每次听到有人说“直接从网站复制粘贴就行了”,我都会忍不住皱一下眉。到了 2025 年,企业团队仍然在把高达 36% 的工作周浪费在手动收集数据和整理表格上(),而互联网上的信息却比以往任何时候都更爆炸。我见过销售人员把70% 的时间花在调研、录入数据这类非销售任务上(),也见过营销人员为了做一份基础的竞品报告就耗掉好几个小时。说到底,我们大多数人都不是数据工程师——也不该为了拿到所需信息就被迫变成数据工程师。

这正是我这么喜欢 的原因——它是我们这款由 AI 驱动的 Easy Scraper Chrome 扩展。它就是为我这种人设计的:想快速拿到网页数据,又不想被技术细节折腾的业务用户。在这篇文章里,我会展示 Thunderbit 的 2 步、无代码工作流,怎么让任何人——没错,连我妈妈都可以——从任何网站、PDF 或图片中抓取数据,并直接导出到 Excel、Google Sheets、Notion 或 Airtable。我会分享我最喜欢的技巧、真实使用场景,以及为什么我认为 Thunderbit 是市面上最简单的网页爬虫。
是什么让 Easy Scraper Thunderbit 与众不同?
Thunderbit 的核心设计理念很简单:把网页爬取做得像在线点披萨一样简单。不用写代码,不用模板,也不用折腾“检查元素”。相反,Thunderbit 会用 AI 读取任意网页(或 PDF、图片),理解哪些数据最重要,并帮你自动完成抓取设置。
下面是 Thunderbit 的独特之处:
- AI 驱动、自然语言交互: 只要点击“AI Suggest Fields”,Thunderbit 的 AI 就会分析页面,并推荐最适合提取的数据列。你不需要描述选择器,也不用手动调参数——AI 会把最费劲的部分都包了()。
- 2 步完成设置: 字段建议出来后,点一下“Scrape”就完成了。没有反复试错,没有编码,没有模板。它真的就是两步完成()。
- 没有技术门槛: Thunderbit 是为非技术用户打造的——销售、运营、电商、房地产,等等。只要你会用浏览器,你就会用 Thunderbit。
- 自动处理子页面和分页: Thunderbit 的 AI 可以自动跟随链接进入子页面(比如商品详情页或领英个人资料),并自动处理分页或无限滚动网站()。
- 预置模板: 针对 Amazon、Zillow、Instagram、Shopify 这类热门网站,Thunderbit 提供即用型模板——选一个就能直接开始抓取,无需设置。
我也试过不少“无代码”爬虫,但大多数还是要你自己建站点地图,或者逐个字段点击配置。Thunderbit 的思路完全不同:让 AI 来思考,你只需要把精力放在真正重要的事情上——用好数据。
为什么 Easy Scraper Thunderbit 对业务用户很重要?
说实话:网页数据是现代商业的燃料,但获取它不该像拔牙一样痛苦。下面看看 Thunderbit 如何为不同团队带来实际回报:
结论很简单:省下的时间,就是赚到的钱。Thunderbit 用户通常每周能省下 8–10 个小时,不再把时间浪费在手工杂活上(),而且数据也更准确——不再有拼写错误或漏填项()。对销售、营销和运营团队来说,这意味着能把更多时间放在策略、外联和成交上。
快速抓取网页数据:Thunderbit 实战演示
我来带你看看 Thunderbit 在真实场景里是怎么工作的——没有技术术语,只有实用步骤。
步骤 1:安装 Thunderbit
- 下载 (可免费试用,整个过程不到一分钟)。
步骤 2:打开目标网站
- 进入你想抓取的页面——Amazon、Zillow、领英、PDF,甚至图片都可以。
步骤 3:点击“AI Suggest Fields”
- Thunderbit 的 AI 会扫描页面,并建议最相关的字段(例如 Amazon 的商品名、价格、评分;Zillow 的地址、价格、经纪人)。
步骤 4:点击“Scrape”
- Thunderbit 会抓取所有数据,即使跨多个页面或无限滚动也没问题。几秒后你就能看到一张整齐的表格。
步骤 5:导出数据
- 选择 Excel、Google Sheets、Notion、Airtable、CSV 或 JSON。导出即时完成,而且始终免费。
真实案例: 我最近需要比较 Amazon 商品列表来做市场分析。用 Thunderbit,我在不到一分钟的时间里就抓取了 100 多个商品(名称、价格、评分、评论)——不用设置,不用写代码,只要两次点击。我甚至只需再点一下,就从每个商品的子页面里提取了详细规格。
Thunderbit 也支持抓取 PDF、Word 文档和图片——只要上传文件,AI 就会把表格或文本提取成结构化数据()。对于处理报告、发票或扫描文档的人来说,这简直是救命功能。
AI Suggest Fields:轻松结构化数据的秘诀
这就是让 Thunderbit 真正“简单”的功能。传统爬虫里,你必须手动选择每个字段——点名称、点价格、点评分,然后祈祷工具能自己看懂规律。一旦页面改版,你之前的设置就会失效。
在 Thunderbit 里,你只要点一下“AI Suggest Fields”。AI 会读取整页内容,理解上下文,并提出一个待提取字段列表——还会附带智能数据类型(文本、数字、邮箱、电话、图片等)。它甚至会在后台自动生成自定义提取逻辑,所以你不用担心漏数据或者格式怪异的问题()。
前后对比示例:
- 手动方式: 花 10–15 分钟逐个点击并配置字段,容易出错,网站改版就会失效。
- Thunderbit AI: 1 秒完成,自动给出所有字段建议,适应布局变化,几乎适用于任何网站。
你当然也可以随时微调建议结果——重命名列、增删字段,或者用“Field AI Prompts”来自定义提取逻辑(比如给商品分类,或实时翻译文本)。但老实说,我觉得 AI 大约 95% 的情况下都能给出正确结果。
用 Thunderbit 导出并增强你的数据
一旦抓到数据,Thunderbit 会让你轻松把它放到你需要的地方:
- 导出选项: 一键导出到 Excel、Google Sheets、Airtable、Notion、CSV 或 JSON()。没有付费墙,导出格式也不受限。
- AI 驱动的分类与标记: 在抓取时使用“Field AI Prompts”对数据进行分类、打标或格式化。例如,基于关键词把线索标记为“热”或“冷”,或者统一日期和价格格式()。
- 自动数据清洗: Thunderbit 可以在提取过程中帮你去重、校验并补充数据,让你导出的表格一拿到手就能直接分析。
我很喜欢直接导出到 Google Sheets 做实时仪表板,或者导出到 Notion 方便和团队分享。再加上 Thunderbit 支持定时爬取,我可以让数据每天早上自动更新——完全不用手动操作。
搞定复杂网页:分页与子页面抓取
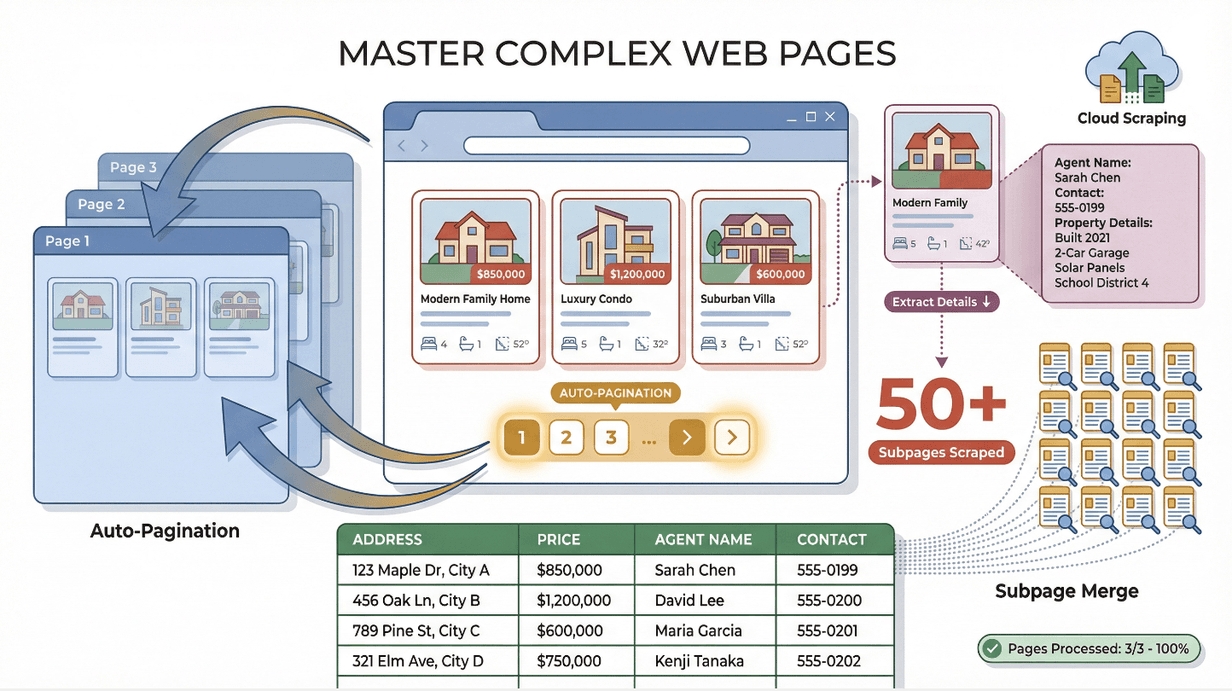
过去,动态网站几乎是所有爬虫的噩梦。现在不是了。
- 分页: Thunderbit 会自动识别并点击分页结果或无限滚动,确保你拿到完整数据集,而不只是第一页()。
- 子页面抓取: 还想要更多细节?Thunderbit 可以跟随链接(比如商品详情页或领英个人资料),抓取额外字段,并把结果合并到主表中()。
场景: 我曾经抓取一个房产 listings 网站上的地址和价格,然后再用子页面抓取,从每个房源里提取经纪人姓名和联系方式。Thunderbit 在几分钟内就处理了 50 多个子页面——如果手工做,这得花我好几个小时。
Thunderbit 也适用于需要登录的网站(比如领英或私有仪表板),因为它是在你的浏览器中运行,并使用你的会话。对于公开的大规模任务,你还可以使用云端爬取,一次处理最多 50 个页面。
分步指南:使用 Easy Scraper Thunderbit
下面是我做任何新抓取项目时最常用的工作流:
- 安装 Thunderbit: ,并将它固定到 Chrome 工具栏。
- 打开网站: 进入目标页面(必要时先筛选或登录)。
- 启动 Thunderbit: 点击 Thunderbit 图标打开侧边栏。
- AI Suggest Fields: 点击“AI Suggest Fields”,查看建议的列。
- 调整字段(可选): 根据需要重命名、添加或删除字段。也可以用“Field AI Prompts”写自定义逻辑。
- 抓取: 点击“Scrape”,看数据自动流入。
- 子页面抓取(可选): 点击“Scrape Subpages”,为表格补充更多细节。
- 导出: 选择你喜欢的格式——Excel、Google Sheets、Notion、Airtable、CSV 或 JSON。
- 分析: 打开导出的数据,开始使用。
排错提示:
- 确保你要的数据是可见的(必要时登录,或点击“show more”)。
- 对于速度慢或页面量巨大的网站,使用云端爬取,或把任务安排到非高峰时段。
- 如果某个字段看起来不对,调整 AI 提示词,或者重新建议字段。
大多数用户都告诉我,他们是“几分钟上手”,而不是“几个小时上手”。如果你遇到卡住的情况,Thunderbit 的和支持团队也会帮你解决。
进阶技巧:把 Easy Scraper Thunderbit 用到极致
掌握基础功能后,这些进阶技巧是我最喜欢的:
- 定时爬取: 用通俗英语设置重复任务(例如“每周一上午 9 点”)。Thunderbit 会自动保持数据更新鲜()。
- Field AI Prompts: 使用自定义指令,在抓取时对数据进行分类、摘要或翻译。例如,“根据商品名称标记为电子产品、服饰或家居用品”。
- 免费提取器: 只需点一下,就能从任意页面立即抓取所有邮箱、电话号码或图片——无需设置()。
- 云端模式 vs 浏览器模式: 对公开的大型任务使用云端爬取(一次最多 50 页),对需要登录或有反爬措施的网站使用浏览器爬取()。
- 多语言支持: Thunderbit 的 AI 支持 34 种语言,并能实时翻译内容——非常适合国际调研()。
- 模板整理: 把你喜欢的字段配置保存为模板,方便快速复用。命名要清晰,比如“Amazon Product Scraper”“Zillow Listings”。
还有一点永远要记住:尊重网站条款和隐私——Thunderbit 很强大,所以请负责任地使用它。
结论与要点总结
Thunderbit 不只是又一个网页爬虫——它是为任何需要网页数据、但又不想折腾代码或复杂工具的人带来的生产力升级。下面是我认为它是市面上最好的 easy scraper 的原因:
- 真正无代码: 只要会点按钮,你就能用 Thunderbit。
- AI 驱动的简单性: “AI Suggest Fields” 让数据提取不再靠猜。
- 2 步工作流: 几秒钟就能从网站到表格。
- 支持各种内容: 可处理网站、PDF、图片、动态页面等。
- 为进阶用户准备的高级功能: 定时任务、子页面抓取、字段提示词等等。
- 可免费试用: 可免费抓取最多 6 个页面(试用加成后最多 10 个),并包含全部功能()。
如果你已经厌倦了漫长的复制粘贴,或者受够了笨重难用的爬虫,那就把 Thunderbit 用在你的下一个项目里试试吧。你会省下好几个小时,拿到更好的数据,甚至可能还会享受这个过程。下载 ,亲自体验一下。如果你想进一步深入了解,也可以去看看 ,那里有更多指南、技巧和真实案例。
常见问题
1. Thunderbit 和其他网页爬虫有什么不同?
Thunderbit 使用 AI 自动完成字段选择和数据提取,所以你不需要懂代码,也不需要自己做模板。它专为非技术用户设计,只需两步即可完成。
2. Thunderbit 能处理带分页或子页面的复杂网站吗?
可以!Thunderbit 会自动识别并抓取分页结果、无限滚动内容,还能跟随链接进入子页面(如商品详情或个人资料),从而丰富你的数据集。
3. Thunderbit 可以提取哪些类型的数据?
Thunderbit 可以抓取文本、数字、日期、URL、邮箱、电话号码、图片等内容——来源包括网站、PDF、Word 文档,甚至图片。
4. 如何从 Thunderbit 导出数据?
你可以一键将数据导出到 Excel、Google Sheets、Notion、Airtable、CSV 或 JSON。所有导出选项都是免费且不限量的。
5. Thunderbit 真的可以免费试用吗?
当然可以。免费版最多可抓取 6 个页面(试用加成后最多 10 个),并可使用所有功能——包括 AI 建议、模板和导出。如果你需要更大额度,升级方案也很实惠()。
准备好告别手动录入了吗?,今天就体验轻松网页爬取。
了解更多