數據在現代就像黃金一樣珍貴,但說真的,沒有人想把時間浪費在一堆雜亂無章的資料裡。來到 2025 年,數據爬取已經是企業團隊把網路龐大資訊轉化成實用洞察的首選利器,不再只是製造雜訊。我親身體驗過,聰明的爬取策略真的能徹底翻轉團隊的工作效率——不管你是要開發新客戶、盯緊競爭對手,還是想讓自家價格永遠領先一步。但重點是:數據爬取絕對不只是「抓資料」這麼簡單,還要確保資料乾淨、合法,並且跟你的業務目標緊密連結。
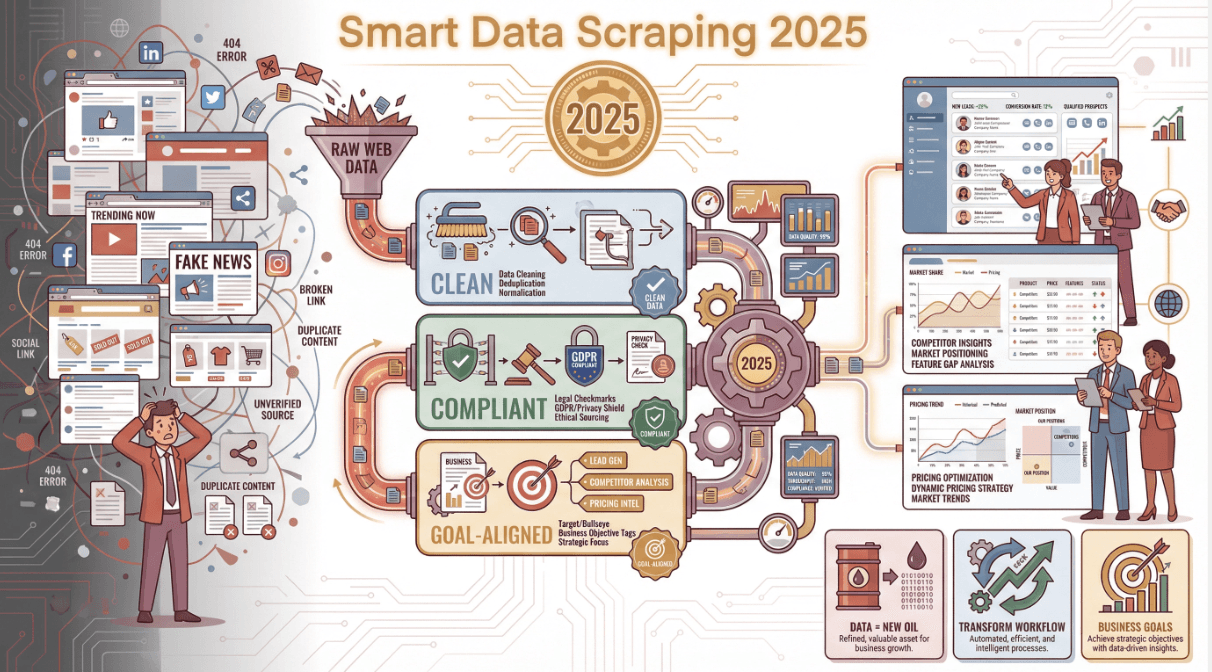
如果你已經受夠了手動複製貼上的無聊苦差事,或是常常發現爬下來的表格一堆錯誤、重複資料,那這篇指南絕對適合你。我會分享自己一路走來的實戰經驗(有些還是踩過雷才學到的),教你怎麼避開常見陷阱,並介紹像 這類工具,如何讓高品質數據爬取變得人人都能輕鬆上手——就算你完全不會寫程式也沒問題。
為什麼數據爬取對現代企業這麼關鍵?
先來看整體趨勢:為什麼數據爬取會成為現代企業團隊的必備武器?數字最有說服力。全球網頁爬蟲軟體市場在 ,而且每年成長超過 40%。將近 都靠公開網路數據做市場情報分析,約 都在用某種數據擷取工具。事實上,2023 年幾乎一半的網路流量都是機器人——也就是爬蟲和抓取工具,而不是人類。
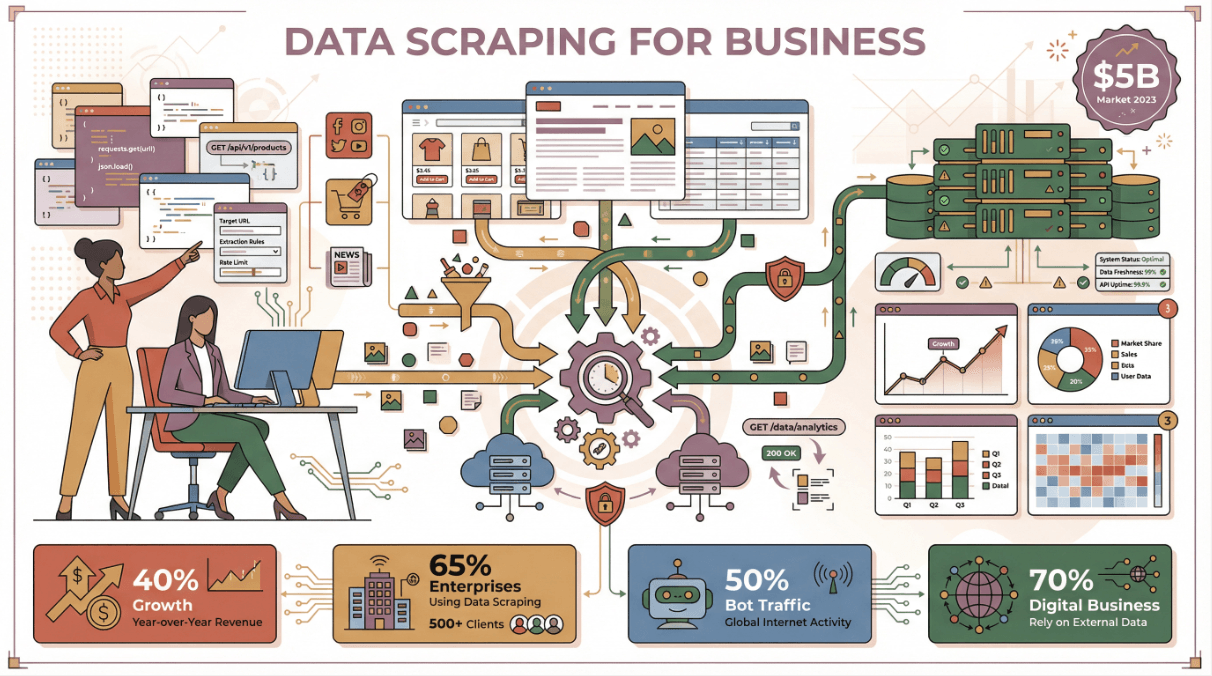
但重點不只在數量,真正的價值在於你怎麼用這些數據:
| 部門 | 爬取應用 | 業務影響(ROI) |
|---|---|---|
| 銷售與行銷 | 從名錄/社群媒體抓取新客戶 | 快速補足銷售名單,潛在客戶開發時間減少 30–40% (scrapingapi.ai) |
| 電商營運 | 監控競爭對手價格/商品上架 | 實現動態定價,提升銷售(John Lewis 銷售額提升 4% browsercat.com) |
| 市場研究 | 匯整評論、評分、趨勢 | 比傳統調查更快掌握新趨勢與消費者聲音 |
| 財務與策略 | 收集新聞、公告、公開數據 | 為決策者提供即時情報 |
正確運用數據爬取,不只是省下大把時間,更能讓決策又快又精準。像 John Lewis、ASOS 這些企業,靠自動化競品監控和數據驅動行銷,真的帶來營收成長()。
不同場景下的數據爬取實戰技巧
數據爬取沒有一套通用公式,最適合的方法要看你的業務目標——不管是市場調查、開發潛在客戶,還是競爭情報。以下針對不同情境拆解實用做法。
市場研究:全面掌握趨勢
市場研究講求大範圍觀察,所以多元來源整合很重要:產品評論、社群媒體、論壇、價格頁面都要納入。例如時尚品牌會同時爬取社群討論和零售網站,搶先發現新潮流()。
市場研究爬取小技巧:
- 來源多元化: 不要只抓一個網站,評論、評分、論壇討論都要收集。
- 結構化資料: 收集元資料(像日期、評分、分類),方便後續分析。
- 定期追蹤: 安排每週或每月自動爬取,隨時掌握趨勢變化。
案例: 有美妝品牌靠爬取社群和美妝電商,發現「玻尿酸」討論度暴增,搶先競爭對手調整行銷策略。
銷售開發:精準拓展潛在客戶
對銷售團隊來說,數據爬取能大幅提升名單質量和效率。重點是鎖定可靠、公開來源(像商業名錄、LinkedIn、協會名單),並重視資料品質。
實戰建議:
- 驗證聯絡資訊: 用郵件/電話驗證工具,去除重複,檢查格式。
- 合規優先: 只抓公開、專業資料。避免未經授權蒐集個人資訊()。
- 小規模測試: 先小量爬取,檢查資料品質再擴大規模。
常見陷阱: 有公司沒設防護就抓個資,結果違規又白忙一場()。記得:要聰明又負責任地爬取。
競爭情報:即時掌握對手動態
想知道競爭對手在搞什麼?數據爬取能幫你追蹤價格、庫存、新品上市,甚至徵才動態。關鍵在於明確定義追蹤項目(像 SKU、價格、評論、職缺),並自動化子頁面導航,取得完整資訊。
實戰建議:
- 自動爬取子頁面: 用能自動點擊連結的工具(像 Thunderbit 的「爬取子頁面」功能),深入抓取商品或職缺詳情。
- 定期檢查: 價格建議每日,部落格每週追蹤。
- 匯出比對: 保存歷史數據,方便趨勢分析和快速反應。
專家建議: 採用瀏覽器型爬蟲(像 Thunderbit Chrome 擴充功能),模擬真實用戶行為,降低被封鎖風險()。
避開常見陷阱,確保數據品質
再好的爬取計畫,遇到這些經典問題也會出錯。以下教你怎麼避開,讓數據更乾淨。
應對動態網頁
現在的網站很多都用 JavaScript、無限滾動、或「載入更多」按鈕。一般爬蟲常常只能抓到表面資料。
解決方法:
- 選用瀏覽器型或 AI 驅動的爬蟲,能執行 JavaScript 並等待內容載入()。
- 檢查有沒有隱藏 API,有時資料其實來自背景 API,可以直接調用。
- 結果 sanity check: 預期 100 筆卻只抓到 10 筆,代表有問題。
Thunderbit 就能像真實瀏覽器一樣載入頁面,自動處理動態內容。
應對反爬蟲機制
網站越來越會防堵機器人——像驗證碼、IP 封鎖、流量限制。如果爬蟲突然失效,通常就是這些原因。
實戰建議:
- 調整請求頻率: 放慢速度、隨機間隔,避免太頻繁。
- 敏感網站用瀏覽器模式: Thunderbit 的瀏覽器模式能模擬真實瀏覽,降低被擋風險。
- 檢查 robots.txt 與服務條款: 如果網站明確禁止爬取,請三思或主動聯繫()。
確保數據完整與正確
錯誤的數據比沒有數據還糟。不要盲信爬蟲,務必驗證、清理、檢查。
檢查清單:
- 格式驗證: 電子郵件正確嗎?價格是數字嗎?日期一致嗎?
- 去除重複: 依唯一 ID 或網址去重。
- 處理缺漏: 標記空值、補齊或重新爬取。
- 定期抽查: 每次執行都隨機檢查一部分,發現異常及早修正。
數據品質不佳每年可能讓企業損失 ,千萬別省略這一步。
Thunderbit 如何讓企業團隊輕鬆搞定數據爬取
接下來聊聊怎麼讓這一切變簡單。Thunderbit 推出的 ,就是為了讓非技術用戶也能輕鬆搞定數據爬取。Thunderbit 怎麼改變遊戲規則(雖然不是「顛覆者」,但你懂的):
Thunderbit 的 AI 自動化流程
- AI 智能欄位建議: 進入任何網頁,點「AI 建議欄位」,Thunderbit 會自動分析頁面,推薦最佳擷取欄位——完全免設定、免寫程式。
- 兩步完成爬取: 欄位可自訂,按下「開始爬取」就搞定,Thunderbit 會自動抓取所有資料,處理分頁,甚至能深入子頁面。
- 即時匯出: 一鍵把數據匯出到 Excel、Google Sheets、Airtable 或 Notion,完全不用手動整理。
我親眼看過沒技術背景的同事,從「完全不會」到「五分鐘內抓到 500 筆競品價格」。
多來源、多語言數據爬取
Thunderbit 不只支援網站,還能從 PDF、圖片、文件中擷取資料——內建 OCR 與 AI 技術。支援 34 種語言,不管是國際團隊還是跨國數據都能輕鬆搞定。
案例: 需要抓日本供應商的產品型錄?Thunderbit 可即時擷取並翻譯資料,直接結構化給你分析。
數據清理與準備:讓原始資料變成商業價值
爬取只是第一步,原始數據通常很亂——重複、格式錯亂、缺漏一堆。真正的價值在於清理、標註、結構化,這樣才能直接用於業務決策。
自動化數據標註與分類
Thunderbit 的 Field AI Prompt 讓你自動完成大量清理工作:
- 產品分類: 例如「根據名稱標註為電子產品、服飾或家居」。
- 欄位翻譯: 一鍵將擷取內容翻譯成英文(或 34 種語言任選)。
- 格式驗證: 擷取時自動標準化日期、價格、電話等格式。
數據清理步驟檢查表:
- 檢查明顯錯誤(欄位錯位、編碼問題)。
- 去除重複資料。
- 格式統一(日期、價格、分類)。
- 處理缺漏值(補齊、標記或刪除)。
- 依業務規則驗證(如價格區間)。
- 如有需要,補充產業、地區等資訊。
- 記錄清理流程,確保透明。
自動化這些步驟,讓雜亂的原始資料變成可直接決策的數據集,省下大把人工整理時間。
法律與道德:數據爬取不可忽視的底線
嚴肅一點:能爬不代表就該爬——尤其要顧及隱私、版權與合規。
你必須知道的重點法規
- GDPR/CCPA: 只要涉及可識別個人資訊,必須有合法依據。建議只抓公開、專業資料,避免敏感資訊。
- 服務條款: 很多網站明文禁止爬取,務必事先查閱。
- 版權: 資料本身不受版權保護,但呈現方式可能有版權。千萬別未經授權抓取並重製完整文章或創意內容。
實戰建議:
- 只收集必要資料(資料最小化)。
- 尊重 robots.txt 與網站規範。
- 清楚標註數據來源。
- 若含個資,務必匿名化或加強保護。
- 建立內部政策,讓團隊成員都清楚規則。
有疑慮時,主動詢問或用官方 API。寧可少抓一點,也不要惹上法律麻煩。
持續優化:監控與調整數據爬取專案
網站會變、業務需求也會變,今天有效的方法明天可能就失效。把數據爬取當成持續優化的流程:
- 監控數據品質: 追蹤完整性、正確性與即時性。若突然抓到的資料變少或異常,設置警示。
- 連結業務成果: 衡量數據對關鍵指標(像潛在客戶、成交、價格優勢)的實際影響。
- 優化頻率: 不要過度頻繁爬取,減輕網站與自身系統負擔。
- 保持彈性: 網站結構變動時,隨時調整爬蟲。記錄有效與無效做法,方便下次快速修正。
頂尖團隊把爬取當成數據管道,而不是一次性專案。持續優化,價值自然倍增。
結論:數據爬取成功的關鍵要點
重點整理如下:
- 明確業務目標: 不要為爬而爬,先想清楚要解決什麼問題。
- 選對工具: AI 驅動的爬蟲(像 )讓人人都能輕鬆取得高品質數據。
- 策略因情境而異: 市場調查、銷售、競爭情報各有不同做法。
- 重視數據品質: 驗證、清理、結構化後再用於決策。
- 合規與道德優先: 尊重隱私、版權與網站規範。
- 持續優化: 監控、調整、隨時應變。
準備好讓數據爬取成為你的團隊秘密武器了嗎?,體驗如何輕鬆把網路變成你的商業情報引擎。想學更多,歡迎逛逛 ,獲取更多實用技巧、教學和真實案例。
常見問答
1. 什麼是數據爬取?為什麼對企業團隊重要?
數據爬取是自動從網站、PDF 或文件中擷取資訊的技術。對企業團隊來說,它能把公開網路數據轉化為銷售、行銷、營運的決策依據,大幅提升效率和洞察力。
2. 數據爬取最常見的錯誤有哪些?
常見問題包括漏抓動態內容(像無限滾動頁)、忽略反爬蟲措施(導致被封鎖)、未驗證或清理數據(產生重複或錯誤)。建議選用能處理動態網站並內建驗證功能的工具。
3. Thunderbit 如何讓非技術用戶也能輕鬆爬取?
Thunderbit 利用 AI 自動建議欄位、處理動態內容、爬取子頁面。只需兩步就能擷取結構化數據並匯出到 Excel、Google Sheets、Airtable 或 Notion,完全不用寫程式。
4. 如何確保數據爬取合法且合乎道德?
只抓公開、非敏感資料,遵守隱私法(像 GDPR/CCPA),並查閱網站服務條款。避免未經授權蒐集個資,優先用官方 API。
5. 爬取後如何讓數據更有用?
清理、去重、結構化數據。可用 AI 工具(像 Thunderbit 的 Field AI Prompt)自動標註、翻譯、分類欄位。務必在業務決策前驗證結果。
延伸閱讀