

你是否曾被主管交付一疊 PDF 檔案,要求你把裡面的資料完整、精準地擷取出來?如果全靠人工處理,肯定得加班到很晚。從 PDF 擷取資料其實相當麻煩,因為和網頁資料不同,PDF 的格式常常不一致。有些 PDF 是表格,有些則只是圖片或掃描文件,直接擷取起來非常棘手。
使用 AI 從任何網站擷取資料 Get Started Free
舉例來說,如果你想從 PDF 中提取電子郵件地址,有些可能是圖片格式,有些則藏在複雜的字元編碼裡。像這個例子:{john.doe,jane.doe}@example.com。它其實代表兩個不同的電子郵件:john.doe@example.com 和 jane.doe@example.com。還有 {first.last}@example.com,你需要把「first」和「last」分別替換成作者的名字與姓氏。傳統的文字辨識工具在這種情況下根本派不上用場。這時候,一個好用的 PDF 爬蟲 就能幫上大忙。
什麼是 PDF 爬蟲
PDF 爬蟲 是一種很實用的工具,能自動從 PDF 檔案中擷取資料,把表格和文字等內容轉成你需要的格式,例如 Excel、CSV 或 JSON。簡單來說,它能把原本繁瑣的複製貼上工作,變成一鍵完成的流程。
想像一下,你手上有一大疊發票、合約、學術論文,甚至是掃描版 PDF,如果要人工逐一轉錄,可能得花上好幾個小時。有了 PDF 爬蟲,你只要上傳檔案,幾秒鐘內就能擷取出資料,既省時省力,也能維持準確度。從此告別手動輸入的麻煩。
如果你的 PDF 內包含表格、連結、圖片等不同資料類型,就交給 AI PDF 爬蟲 處理吧。AI PDF 爬蟲會使用大型語言模型(LLM),可同時處理文字、圖片與表格,效果相當出色。
AI PDF 爬蟲 的優勢不只在於效率和準確度;它的適應性也讓人更省心。無論是掃描文件、圖片,還是多語言 PDF,AI 都能輕鬆應對。市面上有許多優秀的 AI 工具,例如 Thunderbit、ChatGPT 和 ChatPDF,各自具備不同功能,可滿足各種需求。不管你是要快速擷取資料,還是分析複雜文件,選對工具都能讓工作更輕鬆、更有效率。
試試看:使用 AI 從 PDF 擷取資料
試著動手操作吧!你可以一邊觀看,一邊點擊、探索並執行工作流程。
如何選擇合適的 PDF 爬蟲
挑選 PDF 爬蟲,就像買車一樣;最好的那一款,就是最符合你需求的那一款。以下是幾個需要考量的重點:
| 功能 | 說明 |
|---|---|
| 準確性與穩定性 | 檢查工具是否能精準擷取資料,尤其是關鍵資訊。 |
| 輸出格式 | 確認工具是否支援你需要的輸出格式,例如 Excel、CSV 或 JSON。 |
| 與其他工具整合 | 如果你需要連接公司系統,請確認是否支援無縫整合。 |
| 使用介面友善度 | 對一般使用者來說,介面友善的工具更好;而較複雜的工具則可能更適合技術團隊。 |
不同工具各有優勢,選對工具能大幅提升你的工作效率。以下介紹三款熱門的 PDF 爬蟲,各自具備不同功能,適合不同需求:
| 工具 | 優點 | 缺點 |
|---|---|---|
| Thunderbit | 擷取速度快;瀏覽器擴充功能容易上手;很適合團隊協作 | 資料處理規模有限 |
| ChatPDF | 操作簡單,單一 PDF 可用聊天式問答 | 沒有原生 CSV/Excel/JSON 匯出功能,答案會留在聊天中 |
| ChatGPT | 能靈活處理複雜語意,適用範圍廣 | 每次都需要手動輸入提示詞 |
開始使用 AI PDF 爬蟲
Thunderbit
想要快速從 PDF 擷取資料,又不想花太多時間和精力嗎?Thunderbit 就是為你準備的工具。它簡單好上手,只要點一下,就能完成所有步驟。按照以下流程,你就能輕鬆把複雜的 PDF 資料轉成你需要的格式,大幅提升效率:
-
將 Thunderbit 加入 Chrome 並註冊帳號:
前往 Thunderbit 官方網站 ,並將 Thunderbit 擴充功能加入你的 Chrome 瀏覽器。你可以使用 Google 帳號或其他電子郵件註冊。

-
在 Chrome 中開啟 PDF:
在 Chrome 中開啟你想擷取資料的 PDF 檔,然後點擊右上角的 Thunderbit 圖示。
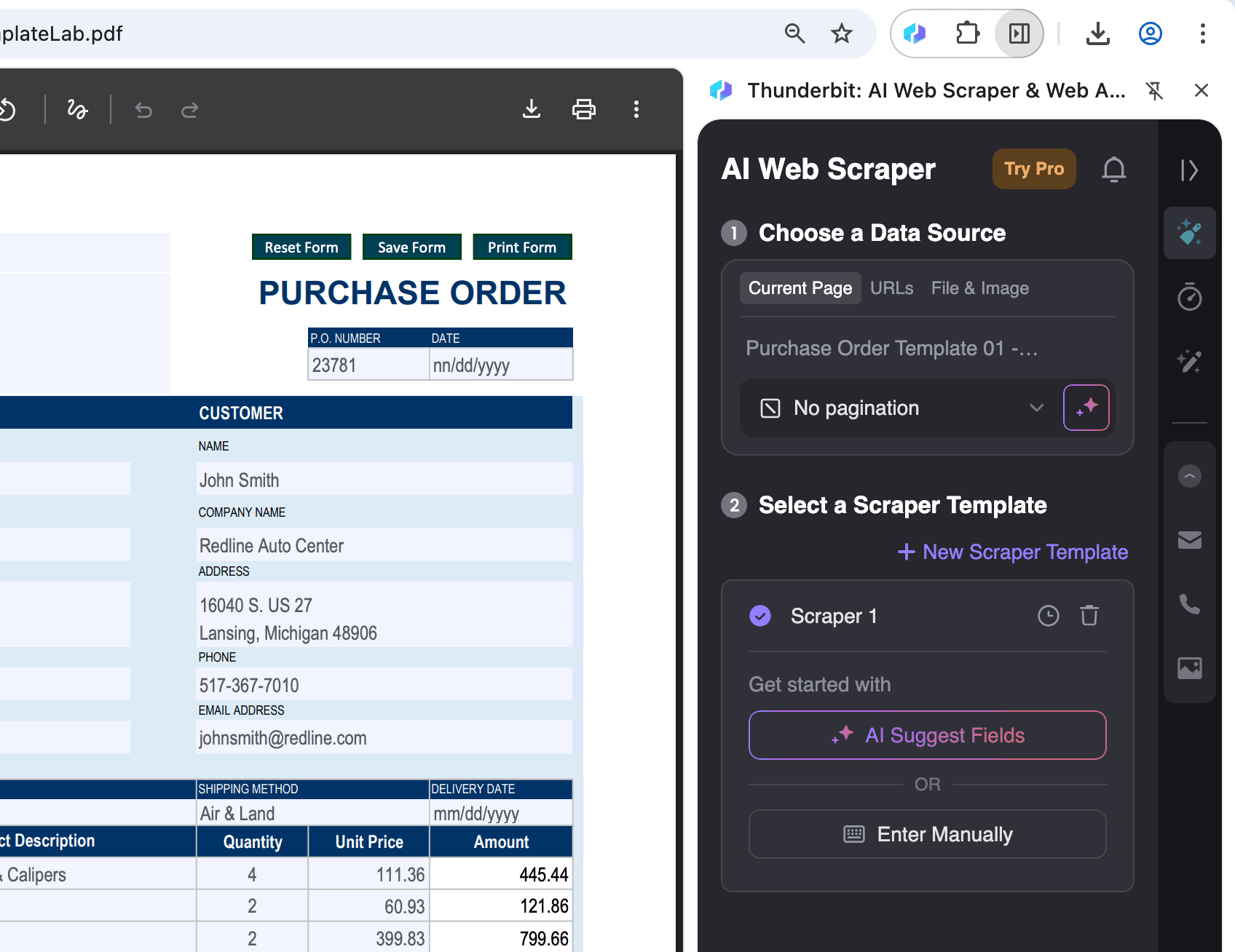
-
選擇輸出格式並匯出:
選擇 AI 建議欄位後,你可以依需求篩選或調整資料。接著,選擇你想要的匯出格式(CSV、Google Sheets、Airtable 或 Notion),然後點擊 擷取 以匯出資料。
 匯出的資料可以直接連接到 Notion、Airtable 或 Google Sheets ,方便團隊協作。
匯出的資料可以直接連接到 Notion、Airtable 或 Google Sheets ,方便團隊協作。
Thunderbit 是一款簡單直接的 PDF 資料擷取工具,能讓你快速從 PDF 檔案中提取所需資料,並轉換成可直接使用的格式。無論是個人使用還是團隊協作,Thunderbit 都能大幅提升生產力,讓資料擷取變得更輕鬆、更便利。
ChatPDF
如果你需要大量處理 PDF,而且只想擷取特定關鍵資訊,而不是完整資料,ChatPDF 會是很好的幫手。它能以對話方式擷取資料,對初學者也很友善。
以下是使用 ChatPDF 擷取 PDF 資料的步驟:
- 前往 ChatPDF 網站: 開啟 ChatPDF 網站或相關平台頁面。
- 上傳 PDF 檔案: 點擊「上傳檔案」按鈕,拖放或選擇你要分析的 PDF 文件。它支援多種檔案類型,例如合約、論文或財務報表。
- 分析 PDF: 上傳後,ChatPDF 會自動解析檔案內容,並生成結構化的文件摘要。接著你就能查看擷取出的關鍵資訊。
- 互動式查詢: 使用輸入框提問,例如「這份報告的結論是什麼?」或「發票上記錄的總金額是多少?」ChatPDF 會根據你的問題擷取相關內容。
- 將答案複製出來: ChatPDF 會在聊天視窗中直接回覆答案。你可以把回覆複製到試算表、文件或自己的表格中;若你需要高度結構化的輸出(例如多個檔案都保持一致欄位的乾淨 CSV/JSON),Thunderbit 或搭配固定提示詞的 ChatGPT 會更適合。
ChatPDF 提供互動式體驗,特別適合快速找出文件資訊,例如查找重點細節或摘要文件內容。
ChatGPT
ChatGPT 擅長處理複雜語意資料,例如解析法律文件中的條款。這個工具彈性很高,讓你可以自訂提示詞來擷取特定資料或分析內容。不過,類似任務每次都需要使用相同提示詞,而且你也需要對提示詞設計有一定理解。
以下是一段可供你修改的預寫提示詞(記得把欄位改成你想擷取的資訊):
你現在是一個 PDF 爬蟲,當給你一份 PDF 時,你需要根據使用者提供的欄位來擷取其內容。你的輸出應該是一個 CSV 檔案。
以下是欄位:
1. 姓名
2. 電子郵件
3. 電話號碼
4. ...
- 註冊或登入: 開啟 ChatGPT 網站並註冊帳號。如果你已經有帳號,直接登入即可。
- 上傳 PDF 並輸入查詢: 直接在輸入框中輸入你的問題,越具體越好。例如:「這份 PDF 文件有三張圖表,請將它們匯出成表格。」
- 檢查並調整結果: 確認答案是否符合你的預期。若有需要,可以透過追問或調整提示詞來優化結果。
- 將資料匯出為 Excel 或 CSV: 如果 ChatGPT 擷取出的資料正是你要的,請在輸入框中輸入:「將這些資料匯出為 Excel 或 CSV。」
- 儲存結果: 點擊 ChatGPT 提供的檔案連結以下載檔案。
AI PDF 爬蟲的實際應用情境
AI PDF 爬蟲就像工作中的萬能助理,無論你處理的是發票、合約、財務報告,還是採購單,都能派上用場。以下是幾個實際應用情境:
發票與收據處理
批次處理公司的發票與收據,擷取金額、日期等關鍵資訊,方便分類與歸檔。
- 啟動 Thunderbit,點擊 AI Web Scraper,然後選擇 Bulk Pages
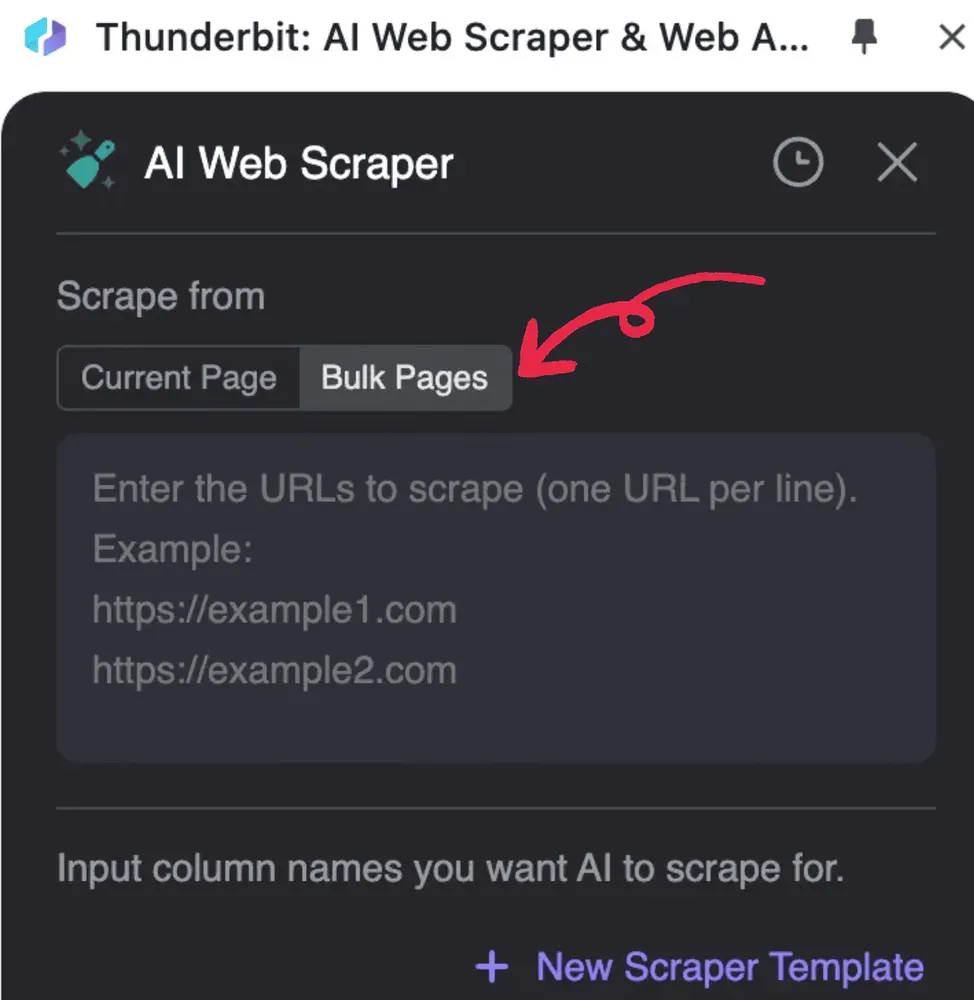 2. 輸入你要處理的 PDF URL,每行一個 URL
2. 輸入你要處理的 PDF URL,每行一個 URL
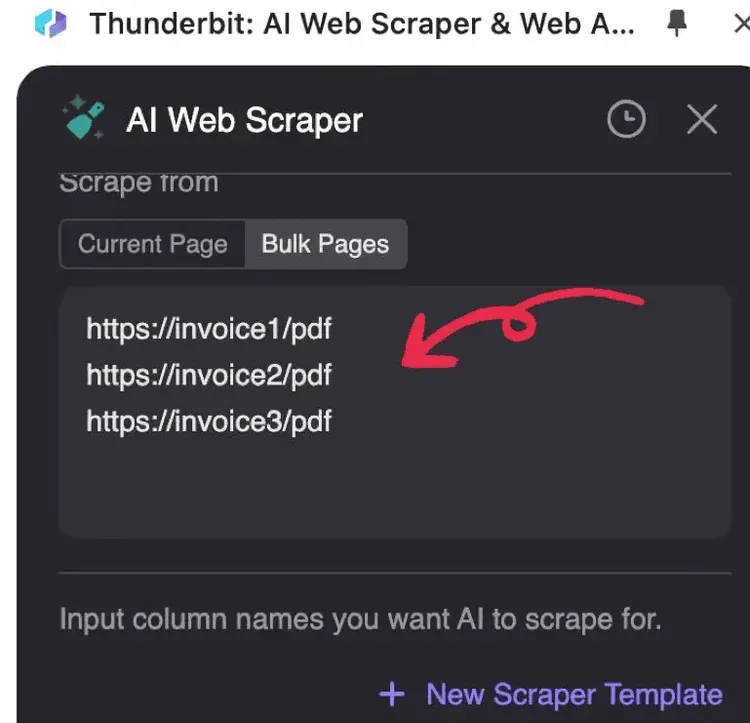 3. 點擊 AI Suggest Columns(AI 會讀取 PDF 並建議資料結構)
4. 點擊 Scrape 並匯出資料
3. 點擊 AI Suggest Columns(AI 會讀取 PDF 並建議資料結構)
4. 點擊 Scrape 並匯出資料
採購單處理
自動識別採購單中的品項、數量與單價,產生標準化資料記錄並從 PDF 中擷取資料,省下人工處理時間。
- 在 Chrome 中開啟採購單,並啟動 Thunderbit
- 點擊 AI Web Scraper,然後點擊 AI Suggest Columns
- 檢查產生的欄位名稱,然後點擊 Scrape
- 點擊 Download CSV
財務資料擷取
只要點一下,就能從財務報告中擷取資料,例如利潤率與銷售數字,省去繁瑣的人工檢查。
- 在 Chrome 中開啟財務報告,並啟動 Thunderbit
- 點擊 Summarize
- 自動生成包含文字與表格內容的關鍵資訊摘要
如果對自動生成的摘要不滿意?你也可以手動輸入想要的專案資訊。
- 在 Chrome 中開啟財務報告,並啟動 Thunderbit
- 點擊 AI Web Scraper,輸入你想要的欄位名稱,例如淨利、銷售額等
- 點擊 Scrape,輸出表格
法律文件分析
還在為合約與協議條款頭痛嗎?AI 工具能快速找出付款條件、違約條款、合約期限與其他重點。只要一鍵擷取,就能生成精簡摘要或條款清單,既省時又不會漏掉細節。
和從財務報告中擷取關鍵資訊類似,你可以開啟 PDF,點擊 Summarize,一鍵查看付款條件、違約條款、合約期限與其他重點資訊。
常見問題
-
我可以一次從多個 PDF 擷取資料嗎?
可以,進階的 PDF 擷取工具可讓使用者同時從多個 PDF 中擷取資料。和人工擷取相比,這種批次處理能力能大幅加快工作流程。
-
PDF 爬蟲是免費的嗎?
是的,市面上有幾款可免費使用的 PDF 爬蟲工具。許多線上工具,例如 Thunderbit 和 ChatPDF,都提供免費的頁面擷取與資料擷取功能。雖然某些進階功能可能需要付費,但基本的資料擷取通常是免費的。
-
使用 PDF 爬蟲需要程式設計知識嗎?
不需要,許多 AI PDF 爬蟲,例如 Thunderbit,都是為沒有程式設計背景的使用者所設計。它們提供友善的介面,讓你只要幾個點擊就能上傳檔案並擷取資料。
-
PDF 爬蟲可以處理哪些類型的文件?
PDF 爬蟲可以處理多種文件類型,包括發票、合約、財務報告、學術論文,以及 PDF 檔案中任何其他結構化或半結構化內容。
-
使用 PDF 爬蟲時,我的資料安全嗎?
信譽良好的 PDF 擷取工具都很重視使用者安全,且通常符合 GDPR 等法規。它們一般會將你的資料儲存在加密伺服器上,且未經你允許不會存取資料。
-
除了 PDF 爬蟲,還有其他從 PDF 擷取資料的方法嗎?
除了手動輸入和 Python 腳本之外,還有幾種從 PDF 擷取資料的方法。包括使用 PDF 轉換器將檔案轉成 Excel 或 CSV 等格式、針對結構化文件的專門 PDF 資料擷取工具(例如 Tabula 和 Excalibur)、結合光學字元辨識(OCR)的 AI 解決方案,可同時處理原生與掃描版 PDF,以及像 Extractous 和 PymuPDF4llm 這類專為高效率資料擷取設計的開源工具。每種方法都有其優缺點,因此要依據使用者的具體需求與技術能力來選擇。
延伸閱讀
試用 AI Web Scraper Get Started Free




