
Picture this: you launch your website, ready to welcome a flood of eager customers, only to discover that half your traffic is… robots. Not the sci-fi kind, but digital crawlers—search engines, AI bots, analytics spiders—all poking around your site, day and night, like a never-ending parade of invisible guests. In 2026, this isn’t just a quirky footnote in your server logs; it’s the new normal. Understanding who (or what) is crawling your site, how often, and why, is now a core part of running any online business.
As someone who’s spent years in SaaS, automation, and AI, I’ve watched web crawling evolve from a behind-the-scenes technical detail into a front-and-center business challenge. The numbers are wild: bots now account for nearly half of all internet traffic, and in some places, they outnumber humans. With the rise of AI-driven crawlers vacuuming up content to train large language models, the stakes have never been higher—for your infrastructure, your budget, and your brand. Let’s dive into the latest web crawling statistics, industry benchmarks, and what it all means for your business in 2026.
Web Crawling in 2026: A Snapshot of the Landscape
Web crawling has hit a whole new level of scale and complexity. Every day, billions of automated requests zip across the internet, made by an ever-growing cast of crawlers. Traditionally, search engine bots like Googlebot and Bingbot were the main players, indexing pages so users could find them in search results. But now, they’re joined by a new generation: AI data crawlers, social media scrapers, analytics bots, and more.
Here’s the big headline: , and in some regions, bot traffic even exceeds human traffic. On Cloudflare’s network, . The kicker? This surge isn’t just from search engines—it’s increasingly driven by AI crawlers collecting data to feed the latest chatbots and generative tools.
The landscape is more diverse than ever:
- Good bots: Search indexers, uptime monitors, legitimate data scrapers.
- Bad bots: Spam, hacking, unauthorized scraping.
- AI crawlers: The new kids on the block, gathering content for AI training and real-time answers.
AI crawlers often behave differently from their search engine cousins. They might retrieve entire page contents for semantic analysis, not just index keywords, and they tend to operate at high volumes—sometimes flooding sites with millions of requests in a matter of days. The result? , blending traditional indexing with AI’s insatiable appetite for data.
Key Web Crawling Statistics Every Business Should Know
Let’s get into the numbers that are shaping the web in 2026. These stats aren’t just for trivia night—they’re the benchmarks that should inform your infrastructure, your content strategy, and your bottom line.
Bots vs. Humans: Who’s Winning the Traffic War?
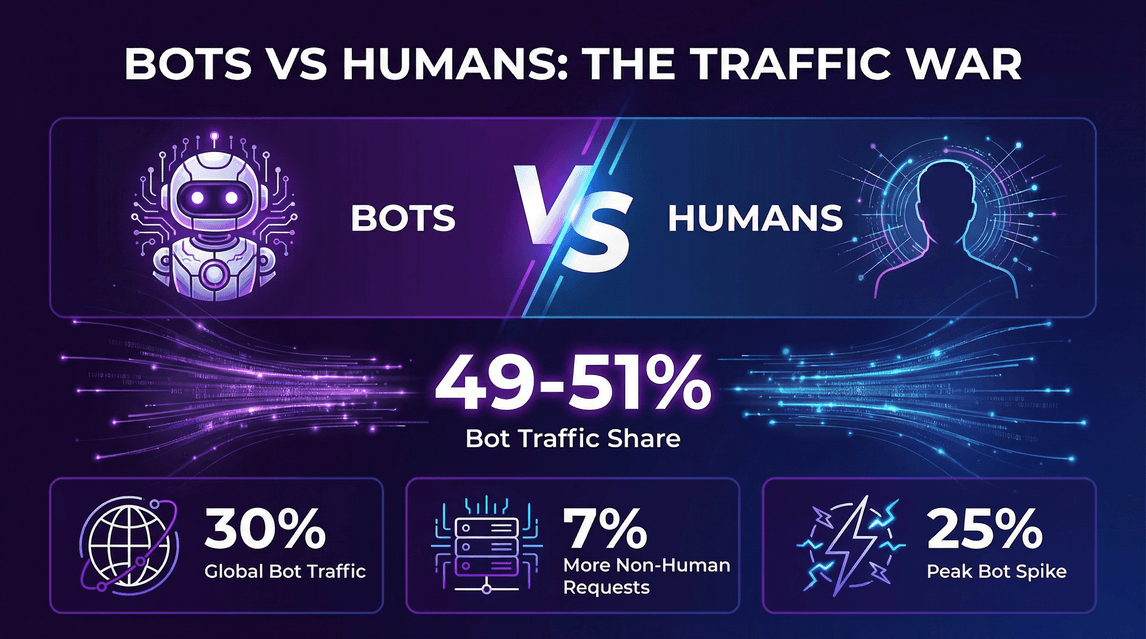
- 49–51% of all internet traffic is now driven by bots, with automated requests on par with or outpacing human visitors ().
- Cloudflare data: .
- Non-human requests to HTML pages were ~7% higher than human requests ().
- At certain points, bot traffic .
The AI Crawler Surge

- AI-oriented bots made up 4.2% of all HTML page requests in 2025 ().
- OpenAI’s GPTBot: Jumped from zero to , growing 305% in one year.
- Perplexity.ai’s bot: .
- Googlebot: , accounting for about 50% of all search/AI crawler requests.
Crawler Traffic in Context
Here’s a real-world example from a :
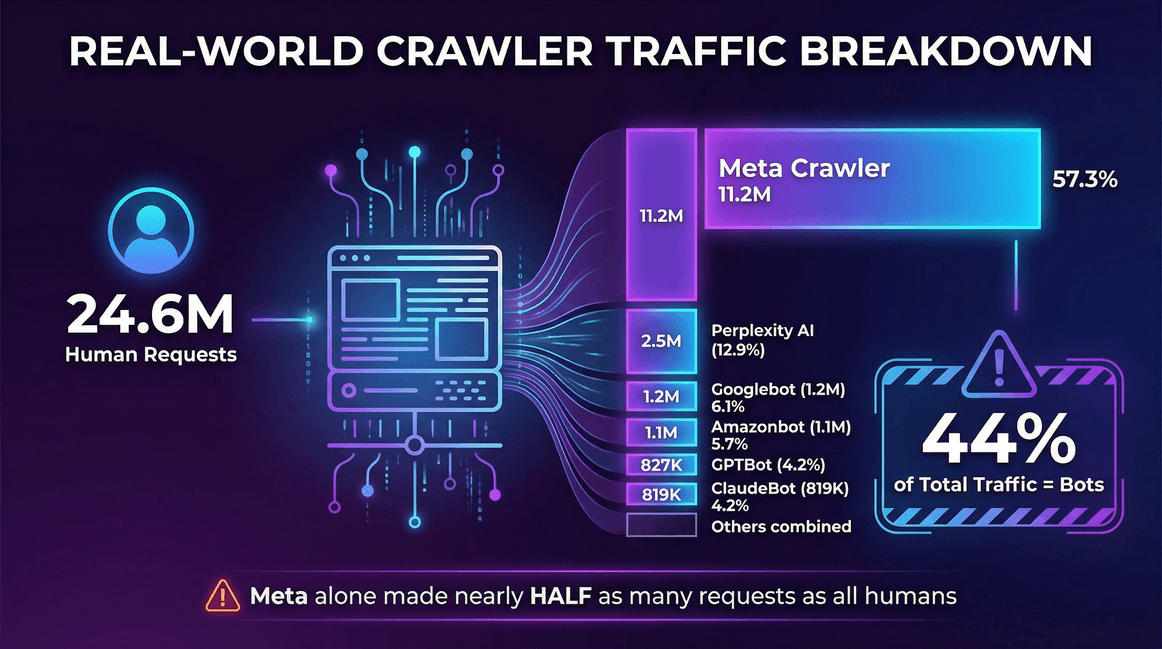
| Traffic Source | Requests (Monthly) | Share of Crawlers |
|---|---|---|
| Real Users (human) | 24,647,904 | -- |
| Meta Crawler (Facebook) | 11,175,701 | 57.3% |
| Perplexity AI | 2,512,747 | 12.9% |
| Googlebot | 1,180,737 | 6.1% |
| Amazonbot | 1,120,382 | 5.7% |
| OpenAI GPTBot | 827,204 | 4.2% |
| ClaudeBot (Anthropic) | 819,256 | 4.2% |
| Bingbot | 599,752 | 3.1% |
| ChatGPT-User (OpenAI) | 557,511 | 2.9% |
| Ahrefs Crawler | 449,161 | 2.3% |
| ByteDance Spider | 267,393 | 1.4% |
On this site, bots made up 44% of total traffic—and Meta’s crawler alone made nearly half as many requests as all real users combined.
The Big Picture
- Crawler traffic (search + AI bots) grew by 18% between May 2024 and May 2025 for a consistent set of sites ().
- LLM training bots comprised nearly 80% of all “bot” traffic on some major CDNs ().
- Cloudflare’s network saw about 50 billion crawler requests per day from AI bots alone by late 2025 ().
The Rise of AI Crawlers: How AI is Changing Web Crawling
Let’s talk about the elephant (or should I say, the robot) in the room: AI crawlers. These bots aren’t just indexing your site for search—they’re gobbling up content to train large language models or provide instant AI-powered answers. And they’re doing it at a scale that would make even the most ambitious search engine blush.
What’s Driving the AI Crawler Boom?
- Data-hungry AI models: Modern LLMs need enormous, diverse datasets. The web is their buffet, and your content is on the menu.
- Training vs. Real-time Answers: , not just answering live queries.
- New crawl patterns: AI bots can hit sites in massive bursts, sometimes crawling millions of pages in days, especially when retraining or updating models.
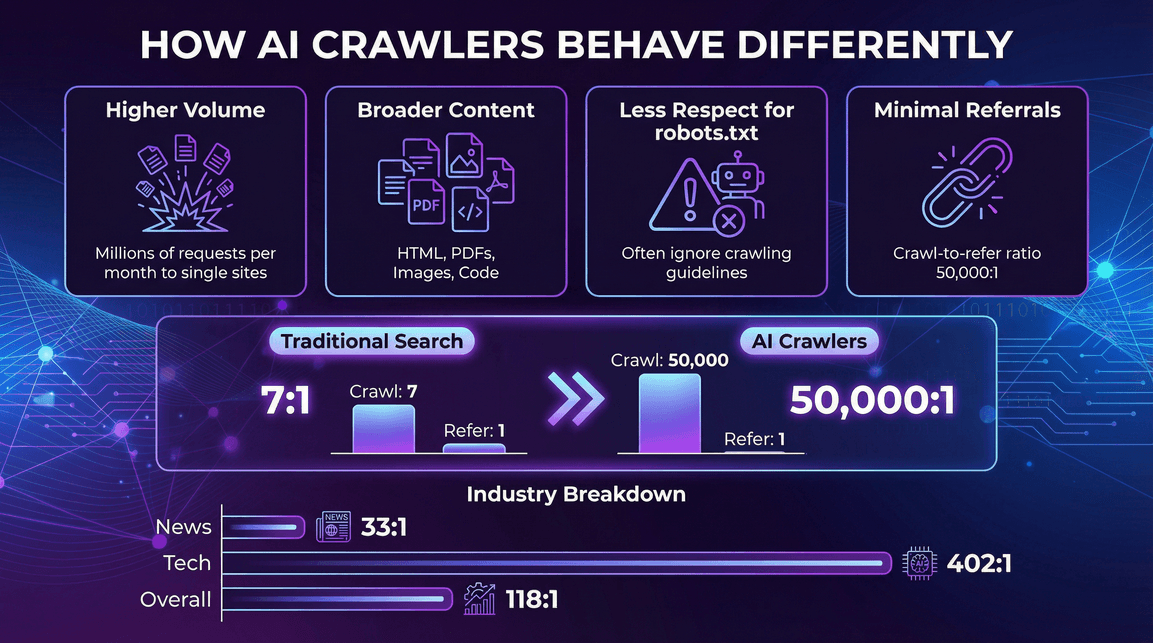
How AI Crawlers Behave Differently
- Higher volume per crawler: A single AI bot can generate millions of requests per month to a single site ().
- Broader content types: Not just HTML—PDFs, images, code, you name it.
- Less respect for robots.txt: Some AI crawlers ignore or only partially honor crawling guidelines ().
- Minimal referral traffic: Unlike search engines, AI crawlers rarely send users back to your site. .
AI Crawler Traffic by Industry
Not all industries get crawled equally. For example:
- News & Publications: Heavy AI crawler activity, but slightly better referral ratios (e.g., Perplexity’s crawl-to-refer ratio is 33:1 on news sites, compared to 118:1 overall) ().
- Technology & Electronics: GPTBot and Amazonbot dominate, with crawl-to-refer ratios still high (e.g., OpenAI’s ratio is 402:1 in tech) ().
- Finance, Academia, and Others: Each sector has its own mix of bots and referral rates, but the trend is clear: AI crawlers are everywhere, and most aren’t sending much traffic back.
Top Web Crawlers in 2026: Who’s Crawling the Web the Most?
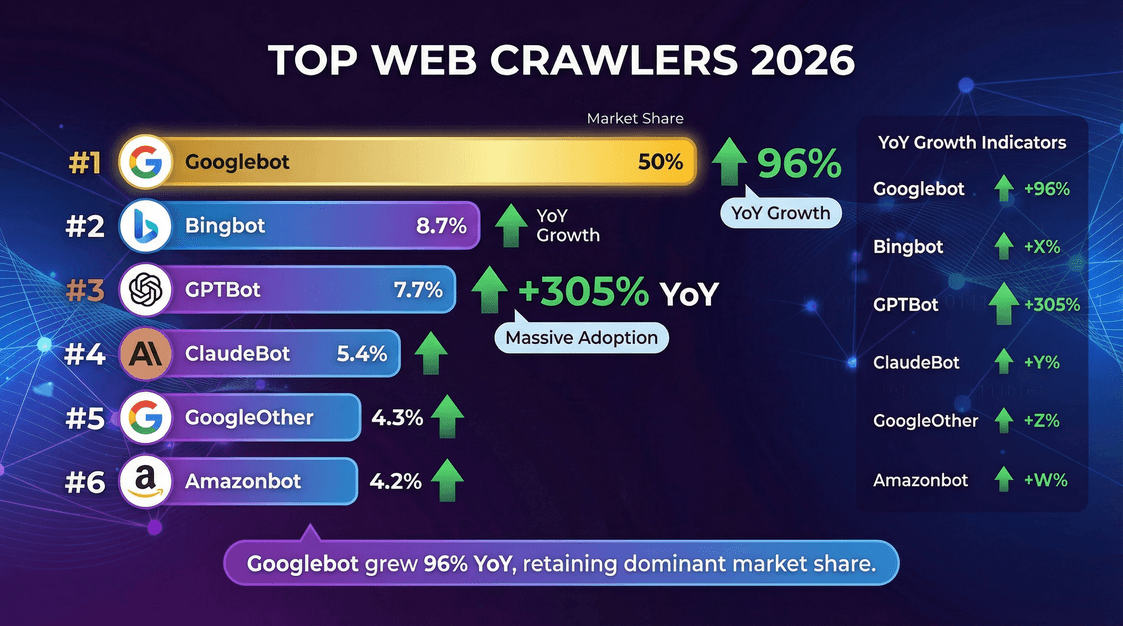
Who are the main characters in this crawling drama? Here’s the leaderboard, based on :
| Crawler (Owner) | % of Crawls (May 2025) | YoY Request Growth |
|---|---|---|
| Googlebot (Google) | 50.0% | +96% |
| Bingbot (Microsoft) | 8.7% | +2% |
| GPTBot (OpenAI) | 7.7% | +305% |
| ClaudeBot (Anthropic) | 5.4% | –46% |
| GoogleOther (Google) | 4.3% | +14% |
| Amazonbot (Amazon) | 4.2% | –35% |
| Googlebot-Image (Google) | 3.3% | –13% |
| Bytespider (ByteDance) | 2.9% | –85% |
| YandexBot (Yandex) | 2.2% | –10% |
| ChatGPT-User (OpenAI) | 1.3% | +2825% |
| Applebot (Apple) | 1.2% | –26% |
| PerplexityBot | 0.2% | +157,490% |
A few key takeaways:
- Googlebot is still the king, responsible for half of all crawling activity.
- GPTBot and Meta’s crawler are the fastest risers, with GPTBot’s share tripling in a year.
- PerplexityBot and ChatGPT-User agents are small in total share but growing at breakneck speed.
Web Crawling Benchmarks: Crawl Rates, Throughput, and Performance
 Web crawling isn’t just about volume—it’s about speed and efficiency. Here’s what you need to know about crawl rates and performance benchmarks in 2026.
Web crawling isn’t just about volume—it’s about speed and efficiency. Here’s what you need to know about crawl rates and performance benchmarks in 2026.
Crawl Rate: How Fast Are Crawlers Fetching Pages?
- Crawl rate is typically measured in pages per second (or requests per second) ().
- Threads/parallel connections: More threads = higher potential crawl rate. For example, 200 threads with a 2-second delay per site can yield about 100 pages per second ().
- Real-world benchmarks: 100–200 pages per second is typical for a well-optimized crawler on a decent server cluster.
- Google and Bing: Likely fetch thousands of pages per second globally, distributed across millions of sites.
Factors Influencing Crawl Rate
- Number of threads/parallel fetchers: More threads, more speed (until you hit other bottlenecks).
- Number of active sites: Crawling multiple domains in parallel multiplies throughput.
- Crawl delay/wait time: Longer delays = slower crawl rate.
- Resource limits: Bandwidth, CPU, database write speed can all be bottlenecks.
- Target site performance: Slow or rate-limited sites drag down crawl speed.
For example, if your crawler has 100 threads and a 1-second delay per site, you might fetch about 100 pages per second—unless your database can’t keep up, in which case you’ll be bottlenecked by storage, not network.
The Business Impact of Web Crawling: Costs, Opportunities, and Risks
Web crawling isn’t just a technical curiosity—it’s a business issue, with real costs and opportunities.
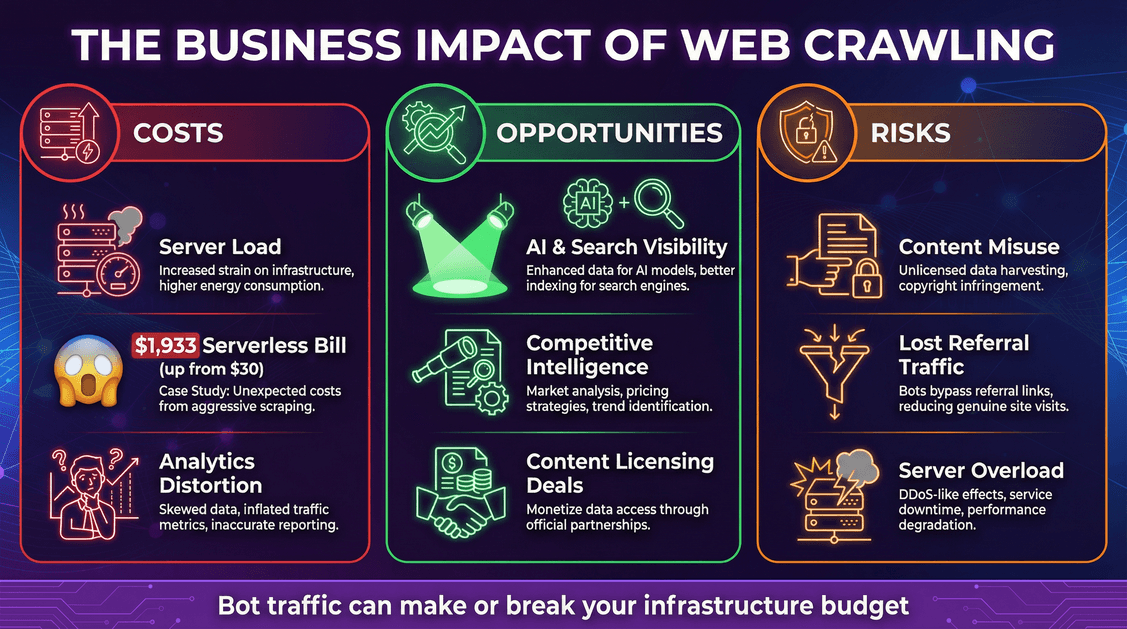
Costs: Infrastructure and Unexpected Bills
- Server load: Every bot request consumes CPU, memory, and bandwidth.
- Cloud bills: If you’re on a pay-per-use model (like serverless), bots can rack up serious charges. One developer saw .
- Analytics distortion: Bots can skew your web analytics, making it harder to interpret real user behavior.
Opportunities: Visibility and Data Leverage
- AI and search visibility: Being included in AI training data or search indexes can boost your brand’s reach ().
- Competitive intelligence: Businesses use crawlers for market research, price monitoring, and more.
- Monetization: Some publishers are now .
Risks: Content Misuse and Lost Traffic
- Content misuse: AI crawlers can absorb your content into their models, sometimes without clear permission or compensation.
- Lost referral traffic: AI answers may satisfy users without sending them to your site, leading to “disintermediation.”
- Security and downtime: Aggressive crawlers can overload your servers, causing slowdowns or outages.
Managing Web Crawler Traffic: Best Practices
So, how do you keep the bots from eating your lunch (or your cloud budget)?
1. Optimize Your robots.txt
- Use
robots.txtto allow or disallow specific bots. Most reputable crawlers (like Googlebot) honor it, but many AI bots may not (). - As of mid-2025, about 14% of top sites had started adding explicit rules for AI bots ().
2. Use Bot Management Tools
- Web Application Firewalls (WAFs) and bot management services can block or rate-limit suspicious traffic.
- Cloudflare and other providers offer bot mitigation features and even “AI Audit” tools for content creators ().
3. Implement Rate Limiting and Caching
- Rate-limit rapid-fire requests from a single bot.
- Serve cached content to bots whenever possible—don’t let them trigger expensive serverless functions or database queries ().
4. Monitor and Analyze Bot Traffic
- Keep an eye on your server logs. Know which bots are hitting you, how often, and when.
- Set up alerts for unusual traffic spikes.
5. Stay Ahead of Emerging Standards
- Watch for new meta tags or HTTP headers for AI usage permissions (e.g.,
<meta name="ai:allow" content="no">). - Keep up with industry initiatives like ) and payment protocols like .
Web Crawling Trends to Watch in 2026 and Beyond
The web crawling landscape is evolving fast. Here’s what I’m watching (and what you should, too):
- AI-driven crawling is only going up: Expect even more AI bots, crawling more content types (text, images, video).
- Content licensing and payment standards: The “Wild West” is giving way to and .
- Regulation is coming: Expect more legal clarity around what bots can and can’t do, especially for AI training data ().
- Technical standards for content usage: Look for new meta tags, robots.txt extensions, and machine-readable bot declarations.
- Publisher-AI collaboration: Instead of being passive targets, more publishers will negotiate structured data feeds or APIs for AI companies.
Conclusion: What These Web Crawling Statistics Mean for Your Business
Here’s the bottom line: web crawling is a dominant force in 2026, and it’s not slowing down. Automated bots—especially AI crawlers—are now responsible for a huge chunk of your traffic, and their impact on your infrastructure, budget, and content strategy is only growing.
What should you do?
- Expect heavy bot traffic: Plan your infrastructure, budgeting, and monitoring accordingly.
- Know your crawlers: Not all bots are created equal—tailor your approach to each.
- Monitor your metrics: Track bot traffic just like you track human visitors.
- Protect your content and your wallet: Use technical controls, legal agreements, and emerging standards.
- Leverage the upside: Being included in AI and search indexes can boost your brand—just make sure you’re getting value in return.
- Stay informed and adapt: The crawling landscape is shifting fast. Keep an eye on new standards, regulations, and business models.
As someone who’s spent years building automation and AI tools (and now at ), I can tell you: the businesses that thrive in this new era are the ones that treat web crawling as a strategic priority—not just a technical nuisance. Whether you’re in sales, ecommerce, marketing, or real estate, understanding web crawling statistics and industry benchmarks is now table stakes.
So, next time you check your server logs and see a parade of bots, don’t just sigh and move on. Use the data. Benchmark your site. Adjust your tactics. And remember: in the age of AI, the bots aren’t just coming—they’re already here. Make them work for you, not the other way around.
Stay vigilant, stay curious, and may your server logs be ever in your favor.
Want to learn more about web scraping, automation, and AI-powered productivity? Check out for deep dives, how-tos, and the latest trends. And if you’re ready to take control of your own data, try the for AI-powered web scraping—no code, no hassle, just results.
Citations and Further Reading: