is een AI Web Scraper Chrome Extension die zakelijke gebruikers helpt om data van websites te halen met behulp van AI. De kern van het probleem is dit: wat op ScrapingBee’s prijspagina betaalbaar lijkt, kan er in de praktijk heel anders uitzien zodra je productievolumes draait en ziet hoe credits verdwijnen tegen 5× tot 75× het basistarief. Deze review behandelt vijf invalshoeken die de meeste artikelen overslaan: de echte kosten op schaal, selector-gebaseerde versus AI-extractie, gebruiksgemak voor niet-technische gebruikers, workflows voor data na het scrapen, en betrouwbaarheidsbenchmarks voor 2026. Als je ScrapingBee voor je team overweegt — of je nu developer bent, sales ops aanstuurt of founder bent — dan is dit de analyse die je nodig hebt.
Wat is ScrapingBee? Een korte introductie
ScrapingBee is een web scraping API die proxy-rotatie, JavaScript-rendering en CAPTCHA-oplossing regelt, zodat developers data van websites kunnen halen zonder hun eigen scraping-infrastructuur te bouwen. Je stuurt een HTTP-request met parameters, en je krijgt HTML terug (of JSON voor bepaalde endpoints). Er is geen visuele interface of klikbare builder om scrapes op te zetten.
Belangrijkste mogelijkheden zijn onder meer:
- Geroteerde en premium proxies (classic, premium, stealth, residential)
- Headless browser rendering (volledige Chrome, standaard ingeschakeld)
- Automatische CAPTCHA-bypass
- Google Search API (gestructureerde JSON: organische resultaten, advertenties, maps, knowledge graph, People Also Ask, afbeeldingen, nieuws)
- Screenshot-capturing (standaard, volledige pagina of gericht op een CSS-selector)
- Geografische targeting via country_code-parameter
- CSS/XPath-extractieregels (declaratief, JSON-gebaseerd, levert gestructureerde JSON op)
- Specifieke API’s voor Amazon-, Walmart-, YouTube- en ChatGPT-scraping
- AI-extractie (toegevoegd rond 2024–2025): ai_query, ai_extract_rules, ai_selector-parameters (+5 credits per request)
- CLI-tool (gelanceerd rond 2025–2026): batchverwerking, crawlen, sitemap-analyse, CSV-verrijking, geplande cron-jobs, proxy-escalatie
ScrapingBee werd in 2019 opgericht in Frankrijk en groeide begin 2026 naar ongeveer , met 2.500+ klanten (SAP, Zapier, Deloitte, Zillow) — volledig bootstrapped met een team van 4–6 mensen. In juni 2025 nam in een deal van acht cijfers. Het merk en de leiding blijven zelfstandig, en het supportteam is voor betere dekking over tijdzones.
Een belangrijke kanttekening: ScrapingBee heeft nog steeds geen native visual builder, point-and-click GUI of ingebouwde planner in een webdashboard. Inplannen moet via de CLI-tool, cron jobs of automatisering van derden (Zapier, Make, n8n). De "no-code"-gidsen die ze publiceren gaan over Make- en Zapier-integraties — niet over een native no-code interface.
Voor wie is ScrapingBee eigenlijk bedoeld?
ScrapingBee is gemaakt voor developers die prima uit de voeten kunnen met Python- of cURL-calls, HTML kunnen lezen en CSS/XPath-selectors kunnen opstellen. De documentatie is sterk codegericht en leunt op Python- en cURL-voorbeelden. Een reviewer op merkte op dat ze "do not provide examples in JavaScript," en een ander beschreef de docs als "bulky, takes a day to a week to read through."
Maar het publiek dat in 2026 zoekt naar een "ScrapingBee review" is breder dan backend engineers. Het gaat ook om marketingmanagers die leadlijsten bouwen, sales ops-teams die CRM-data verrijken, ecommerce-teams die concurrentieprijzen volgen, en founders die tools voor hun teams beoordelen. In elk onderdeel hieronder geef ik aan of een feature of beperking vooral relevant is voor developers, zakelijke gebruikers, of allebei.
ScrapingBee-prijsplannen in één oogopslag
Dit zijn de huidige ScrapingBee-pakketniveaus (per april 2026):
| Plan | Maandelijkse prijs | API-credits/maand | Gelijktijdige requests |
|---|---|---|---|
| Freelance | $49 | 250.000 | 10 |
| Startup | $99 | 1.000.000 | 50 |
| Business | $249 | 3.000.000 | 100 |
| Business+ | $599 | 8.000.000 | 200 |
| Enterprise | Contact sales | 41M+ | Maatwerk |
Jaarlijkse facturatie geeft . Een gratis proefperiode biedt 1.000 API-credits zonder creditcard. De Google Search API is na de overname onlangs per call.
Die opvallende credit-aantallen lijken royaal. Maar ze zijn niet wat ze lijken.
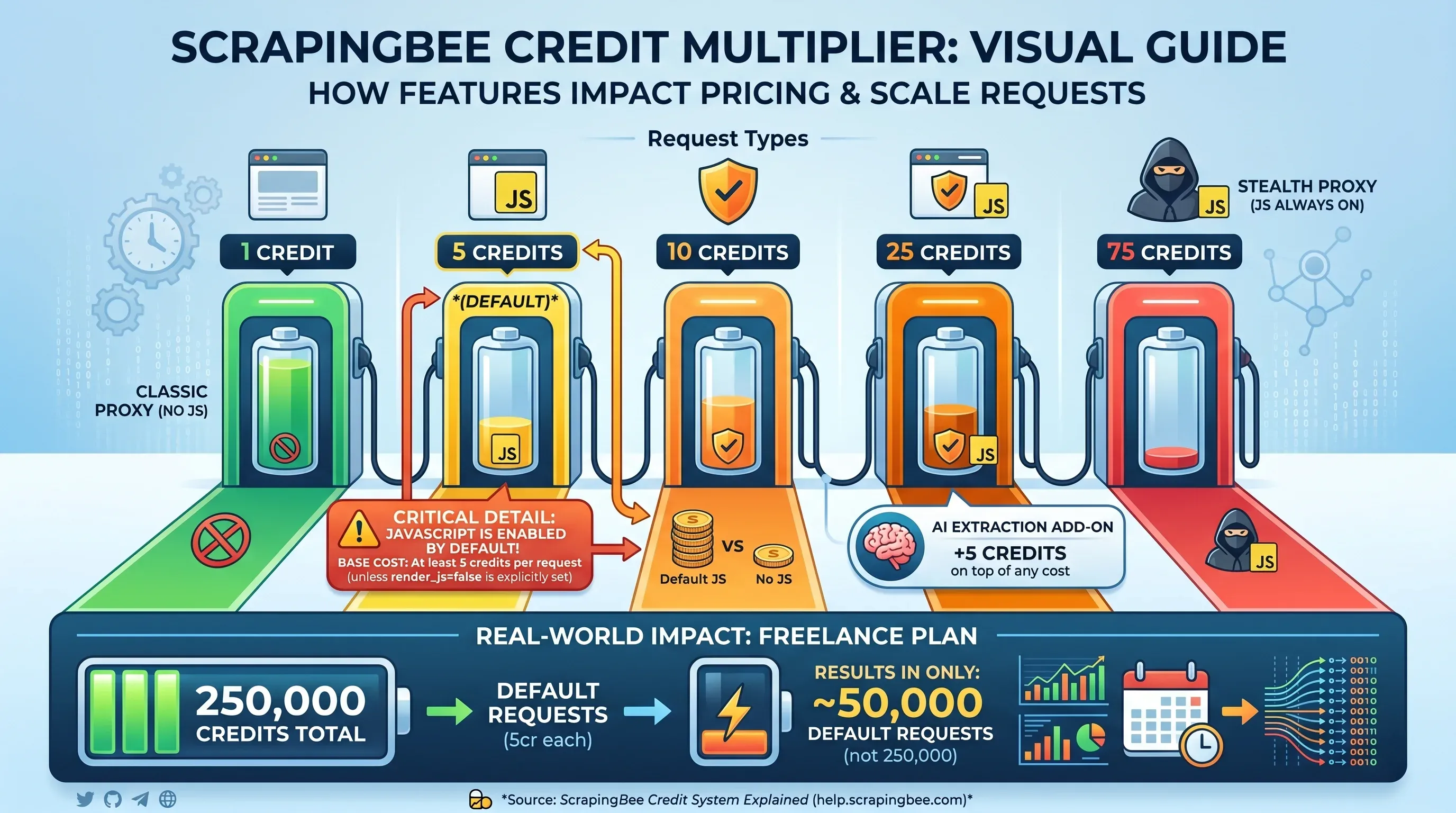
De creditvermenigvuldiger-tabel
Hier wordt de prijsstructuur van ScrapingBee ingewikkeld. Het aantal credits in de headline is niet hetzelfde als het aantal pagina’s dat je kunt scrapen — dat hangt af van welke features je per request inschakelt:
| Type request | Credits per request |
|---|---|
Classic proxy, geen JS-rendering (render_js=false) | 1 credit |
| Classic proxy, JS-rendering (standaard) | 5 credits |
| Premium proxy, geen JS-rendering | 10 credits |
| Premium proxy, JS-rendering | 25 credits |
| Stealth proxy (JS altijd aan) | 75 credits |
| AI-extractie add-on | +5 credits bovenop |
Cruciaal detail: JavaScript-rendering staat . Als je render_js=false niet expliciet instelt, kost elke request dus minimaal 5 credits. Dat betekent dat het Freelance-plan met 250.000 credits in de praktijk maar 50.000 standaardrequests dekt — niet 250.000.
De verborgen creditberekening die niemand laat zien
Hier zie je wat ScrapingBee daadwerkelijk kost voor 10.000 pagina’s in verschillende scenario’s en plan-niveaus:
| Scenario | Benodigde credits | Freelance ($49/250K) | Startup ($99/1M) | Business ($249/3M) |
|---|---|---|---|---|
| 10K pagina’s (statische HTML, 1 cr) | 10.000 | ✅ Gedekt ($0,20/1K) | ✅ Gedekt ($0,10/1K) | ✅ Gedekt ($0,08/1K) |
| 10K pagina’s (JS-rendering, 5 cr) | 50.000 | ✅ Gedekt ($0,98/1K) | ✅ Gedekt ($0,50/1K) | ✅ Gedekt ($0,42/1K) |
| 10K pagina’s (premium proxy + JS, 25 cr) | 250.000 | ⚠️ Precies op limiet ($4,90/1K) | ✅ Gedekt ($2,48/1K) | ✅ Gedekt ($2,08/1K) |
| 10K pagina’s (stealth proxy, 75 cr) | 750.000 | ❌ Ver boven limiet | ✅ Net gedekt ($7,43/1K) | ✅ Gedekt ($6,23/1K) |
Diezelfde 10.000 pagina’s kunnen ergens tussen $0,20 en $7,43 per duizend kosten, afhankelijk van proxy- en renderingconfiguratie. En je weet niet altijd vooraf welke configuratie je nodig hebt.
Budgetscenario: leadgeneratie bij 10.000 pagina’s/maand
Een salesteam scrapt 10.000 bedrijfspagina’s per maand voor leadgeneratie. De meeste moderne B2B-sites gebruiken React of Vue, dus JS-rendering is nodig:
- Benodigde credits: 50.000 (10K × 5 credits)
- Freelance-plan ($49): dekt dit met 200K credits over
- Maar als targets premium proxies vereisen: 250.000 credits — precies de toewijzing van één Freelance-plan, geen buffer
- Als stealth proxies nodig zijn: 750.000 credits — dan is het Startup-plan nodig voor $99/maand
Budgetscenario: e-commerce prijsmonitoring bij 100.000 pagina’s/maand
Een ecommerce-team monitort 100.000 productpagina’s op concurrentiesites:
| Configuratie | Benodigde credits | Benodigd plan | Maandelijkse kosten |
|---|---|---|---|
| Statische HTML (1 cr) | 100.000 | Freelance | $49 |
| JS-rendering (5 cr) | 500.000 | Startup | $99 |
| Premium proxy + JS (25 cr) | 2.500.000 | Business | $249 |
| Stealth proxy (75 cr) | 7.500.000 | Business+ | $599 |
Dezelfde klus loopt dus uiteen van $49 tot $599 per maand. Dat is geen afrondingsverschil — het is een kostenverschil van 12×, puur op basis van configuratie.
"De instapprijs van $49 is het meest misleidende getal in de scraping-API-markt." —
"Credits raken snel op bij gebruik van JavaScript-rendering of geavanceerde functies, waardoor het lastiger wordt om dit te rechtvaardigen voor kleinere projecten of teams met onvoorspelbare scrapingvolumes." — Nick S, Manager, Computer Software,
En ongebruikte credits worden naar de volgende maand.
Hoe ScrapingBee’s kosten zich verhouden tot concurrenten

Op basis van mid-tier plannen voor een eerlijke vergelijking:
| Scenario (per 1K pagina’s) | ScrapingBee ($99/1M) | ScraperAPI ($149/1M) | Scrapfly ($100/1M) |
|---|---|---|---|
| Statische HTML | $0,10 | $0,15 | $0,10 |
| JS-gerenderde pagina’s | $0,50 | $1,64 | $0,60 |
| Premium + JS | $2,48 | $3,73 | $3,00 |
| Stealth/ultra premium + JS | $7,43 | $11,18 | N/B |
ScrapingBee is over het algemeen de goedkoopste of gelijk aan de goedkoopste bij statische en JS-gerenderde pagina’s. is consequent het duurst — de JS-rendering kost daar +10 credits tegenover +5 bij zowel ScrapingBee als Scrapfly. Maar onafhankelijke tests van laten iets anders zien wanneer de complexiteit van echte websites wordt meegenomen:
| Service | Gemiddelde kost per 1K requests | Succespercentage | Gemiddelde responstijd |
|---|---|---|---|
| Scrape.do | $0,80 | 98,19% | 4,7s |
| ScrapingBee | $3,90 | 92,69% | 11,7s |
| Scrapfly | $4,11 | — | — |
| ZenRows | $4,48 | 92,64% | 10,0s |
| ScraperAPI | $8,49 | 92,70% | 15,7s |
Thunderbit’s creditmodel: een andere aanpak
gebruikt een fundamenteel eenvoudiger prijsmodel: 1 credit = 1 outputrij, zonder vermenigvuldigers voor JS-rendering, proxytype of doeldomein. Subpage-scraping kost 2 credits per rij.
| Plan | Maandelijkse prijs | Credits | Kosten per rij |
|---|---|---|---|
| Free | $0 | 6 pagina’s/maand | Gratis |
| Starter | $15 | 500 | $0,030 |
| Pro 1 | $38 | 3.000 | $0,013 |
| Pro 2 | $75 | 6.000 | $0,013 |
| Pro 3 | $125 | 10.000 | $0,013 |
| Pro 4 | $249 | 20.000 | $0,012 |
Een Thunderbit-gebruiker die 10.000 productvermeldingen scrapt van JS-zware ecommerce-sites betaalt $125 per maand, ongeacht of die sites JavaScript-rendering, premium proxies of anti-bot-bypass nodig hebben. Met ScrapingBee kan dezelfde klus $49 tot $599 kosten, afhankelijk van de configuratie. Budgetvoorspelbaarheid is echt een voordeel.
CSS-selectors versus AI-extractie: de onderhoudskosten die je moet kennen
De meeste ScrapingBee-reviews slaan dit volledig over. Het is misschien wel de belangrijkste overweging voor iedereen die maanden of jaren op schaal wil scrapen.
ScrapingBee gebruikt CSS/XPath-selectors om data uit HTML te halen. Je definieert extractieregels als JSON-objecten met CSS-selectors, en ScrapingBee geeft de overeenkomende data terug. In het begin werkt dat prima. Het probleem is wat daarna gebeurt.
Het probleem van kapotte selectors
Wanneer een doelwebsite de lay-out wijzigt — class names, DOM-structuur, frameworkversie — breken je CSS-selectors. In volwassen scraping-systemen met 2.500+ actieve jobs laat onderzoek een zien, wat 30–35 fixes per week vereist om extractors draaiende te houden. Voor organisaties die 50 sites scrapen, loopt het jaarlijkse onderhoud op tot 850–1.300 uur, goed voor $64.000–$156.000 aan volledig belaste engineer-kosten.
Teams onderschatten dit structureel. Eerste inschattingen komen vaak uit op 10–15 onderhoudsuren per maand, maar de praktijk ligt (40–90 uur per maand). Eén stille fout — waarbij een selector breekt maar leeg resultaat blijft teruggeven zonder waarschuwing — kost naar schatting $38.000–$57.000 aan gemiste sales, herstel van ranking en arbeidstijd.
Veelvoorkomende oorzaken zijn: hernoemde CSS-classes bij framework-updates, nieuwe containers rond targets, React/Vue/Angular-upgrades die de DOM herschikken, A/B-tests met dynamische class names en anti-scraping-obfuscatie.
AI-extractie verlaagt onderhoud met 60–80%
Een DataRobot-studie uit 2025 liet zien dat AI-gestuurde scrapers nodig hebben dan traditionele selector-gebaseerde scrapers na een redesign van een site. De verhouding tussen opzet en onderhoud draait daardoor praktisch om:
| Metric | Traditioneel (CSS-selectors) | AI-gestuurd |
|---|---|---|
| Onderhoud na redesigns | Baseline | 70% minder |
| Tijdverdeling (opzet : onderhoud) | 20% : 80% | 5% : 95% op basis van data |
| Totale onderhoudsreductie | Baseline | 60–80% reductie |
| Snelheid op JS-zware pagina’s | Baseline | 30–40% sneller |
Opzettijd: selectors schrijven versus AI-voorgestelde velden
ScrapingBee-setup: paginabron inspecteren → CSS-selectors identificeren → extractieregels als JSON schrijven → testen en debuggen → randgevallen voor paginavariaties afhandelen → breakage monitoren → kapotte selectors repareren wanneer sites updaten.
Thunderbit-setup: pagina openen in Chrome → op "AI Suggest Fields" klikken → AI leest de pagina en stelt kolommen met passende datatypes voor → op "Scrape" klikken. Geen selectors schrijven, geen broncode inspecteren. Thunderbit’s AI draait op meerdere foundation models (ChatGPT, Gemini, Claude, DeepSeek R1) die webpagina’s visueel lezen zoals een mens dat doet.
Thunderbit’s voegen nog een laag toe: elke kolom kan een eigen AI-instructie krijgen die data tijdens het extraheren omzet — datums opmaken, tekst vertalen, producten categoriseren, namen splitsen, telefoonnummers normaliseren. Daardoor valt een aparte nabewerkingsstap weg die ScrapingBee-gebruikers zelf moeten bouwen.
Gestructureerde output: ruwe HTML versus direct bruikbare rijen
| Aspect | ScrapingBee (op selectors gebaseerd) | Thunderbit (AI-gestuurd) |
|---|---|---|
| Standaard output | Ruwe HTML | Gestructureerde rijen met getypeerde kolommen |
| Gestructureerde extractie | Vereist CSS/XPath-regels of AI-add-on (+5 credits) | AI detecteert velden automatisch |
| Ondersteunde datatypes | Tekst (HTML-parsing vereist) | Tekst, getal, datum, URL, e-mail, telefoon, afbeelding |
| Weerstand tegen lay-outwijzigingen | ⚠️ Handmatige selector-updates nodig | ✅ AI leest de pagina telkens opnieuw |
| Benodigde technische vaardigheid | Python/cURL, CSS-selectors, HTML-begrip | Geen — Chrome Extension met workflow in 2 klikken |
| Onderhoud op termijn | Doorlopend (1–2% wekelijkse breekgraad) | Minimaal (AI past zich automatisch aan) |
ScrapingBee heeft AI-extractie toegevoegd (ai_query, ai_extract_rules) om het selector-onderhoud deels aan te pakken. Maar daar komen wel +5 credits per request bovenop de basiskosten, en de tool blijft in de kern API-first zonder visuele interface.
ScrapingBee voor niet-developers: een eerlijke gebruikscheck
ScrapingBee is niet gebouwd voor niet-technische gebruikers. Het is een API. Je schrijft code om het te gebruiken. Als je dit leest als marketingmanager of sales ops-lead, dan is dat het hele verhaal.
Dit is wat een niet-technische gebruiker in de praktijk met ScrapingBee doet:
- Een API-call schrijven in Python, cURL of een andere taal
- HTTP-parameters begrijpen zoals
render_js=true,premium_proxy=true,country_code=us - Ruwe HTML-responses parsen met een library zoals BeautifulSoup
- CSS-selectors schrijven om specifieke datavelden te extraheren
- Paginering afhandelen door eigen crawl-logica te schrijven (ScrapingBee doet alleen single-page requests)
- Een datapipeline bouwen om de geëxtraheerde data op te schonen, te structureren en op te slaan
Er is geen drag-and-drop builder. Geen point-and-click interface. Geen visuele preview van wat je precies scrapt.
"There is a learning curve. And documentation is bulky, takes a day to a week to read through." — Arvind K, Proprietor, Financial Services,
"Their system is very particular and it takes a while to learn their codes and their structure." —
Developers vinden dit juist prettig. Een reviewer noemde het "wholly API based: very modern and elegant: it just works." Maar "ease of use" voor een developer die API’s beoordeelt is iets heel anders dan "ease of use" voor iemand die zonder code een leadlijst wil bouwen.
Wanneer een no-code alternatief logischer is
De biedt een fundamenteel andere ervaring:
- Open een webpagina in Chrome met de extensie geïnstalleerd
- Klik op "AI Suggest Fields" — AI scant de pagina en stelt kolommen voor (Productnaam, Prijs, Beoordeling, URL, enz.) met passende datatypes
- Controleer en pas aan — kolommen toevoegen, verwijderen of hernoemen; Field AI Prompts toevoegen voor transformatie
- Klik op "Scrape" — data wordt in gestructureerde rijen geëxtraheerd
- Exporteren — met één klik naar Google Sheets, Airtable, Notion, Excel, CSV of JSON (alle exports zijn gratis)
Geen API-calls, geen selectors, geen code. Thunderbit ondersteunt per april 2026 .
Voor veelgebruikte sites biedt Thunderbit ook — kant-en-klare, onderhouden templates voor Amazon, Zillow, Shopify, LinkedIn, Google Maps, Instagram, eBay, Apollo en meer. Je hoeft niet eens te wachten tot AI velden voorstelt; de template staat al klaar.
Daarnaast bevat Thunderbit verschillende waarvoor je geen plan nodig hebt: email extractor, phone number extractor en image extractor — handig voor sales- en marketingteams die gewoon snel data willen ophalen.
Besliskader: wie gebruikt wat?
| Als je bent… | Beste keuze |
|---|---|
| Developer die comfortabel is met API’s en HTML-parsing | ScrapingBee of ScraperAPI |
| Technische gebruiker die gestructureerde data wil zonder selectorwerk | Thunderbit API (Extract-endpoint) |
| Zakelijke gebruiker (sales, marketing, ecommerce ops) zonder programmeervaardigheden | Thunderbit Chrome Extension |
| Team dat geplande monitoring nodig heeft zonder devops | Thunderbit Scheduled Scraper (planning in natuurlijke taal) |
| LLM/RAG-pipelines bouwt en schone markdown nodig hebt | Thunderbit Distill API of Firecrawl |
| Prijsvoorspelbaarheid belangrijk vindt en geen creditvermenigvuldigers wil | Thunderbit (1 credit = 1 rij) |
Na het scrapen: waar gaat je data eigenlijk heen?
Scraping is maar de helft van het werk. De andere helft — die data ergens bruikbaar krijgen — is waar de meeste ScrapingBee-reviews stil blijven.
ScrapingBee: ruwe HTML eruit, je bouwt je eigen pipeline
ScrapingBee geeft standaard ruwe HTML terug. Daarna moet je:
- De HTML parsen met BeautifulSoup of lxml
- Navigatie, footers, scripts en styles verwijderen (samen goed voor )
- Specifieke datavelden extraheren
- Omzetten naar gestructureerde formaten
- Paginering en foutstatussen afhandelen
- De data opslaan en verspreiden
"ScrapingBee returns raw HTML. AI agents need clean markdown, semantic search, and webhooks." —
ScrapingBee biedt wel return_page_markdown=true en return_page_text=true als optionele alternatieven, en de Google Search API geeft gestructureerde JSON terug. Maar de standaardworkflow — en de algemene scraping-ervaring — blijft ruwe HTML die je zelf moet verwerken.
Gebruikers hebben meestal extra tools nodig: BeautifulSoup/lxml voor parsing, Pandas voor opschoning, cron/Airflow voor planning, eigen crawl-logica voor multi-page scraping, en . Dat is nogal wat engineering tussen "ik heb het gescrapet" en "ik kan het gebruiken".
Thunderbit: gestructureerde output met ingebouwde export
Thunderbit levert gestructureerde rijen met gedefinieerde datatypes (tekst, getal, datum, URL, e-mail, telefoon, afbeelding) die direct klaar zijn voor export. Alle exports zijn gratis in alle plan-niveaus:
| Exportbestemming | Kosten |
|---|---|
| Excel (.xlsx) | Gratis |
| Google Sheets | Gratis (directe integratie) |
| Airtable | Gratis (directe integratie) |
| Notion | Gratis (directe integratie) |
| CSV | Gratis |
| JSON | Gratis |
Voor teams die Google Sheets of Airtable al gebruiken als CRM of operations-hub, valt daarmee een hele laag engineering weg. Bij export naar Notion of Airtable worden afbeeldingen geüpload naar de image library zodat ze inline zichtbaar zijn — een klein detail dat in de praktijk veel uitmaakt.
Het integratie-ecosysteem van ScrapingBee
ScrapingBee biedt wel integraties van derden: (8.000+ app-koppelingen), (3.000+ apps), n8n en Microsoft Power Automate. Die kunnen de kloof tussen ruwe HTML en je doeltools overbruggen — maar ze voegen kosten, complexiteit en een extra foutpunt toe.
Voor developers: Thunderbit’s Open API
Voor lezers die juist programmatische pipelines willen, biedt Thunderbit een Open API met twee belangrijke endpoints:
- Distill-endpoint — zet pagina’s om naar schone Markdown, ideaal voor LLM/RAG-pipelines (1 credit per call)
- Extract-endpoint — geeft gestructureerde JSON terug volgens een door de gebruiker gedefinieerd schema (20 credits per call)
- Batchverwerking — tot 100 URL’s per request
Thunderbit bedient dus zowel no-code gebruikers (Chrome Extension) als developers (Open API) vanuit dezelfde AI-engine. Vraag niet alleen "kan het scrapen" — vraag "waar gaat de data heen?"
Betrouwbaarheid in 2026: houdt ScrapingBee stand in productie?
Oudere Reddit-threads (2021–2023) bevatten klachten over de betrouwbaarheid van ScrapingBee. Zijn die in 2026 nog steeds relevant? Ik heb data uit zes onafhankelijke benchmarks bekeken. De resultaten zijn gemengd — en soms tegenstrijdig.
Scrapeway tweewekelijkse benchmark (april 2026)
Totaal: — nummer 7 van de 9 geteste services.
| Website | Succespercentage |
|---|---|
| Amazon | 48% |
| 41% | |
| Indeed | 38% |
| Etsy | 21% |
| Booking | 17% |
| Realtor | 0% |
| StockX | 0% |
| Twitter/X | 0% |
| Zillow | 0% |
| Walmart | 0% |
| 0% |
Head-to-head test van Scrapingdog (2025)
| Website | ScrapingBee | Scrapingdog | ScraperAPI |
|---|---|---|---|
| Amazon | 100% | 100% | 100% |
| Glassdoor | 0% | 100% | 100% |
| eBay | 100% | 100% | 100% |
| Walmart | 40% | 100% | 100% |
| 90% | 100% | 80% |
Proxyway-benchmark (december 2025)
- 72,98% succes bij 10 requests per seconde — een daling van 12 punten onder belasting
- 25,46s gemiddelde responstijd — de langzaamste in de benchmarkgroep
Scrape.do-benchmark (2025–2026)
- Sterk op individuele sites: Amazon 99,11%, Indeed 99,29%, GitHub 100%, X/Twitter 99,6%
- Zwak op Capterra: slechts 59% succes met responstijden van 36 seconden
Het patroon
De data laat een duidelijk patroon zien:
- ScrapingBee presteert goed op gangbare, matig beveiligde sites — Amazon, eBay, GitHub en Indeed laten consequent 90–100% succes zien
- ScrapingBee faalt volledig op zwaar beveiligde sites — consequent 0% op LinkedIn, Zillow, Realtor.com, StockX en Twitter in meerdere benchmarks
- Prestaties verslechteren sterk onder belasting — 84% bij 2 req/s daalt naar 73% bij 10 req/s
- Benchmarkresultaten lopen enorm uiteen door methodologie — van 33,3% (Scrapeway, brede mix van sites) tot 92,69% (Scrape.do, matige targets)
ScrapingBee’s (137 reviews) is positief, maar hoge scores voor het gemak van de eerste setup zeggen niet altijd iets over de betrouwbaarheid in productie op lange termijn en op schaal. Gebruikers die overstappen noemen vaak toenemende foutpercentages en oplopende kosten — niet de moeilijkheid van de initiële setup.
"Very positive. ScrapingBee has been stable, predictable, and easy to integrate into production." — Verified Reviewer, CEO,
ScrapingBee vertoonde "inconsistent reliability," met name "0% success rate on Glassdoor" en "."
Hoe AI-gestuurd scrapen anders met betrouwbaarheid omgaat
Thunderbit’s AI leest de gerenderde pagina in realtime en past zich per sessie aan anti-botmaatregelen en lay-outwijzigingen aan. Twee scrapingmodi pakken verschillende betrouwbaarheidssituaties aan:
- Cloud scraping — draait op Thunderbit’s cloudservers, verwerkt tot 50 pagina’s tegelijk en is ideaal voor grote publieke scrapingjobs op sites zoals Amazon, Zillow en Shopify
- Browser scraping — draait lokaal in de Chrome-browser van de gebruiker, met de eigen ingelogde sessie — ideaal voor ingelogde sites (LinkedIn, private dashboards, SaaS-platforms) waar API-gebaseerde tools zoals ScrapingBee niet bij content achter authenticatie kunnen komen
Thunderbit biedt ook voor populaire sites, vooraf gebouwd en onderhouden, zodat ze blijven werken ook als sites van structuur veranderen. Voor de sites waar ScrapingBee 0% succes laat zien (LinkedIn, Zillow), is Thunderbit’s browser scraping-modus — met je eigen ingelogde sessie — een fundamenteel andere aanpak.
ScrapingBee versus topalternatieven: vergelijking naast elkaar
| Aspect | ScrapingBee | Thunderbit | ScraperAPI | Scrapfly |
|---|---|---|---|---|
| Type | Alleen API | Chrome Extension + API | Alleen API | Alleen API |
| Startprijs | $49/maand | Gratis ($0) | $49/maand | $30/maand |
| Creditmodel | Vermenigvuldigers (1×–75×) | 1 credit = 1 rij (geen vermenigvuldigers) | Vermenigvuldigers (1×–75×) | Vermenigvuldigers (1×–30×) |
| AI-extractie | Ja (+5 credits/request) | Ingebouwd (AI Suggest Fields) | Geen native AI | Ja |
| No-code optie | Nee (alleen API) | Ja (Chrome Extension) | Nee (alleen API) | Nee (alleen API) |
| Gestructureerde output | Vereist CSS-regels of AI-add-on | Standaard (getypeerde kolommen) | Gestructureerde endpoints voor specifieke sites | Verschilt |
| Exportbestemmingen | Ruwe HTML/JSON (zelf bouwen) | Excel, Sheets, Airtable, Notion, CSV, JSON (alles gratis) | Ruwe HTML/JSON | Ruwe HTML/JSON |
| Subpage-scraping | Handmatig (eigen crawl-logica schrijven) | Ingebouwd (2 credits/rij) | Handmatig | Handmatig |
| Geplande scraping | Alleen via CLI (geen dashboardplanner) | Ingebouwd (natuurlijke taal) | Niet ingebouwd | Niet ingebouwd |
| Gratis tier | 1.000 credits trial | 6 pagina’s/maand (voor altijd) | 5.000 credits (7-daagse trial) | 1.000 credits |
| JS-rendering standaard | AAN (5× kosten) | Inbegrepen (geen extra kosten) | UIT | UIT |
| Leercurve | Hoog (API + selectors) | Laag (workflow in 2 klikken) | Hoog (API + selectors) | Hoog (API) |
| Beste voor | Developers die proxycontrole willen | Zakelijke gebruikers + developers | Developers + gestructureerde endpoints | Developers die ASP-bypass willen |
| Capterra-score | 4,9/5 (137 reviews) | — | 4,6/5 (62 reviews) | 4,9/5 (221 reviews) |
ScrapingBee versus Thunderbit: de belangrijkste verschillen
De grootste verschillen zitten in architectuur en doelgroep:
- Alleen API versus Chrome Extension + API: ScrapingBee vereist code voor elke interactie. Thunderbit biedt een voor no-code gebruikers en een Open API voor developers — dezelfde AI-engine, twee interfaces.
- Selector-gebaseerde versus AI-gestuurde extractie: ScrapingBee vereist dat je CSS/XPath-selectors schrijft en onderhoudt. Thunderbit’s AI stelt automatisch velden voor en past zich aan wanneer sites veranderen.
- Ruwe HTML-output versus gestructureerde rijen met gratis export: ScrapingBee geeft HTML terug die je moet parsen. Thunderbit geeft getypeerde, gelabelde rijen terug die je met één klik kunt .
- Subpage-scraping: Thunderbit’s AI bezoekt elke detailpagina en verrijkt de hoofdtabel — ingebouwd, geen eigen crawl-logica nodig. ScrapingBee vereist dat je die logica zelf schrijft.
- Instant templates: Thunderbit heeft vooraf gebouwde templates voor populaire sites (Amazon, Zillow, Shopify, LinkedIn, Google Maps, eBay) die direct werken. ScrapingBee heeft wel specifieke API’s voor Amazon en Walmart, maar je moet nog steeds code schrijven om ze te gebruiken.
Andere opvallende alternatieven
- — laagste onafhankelijke kost: $0,80/1K requests met 98,19% succes; start vanaf $29/maand
- Apify — actor-gebaseerd platform met 415+ G2-reviews (4,7/5), maar "Pricing Issues" is de grootste klacht
- — AI/LLM-native, levert markdown met 67% minder tokens dan ruwe HTML; open-source core; vanaf $16/maand
- — enterprise-grade met 72M+ IP’s, vanaf $499/maand; vaste prijs
- ZenRows — 55M residential IP’s, vooraf gebouwde scrapers voor Amazon/Walmart/Zillow, vanaf $69/maand
Welke scrapingtool past bij jouw team?
Aanbevelingen per scenario:
- Als je een developer bent die een aangepaste scraping-pipeline bouwt en granulaire proxycontrole wilt → ScrapingBee of ScraperAPI. Je krijgt fijne HTTP-parameters, keuze in proxytype en volledige controle over rendering. Houd wel rekening met de creditvermenigvuldigers.
- Als je een sales- of marketingteam bent dat leads van websites nodig heeft zonder code te schrijven → . Twee klikken naar gestructureerde data, één klik naar Google Sheets. Geen API, geen selectors, geen parsing.
- Als je snel gestructureerde data van populaire sites nodig hebt → Thunderbit Instant Templates. Amazon, Zillow, Shopify, LinkedIn — vooraf gebouwd en onderhouden, geen AI-setup nodig.
- Als je prijzen of voorraad op schema wilt monitoren zonder devops → Thunderbit Scheduled Scraper. Beschrijf het interval in gewone taal ("elke maandag om 9 uur") en laat het draaien.
- Als je LLM/RAG-pipelines bouwt en schone Markdown op schaal nodig hebt → Thunderbit Distill API of Firecrawl. Beide leveren markdown die geoptimaliseerd is voor AI-verwerking.
- Als prijsvoorspelbaarheid belangrijk is en je geen creditvermenigvuldigers wilt → Thunderbit. 1 credit = 1 rij, ongeacht JS-rendering of proxytype.
Total cost of ownership gaat niet alleen over de API-prijs. Het gaat ook om opzetijd + onderhoudsuren + parsing-engineering + workflow voor data-export. De stickerprijs van ScrapingBee is concurrerend; het totale kostenplaatje minder.
Belangrijkste conclusies uit deze ScrapingBee-review
Vijf punten om te onthouden:
- Creditkosten lopen snel op op schaal. De instapprijs van $49 kan oplopen naar $599+ wanneer JS-rendering en premium proxies nodig zijn. Thunderbit’s vaste 1-credit-per-rij-model haalt die onvoorspelbaarheid weg.
- CSS-selectors brengen doorlopend onderhoud met zich mee; AI-extractie niet. Reken op met AI-tools, en geen selector-breakage wanneer sites worden bijgewerkt.
- Niet-developers krijgen een steile leercurve bij ScrapingBee. Het is een API-only tool die code, HTML-inspectie en selectorconstructie vereist. Zakelijke gebruikers kunnen beter no-code alternatieven bekijken.
- Data-export vereist maatwerk-engineering. ScrapingBee geeft ruwe HTML terug; jij bouwt de pipeline. Thunderbit exporteert gestructureerde data gratis naar .
- Betrouwbaarheid is sterk voor sommige sites, maar wisselvallig voor andere. ScrapingBee werkt goed op Amazon en eBay, maar laat 0% zien op LinkedIn, Zillow en diverse andere zwaar beveiligde targets.
ScrapingBee blijft een capabele tool voor developers die proxy-gestuurde HTTP-toegang met fijne controle willen. Maar het webscrapinglandschap in 2026 is verschoven richting AI-gestuurde, no-code tools — en is specifiek voor die verschuiving gebouwd. Probeer de gratis tier (6 pagina’s gratis, of meer met de proefperiode) om het verschil zelf te zien.
FAQ’s
Is ScrapingBee in 2026 de moeite waard?
Dat hangt af van je technische vaardigheden en schaal. Voor developers die statische pagina’s scrapen op gemiddeld volume, biedt ScrapingBee een solide, goed gedocumenteerde API met responsieve support en een . Voor zakelijke gebruikers, scraping op hoge volumes of teams die gestructureerde data willen zonder te coderen, bieden AI-gestuurde alternatieven zoals Thunderbit meer waarde en aanzienlijk lagere totale eigendomskosten.
Werkt ScrapingBee zonder code?
Nee. ScrapingBee is een API-only tool waarvoor je code moet schrijven (Python, cURL of iets vergelijkbaars) en HTTP-parameters moet begrijpen. Er is geen visuele interface om scrapes te bouwen. Niet-technische gebruikers kunnen beter no-code opties overwegen zoals de , waarmee je data kunt scrapen en exporteren zonder ook maar één regel code te schrijven.
Hoeveel kost ScrapingBee echt per pagina?
Dat hangt af van de ingeschakelde features. Een statische HTML-pagina kost 1 credit. Een JS-gerenderde pagina (standaard) kost . Een premium-proxy + JS-pagina kost 25 credits. Een stealth-proxy-pagina kost 75 credits. AI-extractie voegt daar nog eens +5 credits bovenop toe. Op het Freelance-plan ($49/250K credits) komt dat neer op $0,20 per 1.000 statische pagina’s of $14,70 per 1.000 stealth-proxy-pagina’s. Zie de gedetailleerde kostentabellen hierboven voor het volledige overzicht.
Wat zijn de beste ScrapingBee-alternatieven in 2026?
De belangrijkste alternatieven zijn (AI-gestuurd, no-code Chrome Extension + API, 1 credit = 1 rij), (developer API met gestructureerde endpoints voor specifieke sites), (developer API met sterke anti-bot-bypass), (laagste kost per request in onafhankelijke tests), en (AI/LLM-native, levert schone markdown). Elk heeft een eigen sterktepunt — Thunderbit voor zakelijke gebruikers en prijsvoorspelbaarheid, ScraperAPI en Scrapfly voor proxycontrole door developers, Firecrawl voor LLM-pipelines.
Kan ScrapingBee JavaScript-zware websites scrapen?
Ja, maar het kost 5× de basiscredits met een rotating proxy of 25× met een premium proxy. JavaScript-rendering staat , dus je betaalt al het 5×-tarief tenzij je het expliciet uitzet. Thunderbit handelt JS-rendering automatisch af zonder creditvermenigvuldigers — 1 credit per rij, ongeacht hoe de pagina is opgebouwd.
Meer weten