Je meldt je aan voor ScraperAPI, ziet “100.000 credits” op je Hobby-plan en gaat enthousiast aan de slag met scrapen. Drie dagen later laat je dashboard zien dat 80% van die credits al op is — en je hebt misschien 6.000 pagina’s binnengehaald. Wat is hier gebeurd? Het antwoord is het credits-vermenigvuldigingssysteem, en dat is zonder twijfel het belangrijkste onderdeel van ScraperAPI dat in bijna geen enkele review echt goed wordt uitgelegd. Ik heb weken besteed aan het doorspitten van ScraperAPI’s documentatie, het verzamelen van echte prijsdata van vijf concurrerende providers en het lezen van elke Reddit-thread en Capterra-review die ik kon vinden. Deze ScraperAPI-review is precies het artikel dat ik zelf had willen lezen toen ons team voor het eerst scraping-API’s begon te vergelijken. Ik laat je de echte rekensom achter credits zien, waar ScraperAPI goed in is (en waar het compleet de mist in gaat), vat samen wat echte gebruikers zeggen op G2, Capterra en Reddit, en — heel eerlijk — help ik je uitzoeken of je überhaupt wel een scraping-API nodig hebt.
Wat is ScraperAPI en voor wie is het bedoeld?
ScraperAPI is een webscraping-API die de lastige infrastructuur achter grootschalig scrapen uit handen neemt: proxyrotatie over , automatische CAPTCHA-oplossing, JavaScript-rendering en automatische retries. Je stuurt simpelweg een URL via een API-call op, en krijgt de HTML terug (of geparseerde JSON als je hun structured data-endpoints gebruikt). Het bedrijf is opgericht in 2018 door Daniel Ni, heeft zijn hoofdkantoor in Las Vegas en bedient inmiddels , waaronder Deloitte, Sony en Alibaba — goed voor .
De belangrijkste doelgroep bestaat uit developmentteams en technische operations-teams die eigen scraping-pijplijnen bouwen. Als je niet codeert, is ScraperAPI niet echt voor jou bedoeld (daar kom ik later nog op terug).
Kernfunctionaliteiten: proxyrotatie, JavaScript-rendering, geotargeting, structured data-endpoints voor populaire websites en automatische retries voor mislukte requests.
Maar hier zit meteen de valkuil die de meeste reviews overslaan: de kredietaantallen op ScraperAPI’s prijspagina zijn behoorlijk misleidend als je de multipliers niet snapt. Dus daar beginnen we.
Hoe het creditsysteem van ScraperAPI echt werkt (het deel dat de meeste reviews overslaan)
ScraperAPI rekent af op basis van credits. Het basisidee klinkt simpel: 1 API-request = 1 credit. Alleen loopt dat in de praktijk bijna nooit zo. De werkelijke kredietkost hangt af van twee dingen: het domein dat je scrapt en de feature-flags die je aanzet. En die kosten stapelen op manieren die niet bepaald logisch voelen.
De credit-multiplier-tabel die elke gebruiker zou moeten zien vóór inschrijving

Nog voordat je ook maar één parameter aanzet, bepaalt het type website dat je scrapt al je basiskost in credits:
| Domeincategorie | Basiscredits per request | Voorbeelden |
|---|---|---|
| Normale websites | 1 | Blogs, nieuwssites, simpele HTML |
| E-commerce | 5 | Amazon, eBay, Walmart |
| SERP (zoekmachines) | 25 | Google, Bing |
| Social media | 30 |
Daarbovenop komen extra credits voor feature-flags:
| Parameter | Extra credits | Opmerkingen |
|---|---|---|
render=true (JS-rendering) | +10 | Alle plannen |
screenshot=true | +10 | Alle plannen |
premium=true (premium proxy) | +10 | Alle plannen |
ultra_premium=true | +30 | Alleen betaalde plannen |
| Anti-bot omzeiling (Cloudflare, DataDome, PerimeterX) | +10 elk | Automatisch gedetecteerd — je kiest dit niet zelf |
premium=true + render=true gecombineerd | +25 | NIET +20 |
ultra_premium=true + render=true gecombineerd | +75 | NIET +40 |
Die laatste rij is de echte adder onder het gras. Gecombineerde features kosten MÉÉR dan de losse onderdelen bij elkaar opgeteld. Premium proxy (+10) plus JavaScript-rendering (+10) zou logisch gezien +20 extra credits moeten kosten, maar ScraperAPI rekent . Ultra-premium (+30) plus JavaScript-rendering (+10) zou +40 moeten zijn, maar in werkelijkheid is het — bijna het dubbele. Deze niet-lineaire stapeling staat niet heel prominent in de documentatie, en dat is precies waarom gebruikers melden dat hun credits sneller verdwijnen dan verwacht.
Parameters die nul extra credits kosten: wait_for_selector, country_code, session_number, device_type, output_format, keep_headers=true, autoparse=true.
Wat elk plan je nu echt geeft: van Free tot Enterprise
Hier zijn de van ScraperAPI:
| Plan | Maandprijs | Jaarlijks (per maand) | API-credits | Gelijktijdige threads | Geotargeting |
|---|---|---|---|---|---|
| Free | $0 | — | 1.000 | 5 | Nee |
| Hobby | $49 | $44 | 100.000 | 20 | Alleen VS & EU |
| Startup | $149 | $134 | 1.000.000 | 50 | Alleen VS & EU |
| Business | $299 | $269 | 3.000.000 | 100 | Op landenniveau (50+ landen) |
| Scaling | $475 | $427 | 5.000.000 | 200 | Op landenniveau |
| Enterprise | Maatwerk | Maatwerk | 5.000.000+ | 200+ | Op landenniveau |
En dit zijn de effectieve kosten per 1.000 requests per plan, met de multipliers erbij gerekend:
| Plan | Standaard (1×) | JS-rendering (10×) | E-commerce (5×) | SERP (25×) | Ultra-Premium + JS (75×) |
|---|---|---|---|---|---|
| Hobby ($49) | $0,49 | $4,90 | $2,45 | $12,25 | $36,75 |
| Startup ($149) | $0,15 | $1,49 | $0,75 | $3,73 | $11,18 |
| Business ($299) | $0,10 | $1,00 | $0,50 | $2,49 | $7,48 |
| Scaling ($475) | $0,10 | $0,95 | $0,48 | $2,38 | $7,13 |
Een plan van $49 per maand dat wordt verkocht als “100.000 credits” levert uiteindelijk nog maar 1.333 echte requests op als je beschermde websites scrapt met ultra-premium plus JavaScript-rendering. Dat komt neer op — duurder dan veel volledig beheerde scrapingdiensten.
Waarom credits sneller verdwijnen dan je verwacht
Drie dingen verrassen gebruikers vaak.
Ten eerste: domeingebaseerde prijsstelling gebeurt automatisch. Je kiest niet zelf voor de 5× Amazon-multiplier of de 25× Google-multiplier. Die wordt toegepast zodra ScraperAPI het domein herkent. Hetzelfde geldt voor anti-bot-omzeilingcredits (+10 voor Cloudflare, DataDome, PerimeterX) — die worden automatisch toegevoegd zodra ze worden gedetecteerd.
Ten tweede: credits schuiven niet door naar de volgende periode. Niet-gebruikte credits . Geen opslag, geen rollover.
En ten derde — en dat steekt — Pay-As-You-Go is alleen beschikbaar vanaf het Scaling-plan ($475/maand) en hoger. Als je op Hobby, Startup of Business zit en je credits halverwege de cyclus op zijn, word je simpelweg uitgeschakeld tot de volgende factureringsperiode. Je enige optie is upgraden naar het volgende niveau.
Een gebruiker op Reddit meldde dat hem $3.600 werd geoffreerd voor 60 miljoen credits bij 1 credit per Amazon-request, maar dat er na betaling zonder duidelijke waarschuwing alsnog een 5-credit multiplier werd toegepast. Hun 60M-plan was daardoor effectief nog maar goed voor 12M requests — een ten opzichte van de verwachting.
De credit-val van DataPipeline
ScraperAPI’s no-code DataPipeline-functie (geplande scraping met webhook-levering) gebruikt een apart, flink duurder creditschema. Een basisrequest naar een normale website kost via de standaard-API:
| Type request | Standaard API | DataPipeline | Verhouding |
|---|---|---|---|
| Basisrequest normale site | 1 | 6 | 6× |
| Basis e-commerce | 5 | 10 | 2× |
| Basis SERP | 25 | 30 | 1,2× |
| Ultra-premium + JS (normaal) | 75 | 80 | 1,07× |
Gebruikers die no-code pipelines opzetten en standaard creditkosten verwachten, merken al snel dat ze 6× credits verbranden op basisrequests. Dat staat wel gedocumenteerd, maar je moet er echt even voor zoeken.
Werkelijke kosten per request: ScraperAPI vs. de concurrentie
Headline-prijzen zeggen weinig als je de multipliers niet meerekent. Ik heb de actuele prijzen van vijf providers verzameld en de vergelijking gestandaardiseerd op het prijsniveau van ongeveer $300 per maand voor drie veelvoorkomende scenario’s.
Basale HTML-scrape (geen JS, geen premium proxy)
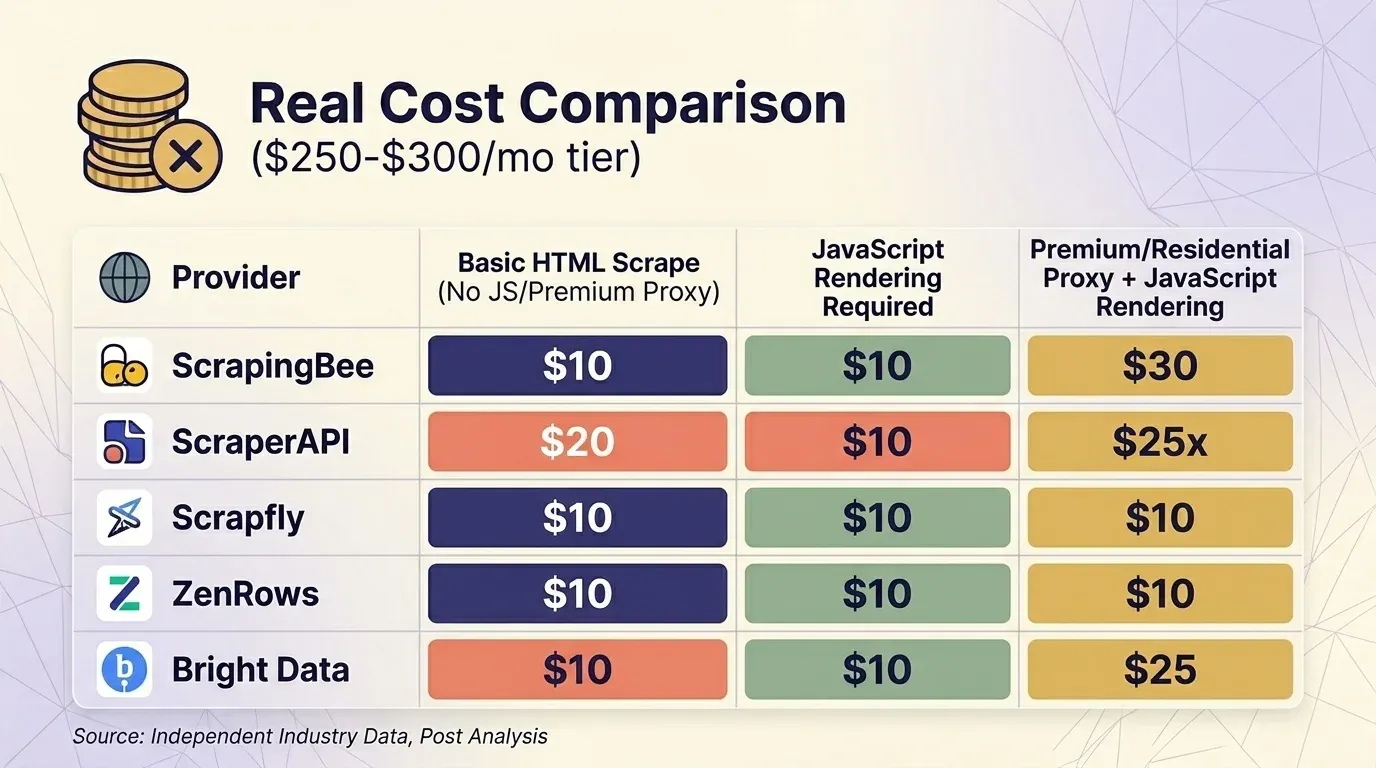
| Provider | Plan | Credits per request | Echte requests | Kosten per 1K |
|---|---|---|---|---|
| ScrapingBee | Business $249 | 1 | 3.000.000 | $0,08 |
| ScraperAPI | Business $299 | 1 | 3.000.000 | $0,10 |
| Scrapfly | Startup $250 | 1 | 2.500.000 | $0,10 |
| ZenRows | Business $300 | $0,28/1K | ~1.071.000 | $0,28 |
| Bright Data | PAYG | $1,50/1K | ~200.000 | $1,50 |
JavaScript-rendering vereist
| Provider | Plan | Credits per request | Echte requests | Kosten per 1K |
|---|---|---|---|---|
| ScrapingBee | Business $249 | 5 (standaard aan) | 600.000 | $0,42 |
| Scrapfly | Startup $250 | 6 | 416.667 | $0,60 |
| ScraperAPI | Business $299 | 10 | 300.000 | $1,00 |
| ZenRows | Business $300 | 5× | ~214.000 | $1,40 |
| Bright Data | PAYG | vast tarief | ~200.000 | $1,50 |
Premium/residential proxy + JavaScript-rendering (beschermde sites)
| Provider | Plan | Credits per request | Echte requests | Kosten per 1K |
|---|---|---|---|---|
| Bright Data | PAYG | vast tarief | ~200.000 | $1,50 |
| ScrapingBee | Business $249 | 25 | 120.000 | $2,08 |
| ScraperAPI | Business $299 | 25 | 120.000 | $2,49 |
| Scrapfly | Startup $250 | 31 | 80.645 | $3,10 |
| ZenRows | Business $300 | 25× | ~42.857 | $7,00 |
Bright Data’s Web Unlocker is de enige provider die — alle requests kosten daar hetzelfde vaste tarief. In het prijssegment rond $300 zijn ScrapingBee en ScraperAPI concurrerend voor scraping van beschermde websites, terwijl ZenRows het duurst uitvalt.
Een belangrijk praktisch detail: ScrapingBee tegen 5× kosten. Vergelijk je ScrapingBee en ScraperAPI direct met elkaar, zorg dan dat je exact dezelfde renderinginstellingen vergelijkt.
Een onafhankelijke analyse van Scrape.do stelde vast dat ScraperAPI gemiddeld — “meer dan elke andere geteste provider” — met een gemiddelde responstijd van , waardoor het “een van de langzaamste beschikbare providers” zou zijn. Goed om te weten voordat je je vastlegt.
Sitespecifieke succescijfers: waar ScraperAPI uitblinkt en waar het worstelt
Geen enkele scraping-API presteert even goed op elke website. Onafhankelijke benchmarks van Scrapeway (april 2026) laten een opvallend tweeslachtig beeld zien.
Prestaties per sitetype
| Doelsite | Succespercentage | Gem. snelheid | Kosten per 1K (Business-plan) |
|---|---|---|---|
| Zillow | 100% | 10,5s | $0,49 |
| Etsy | 99% | 4,8s | $4,90 |
| Amazon | 98% | 6,5s | $2,45 |
| 95% | 17,8s | $14,70 | |
| Walmart | 93% | 11,4s | $2,45 |
| Indeed | 90% | 15,8s | $4,90 |
| StockX | 84% | 3,9s | $4,90 |
| Realtor.com | 12% | 11,8s | $0,49 |
| 0% | — | — | |
| Booking.com | 0% | — | — |
| Twitter/X | 0% | — | — |
Totale gemiddelde succeskans: , net boven het sectorgemiddelde van 58,2–59,5%. Gemiddelde responstijd: 5,2–7,3 seconden, beter dan het sectorgemiddelde van 9,8 seconden.
Waar ScraperAPI goed presteert
ScraperAPI is echt sterk in e-commerce (Amazon, Walmart, Etsy) en vastgoed (Zillow). De structured data-endpoints voor deze sites leveren betrouwbaar geparste JSON op. Als je belangrijkste use case het scrapen van Amazon-productpagina’s of Google SERP’s is, dan is ScraperAPI een prima keuze.
Waar ScraperAPI tekortschiet
Social media is een leeg terrein. Instagram, Twitter/X en Booking.com laten in onafhankelijke tests allemaal een succeskans van 0% zien. LinkedIn werkt op 95%, maar tegen 30 credits per request lopen de kosten snel op.
Sites waarvoor je moet inloggen zijn expliciet uitgesloten. ScraperAPI ondersteunt sessiebehoud via de session_number-parameter, maar . Formulieren invullen, tweefactorauthenticatie of ingewikkelde auth-flows kan het niet afhandelen.
Verouderde data op lastige targets. ScraperAPI past op , wat betekent dat je bij tijdsgevoelige data zoals prijzen of voorraadniveaus resultaten kunt krijgen die tot 10 minuten oud zijn.
In Proxyway’s benchmark uit 2025 had ScraperAPI de met 81,72%.
Samenvatting van prestaties per sitetype
| Sitetype | Prestaties van ScraperAPI | Bekende problemen | Mogelijk alternatief |
|---|---|---|---|
| Amazon / e-commerce | ✅ Sterk (SDP-endpoints) | Creditsintensief op schaal | Thunderbit templates (1 klik, geen credits per rij voor de template) |
| Google SERP’s | ✅ Sterk | Geotargeting kost extra; laagste Google-succes in één benchmark | — |
| Vastgoed (Zillow) | ✅ Uitstekend (100%) | — | — |
| Instagram / social media | ❌ 0% succes | Volledige mislukking | Playwright + proxies (zelf bouwen) |
| JS-zware SPA’s | ⚠️ Matig | Vereist headless rendering tegen 10× credits | Scrapfly, ZenRows |
| Sites met loginvereiste | ❌ Verboden volgens ToS | Geen sessie-/auth-ondersteuning | Thunderbit browser scraping (gebruikt je inlogsessie) |
| Booking.com / travel | ❌ 0% succes | Volledige mislukking | Bright Data |
Wat echte gebruikers zeggen: samenvatting van G2, Capterra en Reddit
Ik heb feedback van drie platforms verzameld. Dit zijn de huidige beoordelingen:
| Platform | Beoordeling | Reviews |
|---|---|---|
| G2 | 4,4/5 | 16 |
| Capterra | 4,6/5 | 62 |
| Trustpilot | 4,5/5 | 43 |
Capterra-subscores: Gebruiksgemak 4,9/5, Klantenservice 4,6/5, Functies 4,5/5, Prijs-kwaliteit 4,5/5.
Samenvatting van sentiment per thema
| Thema | Positieve signalen | Negatieve signalen |
|---|---|---|
| Installatiegemak / documentatie | "Super easy to set up. You can start scraping in minutes." — Latenode community; Capterra Ease of Use 4,9/5 | — |
| Prijs-transparantie | "Affordable entry tier" (meerdere Capterra-reviews) | "Breakdown of credit costs can be confusing" — John S., Founder, Capterra (feb. 2025); "Prices increased by 1000% and quality degraded" — CTO, Online Media, Capterra (sep. 2022) |
| Betrouwbaarheid | "Works great for Amazon/Google" (G2, Capterra) | "ScraperAPI becomes shaky for heavy duty jobs" — emcarter, Latenode; "80% failure rate on some targets" (Reddit) |
| Klantenondersteuning | "Responsive team" (Capterra) | Gebruiker meldde dat hem eerst één prijs werd genoemd en daarna 5× werd gefactureerd zonder voorafgaande melding (Reddit) |
| Waarde op de lange termijn | Rekent alleen voor succesvolle (200/404) requests | "If you're running large-scale operations, the expenses can add up quickly" en eigen infrastructuur bouwen is "more cost-effective in the long run" — mikezhang, Latenode |
De conclusie: ScraperAPI wordt goed beoordeeld voor het gemak van de eerste opzet en presteert betrouwbaar op populaire, goed ondersteunde targets. De klachten gaan vooral over prijssurprises (multipliers, onverwachte verhogingen) en betrouwbaarheid bij lastigere targets.
Zijn de structured data-endpoints van ScraperAPI de extra credits waard?
ScraperAPI biedt over 5 platformen, en geeft geparste JSON terug in plaats van ruwe HTML:
- Amazon (3 endpoints): productdetails op ASIN, zoekresultaten, concurrent-aanbiedingen. Levert 18+ velden op, waaronder prijzen, beoordelingen, beschrijvingen, reviews, BSR, afbeeldingen en verkopersinformatie. Ondersteunt .
- Google (5 endpoints): (organische resultaten, knowledge graph, video’s, gerelateerde vragen, paginering), Shopping, Maps, Nieuws en Jobs.
- Walmart (4 endpoints): Product, Zoekresultaten, Categorie, Reviews.
- eBay (2 endpoints): Product, Zoekresultaten.
- Redfin (4 endpoints): Zoekresultaten, agentdetails, huurwoningen, te koop.
SDE’s zijn beschikbaar op alle plannen, inclusief Free. ScraperAPI claimt een voor ondersteunde SDE-domeinen — al laten onafhankelijke benchmarks een genuanceerder beeld zien, afhankelijk van de site.
Datavolledigheid
De Amazon SDP is het sterkste aanbod van ScraperAPI. Je krijgt een uitgebreide set velden terug: prijs, reviews, BSR, varianten, afbeeldingen, verkopersinformatie en meer. De Google SERP SDP levert organische resultaten, advertenties, featured snippets en People Also Ask. De datavolledigheid is voor deze twee platformen echt sterk.
Credit-efficiëntie: SDP versus zelf parseren
Op het Business-plan ($299/maand, 3M credits) kost het scrapen van 10.000 Amazon-producten via de SDE 50.000 credits (5 per stuk) — ongeveer $5 van het plan. Je eigen parser bouwen met een standaardrequest (1 credit per stuk) kost slechts 10.000 credits, maar dan moet je wel tijd steken in het bouwen en onderhouden van die parser.
Voor kleine teams zonder developers besparen SDE’s echt tijd.
Voor teams met engineeringcapaciteit die op schaal scrapen, is die 5× credit-premie lastig goed te praten.
Hoe SDPs zich verhouden tot no-code scraper templates
Deze vergelijking is belangrijker dan de meeste reviews laten zien. biedt kant-en-klare scraper-templates voor Amazon, Shopify, Zillow en die geen code vereisen en zelf geen per-rij creditkosten hebben voor de template.
| Factor | ScraperAPI SDP (Amazon) | Thunderbit Amazon-template |
|---|---|---|
| Insteltijd | 30–60 min (code + API-integratie) | ~2 minuten (extensie installeren, Amazon openen, template klikken) |
| Kosten per 1.000 producten (Business-plan) | ~$5 (50.000 credits tegen $0,10/credit) | ~$16,50 (1.000 rijen × 1 credit tegen $0,0165/credit op Pro) |
| Teruggegeven velden | 18+ (uitgebreid) | Productnaam, prijs, beoordeling, reviews, afbeeldingen, URL en meer |
| Exportopties | JSON (vereist code om te parsen) | Excel, CSV, Google Sheets, Airtable, Notion — 1 klik |
| Onderhoud | ScraperAPI onderhoudt de SDP | Thunderbit-team onderhoudt templates |
| Technische kennis | Python/Node.js vereist | Geen |
Voor developmentteams die Amazon op hoog volume scrapen, is ScraperAPI’s SDP op schaal per product goedkoper. Voor zakelijke gebruikers die Amazon-data in een spreadsheet willen zonder code te schrijven, is Thunderbit veel sneller in te stellen en te gebruiken.
Heb je überhaupt een scraping-API nodig? Het no-code pad dat de meeste reviews negeren
Veel mensen die zoeken naar een “Scraper API review” hebben zich nog helemaal niet vastgelegd op een API-gebaseerde workflow. Ze proberen vooral uit te zoeken of ze er überhaupt één nodig hebben.
Verrassend genoeg hebben veel mensen die niet nodig. De markt voor webscraping-API’s is een met een jaarlijkse groei van 14–18%, maar die groei wordt vooral gedreven door enterprise engineeringteams — niet door de sales operations manager die 500 leads van een website nodig heeft.
Scraping-API vs. no-code tool: een vergelijking naast elkaar
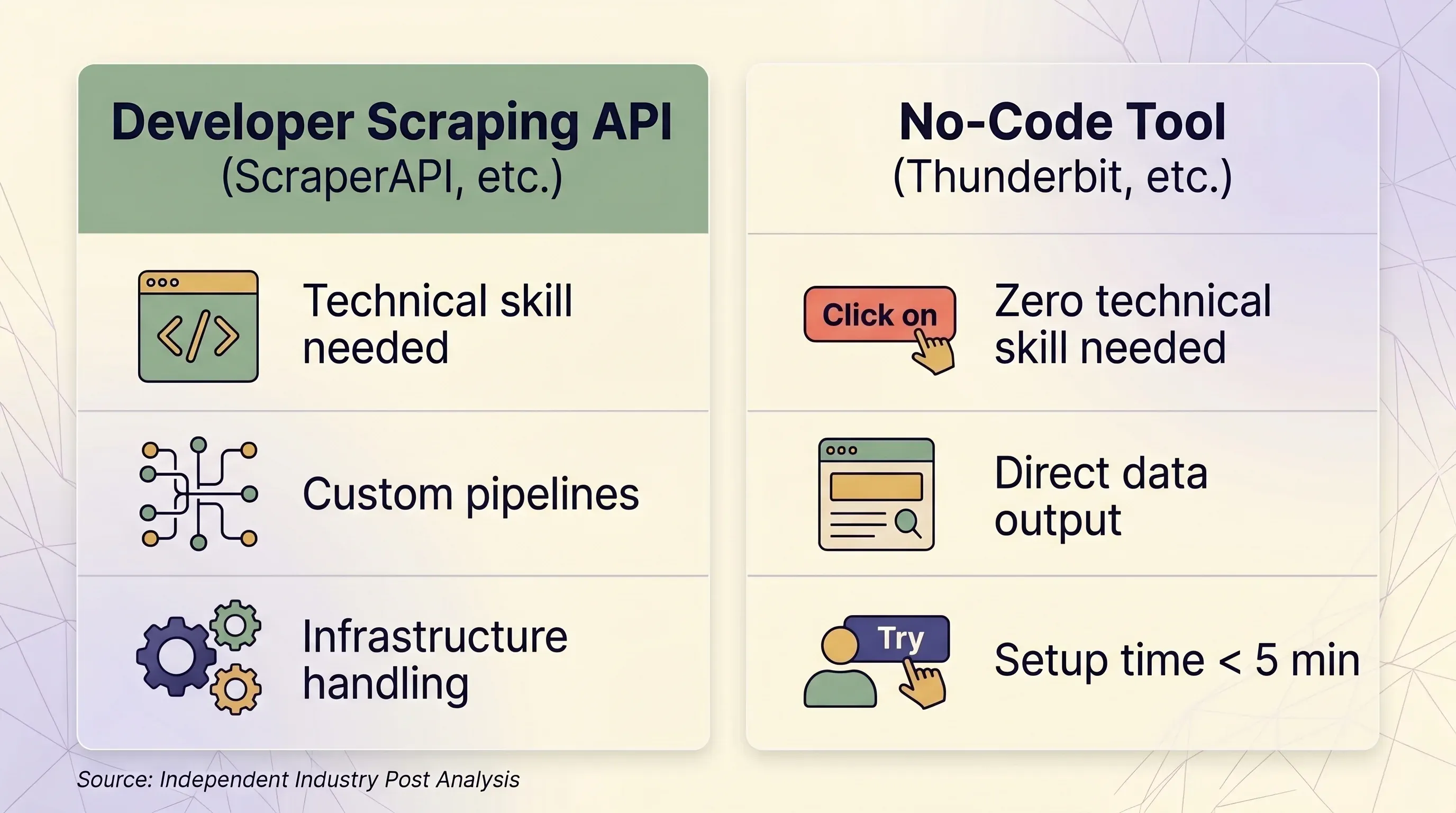
| Factor | Scraping-API (ScraperAPI, enz.) | No-code tool (Thunderbit, enz.) | |---|---|---|---| | Beste voor | Developers die datapijplijnen op schaal bouwen | Zakelijke gebruikers, marketeers, salesteams, onderzoekers | | Benodigde technische kennis | Python/Node.js, HTTP-concepten, JSON-parsing | Geen — klikken in de browser | | Insteltijd | Minstens 1–2 uur (code + testen + debuggen) | Binnen 5 minuten | | Anti-bot-afhandeling | Premium proxies (10–75 credits/request) | Echte browsersessie — omzeilt fingerprinting natuurlijk | | Sites waarvoor login nodig is | ❌ Verboden door de ScraperAPI-ToS | ✅ Browser scraping gebruikt je bestaande sessie | | Schaal (pagina’s/dag) | 100K–3M+ requests/maand | Ad hoc, meestal onder 1.000 pagina’s/dag | | Data-output | Ruwe HTML of JSON (vereist parsingcode) | Gestructureerde rijen/kolommen — direct bruikbaar | | Export | JSON, CSV (via code) | Excel, CSV, Google Sheets, Airtable, Notion, Word, JSON | | Onderhoud | Selectors, retry-logica en infrastructuur moeten worden bijgewerkt | Geen — AI leest de paginastructuur elke keer opnieuw | | Prijseenheid | Per-request credits (variabel: 1–75 credits/request) | Per-rij credits (1 credit = 1 rij, 2 voor subpagina’s) | | Instapprijs | $49/maand voor 100K credits | $9/maand voor 5.000 credits (jaarlijks) | | Gratis plan | 1.000 credits/maand, 5 gelijktijdig | 6 pagina’s/maand, 30 credits/pagina | | Prijsvoorspelbaarheid | Laag — multipliers zorgen voor verrassingskosten | Hoog — 1 rij is altijd 1 credit |
Wanneer een scraping-API zinvol is
- Je hebt een developer- of engineeringteam
- Je moet 100K+ pagina’s per dag programmatisch scrapen
- Je hebt veel controle nodig over headers, sessies en retry-logica
- Je targets worden goed ondersteund (Amazon, Google, Walmart, Zillow)
Wanneer een no-code tool zoals Thunderbit meer voor de hand ligt
- Je zit in sales, e-commerce operations, marketing of vastgoed — niet in engineering
- Je wilt data van tientallen verschillende sites zonder voor elke site een eigen parser te bouwen
- Je wilt direct exporteren naar Excel, Google Sheets, Airtable of Notion
- Je moet sites scrapen waarvoor je moet inloggen (Thunderbit’s gebruikt je sessie)
- Je wilt dat AI de pagina elke keer opnieuw leest — zonder code-onderhoud wanneer websites hun layout aanpassen
- Je hebt subpage scraping nodig: Thunderbit kan elke detailpagina bezoeken en rijen automatisch verrijken
De werkt echt simpel: installeer de extensie, ga naar een pagina, klik op “AI Suggest Fields”, klik op “Scrape” en exporteer. De AI herkent welke data op de pagina staat en stelt kolommen voor — je hoeft geen selectors of code te schrijven. Voor meer uitleg over hoe dit werkt, bekijk onze .
had in 2024 te maken met hogere cloudkosten dan verwacht, en bedrijven die gebruiksgebaseerde pricing zonder goede vangrails inzetten, zien door bill shock. De voorspelbaarheid van een per-rij-creditmodel is dus zeker het overwegen waard als je eerder bent verrast door variabele API-kosten.
ScraperAPI voor- en nadelen in één oogopslag
| Voordelen | Nadelen |
|---|---|
| Sterke proxy-infrastructuur (40M+ IP’s, 50+ landen) | Verwarrend credits-multiplier-systeem — combineren van features kost meer dan de som |
| Uitstekende documentatie en eenvoudige eerste setup (Capterra Ease of Use: 4,9/5) | Credits schuiven niet mee van maand tot maand |
| Betrouwbaar op Amazon, Google, Zillow, Etsy | 0% succes op Instagram, Twitter/X, Booking.com |
| Rekent alleen voor succesvolle requests (200/404) | 404-responses kosten wel credits |
| 18 structured data-endpoints met geparste JSON-output | Sites waarvoor je moet inloggen zijn expliciet verboden |
| Beschikbaar op alle plannen, inclusief Free | Pay-As-You-Go alleen op Scaling ($475/maand) en hoger |
| 7 dagen niet-goed-geld-terugbeleid zonder gedoe | Verplichte 10-minuten-cache op lastige targets — risico op verouderde data |
| 30–35% omzetgroei op jaarbasis wijst op actieve ontwikkeling | DataPipeline kost tot 6× standaard API-credits |
| — | Geotargeting buiten VS & EU vereist Business-plan ($299/maand) |
| — | Geen proactieve gebruiksalerts — je moet het dashboard handmatig checken |
Praktische tips om het maximale uit ScraperAPI te halen (als je het toch gebruikt)
Controleer je creditverbruik dagelijks
Het van ScraperAPI toont gebruiksstatistieken zoals gemiddelde latency, gescrapete domeinen en concurrency-metrics. Maar er zijn geen proactieve gebruiksalerts — geen e-mail of sms wanneer credits bijna op zijn. Je moet dit zelf handmatig in de gaten houden. De analysegeschiedenis is beperkt tot 2 weken op Hobby/Startup en 6 maanden op Business+.
Zet in de eerste maand elke dag een herinnering in je agenda om het dashboard te checken. Je moet gevoel krijgen voor hoe snel credits op jouw specifieke targets worden verbruikt.
Begin met het gratis plan om je doelwebsites te testen
Gebruik de 1.000 gratis credits (plus een proefperiode van 7 dagen met 5.000 credits) om succescijfers op je eigen target-sites te testen voordat je overstapt op een betaald plan. Noteer welke sites JavaScript-rendering of premium proxies nodig hebben, zodat je realistische maandkosten kunt inschatten met de multipliers erbij.
Zet premium features uit, tenzij de target ze echt nodig heeft
ScraperAPI schakelt premium proxies of JavaScript-rendering NIET automatisch in — je moet expliciet render=true, premium=true of ultra_premium=true instellen. Maar domeingebaseerde prijsstelling IS automatisch: Amazon kost altijd 5 credits, Google altijd 25 en LinkedIn altijd 30. Anti-bot-omzeilingcredits (+10 voor Cloudflare, DataDome, PerimeterX) worden ook automatisch toegevoegd zodra ze worden gedetecteerd. Houd daar dus rekening mee vóór je een batch draait.
Gebruik structured data-endpoints voor ondersteunde sites
Als je Amazon of Google scrapt, besparen de SDE’s ontwikkeltijd, zelfs als ze meer credits kosten. Voor niet-ondersteunde sites kun je beter inschatten of een sneller en goedkoper is dan zelf een parser bouwen.
Zorg voor een back-upplan voor onbetrouwbare targets
Als ScraperAPI’s succeskans op een bepaalde site onder de 90% ligt, overweeg dan om die requests via een andere provider te laten lopen of een browsergebaseerde tool te gebruiken. Voor sites waarvoor je moet inloggen werkt ScraperAPI simpelweg niet — je hebt dan een tool nodig zoals die binnen je browsersessie werkt.
Ken de valkuilen
- 404-responses kosten credits — ScraperAPI rekent zowel 200- als 404-statuscodes aan
- Geannuleerde requests worden toch gefactureerd als je annuleert vóór het einde van het 70-seconden verwerkingsvenster
- Verplichte 10-minuten-caching op lastige targets — je kunt verouderde data krijgen
- Pay-As-You-Go alleen op Scaling ($475/maand) en hoger — gebruikers op lagere plannen worden afgesloten als hun credits op zijn
- Geotargeting buiten VS & EU vereist het Business-plan ($299/maand)
Belangrijkste conclusies: is ScraperAPI het juiste hulpmiddel voor jou?
Dit is waar ik na al het onderzoek op uitkwam:
- ScraperAPI is een sterke keuze voor developmentteams die op hoog volume scrapen op goed ondersteunde targets zoals Amazon, Google, Walmart en Zillow. De structured data-endpoints zijn echt nuttig, de proxy-infrastructuur is groot en de documentatie is bovengemiddeld.
- Het credits-multiplier-systeem is het grootste risico. Als je niet begrijpt hoe multipliers stapelen, ga je te veel betalen. Het gat tussen geadverteerde credits en echte requests kan 5–75× zijn. Reken vooraf goed door wat dat voor jouw use case betekent voordat je een betaald plan neemt.
- Betrouwbaarheid hangt af van de site. ScraperAPI is uitstekend voor e-commerce en vastgoed, matig voor vacaturebanken en social media, en compleet waardeloos op Instagram, Twitter/X en Booking.com. Verwacht geen gelijkmatige prestaties.
- Voor niet-technische teams is ScraperAPI niet de juiste tool. Als je in sales, marketing of operations zit en gestructureerde data nodig hebt zonder code te schrijven, kom je met een no-code tool zoals in twee klikken waar je wilt zijn — met AI-gedreven veldherkenning, directe spreadsheet-export, verrijking van subpagina’s en geen onderhoudslast. Bekijk de of kijk tutorials op het .
- Voor developers met een beperkt budget: test eerst de gratis tier van ScraperAPI op je eigen targets en vergelijk daarna de effectieve kosten per request met ScrapingBee, Scrapfly en Bright Data voordat je kiest. De goedkoopste optie hangt volledig af van je use case en featurevereisten.
Wil je zien hoe de cijfers uitpakken voor jouw specifieke scrapingbehoefte? Begin met de gratis tier van ScraperAPI om je target-sites te testen, of om te zien hoe ver twee klikken je brengen. Voor meer informatie over , bekijk onze plannen.
FAQ's
Is ScraperAPI gratis?
Ja, ScraperAPI biedt een gratis plan met en een proefperiode van 7 dagen met 5.000 credits. Maar door credit-multipliers voor JavaScript-rendering, premium proxies of dure domeinen (Amazon = 5×, Google = 25×, LinkedIn = 30×) kan je werkelijke capaciteit veel lager liggen dan 1.000 requests. Op het gratis plan zijn ultra-premium proxies niet beschikbaar.
Hoeveel kost ScraperAPI per request?
Dat hangt sterk af van de feature-flags en het doeldomein. Een standaardrequest naar een simpele HTML-site kost 1 credit. Een Amazon-request kost 5 credits. Een Google SERP-request kost 25 credits. JavaScript-rendering toevoegen kost 10 credits extra. Het combineren van een ultra-premium proxy met JavaScript-rendering kost 75 credits per request. Op het Hobby-plan ($49/maand, 100K credits) ligt dat ergens tussen $0,00049 per request (standaard) en $0,0368 per request (ultra-premium + JS). Zie de volledige kostentabellen hierboven voor details.
Is ScraperAPI goed voor Amazon-scraping?
Het Amazon Structured Data-endpoint van ScraperAPI is een van de sterkste functies, met een in onafhankelijke benchmarks en uitgebreide geparste JSON-output (18+ velden). Wel kost elke Amazon-request minimaal 5 credits, dus de kosten lopen op schaal snel op. Voor kleinere teams die Amazon-data in een spreadsheet willen zonder code, biedt een alternatief met 1 klik en directe export.
Wat zijn de beste alternatieven voor ScraperAPI?
Voor developers: (goedkoopst voor basale HTML), (sterk in JavaScript-rendering), (beste voor beschermde sites — vast tarief ongeacht rendering) en . Voor niet-technische gebruikers: — een no-code, AI-gedreven Chrome-extensie met directe export naar Excel, Google Sheets, Airtable en Notion. Zie onze voor een diepere analyse.
Kan ScraperAPI sites scrapen waarvoor je moet inloggen?
ScraperAPI ondersteunt sessiebehoud via de session_number-parameter (dezelfde IP over meerdere requests), maar . Formulieren invullen, tweefactorauthenticatie of ingewikkelde auth-flows kan het niet verwerken. Voor sites waarvoor je moet inloggen zijn browsergebaseerde tools zoals — die je bestaande browsersessie gebruiken om te scrapen wat je kunt zien — de betrouwbaardere optie.
Meer weten