

Heb je ooit van je manager een stapel PDF-bestanden gekregen met de opdracht om er perfect opgemaakte en nauwkeurige data uit te halen? Dat handmatig doen is een gegarandeerde route naar overuren. Data uit PDF’s halen kan echt een gedoe zijn, omdat PDF’s in tegenstelling tot webdata vaak een inconsistente opmaak hebben. Sommige PDF’s bevatten tabellen, andere zijn gewoon afbeeldingen of gescande documenten, waardoor directe extractie behoorlijk lastig is.
Data van elke website halen met AI Get Started Free
Als je bijvoorbeeld e-mailadressen uit een PDF wilt halen, kunnen sommige in afbeeldingsformaat zijn, terwijl andere verborgen zitten in complexe tekencoderingen. Neem dit voorbeeld: {john.doe,jane.doe}@example.com. Dit staat eigenlijk voor twee losse e-mails: john.doe@example.com en jane.doe@example.com. En dan is er nog {first.last}@example.com, waarbij je “first” en “last” vervangt door respectievelijk de voor- en achternaam van de auteur. Traditionele tekherkenningstools schieten hier simpelweg tekort. Dáár komt een handige tool, de PDF Scraper, om de hoek kijken.
Wat is een PDF Scraper
Een PDF Scraper is een handige tool die automatisch data uit PDF-bestanden haalt en content zoals tabellen en tekst omzet naar de formaten die je nodig hebt, zoals Excel, CSV of JSON. Simpel gezegd verandert het tijdrovend knip- en plakwerk in een oplossing met één klik.
Stel je een stapel facturen, contracten, academische papers of zelfs gescande PDF’s voor die je handmatig uren zou kosten om over te typen. Met een PDF Scraper upload je simpelweg het bestand en wordt de data binnen enkele seconden geëxtraheerd. Dat bespaart tijd en moeite en zorgt tegelijk voor nauwkeurigheid. Zeg maar dag tegen het gedoe van handmatige gegevensinvoer.
Als je PDF verschillende gegevenstypen bevat, zoals tabellen, links en afbeeldingen, laat dan een AI PDF Scraper het werk doen. AI PDF Scrapers gebruiken grote taalmodellen (LLM’s) die tekst, afbeeldingen en tabellen tegelijk kunnen verwerken en indrukwekkende resultaten leveren.
De voordelen van een AI PDF Scraper gaan verder dan efficiëntie en nauwkeurigheid; de flexibiliteit maakt het een zorgeloze keuze. Of je nu te maken hebt met gescande documenten, afbeeldingen of meertalige PDF’s, AI verwerkt het allemaal moeiteloos. Er zijn veel goede AI-tools beschikbaar, zoals Thunderbit, ChatGPT en ChatPDF, elk met unieke functies voor verschillende behoeften. Of je nu snel data wilt extraheren of complexe documenten wilt analyseren, de juiste tool kiezen kan je werk makkelijker en efficiënter maken.
Probeer het zelf: data uit PDF’s extraheren met AI
Tip: je kunt klikken, rondkijken en de workflow uitvoeren terwijl je meekijkt.
Hoe kies je de juiste PDF Scraper
Een PDF Scraper kiezen is als een auto kopen; de beste is degene die past bij jouw behoeften. Hier zijn een paar punten om rekening mee te houden:
| Functie | Beschrijving |
|---|---|
| Nauwkeurigheid en stabiliteit | Controleer of de tool data nauwkeurig extraheert, vooral als het om cruciale informatie gaat. |
| Uitvoerformaten | Zorg ervoor dat de tool de uitvoerformaten ondersteunt die je nodig hebt, zoals Excel, CSV of JSON. |
| Integratie met andere tools | Als je verbinding moet maken met de systemen van je bedrijf, kijk dan of er soepele integratiemogelijkheden zijn. |
| Gebruiksvriendelijke interface | Een gebruiksvriendelijke tool is beter voor algemene gebruikers, terwijl complexere tools meer geschikt kunnen zijn voor technische teams. |
Verschillende tools hebben hun eigen sterke punten, en de juiste keuze kan je productiviteit aanzienlijk verhogen. Hier zijn drie populaire PDF Scrapers, elk met eigen functies voor verschillende behoeften:
| Tool | Voordelen | Nadelen |
|---|---|---|
| Thunderbit | Snelle extractie; eenvoudig te gebruiken als browserextensie; ideaal voor samenwerking in teams | Beperkte schaal voor dataverwerking |
| ChatPDF | Makkelijk in gebruik, chat-achtige Q&A op één enkele PDF | Geen native export naar CSV/Excel/JSON — antwoorden blijven in de chat |
| ChatGPT | Flexibel bij complexe semantiek, breed inzetbaar | Vereist elke keer handmatige promptinvoer |
Aan de slag met AI PDF Scraper
Thunderbit
Wil je snel data uit PDF’s halen zonder al te veel tijd en moeite te besteden? Dan is Thunderbit de tool voor jou. Hij is eenvoudig te gebruiken en met slechts één klik heb je alles geregeld. Volg deze stappen om complexe PDF-data eenvoudig om te zetten naar het formaat dat je nodig hebt, zodat je efficiëntie flink stijgt:
-
Voeg Thunderbit toe aan Chrome en meld je aan:
Ga naar de officiële Thunderbit-website en voeg de Thunderbit extensie toe aan je Chrome-browser. Meld je aan met je Google-account of een ander e-mailadres.

-
Open de PDF in Chrome:
Open het PDF-bestand waarvan je data wilt extraheren in Chrome en klik op het Thunderbit-pictogram rechtsboven.
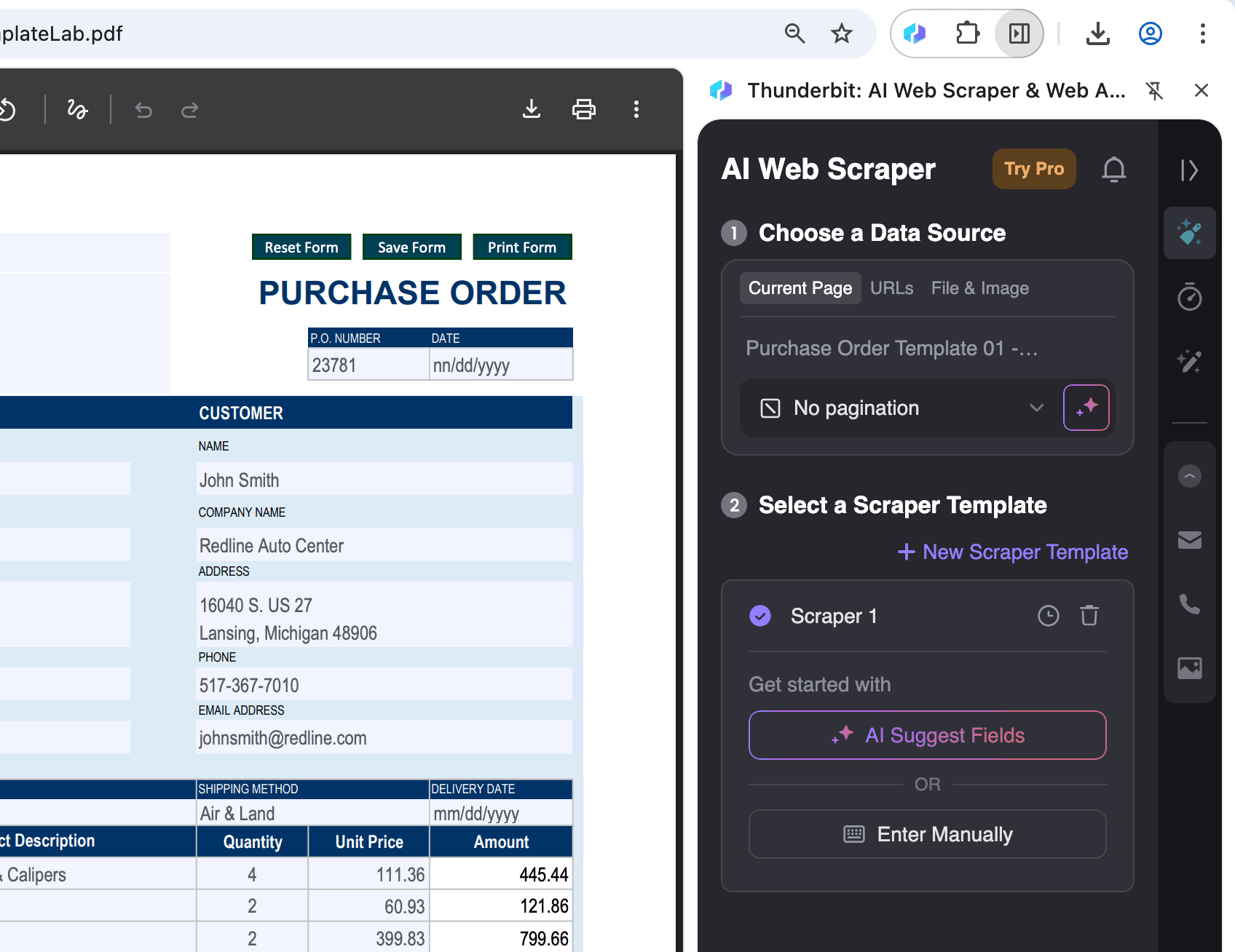
-
Kies het uitvoerformaat en exporteer:
Nadat je AI Suggest Columns hebt geselecteerd, kun je de data filteren of aanpassen waar nodig. Kies daarna het gewenste exportformaat (CSV, Google Sheets, Airtable of Notion) en klik op Scrape om de data te exporteren.
 De geëxporteerde data kan direct worden gekoppeld aan Notion, Airtable of Google Sheets voor eenvoudige samenwerking in teams.
De geëxporteerde data kan direct worden gekoppeld aan Notion, Airtable of Google Sheets voor eenvoudige samenwerking in teams.
Thunderbit is een eenvoudige tool voor het extraheren van PDF-data waarmee je snel de data kunt ophalen die je nodig hebt uit PDF-bestanden en deze kunt omzetten naar een bruikbaar formaat. Voor persoonlijk gebruik of samenwerking in teams kan Thunderbit je productiviteit aanzienlijk verhogen en data-extractie makkelijker en handiger maken.
ChatPDF
Als je PDF’s in bulk moet verwerken en alleen specifieke kerninformatie wilt extraheren in plaats van alle data, dan is ChatPDF een handige hulp. Je kunt data extraheren op een gespreksachtige manier, waardoor het geschikt is voor beginners.
Zo haal je PDF-data uit ChatPDF:
- Bezoek de ChatPDF-website: Open de ChatPDF website of de bijbehorende platformpagina.
- Upload PDF-bestanden: Klik op de knop "Upload File" om het PDF-document dat je wilt analyseren te slepen of te selecteren. Het ondersteunt verschillende bestandstypen, zoals contracten, papers of financiële overzichten.
- Analyseer de PDF: Zodra het bestand is geüpload, parseert ChatPDF automatisch de inhoud en genereert het een gestructureerde samenvatting van het document. Daarna kun je de geëxtraheerde kerninformatie bekijken.
- Stel interactieve vragen: Gebruik het invoerveld om vragen te stellen zoals "Wat is de conclusie van dit rapport?" of "Wat is het totale bedrag dat op de factuur staat?" ChatPDF haalt op basis van je vraag relevante content eruit.
- Kopieer de antwoorden: ChatPDF geeft antwoorden terug in het chatvenster. Kopieer het antwoord naar een spreadsheet, document of je eigen tabel — voor sterk gestructureerde uitvoer (schone CSV/JSON met consistente kolommen over veel bestanden) passen Thunderbit of ChatGPT met een vaste prompt beter.
ChatPDF biedt een interactieve ervaring en is daardoor vooral geschikt om snel documentinformatie te vinden, zoals belangrijke details opzoeken of de inhoud van documenten samenvatten.
ChatGPT
ChatGPT blinkt uit in het verwerken van complexe semantische data, zoals het ontleden van clausules in juridische documenten. Deze tool is zeer flexibel en laat je prompts aanpassen om specifieke data te extraheren of content te analyseren. Wel moet je bij vergelijkbare taken steeds dezelfde prompt opnieuw gebruiken, en het vereist een goed begrip van prompt-engineering.
Hier is een vooraf geschreven prompt die je naar wens kunt aanpassen (vergeet niet de kolommen te vervangen door de informatie die je wilt extraheren):
Je bent nu een PDF scraper. Als je een PDF krijgt, moet je de content extraheren op basis van de kolommen die de gebruiker opgeeft. Je uitvoer moet een CSV-bestand zijn.
Hier zijn de kolommen:
1. Naam
2. E-mail
3. Telefoonnummer
4. ...
- Registreren of inloggen: Open de ChatGPT website en maak een account aan. Heb je al een account, log dan gewoon in.
- PDF uploaden en vraag invoeren: Typ je vraag direct in het invoerveld; hoe specifieker, hoe beter. Bijvoorbeeld: "Dit PDF-document bevat drie grafieken, exporteer ze als tabellen."
- Resultaten controleren en aanpassen: Controleer of het antwoord aan je verwachtingen voldoet. Verfijn de resultaten indien nodig door vervolgvragen te stellen of de prompt aan te passen.
- Data exporteren als Excel of CSV: Als de data die ChatGPT heeft geëxtraheerd klopt, typ dan in het invoerveld: "Exporteer deze data als Excel of CSV."
- Resultaten opslaan: Klik op de bestandslink die ChatGPT geeft om het bestand te downloaden.
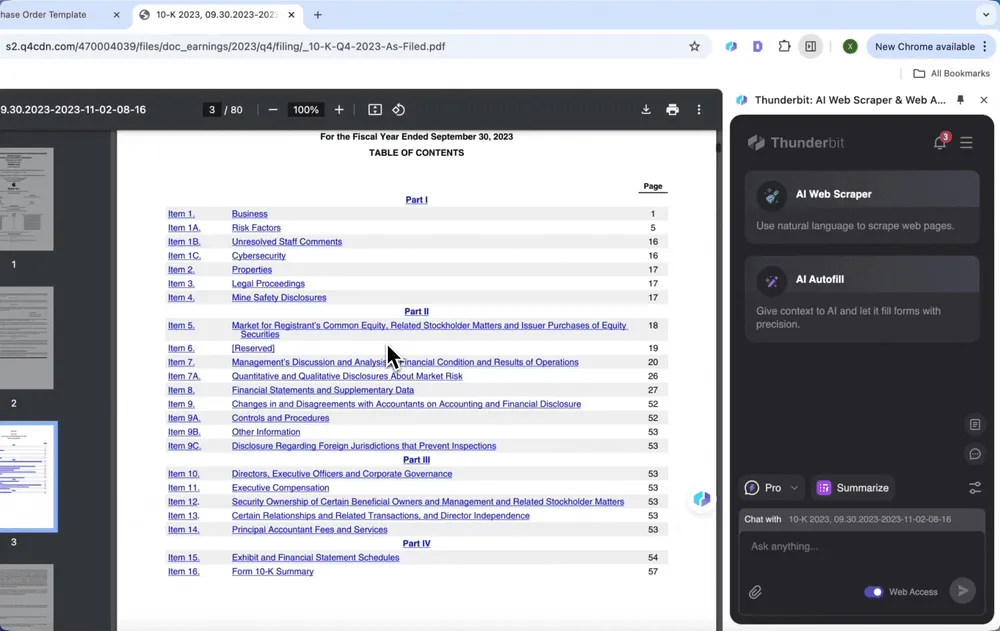
Praktische toepassingen van AI PDF Scraper
AI PDF Scraper is als een veelzijdige assistent op je werk, of je nu te maken hebt met facturen, contracten, financiële rapporten of inkooporders. Hier zijn enkele praktische scenario’s waarin het echt uitblinkt:
Verwerking van facturen en bonnetjes
Verwerk bedrijfsfacturen en bonnetjes in batches en extraheer kerninformatie zoals bedragen en data voor classificatie en archivering.
- Start Thunderbit, klik op AI Web Scraper en vervolgens op Bulk Pages
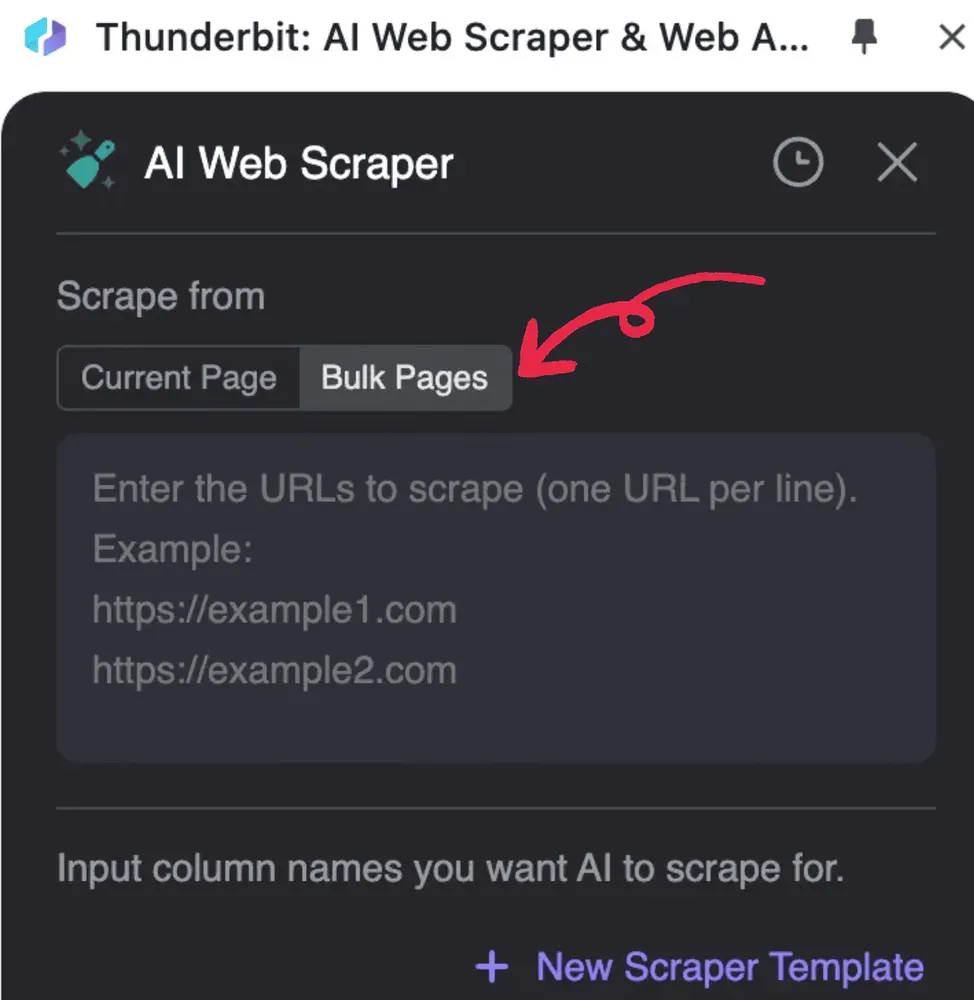 2. Voer de PDF-URL’s in die je wilt verwerken, één URL per regel
2. Voer de PDF-URL’s in die je wilt verwerken, één URL per regel
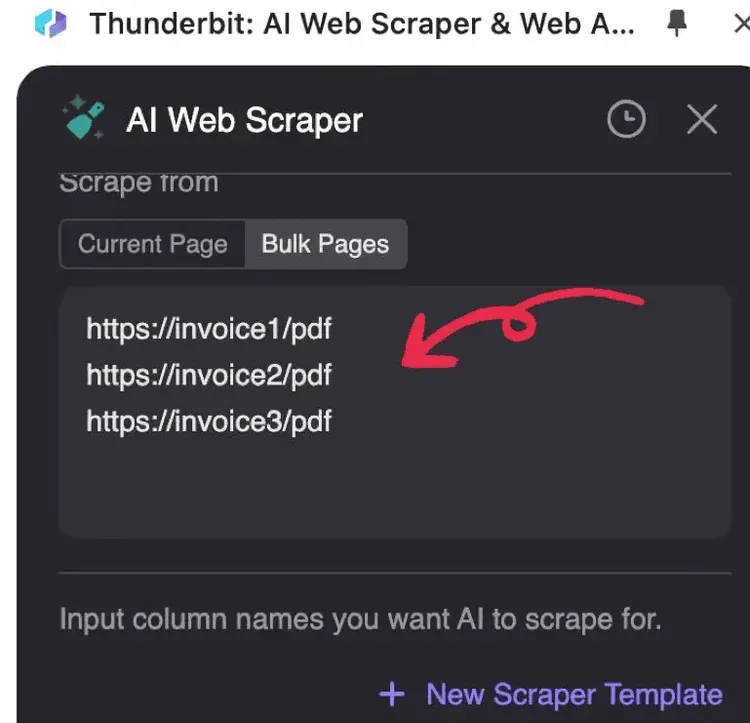 3. Klik op AI Suggest Columns (AI leest de PDF en stelt voor hoe de data moet worden gestructureerd)
4. Klik op Scrape en exporteer de data
3. Klik op AI Suggest Columns (AI leest de PDF en stelt voor hoe de data moet worden gestructureerd)
4. Klik op Scrape en exporteer de data
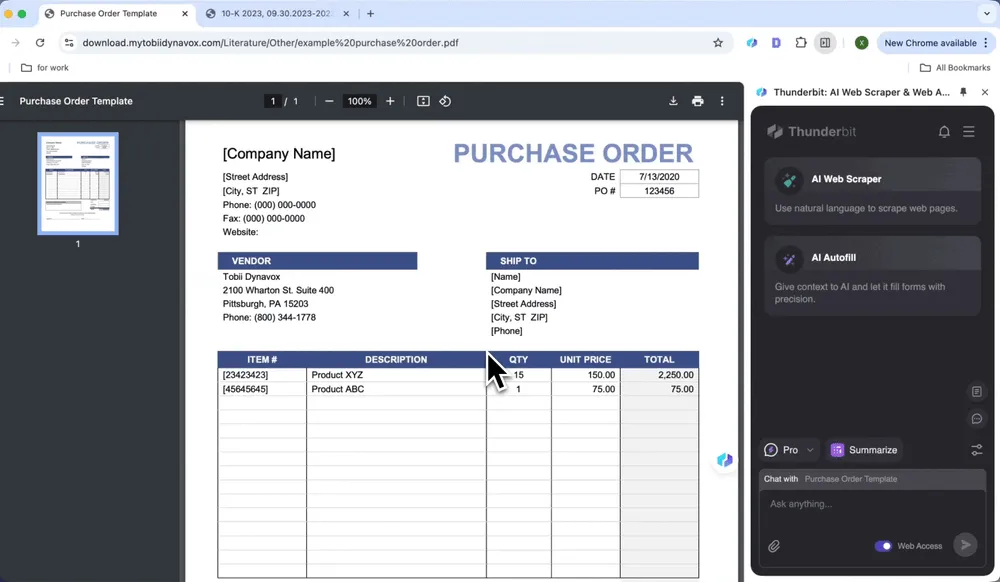
Verwerking van inkooporders
Identificeer automatisch artikelen, aantallen en stukprijzen in inkooporders, genereer gestandaardiseerde datarijen en haal data uit PDF’s, zodat handmatige verwerking minder tijd kost.
- Open de inkooporder in Chrome en start Thunderbit
- Klik op AI Web Scraper en daarna op AI Suggest Columns
- Controleer de gegenereerde lijstnamen en klik op Scrape
- Klik op Download CSV
Extractie van financiële data
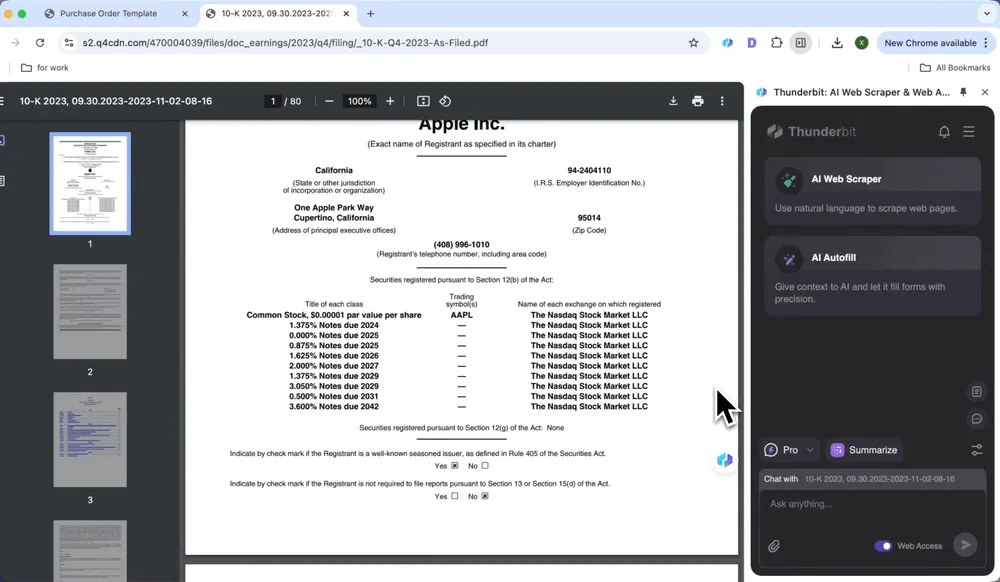
Extraheer met één klik data uit financiële rapporten, zoals winstmarges en verkoopcijfers, zodat tijdrovende handmatige controle niet meer nodig is.
- Open het financiële rapport in Chrome en start Thunderbit
- Klik op Summarize
- Genereer automatisch een samenvatting van kerninformatie, inclusief tekst en tabelinhoud
Niet tevreden met de automatisch gegenereerde samenvatting? Je kunt de projectinformatie die je wilt ook handmatig invoeren.
- Open het financiële rapport in Chrome en start Thunderbit
- Klik op AI Web Scraper en voer de projectnamen in die je wilt, zoals Net Income, Sales, enz.
- Klik op Scrape, uitvoer als tabel
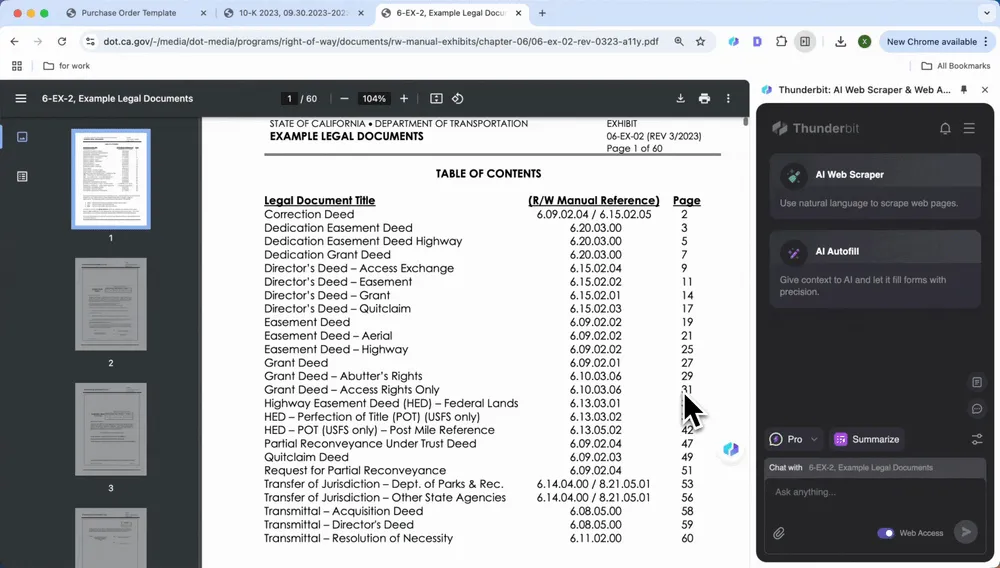
Analyse van juridische documenten
Problemen met clausules in contracten en overeenkomsten? AI-tools kunnen snel betalingsvoorwaarden, wanprestatieclausules, contractduur en andere belangrijke punten vinden. Extraheer ze met één klik om een beknopte samenvatting of lijst met clausules te genereren, zodat je tijd bespaart en niets over het hoofd ziet.
Net als bij het extraheren van kerninformatie uit financiële rapporten kun je de PDF openen en op Summarize klikken om betalingsvoorwaarden, wanprestatieclausules, contractduur en andere belangrijke informatie met één klik te bekijken.
Veelgestelde vragen
-
Kan ik data uit meerdere PDF’s tegelijk extraheren?
Ja, geavanceerde PDF scraping-tools maken het mogelijk om data uit meerdere PDF’s tegelijk te halen. Deze batchverwerking versnelt de workflow aanzienlijk vergeleken met handmatige extractiemethoden.
-
Is PDF Scraper gratis?
Ja, er zijn verschillende gratis PDF scraper-tools beschikbaar. Veel online tools, zoals Thunderbit en ChatPDF, bieden gratis functies voor pagina-extractie en data-extractie. Hoewel sommige geavanceerde functies betaald kunnen zijn, zijn de basisfuncties voor data-extractie doorgaans gratis.
-
Is programmeerkennis nodig om een PDF scraper te gebruiken?
Nee, veel AI PDF scrapers, zoals Thunderbit, zijn ontworpen voor gebruikers zonder programmeerkennis. Ze hebben gebruiksvriendelijke interfaces waarmee je bestanden kunt uploaden en met slechts een paar klikken data kunt extraheren.
-
Welke soorten documenten kunnen met een PDF scraper worden verwerkt?
PDF scrapers kunnen verschillende soorten documenten verwerken, waaronder facturen, contracten, financiële rapporten, academische papers en andere gestructureerde of semi-gestructureerde content in PDF-bestanden.
-
Is mijn data veilig bij gebruik van een PDF scraper?
Betrouwbare PDF scraping-tools geven prioriteit aan gebruikersveiligheid en voldoen vaak aan regelgeving zoals de AVG. Ze bewaren je data doorgaans op versleutelde servers en openen die niet zonder jouw toestemming.
-
Zijn er nog andere manieren om data uit PDF’s te halen?
Er zijn meerdere methoden om data uit PDF-bestanden te halen naast handmatige invoer en Python-scripting. Denk aan PDF-converters om bestanden om te zetten naar formaten zoals Excel of CSV, gespecialiseerde tools voor PDF-data-extractie zoals Tabula en Excalibur voor gestructureerde documenten, AI-oplossingen met optical character recognition (OCR) voor zowel native als gescande PDF’s, en open-source tools zoals Extractous en PymuPDF4llm die zijn ontworpen voor efficiënte data-extractie. Elke methode heeft eigen voor- en nadelen, dus de keuze hangt af van de specifieke eisen en technische kennis van de gebruiker.
Meer weten
- Hoe je elke website kunt scrapen met AI
- De 5 beste tools met AI om data uit PDF’s te extraheren
- Hoe je ChatGPT gebruikt om data uit PDF’s te extraheren
- Gratis PDF-samenvatter online
Probeer AI Web Scraper Get Started Free




