सबस्टैक स्क्रैपर

प्रमुख कंपनियों के पेशेवरों का भरोसा














Thunderbit के साथ Substack डेटा अनलॉक करें
Substack डेटा सीधे अपने ऐप्स में भेजें
Substack प्रकाशन विवरण जैसे लेखक का नाम, लेख शीर्षक और सब्सक्राइबर काउंट को हाथ से कॉपी-पेस्ट करना बंद करें। Thunderbit के साथ, सिर्फ़ एक क्लिक में आपका निकाला हुआ डेटा सीधे Google Sheets, Notion या Airtable में भेजा जा सकता है। थकाऊ मैन्युअल काम के बिना प्रकाशन रुझानों और कंटेंट परफ़ॉर्मेंस का विश्लेषण करें.
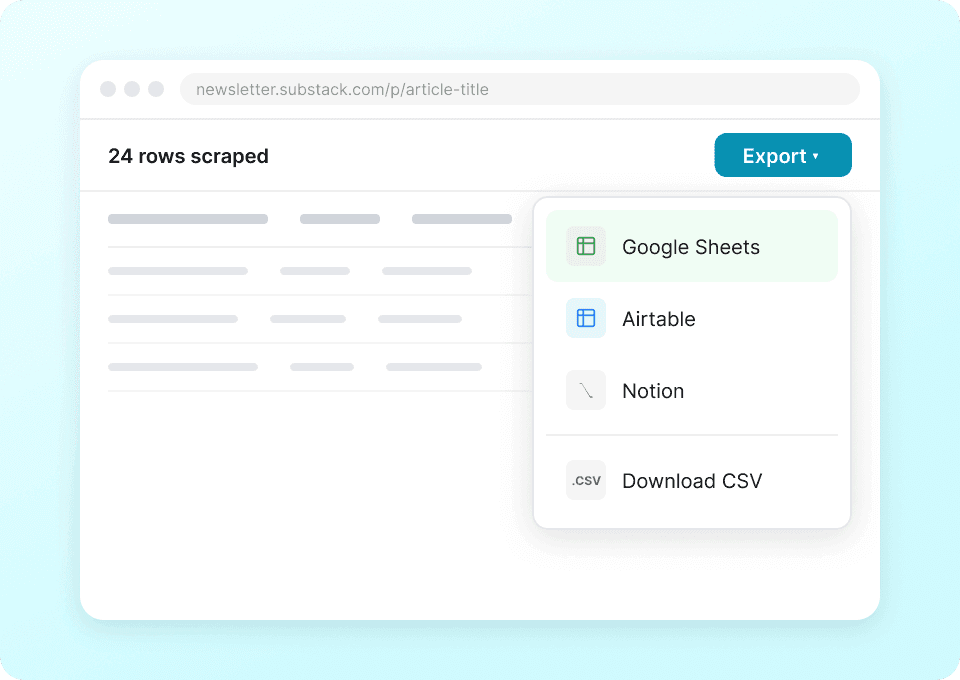
Substack और उससे आगे के लिए एक ही स्क्रैपर
हर वेबसाइट के लिए अलग स्क्रैपर इस्तेमाल करने में न फँसें। Thunderbit Substack पर तुरंत काम करता है, और अन्य लोकप्रिय प्लेटफ़ॉर्म के लिए 50 से अधिक pre-built templates भी शामिल हैं। प्रकाशन विवरण, लेख सामग्री और बहुत कुछ निकालें, फिर उसी टूल का इस्तेमाल कहीं और से भी डेटा इकट्ठा करने के लिए करें।
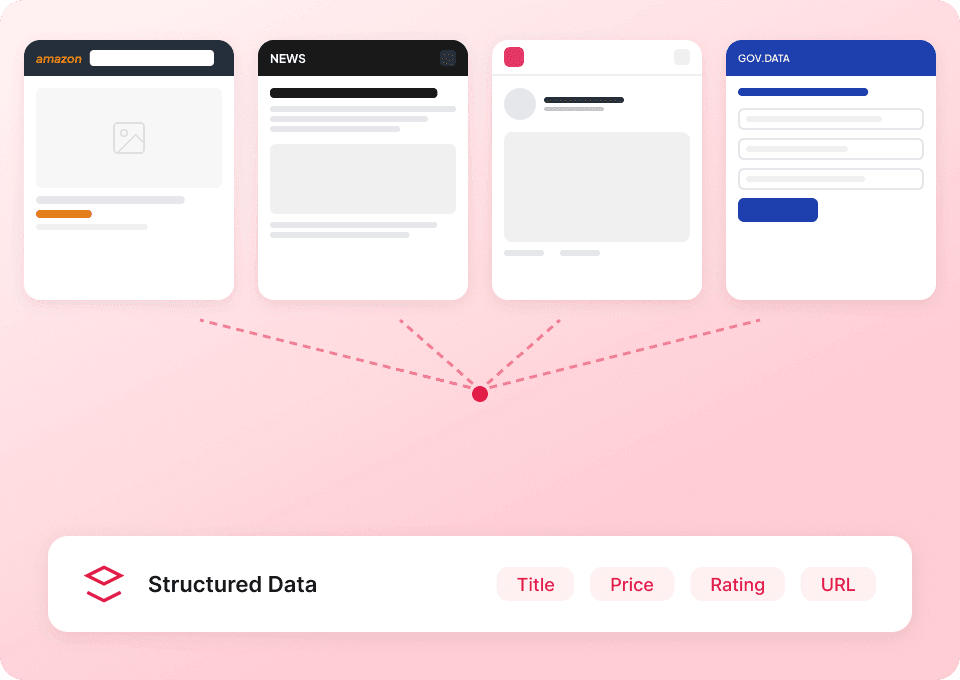
Substack की पूरी कहानी पाएं
Substack के प्रकाशन लिस्टिंग पेज केवल सारांश दिखाते हैं। Thunderbit अपने-आप हर article subpage पर जाकर पूरा कंटेंट निकालता है, जिससे आपको एक पूरा डेटासेट मिलता है। पूरे लेख शीर्षक, लेखक नाम, प्रकाशन नाम और लेख सामग्री एक ही बार में प्राप्त करें।
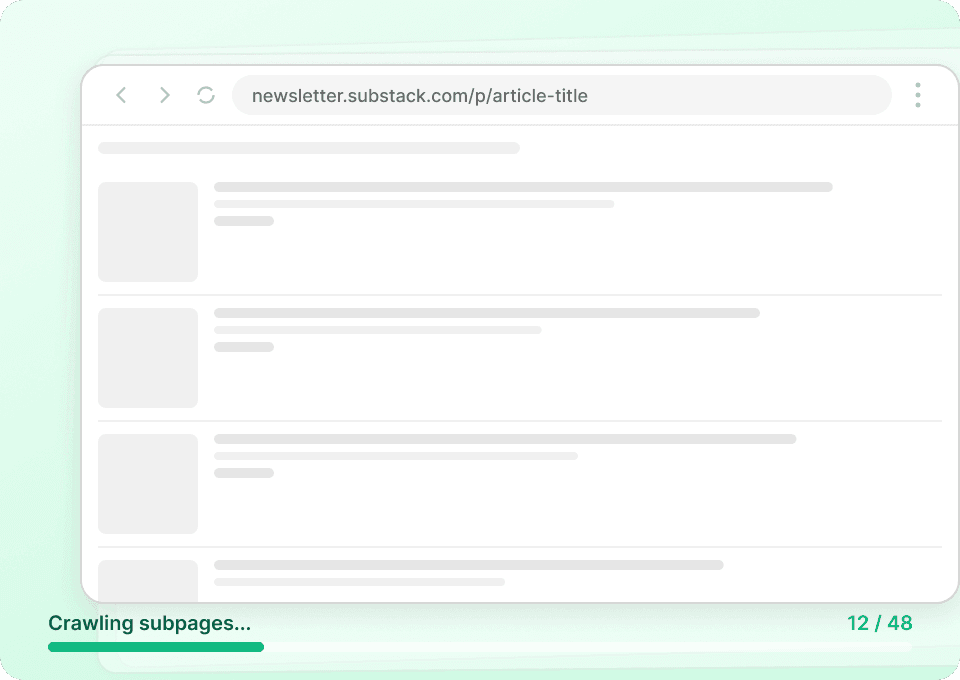
क्या Substack को प्रभावी ढंग से स्क्रैप करने में परेशानी हो रही है?
देखिए कि Thunderbit Substack डेटा के लिए पारंपरिक scrapers से बेहतर क्यों है.
पारंपरिक scrapers
काम करने का पुराना तरीकाThunderbit
ज़्यादा स्मार्ट तरीकासिर्फ हमारी बात पर भरोसा मत करें
देखें Thunderbit के बारे में हमारे उपयोगकर्ता क्या कहते हैं।






अक्सर पूछे जाने वाले प्रश्न
संबंधित उपयोग के मामले
Thunderbit के वेब स्क्रैपर के और उपयोग के मामले देखें।

UNIQLO Scraper
Thunderbit के Chrome extension की मदद से सिर्फ 2 क्लिक में Uniqlo के product data, जैसे नाम, कीमतें और उपलब्ध sizes, आसानी से निकालें।
और जानें ->
Sports Direct Scraper
Thunderbit के AI की मदद से Sports Direct से प्रोडक्ट नाम, कीमतें और डिस्काउंट प्रतिशत आसानी से निकालें — किसी जटिल सेटअप या कोडिंग की ज़रूरत नहीं।
और जानें ->
United Airlines Scraper
United Airlines की फ्लाइट जानकारी जैसे फ्लाइट नंबर, आगमन समय और प्रस्थान हवाई अड्डा — बस पॉइंट और क्लिक करें, बाकी काम Thunderbit AI अपने आप संभाल लेता है।
और जानें ->
विकिपीडिया स्क्रैपर
विकिपीडिया के इन्फोबॉक्स डेटा, संदर्भ और लेख के पाठ को एक साफ़-सुथरी स्प्रेडशीट में लाएँ — बिना कोड के, AI आपके लिए संरचना तैयार कर देता है।
और जानें ->
HKTVmall Scraper
बस कुछ ही क्लिक में HKTVmall लिस्टिंग से प्रोडक्ट के नाम, कीमतें और ग्राहक रेटिंग तक निकालें — किसी जटिल सेटअप की ज़रूरत नहीं।
और जानें ->
PubMed Scraper
Thunderbit का PubMed Scraper आपको AI की मदद से PubMed के सर्च रिज़ल्ट्स और आर्टिकल पेजों से व्यवस्थित (structured) डेटा निकालने में मदद करता है। ट्रेंडिंग मेडिकल रिसर्च, क्लिनिकल ट्रायल से जुड़े प्रमाण, एब्स्ट्रैक्ट, लेखक, संस्थागत संबद्धताएँ, प्रकाशन तिथियाँ और लिंक स्क्रैप करें—और फिर डेटा को Excel, Google Sheets, Airtable या Notion में एक्सपोर्ट करें।
और जानें ->क्या आप अपने डेटा एक्सट्रैक्शन को तेज़ करने के लिए तैयार हैं?
100,000+ पेशेवरों से जुड़ें जो पहले से ही Thunderbit का उपयोग अपने वेब स्क्रैपिंग वर्कफ़्लो को ऑटोमेट करने के लिए कर रहे हैं।
मुफ्त ट्रायल 8 वेबपेजों के लिए असीमित क्रेडिट देता है।