सिंपल Reddit स्क्रैपर

प्रमुख कंपनियों के पेशेवरों का भरोसा














सिर्फ दो क्लिक में Reddit डेटा अनलॉक करें
दो क्लिक में Reddit डेटा निकालें
क्या आप ऐसे जटिल स्क्रैपर्स से थक गए हैं जिनमें कोडिंग की ज़रूरत पड़ती है? Thunderbit की मदद से आप Reddit का डेटा — जैसे पोस्ट टाइटल, टेक्स्ट, लेखक, सबरेडिट्स और अपवोट्स — सिर्फ दो क्लिक में निकाल सकते हैं। बस जिस डेटा की ज़रूरत है उस पर पॉइंट करें, और Thunderbit तुरंत फ़ील्ड्स पहचानकर उसे एक्सट्रैक्ट कर लेता है। न कोड, न CSS सेलेक्टर्स, न झंझट।
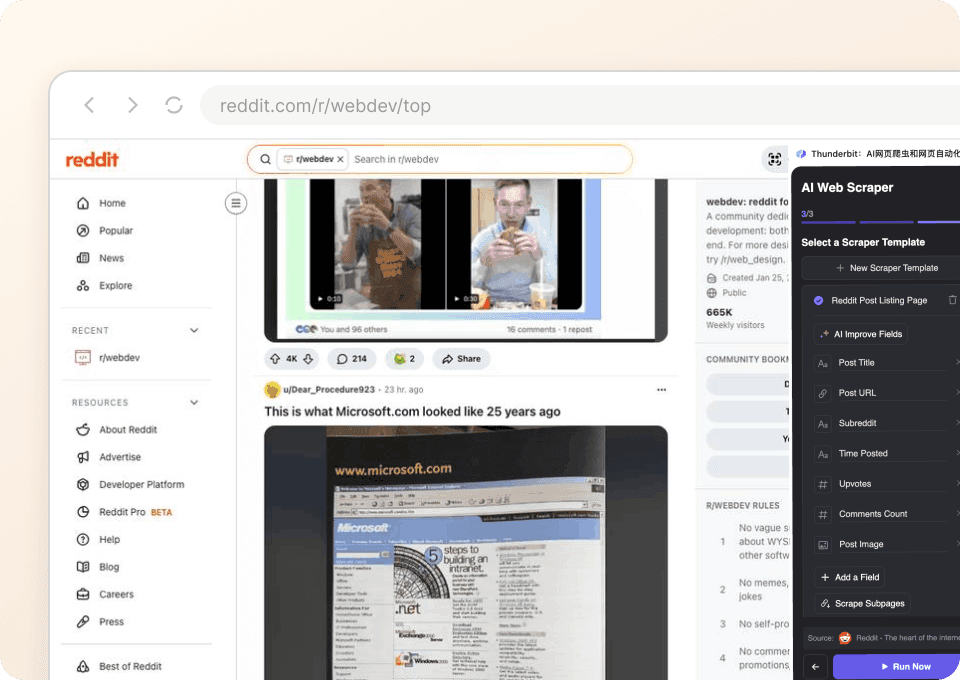
Reddit के लेआउट बदलाव के साथ खुद को ढालता है
Reddit का लेआउट बदलता रहता है, और ज़्यादातर स्क्रैपर्स टूट जाते हैं। Thunderbit सेमांटिक AI का इस्तेमाल करता है, जो पेज के मतलब को समझता है, सिर्फ फिक्स्ड सेलेक्टर्स को नहीं। इसका मतलब है कि यह लेआउट बदलने पर भी अपने-आप एडजस्ट हो जाता है, ताकि आप बिना रुकावट पोस्ट डेटा, लेखक की जानकारी और सबरेडिट डिटेल्स स्क्रैप करते रह सकें।
Reddit डेटा कलेक्शन को ऑटोमेट करें
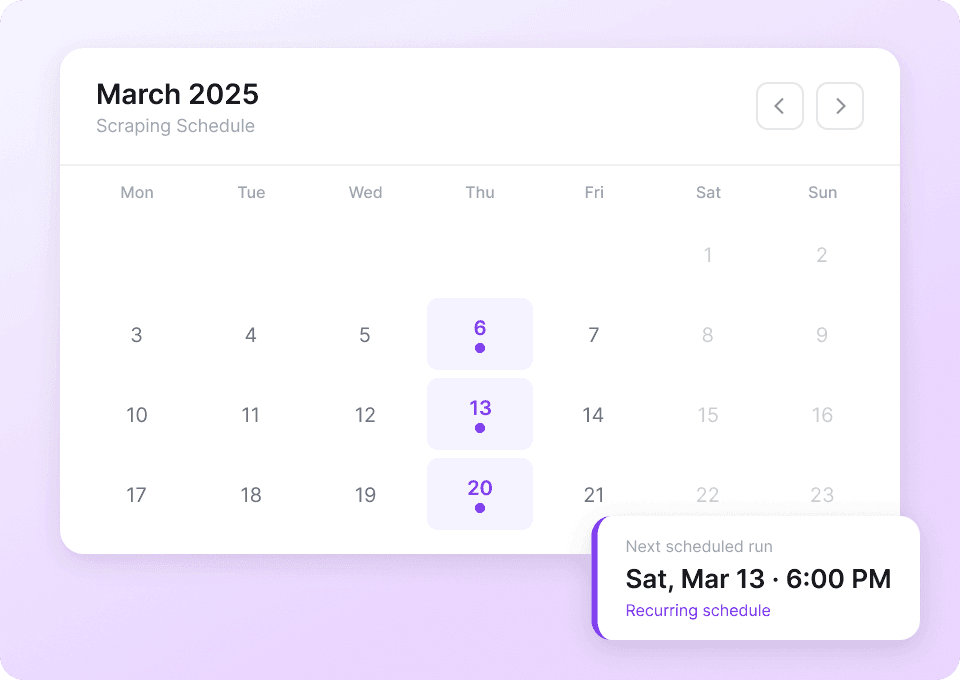
Reddit डेटा लगातार अपडेट होता रहता है। Thunderbit आपको ऑटोपायलट पर रीकुरिंग स्क्रैपिंग टास्क शेड्यूल करने देता है। बिना बार-बार स्क्रैपर चलाए, नए पोस्ट टाइटल, अपवोट्स और बाकी जानकारी सीधे Google Sheets, Notion या Airtable में पहुँच जाए। बिना मेहनत किए अपना डेटा हमेशा ताज़ा रखें।
Redfin स्क्रैपिंग की परेशानियों से थक गए हैं?
देखिए Thunderbit किस तरह Redfin डेटा निकालने का सबसे आसान तरीका बनाता है।
पारंपरिक स्क्रैपर
काम करने का पुराना तरीकाThunderbit
ज़्यादा स्मार्ट तरीकासिर्फ हमारी बात पर भरोसा मत करें
देखें Thunderbit के बारे में हमारे उपयोगकर्ता क्या कहते हैं।





अक्सर पूछे जाने वाले प्रश्न
संबंधित उपयोग के मामले
Thunderbit के वेब स्क्रैपर के और उपयोग के मामले देखें।

Priceline स्क्रेपर
Thunderbit की AI की मदद से बस कुछ क्लिक में Priceline से होटल के नाम, कीमतें और रेटिंग निकालें।
और जानें ->
Trustpilot स्क्रैपर
Trustpilot पेजों को समीक्षाओं, रेटिंग्स और समीक्षकों के नामों वाली साफ़-सुथरी स्प्रेडशीट में बदलें। हम आपके लिए हर पेज पढ़ते हैं, इसलिए न कोड की ज़रूरत है, न कॉपी-पेस्ट की।
और जानें ->
विकिपीडिया स्क्रैपर
विकिपीडिया के इन्फोबॉक्स डेटा, संदर्भ और लेख के पाठ को एक साफ़-सुथरी स्प्रेडशीट में लाएँ — बिना कोड के, AI आपके लिए संरचना तैयार कर देता है।
और जानें ->
United Airlines Scraper
United Airlines की फ्लाइट जानकारी जैसे फ्लाइट नंबर, आगमन समय और प्रस्थान हवाई अड्डा — बस पॉइंट और क्लिक करें, बाकी काम Thunderbit AI अपने आप संभाल लेता है।
और जानें ->
HKTVmall Scraper
बस कुछ ही क्लिक में HKTVmall लिस्टिंग से प्रोडक्ट के नाम, कीमतें और ग्राहक रेटिंग तक निकालें — किसी जटिल सेटअप की ज़रूरत नहीं।
और जानें ->
UNIQLO Scraper
Thunderbit के Chrome extension की मदद से सिर्फ 2 क्लिक में Uniqlo के product data, जैसे नाम, कीमतें और उपलब्ध sizes, आसानी से निकालें।
और जानें ->क्या आप अपने डेटा एक्सट्रैक्शन को तेज़ करने के लिए तैयार हैं?
100,000+ पेशेवरों से जुड़ें जो पहले से ही Thunderbit का उपयोग अपने वेब स्क्रैपिंग वर्कफ़्लो को ऑटोमेट करने के लिए कर रहे हैं।
मुफ्त ट्रायल 8 वेबपेजों के लिए असीमित क्रेडिट देता है।