

Picture this: You’re searching for the perfect pair of sneakers online. You scroll through page after page, clicking “Next” or “Load More,” and somewhere around page 12, you start to wonder—how much more is out there? Now, imagine you’re not just shopping, but trying to collect every product listing for a price comparison, or maybe you’re a sales rep hunting for leads buried in a massive online directory. That’s when web pagination goes from a minor convenience (or annoyance) to a major technical hurdle.
As someone who’s spent years in SaaS, automation, and AI, I’ve seen firsthand how pagination can make or break a data project. And with the rise of AI web scraping agents like Thunderbit, the way we handle web pagination is evolving fast. In this guide, I’ll break down what web pagination is, why it matters for anyone scraping data, and how modern tools (especially AI-powered ones) are making it easier than ever to extract complete datasets—no matter how many pages deep the info is hiding.
What is Web Pagination? A Simple Guide for Business Users
What Is Data Scraping and How to Do It in 2025 Get Started Free
Let’s start with the basics. Web pagination is just a fancy way of saying “breaking up a long list of stuff into smaller, easier-to-handle pages.” If a website has 500 products, it probably won’t load them all at once (unless it wants your browser to cry for help). Instead, it’ll show you, say, 20 products per page, with navigation controls—like page numbers, “Next,” or “Load More” buttons—so you can browse chunk by chunk.
But why do websites do this? Three big reasons:
- Usability: No one wants to scroll through a single, endless page of 1,000 items. Pagination helps users find what they need, remember where they left off (“That deal was on page 3!”), and not get lost in the digital weeds.
- Performance: Loading smaller batches of content is way faster and easier on your browser (and the website’s servers). It also saves bandwidth, especially when images are involved.
- Navigation & Structure: Pagination gives a sense of order. You can jump to the beginning, end, or a specific section. It’s like having a table of contents for a book instead of one giant, unbroken scroll.
Without pagination, a lot of websites would be downright unusable. Imagine an e-commerce site dumping all 10,000 products on one page—your laptop fan would sound like it’s about to take off.
Why Web Pagination Matters for Web Scraper Pagination
Now, here’s where things get interesting for anyone using web scraping tools. If you’re only scraping the first page of results, you’re missing out on the majority of the data. And in business, incomplete data is about as useful as a pizza box with no pizza inside.
Let’s look at some real-world use cases:
| Use Case | Why Scraping Beyond Page 1 is Crucial |
|---|---|
| Lead Generation (e.g., extracting contacts from directories or LinkedIn) | Most contacts aren’t on the first page. Without pagination, you’d collect only a small fraction of available leads. |
| Price Monitoring (competitor products on e-commerce sites) | Competitor offerings and prices may span dozens of pages. Only scraping page 1 could miss low-priced items or specific SKUs deeper in the listing. |
| Market Research/SEO (search results, rankings) | A brand’s presence might be on page 2, 3, or beyond. For thorough analysis, scrapers must gather data from all result pages. |
| Listings Aggregation (real estate, job boards, etc.) | Critical listings could be anywhere in a 100+ page list. Incomplete scraping means missed opportunities. |
As one web scraping guide puts it: “Without handling pagination, your dataset is incomplete. And incomplete data is useless data.”
The Most Common Pagination Examples on the Web
Websites have gotten creative (sometimes too creative) with how they paginate content. Here are the most common styles you’ll run into:
Numbered Pagination
This is the classic format: at the bottom of the list, you’ll see numbered page links (1, 2, 3, …, 10, Next >). It’s everywhere—Google search, Amazon, eBay, Walmart. You can jump to any page or click “Next” to go one by one.
![]()
Pros:
- Easy to understand.
- Lets you jump around.
- Usually, the page number is right in the URL (like
?page=2), making it a breeze for web scrapers.
Cons:
- Clicking through lots of pages can be tedious for users.
- Some sites hide page numbers or use tricky systems (like only showing a few numbers at a time).
For web scraping, numbered pagination is usually the friendliest—just increment the page number in the URL or follow the “Next” link until you hit the end (more details here).
“Load More” Button Pagination
Instead of pages, some sites have a big “Load More” button at the bottom. Click it, and more items appear—no page reload, just more stuff tacked onto the list. This is common on mobile-friendly sites and social feeds.
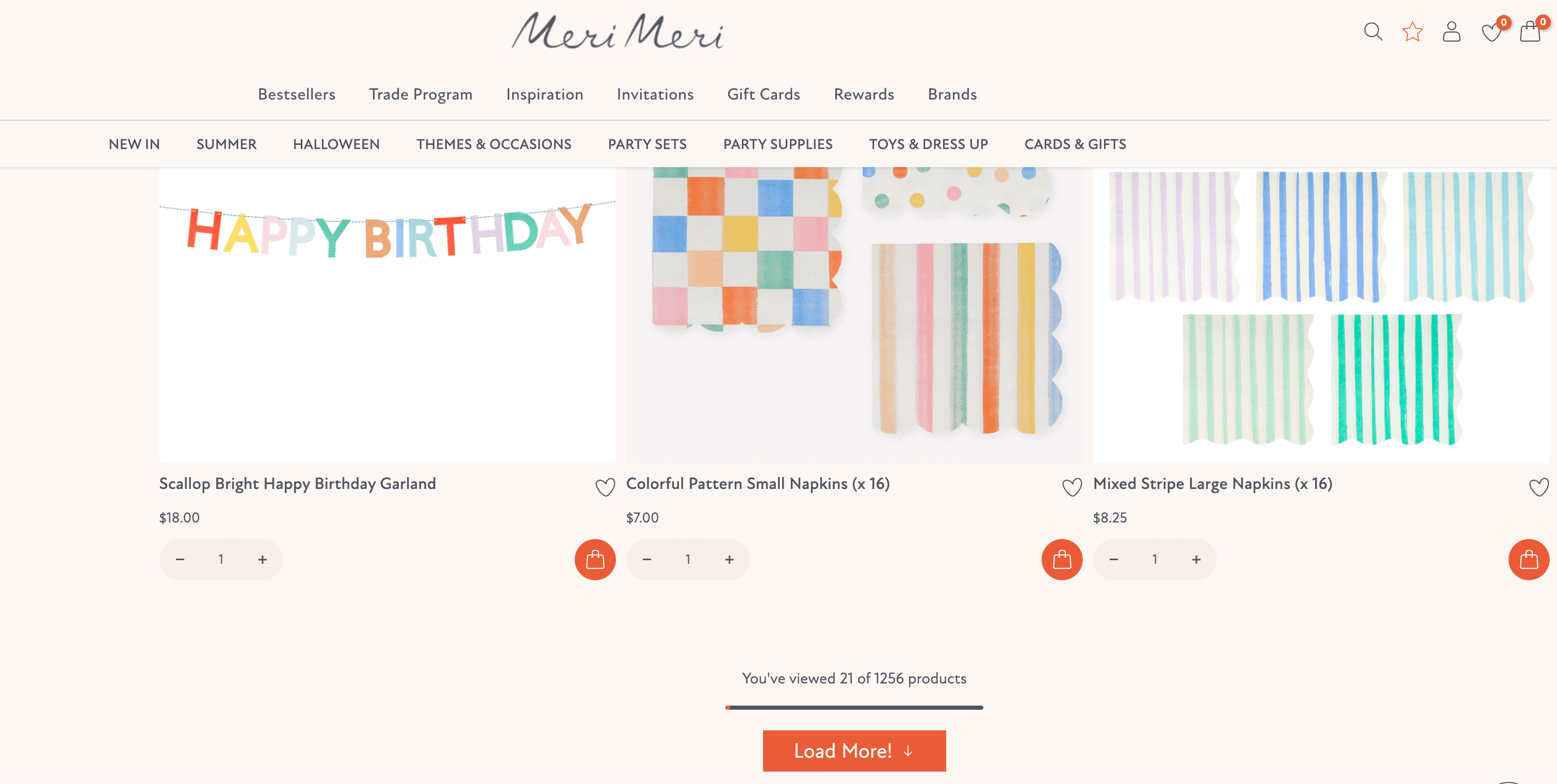
Pros:
- Smoother experience for users.
- Keeps everything on one page.
Cons:
- For scrapers, you have to simulate clicking that button (not just change a URL).
- Sometimes the button triggers hidden API calls, which can be tricky to mimic.
Web scraping tools need to either simulate the button click or replicate the network request behind it (see how it works).
Infinite Scroll Pagination
Ah, infinite scroll—the “just one more post” trap perfected by social media. As you scroll down, more content loads automatically. Instagram, Twitter, Facebook, TikTok, and even some retail sites like Nike use this approach.
Pros:
- Super engaging for users (sometimes too engaging).
- Great for mobile.
Cons:
- Hard to find something you saw earlier (no page numbers).
- For scrapers, it’s the trickiest—there’s no “Next” button, so you have to simulate scrolling and wait for new content to load.
Infinite scroll often requires browser automation tools or AI-powered scrapers that can mimic real user behavior (here’s why it’s tough).
Next/Previous Navigation
Some sites keep it simple: just “Next >” and “< Previous” links, with no page numbers. You have to go one by one, like flipping through a photo album.
Pros:
- Clean and simple for users.
Cons:
- You can’t jump to a specific page.
- For scrapers, you have to keep clicking “Next” until it disappears.
This pattern is common on minimalist blogs, some forums, and older web apps.
How Web Scraping Pagination Works: The Basics
So, how do web scrapers actually handle pagination? Here’s the basic playbook:
- Start on Page 1: The scraper loads the first page and grabs the data.
- Detect Pagination Controls: It looks for clues—page numbers, “Next” buttons, “Load More,” or signs of infinite scroll.
- Iterate: Depending on the type, the scraper either:
- Increments the page number in the URL,
- Clicks the “Next” or “Load More” button,
- Or scrolls down the page to trigger more content.
- Repeat: It keeps going—scraping, clicking, or scrolling—until there are no more pages or items to load.
- Finish Up: After collecting everything, the scraper merges the data, removes duplicates, and outputs the final result.
Here’s a simple flowchart for the visual folks:
[Page 1] → [Scrape Data] → [Is there a next page?] → Yes → [Go to Next Page] → [Scrape Data] → ... → No → [Done!]
The trick is that “next page” could mean a literal link, a button, or a scroll action. Modern scrapers (especially AI-powered ones) can figure this out automatically, but it’s always good to know what’s happening under the hood.
Thunderbit’s Approach: AI-Powered Web Scraper Pagination
Scrape paginated websites with AI Get Started Free
Okay, let’s talk about the fun stuff—how Thunderbit is changing the pagination game for web scraping.
As the co-founder of Thunderbit, I’ve seen users struggle with all kinds of pagination nightmares. That’s why we built Thunderbit’s AI to handle pagination automatically—so you don’t have to mess with loops, selectors, or code.
Here’s how Thunderbit handles pagination:
- Automatic Detection: Thunderbit’s AI scans the page and figures out if there’s pagination—whether it’s numbered links, a “Next” button, “Load More,” or infinite scroll. If it finds pagination, it knows how to interact with it.
- Browser-Mode Scraping: Thunderbit runs inside Chrome, so it sees everything a real user would—including content loaded by JavaScript. This is huge for infinite scroll and dynamic “Load More” buttons.
- Cloud Scraping for Speed: Need to scrape lots of pages? Thunderbit’s cloud mode can fetch up to 50 pages at once, in parallel. That’s like having 50 interns clicking “Next” for you—without the coffee breaks.
- No Manual Scripting: Just click “AI Suggest Fields,” let Thunderbit figure out the columns, and hit “Scrape.” If there’s pagination, Thunderbit keeps going until it’s done. No code, no XPath, no headaches.
- Handles Both Click and Scroll: Whether the site uses clickable pagination or infinite scroll, Thunderbit can handle it. You can let the AI decide or choose the mode yourself.
- Subpage Scraping: After scraping a list, Thunderbit can even visit each item’s detail page to grab more info—perfect for e-commerce or real estate listings.
In short, Thunderbit’s AI treats pagination like just another part of the page. It knows how to “turn the page” for you, whether that means clicking, scrolling, or something in between. (And unlike me, it never gets bored.)
Try Thunderbit for Paginated Web Scraping
Thunderbit vs. Traditional Web Scraper Pagination
Let’s put Thunderbit side-by-side with the old-school approach:
| Feature | Traditional Scraper | Thunderbit (AI-Powered) |
|---|---|---|
| Setup Time | Manual: Select “Next” button, write loops, tweak selectors | Automated: Click “AI Suggest Fields,” hit “Scrape” |
| Handles Infinite Scroll | Requires browser automation, custom code | Built-in AI mode, just toggle on |
| Adapts to Site Changes | Breaks if site changes layout or button | AI re-analyzes page each time |
| Speed | Sequential (one page at a time) | Cloud mode: up to 50 pages in parallel |
| Maintenance | High—update scripts if site changes | Low—AI adapts, team updates models |
| Anti-Bot Evasion | Manual: add delays, proxies | Built-in: human-like timing, cloud IPs |
| Subpage Scraping | Manual setup for each layer | One-click “Scrape Subpages” |
Thunderbit is like having a super-smart assistant who knows how to find every page, click every button, and never gets lost—even when the website tries to hide the path.
Best Practices for Handling Web Scraping Pagination
Whether you’re using Thunderbit or another tool, here are some tips to make sure you get all the data (and none of the headaches):
- Identify the Pagination Pattern: Before scraping, check how the site paginates. Is it numbered? “Load More”? Infinite scroll? Knowing this helps you pick the right tool or mode.
- Use the Right Tool: For simple pagination, basic scrapers work. For infinite scroll or dynamic sites, use a browser-based or AI-powered tool like Thunderbit.
- Avoid Missing Pages: Always check that you scraped all the data. If the site says “500 results,” make sure you got 500 (or close to it).
- Prevent Duplicates: Some sites overlap items between pages. Use unique IDs (like product URLs) to deduplicate your results.
- Throttle Requests: Don’t go too fast—rapid-fire requests can get you blocked. Thunderbit mimics human timing, but if you’re coding, add delays.
- Use Proxies for Large Jobs: If you’re scraping hundreds of pages, rotating IPs can help avoid blocks. Thunderbit’s cloud mode handles this behind the scenes.
- Plan for Errors: Sometimes a page fails to load. Log errors, retry failed pages, and always check your results.
- Leverage AI Features: For tricky pagination (like AJAX or cursor-based), AI scrapers can handle the complexity for you.
- Respect Site Policies: Always check if scraping is allowed. Don’t overload servers, and respect privacy rules.
Real-World Pagination Examples for Web Scraper Pagination
Let’s see how this plays out on some real websites:
1. Amazon (Numbered Pagination, Anti-Bot)
Amazon uses classic numbered pagination, but with a twist—they’re serious about blocking bots. Thunderbit detects the “Next” button or page links and clicks through, using browser mode to mimic a real user. In cloud mode, it can fetch multiple pages at once. If Amazon throws up a captcha, Thunderbit’s browser mode (with human-like timing) helps avoid blocks.
2. Zillow (Numbered, Page Limit)
Zillow paginates property listings, but caps at 20 pages (about 800 listings). Thunderbit auto-clicks through pages 1–20, then stops when there’s no “Next.” If you need more, you’ll have to narrow your search (Thunderbit can help you filter and scrape in batches).
3. LinkedIn (Infinite Scroll Hybrid)
LinkedIn job search (not logged in) uses infinite scroll—more jobs load as you scroll. Thunderbit switches to infinite scroll mode, scrolling and scraping until no new jobs appear. If you’re logged in and see page numbers, Thunderbit adapts and clicks through.
4. Yelp (Offset Pagination)
Yelp uses offset-based pagination (like start=10 in the URL). Thunderbit clicks “Next” or increments the offset automatically. If Yelp asks for your location, Thunderbit’s browser mode can handle the prompt.
5. AliExpress (Hybrid: Scroll + Pages)
AliExpress loads more products as you scroll, then sometimes shows a “Next” button. Thunderbit scrolls to load as much as possible, then clicks to the next page if needed. It’s the Swiss Army knife of pagination.
Troubleshooting Web Scraping Pagination Issues
Even with the best tools, things can go sideways. Here’s what to watch for—and how Thunderbit helps:
- Only Got the First Page: Make sure pagination is enabled in your tool. In Thunderbit, check the “Paginate” toggle. If needed, manually click “Scrape Next Page.”
- Missing Data: Compare your result count to what the site says. If you’re missing chunks, re-run the scrape or target the missing pages.
- Scraper Gets Stuck: Infinite scroll can hang if content loads slowly. In Thunderbit, try browser mode for more control, or set a max scroll time.
- Duplicates or Out-of-Order Data: Deduplicate by unique ID. Thunderbit usually keeps order, but you can sort in Excel if needed.
- Repeating or Empty Pages: Make sure your scraper stops at the end. Thunderbit’s AI knows when to quit, but if you’re coding, break the loop when no new data appears.
Thunderbit’s AI is built to handle most of these headaches automatically—detecting pagination, adding human-like delays, and retrying failed pages. And if you ever hit a weird edge case, the Thunderbit team is always updating the AI to handle new patterns.
Scrape Paginated Data with Thunderbit AI
Key Takeaways: Making the Most of Web Scraper Pagination
Let’s wrap up with a quick checklist for scraping paginated sites:
- Understand the Pagination Style: Numbered, “Load More,” infinite scroll, or next/prev? Know what you’re dealing with.
- Choose the Right Tool: Use AI-powered scrapers like Thunderbit for complex or dynamic sites.
- Scrape All Pages: Don’t stop at page one—make sure you get the full dataset.
- Check for Errors: Watch for missing data, duplicates, or blocks.
- Throttle and Rotate: Avoid getting blocked by pacing your requests and using proxies if needed.
- Leverage Scheduling: For recurring jobs, use a scheduler (Thunderbit’s natural language scheduler makes this easy).
- Use AI for Data Cleanup: Thunderbit’s Field AI can help label, deduplicate, and organize your data as you scrape.
- Learn from Real-World Patterns: Recognize common site behaviors and adapt your strategy.
- Use Templates: Thunderbit has one-click templates for many popular sites—use them to save time.
- Stay Ethical: Always respect site policies and privacy rules.
Web pagination might seem like a hurdle, but with the right knowledge and tools, it’s just another step on the path to complete, accurate data. And with Thunderbit’s AI-powered approach, you can spend less time fighting with pagination and more time putting your data to work.
FAQs
1. What is web pagination, and why do websites use it?
Web pagination is the practice of splitting long lists of content (like product listings or search results) into multiple smaller pages. Websites use it to improve usability, performance, and structure—helping users navigate easily, reducing load times, and organizing content effectively.
2. Why is pagination important for web scraping?
If your scraper only collects data from the first page of a site, you're likely missing most of the valuable content. Many business use cases—such as lead generation, price monitoring, or market research—require scraping beyond the first page to ensure a complete dataset.
3. What are the most common types of pagination on websites?
The main types include:
- Numbered Pagination: Pages labeled 1, 2, 3, etc.
- “Load More” Buttons: Adds more results without reloading the page.
- Infinite Scroll: Automatically loads new content as you scroll.
- Next/Previous Links: Lets users navigate one page at a time.
Each type requires a different scraping strategy.
4. How does Thunderbit handle web scraping pagination?
Thunderbit uses AI to automatically detect and handle all common pagination types—numbered links, “Load More” buttons, and infinite scroll. It runs in browser mode for dynamic pages and can use cloud scraping to process up to 50 pages in parallel, all without writing code.
5. What are some best practices when scraping paginated websites?
- Identify the pagination type before scraping.
- Use tools that can handle dynamic content (like Thunderbit).
- Always verify that all pages were scraped (not just the first).
- Deduplicate data using unique identifiers.
- Throttle requests and use proxies for large jobs.
- Respect website terms and data usage policies.
Learn More:
- The Best Web Scraping Tools & Software in 2025
- How to Scrape Any Website Using AI
- Mastering Pagination in Web Scraping: A Complete Guide
- What is Pagination? And How to Implement it on Your Website
Try Thunderbit AI Web Scraper for Paginated Sites Get Started Free




