कफ़्लो बनाएं:
- स्प्रेडशीट में एक्सपोर्ट:
- अगर आप research ops में PDFs भी स्क्रैप करते हैं: