TechCrunch स्क्रैपर

प्रमुख कंपनियों के पेशेवरों का भरोसा














सिर्फ़ दो क्लिक में TechCrunch डेटा अनलॉक करें
दो क्लिक में सरल TechCrunch स्क्रैपिंग
TechCrunch से लेख शीर्षक, लेखक, प्रकाशन तिथि, या यहाँ तक कि पूरा लेख सामग्री भी मैन्युअल रूप से कॉपी करना उबाऊ है। Thunderbit आपको यह झंझट छोड़ने देता है। बस ज़रूरी डेटा की ओर पॉइंट करें, और हमारी AI बाकी काम समझ लेती है। दो क्लिक में, आप बिना एक भी कोड लाइन लिखे या जटिल सेटअप से उलझे डेटा निकाल रहे होते हैं।
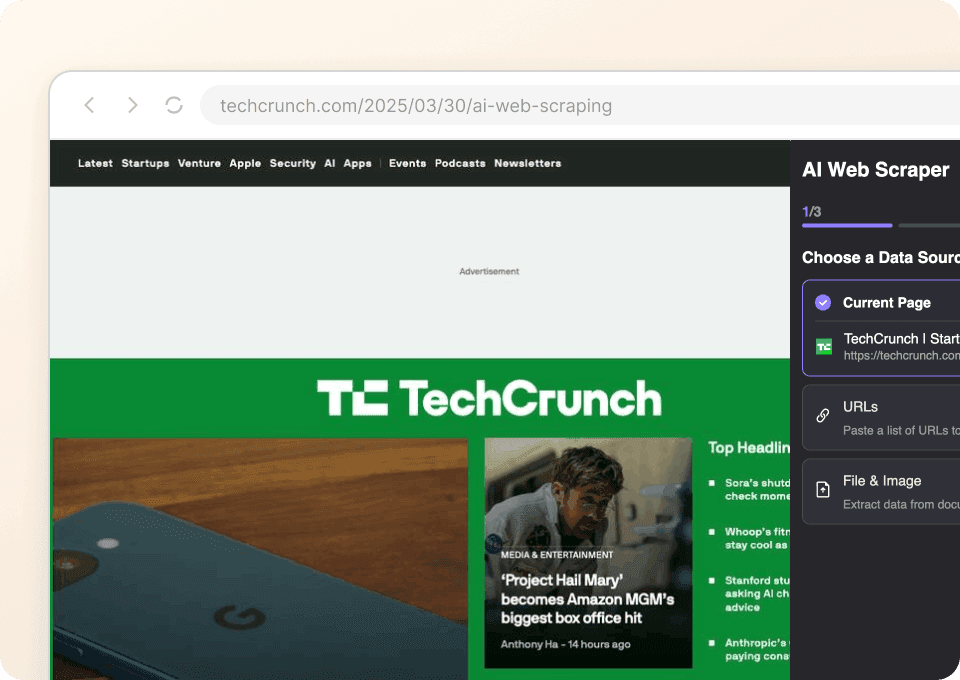
तुरंत साफ़ TechCrunch डेटा पाएँ
TechCrunch से रॉ HTML स्क्रैप करने से कुछ हासिल नहीं होता – आपको साफ़, संरचित डेटा चाहिए। Thunderbit डेटा को निकालते समय ही अपने-आप साफ़ और फ़ॉर्मैट कर देता है, ताकि आप तुरंत लेख श्रेणियों का विश्लेषण कर सकें, लेखकों को ट्रैक कर सकें, या प्रकाशन तिथियों की तुलना कर सकें। सीधे Google Sheets, Notion, या Airtable में एक्सपोर्ट करें और मैन्युअल सफ़ाई की झंझट के बिना तुरंत व्यवस्थित डेटा के साथ काम शुरू करें।
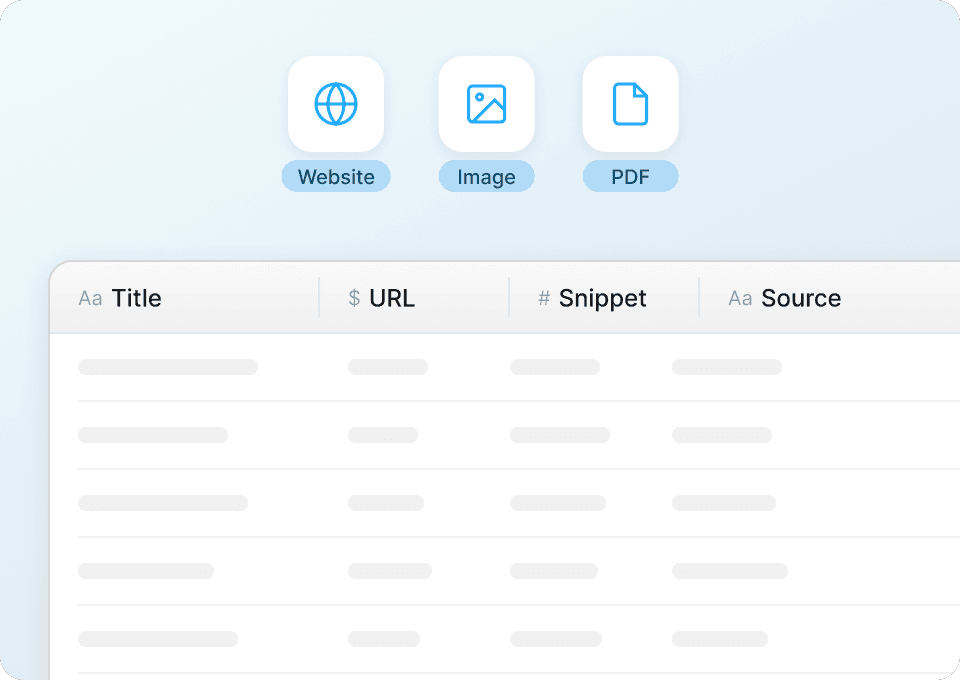
सिर्फ़ TechCrunch ही नहीं, किसी भी साइट को स्क्रैप करें
हर वेबसाइट के लिए नया टूल क्यों सीखना? Thunderbit लगभग किसी भी वेबसाइट पर काम करता है, जिसमें TechCrunch भी शामिल है। शुरुआत और तेज़ करने के लिए हमारे पास 50+ पहले से बने टेम्पलेट भी हैं। चाहे आप लेख सामग्री, टैग्स, या अन्य विवरण इकट्ठा कर रहे हों, Thunderbit वेब से डेटा स्क्रैप करने का आपका एकमात्र समाधान है।
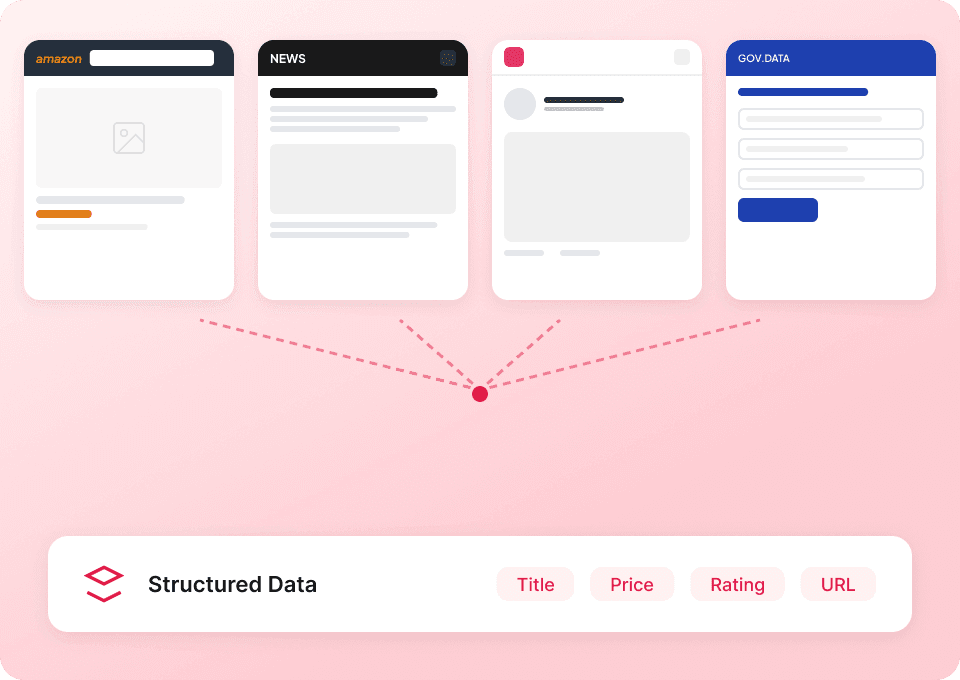
TechCrunch को प्रभावी ढंग से स्क्रैप करने में दिक्कत हो रही है?
देखिए कि Thunderbit पारंपरिक तरीकों की तुलना में TechCrunch डेटा एक्सट्रैक्शन को कैसे आसान बनाता है।
पारंपरिक स्क्रैपर्स
काम करने का पुराना तरीकाThunderbit
ज़्यादा समझदार तरीकासिर्फ हमारी बात पर भरोसा मत करें
देखें Thunderbit के बारे में हमारे उपयोगकर्ता क्या कहते हैं।







अक्सर पूछे जाने वाले प्रश्न
संबंधित उपयोग के मामले
Thunderbit के वेब स्क्रैपर के और उपयोग के मामले देखें।

United Airlines Scraper
United Airlines की फ्लाइट जानकारी जैसे फ्लाइट नंबर, आगमन समय और प्रस्थान हवाई अड्डा — बस पॉइंट और क्लिक करें, बाकी काम Thunderbit AI अपने आप संभाल लेता है।
और जानें ->
PlayStation Scraper
कुछ ही क्लिक में PlayStation गेम डेटा जैसे शीर्षक, जेनर और डिस्काउंटेड कीमत हासिल करें — मैन्युअल कॉपी-पेस्ट की झंझट अब खत्म।
और जानें ->
Sports Direct Scraper
Thunderbit के AI की मदद से Sports Direct से प्रोडक्ट नाम, कीमतें और डिस्काउंट प्रतिशत आसानी से निकालें — किसी जटिल सेटअप या कोडिंग की ज़रूरत नहीं।
और जानें ->Elgiganten Scraper
Thunderbit के AI की मदद से सिर्फ दो क्लिक में Elgiganten से प्रोडक्ट नाम, कीमतें और उपलब्धता का डेटा निकालें — बाकी भारी काम AI कर देगा।
और जानें ->
Trustpilot स्क्रैपर
Trustpilot पेजों को समीक्षाओं, रेटिंग्स और समीक्षकों के नामों वाली साफ़-सुथरी स्प्रेडशीट में बदलें। हम आपके लिए हर पेज पढ़ते हैं, इसलिए न कोड की ज़रूरत है, न कॉपी-पेस्ट की।
और जानें ->PeopleWhiz स्क्रैपर
Thunderbit PeopleWhiz स्क्रैपर आपको AI-संचालित फ़ील्ड सुझावों के साथ PeopleWhiz खोज परिणामों और प्रोफाइलों से डेटा निकालने देता है। शोध, मार्केटिंग या लीड जनरेशन के लिए नाम, संपर्क विवरण, स्थान और भी बहुत कुछ इकट्ठा करें। PeopleWhiz डेटा को संरचित डेटासेट में जल्दी और कुशलता से बदलें।
और जानें ->क्या आप अपने डेटा एक्सट्रैक्शन को तेज़ करने के लिए तैयार हैं?
100,000+ पेशेवरों से जुड़ें जो पहले से ही Thunderbit का उपयोग अपने वेब स्क्रैपिंग वर्कफ़्लो को ऑटोमेट करने के लिए कर रहे हैं।
मुफ्त ट्रायल 8 वेबपेजों के लिए असीमित क्रेडिट देता है।