

Amazon 的目录里有近 200 万个卖家合作伙伴和数亿件商品。如果你曾经试着把商品标题、价格、评分和 ASIN 手动复制到表格里,你一定知道那有多痛苦——而且一旦规模上来,问题会立刻被放大。
我在 Thunderbit 工作,我们做的是 AI 网页爬虫,所以我平时一直很关注大家是怎么从网站提取数据的。但这次写这篇文章,我想做一件别的综述很少会做的事:把 7 个你真的可以安装、并在 Amazon 上直接跑的 Chrome 扩展放到一起,在同样的页面上测试,然后直接告诉你哪些能用、哪些不行、每个工具适合什么场景。我从 8 个维度评估了每个扩展,这些维度都正好对应论坛里和我们用户最常提到的痛点——比如 AI 字段识别、子页面抓取、封号风险、免费额度和导出选项。不管你是 Amazon 卖家、营销人员,还是单纯受够了复制粘贴的人,这篇指南都适合你。
为什么要先抓取 Amazon 商品数据?
那到底是谁在抓 Amazon?又为什么要抓?
简单来说,几乎所有在线销售、营销或研究商品的人都会这么做。Amazon 说,店铺里超过 60% 的销售额来自独立卖家,而这些卖家也一直在互相观察。以下是我最常见到的使用场景:
| 使用场景 | 使用者 | 能得到什么 |
|---|---|---|
| 竞争对手价格监控 | 卖家、定价团队、代理机构 | 竞品的实时价格和库存可用性数据 |
| 商品研究与趋势追踪 | Amazon 卖家、市场研究人员 | 发现增长中的类目、新入局者和需求变化 |
| 评论情绪分析 | 白牌卖家、品牌团队 | 反复出现的抱怨、功能缺口和机会点 |
| 线索挖掘(卖家联系方式) | 批发团队、代理机构 | 卖家名称、店铺和联系信息 |
| 目录与库存监控 | 电商运营、品牌保护 | 跟踪库存水平、Listing 变化和未经授权的卖家 |
| 关键词与 Listing 优化 | 品牌方、平台运营者 | 搜索词数据、Listing 文案和竞品关键词 |
投入产出是实实在在的。Amazon 自己的案例研究显示,thefitguy 通过用结构化数据优化高频搜索词,季度销售额增长了 40% 以上。而 Parseur 的一项调查发现,员工每周要花 9 个多小时在重复性数据录入上。只要能把其中一部分自动化,你就能把大量时间腾出来,真正用于决策。
一个优秀的 Amazon 抓取 Chrome 扩展应该具备什么?(我的测试标准)
并不是所有 Chrome 扩展都一样——而且很多对比文章把 API、桌面应用和浏览器扩展混在一起,仿佛它们可以互换。其实并不能。下面是我使用的评估框架,以及每项标准为什么重要:
- 上手难度——非技术用户能不能在 5 分钟内拿到结果?(论坛也证实这确实是最核心的顾虑之一。)
- AI 字段识别——工具会不会自动识别商品字段,还是必须手动配置选择器?(几乎没有竞品会把它当成一个独立类别来讨论。)
- 子页面/详情页抓取——能不能在一个流程里把商品详情页的数据补充到列表数据中?
- 反爬/封号风险处理——它怎么应对 Amazon 激进的机器人检测?(用户论坛里的头号痛点。)
- 分页支持——能不能自动抓取多页结果?
- 免费额度/定价——不付费时到底能用什么?(用户会明确问有没有免费方案,而多数竞品都不给出实际可行的答案。)
- 导出选项——CSV、Excel、Google Sheets、Airtable、Notion?
- 定时与自动化——能不能设置成定期运行?
我在 Amazon 美国站的搜索结果页和商品详情页上测试了每个扩展,使用的是相同的查询和相同的条件。

AI 驱动抓取 vs. 选择器抓取:为什么这件事对 Amazon 特别重要
有一个区别,是其他 Amazon 抓取综述完全没提到的——但它也是决定你的爬虫后期维护成本的最大因素。
大多数 Chrome 扩展式爬虫,都是把 CSS 选择器映射到数据字段上。你(或者工具模板)把“价格”或“标题”对应到某个 HTML 元素,爬虫就把那里的内容抓下来。问题是?Amazon 会几乎每天更改底层 HTML 和 CSS,用来破坏爬虫。论坛用户把哈希化或不断变化的类名描述为一种常见故障模式。
下面是三种主要方案的对比:
| 方案 | 工作方式 | Amazon 调整页面布局时会怎样 |
|---|---|---|
| 基于选择器(传统) | 用户手动把 CSS 选择器映射到字段 | 会失效——用户必须重新配置 |
| 基于模板 | 预先为 Amazon 页面准备好的抓取规则 | 会失效,直到开发者更新模板 |
| AI 驱动(例如 Thunderbit) | AI 读取页面内容并自动识别字段 | 自动适应——无需维护 |
我测试的 7 个扩展里,只有一个——Thunderbit——默认就用 AI 字段识别。其他的都依赖选择器或模板,这意味着 Amazon 一旦改版,你就得付出更多维护成本。把这点弄明白,后面能少很多麻烦。
1. Thunderbit —— AI 驱动的 Amazon 抓取 Chrome 扩展
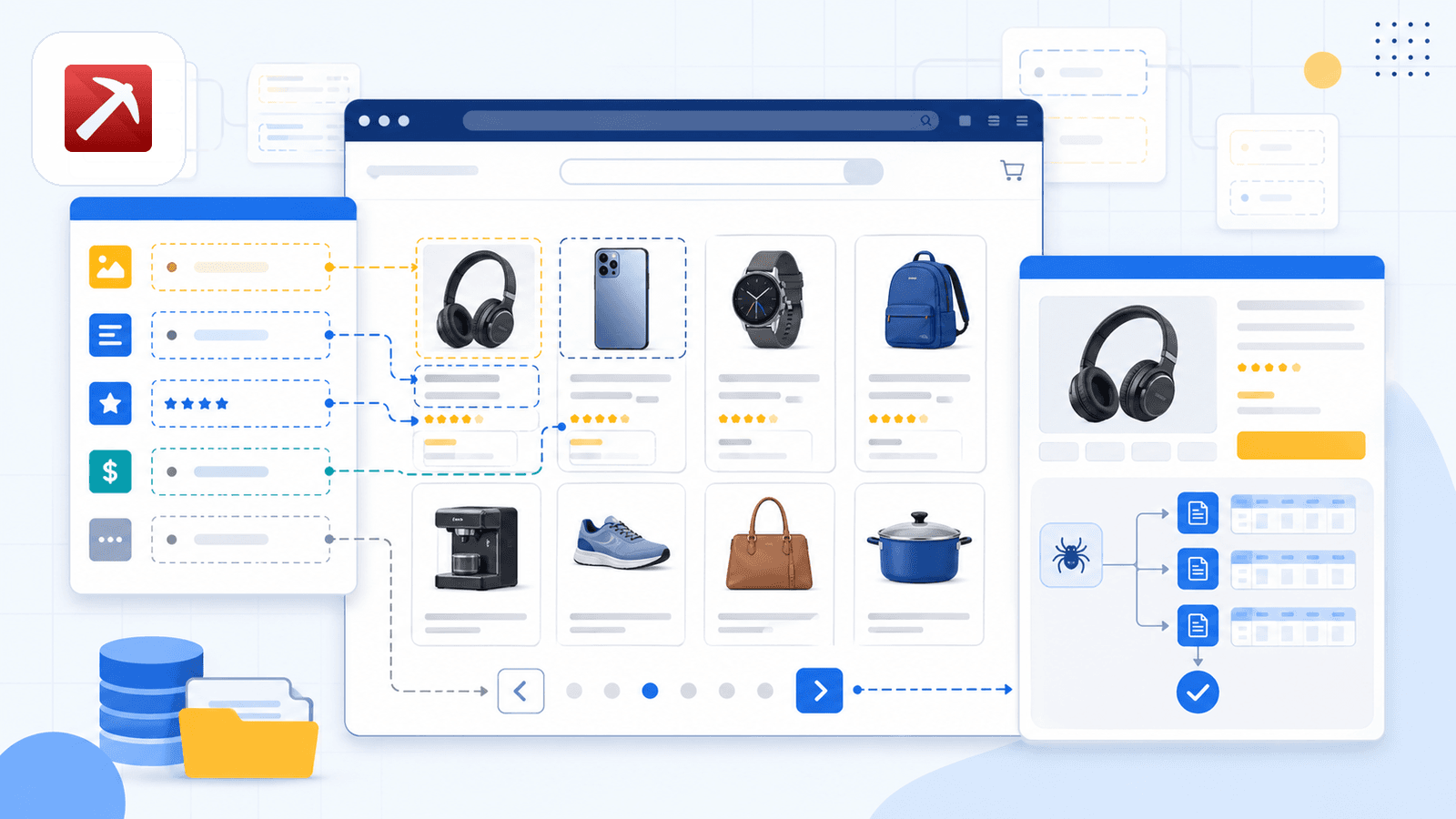
Thunderbit 是我们公司自己做的工具,所以我先说明这一点。但我也真心认为,它最适合那些不想折腾选择器或代码、却希望快速准确拿到 Amazon 数据的非技术用户。
它最核心的差异点是 AI Suggest Fields。当你打开 Amazon 搜索结果页并点击按钮时,Thunderbit 的 AI 会读取页面并推荐列名——标题、价格、评分、ASIN、评论数、商品 URL 等等。你不需要做任何配置。AI 会自己判断页面上有什么,然后建议合适的字段和数据类型。
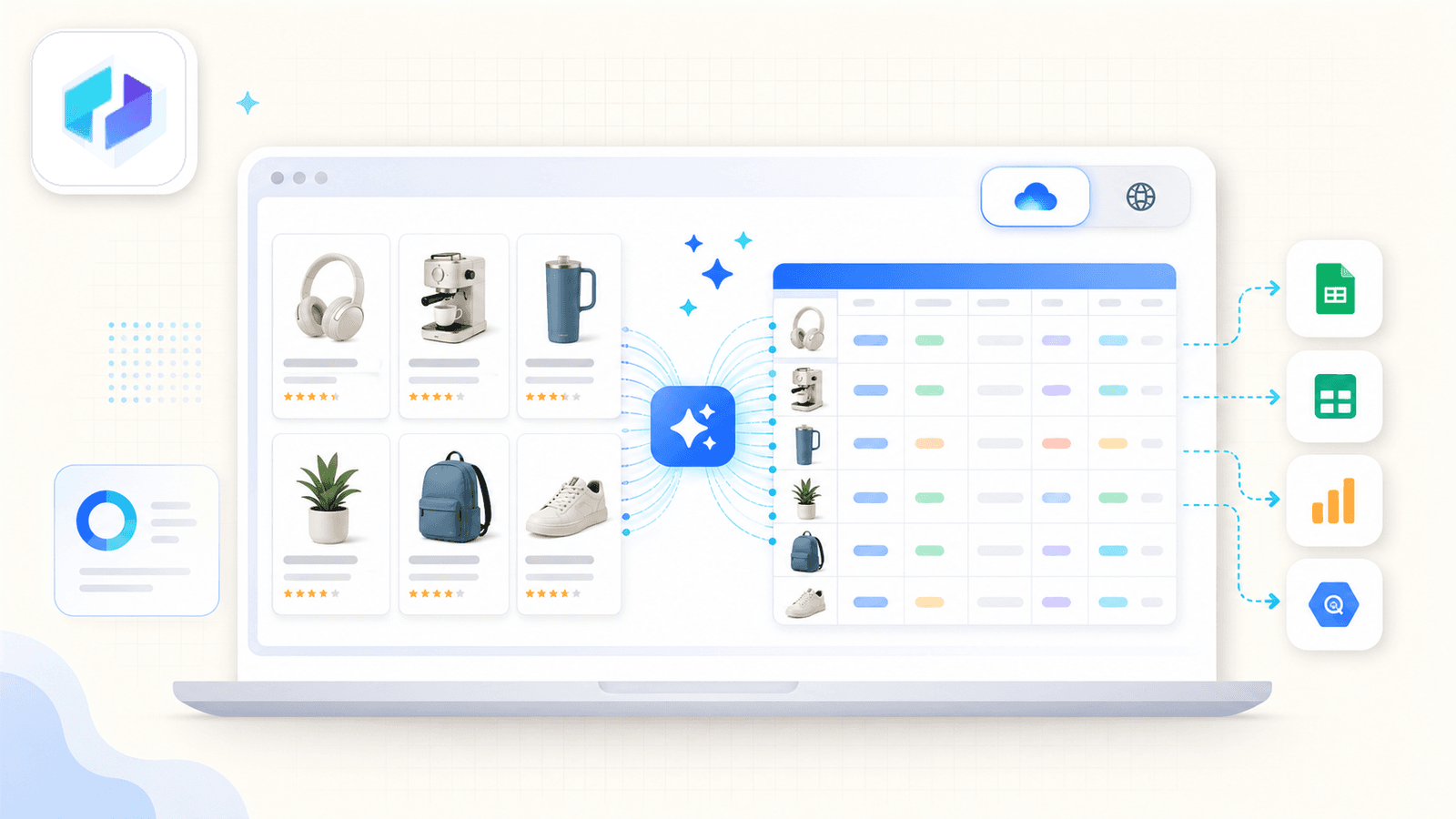
一次典型的 Amazon 抓取流程看起来是这样的:
- 安装 Thunderbit Chrome Extension,打开 Amazon 搜索结果页。
- 点击 AI Suggest Fields——AI 会自动识别并推荐列。
- 点击 Scrape——数据会立刻填充出来。
- 对于热门 Amazon 页面,你也可以直接使用预置的 Amazon Scraper Template,真正做到 1 次点击。
Thunderbit 真正突出的地方是 子页面抓取。在抓完列表页后,点击 Scrape Subpages——Thunderbit 会逐个访问每个商品 URL,并把详情字段(完整描述、要点、卖家信息、图片 URL)追加到同一张表里。大多数竞品扩展根本不提供这个能力。
它还有一个 云端/浏览器切换。云端模式最多可同时抓取 50 个公开页面;浏览器模式则使用你自己的 Chrome 会话——特别适合你登录了 Seller Central,或者需要更低调地运行时使用。
定时功能用的是自然语言:你直接描述时间间隔,AI 会把它转换成计划任务。
导出选项覆盖 Excel、Google Sheets、Airtable、Notion、CSV 和 JSON——免费版就包含这些。
Thunderbit 的优缺点
优点:
- AI 自动识别字段——无需配置选择器,Amazon 改版后也不用维护
- 一键补充子页面数据
- 云端/浏览器双模式,灵活且更低封号风险
- 导出选项最全(Sheets、Airtable、Notion、Excel、CSV、JSON)
- 支持自然语言定时
- 预置 Amazon 模板,可立即出结果
缺点:
- 采用积分制,重度用户最终还是需要付费方案
- AI 字段识别会多一个短暂处理步骤(几秒)
- 相比老牌工具,社区文档还少一些
Thunderbit 定价
- 免费版: 6 页(试用加成后 10 页),包含 AI 功能和所有导出格式
- 付费方案: 年付起价约 9 美元/月,含 500 积分;1 积分 = 1 行输出
- 最新详情见 Thunderbit 定价
用 AI 抓取 Amazon 页面 Get Started Free
2. Instant Data Scraper —— 免费、简洁的选择
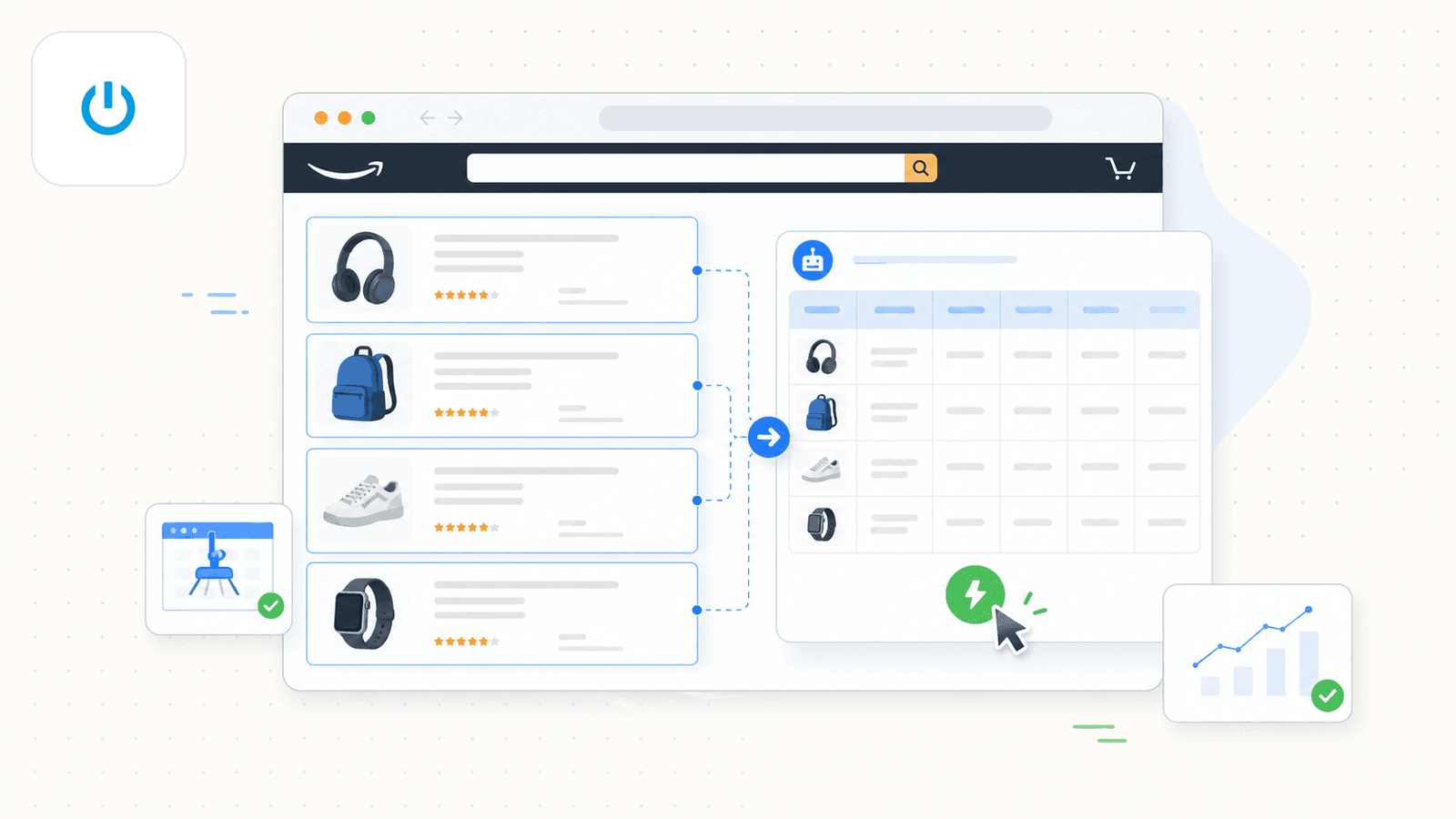
Instant Data Scraper 是一个 Chrome 扩展,它使用启发式算法自动识别网页中的表格数据。它已经存在很多年了,至今仍是 Chrome Web Store 上下载量最高的免费爬虫之一。
在 Amazon 上,你打开搜索结果页后启动扩展,它会尝试自动识别数据表。有时如果第一次识别不准,你需要点一下“try another table”。对于简单的一次性抓取,它的表现还算可以。
不过,2026 年有一个重要情况:它的官方落地页现在明确说明,Instant Data Scraper 已不再由 Web Robots 拥有、开发或支持。这意味着没有更新、没有 bug 修复,也没有新功能。在一个 Reddit 讨论串里,某位 用户反馈它可以处理概览页,但一旦需要点击进入详情级页面,就会卡住。
Instant Data Scraper 的优缺点
优点:
- 100% 免费,不需要账号
- 轻量、快速,适合简单表格
- 支持基础分页(点击“Next”按钮)
缺点:
- 没有 AI 字段识别(依赖模式匹配,容易误读 Amazon 的复杂布局)
- 不支持子页面抓取
- 只支持 CSV/Excel 导出
- 没有定时,没有云端模式
- 已不再维护——Amazon 改版就会失效,而且没人修
3. Web Scraper —— 老牌手动配置扩展
Web Scraper 是最成熟的 Chrome 扩展式爬虫之一,它围绕一个可视化 sitemap 构建器运作。你打开 DevTools,通过点选来定义选择器、配置分页,并且可以沿着链接抓取商品详情页。
Web Scraper 还在它的 marketplace 里提供了 Amazon Products Listings Scraper 模板,可以处理导航、分页和商品页提取。它的分步指南会带你完成一个 8 步设置流程——安装、生成选择器、配置分页、跟随商品链接、在本地或云端运行。
云端版本还增加了定时、API 访问、代理轮换、验证码绕过和 Google Sheets 集成。

Web Scraper 的优缺点
优点:
- 成熟、文档完善、社区支持强
- 免费浏览器扩展(本地使用不限量)
- 有 Amazon 的 marketplace 模板
- 有云端版本可扩展(定时、IP 轮换、集成)
- 支持跟随链接进入商品详情页(可做部分子页面补充)
缺点:
- 需要手动配置选择器——对非技术用户学习成本更高
- 没有 AI 自动识别字段
- Amazon 改版后模板可能失效
- 高级功能被锁在付费云端方案里
Web Scraper 定价
- 免费: Chrome 扩展,本地抓取不限量
- 云端方案: Project 起价 50 美元/月,Professional 100 美元/月,Scale 从 200 美元/月起
4. Octoparse —— 功能很全的平台(但 Chrome 扩展有个前提)
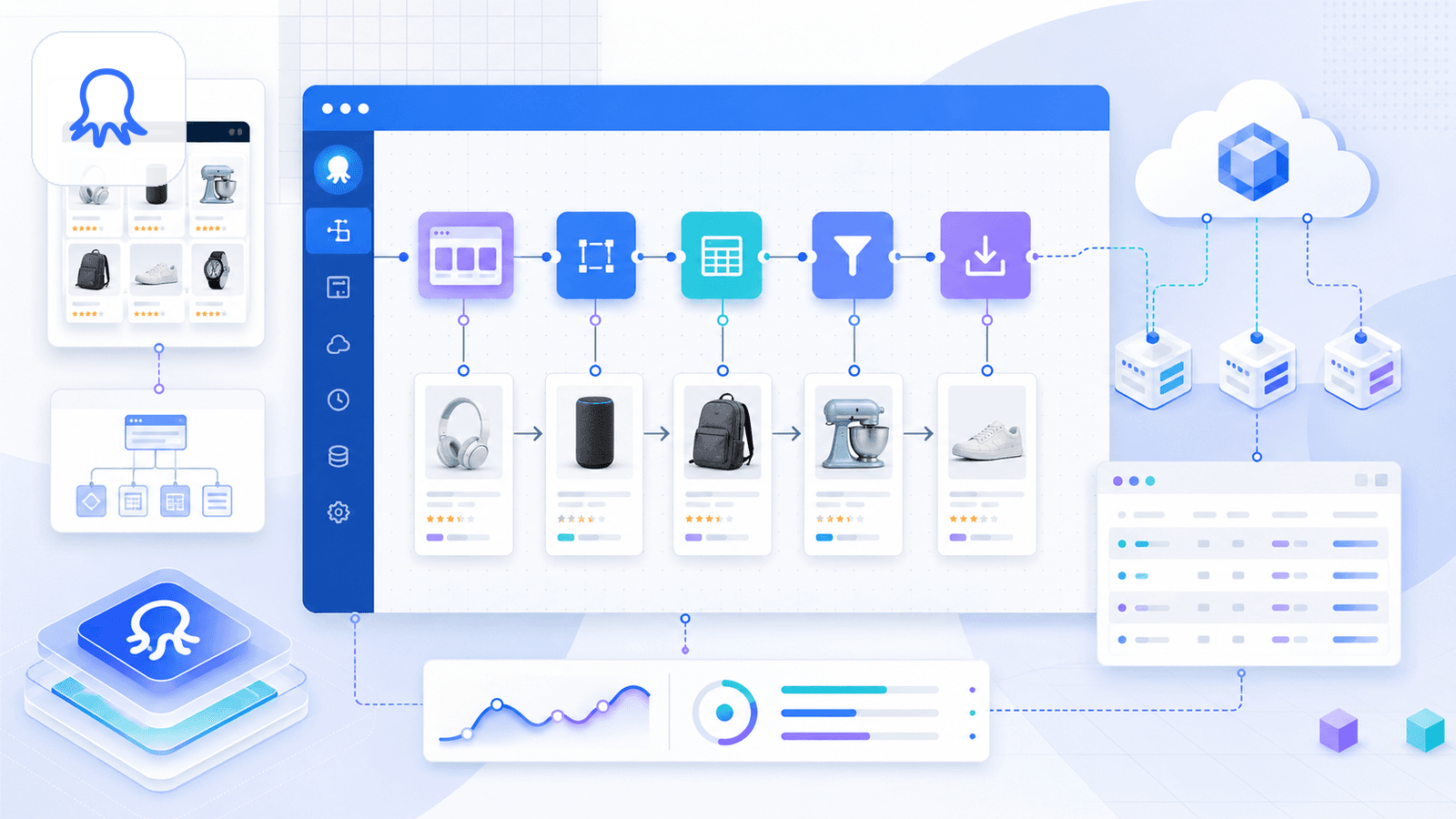
Octoparse 是一个功能强大的无代码抓取平台,提供了商品详情、关键词搜索和评论的预置 Amazon 模板。它支持云端抓取、定时以及多步骤工作流。
但这里有个重要细节:Octoparse 在 Chrome Web Store 上的扩展现在叫 Octoparse AI Web Automation,而且页面明确说明它只能和 Windows 上的 Octoparse AI Bot 一起使用。也就是说,它的真实体验更偏向“平台优先”,而不是“扩展优先”。如果你想要的是纯粹的“安装后就在 Chrome 里抓取”流程,Octoparse 更像是带浏览器辅助的桌面应用。
不过,它的模板确实很强。你输入搜索 URL,Octoparse 就能自动提取商品数据;你也可以用点选式选择器、分页和跟随链接等方式搭建自定义工作流,抓取详情页。
Octoparse 的优缺点
优点:
- 功能强大,带 Amazon 模板
- 云节点支持提速、定时,以及通过工作流进行子页面提取
- 分页处理能力不错
- 适合复杂的多步骤抓取流程
缺点:
- 要发挥全部能力需要桌面应用——并不是纯 Chrome 扩展体验
- 没有 AI 自动建议字段(另有独立的 Chat4Data 产品,但那是另一个扩展)
- 免费版导出上限约为每月 5 万条数据,每次最多导出 1 万行
- 对新手来说界面可能偏复杂
Octoparse 定价
- 免费: 功能有限(本地提取,导出上限 5 万)
- Standard: 约 75–83 美元/月
- Professional: 约 208–249 美元/月
- 附加项:IP 轮换 3 美元/GB,验证码识别 2–2.5 美元/1000 次
5. Axiom.ai —— 无代码机器人搭建器
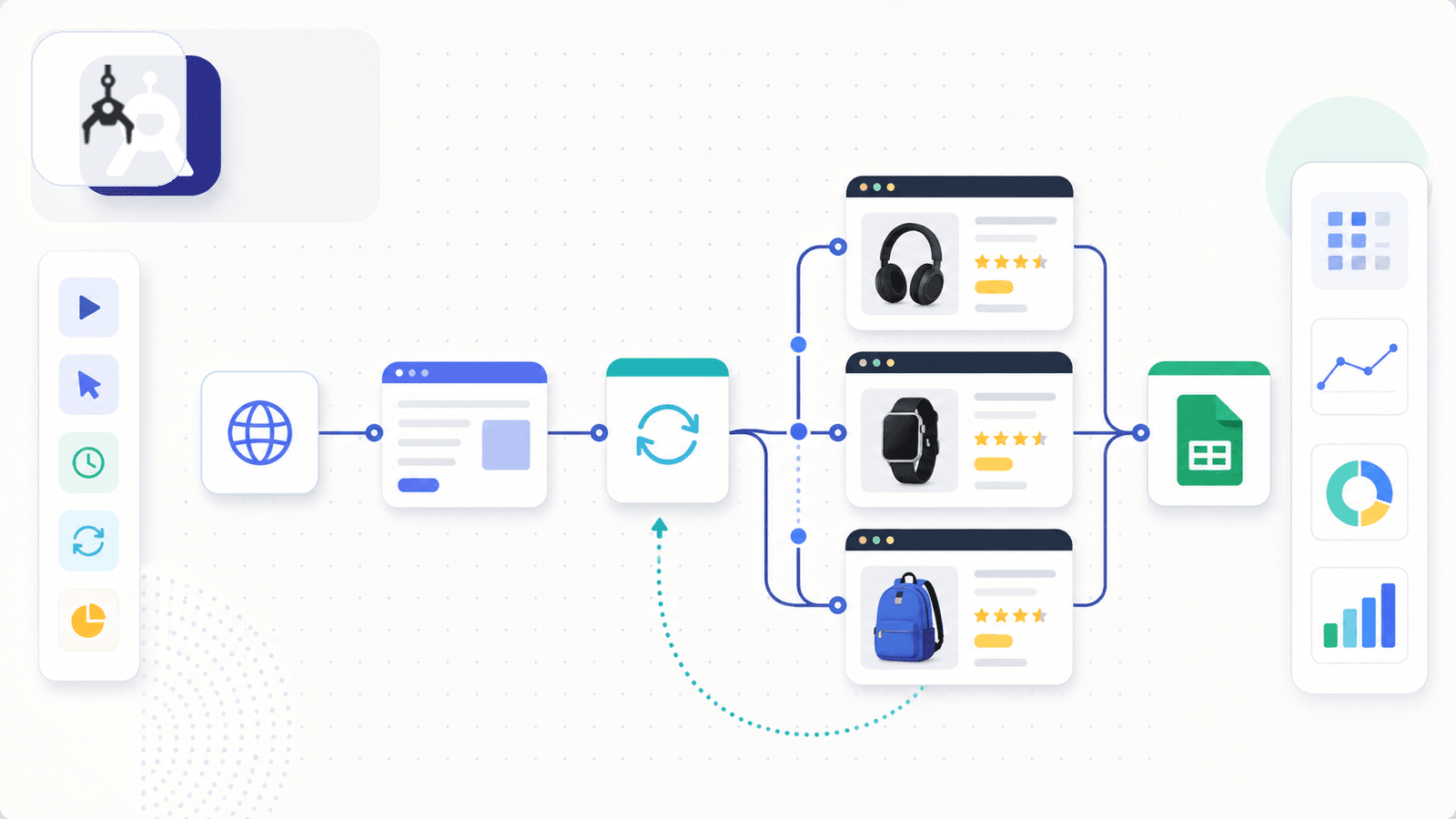
Axiom.ai 是一个 Chrome 扩展,可用无代码可视化构建器来搭建浏览器自动化机器人。它更像是通用自动化工具,而不是专门的爬虫,但它也有 Amazon 抓取模板和 ASIN 提取指南。
你可以创建一个机器人(或者直接拿模板),让它循环访问 Google Sheet 里的商品 URL,逐页打开并通过点选式选择器提取数据,再把结果写回表格。付费方案支持定时;现在云端运行也已开放,Starter 和 Pro 方案可在云端运行 1 个机器人,Ultimate 则最多支持 20 个并发云端机器人。
Axiom.ai 的优缺点
优点:
- 通用性强的无代码自动化,不只是抓取
- 原生集成 Google Sheets
- 付费方案支持定时和云端运行
- 有 Amazon 模板
- 适合抓取之外的多步骤工作流
缺点:
- 对简单抓取来说,前期设置更重(需要设计机器人、配置 Google Sheet、测试循环)
- 没有 AI 字段识别
- 没有一键式子页面补充(需要自己再搭一个机器人步骤)
- 导出仅限 Google Sheets 或 CSV
Axiom.ai 定价
- 免费: 2 小时运行时长
- Starter: 15 美元/月
- Pro: 50 美元/月
- Pro Max: 150 美元/月
- Ultimate: 250 美元/月
6. Data Miner —— 以“配方”为核心的扩展
Data Miner 是一个 Chrome 扩展,重点是用“配方”来提取数据——也就是预定义或自定义的抓取模板。你可以在公共库里搜索现成的 Amazon 配方,也可以通过选择页面元素自己创建一个。
Data Miner 通过 Next Page Automation 支持分页,而且它确实提供了 Crawl Scrape 工作流,可以访问详情 URL 并应用第二个配方。所以它并不是“没有子页面抓取”——但这个过程是手动的、多步骤的,而不是一键补充。
最大的限制是免费版:每月 500 页,而且免费版对部分域名有限制。配方也是按站点定制的,而 Data Miner 自己的文档还警告说,如果网站改版、参考 HTML 代码变化,配方就不会工作。
Data Miner 的优缺点
优点:
- 已有配方可以很快跑起来
- 有社区配方库
- 支持分页和详情页爬取(需手动配置)
- 界面简单
缺点:
- 免费版限制为每月 500 页
- 没有 AI 字段识别
- Amazon 改版后配方会失效
- 没有云端抓取,公开文档也不支持定时
- 导出:CSV、Excel、剪贴板;付费后可导出到 Google Sheets
Data Miner 定价
- 免费: 每月 500 页
- 付费: 19.99、49、99、200 美元/月,限制和功能逐步提升
7. Helium 10 —— 面向 Amazon 卖家的情报套件
Helium 10 是一套完整的 Amazon 卖家工具,而不是通用网页爬虫。它的 Chrome 扩展(Xray)会直接把数据覆盖在 Amazon 搜索结果上,展示预估销量、营收、评论趋势、BSR 等信息。它是给做商品研究的 Amazon 卖家用的,不是给你提取任意页面原始数据用的。
不过到了 2026 年,Helium 10 确实有免费计划,但免费版的 Chrome 扩展访问是受限的。扩展可以把结果导出为 CSV 或 Excel,也支持剪贴板工作流。
Helium 10 的优缺点
优点:
- Amazon 专属洞察很深(销量估算、关键词数据、BSR 趋势)
- 受到专业卖家信任
- 有云端支持的数据和定时功能,用于关键词/排名跟踪
- 有免费计划(但有限制)
缺点:
- 不是通用爬虫——不能从任意页面提取自定义字段
- 相比专注抓取的工具,价格偏高
- 导出格式有限(CSV、Excel)
- 没有 AI 字段识别,也没有爬虫意义上的子页面补充
Helium 10 定价
- 免费: 有限访问,包括 Chrome 扩展
- Starter: 49 美元/月
- Platinum: 229 美元/月
- Diamond: 359 美元/月
Amazon 爬虫 Chrome 扩展横向对比:完整表格
下面是诚实的对比表。我在实测并核对 2026 年信息后,对前几版草稿里的一些判断做了修正:
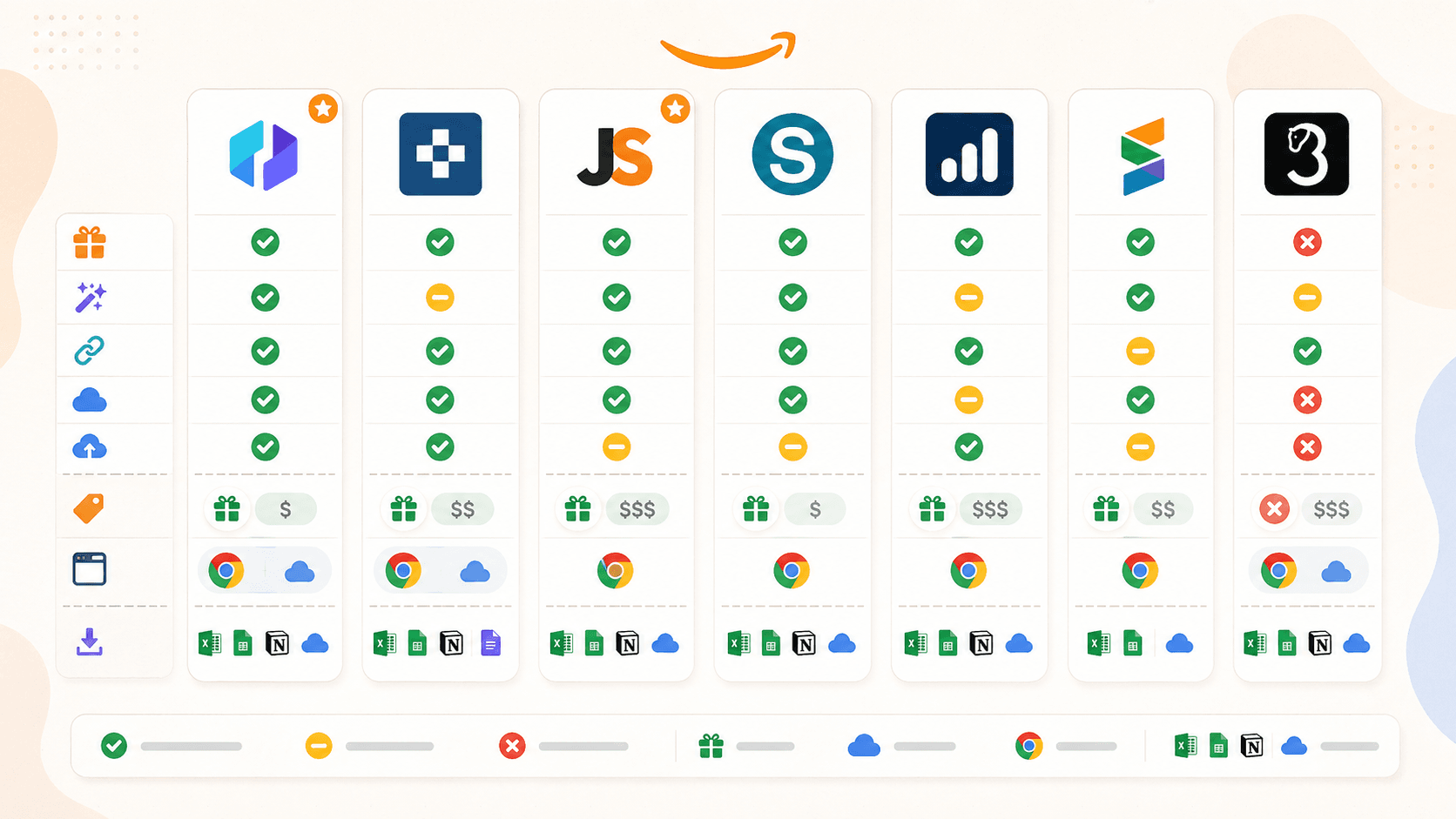
| 功能 | Thunderbit | Instant Data Scraper | Web Scraper | Octoparse | Axiom.ai | Data Miner | Helium 10 |
|---|---|---|---|---|---|---|---|
| 主要类别 | AI 爬虫扩展 | 免费启发式爬虫 | 选择器/模板爬虫 | 无代码抓取平台 | 浏览器自动化机器人搭建器 | 基于配方的爬虫扩展 | 卖家研究覆盖层 |
| AI 自动建议字段 | 有 | 无 | 无 | 无(另有 Chat4Data) | 无 | 无 | 无 |
| 子页面补充 | 有(一键) | 无 | 有(手动 sitemap) | 有(工作流) | 有(手动机器人步骤) | 有(手动爬取) | 不适用 |
| 云端抓取 | 有 | 无 | 有(付费) | 有(付费) | 有(付费) | 无 | 云端支持分析 |
| 定时 | 有 | 无 | 有(付费) | 有(付费) | 有(付费) | 无 | 有(关键词/排名跟踪) |
| 免费版 | 有(6–10 页) | 有(完全免费) | 有(仅浏览器) | 有(有限) | 有(2 小时运行) | 有(500 页/月) | 有(有限) |
| 预置 Amazon 模板 | 有 | 无 | 有 | 有 | 有(指南) | 配方库 | 不适用 |
| 导出到 Sheets/Airtable/Notion | 有(全支持) | 仅 CSV/Excel | CSV、Excel、JSON;Sheets 需云端 | CSV、Excel、JSON 等更多格式 | Google Sheets、CSV | CSV、Excel;付费后可到 Sheets | CSV、Excel |
有几点很明显。Thunderbit 是唯一同时具备 AI 字段识别和最丰富免费导出选项的扩展。Instant Data Scraper 是最简单的免费方案,但已经不再维护。Web Scraper 和 Octoparse 对愿意投入配置时间的用户很强,但它们都不是那种“安装完就能直接用”的纯扩展体验。Axiom.ai 更适合超出抓取范围的多步骤自动化。Data Miner 适合跑现成配方,但免费版比较紧。Helium 10 是卖家情报工具,不是通用爬虫。
Amazon 的云端抓取 vs. 浏览器抓取:你需要知道的封号风险
这就是最关键的问题。Amazon 会主动检测并阻止自动化抓取。Reddit 上的用户报告说,即使是低频抓取也会出现验证码,而 Amazon 自己的使用条款也明确说明,许可不包括“任何数据挖掘、机器人或类似的数据收集和提取工具的使用”。
那浏览器抓取和云端抓取,实际差别是什么?
- 浏览器抓取在你自己的 Chrome 会话里运行——是真实 cookie、已登录状态和自然的浏览行为。低频时看起来更像真人,但会占用你的浏览器。
- 云端抓取使用远程服务器来提速(Thunderbit 云端模式一次可处理 50 个页面),但需要限速和代理轮换来避免被识别。
我常用的判断矩阵如下:
| 场景 | 推荐模式 | 原因 |
|---|---|---|
| 抓 20 个商品页做研究 | 浏览器 | 量小,行为更自然 |
| 每周监控 500 个竞品 SKU | 云端 | 速度更重要,而且是公开数据 |
| 登录 Seller Central 期间抓取 | 浏览器 | 需要你的登录会话 |
| 一次性批量导出某个类目 | 云端 | 并行抓取更快 |
在这 7 个扩展里,Thunderbit、Web Scraper(付费)、Octoparse(付费)、Axiom.ai(付费)和 Helium 10(用于其分析)都支持云端抓取。Instant Data Scraper 和 Data Miner 只能在浏览器里用。
降低封号风险的实用建议: 保持请求间隔合理,避免在高峰时段抓取,如果工具支持,记得轮换 user agent。并且永远不要对自己承诺“零风险”——你只能管理风险,而不是消除它。
从列表页到详情页:Amazon 的子页面抓取是怎么工作的?
这个流程其实被低估了——而且没有任何竞品文章能完整演示它。
当你抓 Amazon 搜索结果页时,拿到的是摘要数据:商品标题、价格、评分、ASIN 和商品 URL。但很多时候你还需要详情页数据——完整描述、要点、图片 URL、卖家信息、评论拆分等等。子页面抓取就是为了解决这个问题。
在 Thunderbit 里,流程是这样的:
- 抓取 Amazon 搜索结果页 -> 得到一个商品表格(标题、价格、评分、ASIN、商品 URL)。
- 点击“Scrape Subpages” -> Thunderbit 会逐个访问每个商品 URL,并把详情字段(描述、评论数、卖家名称、图片 URL 等)追加到同一张表里。
- 导出补充后的表格到 Google Sheets、Airtable、Notion 或 Excel。
AI 会自动识别子页面结构并补充表格——不需要手动配置。按我的经验,这比你逐个打开商品页再手动复制字段,至少能省下一小时。
其他工具也能做到,但要更费工:
- Web Scraper: 你需要配置一个 sitemap,让它跟随商品链接,并为每个详情字段定义选择器。能做,但这是多步骤的手动流程。
- Octoparse: 你要搭一个带链接跟随步骤的工作流。很强,但不是一键式。
- Axiom.ai: 你要设计一个机器人循环,逐个访问 URL 并提取数据。很灵活,但需要机器人搭建能力。
- Data Miner: 你要用 Crawl Scrape 功能访问保存的 URL,并应用第二个配方。手动,而且依赖配方。
- Instant Data Scraper 和 Helium 10: 没有子页面补充工作流。
如果你经常同时需要 Amazon 的列表级数据和详情级数据,你选的工具就应该让这个流程变简单——而不只是“勉强可行”。
诚实的免费版拆解:不付费到底能得到什么?
论坛用户最常问的就是这个,而竞品文章往往完全没有说透。
| 扩展 | 免费版 | 免费能得到什么 | 什么时候需要升级 |
|---|---|---|---|
| Thunderbit | 有(6 页,试用后 10 页) | AI 字段建议、所有导出格式(Excel、Sheets、Airtable、Notion)、邮箱/电话提取器 | 需要更多页面或定时抓取时 |
| Instant Data Scraper | 有(完全免费) | 基础表格识别、CSV/Excel 导出 | 不适用(没有付费版,但也没有更新) |
| Web Scraper | 有(仅浏览器) | 浏览器抓取、CSV 导出 | 云端抓取、定时、集成 |
| Octoparse | 有(有限) | 每月约 5 万条导出、本地提取 | 更多记录、云节点 |
| Axiom.ai | 有(2 小时运行) | 基础自动化、Google Sheets | 更多运行次数、定时、云端 |
| Data Miner | 有(500 页/月) | 配方、CSV/Excel、Next Page Automation | 更多页面、Sheets、爬取功能 |
| Helium 10 | 有(有限) | 有限的 Chrome 扩展访问 | 完整 Xray、关键词工具、定时 |
关键结论是:Thunderbit 的免费版包含 AI 功能和所有导出格式——大多数竞品都把高级导出或 AI 锁在付费方案后面。Instant Data Scraper 完全免费,但没有 AI、子页面和定时功能(而且已经不再维护)。Helium 10 确实有免费计划,但扩展访问受限,而且它不是通用爬虫。
按场景给你的建议:
- “只是先试试” -> Instant Data Scraper(完全免费)或 Thunderbit 免费版
- “需要稳定、持续地抓取” -> Thunderbit 或 Web Scraper 付费方案
- “Amazon 卖家,需要市场情报” -> Helium 10
那么,你该选哪款 Amazon 抓取 Chrome 扩展?
测试完这 7 款之后,我的真实结论是:
- 最适合非技术用户、想要快速 AI 结果的人: Thunderbit。AI 自动识别字段、一键补充子页面、导出选项最全、云端/浏览器可切换。如果你想在 2 分钟内从 Amazon 页面直接变成表格,这就是首选。
- 最适合快速、一次性抓取的完全免费方案: Instant Data Scraper。零成本、无需账号,但功能有限,而且已经不再维护。
- 最适合愿意手动配置的用户: Web Scraper。灵活的 sitemap 构建器,云端方案也不错,文档完善。
- 最适合复杂、多步骤抓取流程: Octoparse(桌面应用 + 扩展)或 Axiom.ai(浏览器机器人)。两者都很强,但都不是纯粹“安装即用”的 Chrome 扩展。
- 最适合基于配方的简单提取: Data Miner。现成配方好用,但免费版紧,且没有 AI。
- 最适合 Amazon 卖家情报(不是通用抓取): Helium 10。专门为此设计,专有数据很深,但价格贵,而且不是通用爬虫。
如果你想看看 AI 驱动的 Amazon 抓取到底长什么样,不妨先试试 Thunderbit 的免费版。我觉得你会惊讶于,只靠几次点击就能完成这么多事。如果 Thunderbit 不是最适合你的工具,也可以试试这份列表里的其他几个——现在正是停止复制粘贴、开始更聪明地抓取的最好时机。
想了解更多 Amazon 抓取技巧,可以看看这些指南:如何抓取 Amazon 商品和评论、抓取 Amazon 价格、以及提取和分析 Amazon 销售数据。你也可以在 Thunderbit YouTube 频道观看教程。
用 Thunderbit 试试 AI Amazon 抓取 Get Started Free
常见问题
1. 抓取 Amazon 商品数据合法吗?
抓取公开可见数据通常是允许的,但 Amazon 的使用条款明确禁止未经书面同意的数据挖掘和自动化提取。本文不构成法律建议——在大规模抓取前,请务必先查看 Amazon 的条款。
2. Amazon 能检测并封禁 Chrome 扩展式爬虫吗?
能。Amazon 有反机器人系统,可能触发验证码、限速请求,或者封 IP。对小任务使用合理的请求频率、基于浏览器的抓取,以及对大任务使用带限速的云端抓取,都能降低风险。上面的云端 vs. 浏览器部分有一张实用决策表。
3. 用 Chrome 扩展可以抓取 Amazon 的哪些数据?
常见字段包括商品标题、价格、评分、评论数、ASIN、卖家名称、描述、图片 URL、库存可用性和配送信息。像 Thunderbit 这样的 AI 工具可以自动识别并建议这些字段,不需要手动设置。
4. 使用 Amazon 抓取 Chrome 扩展需要编程技能吗?
不需要——这 7 个工具都面向非技术用户设计。有些需要更多设置(Web Scraper、Octoparse、Axiom.ai),有些则几乎零配置(Thunderbit、Instant Data Scraper)。取舍通常是灵活性和易用性之间的平衡。
5. 哪个 Amazon 抓取 Chrome 扩展的免费版最好?
Thunderbit 的免费版包含 AI 字段识别和所有导出格式(Sheets、Airtable、Notion、Excel、CSV、JSON),而大多数竞品都把这些锁在付费方案后面。Instant Data Scraper 完全免费,但没有 AI、子页面和定时。Data Miner 每月提供 500 页免费额度。Helium 10 的免费计划限制较多,更偏向卖家研究,不是通用抓取。
了解更多




