समाचार स्क्रैपर

प्रमुख कंपनियों के पेशेवरों का भरोसा














न्यूज़ डेटा, और तेज़ी से कैप्चर करें
मैन्युअल झंझट के बिना लेखों, लिस्टिंग और स्रोतों से साफ़ न्यूज़ डेटा खींचें।
पूरा लेख विवरण प्राप्त करें
न्यूज़ लिस्टिंग पेज आपको केवल एक टीज़र देते हैं। Thunderbit हर लेख सबपेज पर जाता है और पूरा विवरण वापस लाता है, जिसमें शीर्षक, लेख सारांश, लेखक, प्रकाशन तिथि, न्यूज़ स्रोत और सेक्शन शामिल हैं। इसका मतलब है कि आप कम स्टेप में कहानियों की साधारण सूची से एक पूर्ण डेटासेट तक पहुँच सकते हैं।
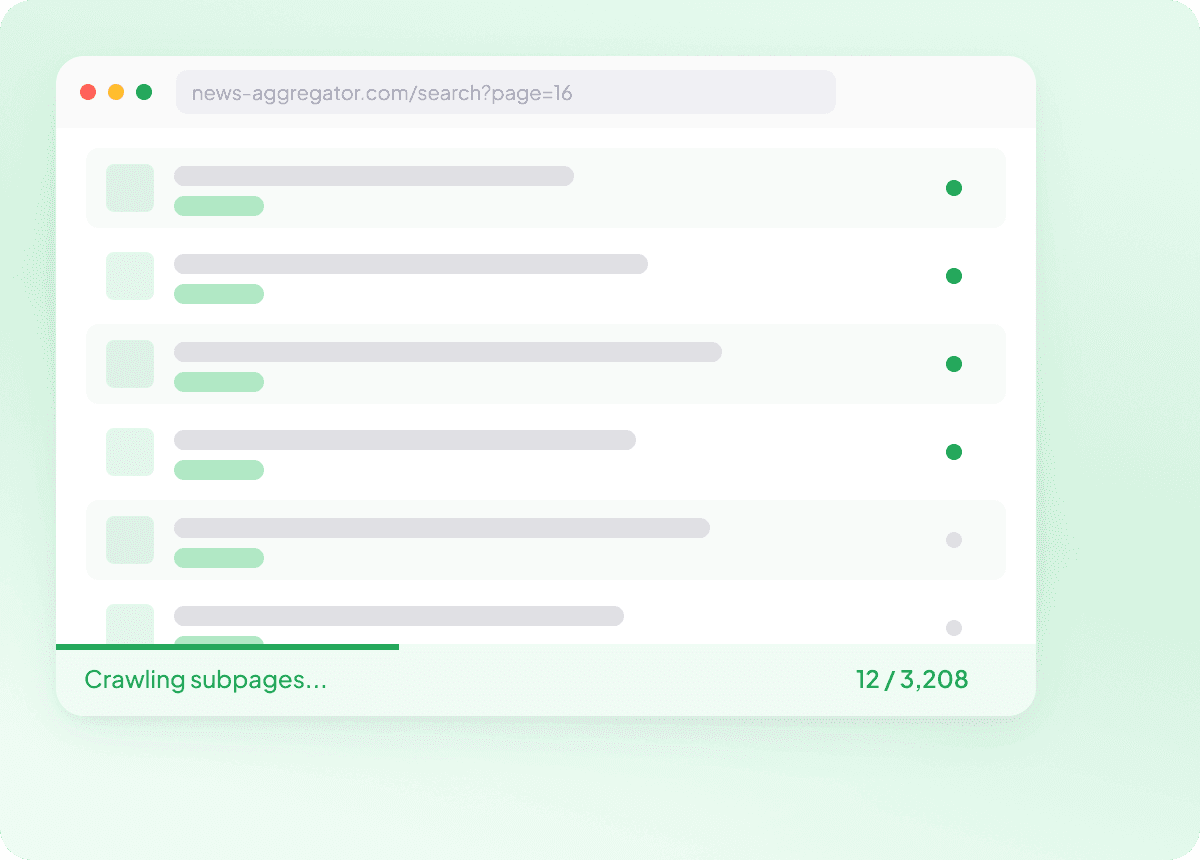
News URL सूचियों को bulk में स्क्रैप करें
न्यूज़ को एक-एक पेज करके स्क्रैप करना जल्दी ही धीमा हो जाता है। Thunderbit के साथ आप लेख URL की एक सूची दे सकते हैं और सैकड़ों पेज एक साथ bulk में स्क्रैप कर सकते हैं, ताकि हर कहानी आपकी जरूरत के फ़ील्ड के साथ कैप्चर हो जाए। यह बिना एक ही काम दोहराए बड़े न्यूज़ डेटासेट इकट्ठा करने का व्यावहारिक तरीका है।

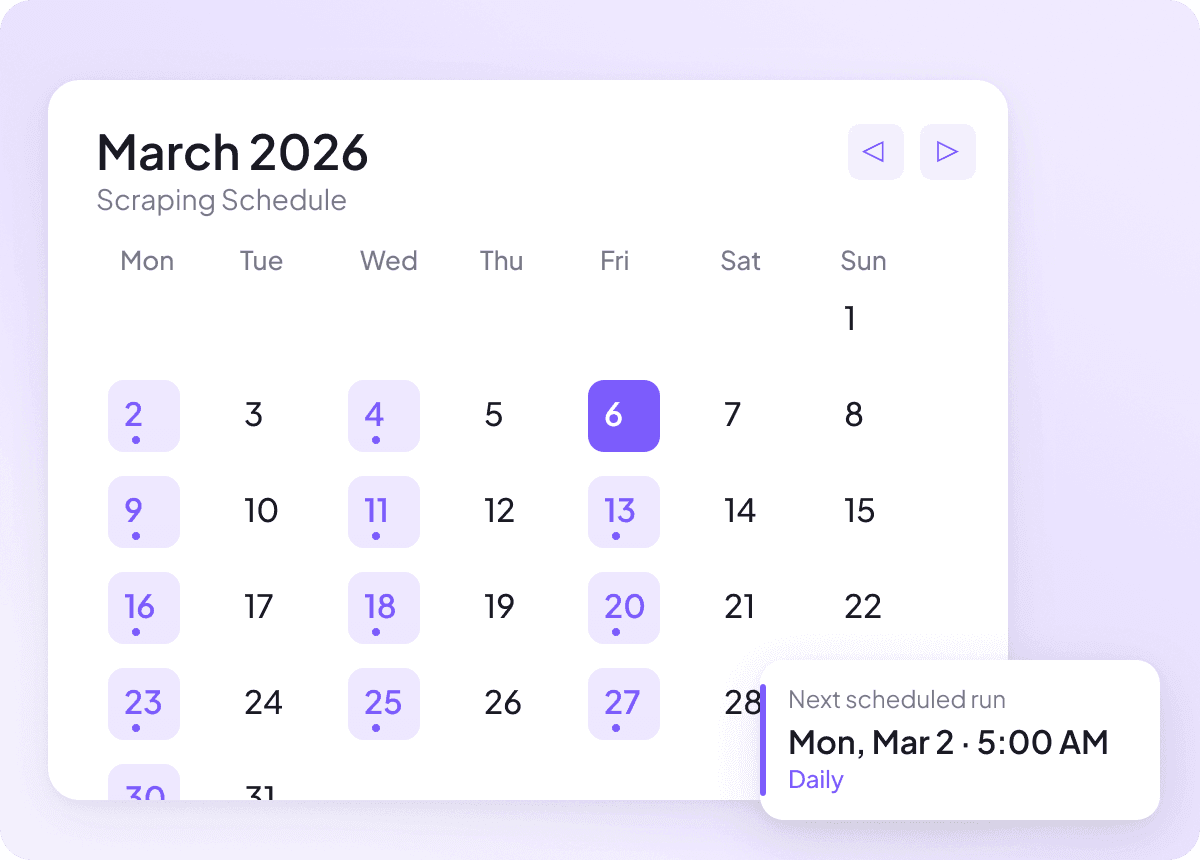
News डेटा को ताज़ा रखें
न्यूज़ रोज़ बदलती है, और पुराना डेटा बेकार हो जाता है। शेड्यूल्ड स्क्रैपिंग सेट करें, ताकि Thunderbit अपने-आप चले और आपकी स्प्रेडशीट को ताज़ा सुर्खियों, सारांशों, लेखकों, प्रकाशन तिथियों, न्यूज़ स्रोतों और सेक्शनों के साथ अपडेट रखे। आपको यह काम याद रखने की जरूरत नहीं पड़ती, फिर भी नियमित अपडेट मिलते रहते हैं।
Thunderbit पारंपरिक न्यूज़ स्क्रैपर्स से अलग क्यों है?
लगातार टूट-फूट के बिना अव्यवस्थित न्यूज़ डेटा इकट्ठा करने का तेज़ तरीका।
पारंपरिक स्क्रैपर्स
काम करने का पुराना तरीकाThunderbit AI
ज़्यादा स्मार्ट तरीकासिर्फ हमारी बात पर भरोसा मत करें
देखें Thunderbit के बारे में हमारे उपयोगकर्ता क्या कहते हैं।





अक्सर पूछे जाने वाले प्रश्न
संबंधित उपयोग के मामले
Thunderbit के वेब स्क्रैपर के और उपयोग के मामले देखें।

HKTVmall Scraper
बस कुछ ही क्लिक में HKTVmall लिस्टिंग से प्रोडक्ट के नाम, कीमतें और ग्राहक रेटिंग तक निकालें — किसी जटिल सेटअप की ज़रूरत नहीं।
और जानें ->
Carousell स्क्रैपर
बिना किसी जटिल सेटअप या कोड के, Carousell से आइटम टाइटल, डिस्क्रिप्शन और कीमत जैसी जानकारी आसानी से निकालें।
और जानें ->
कूपांग स्क्रैपर
दो क्लिक में कूपांग से उत्पाद के नाम, कीमतें और छूट दरें निकालें — किसी कोडिंग की जरूरत नहीं।
और जानें ->
PubMed Scraper
Thunderbit का PubMed Scraper आपको AI की मदद से PubMed के सर्च रिज़ल्ट्स और आर्टिकल पेजों से व्यवस्थित (structured) डेटा निकालने में मदद करता है। ट्रेंडिंग मेडिकल रिसर्च, क्लिनिकल ट्रायल से जुड़े प्रमाण, एब्स्ट्रैक्ट, लेखक, संस्थागत संबद्धताएँ, प्रकाशन तिथियाँ और लिंक स्क्रैप करें—और फिर डेटा को Excel, Google Sheets, Airtable या Notion में एक्सपोर्ट करें।
और जानें ->सबस्टैक स्क्रैपर
सबस्टैक के सब्सक्राइबर काउंट, लेख शीर्षक और प्रकाशन विवरण एक साफ़ स्प्रेडशीट में लाएँ — कोड की ज़रूरत नहीं, AI खुद संरचना बना देता है।
और जानें ->
Trivago स्क्रैपर
बस कुछ ही क्लिक में Trivago से होटल के नाम, कीमतें और रेटिंग्स स्क्रैप करें — किसी कोडिंग या सेटअप की ज़रूरत नहीं।
और जानें ->क्या आप अपने डेटा एक्सट्रैक्शन को तेज़ करने के लिए तैयार हैं?
100,000+ पेशेवरों से जुड़ें जो पहले से ही Thunderbit का उपयोग अपने वेब स्क्रैपिंग वर्कफ़्लो को ऑटोमेट करने के लिए कर रहे हैं।
मुफ्त ट्रायल 8 वेबपेजों के लिए असीमित क्रेडिट देता है।