
The web is growing at a pace that’s honestly hard to wrap your head around. As of 2024, we’re talking about over 1.1 billion websites, with 149 zettabytes of data floating around (and projected to hit 181 ZB by next year). That’s a lot of pizza menus. But here’s the kicker: only about 4% of online content is indexed by search engines. The rest is the “deep web,” hidden from our everyday searches. So, how do search engines and businesses make sense of this digital jungle? Enter the web crawler.
In this guide, I’ll break down what web crawling is, how it works, and why it matters—not just for techies, but for anyone who wants to tap into the vast world of online data. We’ll also clear up the difference between web crawling and web scraping (trust me, they’re not the same thing), explore real-world use cases, and walk through both code-based and no-code solutions (including my favorite, Thunderbit). Whether you’re a curious beginner or a business user looking to get more from the web, you’re in the right place.
What is a Web Crawler? Understanding the Basics of Web Crawling
Let’s start simple. A web crawler (sometimes called a spider, bot, or website crawler) is an automated program that systematically browses the web, fetching pages and following links to discover new content. Imagine a robot librarian who starts with a list of books (URLs), reads each one, and then follows every reference to find even more books. That’s basically how a crawler works—except instead of books, it’s web pages, and instead of a library, it’s the entire internet.
Here’s the core idea:
- Start with a list of URLs (called “seeds”)
- Visit each page, download its content (HTML, images, etc.)
- Find hyperlinks on those pages, add them to the queue
- Repeat—visit new links, discover more pages, and so on
The main job of a web crawler is to discover and catalog pages. In the context of search engines, crawlers copy page contents and send them back to be indexed and analyzed. In other scenarios, specialized crawlers might extract specific data points (which is where web scraping comes in—but more on that in a minute).
Key takeaway:
Web crawling is about finding and mapping the web, not just grabbing data. It’s the backbone of how search engines like Google and Bing know what’s out there.
How Does a Search Engine Work? The Role of Crawlers
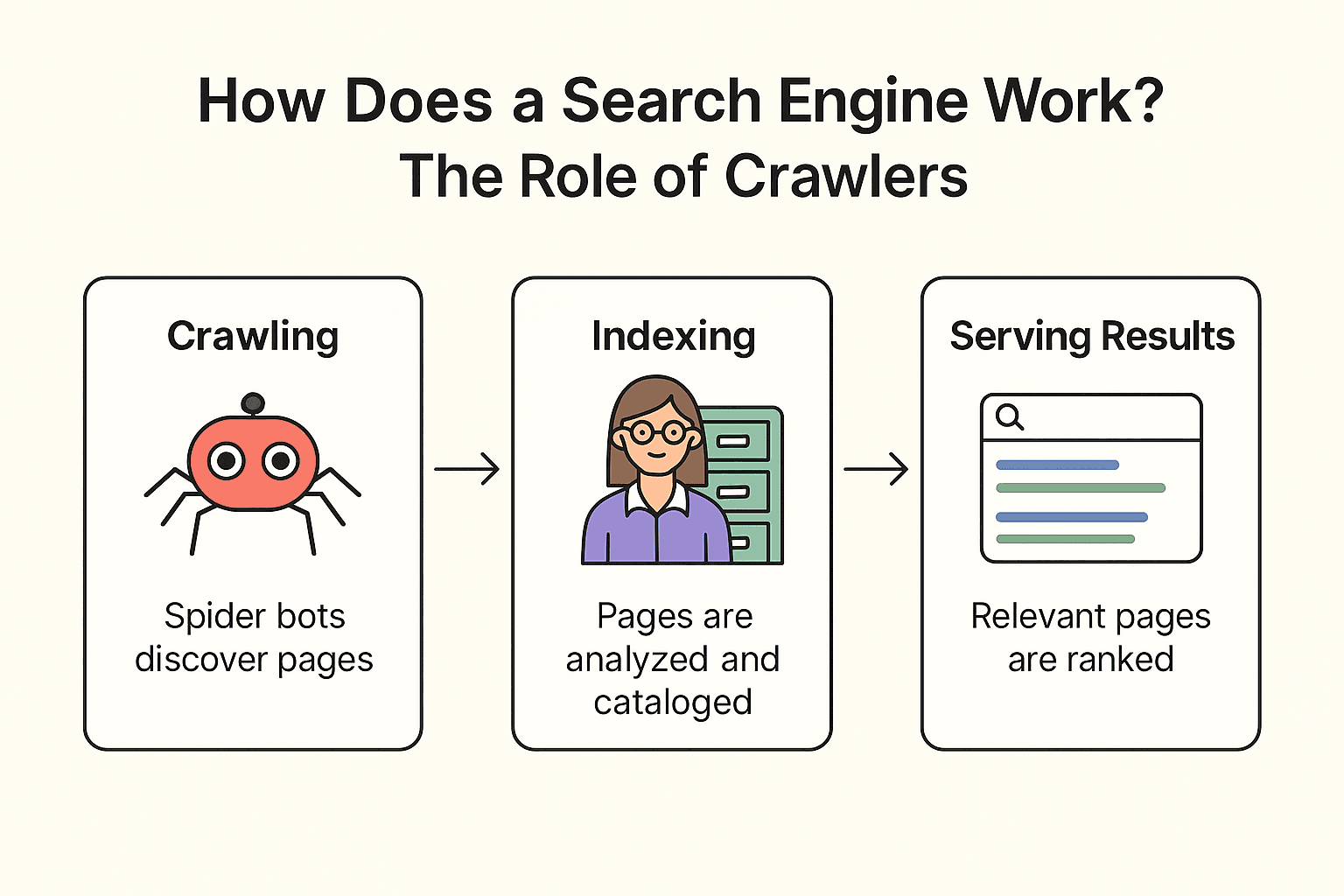
So, how does Google (or Bing, or DuckDuckGo) actually work? It’s a three-step process: crawling, indexing, and serving results (Google’s official docs).
Let’s use a library analogy (because who doesn’t love a good book metaphor?):
-
Crawling:
The search engine sends out its “spider bots” (like Googlebot) to explore the web. They start with known pages, fetch their content, and follow links to discover new pages—just like a librarian checking every bookshelf and following footnotes to find more books.
-
Indexing:
Once a page is found, the search engine analyzes its content, figures out what it’s about, and stores key info in a giant digital card catalog (the index). Not every page makes the cut—some are skipped if they’re blocked, low-quality, or duplicates.
-
Serving Results:
When you search for “best pizza near me,” the search engine looks up relevant pages from its index and ranks them based on hundreds of factors (like keywords, popularity, freshness). The result? A neatly ordered list of web pages, ready for you to browse.
Fun fact:
Search engines don’t crawl every page on the web. Pages behind logins, blocked by robots.txt, or with no inbound links might never be discovered. That’s why businesses sometimes submit their URLs or sitemaps directly to Google.
Web Crawling vs. Web Scraping: What’s the Difference?
Here’s where things get spicy. People often use “web crawling” and “web scraping” interchangeably, but they’re actually quite different.
| Aspect | Web Crawling (Spidering) | Web Scraping |
|---|---|---|
| Goal | Discover and index as many pages as possible | Extract specific data from one or more webpages |
| Analogy | Librarian cataloging every book in a library | Student copying key notes from a few relevant books |
| Output | List of URLs or page content (for indexing) | Structured dataset (CSV, Excel, JSON) with targeted info |
| Used by | Search engines, SEO auditors, web archivers | Business teams in sales, marketing, research, etc. |
| Scale | Massive (millions/billions of pages) | Focused (tens, hundreds, or thousands of pages) |
In plain English:
- Web crawling is about finding pages (mapping the web)
- Web scraping is about grabbing the data you want from those pages (extracting info into a spreadsheet)
Most business users (especially in sales, ecommerce, or marketing) are actually more interested in scraping—getting structured data for analysis—than in crawling the whole web. Crawling is foundational for search engines and large-scale discovery, while scraping is about targeted data extraction.
Why Use a Web Crawler? Real-World Business Applications
Web crawling isn’t just for search engines. Businesses of all sizes use crawlers and scrapers to unlock valuable insights and automate tedious tasks. Here are some real-world applications:
| Use Case | Target User | Expected Benefit |
|---|---|---|
| Lead Generation | Sales teams | Automate prospecting, fill CRM with fresh leads |
| Competitive Intelligence | Retail, e-commerce | Monitor competitor prices, stock, and product changes |
| SEO & Website Auditing | Marketing, SEO teams | Find broken links, optimize site structure |
| Content Aggregation | Media, research, HR | Gather news, job postings, or public datasets |
| Market Research | Analysts, product teams | Analyze reviews, trends, or sentiment at scale |
- Groupon doubled its inbound leads by automating lead generation with web crawling.
- 82% of e-commerce organizations and 71% of financial services firms rely on web scraping for decision-making.
- Web scraping can cut 90% of infrastructure costs and 60% of time compared to manual data collection.
Bottom line: If you’re not leveraging web data, your competitors probably are.
Coding a Web Crawler with Python: What You Need to Know
If you’re comfortable with code, Python is the go-to language for building custom web crawlers. The basic recipe:
- Use requests to fetch web pages
- Use BeautifulSoup to parse HTML and extract links/data
- Write loops (or recursion) to follow links and crawl additional pages
Pros:
- Maximum flexibility and control
- Can handle complex logic, custom data flows, and integration with databases
Cons:
- Requires programming skills
- Maintenance headache: if the website changes its layout, your script might break
- Need to handle anti-bot measures, delays, and error handling yourself
Beginner-friendly Python crawler example:
Here’s a simple script that fetches quotes and authors from quotes.toscrape.com:
import requests
from bs4 import BeautifulSoup
url = "<http://quotes.toscrape.com/page/1/>"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
for quote in soup.find_all('div', class_='quote'):
text = quote.find('span', class_='text').get_text()
author = quote.find('small', class_='author').get_text()
print(f"{text} --- {author}")
To crawl multiple pages, you’d add logic to find the “Next” button and loop until you run out of pages.
Common pitfalls:
- Not respecting robots.txt or crawl delays (don’t be that person)
- Getting blocked by anti-bot systems
- Accidentally crawling infinite loops (like calendar pages that go on forever)
Step-by-Step Guide: How to Build a Simple Web Crawler with Python
If you want to roll up your sleeves and try coding, here’s a step-by-step outline for a basic crawler.
Step 1: Setting Up Your Python Environment
First, make sure you have Python installed. Then, install the necessary libraries:
pip install requests beautifulsoup4
If you run into issues, double-check your Python version (python --version) and that pip is working.
Step 2: Writing the Core Crawler Logic
Here’s a basic pattern:
import requests
from bs4 import BeautifulSoup
def crawl(url, depth=1, max_depth=2, visited=None):
if visited is None:
visited = set()
if url in visited or depth > max_depth:
return
visited.add(url)
print(f"Crawling: {url}")
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# Extract links
for link in soup.find_all('a', href=True):
next_url = link['href']
if next_url.startswith('http'):
crawl(next_url, depth + 1, max_depth, visited)
start_url = "<http://quotes.toscrape.com/>"
crawl(start_url)
Tips:
- Limit crawl depth to avoid infinite loops
- Track visited URLs to avoid revisiting the same page
- Respect robots.txt and add delays (time.sleep(1)) between requests
Step 3: Extracting and Saving Data
To save data, you can write to a CSV or JSON file:
import csv
with open('quotes.csv', 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(['Quote', 'Author'])
# Inside your crawl loop:
writer.writerow([text, author])
Or use Python’s json module for JSON output.
Key Considerations and Best Practices for Web Crawling
Web crawling is powerful, but with great power comes great responsibility (and the risk of getting your IP banned). Here’s how to stay on the right side of the line:
- Respect robots.txt: Always check and honor a site’s robots.txt file. It tells you what’s off-limits.
- Crawl gently: Add delays between requests (at least a few seconds). Don’t overload servers.
- Limit scope: Only crawl what you need. Set depth and domain limits.
- Identify yourself: Use a descriptive User-Agent string.
- Follow the law: Don’t scrape private or sensitive info. Stick to public data.
- Be ethical: Don’t copy entire websites or use scraped data for spam.
- Test slowly: Start with a small crawl, then scale up if all goes well.
For more, check out this best practices guide.
When to Choose Web Scraping Instead: Thunderbit for Business Users
Scrape data from any website using AI Get Started Free
Here’s my honest take: unless you’re building your own search engine or need to map entire site structures, most business users are better off with web scraping tools.
That’s where Thunderbit comes in. As the co-founder and CEO, I might be a little biased, but I genuinely believe Thunderbit is the easiest way for non-technical users to extract web data.
Why Thunderbit?
- Two-click setup: Click “AI Suggest Fields” and then “Scrape”—that’s it.
- AI-powered: Thunderbit reads the page and suggests the best columns to extract (product names, prices, images, you name it).
- Bulk & PDF support: Scrape data from current pages, bulk URLs, or even PDFs.
- Flexible export: Download as CSV/JSON, or send directly to Google Sheets, Airtable, or Notion.
- No code required: If you can use a browser, you can use Thunderbit.
- Subpage scraping: Need more detail? Thunderbit can visit subpages and enrich your data automatically.
- Scheduling: Set up recurring scrapes in plain English (e.g., “every Monday at 9am”).
Try Thunderbit Chrome Extension for Free
When should you use a crawler instead?
If your goal is to map an entire website (like building a search index or a sitemap), a crawler is the right tool. But if you just want structured data from specific pages (like product listings, reviews, or contact info), scraping is faster, easier, and more practical.
Conclusion & Key Takeaways
Let’s wrap it up:
- Web crawling is how search engines and big data projects discover and map the web. It’s about breadth—finding as many pages as possible.
- Web scraping is about depth—extracting the specific data you care about from those pages. Most business users need scraping, not crawling.
- You can code your own crawler (Python is great for this), but it takes time, skill, and maintenance.
- No-code and AI-powered tools like Thunderbit make web data extraction accessible to everyone—no programming required.
- Best practices matter: Always crawl and scrape responsibly, respect website rules, and use data ethically.
If you’re just starting out, pick a simple project—maybe scrape some product prices or collect leads from a directory. Try a tool like Thunderbit for a quick win, or experiment with Python if you want to learn the nuts and bolts.
The web is a goldmine of information. With the right approach, you can unlock insights that drive smarter decisions, save time, and keep your business a step ahead.
Start Scraping with Thunderbit
FAQ
- What’s the difference between web crawling and web scraping?
Crawling finds and maps pages. Scraping pulls specific data from them. Crawling = discovery; scraping = extraction.
- Is web scraping legal?
Scraping public data is usually okay if you follow robots.txt and terms of service. Avoid private or copyrighted content.
- Do I need to code to scrape websites?
No. Tools like Thunderbit let you scrape with clicks and AI—no coding needed.
- Why isn’t the whole web indexed by Google?
Because most of it is behind logins, paywalls, or blocked. Only about 4% is actually indexed.
Further reading
- FreeCodeCamp – Web Scraping with Python and BeautifulSoup
- Scrapy Official Tutorial
- Real Python – How to Use Selenium and Python for Web Scraping
- Apify Academy: Web Scraping and Automation
Try AI Web Scraper Get Started Free




