

Er speelt overal op kantoor een stille revolutie, en die heeft niets te maken met pingpongtafels of kombucha van de tap. Het is de opkomst van “eenvoudige webextractie”: de mogelijkheid voor iedereen, niet alleen programmeurs, om in minuten in plaats van dagen nuttige data van het web te halen. Heb je ooit naar een website zitten staren, hopend dat je gewoon al die namen, prijzen of e-mailadressen kon pakken en in een spreadsheet kon zetten? Dan ben je niet de enige. Ik heb met salesmedewerkers, marketeers en operations-teams gesproken, en ze zeggen allemaal hetzelfde: “Waarom is dit nog steeds zo moeilijk?”
De waarheid is dat de vraag naar eenvoudige methoden voor webscraping explosief groeit. Volgens McKinsey's State of AI 2025 gebruikt 71% van de organisaties inmiddels generatieve AI in minstens één bedrijfsfunctie, tegenover 65% begin 2024, en webdata-extractie wordt razendsnel een van de meest gewilde toepassingen. De markt voor webscraping stevent af op $1,17 miljard in 2026 en $2,23 miljard in 2031, en zakelijke gebruikers — vooral zonder technische achtergrond — drijven de vraag naar tools die data-extractie net zo eenvoudig maken als kopiëren en plakken. Maar wat betekent “eenvoudige webextractie” nu echt, en hoe kun je het gebruiken om je workflow te vereenvoudigen? Laten we het uitpluizen.
Probeer eenvoudige webextractie met Thunderbit (gratis)
Eenvoudige webextractie voor niet-technische gebruikers: geen code, geen gedoe
Laten we bij het begin beginnen: Wat is “eenvoudige webextractie”? In de kern gaat het erom het rommelige, voortdurend veranderende web om te zetten in schone, gestructureerde tabellen — zonder ook maar één regel code te schrijven. Voor niet-technische zakelijke gebruikers is dat een gamechanger. Geen eindeloos IT hoeven smeken om hulp, geen gevecht met Python-scripts, en geen opgave meer wanneer een website ’s nachts zijn lay-out verandert.
Waarom is dit nu zo belangrijk? Het web is dynamischer dan ooit. Sites gebruiken oneindig scrollen, pop-ups en complexe JavaScript die ouderwetse scrapers links en rechts breekt. Tegelijkertijd is de druk op business-teams om snel inzichten te leveren nooit hoger geweest. In retail en ecommerce zegt 98% van de organisaties dat publieke webdata cruciaal of zeer belangrijk is voor hun bedrijfsvoering, en meer dan de helft gebruikt die data dagelijks.
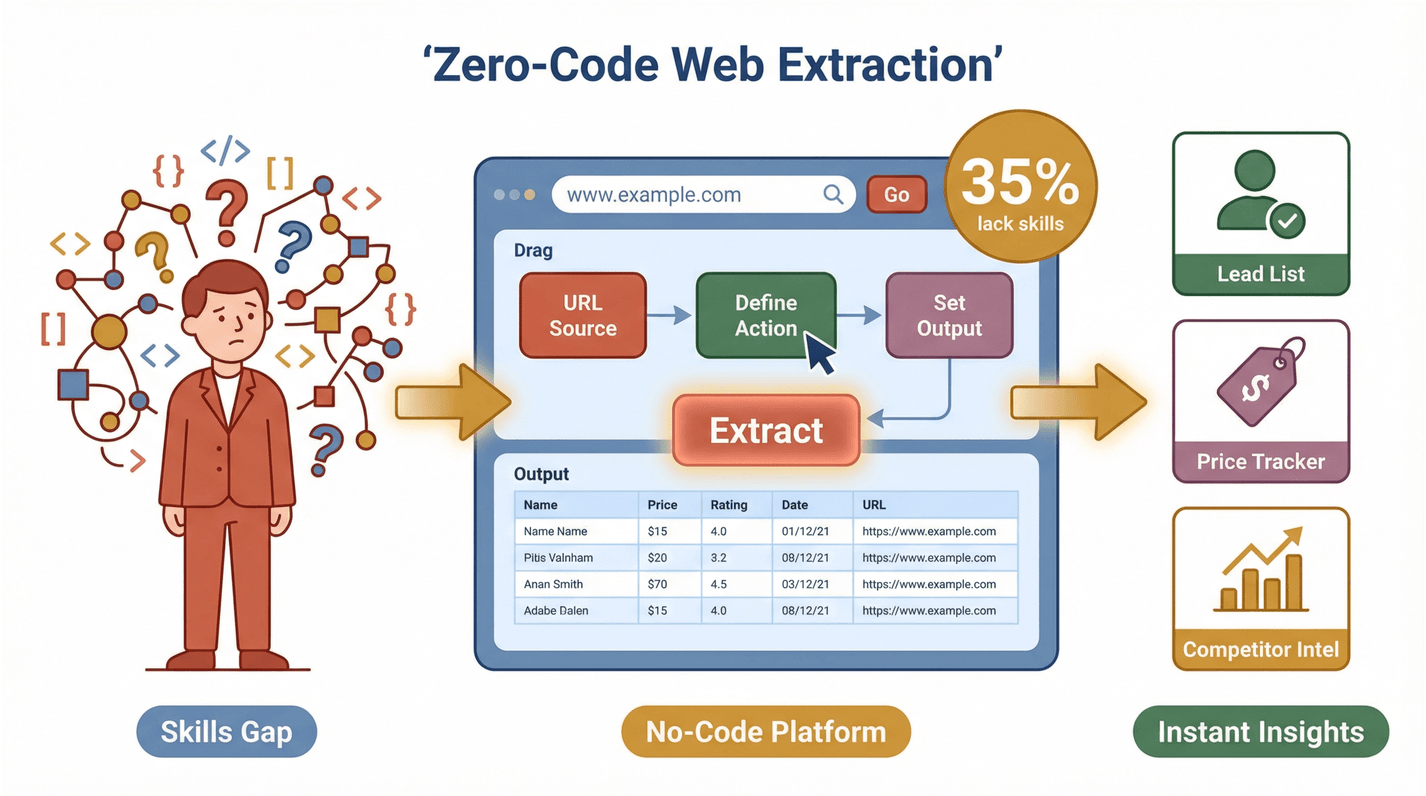
Maar hier zit de clou: de meeste van die teams zijn niet technisch. Uit een recent onderzoek bleek dat 35% van de organisaties niet over de juiste vaardigheden beschikt voor webdata-extractie, en 33% niet over de juiste tools. Dat biedt een enorme kans voor oplossingen zonder code. Wanneer iedereen webdata kan extraheren en gebruiken, ontgrendel je een nieuw niveau van productiviteit — of je nu een leadlijst bouwt, concurrenten volgt of prijzen monitort.
De no-code/low-code-beweging: waarom dit telt
De opkomst van no-code en low-code tools draait om het democratiseren van technologie. Het is niet alleen een buzzword uit Silicon Valley; het is een echte verschuiving in hoe werk wordt gedaan. In de wereld van webscraping betekent dit:
- Geen code nodig: Iedereen kan data extraheren, niet alleen engineers.
- Snelheid: Resultaten in minuten, niet dagen.
- Flexibiliteit: Direct aanpassen aan nieuwe sites en databronnen.
- Minder fouten: Automatisering betekent minder kopieer- en plakfouten.
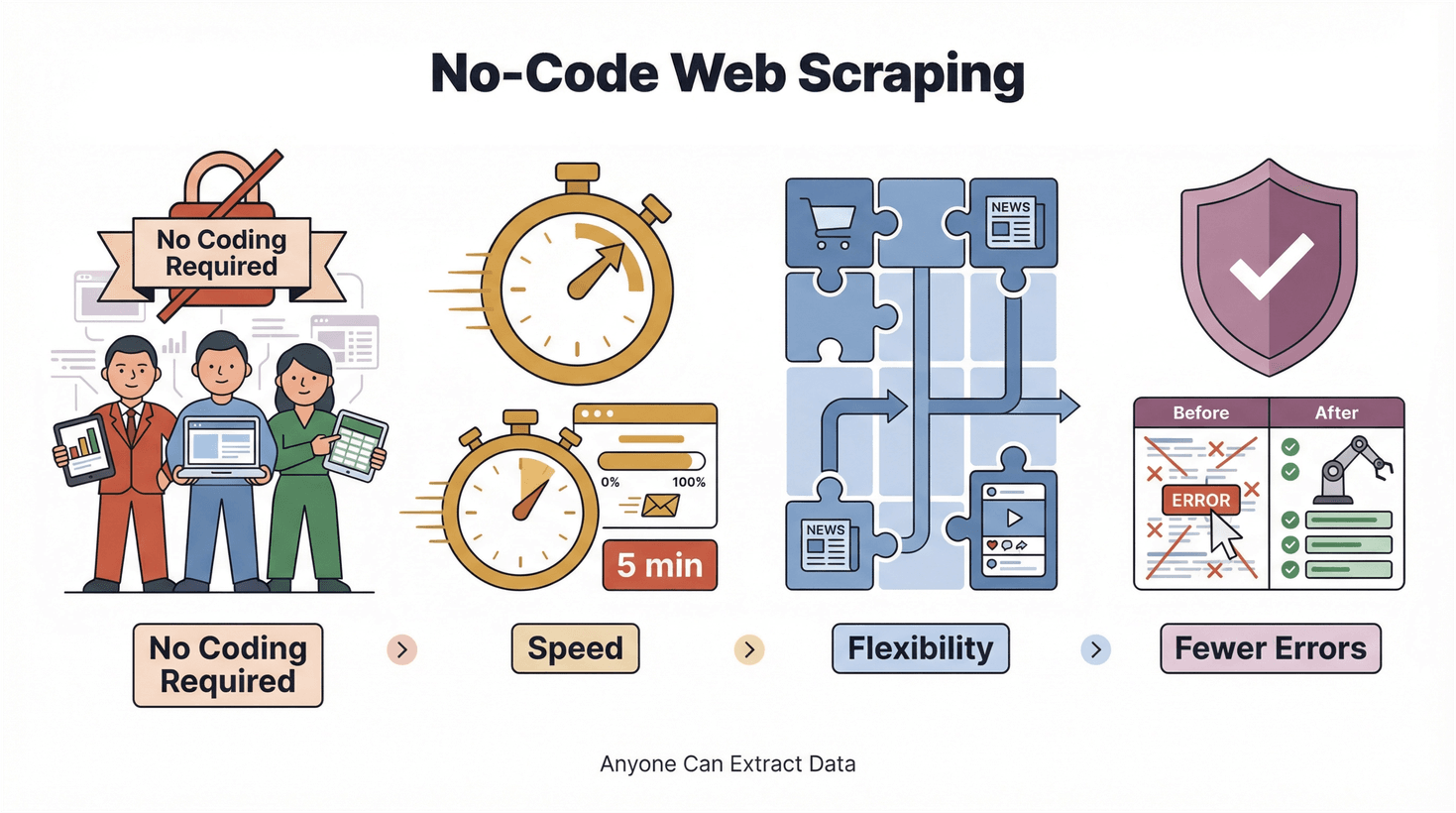
En het mooiste? Je hoeft geen tech-goeroe te worden om mee te doen.
Waarom traditionele webscrapingtools zo frustrerend zijn
Laten we eerlijk zijn: traditionele webscrapingtools voelen vaak alsof ze zijn gemaakt door en voor developers, niet voor zakelijke gebruikers. Ik heb het zelf gezien: teams raken enthousiast over een nieuw project, maar lopen vast zodra de tool vraagt om CSS-selectors, XPath of reguliere expressies. Dan zie je al snel lege blikken en e-mails met “misschien volgend kwartaal”.
Dit gaat meestal mis:
- Code nodig: De meeste oudere tools verwachten dat je scripts schrijft of complexe sjablonen instelt.
- Gedoe bij de installatie: Je moet elk veld in kaart brengen, inlogflows afhandelen en proxies instellen om blokkades te voorkomen.
- Kwetsbare logica: Websites veranderen van lay-out, en ineens werkt je scraper niet meer. Dan ben je code aan het debuggen in plaats van je echte werk te doen.
- Onderhoudslast: Elke keer dat een site wordt bijgewerkt, begin je weer opnieuw.
Geen wonder dat dezelfde teams die een vaardigheidskloof melden ook een toolkloof melden — Bright Data's onderzoek uit 2024 vond dat 35% van de organisaties niet de juiste vaardigheden heeft en 33% niet de juiste tools voor public web data-werk. Zelfs geavanceerde teams hebben moeite om bij te blijven met IP-blokkades, dynamische content en CAPTCHA’s.
Intussen willen zakelijke gebruikers gewoon een eenvoudige, betrouwbare manier om data in hun spreadsheets of CRM’s te krijgen. Daar komen eenvoudige webextractie en simpele methoden voor webscraping om de hoek kijken.
Hoe Thunderbit eenvoudige webextractie mogelijk maakt
Extraheer data van elke website met AI Get Started Free
Hier word ik enthousiast van — want dit is precies het probleem dat we bij Thunderbit wilden oplossen. Onze missie is om webscraping zo eenvoudig te maken dat iedereen het kan, ongeacht technische achtergrond.
Thunderbit is een AI-webscraper Chrome-extensie die webextractie omzet in een proces van twee klikken. Zo werkt het:
- Beschrijf wat je wilt: Gebruik natuurlijke taal om Thunderbit te vertellen welke data je nodig hebt. Bijvoorbeeld: “Extraheer alle productnamen en prijzen van deze pagina.”
- Klik op “AI Suggest Fields”: De AI van Thunderbit leest de pagina en stelt de beste kolommen voor om te extraheren — zoals “Naam”, “Prijs”, “E-mail” of “Afbeelding”.
- Klik op “Scrape”: Thunderbit doet de rest, inclusief paginering, subpagina’s en indien nodig zelfs content achter een login.
Dat is alles. Geen code, geen sjablonen, geen installatiegedoe. De interface is ontworpen voor zakelijke gebruikers — sales, marketing, ecommerce, vastgoed — die gewoon resultaat willen.
Thunderbits AI-gestuurde workflow: slimmer, niet harder werken
De echte magie zit in de AI. Thunderbit raadt niet zomaar wat je wilt — het leest de pagina, begrijpt de context en structureert de data automatisch. Wil je het wat geavanceerder aanpakken, dan kun je voor elk veld eigen instructies toevoegen (zoals “categoriseer deze kolom” of “vertaal naar Engels”), maar de meeste gebruikers klikken gewoon en gaan.
Deze AI-gedreven aanpak betekent:
- Minder fouten: De AI past zich aan verschillende lay-outs aan, zodat je consistente resultaten krijgt, zelfs als websites veranderen.
- Snellere installatie: Geen sjablonen bouwen of scripts schrijven.
- Bruikbare data: Thunderbit kan je data labelen, categoriseren en zelfs verrijken terwijl het scrapt.
Voor een diepere duik kun je Thunderbit’s documentatie bekijken of onze blogpost over geautomatiseerde data-extractie. Je kunt ook meer handleidingen ontdekken op de Thunderbit Blog, zoals Hoe je elke website met AI scrapt en Wat is data scraping en hoe doe je het in 2025.
Thunderbits unieke functies voor eenvoudige webscrapingmethoden
Wat Thunderbit onderscheidt, is niet alleen de AI — het is de hele workflow, ontworpen voor echte zakelijke behoeften. Dit zijn enkele functies waar onze gebruikers dol op zijn:
- Automatische paginering: Thunderbit verwerkt meerpaginawebsites en oneindig scrollen zonder enige installatie.
- Subpagina-scraping: Meer details nodig? Thunderbit kan elke subpagina bezoeken (zoals productdetails of LinkedIn-profielen) en je dataset automatisch verrijken.
- Exporteren waar je wilt: Stuur je data direct naar Excel, Google Sheets, Airtable, Notion of download als CSV/JSON. Geen eindeloze kopieer- en plakmarathons meer.
- Werkt op ingelogde pagina’s: Scrape data van sites waarvoor je moet inloggen — Thunderbit draait in je browser, dus het ziet wat jij ziet.
- AI-gestuurde labeling en categorisering: Voeg instructies toe om data te classificeren, te taggen of te vertalen terwijl je het extraheert.
- Geplande scraping: Stel terugkerende taken in om je data actueel te houden — perfect voor prijsmonitoring of leadtracking.
En ja, dit alles zit in een tool waar wereldwijd meer dan 100.000 gebruikers op vertrouwen.
Automatische paginering en extractie van subpagina’s
Een van de grootste ergernissen bij webscraping is het omgaan met gepagineerde lijsten of geneste detailpagina’s. Met Thunderbit hoef je je daar geen zorgen over te maken. De AI herkent paginering (of dat nu een “Volgende”-knop is of oneindig scrollen) en volgt automatisch links naar subpagina’s. Zo kun je in één keer honderden of duizenden records extraheren — zonder handmatig klikken.
Als je bijvoorbeeld een lijst met producten op Amazon scrapt, kan Thunderbit alle producten over meerdere pagina’s heen ophalen en vervolgens elke productpagina openen om reviews, beoordelingen of verkopersinformatie te verzamelen. Het is alsof je een onvermoeibare assistent hebt die nooit moe wordt.
Export in meerdere formaten en CRM-integratie
Data is alleen nuttig als je er echt iets mee kunt doen. Thunderbit laat je resultaten exporteren in het formaat dat je team nodig heeft — Excel, Google Sheets, Airtable, Notion of CSV/JSON. Je kunt data zelfs rechtstreeks naar je CRM of workflowtools sturen, zodat je sales- en operations-teams altijd over de nieuwste info beschikken.
Die directe integratie bespaart enorm veel tijd. Geen rommelige exports meer opschonen of kolommen opnieuw opmaken — de AI van Thunderbit regelt alles.
Praktische use cases voor eenvoudige webextractie
Waar maakt eenvoudige webextractie nu de grootste impact? Hier zijn een paar praktijkvoorbeelden die ik van Thunderbit-gebruikers heb gezien:
Leadextractie voor sales
Sales-teams leven en sterven bij hun leadlijsten. Met Thunderbit kun je binnen enkele minuten contactgegevens van LinkedIn, Google Maps of bedrijvengidsen scrapen. Open gewoon de pagina, klik op “AI Suggest Fields” en laat Thunderbit namen, e-mails, telefoonnummers en bedrijfsgegevens in een gebruiksklare spreadsheet zetten.
Een salesmanager vertelde me dat ze vroeger elke week uren kwijt waren aan leads kopiëren en plakken. Nu bouwen ze met Thunderbit in een fractie van de tijd gerichte lijsten — en kan het team zich richten op outreach, niet op data-invoer.
Ecommerce- en marktmonitoring
Ecommerce-teams gebruiken Thunderbit om SKU’s, prijzen en reviews van concurrenten te volgen op Amazon, Shopify en andere platforms. Prijswijzigingen of nieuwe productlanceringen monitoren? Stel een geplande scrape in en ontvang elke ochtend verse data in je Google Sheet.
Thunderbits subpage scraping is hier extra handig — je kunt productdetails, afbeeldingen en zelfs klantreviews ophalen zonder een vinger uit te steken.
Vastgoeddata verzamelen
Vastgoedprofessionals gebruiken Thunderbit om woningaanbod, prijzen en makelaarsinformatie te verzamelen van sites zoals Zillow of Realtor.com. De AI regelt paginering en subpagina’s, zodat je een volledig en actueel beeld van de markt krijgt — ideaal voor analyses of klantrapporten.
Een vastgoedanalist vertelde dat werk dat vroeger een hele middag kostte, nu met slechts een paar klikken klaar is. Dat is de kracht van eenvoudige webscrapingmethoden.
Traditionele en eenvoudige webscrapingmethoden vergeleken
Laten we alles naast elkaar zetten in een vergelijking:
| Kenmerk | Traditionele scrapers | Eenvoudige webextractie (Thunderbit) |
|---|---|---|
| Code nodig | Ja (scripts, selectors) | Nee (AI + natuurlijke taal) |
| Installatietijd | Hoog (sjablonen, configuratie) | Laag (2 klikken) |
| Onderhoud | Vaak (breekt bij wijzigingen op de site) | Minimaal (AI past zich aan) |
| Ondersteunt paginering | Handmatige instelling | Automatisch |
| Extractie van subpagina’s | Complexe logica | 1 klik |
| Exportformaten | Vaak beperkt | Excel, Sheets, Airtable, Notion, CSV, JSON |
| Werkt op ingelogde pagina’s | Soms (met configuratie) | Ja (browsergebaseerd) |
| Data labeling/categorisering | Handmatige nabewerking | AI-gestuurd, ingebouwd |
| Planning/bewaking | Soms (geavanceerd) | Ja (eenvoudig in te stellen) |
Het verschil is dag en nacht. Met Thunderbit kan iedereen webdata extraheren, ordenen en gebruiken — geen technische vaardigheden nodig.
Toekomsttrends in eenvoudige webextractie en eenvoudige webscrapingmethoden
Vooruitkijkend ziet de toekomst er rooskleurig uit voor eenvoudige webextractie. AI wordt alleen maar slimmer, en de vraag naar no-code tools groeit snel. Volgens McKinsey's State of AI 2025 gebruikt 88% van de organisaties AI inmiddels regelmatig in minstens één functie, tegenover 78% een jaar eerder, en agentische systemen — AI-tools die meerstaps webworkflows aankunnen — zijn in opkomst.
Wat betekent dat voor zakelijke gebruikers? Meer mogelijkheden, minder gedoe. Naarmate AI zich blijft verbeteren, gaan we zien:
- Nog slimmere veldherkenning: AI begrijpt complexere data en relaties.
- Betere integratie: Directe koppelingen met meer zakelijke tools en platformen.
- Verbeterde betrouwbaarheid: Minder breuken, consistentere resultaten, zelfs op dynamische of afgeschermde sites.
- Grotere toegankelijkheid: Webextractie wordt een standaardvaardigheid voor iedereen, niet alleen voor techneuten.
En ja, Thunderbit staat precies aan de frontlinie van deze beweging.
Conclusie en belangrijkste inzichten
Bekijk Thunderbit-plannen en credits Get Started Free
Het web is de grootste database ter wereld — maar tot voor kort konden alleen programmeurs daar echt gebruik van maken. Dat verandert snel. Met eenvoudige webextractie en simpele webscrapingmethoden kan iedereen websites in minuten omzetten in bruikbare data.
Dit heb ik geleerd (en dit hoop ik dat je meeneemt):
- Webextractie zonder code is blijvertje: Tools zoals Thunderbit maken het mogelijk voor iedereen om webdata te verzamelen en te gebruiken — geen technische vaardigheden nodig.
- AI is de geheime saus: Door veldselectie, paginering, extractie van subpagina’s en data-labeling te automatiseren, besparen AI-scrapers tijd en verminderen ze fouten.
- De zakelijke impact is reëel: Sales-, ecommerce- en vastgoedteams zien al productiviteitswinst, actuelere data en betere besluitvorming.
- De toekomst is nog rooskleuriger: Naarmate AI en no-code tools zich ontwikkelen, wordt webdata-extractie net zo gewoon als een e-mail versturen.
Ben je klaar met handmatig kopiëren en plakken, gefrustreerd door kapotte scrapers, of gewoon benieuwd wat er mogelijk is? Probeer Thunderbit dan eens. Je kunt de Chrome-extensie downloaden en gratis beginnen met data extraheren — geen installatie, geen code, geen gedoe.
En als je dieper wilt duiken, bekijk dan de Thunderbit Blog voor meer handleidingen, tips en praktijkvoorbeelden.
Veelgestelde vragen
1. Wat is “eenvoudige webextractie” en voor wie is het bedoeld?
Eenvoudige webextractie verwijst naar no-code, AI-gestuurde webscrapingmethoden waarmee iedereen — vooral niet-technische zakelijke gebruikers — snel en eenvoudig gestructureerde data van websites kan halen. Ideaal voor sales-, marketing-, ecommerce- en operationele teams die bruikbare data nodig hebben zonder technische hoofdpijn.
2. Hoe verschilt Thunderbit van traditionele webscrapingtools?
Thunderbit gebruikt AI om veldselectie, paginering en extractie van subpagina’s te automatiseren. In tegenstelling tot traditionele scrapers die code of complexe sjablonen vereisen, kun je Thunderbit in gewone taal vertellen wat je nodig hebt en met slechts twee klikken data extraheren.
3. Kan Thunderbit dynamische of meerpaginawebsites aan?
Ja. Thunderbit herkent en verwerkt paginering automatisch (inclusief oneindig scrollen) en kan links naar subpagina’s volgen voor diepere data-extractie — allemaal met minimale installatie.
4. Welke exportopties ondersteunt Thunderbit?
Thunderbit laat je data direct exporteren naar Excel, Google Sheets, Airtable, Notion, CSV of JSON. Je kunt ook integreren met CRM’s en andere workflowtools voor soepele bedrijfsprocessen.
5. Is het veilig en ethisch om tools voor eenvoudige webextractie zoals Thunderbit te gebruiken?
Thunderbit moedigt verantwoord en ethisch webscrapen aan. Respecteer altijd de gebruiksvoorwaarden van websites, scrape geen persoonsgegevens zonder toestemming en gebruik rate limiting om verstoring van diensten te voorkomen. Voor meer best practices, zie Thunderbit’s gids voor webscraping.
Klaar om de kracht van webdata te ontsluiten? Probeer Thunderbit vandaag nog en ontdek hoe eenvoudige webextractie je workflow kan veranderen.
Probeer Thunderbit voor eenvoudige webextractie
Probeer Thunderbit AI-webscraper Get Started Free
Meer weten




