आज इंटरनेट ट्रैफिक का करीब आधा हिस्सा बॉट्स से आता है—और इनमें से ज़्यादातर बड़े स्केल पर लिंक, डेटा और URLs स्क्रैप करते हैं। अगर तुम अब भी ये सब हाथ से कर रहे हो, तो सच में तुम गेम में पीछे छूट रहे हो।
मैंने 12 लिंक एक्सट्रैक्टर टूल्स टेस्ट किए—AI-पावर्ड Chrome एक्सटेंशन से लेकर Python लाइब्रेरीज़ तक—ताकि साफ हो सके कि जब तुम्हें फटाफट हजारों URLs निकालने हों, तब कौन-से टूल्स असल में काम के हैं।
ये रहा मेरा निष्कर्ष।
लिंक एक्सट्रैक्टर क्यों ज़रूरी हैं
सीधी बात: वेब डेटा से भरा पड़ा है, और बिज़नेस उस बिखरे हुए डेटा को काम की इनसाइट्स में बदलने की रेस में हैं। और अब उन टीमों के लिए “मिशन-क्रिटिकल” बन चुके हैं जो:
- लीड्स बनाना चाहते हैं: सेल्स टीमें डायरेक्टरीज़ या LinkedIn से मिनटों में कंपनी प्रोफाइल लिंक निकाल सकती हैं, फिर उन्हीं URLs को आगे कॉन्टैक्ट डिटेल्स निकालने वाले टूल्स में डाल सकती हैं। लगातार क्लिकिंग का झंझट खत्म।
- कंटेंट एग्रीगेट करके SEO बढ़ाना चाहते हैं: मार्केटर्स ब्लॉग के सारे आर्टिकल URLs इकट्ठा कर सकते हैं, कॉम्पिटिटर बैकलिंक्स ट्रैक कर सकते हैं, या टूटे हुए लिंक ढूंढने के लिए साइट स्ट्रक्चर ऑडिट कर सकते हैं।
- कंपटीशन मॉनिटरिंग और मार्केट रिसर्च करना चाहते हैं: ऑपरेशंस टीमें नए प्रोडक्ट्स, प्राइसिंग पेजेज़ या प्रेस रिलीज़ के लिंक ऑटोमैटिकली जुटा सकती हैं—बिना मेहनत के प्रतिस्पर्धियों पर नज़र बनी रहती है।
- वर्कफ़्लो ऑटोमेट करके समय बचाना चाहते हैं: मॉडर्न लिंक स्क्रैपर्स बल्क URLs संभालते हैं, सबपेजेज़ क्रॉल करते हैं, और डेटा को स्ट्रक्चर्ड फॉर्मेट (CSV, Excel, Google Sheets, Notion—जो चाहें) में एक्सपोर्ट करते हैं। यानी कॉपी-पेस्ट मैराथन और गंदे टेक्स्ट फाइल्स की सफाई से छुटकारा।
जब , तब मैन्युअल तरीके से यह काम करना प्रैक्टिकल ही नहीं है। सही लिंक एक्सट्रैक्टर ऐसा है जैसे तुम्हारे पास एक सुपरचार्ज्ड असिस्टेंट हो—जो थकता नहीं, कोई लिंक मिस नहीं करता, और कॉफी ब्रेक भी नहीं मांगता।
हमने बेस्ट लिंक एक्सट्रैक्टर कैसे चुने
इतने सारे टूल्स में सही लिंक एक्सट्रैक्टर चुनना कभी-कभी टेक कॉन्फ्रेंस में स्पीड-डेटिंग जैसा लगता है—सब खुद को “परफेक्ट” बताते हैं, लेकिन काम कुछ ही करते हैं। मैंने टॉप 12 चुनने के लिए ये मानदंड रखे:
- यूज़ करना कितना आसान है: क्या बिना कोडिंग वाले लोग regex में PhD किए बिना चला सकते हैं? नो-कोड/लो-कोड को अतिरिक्त अंक।
- बल्क और मल्टी-लेवल स्क्रैपिंग: क्या एक साथ सैकड़ों URLs संभाल सकता है? क्या सबपेजेज़ क्रॉल करके लिंक अपने आप फॉलो करता है?
- एक्सपोर्ट और इंटीग्रेशन: CSV, Excel, Google Sheets, Notion, Airtable या API—कहाँ-कहाँ भेज सकता है? जितना कम मैन्युअल काम, उतना बेहतर।
- यूज़र टाइप और फ्लेक्सिबिलिटी: बिज़नेस यूज़र्स, एनालिस्ट्स या डेवलपर्स—किसके लिए बना है? कुछ टूल्स सबके लिए, कुछ खास जरूरतों के लिए।
- एडवांस्ड फीचर्स: AI रिकग्निशन, शेड्यूलिंग, क्लाउड स्केलिंग, डेटा क्लीनिंग, और कॉमन साइट्स के लिए टेम्पलेट्स।
- प्राइसिंग और स्केलेबिलिटी: फ्री टियर, पे-एज़-यू-गो, या एंटरप्राइज़? मैंने वैल्यू-फॉर-मनी भी देखा।
मैंने ब्राउज़र एक्सटेंशन से लेकर एंटरप्राइज़ प्लेटफ़ॉर्म तक सब शामिल किए हैं—तो तुम सोलो फाउंडर हो या Fortune 500 की डेटा टीम, तुम्हारे लिए ऑप्शन मिलेगा।
Thunderbit: बिज़नेस यूज़र्स के लिए सबसे स्मार्ट लिंक एक्सट्रैक्टर
सबसे ऊपर से शुरू करते हैं। लिंक एक्सट्रैक्शन के लिए मेरी टॉप रिकमेंडेशन है—और सिर्फ इसलिए नहीं कि मैंने इसे बनाने में मदद की है। Thunderbit एक है, जिसे खास तौर पर उन बिज़नेस यूज़र्स के लिए बनाया गया है जिन्हें तेज़ नतीजे चाहिए।
Thunderbit को अलग क्या बनाता है? ये ऐसा है जैसे तुम्हारे पास एक AI इंटर्न हो जो सच में तुम्हारी बात समझता हो। तुम नैचुरल लैंग्वेज में बता सकते हो कि तुम्हें क्या चाहिए (“इस पेज से सारे प्रोडक्ट लिंक और प्राइस उठा लो”), और Thunderbit का AI बाकी काम खुद संभाल लेता है। न सेलेक्टर्स से छेड़छाड़, न स्क्रिप्ट लिखने की जरूरत।
और ये यहीं नहीं रुकता:
- बल्क URL सपोर्ट: एक URL पेस्ट करो या सैकड़ों की लिस्ट—Thunderbit एक ही रन में सब संभाल लेता है।
- सबपेज नेविगेशन: लिस्ट पेज से लिंक निकालकर हर डिटेल पेज पर जाकर और URLs चाहिए? Thunderbit की मल्टी-लेयर स्क्रैपिंग लॉजिक यही काम करती है।
- स्ट्रक्चर्ड एक्सपोर्ट: लिंक निकलने के बाद तुम फील्ड्स का नाम बदल सकते हो, कैटेगराइज़ कर सकते हो, और सीधे Google Sheets, Notion, Airtable, Excel या CSV में एक्सपोर्ट कर सकते हो। बाद की प्रोसेसिंग का सिरदर्द खत्म।
Thunderbit पर दुनिया भर में 30,000+ यूज़र्स भरोसा करते हैं—सेल्स टीमों से लेकर रियल एस्टेट एजेंट्स और इंडी ई-कॉमर्स शॉप्स तक। और हाँ, इसमें भी है (6 पेज तक स्क्रैप, या ट्रायल बूस्ट के साथ 10), ताकि तुम बिना रिस्क के ट्राय कर सको।
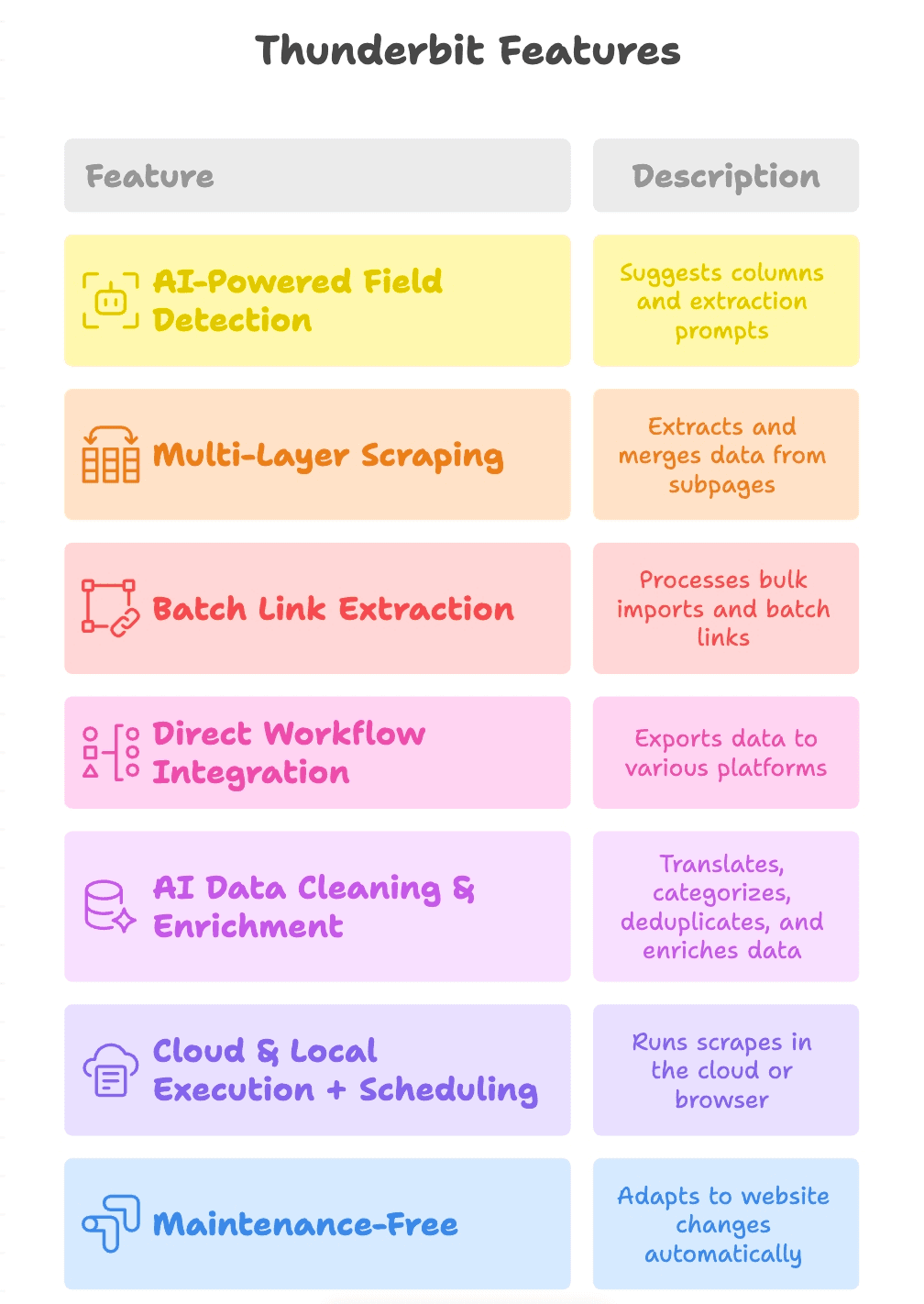
Thunderbit की खास खूबियाँ
आओ देखें कि Thunderbit को वाकई अलग क्या बनाता है:
- AI-पावर्ड फील्ड डिटेक्शन: “AI Suggest Fields” पर क्लिक करो—Thunderbit पेज पढ़कर कॉलम सुझाता है (जैसे “Product Link”, “PDF URL”, “Contact Email”) और हर फील्ड के लिए एक्सट्रैक्शन प्रॉम्प्ट भी बना देता है।
- मल्टी-लेयर स्क्रैपिंग: Thunderbit मेन पेज से सबपेजेज़ (जैसे प्रोडक्ट डिटेल पेज या PDF डाउनलोड) तक लिंक फॉलो कर सकता है, और सब डेटा एक ही टेबल में मर्ज कर देता है।
- बैच लिंक एक्सट्रैक्शन: एक पेज हो या हजार—Thunderbit बल्क इम्पोर्ट और बैच एक्सट्रैक्शन आसानी से कर लेता है।
- सीधा वर्कफ़्लो इंटीग्रेशन: रिज़ल्ट्स को Google Sheets, Notion, Airtable में भेजो या CSV/Excel डाउनलोड करो—डेटा वहीं पहुँचता है जहाँ टीम को चाहिए।
- AI डेटा क्लीनिंग और एनरिचमेंट: स्क्रैप करते-करते Thunderbit ट्रांसलेट, कैटेगराइज़, डीडुप्लिकेट और डेटा एनरिच भी कर सकता है—आउटपुट सिर्फ रॉ डंप नहीं, इस्तेमाल के लिए तैयार होता है।
- क्लाउड और लोकल रन + शेड्यूलिंग: स्पीड के लिए क्लाउड में रन करो, या लॉगिन वाली साइट्स के लिए ब्राउज़र में। रेकरिंग जॉब्स शेड्यूल करके डेटा हमेशा अपडेट रखो।
- मेंटेनेंस-फ्री: वेबसाइट बदलती रहे, Thunderbit का AI एडाप्ट करता है—टूटे स्क्रैपर्स ठीक करने में कम समय, रिज़ल्ट्स में ज़्यादा।
Octoparse: हर किसी के लिए नो-कोड लिंक स्क्रैपर
नो-कोड स्क्रैपिंग की दुनिया का क्लासिक टूल है। ये एक डेस्कटॉप ऐप (Windows/Mac) है, जिसमें विज़ुअल पॉइंट-एंड-क्लिक इंटरफ़ेस मिलता है। तुम वेबपेज खोलते हो, जिन लिंक की जरूरत है उन पर क्लिक करते हो, और Octoparse बाकी सेटअप समझ लेता है।
- बिगिनर्स के लिए बढ़िया: कोडिंग की जरूरत नहीं—क्लिक करो, एक्सट्रैक्ट करो, आगे बढ़ो।
- पेजिनेशन और डायनेमिक कंटेंट: “Next” बटन क्लिक करना, स्क्रॉल करना, यहाँ तक कि लॉगिन भी संभाल सकता है।
- क्लाउड स्क्रैपिंग और शेड्यूलिंग: पेड प्लान्स में क्लाउड रन और रेकरिंग टास्क शेड्यूलिंग।
- एक्सपोर्ट ऑप्शंस: CSV, Excel, JSON में डाउनलोड या डेटाबेस में पुश।
फ्री प्लान छोटे कामों के लिए ठीक-ठाक है (10 टास्क और 50,000 रो/माह तक), लेकिन हेवी यूज़र्स को पेड प्लान चाहिए (लगभग $75/माह से)।
Apify: कस्टम वर्कफ़्लो के लिए फ्लेक्सिबिल URL एक्सट्रैक्टर
वेब स्क्रैपिंग का “स्विस आर्मी नाइफ” है। इसमें प्री-बिल्ट “actors” (स्क्रैपिंग टूल्स) का मार्केटप्लेस है, और तुम JavaScript या Python में अपने स्क्रिप्ट्स भी लिख सकते हो।
- प्री-बिल्ट + कस्टमाइज़ेबल: कॉमन कामों के लिए कम्युनिटी actors इस्तेमाल करो, या अपने हिसाब से बनाओ।
- बल्क और शेड्यूल्ड स्क्रैपिंग: URLs क्यू में डालो, पैरेलल रन करो, और रेकरिंग स्क्रैप्स शेड्यूल करो।
- API-फर्स्ट: JSON/CSV/Excel/Google Sheets में एक्सपोर्ट और डेटा पाइपलाइन में इंटीग्रेशन।
- पे-एज़-यू-गो: हर महीने फ्री क्रेडिट्स, फिर यूज़ेज-बेस्ड बिलिंग।
ये उन सेमी-टेक्निकल टीमों और डेवलपर्स के लिए बढ़िया है जिन्हें फ्लेक्सिबिलिटी और स्केल चाहिए।
Bright Data URL Scraper: एंटरप्राइज़-ग्रेड लिंक स्क्रैपिंग
उन एंटरप्राइज़ के लिए बना है जिन्हें बड़े पैमाने पर स्क्रैप करना होता है। उनका Data Collector हाई-वॉल्यूम जॉब्स के लिए प्रीसेट URL Scraper देता है।
- बहुत बड़े स्केल पर काम: हजारों/लाखों पेज स्क्रैप, और ब्लॉक से बचने के लिए मजबूत प्रॉक्सी इंफ्रास्ट्रक्चर।
- प्रीसेट टेम्पलेट्स: ई-कॉमर्स, सोशल, रियल एस्टेट आदि के लिए रेडी-मेड स्क्रैपर्स।
- एंटरप्राइज़ फीचर्स: कंप्लायंस टूल्स, एक्सपर्ट सपोर्ट, एडवांस्ड एंटी-ब्लॉकिंग।
- प्राइसिंग: लगभग $350 से 100,000 पेज लोड्स—स्पष्ट रूप से बड़े बिज़नेस के लिए।
स्टार्टअप के लिए ये ओवरकिल हो सकता है, लेकिन मिशन-क्रिटिकल हाई-वॉल्यूम स्क्रैपिंग में Bright Data बहुत ताकतवर है।
WebHarvy: पॉइंट-एंड-क्लिक वाला विज़ुअल लिंक एक्सट्रैक्टर
एक Windows डेस्कटॉप ऐप है, जिसमें बिल्ट-इन ब्राउज़र के अंदर लिंक पर क्लिक करके स्क्रैप किया जा सकता है।
- बहुत आसान: एक लिंक पर क्लिक करो—WebHarvy मिलते-जुलते एलिमेंट्स को अपने आप हाइलाइट कर देता है।
- रेगुलर एक्सप्रेशन सपोर्ट: कॉमन कामों के लिए बिल्ट-इन पैटर्न, बिना कोडिंग।
- Excel, CSV, JSON, XML, SQL में एक्सपोर्ट: बिज़नेस यूज़र्स के लिए परिचित फॉर्मेट्स।
- वन-टाइम लाइसेंस: एक बार भुगतान, लंबे समय तक उपयोग।
छोटे बिज़नेस, रिसर्चर्स, या किसी भी ऐसे व्यक्ति के लिए बढ़िया जो बिना कोडिंग जल्दी लिंक निकालना चाहता है।
Web Scraper (Chrome Extension): ब्राउज़र में फटाफट लिंक स्क्रैपिंग
एक फ्री, ओपन-सोर्स टूल है जो तुम्हारे ब्राउज़र को ही स्क्रैपर बना देता है।
- Sitemaps डिफाइन करें: बताओ कैसे नेविगेट करना है और क्या निकालना है।
- पेजिनेशन और मल्टी-लेवल क्रॉलिंग: कैटेगरी, सबकैटेगरी और डिटेल पेजेज़ तक क्रॉल।
- CSV/XLSX एक्सपोर्ट: ब्राउज़र से ही डेटा डाउनलोड।
- कम्युनिटी टेम्पलेट्स: पॉपुलर साइट्स के लिए कई शेयर किए गए sitemaps।
क्विक, वन-ऑफ कामों या बजट में स्टूडेंट्स/छोटी टीमों के लिए बढ़िया।
ScraperAPI: डेवलपर्स के लिए स्केलेबल लिंक स्क्रैपर
उन डेवलपर्स के लिए है जो बड़े पैमाने पर वेब पेज फेच करना चाहते हैं—प्रॉक्सी, ब्लॉक्स या CAPTCHA की चिंता किए बिना।
- API-ड्रिवन: URL भेजो, बदले में HTML या स्क्रैप्ड डेटा पाओ।
- स्केल और एंटी-बॉट हैंडलिंग: प्रॉक्सी रोटेशन, JS रेंडरिंग, CAPTCHA सॉल्विंग बिल्ट-इन।
- तुम्हारे कोड के साथ इंटीग्रेशन: Python, Node.js या किसी भी भाषा में।
- प्राइसिंग: फ्री टियर (~1000 API कॉल्स), फिर रिक्वेस्ट के हिसाब से।
कस्टम क्रॉलर्स या स्केल पर भरोसेमंद स्पीड चाहिए हो, तो ये अच्छा विकल्प है।
ParseHub: एडवांस्ड सिलेक्शन वाला विज़ुअल लिंक स्क्रैपर
एक डेस्कटॉप ऐप (Windows, Mac, Linux) है, जिसमें तुम विज़ुअली स्क्रैपिंग प्रोजेक्ट बना सकते हो।
- एडवांस्ड सिलेक्शन और नेविगेशन: क्लिक, लूप, और कंडीशनल एक्सट्रैक्शन—डायनेमिक/हिडन एलिमेंट्स से भी।
- नेस्टेड पेजेज़ हैंडल: कैटेगरी → डिटेल पेज → और लिंक एक्सट्रैक्शन।
- CSV, Excel, JSON एक्सपोर्ट: पेड प्लान्स में क्लाउड रन और API एक्सेस।
- फ्री प्लान: 5 प्रोजेक्ट्स, प्रति रन 200 पेज तक।
मार्केटर्स और रिसर्चर्स के लिए पसंदीदा, जिन्हें बिना कोड के पावर चाहिए।
Scrapy: डेवलपर्स के लिए Python लिंक एक्सट्रैक्टर
Python डेवलपर्स के लिए “गोल्ड स्टैंडर्ड” है, जिन्हें पूरा कंट्रोल चाहिए।
- कोड-फर्स्ट: कस्टम spiders बनाकर किसी भी स्केल पर क्रॉल और लिंक एक्सट्रैक्ट।
- डिस्ट्रिब्यूटेड क्रॉलिंग: एफिशिएंट, असिंक्रोनस और बेहद कस्टमाइज़ेबल।
- CSV/JSON/XML/Database में एक्सपोर्ट: आउटपुट पूरी तरह तुम्हारे कंट्रोल में।
- ओपन-सोर्स और फ्री: लेकिन एनवायरनमेंट तुम्हें खुद मैनेज करना होगा।
अगर तुम Python में सहज हो, तो Scrapy जितना ताकतवर विकल्प कम ही है।
Diffbot: स्ट्रक्चर्ड डेटा के लिए AI-पावर्ड लिंक स्क्रैपर
वेब स्क्रैपिंग का “AI ब्रेन” है। ये पेज को समझकर बिना मैन्युअल सेटअप के स्ट्रक्चर्ड डेटा (लिंक्स सहित) लौटाता है।
- ऑटोमैटिक कंटेंट रिकग्निशन: URL दो, स्ट्रक्चर्ड डेटा पाओ (आर्टिकल्स, प्रोडक्ट्स, लिंक्स आदि)।
- Crawlbot और Knowledge Graph: पूरी साइट क्रॉल करो या उनके बड़े वेब इंडेक्स को क्वेरी करो।
- API-ड्रिवन: BI टूल्स या डेटा पाइपलाइन में इंटीग्रेट करो।
- एंटरप्राइज़ प्राइसिंग: लगभग $299/माह से—लेकिन क्वालिटी भी उसी लेवल की।
उन एंटरप्राइज़ के लिए बेस्ट जो स्क्रैपर्स मैनेज किए बिना साफ-सुथरा स्ट्रक्चर्ड डेटा चाहते हैं।
Cheerio: Node.js के लिए हल्का-फुल्का लिंक स्क्रैपर
Node.js के लिए एक तेज़, jQuery-जैसा HTML पार्सर है।
- बहुत तेज़: मिलीसेकंड्स में HTML पार्स।
- फैमिलियर सिंटैक्स: jQuery आता है तो Cheerio भी आसान लगेगा।
- स्टैटिक पेजेज़ के लिए बढ़िया: JS रेंडर नहीं करता, लेकिन सर्वर-रेंडर्ड कंटेंट के लिए परफेक्ट।
- ओपन-सोर्स और फ्री: रिक्वेस्ट्स के लिए axios या fetch के साथ इस्तेमाल करो।
डेवलपर्स के लिए अच्छा जो स्पीड और सादगी के साथ कस्टम स्क्रिप्ट बनाना चाहते हैं।
Puppeteer: एडवांस्ड लिंक स्क्रैपिंग के लिए ब्राउज़र ऑटोमेशन
एक Node.js लाइब्रेरी है जो headless मोड में Chrome कंट्रोल करती है।
- फुल ब्राउज़र ऑटोमेशन: पेज लोड, क्लिक, स्क्रॉल—सब कुछ रियल यूज़र जैसा।
- डायनेमिक कंटेंट और लॉगिन्स: JavaScript-हेवी साइट्स या कॉम्प्लेक्स वर्कफ़्लो के लिए बढ़िया।
- फाइन कंट्रोल: एलिमेंट्स का इंतज़ार, स्क्रीनशॉट्स, नेटवर्क रिक्वेस्ट इंटरसेप्ट।
- ओपन-सोर्स और फ्री: लेकिन रिसोर्स-इंटेंसिव और हल्के टूल्स से धीमा।
जब साइट बेसिक स्क्रैपर्स के साथ “कोऑपरेट” न करे, तब Puppeteer काम आता है।
एक नज़र में तुलना: आपके लिए कौन-सा लिंक एक्सट्रैक्टर सही है?
यहाँ 12 टूल्स की क्विक तुलना है:
| Tool | Best For | Bulk & Subpage Support | Data Export Options | Pricing |
|---|---|---|---|---|
| Thunderbit | बिना कोडिंग वाले, बिज़नेस | हाँ (AI, मल्टी-लेवल) | Excel, CSV, Sheets, Notion, Airtable | फ्री ट्रायल, ~$9/माह से |
| Octoparse | नो-कोड यूज़र्स, एनालिस्ट्स | हाँ | CSV, Excel, JSON, क्लाउड स्टोरेज | फ्री टियर, ~$75/माह |
| Apify | सेमी-टेक, डेवलपर्स | हाँ | CSV, JSON, API के जरिए Sheets | फ्री क्रेडिट्स, यूज़ेज-बेस्ड |
| Bright Data | एंटरप्राइज़ | हाँ (हाई वॉल्यूम) | CSV, JSON, NDJSON via API | ~$350/100k पेज |
| WebHarvy | बिना कोडिंग वाले, डेस्कटॉप | हाँ | Excel, CSV, JSON, XML, SQL | पेड लाइसेंस |
| Web Scraper Extension | कोई भी, क्विक/फ्री | हाँ | CSV, XLSX | फ्री, ओपन-सोर्स |
| ScraperAPI | डेवलपर्स, API यूज़र्स | हाँ | JSON (HTML via API) | फ्री 1k req, पेड टियर्स |
| ParseHub | बिना कोडिंग वाले, एडवांस्ड | हाँ | CSV, Excel, JSON, API | फ्री 5 प्रोजेक्ट्स, पेड |
| Scrapy | डेवलपर्स, Python | हाँ | CSV, JSON, XML, DB | फ्री, ओपन-सोर्स |
| Diffbot | एंटरप्राइज़, AI | हाँ (AI क्रॉल) | JSON (API से स्ट्रक्चर्ड डेटा) | ~$299/माह+ |
| Cheerio | डेवलपर्स, Node.js | हाँ (कस्टम कोड) | कस्टम (JSON आदि) | फ्री, ओपन-सोर्स |
| Puppeteer | डेवलपर्स, कॉम्प्लेक्स साइट्स | हाँ (फुल ऑटोमेशन) | कस्टम (स्क्रिप्टेड आउटपुट) | फ्री, ओपन-सोर्स |
अपने बिज़नेस के लिए सही लिंक स्क्रैपर कैसे चुनें
तो चुनना कैसे है? ये रहा मेरा चीट शीट:
- कोडिंग नहीं आती? Thunderbit, Octoparse, ParseHub, WebHarvy या Web Scraper extension से शुरू करो।
- कस्टम वर्कफ़्लो चाहिए? डेवलपर्स के लिए Apify, ScraperAPI या Cheerio बढ़िया हैं।
- एंटरप्राइज़ स्केल चाहिए? Bright Data या Diffbot तुम्हारे लिए बने हैं।
- Python या Node.js डेवलपर हो? Scrapy (Python) या Cheerio/Puppeteer (Node.js) से पूरा कंट्रोल मिलेगा।
- Sheets/Notion में डायरेक्ट एक्सपोर्ट चाहिए? Thunderbit सबसे मजबूत विकल्प है।
टूल को अपनी टेक्निकल कम्फर्ट, डेटा वॉल्यूम और इंटीग्रेशन जरूरतों के हिसाब से चुनो। ज़्यादातर टूल्स फ्री ट्रायल देते हैं—टेस्ट करने से मत हिचको।
2026 में लिंक एक्सट्रैक्शन के लिए Thunderbit की यूनिक वैल्यू
अब एक बार फिर देखो कि Thunderbit को सच में अलग क्या बनाता है:
- AI-पावर्ड सादगी: साधारण अंग्रेज़ी में बताओ—Thunderbit का AI बाकी काम कर देता है।
- मल्टी-लेयर स्क्रैपिंग: मेन पेज से लिंक निकालो, सबपेजेज़ तक जाओ, और और URLs उठाओ—एक ही फ्लो में।
- बल्क इम्पोर्ट और बैच प्रोसेसिंग: सैकड़ों URLs पेस्ट करो, बल्क में लिंक निकालो, और तुरंत स्ट्रक्चर्ड डेटा एक्सपोर्ट करो।
- वर्कफ़्लो इंटीग्रेशन: Google Sheets, Notion, Airtable में डायरेक्ट एक्सपोर्ट या CSV/Excel डाउनलोड।
- ज़ीरो मेंटेनेंस: वेबसाइट बदलती रहे—Thunderbit का AI एडाप्ट करता है, तुम्हें बार-बार स्क्रैपर ठीक नहीं करना पड़ता।
Thunderbit “बस डेटा स्क्रैप करना” और “ऐसा डेटा पाना जिसे तुम तुरंत इस्तेमाल कर सको”—इन दोनों के बीच की दूरी कम करता है। ये वही टूल है जिसकी मुझे सालों पहले जरूरत थी, जब मैं मैन्युअल डेटा कामों में फँसा रहता था।
निष्कर्ष: लिंक स्क्रैपिंग को स्मार्ट बनाइए और वर्कफ़्लो तेज़ कीजिए
वेब डेटा बिज़नेस ग्रोथ का ईंधन है—और सही लिंक एक्सट्रैक्टर तुम्हारा इंजन। चाहे तुम लीड लिस्ट बना रहे हो, कॉम्पिटिटर्स पर नज़र रख रहे हो, या रिसर्च ऑटोमेट कर रहे हो—इस लिस्ट में तुम्हारे लिए सही टूल मौजूद है।
अगर तुम देखना चाहते हो कि मॉडर्न लिंक एक्सट्रैक्शन कैसा होता है, तो । कुछ ही क्लिक में तुम कितना कर सकते हो, ये देखकर सच में सरप्राइज़ हो जाओगे। और अगर Thunderbit तुम्हारे लिए परफेक्ट फिट नहीं है, तो इस लिस्ट के कुछ और टूल्स ट्राय कर लो—आज के टाइम में बोरिंग काम ऑटोमेट करके असली काम पर फोकस करने का इससे बेहतर मौका नहीं।
हैप्पी स्क्रैपिंग—और तुम्हारी लिंक लिस्ट हमेशा साफ, स्ट्रक्चर्ड और एक्शन के लिए तैयार रहे। अगर तुम वेब स्क्रैपिंग में और गहराई से जाना चाहते हो, तो और गाइड्स और टिप्स के लिए देखो।
FAQs
1. लिंक एक्सट्रैक्टर जरूरी क्यों हैं?
जब इंटरनेट ट्रैफिक का बड़ा हिस्सा बॉट्स से आता है और कंपनियाँ आक्रामक तरीके से डेटा स्क्रैप कर रही हैं, तब लिंक एक्सट्रैक्टर वेब के “शोर” को काम की इनसाइट्स में बदलने के लिए जरूरी हैं। ये लीड जनरेशन, कंटेंट एग्रीगेशन, SEO ऑडिट और कॉम्पिटिटर मॉनिटरिंग जैसे काम ऑटोमेट करके बहुत समय और मेहनत बचाते हैं।
2. दूसरे लिंक एक्सट्रैक्टर्स के मुकाबले Thunderbit को खास क्या बनाता है?
Thunderbit AI के जरिए स्क्रैपिंग को बेहद आसान बना देता है—तुम बस साधारण भाषा में लक्ष्य बताओ, बाकी काम ये खुद कर लेता है। इसमें बल्क URL इनपुट, मल्टी-लेयर स्क्रैपिंग, स्मार्ट फील्ड डिटेक्शन और Google Sheets/Notion जैसे प्लेटफ़ॉर्म्स में स्मूद एक्सपोर्ट मिलता है। ये उन बिज़नेस यूज़र्स के लिए आइडियल है जिन्हें बिना टेक्निकल झंझट के पावरफुल रिज़ल्ट चाहिए।
3. क्या डेवलपर्स और कस्टम वर्कफ़्लो के लिए भी लिंक एक्सट्रैक्टर टूल्स हैं?
हाँ। Apify, ScraperAPI, Cheerio, Puppeteer और Scrapy जैसे टूल्स डेवलपर्स के लिए बने हैं। इनमें स्क्रिप्टिंग, API इंटीग्रेशन और फ्लेक्सिबिलिटी मिलती है, जिससे कॉम्प्लेक्स स्क्रैपिंग, बड़े स्केल के जॉब्स और एडवांस्ड ऑटोमेशन संभव होता है।
4. जिनको कोडिंग नहीं आती, उनके लिए कौन-से टूल्स सबसे अच्छे हैं?
Thunderbit, Octoparse, ParseHub, WebHarvy और Web Scraper Chrome extension नॉन-टेक्निकल यूज़र्स के लिए बेहतरीन विकल्प हैं। इनमें विज़ुअल इंटरफ़ेस, प्री-बिल्ट टेम्पलेट्स और AI-ड्रिवन फीचर्स मिलते हैं, जिससे लिंक एक्सट्रैक्शन हर किसी के लिए आसान हो जाता है।
5. अपनी जरूरत के हिसाब से सही लिंक एक्सट्रैक्टर कैसे चुनें?
अपनी टेक्निकल स्किल, डेटा वॉल्यूम और एक्सपोर्ट जरूरतों को देखो। नॉन-कोडर्स Thunderbit या Octoparse चुन सकते हैं, जबकि डेवलपर्स Scrapy या Puppeteer पसंद कर सकते हैं। एंटरप्राइज़ के लिए Bright Data या Diffbot बड़े स्केल पर बेहतर हैं। सबसे अच्छा तरीका है—फ्री ट्रायल से शुरू करो और देखो तुम्हारे लिए क्या फिट बैठता है।