

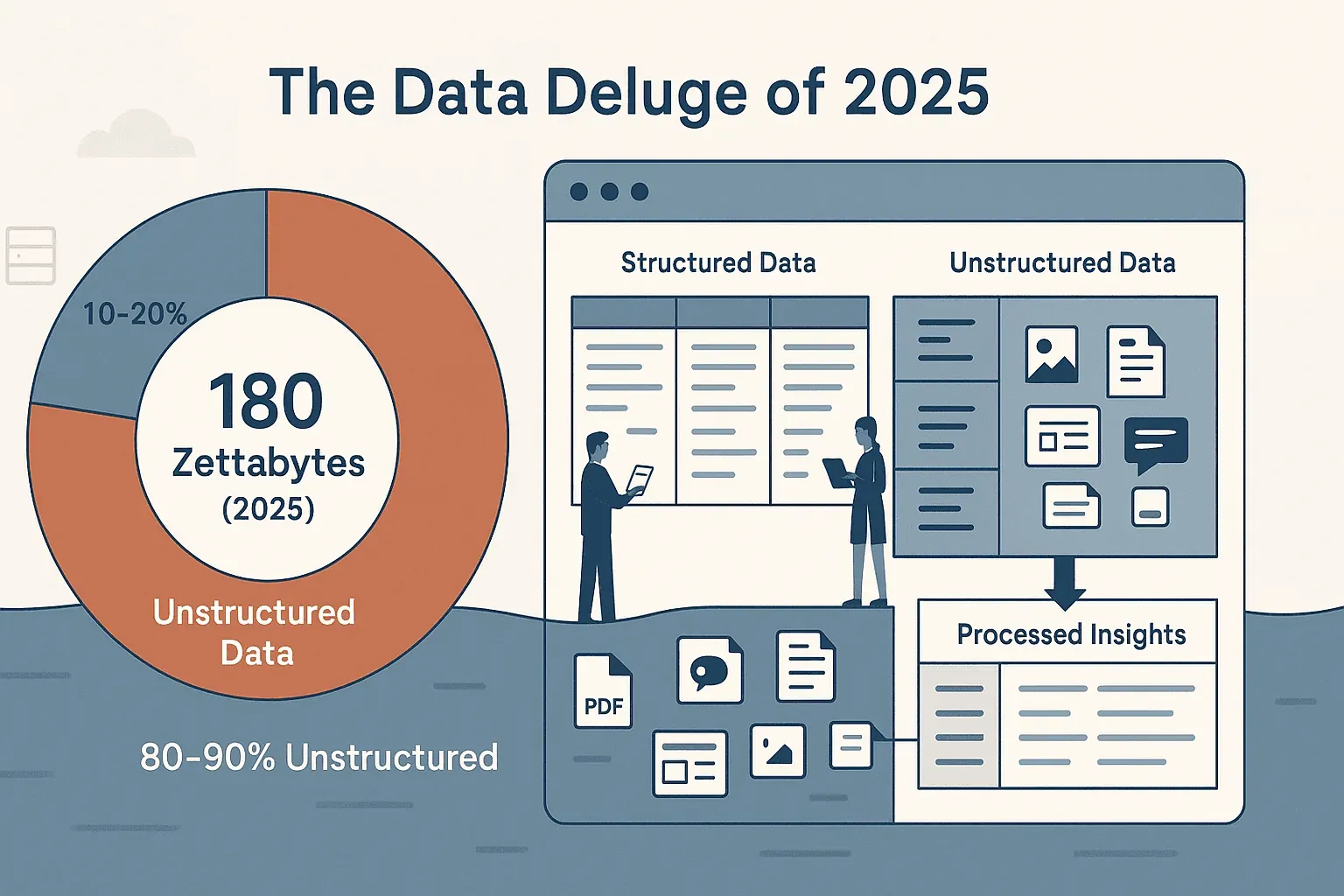
如果你曾经试着从网站收集数据——不管是销售线索、竞品价格,还是整理一团乱的产品目录——你就会知道,网页天生就不是为了让你轻松复制粘贴而设计的。线上数据的规模大得惊人——IDC 和 Statista 估算,全球数据总量在 2025 年约为 180 ZB,而到 2026 年有望达到 221 ZB 左右。更麻烦的不是体量,而是形式:大约 80% 的数据是非结构化的,散落在网页、PDF、图片和动态数据流里。包括我在内,大多数业务团队都花了太多时间和这团乱麻较劲,最后只换来半成品表格,以及一种似曾相识的疲惫感。
用 AI 从任何网站抓取数据 Get Started Free
这也是我为什么这么迷高效网站抓取。在这篇指南里,我会带你用 Thunderbit——我们的 AI 网页爬虫——一步步抓取任何网站,而且不用写代码,也不会让你头疼。不管你是做销售、运营,还是单纯受够了手动录入,我都会演示怎么处理复杂布局、分页、子页面,甚至从 PDF 和图片中提取数据。让我们把网页上的混乱,变成你的下一项业务优势。
高效抓取网站到底是什么意思?
先拆开来说:抓取网站,就是用自动化工具(可以把它理解成一个机器人助手)系统性地访问网页,并提取你关心的信息——姓名、价格、邮箱、产品规格,等等。高效抓取不只是快;它还意味着准确、尽量少的人工操作,以及能处理真实网页里的各种障碍,比如分页、子页面和非结构化数据(Wikipedia)。
高效抓取和一轮又一轮复制粘贴的区别是什么?关键就在这些地方:
- 速度: 几分钟内抓完成百上千页或记录,而不是花几个小时。
- 准确性: 精准抓取你需要的数据,不漏项,也不带进错别字。
- 自动化: 让工具处理“下一页”点击、跳转详情页这类重复工作。
- 适应性: 能应对复杂布局、动态内容,甚至网站结构变化。
- 低门槛: 不用写代码,不用调选择器,也不用频繁维护。
现实世界里并没有完美的表格。现代网站常常有无限滚动、多步导航、登录要求,以及藏在 PDF 或图片里的数据。高效抓取,就是把这些难题一一解决——这样你就能少做体力活,把更多时间放在分析和决策上(AIMultiple)。
为什么高效网站抓取对销售和运营很重要
为什么业务团队这么看重网站抓取?因为合适的数据——而且要快——往往决定了下一次营销活动、产品发布,甚至销售季度的成败。下面是我每周都会看到的一些最常见、也最有回报的用例:
| 用例 | 收益与投资回报 | 示例结果 |
|---|---|---|
| 线索开发 | 更快填满销售漏斗,节省调研潜在客户的时间,减少人工错误 | 一夜抓取 5,000 个精准线索,活动提前 2 周启动,约见量提升 30% |
| 竞品价格监控 | 支持动态定价,实时应对市场变化,保护利润率 | 零售商每天调整价格,销售额增长 4% |
| 产品目录/库存提取 | 让商品信息保持最新,减少手动录入,避免超卖或定价错误 | 电商团队每天更新 10,000 个 SKU,更新时间缩短 90% |
| 市场研究与评论分析 | 大规模洞察客户情绪和趋势,在竞争对手之前发现机会 | 分析 10,000+ 条评论,识别新产品机会,优化营销文案 |
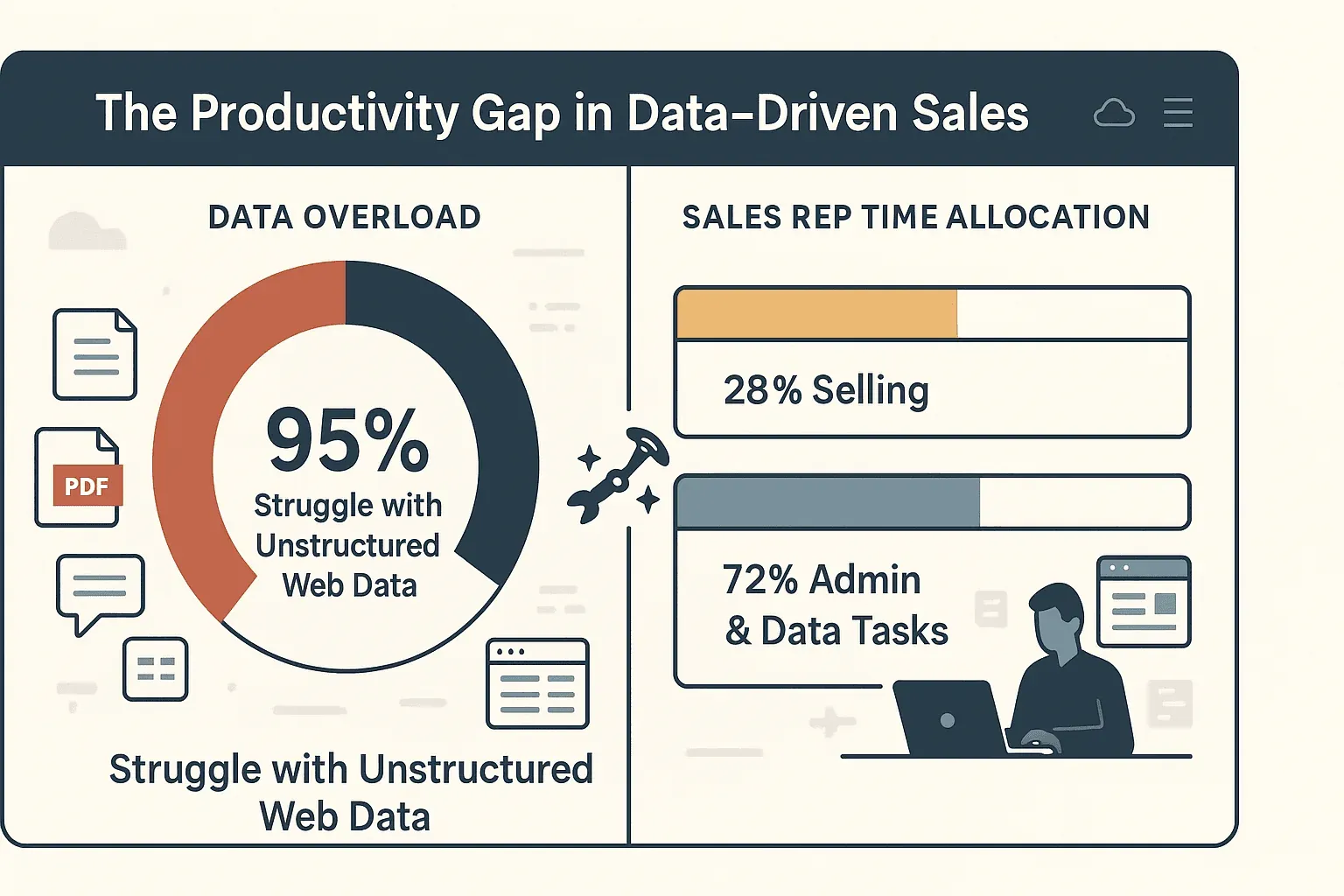
一句话总结:高效抓取能让决策更快、更聪明,而且能大幅减少复制粘贴的时间。事实上,95% 的企业 都承认自己难以利用非结构化网页数据,而销售人员真正用于销售的时间只有 28%。其余时间都耗在了手动录入和行政事务上。
Thunderbit:抓取网站最简单的方式
说实话:大多数网页爬虫工具都是给开发者做的,不是给业务用户做的。这也是我们打造 Thunderbit 的原因——一款 AI 网页爬虫,简单得就像点外卖一样。Thunderbit 的不同之处在于:
- 自然语言提示: 你只要描述想要的数据(比如“抓取这个页面上的所有产品名称和价格”),Thunderbit 的 AI 就会自动处理剩下的事情。
- AI 推荐字段: 点击“AI 推荐字段”,Thunderbit 会扫描页面,推荐最适合提取的列,并帮你完成爬虫配置。
- 2 步工作流: 字段满意后,点击“抓取”就行——无需代码、无需模板、无需和选择器死磕。
- 支持分页和子页面: Thunderbit 会自动识别并导航多页列表,还可以跟随链接进入详情页(子页面)来丰富你的数据。
- 即时导出: 可将数据直接发送到 Excel、Google Sheets、Airtable 或 Notion,也可以免费导出为 CSV/JSON。
- 支持 PDF 和图片 OCR: 需要从 PDF、图片或扫描文档中获取数据?Thunderbit 内置的 OCR 也能提取并结构化这些内容。
Thunderbit 是为非技术用户设计的——只要你会浏览网页、会输入一句话,就能像专业人士一样抓取网站。当然,我们还有 免费套餐,你可以零风险试用。
网站抓取方案对比:Thunderbit vs. 传统方式
我们把 Thunderbit 和常见方案放在一起对比一下:
| 方式 | 设置时间与复杂度 | 所需技能 | 维护与可靠性 |
|---|---|---|---|
| 手动复制粘贴 | 极高,无法规模化 | 不需要,但容易出错 | 100% 手工,每次更新都要重做 |
| 自定义代码(Python 等) | 初始设置成本高,每个网站都要花数小时/数天 | 需要编程能力 | 网站一变就坏,需要持续修复 |
| 传统无代码工具 | 中等,可点选式配置 | 低/中等 | 布局变动就要更新,且不一定能处理动态网站 |
| Thunderbit(AI 驱动) | 很低,2 步即可完成 | 不需要 | AI 可适应变化,维护成本极低 |
传统工具也许能帮你走到一半,但它们常常会在动态内容、分页上卡住,或者需要你一直盯着每一次变化。Thunderbit 的 AI 会像人一样读取网站,适应新的布局,还能处理那些麻烦事——所以你不用再操心(Thunderbit Blog)。
第 1 步:使用 Thunderbit 设置你的网站抓取任务
上手非常简单:
- 安装 Thunderbit Chrome 扩展。 注册一个免费账号。
- 进入目标网站。 打开你想抓取的页面——可以是商品列表、目录,甚至 PDF。
- 打开 Thunderbit。 点击 Chrome 工具栏里的 Thunderbit 图标。
- 描述你的数据需求。 你可以点击“AI 推荐字段”让 Thunderbit 帮你推荐列,也可以直接输入自然语言提示词(例如:“提取每个商品的名称、价格和图片链接”)。
- 预览并调整。 Thunderbit 会显示预览表格——你可以编辑字段名、删除多余字段,或按需添加自定义指令。
小贴士:提示词要具体,但保持简洁。把网站上实际出现的数据点说清楚(比如“价格”“地址”等),剩下的交给 Thunderbit 的 AI 来处理。
第 2 步:在网站抓取过程中处理分页和子页面
这正是 Thunderbit 真正出彩的地方。现实中的大多数数据并不只在一个页面上,而是分布在分页列表里,或者藏在子页面中。
- 分页: Thunderbit 会自动识别“下一页”按钮、页码或无限滚动。点击“抓取”后,它会持续加载页面,直到把所有内容都抓完——你无需手动输入 URL,也不用一页页点过去。
- 子页面抓取: 想要更多细节?先抓主列表,再点击“抓取子页面”。Thunderbit 会跟随链接(比如商品详情页或公司主页),提取额外信息,并把它合并到你的表格里。
示例: 在抓一个电商网站?Thunderbit 会先抓商品列表,再访问每个商品的详情页,提取规格、评论或图片——一气呵成。
最佳实践:先让 Thunderbit 完成主抓取,再用子页面抓取获取更深层的数据。你会看到进度更新,也可以检查是否有缺失记录。
第 3 步:用 Thunderbit 智能提取非结构化数据
并不是所有数据都会整整齐齐地排成表格。产品描述、评论,或混合格式字段,对传统爬虫来说都可能是噩梦。Thunderbit 的 AI 会正面解决这些问题:
- 清洗并格式化数据: 去掉货币符号、解析数字,并拆分复杂字段(例如把“USD 299(立减 50%!)”拆成“299”和“立减 50%”)。
- 解析复杂文本: 从段落中提取结构化信息(例如在职位描述里找到“地点:纽约”)。
- 分类与标注: 根据内容添加分类或标签(例如“电子产品”与“服装”)。
- 处理不一致性: 适应缺失字段或布局变化,保持数据对齐和准确。
- 总结或翻译: 需要一句话摘要或翻译?加一条自定义指令就行——Thunderbit 的 AI 也能做到。
结果就是:干净、可直接使用的数据——再也不用花几个小时在 Excel 里收拾烂摊子。
第 4 步:在云端抓取和浏览器抓取之间做选择
Thunderbit 根据你的需求提供两种抓取方式:
- 浏览器抓取: 在你的 Chrome 浏览器中运行,使用你当前登录的会话。非常适合需要登录或有强反爬限制的网站。你可以实时看到抓取过程,它也会尽量模拟人工浏览。
- 云端抓取: 将任务交给 Thunderbit 的云端服务器。可并行处理最多 50 个页面——非常适合大批量任务或定时任务。你可以合上笔记本,让 Thunderbit 替你完成重活。
何时使用哪一种:
- 对需要登录的网站,或需要和页面互动时,使用 浏览器模式。
- 对公开网站、批量任务,或想要更快更自动化时,使用 云端模式。
切换模式很简单——在开始抓取前选择你的偏好即可。
第 5 步:使用 OCR 从文档和图片中提取数据
有时候,你需要的数据被困在 PDF、图片或扫描文档里。Thunderbit 内置的 OCR(光学字符识别)会让这件事变得完全不同:
- PDF: 从报告、发票或目录中提取表格、邮箱或文本。
- 图片: 从截图、产品标签,甚至信息图中提取文字。
- 扫描表单: 自动录入收据、合同或名片中的数据。
只要把 Thunderbit 指向 PDF 或图片链接,它就会提取并结构化内容——无需额外软件。你甚至可以把 OCR 和 AI 提示词结合起来做高级提取(例如:“找出这份 PDF 中所有邮箱地址”)。
第 6 步:导出并使用你抓取到的数据
抓取完成后,就该把数据用起来了:
- 导出选项: 可下载为 CSV 或 JSON,也可以直接导出到 Google Sheets、Excel、Airtable 或 Notion。所有格式免费提供——即使是基础套餐也可以。
- 销售与 CRM: 把线索列表导入 CRM,发起外联活动,或丰富已有联系人信息。
- 营销与分析: 分析竞品定价、追踪市场趋势,或在仪表盘中可视化数据。
- 运营与库存: 监控库存、更新目录,或在关键变化发生时触发提醒。
- 自动化: 使用集成工具(比如 Zapier 或 Google Apps Script)自动完成跟进、报告或数据补充。
Thunderbit 的结构化输出意味着,你可以在几分钟内从抓取直接进入行动,而不是等上几天。
结论与核心要点
高效抓取网站不只是技术宅的梦想——它还是一种业务超能力。有了 Thunderbit,任何人都可以:
- 在几秒内完成抓取设置,使用自然语言或 AI 推荐字段。
- 处理复杂网站,包括分页、子页面和动态内容——无需代码。
- 从杂乱的网页、PDF 和图片中提取干净、结构化的数据。
- 根据速度、规模和安全性选择最佳模式(浏览器或云端)。
- 把数据即时导出到你喜欢的工具和工作流中。
无休止复制粘贴和失灵爬虫的时代已经结束。下载 Thunderbit,试一次免费抓取,看看你能节省多少时间(以及多少精力)。你的下一个重大洞察——或者销售胜利——可能只差一次点击。
想了解更多技巧和深度解析?欢迎查看 Thunderbit 博客,获取教程、应用案例,以及最新的 AI 网页抓取内容。
常见问题
1. 网页抓取和网页爬取有什么区别?
网页爬取指的是系统性浏览网站、发现页面和链接;而网页抓取则是从这些页面中提取具体数据。Thunderbit 把两者结合在一起——既能发现和导航,也能提取你需要的信息。
2. Thunderbit 能处理需要登录的网站吗?
可以!使用 Thunderbit 的浏览器模式,就能抓取需要身份验证的网站。它会使用你已登录的 Chrome 会话,因此你可以访问登录后或付费墙后的数据(前提是符合网站服务条款)。
3. Thunderbit 如何处理分页和无限滚动?
Thunderbit 会自动检测并导航分页列表和无限滚动页面。它会点击“下一页”、滚动页面或加载更多内容,直到抓取到所有数据——无需手动设置。
4. Thunderbit 可以提取哪些类型的数据?
Thunderbit 可以提取文本、数字、日期、URL、邮箱、电话号码、图片,甚至还能通过 OCR 从 PDF 和图片中提取数据。你还可以自定义字段,并使用 AI 提示词做高级结构化和清洗。
5. Thunderbit 可以免费使用吗?
Thunderbit 提供免费套餐,可抓取有限数量的页面。所有导出格式(CSV、Excel、Google Sheets、Airtable、Notion)都免费包含在内。付费套餐从每月 15 美元起,可获得更高额度和高级功能。
准备好更聪明地抓取,而不是更费力地抓取了吗?今天就试试 Thunderbit,让 AI 为你的下一个网页数据项目承担重活。 了解更多
免费试用 AI 网页爬虫 Get Started Free




