
有没有遇到过这种情况:老板丢给你一堆 PDF 文件,让你把里面的数据整理出来,还要求格式规范、结果准确?如果靠人工一个个复制粘贴,大概率又要加班。PDF 数据提取之所以麻烦,是因为它不像网页数据那样结构清晰。不同 PDF 的排版差异很大,有的是表格,有的是图片,还有的是扫描件,想直接提取里面的数据并不容易。
比如,你想从 PDF 中提取邮箱地址。有些邮箱可能藏在图片里,有些则被复杂的字符编码包裹起来。举个例子:{john.doe,jane.doe}@example.com 实际上代表两个邮箱:john.doe@example.com 和 jane.doe@example.com。再比如 {first.last}@example.com,这里需要把 “first” 和 “last” 分别替换成作者的名和姓。传统 OCR 或文本识别工具很难准确处理这类情况。这时候,一个好用的 PDF Scraper 就能派上用场。
什么是 PDF Scraper
PDF Scraper 是一种可以自动从 PDF 文件中提取数据的工具,能把 PDF 里的表格、文本等内容转换成你需要的格式,比如 Excel、CSV 或 JSON。简单来说,它可以把繁琐的复制粘贴工作,变成一次点击就能完成的流程。
想象一下,你手上有一堆发票、合同、学术论文,甚至是扫描版 PDF。如果手动录入,可能要花上好几个小时。但使用 PDF Scraper,只需要上传文件,几秒钟内就能提取出数据,既省时间,也能减少人工录入错误。
如果你的 PDF 里包含表格、链接、图片等多种内容类型,可以交给 AI PDF Scraper 来处理。AI PDF Scraper 通常基于大语言模型(LLM),能够同时理解文本、图片和表格,提取效果也更稳定。
AI PDF Scraper 的优势不只是效率和准确率,更重要的是适应性强。无论是扫描件、图片型 PDF,还是多语言文档,AI 都能更轻松地处理。目前市面上也有不少优秀工具,比如 、 和 。不同工具适合不同场景,选对工具,可以让 PDF 数据提取变得更简单高效。
试试看:用 AI 从 PDF 中提取数据
你可以直接点击、探索,并跟着演示运行整个流程。
如何选择合适的 PDF Scraper
选择 PDF Scraper 就像买车,最重要的不是功能越多越好,而是是否适合你的实际需求。可以重点关注下面几点:
| 功能 | 说明 |
|---|---|
| 准确率和稳定性 | 查看工具是否能稳定、准确地提取数据,尤其是关键字段。 |
| 导出格式 | 确认是否支持你需要的格式,比如 Excel、CSV 或 JSON。 |
| 工具集成能力 | 如果需要接入公司内部系统,要关注是否支持无缝集成。 |
| 易用性 | 普通用户更适合界面简单的工具,技术团队则可以选择更灵活的方案。 |
不同工具各有优势,选对工具能明显提升工作效率。下面是三款常见 PDF Scraper 的对比:
| 工具 | 优点 | 缺点 |
|---|---|---|
| Thunderbit | 提取速度快;浏览器插件形式,上手简单;适合团队协作 | 超大规模数据处理能力有限 |
| ChatPDF | 使用简单,可通过聊天方式提取信息 | 面对复杂文件时准确率相对有限 |
| ChatGPT | 适合处理复杂语义,使用场景灵活 | 每次任务通常需要手动编写提示词 |
如何开始使用 AI PDF Scraper
Thunderbit
如果你想快速从 PDF 中提取数据,又不想花太多时间学习工具,Thunderbit 会是一个很适合的选择。它操作简单,只需几步就能把复杂 PDF 数据转换成可用格式,大幅提升处理效率。
-
将 Thunderbit 添加到 Chrome 并注册账号:
访问 ,将 扩展添加到 Chrome 浏览器。你可以使用 Google 账号或其他邮箱注册。

-
在 Chrome 中打开 PDF:
在 Chrome 中打开需要提取数据的 PDF 文件,然后点击右上角的 Thunderbit 图标。
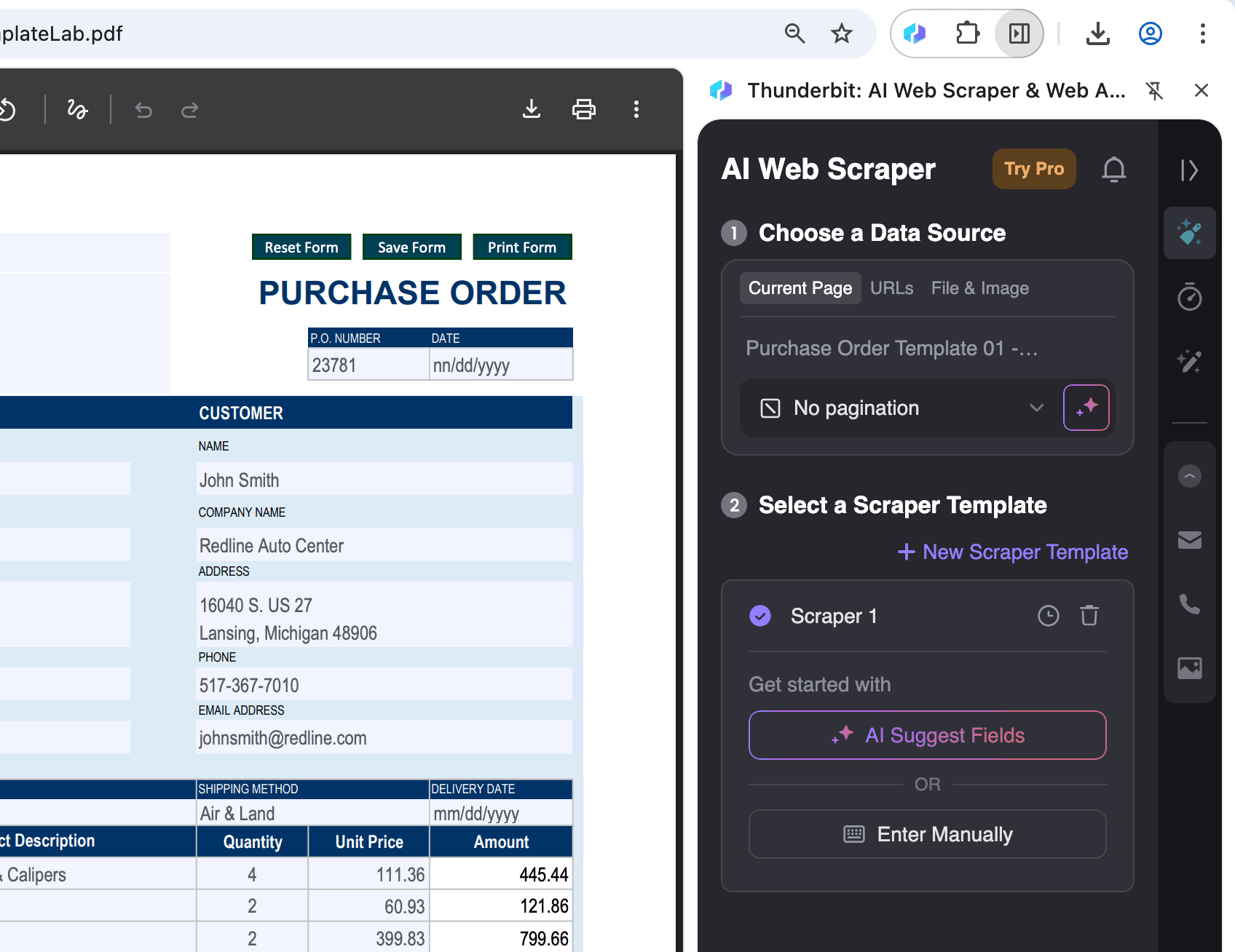
-
选择导出格式并导出数据:
点击 AI Suggest Columns 后,可以根据需要筛选或调整数据字段。然后选择导出格式(CSV、Google Sheets、Airtable 或 Notion),点击 Scrape 即可导出数据。
导出的数据可以直接连接到 、 或 ,方便团队协作。
Thunderbit 是一款上手简单的 PDF 数据提取工具,可以快速从 PDF 文件中提取所需数据,并转换成可用格式。无论是个人使用还是团队协作,都能显著提升效率。
ChatPDF
如果你需要批量处理 PDF,并且只想提取某些关键信息,而不是完整数据, 是一个不错的选择。它支持通过对话方式提取内容,适合新手快速上手。
使用 ChatPDF 提取 PDF 数据的方法如下:
- 访问 ChatPDF 网站: 打开 官网或相关平台页面。
- 上传 PDF 文件: 点击 “Upload File” 按钮,拖拽或选择需要分析的 PDF 文档。它支持合同、论文、财务报表等多种文件类型。
- 分析 PDF 内容: 上传完成后,ChatPDF 会自动解析文件内容,并生成结构化摘要,你可以查看提取出的关键信息。
- 进行交互式提问: 在输入框中提问,例如 “这份报告的结论是什么?” 或 “这张发票记录的总金额是多少?” ChatPDF 会根据问题提取相关内容。
- 导出结果: 如有需要,可以将提取结果导出为 CSV、Excel 或 JSON 格式,方便后续整理和使用。
ChatPDF 的优势在于交互体验,尤其适合快速定位文档信息,比如查找重点内容或生成文档摘要。
ChatGPT
擅长处理复杂语义数据,比如解析法律文档中的条款。它非常灵活,你可以自定义提示词来提取指定数据或分析内容。不过,如果要反复处理类似任务,通常需要重复使用相同提示词,因此也需要一定的提示词编写能力。
下面是一段可以按需修改的提示词示例(记得把字段替换成你想提取的信息):
1你现在是一个 PDF 数据提取工具。当用户提供 PDF 时,你需要根据用户给出的字段提取内容。你的输出应该是一个 CSV 文件。
2以下是需要提取的字段:
31. 姓名
42. 邮箱
53. 电话号码
64. ...- 注册或登录: 打开 网站并注册账号。如果已有账号,直接登录即可。
- 上传 PDF 并输入需求: 在输入框中输入你的需求,描述越具体越好。例如:“这份 PDF 文档包含三张图表,请将它们导出为表格。”
- 检查并调整结果: 查看回答是否符合预期。如有需要,可以继续追问或调整提示词来优化结果。
- 导出为 Excel 或 CSV: 如果 ChatGPT 提取的数据符合你的需求,可以输入:“请将这些数据导出为 Excel 或 CSV。”
- 保存结果: 点击 ChatGPT 提供的文件链接下载结果文件。
AI PDF Scraper 的常见应用场景
AI PDF Scraper 就像一个灵活的办公助手,不管你处理的是发票、合同、财务报告还是采购订单,都能节省大量重复劳动。下面是几个典型场景:
发票和收据处理
批量处理公司发票和收据,提取金额、日期等关键信息,用于分类和归档。
- 启动 ,点击 AI Web Scraper,然后选择 Bulk Pages
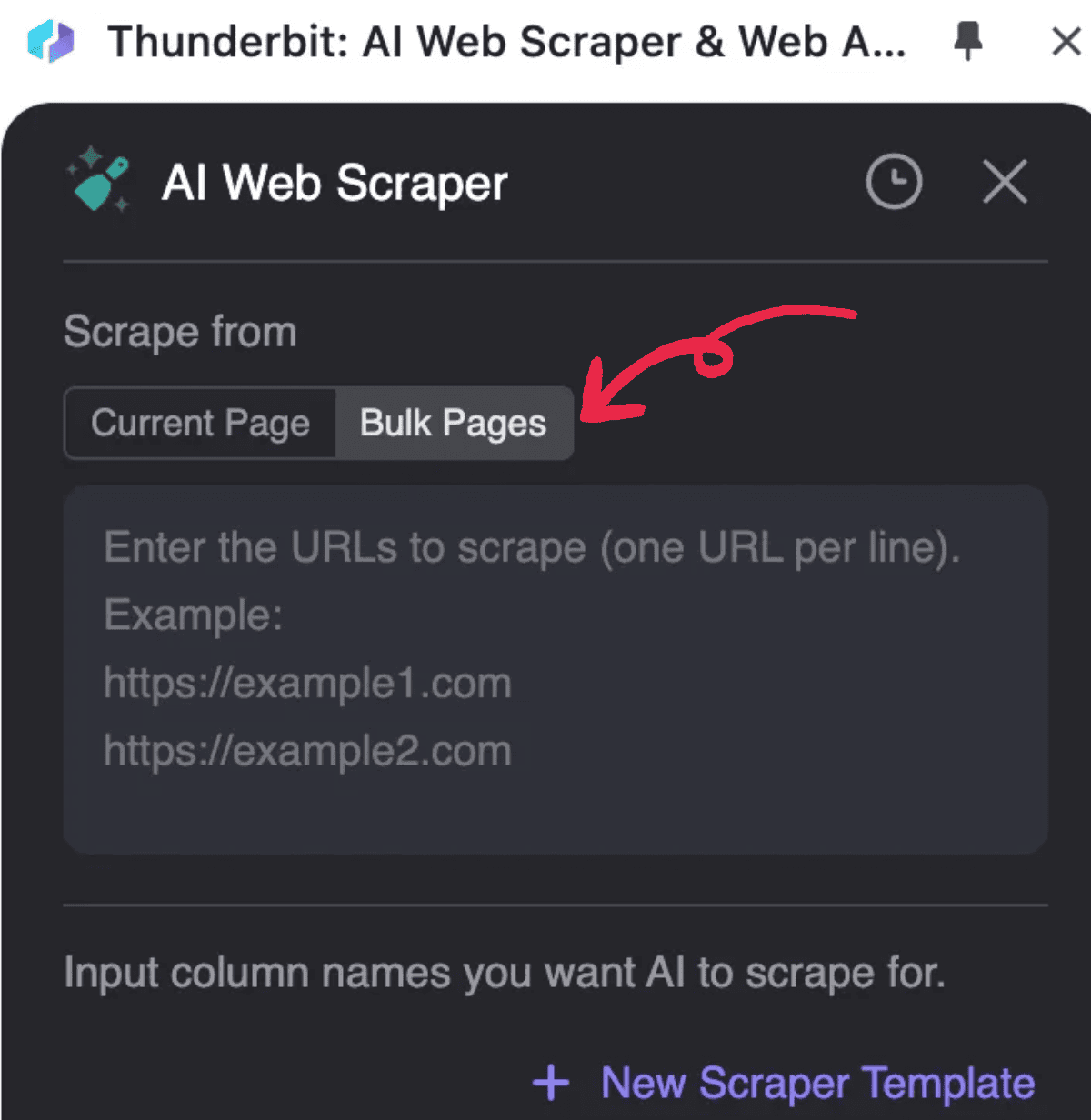
- 输入需要处理的 PDF URL,每行一个链接
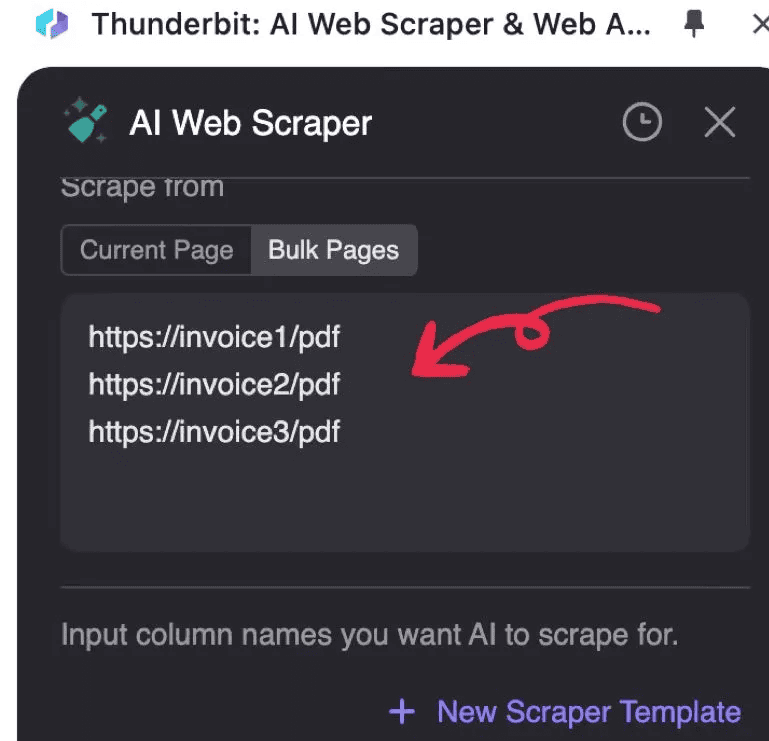
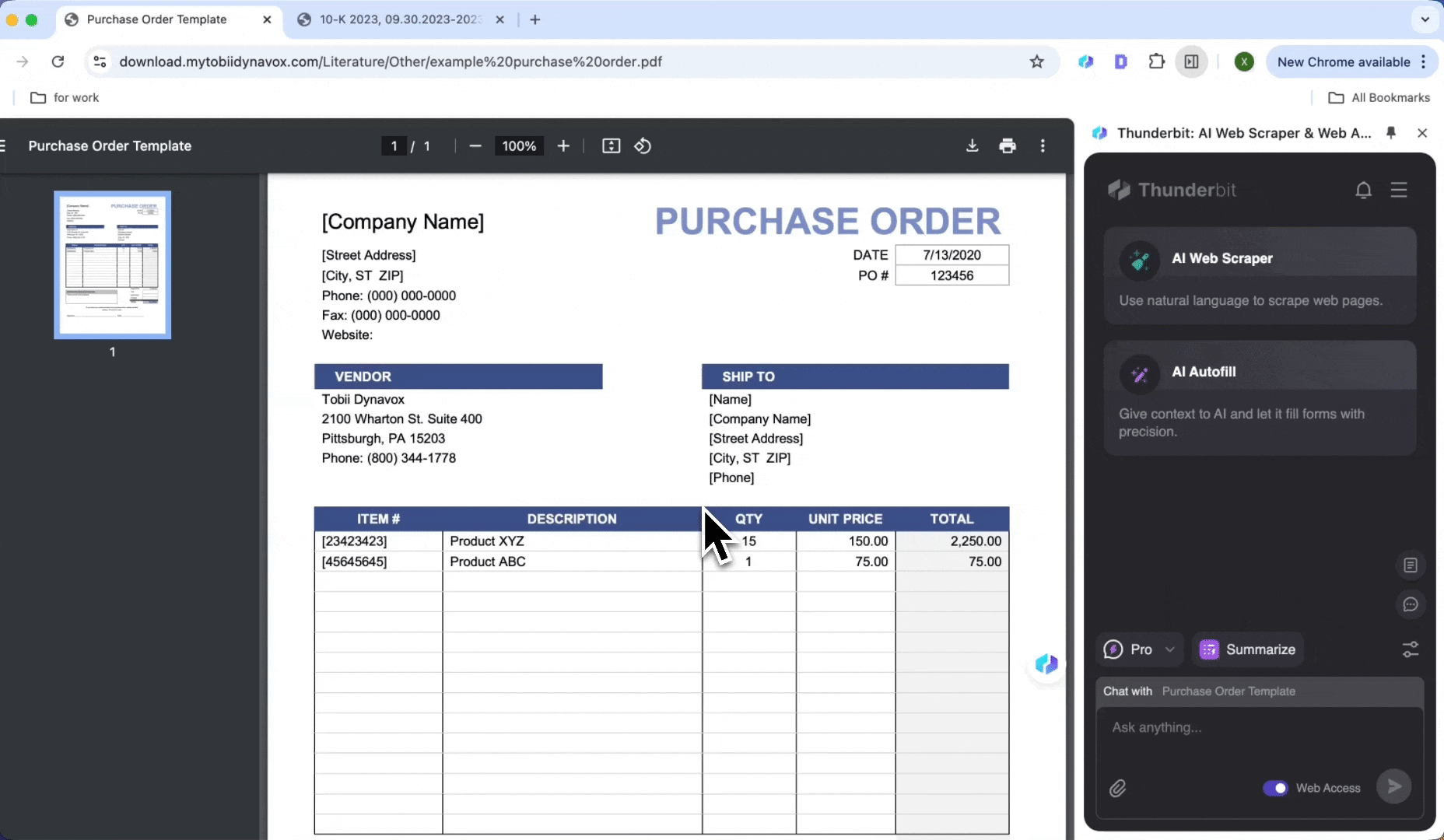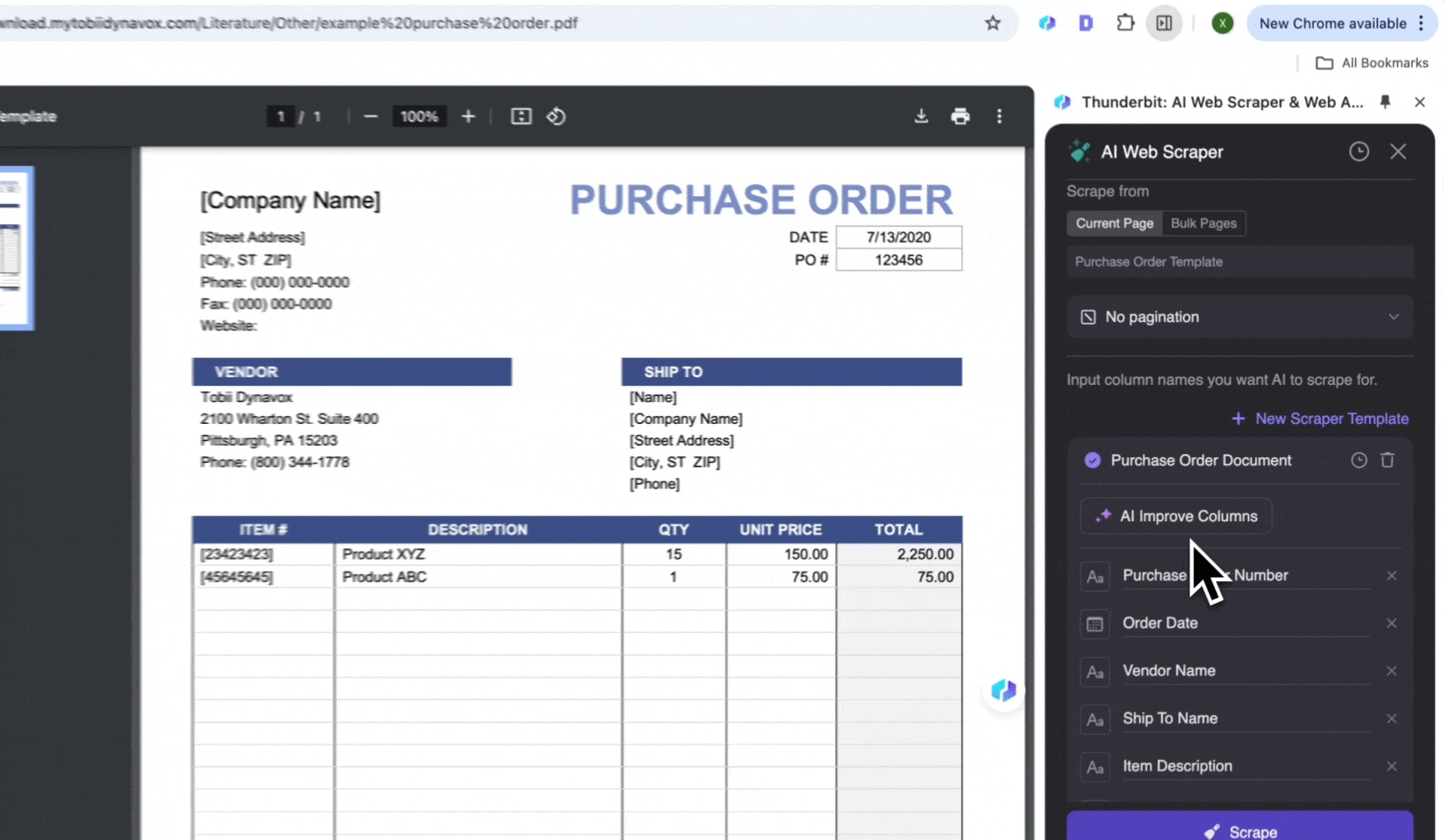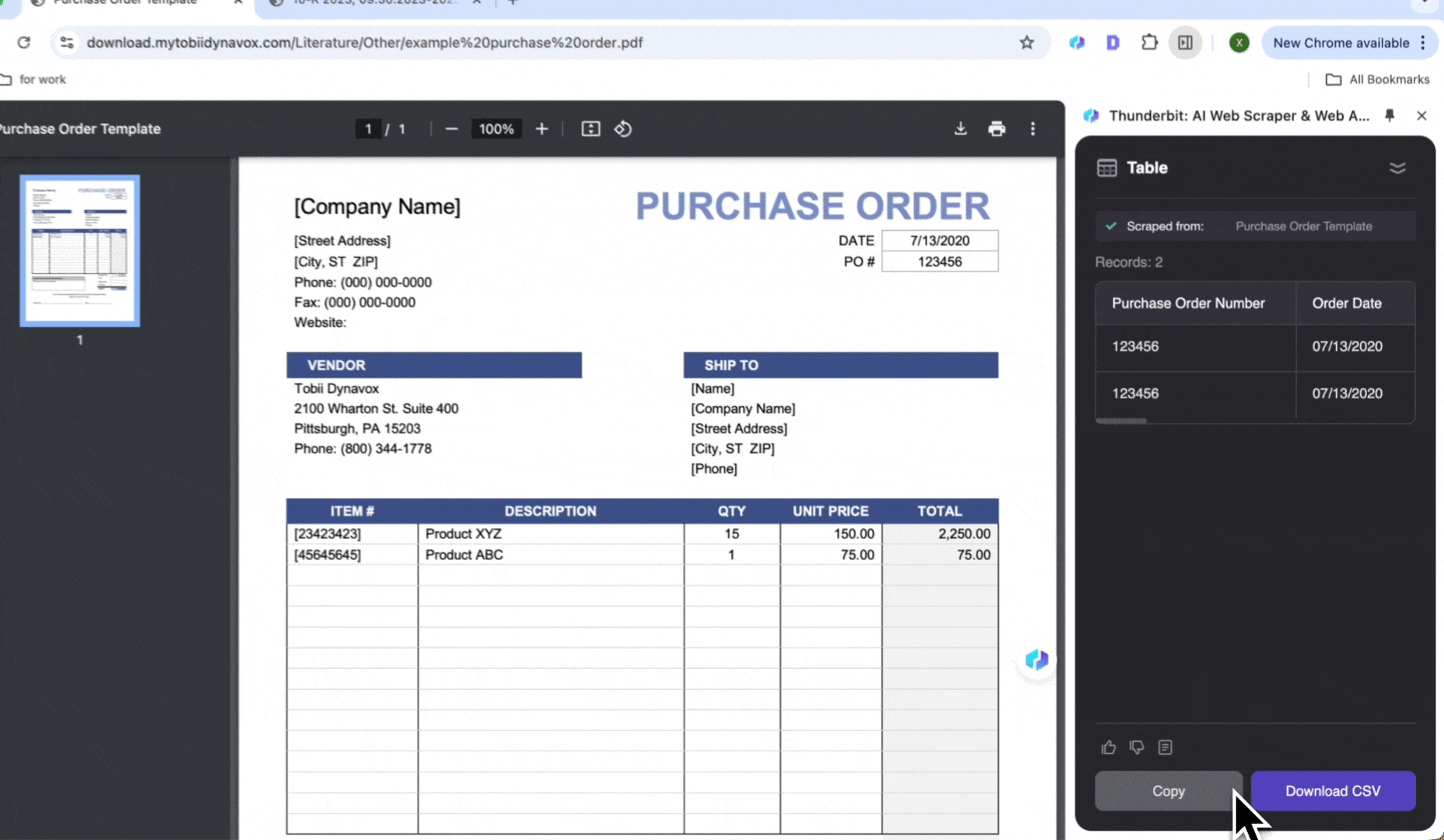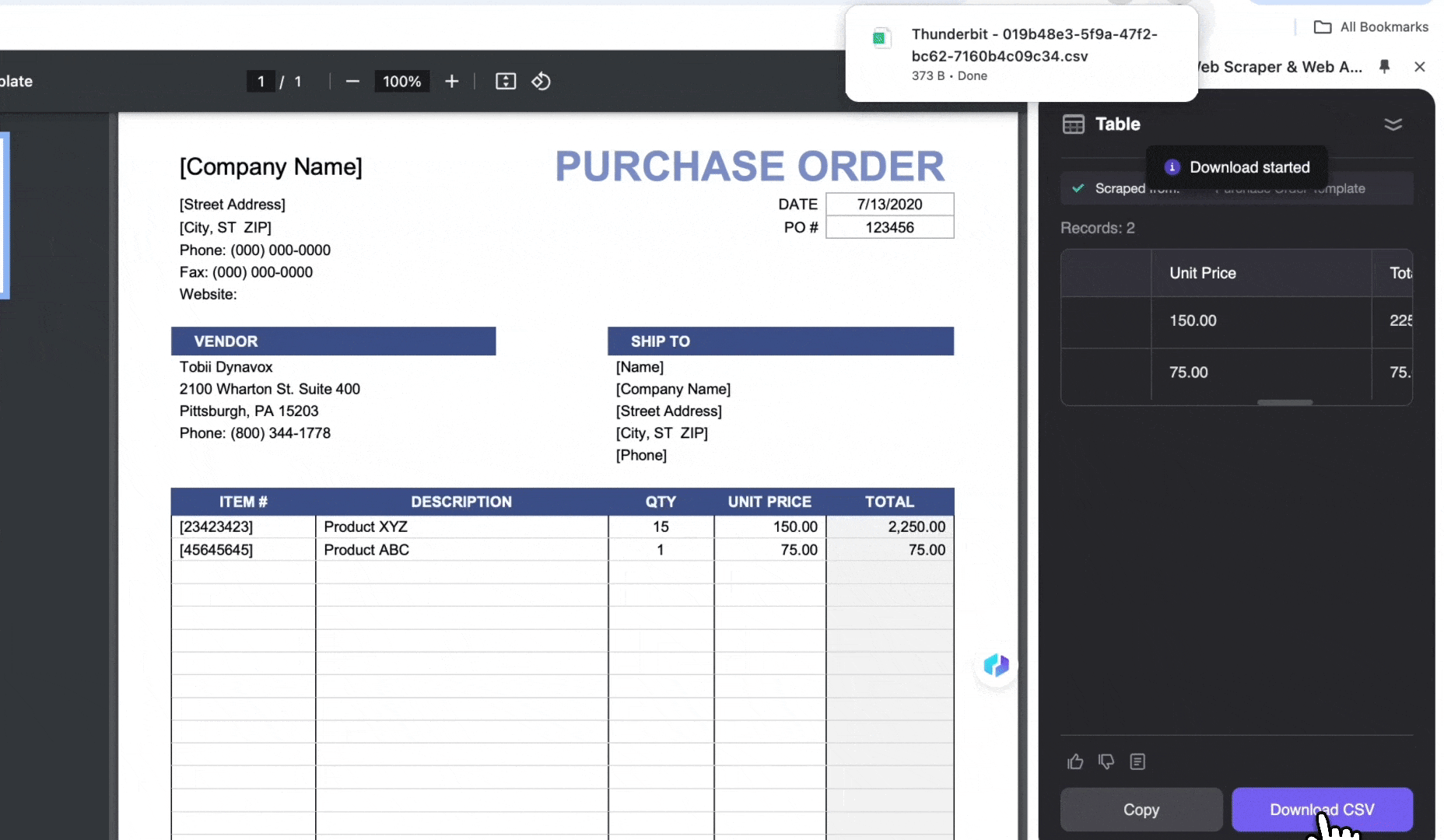
- 点击 AI Suggest Columns,AI 会读取 PDF 并建议数据结构
- 点击 Scrape 并导出数据
采购订单处理
自动识别采购订单中的商品、数量和单价,生成标准化数据记录,减少人工整理时间。
- 在 Chrome 中打开采购订单,并启动
- 点击 AI Web Scraper,然后点击 AI Suggest Columns
- 检查生成的字段名称,并点击 Scrape
- 点击 Download CSV
财务数据提取
一键从财务报告中提取利润率、销售额等数据,减少逐页人工查找的时间。
- 在 Chrome 中打开财务报告,并启动
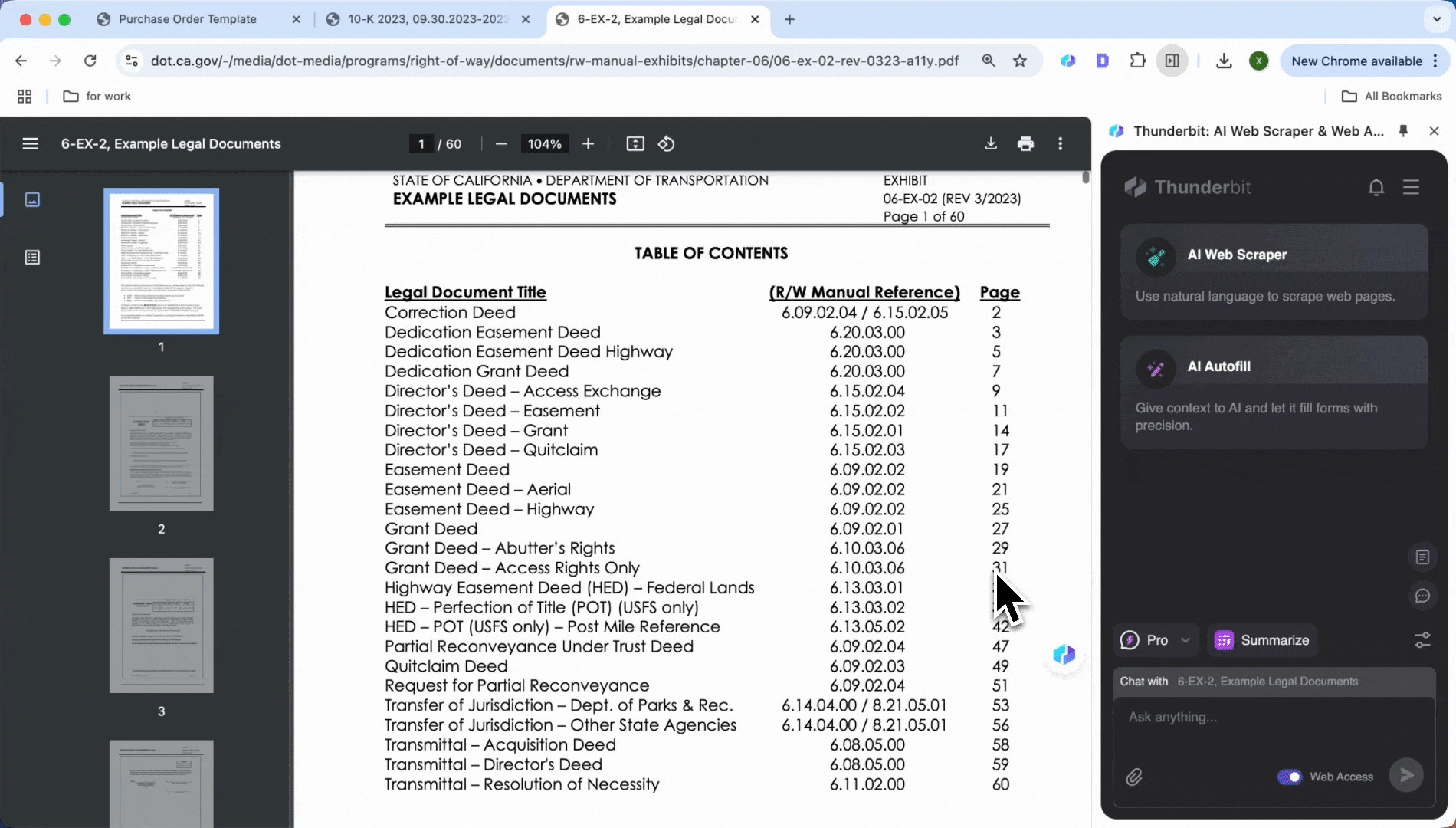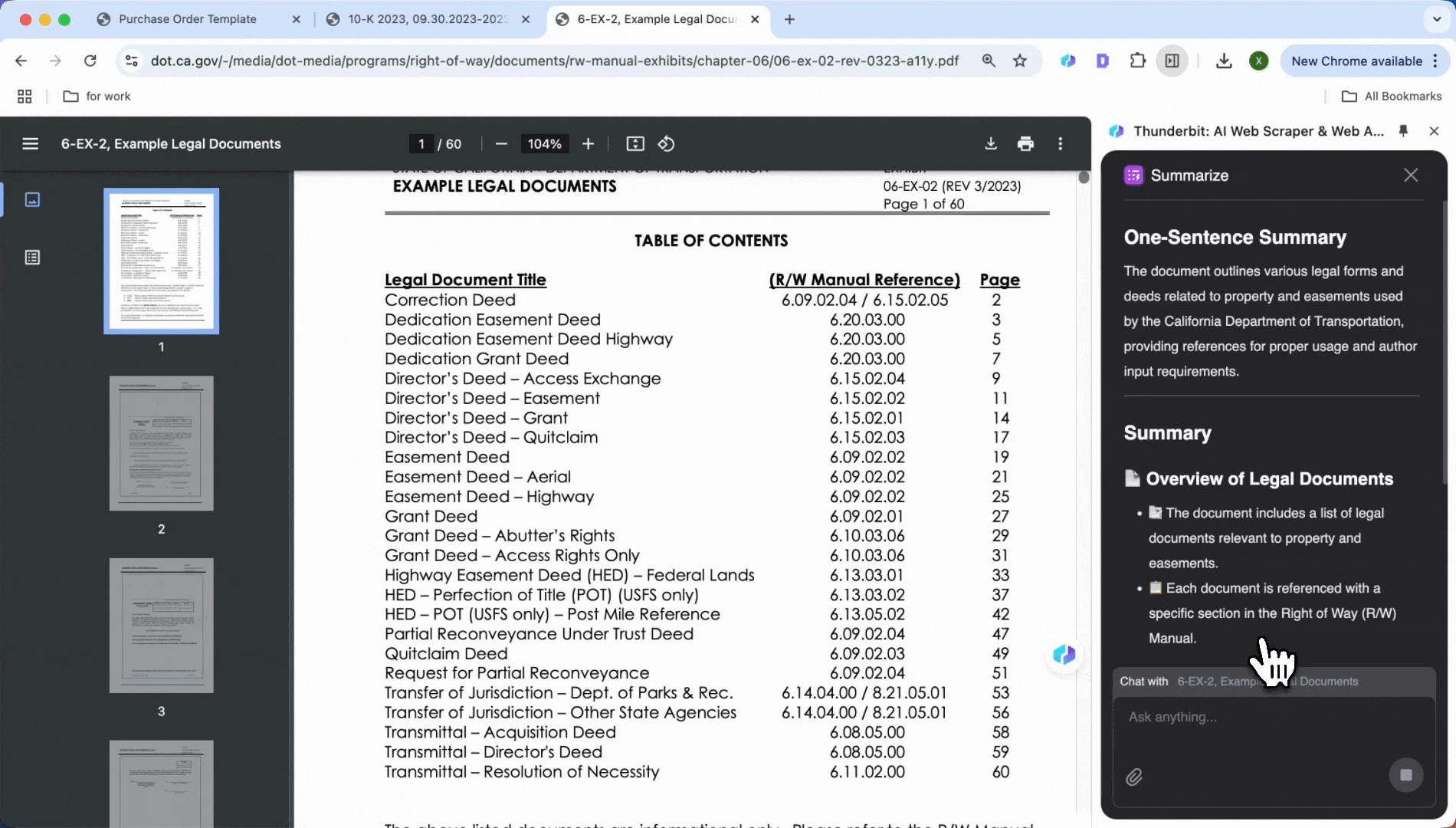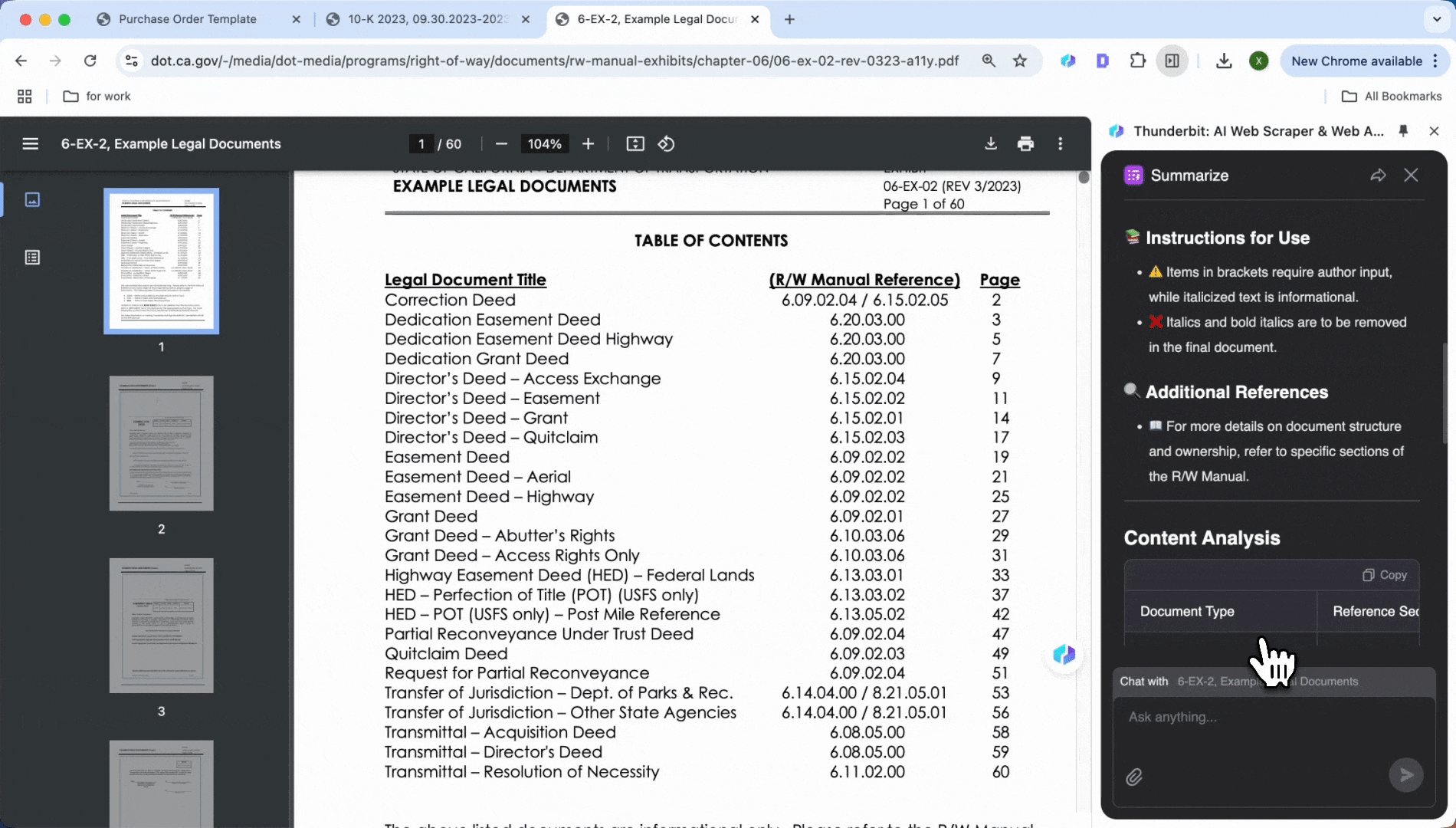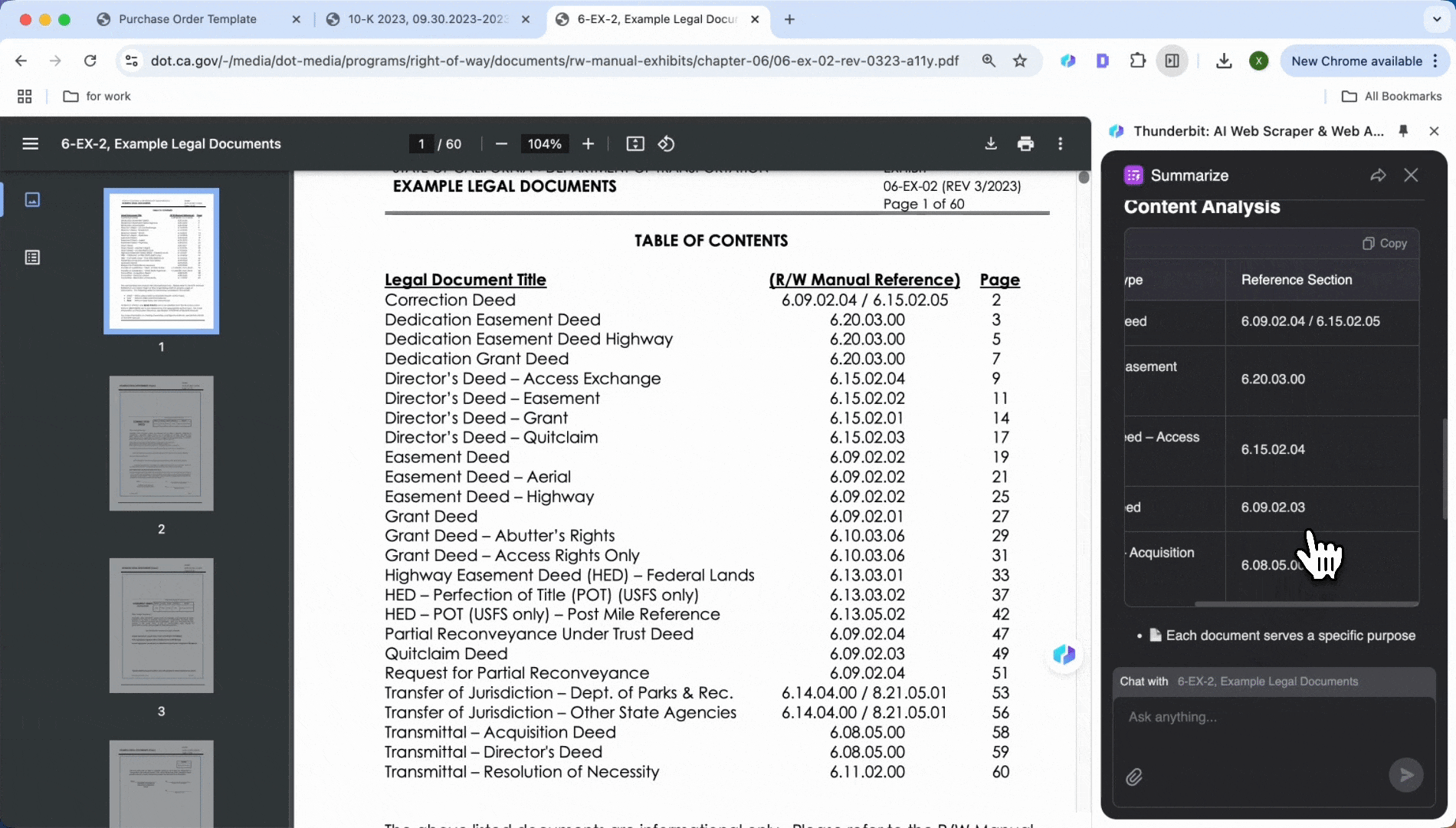
- 点击 Summarize
- 自动生成关键信息摘要,包括文本和表格内容
如果对自动生成的摘要不满意,也可以手动输入你想提取的项目。
- 在 Chrome 中打开财务报告,并启动
- 点击 AI Web Scraper,输入你想提取的项目名称,例如 Net Income、Sales 等
- 点击 Scrape,输出表格
法律文档分析
如果你经常需要阅读合同和协议条款,AI 工具可以快速定位付款条款、违约条款、合同期限等重点内容。只需一次点击,就能生成简洁摘要或条款列表,既节省时间,也能减少遗漏。
和提取财务报告关键信息类似,你可以打开 PDF 后点击 Summarize,一键查看付款条款、违约条款、合同期限等核心信息。
常见问题
-
可以一次从多个 PDF 中提取数据吗?
可以。高级 PDF 抓取工具通常支持同时从多个 PDF 中提取数据。相比手动处理,批量处理能力可以显著提升工作效率。
-
PDF Scraper 是免费的吗?
是的,目前有不少免费的 PDF Scraper 工具可用。例如 和 都提供一定的免费页面提取和数据提取功能。部分高级功能可能需要付费,但基础数据提取能力通常可以免费使用。
-
使用 PDF Scraper 需要会编程吗?
不需要。许多 AI PDF Scraper,比如 ,都是为非技术用户设计的。你只需要上传文件并点击几下,就能完成数据提取。
-
PDF Scraper 可以处理哪些类型的文档?
PDF Scraper 可以处理多种文档,包括发票、合同、财务报告、学术论文,以及其他包含结构化或半结构化内容的 PDF 文件。
-
使用 PDF Scraper 时,我的数据安全吗?
可靠的 PDF Scraper 通常会重视用户数据安全,并遵守 GDPR 等隐私法规。它们一般会将数据存储在加密服务器中,并且不会在未经许可的情况下访问你的数据。
-
除了 PDF Scraper,还有其他方法可以从 PDF 中提取数据吗?
有。除了手动录入和 Python 脚本之外,还可以使用 PDF 转换器将文件转换为 Excel 或 CSV;使用 Tabula、Excalibur 等专门面向结构化文档的 PDF 数据提取工具;使用带 OCR 能力的 AI 方案处理原生 PDF 和扫描件;也可以使用 Extractous、PymuPDF4llm 等开源工具进行高效提取。不同方法各有优缺点,具体选择取决于你的需求和技术能力。
延伸阅读