

Het web stroomt over van data, en in 2026 is de race om die chaos om te zetten in zakelijk goud feller dan ooit. Ik heb gezien hoe sales-, e-commerce- en operationsteams hun workflows compleet veranderen door taken te automatiseren die vroeger urenlang geestdodend knippen en plakken kostten. Tegenwoordig geldt: als je geen software voor web data scraping gebruikt, loop je niet alleen achter — je zit waarschijnlijk nog steeds vast in spreadsheet-hel, terwijl je concurrenten al aan hun tweede koffie zitten.
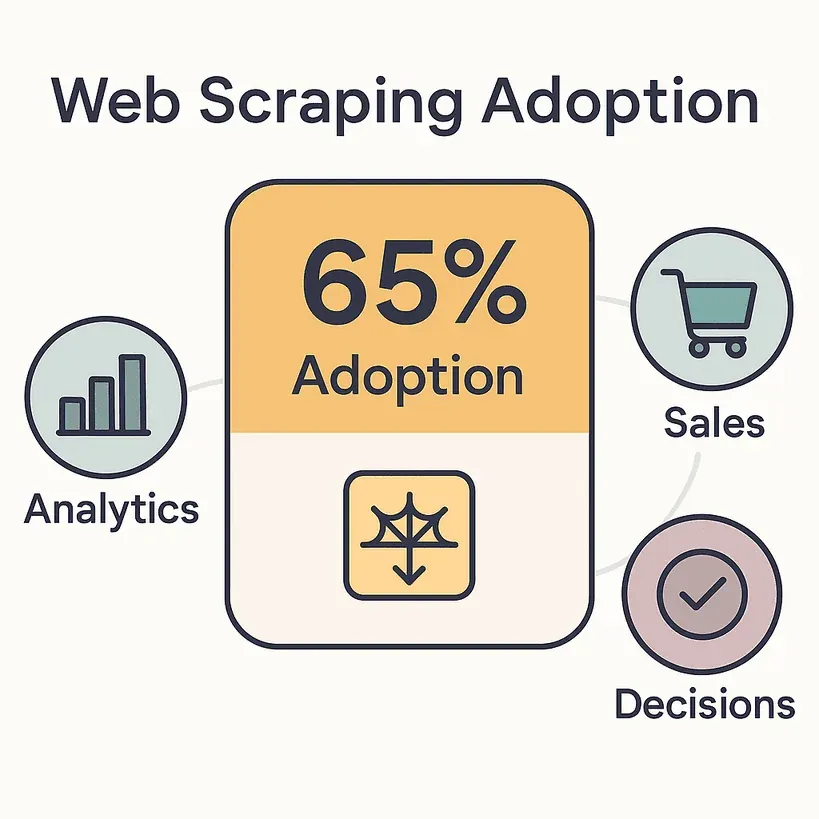
Dit is de realiteit: 65% van de ondernemingen gebruikt inmiddels webscrapingtools om analyses, sales en besluitvorming te voeden. De wereldwijde markt voor het extraheren van webdata is inmiddels meer dan $1 miljard waard, en de verwachting is dat die tegen 2030 verdubbelt. Salesmedewerkers besteden tot 70% van hun tijd aan niet-verkoopgerelateerde taken zoals data invoeren en onderzoek doen. Dat is een hoop tijd die ook besteed had kunnen worden aan deals sluiten — of op z’n minst aan een lunchpauze.

Dus, wat is de beste software voor web data scraping in 2026? Ik heb de vijf beste tools grondig onder de loep genomen die het spel veranderen voor teams van elke omvang en elk technisch niveau. Of je nu geen code wilt schrijven en gewoon wilt klikken, of een ontwikkelaar bent die maximale flexibiliteit zoekt — hier zit iets voor jou tussen.
Wat maakt de beste software voor web data scraping?
Wat is data scraping en hoe doe je het in 2025 Get Started Free
Laten we eerlijk zijn: niet alle webscrapers zijn gelijk. De beste software voor web data scraping in 2026 onderscheidt zich doordat data-extractie snel, betrouwbaar en toegankelijk voor iedereen is — niet alleen voor mensen die in Python dromen.
Dit zijn de belangrijkste criteria waar ik op let (en waar zakelijke gebruikers het meest om geven):
- Gebruiksgemak: Kunnen niet-technische gebruikers binnen enkele minuten een scrapingtaak opzetten? No-code en AI-gestuurde interfaces zijn voor de meeste teams onmisbaar.
- Flexibiliteit van databronnen: Werkt het met webpagina’s, pdf’s, afbeeldingen en dynamische content (zoals infinite scroll of AJAX)? Hoe meer bronnen, hoe beter.
- Automatisering en planning: Kun je terugkerende scrapingtaken inplannen, paginering afhandelen en navigatie door subpagina’s automatiseren? Automatisering is het verschil tussen “instellen en vergeten” en “instellen en blijven opletten”.
- Integratie en export: Kan het direct exporteren naar Excel, Google Sheets, Notion, Airtable of via een API? Hoe minder handmatig gedoe, hoe tevredener je team.
- Vereiste technische kennis: Is het echt no-code, of moet je eerst je regex weer opfrissen? De beste tools zijn geschikt voor zowel niet-coders als power users.
- Schaalbaarheid: Kan het honderden of duizenden pagina’s scrapen zonder te haperen?
- Ondersteuning en community: Is er goede documentatie, snelle support en een actieve gebruikersgroep?
Deze criteria zijn niet zomaar nice-to-haves — ze maken het verschil tussen tools die je uren besparen en tools die je dagen kosten. In 2026, nu bijna de helft van al het internetverkeer van bots afkomstig is, is de juiste scraper een concurrentievoordeel.
Laten we nu in de top vijf duiken.
De top 5 beste software voor web data scraping in 2026
- Thunderbit voor no-code, AI-gestuurde scraping uit meerdere bronnen
- Import.io voor datapunten en pipelines van enterprisekwaliteit
- Scrapy voor open-source flexibiliteit gedreven door ontwikkelaars
- Octoparse voor visuele no-code scraping met planning
- ParseHub voor gebruiksvriendelijke data-extractie met point-and-click
1. Thunderbit: de makkelijkste AI-aangedreven software voor web data scraping
Data van elke website scrapen met AI Get Started Free
Thunderbit is mijn vaste aanrader voor iedereen die webdata wil scrapen zonder ook maar één regel code te schrijven. En ja, ik ben een beetje bevooroordeeld — ik heb eraan meegebouwd. Maar luister: Thunderbit is gemaakt voor zakelijke gebruikers die resultaat willen, geen hoofdpijn.
Wat maakt Thunderbit zo sterk?
- AI-velden voorstellen: Klik gewoon op “AI-velden voorstellen” en Thunderbit’s AI leest de pagina, adviseert wat je moet extraheren en zet de scraper voor je op. Geen selectors, geen templates, geen drama.
- Scraping uit meerdere bronnen: Scrape niet alleen webpagina’s, maar ook pdf’s en afbeeldingen. Thunderbit kan tekst, links, e-mails, telefoonnummers en afbeeldingen extraheren — allemaal in twee klikken.
- Automatisering van subpagina’s en paginering: Moet je details ophalen van elke product- of profielpagina? Thunderbit volgt links, haalt extra info op en voegt die samen in je tabel. Ook infinite scroll en paginering zijn geen probleem.
- Batch- en geplande scraping: Plak een lijst met URL’s, plan terugkerende taken in en laat Thunderbit het zware werk doen — of het nu gaat om dagelijkse prijsmonitoring of wekelijkse lead-updates.
- Direct exporteren: Exporteer direct naar Excel, Google Sheets, Airtable, Notion, CSV of JSON. Geen eindeloze knip-en-plakmarathons meer.
- Aangepaste AI-prompts: Wil je data categoriseren, vertalen of labelen terwijl je scrapt? Voeg een eigen instructie toe en Thunderbit’s AI regelt het.
- Cloud- of browsermodus: Draai scrapingtaken in de cloud voor snelheid (50 pagina’s tegelijk) of lokaal voor sites waarvoor je moet inloggen.
Thunderbit wordt vertrouwd door meer dan 30.000 gebruikers wereldwijd, van salesteams tot makelaars en onafhankelijke e-commercewinkels. Met de gratis versie kun je tot 6 pagina’s scrapen (of 10 met een proefboost), en je betaalt alleen voor wat je gebruikt — één credit per uitvoerregel.
Waarom ik het geweldig vind: Thunderbit is de enige tool die ik heb gezien waarbij een niet-technische gebruiker in minder dan vijf minuten van “ik heb deze data nodig” naar “hier is mijn spreadsheet” kan gaan. De interface is oprecht gebruiksvriendelijk (daar hebben we obsessief aan gewerkt), en de AI past zich aan websitewijzigingen aan, zodat je niet voortdurend kapotte scrapers hoeft te repareren.
Beste voor: Sales, e-commerce, operations en iedereen die no-code, AI-aangedreven scraping wil zonder onderhoud.
Probeer de Chrome-extensie van Thunderbit
Bekijk de Thunderbit Blog voor meer handleidingen.
2. Import.io: web data scraping en integratie van enterprisekwaliteit
Import.io is de zwaargewichtkampioen voor ondernemingen die op grote schaal webdata nodig hebben — en die data direct in bedrijfssystemen willen laten landen.
Wat onderscheidt Import.io?
- Pipelines voor enterprises: Import.io is niet zomaar een scraper; het is een volwaardig platform voor integratie van webdata. Denk aan “data as a service” met doorlopende, geautomatiseerde feeds.
- Self-healing AI: Als een website verandert, probeert Import.io’s AI velden automatisch opnieuw te mappen, zodat je pipelines niet van de ene op de andere dag kapotgaan.
- Robuuste automatisering: Plan scrapingtaken per uur, per dag of op aangepaste intervallen. Ontvang meldingen als er iets misgaat of als de data er vreemd uitziet.
- Interactieve workflows: Verwerk sites met logins, formulieren of navigatie in meerdere stappen. Import.io kan complexe sequenties opnemen en afspelen.
- Compliance en governance: Geautomatiseerde detectie van persoonsgegevens, masking en auditlogs — cruciaal voor gereguleerde sectoren.
- API en integratie: Stream data rechtstreeks naar Google Sheets, Excel, Tableau, Power BI, databases of je eigen apps via de API.
Import.io wordt vertrouwd door merken als Unilever, Volvo en RedHat. Het is de go-to voor use cases zoals prijsmonitoring over duizenden e-commercesites, marktinformatie of het voeden van AI/ML-modellen met verse webdata.
Prijs: Import.io is een premiumoplossing, vanaf ongeveer $299 per maand voor self-service-abonnementen. Er is een gratis proefperiode, maar geen langdurige gratis versie. Als webdata bedrijfskritisch is, levert het de investering op.
Beste voor: Enterprises en data-gedreven organisaties die betrouwbaarheid, schaal, compliance en diepe integratie nodig hebben.
3. Scrapy: open-source webscrapingframework voor ontwikkelaars
Scrapy is het open-source krachtpakket voor ontwikkelaars die maximale flexibiliteit en controle willen. Als jij — of je team — in Python kunt coderen, is Scrapy het Zwitsers zakmes van webscraping.
Waarom ontwikkelaars Scrapy waarderen:
- Volledige aanpasbaarheid: Schrijf spiders (scripts) om data precies te crawlen, parsen en verwerken zoals jij dat wilt. Verwerk multi-page flows, aangepaste logica en complexe datacleaning.
- Asynchroon en snel: Scrapy’s architectuur is gebouwd voor snelheid en schaal — scrape honderden pagina’s per minuut, of miljoenen met gedistribueerde crawlers.
- Uitbreidbaar: Een enorm ecosysteem van plugins en middleware voor proxies, headless browsers (Splash/Playwright) en integraties.
- Gratis en open source: Geen licentiekosten. Draai het op je eigen hardware of in de cloud, en schaal zo groot als je nodig hebt.
- Communityondersteuning: Meer dan 55.000 GitHub-sterren en een enorme gebruikersgroep. Loop je vast, dan heeft iemand het probleem waarschijnlijk al opgelost.
Aandachtspunten: Scrapy vereist Python-vaardigheden en comfort met de command line. Er is geen point-and-click-interface — dit is een code-first omgeving. Maar voor maatwerkprojecten, AI-trainingsdata of enorme crawls is er niets dat hieraan kan tippen.
Beste voor: Organisaties met interne ontwikkelaars, aangepaste datapipelines of grootschalige, complexe scrapingbehoeften.
4. Octoparse: visuele web data scraping simpel gemaakt
Octoparse is een favoriet onder niet-coders die krachtige scraping willen met een visuele point-and-click-interface.
Waarom Octoparse populair is:
- Visuele workflowbouwer: Klik op elementen in een ingebouwde browser en Octoparse detecteert automatisch patronen. Geen code, alleen klikken en extraheren.
- Kan dynamische content aan: Scrape AJAX, infinite scroll en sites achter een login. Simuleer klikken, scrollen en het verzenden van formulieren.
- Cloud scraping en planning: Draai taken in de cloud (sneller, parallel) en plan terugkerende jobs voor altijd verse data.
- Vooraf gebouwde templates: Honderden templates voor populaire sites (Amazon, Twitter, Zillow, enz.) laten je direct beginnen met scrapen.
- Export en API: Download resultaten als CSV, Excel, JSON of haal data op via de API. Integreer met Google Sheets of databases.
Octoparse wordt vaak omschreven als “supermakkelijk in gebruik, zelfs voor beginners.” De gratis versie is beperkt, maar betaalde pakketten (vanaf ongeveer $83 per maand) ontsluiten cloudruns, planning en meer snelheid.
Beste voor: Niet-technische gebruikers, marketeers, onderzoekers en kleine teams die regelmatig geautomatiseerd data willen verzamelen zonder te coderen.
5. ParseHub: gebruiksvriendelijke data-extractie voor alledaagse taken
ParseHub is nog een no-code favoriet, vooral voor kleine bedrijven en freelancers die alledaagse datataken willen automatiseren.
Wat maakt ParseHub sterk?
- Point-and-click eenvoud: Selecteer data door op elementen in een browserweergave te klikken. Bouw workflows visueel op — coderen is niet nodig.
- Kan met JS en dynamische sites werken: Scrape pagina’s met veel JavaScript, infinite scroll en navigatie in meerdere stappen.
- Cloud- en lokale runs: Draai scrapingtaken op je desktop of in de cloud. Plan terugkerende jobs en krijg via de API toegang tot resultaten (bij hogere abonnementen).
- Exportopties: Download data als CSV, Excel of JSON. API-toegang voor automatisering.
- Cross-platform: Beschikbaar voor Windows, Mac en Linux.
Het gratis plan van ParseHub is beperkt (200 pagina’s per run), maar betaalde plannen (vanaf ongeveer $189 per maand) ontsluiten meer kracht, snelheid en API-toegang.
Beste voor: Kleine bedrijven, freelancers en teams met eenvoudige scrapingbehoeften die een betrouwbaar, visueel hulpmiddel willen.
Vergelijkingstabel: de beste software voor web data scraping in één oogopslag
| Tool | Gebruiksgemak | Databronnen | Automatisering & planning | Integratie & export | Technische kennis | Prijs |
|---|---|---|---|---|---|---|
| Thunderbit | No-code, AI-gestuurd | Web, pdf, afbeeldingen | Subpagina’s, paginering, gepland, batch | Excel, Sheets, Notion, Airtable, CSV, JSON | Geen | Freemium (betalen per rij) |
| Import.io | Point-and-click UI | Web (statisch/dynamisch, login) | Self-healing, gepland, waarschuwingen | API, BI-tools, Sheets, Excel, DB | Laag–gemiddeld | $299+/maand |
| Scrapy | Code vereist | Web, API’s, (JS via add-ons) | Volledige automatisering via code | Alles (via code) | Python-ontwikkelaars | Gratis (open source) |
| Octoparse | Visueel, no-code | Web (dynamisch, login) | Cloudplanning, templates | CSV, Excel, JSON, API | Geen | $83+/maand |
| ParseHub | Visueel, no-code | Web (JS, dynamisch) | Cloud/lokaal, gepland | CSV, Excel, JSON, API | Geen | $189+/maand |
Hoe kies je de beste software voor web data scraping voor jouw bedrijf?
Weet je niet zeker welke tool bij je past? Hier is mijn spiekbriefje:
- Niet-technische gebruikers, snel resultaat: Kies voor Thunderbit of Octoparse. Thunderbit is onovertroffen voor directe, AI-aangedreven scraping en ondersteuning voor meerdere bronnen (web, pdf, afbeeldingen). Octoparse is geweldig voor visuele, geplande scraping.
- Enterprise-integratie, compliance en schaal: Import.io is je beste keuze. Het is gebouwd voor doorlopende, betrouwbare datapipelines en diepe integratie.
- Ontwikkelaars, maatwerkprojecten of enorme crawls: Scrapy is de weg vooruit. Je hebt Python-skills nodig, maar je krijgt onbeperkte flexibiliteit.
- Kleine bedrijven, freelancers of alledaagse taken: ParseHub is een solide, gebruiksvriendelijke keuze voor point-and-click scraping en matige automatisering.
Tips om de juiste tool te kiezen:
- Stem de tool af op de technische vaardigheden van je team en je databehoeften.
- Houd rekening met de complexiteit van de sites die je wilt scrapen (dynamische content? logins?).
- Denk na over hoe je de data gaat gebruiken — heb je directe export naar Sheets nodig, of diepe API-integratie?
- Begin met een gratis proefperiode of freemium-plan om echte taken te testen.
- Onderschat de waarde van goede support en documentatie niet.
Begin met scrapen met Thunderbit
Conclusie: zakelijke waarde ontsluiten met de beste software voor web data scraping
Webdata is de brandstof voor slimmere zakelijke beslissingen in 2026. De juiste software voor web data scraping kan je uren besparen, fouten verminderen en je team een echt voordeel geven — of je nu leadlijsten bouwt, concurrenten monitort of je analytics-engineHet web stroomt over van data, en in 2026 is de race om van die chaos zakelijk goud te maken feller dan ooit. Ik heb gezien hoe sales-, e-commerce- en operationsteams hun workflows compleet omgooien door taken te automatiseren die vroeger urenlang geestdodend kopieer- en plakwerk kostten. Tegenwoordig geldt: als je geen software voor web data scraping gebruikt, loop je niet alleen achter — je zit waarschijnlijk nog steeds vast in spreadsheet-hel, terwijl je concurrenten al aan hun tweede koffie zitten.
Dit is de realiteit: 65% van de ondernemingen gebruikt inmiddels webscrapingtools om analyses, sales en besluitvorming te voeden. De wereldwijde markt voor het extraheren van webdata is inmiddels meer dan $1 miljard waard, en de verwachting is dat die tegen 2030 verdubbelt. Salesmedewerkers besteden tot 70% van hun tijd aan niet-verkoopgerelateerde taken zoals data invoeren en onderzoek doen. Dat is een hoop tijd die ook had kunnen gaan naar deals sluiten — of op z’n minst naar een lunchpauze.
Dus, wat is in 2026 de beste software voor web data scraping? Ik heb de vijf beste tools grondig onder de loep genomen die het spel veranderen voor teams van elke omvang en op elk technisch niveau. Of je nu geen code wilt schrijven en gewoon wilt klikken, of een ontwikkelaar bent die maximale flexibiliteit zoekt — hier zit iets voor jou tussen.
Wat maakt de beste software voor web data scraping?
Wat is data scraping en hoe doe je het in 2025 Get Started Free
Laten we eerlijk zijn: niet alle webscrapers zijn gelijk. De beste software voor web data scraping in 2026 onderscheidt zich doordat data-extractie snel, betrouwbaar en toegankelijk voor iedereen is — niet alleen voor mensen die in Python dromen.
Dit zijn de belangrijkste criteria waar ik op let (en waar zakelijke gebruikers het meest om geven):
- Gebruiksgemak: Kunnen niet-technische gebruikers binnen enkele minuten een scrapingtaak opzetten? No-code en AI-gestuurde interfaces zijn voor de meeste teams onmisbaar.
- Flexibiliteit van databronnen: Werkt het met webpagina’s, pdf’s, afbeeldingen en dynamische content (zoals infinite scroll of AJAX)? Hoe meer bronnen, hoe beter.
- Automatisering en planning: Kun je terugkerende scrapingtaken inplannen, paginering afhandelen en navigatie door subpagina’s automatiseren? Automatisering is het verschil tussen “instellen en vergeten” en “instellen en blijven opletten”.
- Integratie en export: Kan het direct exporteren naar Excel, Google Sheets, Notion, Airtable of via een API? Hoe minder handmatig gedoe, hoe tevredener je team.
- Vereiste technische kennis: Is het echt no-code, of moet je eerst je regex weer opfrissen? De beste tools zijn geschikt voor zowel niet-coders als power users.
- Schaalbaarheid: Kan het honderden of duizenden pagina’s scrapen zonder te haperen?
- Ondersteuning en community: Is er goede documentatie, snelle support en een actieve gebruikersgroep?
Deze criteria zijn niet zomaar nice-to-haves — ze maken het verschil tussen tools die je uren besparen en tools die je dagen kosten. In 2026, nu bijna de helft van al het internetverkeer van bots afkomstig is, is de juiste scraper een concurrentievoordeel.
Laten we nu in de top vijf duiken.
De top 5 beste software voor web data scraping in 2026
- Thunderbit voor no-code, AI-gestuurde scraping uit meerdere bronnen
- Import.io voor datapunten en pipelines van enterprisekwaliteit
- Scrapy voor open-source flexibiliteit gedreven door ontwikkelaars
- Octoparse voor visuele no-code scraping met planning
- ParseHub voor gebruiksvriendelijke data-extractie met point-and-click
1. Thunderbit: de makkelijkste AI-aangedreven software voor web data scraping
Data van elke website scrapen met AI Get Started Free
Thunderbit is mijn vaste aanrader voor iedereen die webdata wil scrapen zonder ook maar één regel code te schrijven. En ja, ik ben een beetje bevooroordeeld — ik heb eraan meegebouwd. Maar luister: Thunderbit is gemaakt voor zakelijke gebruikers die resultaat willen, geen hoofdpijn.
Wat maakt Thunderbit zo sterk?
- AI-velden voorstellen: Klik gewoon op “AI-velden voorstellen” en Thunderbit’s AI leest de pagina, adviseert wat je moet extraheren en zet de scraper voor je op. Geen selectors, geen templates, geen drama.
- Scraping uit meerdere bronnen: Scrape niet alleen webpagina’s, maar ook pdf’s en afbeeldingen. Thunderbit kan tekst, links, e-mails, telefoonnummers en afbeeldingen extraheren — allemaal in twee klikken.
- Automatisering van subpagina’s en paginering: Moet je details ophalen van elke product- of profielpagina? Thunderbit volgt links, haalt extra info op en voegt die samen in je tabel. Ook infinite scroll en paginering zijn geen probleem.
- Batch- en geplande scraping: Plak een lijst met URL’s, plan terugkerende taken in en laat Thunderbit het zware werk doen — of het nu gaat om dagelijkse prijsmonitoring of wekelijkse lead-updates.
- Direct exporteren: Exporteer direct naar Excel, Google Sheets, Airtable, Notion, CSV of JSON. Geen eindeloze kopieer-plakmarathons meer.
- Aangepaste AI-prompts: Wil je data categoriseren, vertalen of labelen terwijl je scrapt? Voeg een eigen instructie toe en Thunderbit’s AI regelt het.
- Cloud- of browsermodus: Draai scrapingtaken in de cloud voor snelheid (50 pagina’s tegelijk) of lokaal voor sites waarvoor je moet inloggen.
Thunderbit wordt vertrouwd door meer dan 30.000 gebruikers wereldwijd, van salesteams tot makelaars en onafhankelijke e-commercewinkels. Met de gratis versie kun je tot 6 pagina’s scrapen (of 10 met een proefboost), en je betaalt alleen voor wat je gebruikt — één credit per uitvoerregel.
Waarom ik het geweldig vind: Thunderbit is de enige tool die ik heb gezien waarbij een niet-technische gebruiker in minder dan vijf minuten van “ik heb deze data nodig” naar “hier is mijn spreadsheet” kan gaan. De interface is oprecht gebruiksvriendelijk (daar hebben we obsessief aan gewerkt), en de AI past zich aan websitewijzigingen aan, zodat je niet voortdurend kapotte scrapers hoeft te repareren.
Beste voor: Sales, e-commerce, operations en iedereen die no-code, AI-aangedreven scraping wil zonder onderhoud.
Probeer de Chrome-extensie van Thunderbit
Bekijk de Thunderbit Blog voor meer handleidingen.
2. Import.io: web data scraping en integratie van enterprisekwaliteit
Import.io is de zwaargewichtkampioen voor ondernemingen die op grote schaal webdata nodig hebben — en die die data direct in bedrijfssystemen willen laten landen.
Wat onderscheidt Import.io?
- Pipelines voor enterprises: Import.io is niet zomaar een scraper; het is een volwaardig platform voor integratie van webdata. Denk aan “data as a service” met doorlopende, geautomatiseerde feeds.
- Self-healing AI: Als een website verandert, probeert Import.io’s AI velden automatisch opnieuw te mappen, zodat je pipelines niet van de ene op de andere dag kapotgaan.
- Robuuste automatisering: Plan scrapingtaken per uur, per dag of op aangepaste intervallen. Ontvang meldingen als er iets misgaat of als de data er vreemd uitziet.
- Interactieve workflows: Verwerk sites met logins, formulieren of navigatie in meerdere stappen. Import.io kan complexe sequenties opnemen en afspelen.
- Compliance en governance: Geautomatiseerde detectie van persoonsgegevens, masking en auditlogs — cruciaal voor gereguleerde sectoren.
- API en integratie: Stream data rechtstreeks naar Google Sheets, Excel, Tableau, Power BI, databases of je eigen apps via de API.
Import.io wordt vertrouwd door merken als Unilever, Volvo en RedHat. Het is de go-to voor use cases zoals prijsmonitoring over duizenden e-commercesites, marktinformatie of het voeden van AI/ML-modellen met verse webdata.
Prijs: Import.io is een premiumoplossing, vanaf ongeveer $299 per maand voor self-service-abonnementen. Er is een gratis proefperiode, maar geen langdurige gratis versie. Als webdata bedrijfskritisch is, levert het de investering op.
Beste voor: Enterprises en data-gedreven organisaties die betrouwbaarheid, schaal, compliance en diepe integratie nodig hebben.
3. Scrapy: open-source webscrapingframework voor ontwikkelaars
Scrapy is het open-source krachtpakket voor ontwikkelaars die maximale flexibiliteit en controle willen. Als jij — of je team — in Python kunt coderen, is Scrapy het Zwitsers zakmes van webscraping.
Waarom ontwikkelaars Scrapy waarderen:
- Volledige aanpasbaarheid: Schrijf spiders (scripts) om data precies te crawlen, parsen en verwerken zoals jij dat wilt. Verwerk multi-page flows, aangepaste logica en complexe datacleaning.
- Asynchroon en snel: Scrapy’s architectuur is gebouwd voor snelheid en schaal — scrape honderden pagina’s per minuut, of miljoenen met gedistribueerde crawlers.
- Uitbreidbaar: Een enorm ecosysteem van plugins en middleware voor proxies, headless browsers (Splash/Playwright) en integraties.
- Gratis en open source: Geen licentiekosten. Draai het op je eigen hardware of in de cloud, en schaal zo groot als je nodig hebt.
- Communityondersteuning: Meer dan 55.000 GitHub-sterren en een enorme gebruikersgroep. Loop je vast, dan heeft iemand het probleem waarschijnlijk al opgelost.
Aandachtspunten: Scrapy vereist Python-vaardigheden en comfort met de command line. Er is geen point-and-click-interface — dit is een code-first omgeving. Maar voor maatwerkprojecten, AI-trainingsdata of enorme crawls is er niets dat hieraan kan tippen.
Beste voor: Organisaties met interne ontwikkelaars, aangepaste datapipelines of grootschalige, complexe scrapingbehoeften.
4. Octoparse: visuele web data scraping simpel gemaakt
Octoparse is een favoriet onder niet-coders die krachtige scraping willen met een visuele point-and-click-interface.
Waarom Octoparse populair is:
- Visuele workflowbouwer: Klik op elementen in een ingebouwde browser en Octoparse detecteert automatisch patronen. Geen code, alleen klikken en extraheren.
- Kan dynamische content aan: Scrape AJAX, infinite scroll en sites achter een login. Simuleer klikken, scrollen en het verzenden van formulieren.
- Cloud scraping en planning: Draai taken in de cloud (sneller, parallel) en plan terugkerende jobs voor altijd verse data.
- Vooraf gebouwde templates: Honderden templates voor populaire sites (Amazon, Twitter, Zillow, enz.) laten je direct beginnen met scrapen.
- Export en API: Download resultaten als CSV, Excel, JSON of haal data op via de API. Integreer met Google Sheets of databases.
Octoparse wordt vaak omschreven als “supermakkelijk in gebruik, zelfs voor beginners.” De gratis versie is beperkt, maar betaalde pakketten (vanaf ongeveer $83 per maand) ontsluiten cloudruns, planning en meer snelheid.
Beste voor: Niet-technische gebruikers, marketeers, onderzoekers en kleine teams die regelmatig geautomatiseerd data willen verzamelen zonder te coderen.
5. ParseHub: gebruiksvriendelijke data-extractie voor alledaagse taken
ParseHub is nog een no-code favoriet, vooral voor kleine bedrijven en freelancers die alledaagse datataken willen automatiseren.
Wat maakt ParseHub sterk?
- Point-and-click eenvoud: Selecteer data door op elementen in een browserweergave te klikken. Bouw workflows visueel op — coderen is niet nodig.
- Kan met JS en dynamische sites werken: Scrape pagina’s met veel JavaScript, infinite scroll en navigatie in meerdere stappen.
- Cloud- en lokale runs: Draai scrapingtaken op je desktop of in de cloud. Plan terugkerende jobs en krijg via de API toegang tot resultaten (bij hogere abonnementen).
- Exportopties: Download data als CSV, Excel of JSON. API-toegang voor automatisering.
- Cross-platform: Beschikbaar voor Windows, Mac en Linux.
Het gratis plan van ParseHub is beperkt (200 pagina’s per run), maar betaalde plannen (vanaf ongeveer $189 per maand) ontsluiten meer kracht, snelheid en API-toegang.
Beste voor: Kleine bedrijven, freelancers en teams met eenvoudige scrapingbehoeften die een betrouwbaar, visueel hulpmiddel willen.
Vergelijkingstabel: de beste software voor web data scraping in één oogopslag
| Tool | Gebruiksgemak | Databronnen | Automatisering & planning | Integratie & export | Technische kennis | Prijs |
|---|---|---|---|---|---|---|
| Thunderbit | No-code, AI-gestuurd | Web, pdf, afbeeldingen | Subpagina’s, paginering, gepland, batch | Excel, Sheets, Notion, Airtable, CSV, JSON | Geen | Freemium (betalen per rij) |
| Import.io | Point-and-click UI | Web (statisch/dynamisch, login) | Self-healing, gepland, waarschuwingen | API, BI-tools, Sheets, Excel, DB | Laag–gemiddeld | $299+/maand |
| Scrapy | Code vereist | Web, API’s, (JS via add-ons) | Volledige automatisering via code | Alles (via code) | Python-ontwikkelaars | Gratis (open source) |
| Octoparse | Visueel, no-code | Web (dynamisch, login) | Cloudplanning, templates | CSV, Excel, JSON, API | Geen | $83+/maand |
| ParseHub | Visueel, no-code | Web (JS, dynamisch) | Cloud/lokaal, gepland | CSV, Excel, JSON, API | Geen | $189+/maand |
Hoe kies je de beste software voor web data scraping voor jouw bedrijf?
Weet je niet zeker welke tool bij je past? Hier is mijn spiekbriefje:
- Niet-technische gebruikers, snel resultaat: Kies voor Thunderbit of Octoparse. Thunderbit is onovertroffen voor directe, AI-aangedreven scraping en ondersteuning voor meerdere bronnen (web, pdf, afbeeldingen). Octoparse is geweldig voor visuele, geplande scraping.
- Enterprise-integratie, compliance en schaal: Import.io is je beste keuze. Het is gebouwd voor doorlopende, betrouwbare datapipelines en diepe integratie.
- Ontwikkelaars, maatwerkprojecten of enorme crawls: Scrapy is de weg vooruit. Je hebt Python-skills nodig, maar je krijgt onbeperkte flexibiliteit.
- Kleine bedrijven, freelancers of alledaagse taken: ParseHub is een solide, gebruiksvriendelijke keuze voor point-and-click scraping en matige automatisering.
Tips om de juiste tool te kiezen:
- Stem de tool af op de technische vaardigheden van je team en je databehoeften.
- Houd rekening met de complexiteit van de sites die je wilt scrapen (dynamische content? logins?).
- Denk na over hoe je de data gaat gebruiken — heb je directe export naar Sheets nodig, of diepe API-integratie?
- Begin met een gratis proefperiode of freemium-plan om echte taken te testen.
- Onderschat de waarde van goede support en documentatie niet.
Begin met scrapen met Thunderbit
Conclusie: zakelijke waarde ontsluiten met de beste software voor web data scraping
Webdata is de brandstof voor slimmere zakelijke beslissingen in 2026. De juiste software voor web data scraping kan je uren besparen, fouten verminderen en je team een echt voordeel geven — of je nu leadlijsten bouwt, concurrenten monitort of je analytics-engine van data voorziet.
Samengevat:
- Thunderbit is de makkelijkste AI-aangedreven no-code scraper voor zakelijke gebruikers.
- Import.io is de enterprise-oplossing voor doorlopende, geïntegreerde datapipelines.
- Scrapy is de open-source toolkit voor ontwikkelaars die volledige controle willen.
- Octoparse en ParseHub maken visuele no-code scraping toegankelijk voor iedereen.
De meeste van deze tools bieden gratis proefversies of freemium-abonnementen — dus probeer ze vooral uit. Automatiseer het saaie werk, ontdek nieuwe inzichten en laat je team focussen op wat er echt toe doet.
Veel succes met scrapen — en moge je data altijd vers, gestructureerd en klaar voor actie zijn.
Veelgestelde vragen
1. Waarvoor wordt software voor web data scraping gebruikt?
Software voor web data scraping automatiseert het extraheren van informatie uit websites, pdf’s en afbeeldingen. Het wordt gebruikt voor leadgeneratie, prijsmonitoring, marktonderzoek, contentaggregatie en meer.
2. Is web data scraping legaal?
Webscraping is legaal wanneer je publiek beschikbare data verzamelt en je je houdt aan de gebruiksvoorwaarden en privacywetten van de website. Controleer altijd het beleid van de site en gebruik data verantwoord.
3. Moet ik kunnen coderen om software voor web data scraping te gebruiken?
Niet per se! Tools zoals Thunderbit, Octoparse en ParseHub zijn ontworpen voor niet-coders. Voor complexere of volledig op maat gemaakte projecten kunnen ontwikkelaarstools zoals Scrapy nodig zijn.
4. Hoe exporteer ik gescrapete data naar Excel of Google Sheets?
De meeste moderne scrapers (Thunderbit, Octoparse, ParseHub) bieden export met één klik naar Excel, Google Sheets, CSV of zelfs directe integratie met Notion en Airtable.
5. Kan software voor web data scraping dynamische sites of logins aan?
Ja — toonaangevende tools zoals Import.io, Octoparse en ParseHub kunnen dynamische content (AJAX, infinite scroll) en sites achter een login verwerken. Thunderbit ondersteunt ook scraping van dynamische pagina’s en subpagina’s.
Wil je zien hoe moderne webscraping eruitziet? Download Thunderbit’s Chrome-extensie of bekijk de Thunderbit Blog voor meer tips, tutorials en diepgaande inzichten in de wereld van AI-aangedreven data-extractie.
Probeer AI-webscraper Get Started Free




