
De e-commercewereld in het Midden-Oosten groeit razendsnel, en staat daar precies middenin. Met miljoenen producten, talloze verkopers en een gebruikersbestand dat elke dag groter wordt, is Noon uitgegroeid tot een goudmijn voor iedereen die datagedreven beslissingen wil nemen in retail, sales of marktonderzoek. Maar hier zit de valkuil: proberen om Noon’s productdata handmatig te verzamelen en te ordenen is ongeveer net zo leuk als IKEA-meubels in elkaar zetten zonder handleiding—tijdrovend, verwarrend en met grote kans dat je nog een paar onderdelen mist.
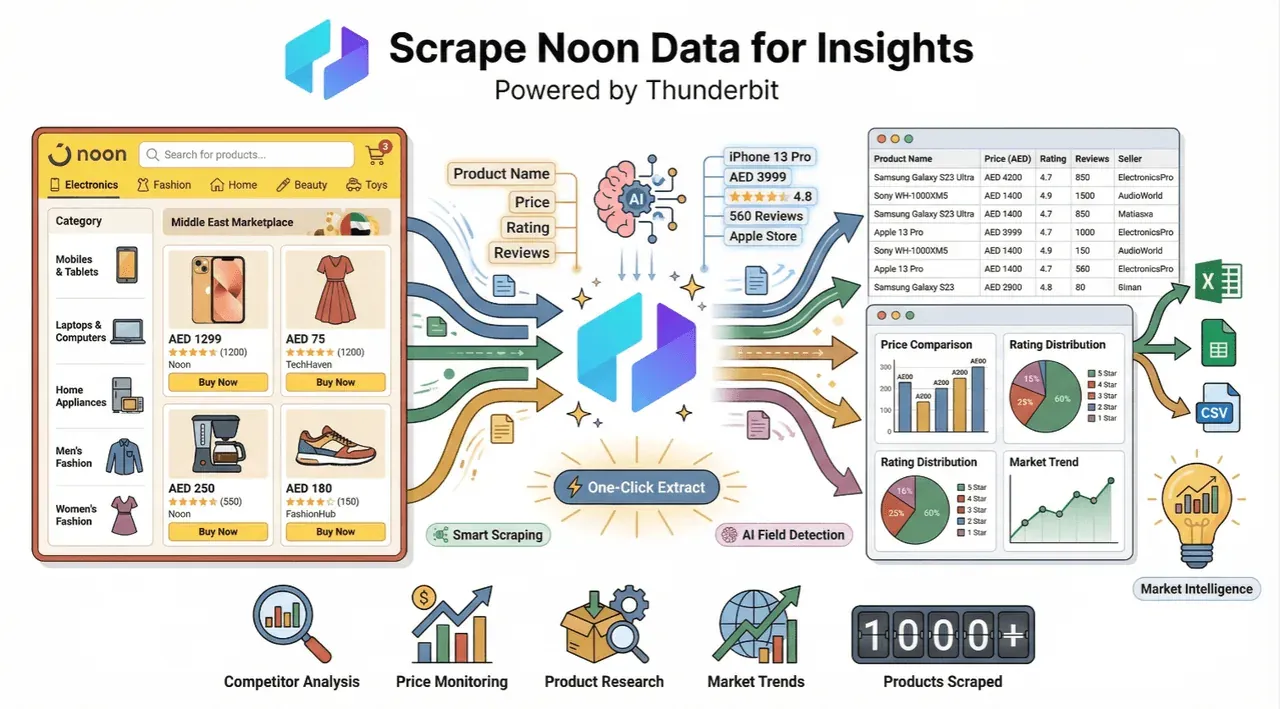 Ik heb uit eerste hand gezien hoeveel tijd teams verspillen aan het kopiëren en plakken van prijzen, productnamen en voorraadgegevens van Noon. Daarom laat ik je graag zien hoe —onze AI-webscraper—die marathon kan omzetten in een sprint. Of je nu concurrenten volgt, voorraad bewaakt of gewoon je prijzen scherp wilt houden, het automatiseren van Noon-data-extractie verandert je workflow echt. Laten we stap voor stap bekijken hoe je dat doet, en waarom Thunderbit de tool is die je daarbij wilt hebben.
Ik heb uit eerste hand gezien hoeveel tijd teams verspillen aan het kopiëren en plakken van prijzen, productnamen en voorraadgegevens van Noon. Daarom laat ik je graag zien hoe —onze AI-webscraper—die marathon kan omzetten in een sprint. Of je nu concurrenten volgt, voorraad bewaakt of gewoon je prijzen scherp wilt houden, het automatiseren van Noon-data-extractie verandert je workflow echt. Laten we stap voor stap bekijken hoe je dat doet, en waarom Thunderbit de tool is die je daarbij wilt hebben.
Maak kennis met Noon: de basis voor succesvol data scrapen
Voordat je begint met scrapen, is het slim om eerst te snappen hoe de website van Noon in elkaar zit. Noon is niet zomaar een enorme webshop; het is een doolhof van categorieën, subcategorieën, productoverzichten en detailpagina’s. Als je schone, complete data wilt, moet je die structuur goed in kaart brengen.
- Categorieën en navigatie: De hoofdnavigatie van Noon verdeelt producten in grote categorieën—elektronica, mode, wonen, beauty en meer. Elke categorie splitst weer op in subcategorieën en filters (merk, prijs, beoordeling, enz.).
- Productoverzichten: Categorie- en zoekresultaatpagina’s tonen tientallen, soms honderden producten, elk met een miniatuurafbeelding, prijs en een link naar de productdetailpagina.
- Paginering: Overzichten lopen over meerdere pagina’s, via klassieke “Volgende”-knoppen of infinite scroll. Eén pagina missen betekent dat je waardevolle SKU’s mist.
- Productdetailpagina’s: Hier zit de echte goudmijn—gedetailleerde specificaties, beschrijvingen, afbeeldingen, verkoperinformatie en realtime voorraad- of prijsupdates.
Deze structuur begrijpen is cruciaal. Als je alleen de eerste pagina van een categorie scrapt, laat je het grootste deel van de producten liggen. Als je subpagina’s negeert, mis je rijke productdetails. Daarom raad ik bij het opzetten van een scrapingstrategie altijd aan om:
- De navigatiestroom uit te tekenen
- Vast te stellen waar je doeldata staat (overzichten vs. detailpagina’s)
- Te noteren hoe paginering werkt voor de gekozen categorieën
Dit voorbereidende werk zorgt ervoor dat je data volledig en nauwkeurig is—geen verrassingen meer in de trant van: “Waar is dat product gebleven?”
Waarom Noon-data scrapen? Zakelijke waarde ontsluiten
Dus waarom zou je al die moeite doen om Noon te scrapen? Omdat gestructureerde data het geheime wapen is voor e-commerceteams die de concurrentie te slim af willen zijn. Dit zijn een paar van de meest voorkomende use-cases die ik zie:
| Use Case | Beschrijving |
|---|---|
| Prijsbewaking | Volg prijzen van concurrenten om je eigen prijzen aan te passen en concurrerend te blijven (Octoparse). |
| Assortimentsanalyse | Zie welke producten trending zijn of ontbreken in je catalogus. |
| Voorraadtracking | Bewaak voorraadniveaus om tekorten of overvoorraad op te sporen (Octoparse). |
| Benchmarking van concurrenten | Vergelijk je vermeldingen, beoordelingen en reviews met die van rivalen (Actowiz). |
| Trends signaleren | Identificeer snel verkopende producten of categorieën om marketing- en inkoopbeslissingen te ondersteunen (Octoparse). |
| Betere besluitvorming | Gebruik realtime data voor slimmere promoties, voorraadplanning en verkoopprognoses (Octoparse). |
In een hypercompetitieve markt zoals de VAE, waar Noon en Amazon verwikkeld zijn in een prijzen- en assortimentsstrijd, is actuele data niet alleen handig—het is essentieel om te overleven ().
Noon-data-scrapingtools vergelijken: waarom Thunderbit opvalt
Er zijn genoeg manieren om data uit Noon te halen, maar niet alle aanpakken zijn even sterk. Zo verhouden de belangrijkste methodes zich tot elkaar:
| Methode | Voordelen | Nadelen |
|---|---|---|
| Handmatig kopiëren en plakken | Geen installatie, iedereen kan het | Traag, foutgevoelig, niet schaalbaar |
| Codegebaseerde scrapers | Flexibel, aanpasbaar | Vereist programmeren, breekt bij wijzigingen |
| Browserextensies | Eenvoudiger, soms ondersteuning voor paginering | Vaak sjabloongebaseerd, beperkt door layout |
| AI-gedreven tools | Snel, past zich aan wijzigingen aan, geen code nodig | Nieuwere technologie, maar snel beter geworden |
combineert het beste van alles: net zo eenvoudig als een browserextensie, maar aangedreven door AI die de complexe lay-outs van Noon begrijpt, paginering afhandelt en zelfs suggesties doet voor welke velden je moet extraheren. Dit is waarom ik denk dat het de beste keuze is voor Noon-scraping:
| Functie | Traditionele scrapers | Thunderbit (AI-webscraper) |
|---|---|---|
| No-code installatie | Soms | Altijd (2-klik-installatie) |
| Ondersteuning voor paginering/infinite scroll | Soms | Ja (AI past zich aan, geen handmatige setup) |
| AI-veldsuggesties | Nee | Ja (“AI-velden voorstellen”-knop) |
| Scrapen van subpagina’s (detailpagina’s) | Handmatige scripting | Ja (1 klik, AI-gestuurd) |
| Gratis sjablonen voor Noon | Zeldzaam | Ja (Noon Scraper-sjabloon) |
| Data-export (Excel, Sheets, enz.) | Soms | Ja (gratis, direct) |
| Onderhoud vereist | Hoog | Laag (AI past zich aan sitewijzigingen aan) |
| Datalabeling/vertaling | Nee | Ja (ingebouwde AI-functies) |
Thunderbit is gemaakt voor zakelijke gebruikers, niet alleen voor developers. Je hoeft geen XPath, CSS-selectors of Python-scripts te debuggen. Richt, klik en haal je data op.
Stap voor stap: hoe je Noon-data scrapt met Thunderbit
Klaar om aan de slag te gaan? Zo zet je binnen enkele minuten Noon-data in je spreadsheet—zonder technische kennis.
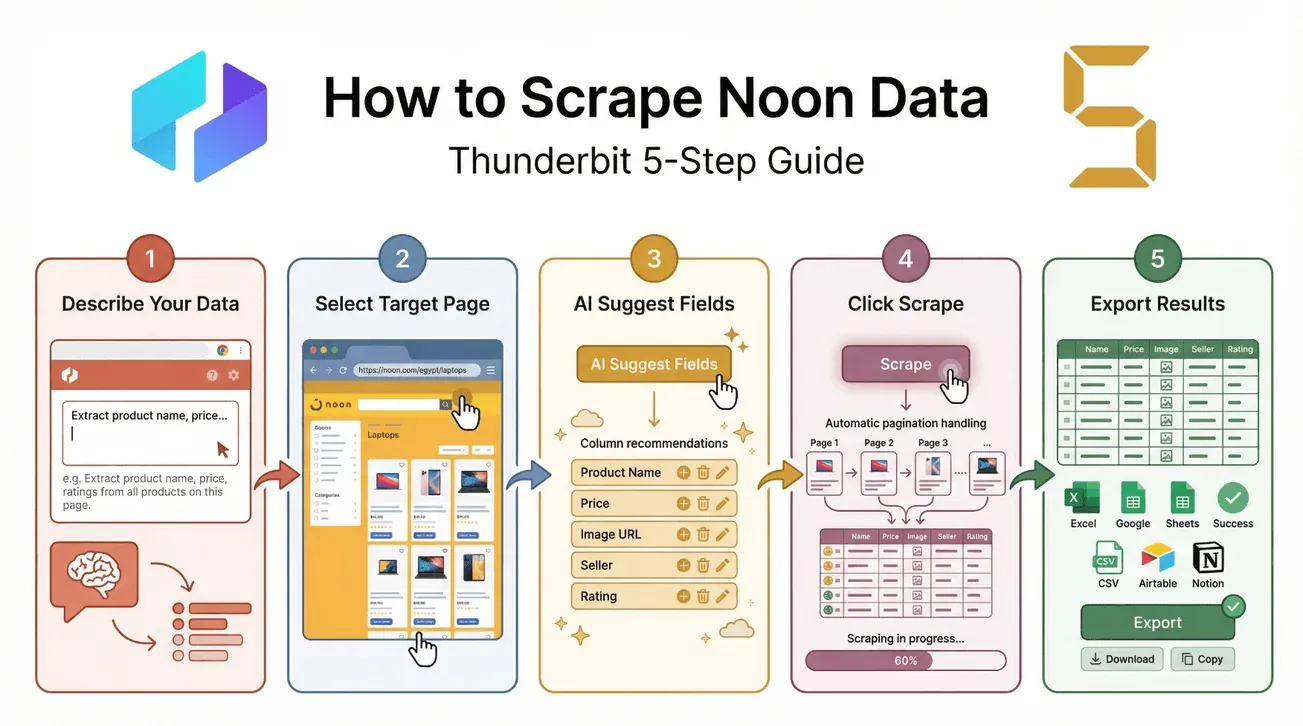
1. Beschrijf je databehoefte in natuurlijke taal
Open de . Typ in het vak “Beschrijf je data” gewoon wat je wilt, bijvoorbeeld:
“Extraheer productnaam, prijs, beoordeling en verkoper uit de elektronicacategorie van Noon.”
Thunderbit’s AI gebruikt dit als startpunt voor veldsuggesties.
2. Selecteer de gewenste Noon-pagina
Navigeer naar de categorie- of zoekresultatenpagina van Noon die je wilt scrapen. Zorg dat alle producten die je nodig hebt zichtbaar zijn (of gepagineerd).
3. Gebruik “AI-velden voorstellen” voor automatische kolomaanbevelingen
Klik op de knop “AI-velden voorstellen”. Thunderbit scant de pagina en beveelt kolommen aan, zoals Productnaam, Prijs, Afbeeldings-URL, Verkoper en meer. Je kunt kolommen toevoegen, verwijderen of hernoemen zoals nodig.
4. Klik op “Scrapen” om data te extraheren
Klik op de knop “Scrapen”. Thunderbit zal:
- Paginering automatisch afhandelen (zelfs infinite scroll)
- Elke productvermelding bezoeken en, als je wilt, ook elke productdetailpagina voor meer informatie
- De data netjes in een tabel structureren
5. Exporteer resultaten naar Excel, Google Sheets of andere formaten
Zodra het scrapen klaar is, exporteer je je data met één klik:
- Download als CSV of Excel
- Exporteer direct naar Google Sheets, Airtable of Notion
- Kopieer naar het klembord om snel te plakken
Je kunt zelfs Thunderbit’s gebruiken voor een vooraf ingestelde setup—gewoon toepassen en gaan.
Visuele gids: screenshots en tips
- Screenshots: Voor een visuele rondleiding kun je terecht in de van Thunderbit of op de .
- Probleemoplossing:
- Als Noon je vraagt om in te loggen, zorg dan dat je vóór het scrapen bent ingelogd.
- Bij infinite scroll: laat de pagina alle producten laden voordat je start, of laat Thunderbit het scrollen afhandelen.
- Loop je vast? Probeer dan te wisselen tussen browser- en cloud-scrapingmodi.
Meer inzichten halen: hoe Thunderbit’s AI Noon-data-analyse versterkt
Scrapen is pas de eerste stap. Thunderbit’s AI-functies brengen je Noon-data van “ruw” naar “klaar voor actie”:
- Labeling: Tag producten automatisch op categorie, merk of aangepaste regels.
- Opmaak: Normaliseer prijzen, datums en cijfers voor eenvoudige analyse.
- Vertaling: Vertaal productbeschrijvingen of reviews direct naar je voorkeurstaal.
- Categorisering: Groepeer producten op type, prijsklasse of verkoper voor segmentatie.
Dankzij deze ingebouwde AI-tools ga je van een rommelige datadump naar een schone, bruikbare dataset—zonder extra software of handmatige opschoning.
Praktijkvoorbeelden: van ruwe data naar zakelijke inzichten
Zo zetten teams Thunderbit-verrijkte Noon-data in de praktijk in:
- Sales: Identificeer ondergeprijsde producten of hardlopers om je eigen prijzen of voorraad aan te passen.
- Marketing: Signaleer trending categorieën voor gerichte campagnes.
- Operations: Monitor voorraadtekorten of prijswijzigingen om supplychain-beslissingen te optimaliseren.
- Analytics: Voer gestructureerde Noon-data in BI-dashboards in voor realtime marktmonitoring.
Een gebruiker vertelde me dat hij met Thunderbit’s AI-gedreven scraping en labeling zijn wekelijkse tijd voor prijsbewaking terugbracht van 8 uur naar 30 minuten. Dát is de soort ROI waardoor je ochtendkoffie nog beter smaakt.
Naleving waarborgen: Noon-data verantwoord scrapen
Laten we het over de olifant in de kamer hebben: compliance. Data scrapen van Noon (of welke site dan ook) brengt verantwoordelijkheden met zich mee.
- Controleer Noon’s voorwaarden: Noon’s verbieden expliciet scrapen en geautomatiseerde toegang zonder toestemming. Bekijk de actuele versie van hun beleid voordat je begint, en overleg met juridische zaken als je meer doet dan persoonlijk onderzoek.
- Respecteer robots.txt: Als Noon’s robots.txt scrapen van bepaalde pagina’s verbiedt, blijf daar dan weg.
- Beperk je verzoeken: Overbelast Noon’s servers niet—Thunderbit laat je de scrape-snelheid instellen.
- Gebruik data ethisch: Gebruik gescrapete data alleen voor legitieme zakelijke doeleinden en vermijd het verzamelen van persoonlijke informatie tenzij je toestemming hebt.
Praktische compliance-checklist
- [ ] Controleer Noon’s gebruiksvoorwaarden
- [ ] Kijk in robots.txt naar verboden paden
- [ ] Beperk scrape-frequentie en volume
- [ ] Vermijd het verzamelen van gevoelige persoonsgegevens
- [ ] Vermeld databronnen indien vereist
- [ ] Blijf op de hoogte van lokale privacywetgeving
Een goede webburger zijn is niet alleen netjes—het houdt je bedrijf ook uit de problemen ().
Veelvoorkomende uitdagingen bij het scrapen van Noon overwinnen
Noon, net als veel moderne e-commercesites, gooit scrapers een paar verrassingen voor de voeten:
- Dynamische content: Productoverzichten kunnen via JavaScript of infinite scroll laden. Thunderbit’s browsermodus kan met dit soort situaties omgaan ().
- Anti-botmaatregelen: Noon gebruikt rate limiting en CAPTCHA’s om geautomatiseerd verkeer eruit te filteren. Thunderbit laat je schakelen tussen browsermodus (draait in je ingelogde tab, oogt als normaal browsen) en cloudmodus (aparte IP’s, beter voor bulk), en je kunt de snelheid verlagen als een categoriepagina lege resultaten begint terug te geven. Niets hiervan garandeert dat je nooit geblokkeerd wordt bij een run met veel volume — als dat gebeurt, vertraag dan of splits de taak op.
- Complexe paginering: Of het nu “Volgende”-knoppen zijn of eindeloos scrollen, Thunderbit kan de flow volgen en elk product pakken ().
- Wijzigende lay-outs: Noon werkt de site regelmatig bij. Thunderbit’s AI leest de pagina elke keer opnieuw, zodat je niet vastzit aan het repareren van kapotte sjablonen.
Als je tegen problemen aanloopt, probeer dan:
- Te wisselen tussen browser- en cloud-scraping
- Je scraping-snelheid aan te passen
- Thunderbit’s functie “Aangepaste instructie” te gebruiken om lastige velden te verduidelijken
Je Noon-data exporteren en gebruiken: volgende stappen
Zodra je je Noon-data hebt gescrapt en verrijkt, is het tijd om ermee aan de slag te gaan:
- Exportopties: Thunderbit laat je exporteren naar Excel, CSV, Google Sheets, Airtable of Notion—wat maar bij je workflow past ().
- Integratie: Voer je data in BI-dashboards, prijstools of voorraadbeheersystemen in.
- Automatisering: Plan regelmatige scrapes om je data actueel te houden en je rapporten up-to-date.
Voor terugkerende taken sla je je Thunderbit-scraper-sjabloon op en laat je die automatisch draaien. Je team zal je dankbaar zijn voor de bespaarde tijd.
Conclusie en belangrijkste inzichten
Noon-data scrapen hoeft geen hoofdpijn te zijn. Met Thunderbit kun je:
- Snel gestructureerde data extraheren uit Noon’s complexe site—zonder code
- AI benutten voor veldsuggesties, scrapen van subpagina’s en dataverrijking
- Je resultaten exporteren naar de tools die je al gebruikt (Excel, Sheets, Notion, Airtable)
- Compliant blijven door best practices te volgen en Noon’s beleid te respecteren
- Ruwe data omzetten in bruikbare inzichten voor prijsstelling, voorraad, marketing en meer
Als je klaar bent om het handmatige werk achter je te laten en het volledige potentieel van Noon-data te benutten, voor je volgende project. Met de gratis versie kun je tot 6 pagina’s scrapen—genoeg om de magie in actie te zien.
Wil je meer tips over webscraping, e-commercanalytics of AI-gedreven productiviteit? Bekijk de en abonneer je op ons voor tutorials en walkthroughs.
Veel succes met scrapen—en moge je data altijd schoon, compleet en een stap voor op de concurrentie zijn.
Veelgestelde vragen
1. Is het legaal om Noon-data te scrapen?
Dat hangt af van Noon’s gebruiksvoorwaarden en lokale privacywetgeving. Controleer altijd Noon’s , bekijk robots.txt en gebruik data verantwoord. Thunderbit moedigt ethisch scrapen en naleving aan.
2. Welke data kan ik met Thunderbit van Noon extraheren?
Je kunt productnamen, prijzen, beoordelingen, afbeeldingen, beschrijvingen, verkoperinformatie en meer extraheren. Thunderbit’s AI stelt relevante velden voor en kan zelfs detailpagina’s scrapen voor rijkere data.
3. Hoe gaat Thunderbit om met Noon’s paginering en dynamische content?
Thunderbit’s AI detecteert en verwerkt automatisch zowel klassieke paginering als infinite scroll. Het kan ook met JavaScript-geladen content omgaan via browsermodus.
4. Kan ik Noon-data exporteren naar Excel of Google Sheets?
Zeker. Thunderbit ondersteunt directe export naar Excel, CSV, Google Sheets, Airtable en Notion—zonder extra stappen.
5. Wat als Noon zijn website-indeling wijzigt?
Omdat Thunderbit's AI de pagina bij elke run opnieuw leest in plaats van te vertrouwen op een handgemaakt sjabloon, breken kleine lay-outwijzigingen de scrape meestal niet — je klikt gewoon opnieuw op "AI-velden voorstellen". De eerlijke kanttekening: een volledige herontwerp van Noon, een nieuwe CAPTCHA-muur of een A/B-variant kan nog steeds elke scraper van de wijs brengen. Als iets er niet goed uitziet, voer dan "AI-velden voorstellen" opnieuw uit, wissel tussen browser- en cloudmodus, of verfijn je veld met een aangepaste instructie.
Klaar om te beginnen? en ontdek hoe eenvoudig Noon-data scrapen kan zijn.
Meer lezen