
Everyone's buzzing about data-driven decision-making, but they often forget how time-consuming and tedious data collection can be. If you've ever tried gathering data by hand, you know it's a drag. I've seen plenty of companies struggle to get their data-driven strategies off the ground because of inefficient data collection. If you're in the same boat, this article's got some fresh solutions for you.
💡 In this article, we're diving into the world of data scraping and how it's evolving with technology. We'll look at the downsides of old-school methods, highlight the perks of AI-driven data scraping, and give you some hands-on tips for real-world use.
What is Data Scraping?
Data scraping, or web scraping, is all about pulling structured info from web pages using tools (often laid out in tables). It's a super-efficient way to gather a ton of data quickly. For instance, you can snag public data from Google Maps for lead generation, scrape e-commerce SKUs from Amazon for resale or market analysis, or pull social media reviews from Yelp for customer insights.
The Technological Shift in Data Scraping
Back in the day, data collection seemed like something only techies could handle (or involved a lot of manual copy-pasting). But now it's 2025, and AI is stepping in. Data scraping isn't just for programmers or simple automation anymore.
Traditional Methods Are Failing
Modern websites are also throwing more challenges our way: dynamic content loading (like with React/Vue frameworks), the rise of multimodal data (text, video, images), and non-standardized data structures (multiple templates on the same page). Recent studies point out three big issues with traditional web scraping methods:
-
Maintenance Cost Black Hole Traditional web scrapers need constant manual upkeep (about 3-5 hours a month per website). When a site updates or changes its front-end framework, 60% of XPath selectors fail. AI tools, with their language models and code smarts, can automatically adjust to 90% of structural changes, slashing maintenance costs by 60-80%. For modern sites built with React/Vue, AI tools keep data scraping stable through semantic understanding, even when class names change.
-
Limited Data Dimensions Traditional methods can only grab structured data, missing out on valuable info like:
- Data within images
- Textual data within articles
- Unstructured data without HTML tags
-
Data Quality Issues Traditional methods struggle with dynamic content, leading to incomplete or incorrect data:
- For paginated data (like e-commerce product lists), traditional scrapers capture only 30-50% of the first screen's content.
- Infinite scrolling pages (like social media feeds) lose over 60% of critical data.
- High error rates in matching unstructured data (misaligned list data).
This is where AI-driven tools like Thunderbit come into play. I'll break down their benefits below.
The Rise of AI Data Scraping
Scrape data from any website using AI Get Started Free
By 2025, AI, especially large language models (LLMs), have shown some serious skills. These models can understand and generate natural language, tackle complex data analysis tasks, and offer more efficient solutions. Many data scraping tools now use LLMs to get past the limitations of traditional methods. After checking out 13 data scraping tools over the past few months, I recommend Thunderbit AI Web Scraper.
Here's why Thunderbit is a standout:
-
Revolutionary Interaction: Users can type in simple natural language commands, and the system automatically creates a scraping plan, cutting down configuration time by 87% compared to traditional tools.
-
Significant Advantages of Localized Scraping: As a browser extension, Thunderbit offers:
- Instant data scraping
- Scraping of dynamic and infinite scrolling pages
- Scraping of login-required pages
-
Powerful Multimodal Data Processing: Thunderbit can handle various data types, such as:
- Extracting data from text within articles
- Extracting financial data tables from PDFs
- Recognizing data from multiple images and forming tables
- Scraping video subtitles and summarizing them
With Thunderbit, you can easily tackle various data collection scenarios. Let's explore how to use Thunderbit.
How to Data Scrape Using AI
Follow these four steps to tap into Thunderbit's powerful AI web scraping capabilities:
-
Install the Browser Extension Head over to the Thunderbit website and download the Thunderbit extension from the Chrome Web Store. Once it's installed, pin the extension to your browser toolbar.
-
Register and Get Free Credits Sign up within the extension to snag some trial credits. These credits let you try out core features like AI web scraping, form autofill, and smart summarization. It's a good idea to first play around with the tool in the playground for free before using the credits to see how effective it is.
-
Initiate Smart Scraping Launch a template from Thunderbit's sidebar. Use language descriptions to pick the data content and type you want, set specific extraction formats, or tweak other details. Then hit the scrape button to start data scraping.
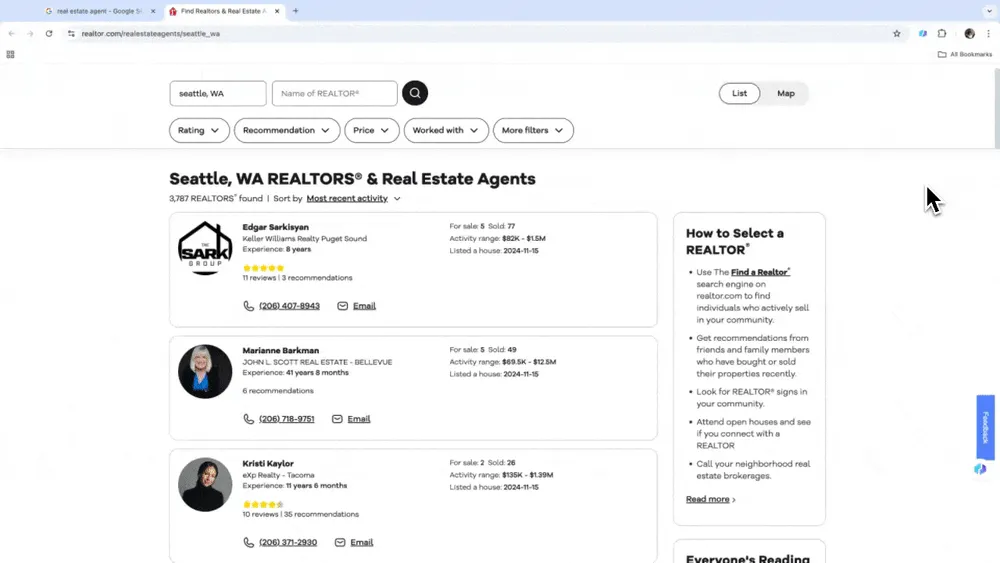
Advanced Scraping Features (Pro Tier)
By subscribing to Thunderbit's Pro Tier (or starting a Free Trial), you'll unlock these features:
-
Multimodal Data Processing Handles complex scenarios like PDF document parsing (financial reports/product manuals), image data extraction (price tags/spec sheets), and video subtitle scraping. The system automatically standardizes unstructured data.
-
Deep Subpage Scraping Optionally access all sublinks on a page (like product detail pages/user review pages), intelligently recognize related data, and automatically merge it into the main data table. Perfect for e-commerce product catalogs, real estate listings, and more.
-
Pre-built Template Library Instantly use optimized scraping templates for over 30 platforms like TikTok, Amazon, and Zillow, automatically adapting to page structure changes. New users save an average of 83% in configuration time.
-
Bulk Scraping Task Run multiple scraping tasks at once, supporting URL list imports for batch scraping.
-
Intelligent Pagination Handling Automatically recognize and scrape paginated content (including "load more" buttons and page navigation), supporting infinite scrolling pages. Tested to fully scrape over 200 pages of e-commerce product lists.
Thunderbit Practical Guide
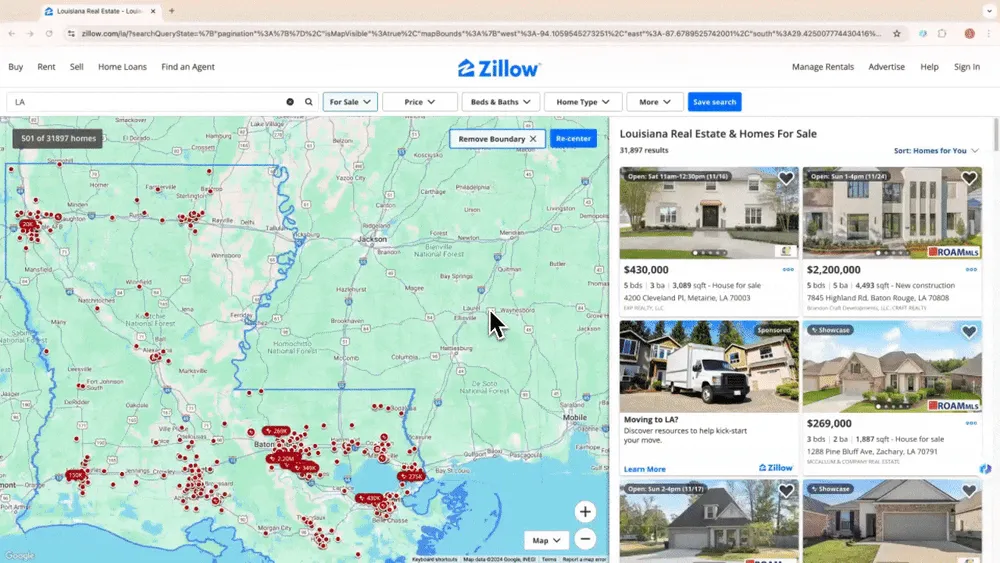
Scenario 1: Real Estate Data Collection
If you're a real estate agent looking to gather property data from Zillow, or an investor seeking profitable opportunities, a reliable web scraper can be your best ally. Thunderbit's AI web scraper allows you to easily extract crucial property information from Zillow, keeping you updated and competitive. Check out a tutorial video on how to scrape Zillow using Thunderbit.
Scenario 2: Talent and Client Prospecting
If you're in HR searching for talent or a salesperson seeking new leads, a reliable web scraper can be a powerful assistant. Thunderbit enables you to extract useful contact and company data from public websites, directories, and profile pages, helping you streamline talent search and lead management. After using it, you'll find that time-consuming manual searches and copy-pasting are a thing of the past. For a ready-to-use workflow, start with the Website Contact Scraper.
Scenario 3: Market Analysis and Customer Targeting
If you're a business owner collecting location-based data for market analysis, or a sales professional seeking local business leads, a reliable web scraper can change the game. Thunderbit allows you to easily extract key data from Google Maps, helping you make informed decisions and optimize your outreach.
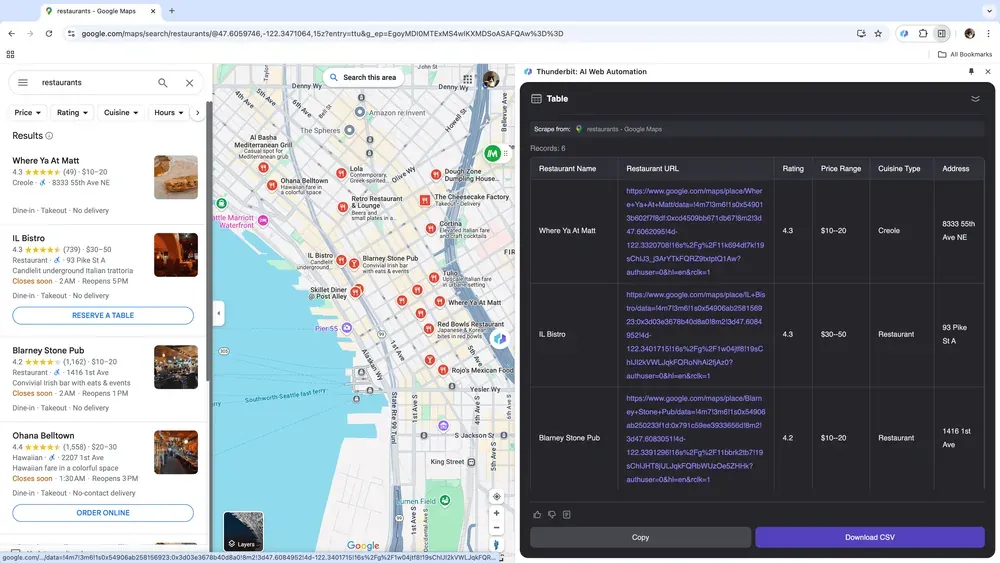
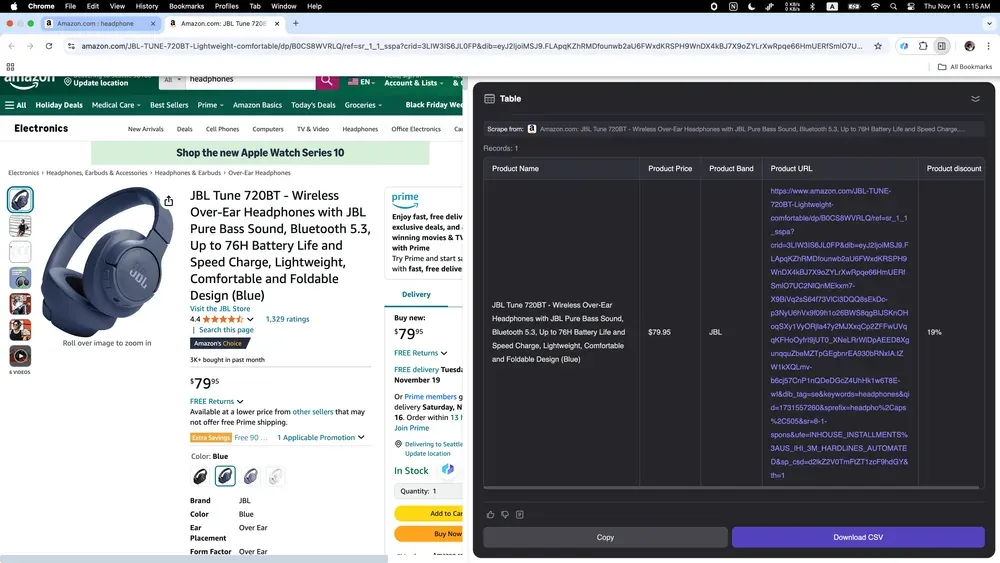
Scenario 4: E-commerce Data Analysis
If you're an online seller wanting to understand competitors or an entrepreneur tracking market trends, Thunderbit is your perfect tool! It can easily collect various product data from Amazon, including detailed descriptions, prices, and user reviews.
Thunderbit AI web scraper redefines how business users collect data, making it faster, simpler, and more efficient than ever. Whether you're searching for properties in the real estate market, seeking potential clients in the talent market, or analyzing trends in the e-commerce market, AI web scrapers can save you countless hours and hassle. Embrace the power of AI in web scraping and witness a leap in your productivity. Ready to get started? Try Thunderbit and take the first step towards smarter web scraping.
Exclusive Data Cleaning Tips
With traditional scrapers, the real challenge begins after data scraping—data cleaning. Thunderbit's AI can perform data cleaning during data scraping using LLM, reducing data cleaning workload by 83% through the following innovative features:
Tip 1: Intelligent Field Alignment
When dealing with multi-source heterogeneous data (like scraping LinkedIn and Zillow simultaneously), Thunderbit's AI automatically establishes semantic mapping relationships:
- Automatically identifies field correspondences across different data sources (e.g., "price" ↔ "售价" ↔ "Price")
- Intelligently merges similar fields (e.g., "area" and "square feet")
- Cross-platform data standardization (e.g., LinkedIn's "current position" and Zillow's "property status" unified as tag data)
Tip 2: Context-Aware Completion
With the contextual understanding capabilities of large language models, Thunderbit achieves an industry-leading 99% data fill rate:
- Address completion: Automatically fills city/state information based on zip code (e.g., input 10001 → New York City, NY)
- Career path inference: Predicts possible work experiences based on LinkedIn education background
Tip 3: Data Optimization
- Multilingual translation (supports real-time translation in 12 languages, including English, Chinese, and Japanese)
- Intelligent summarization (condenses a 500-word product description into three key selling points)
- Unit unification (automatically converts square feet ↔ square meters, Fahrenheit ↔ Celsius)
- Format standardization (dates unified to YYYY-MM-DD, currency unified to USD)
Tip 4: Quality Verification
- Intelligent error correction: Automatically fixes format errors (e.g., phone number +01 138-1234-5678 → +113812345678)
- Logical validation: Ensures "year built" is earlier than "last renovation time"
Tip 5: AI Tagging
Automatically generates intelligent tags through natural language processing:
- Sentiment analysis tags (automatically labels customer reviews as positive/negative/neutral)
- Business value tags (automatically labels "high-potential clients"/"properties to follow up on")
- Industry classification tags (automatically tags LinkedIn profiles with "tech|finance|healthcare" labels)
The Downside of Data Scraping
While data scraping offers tremendous value, it's important to acknowledge the hurdles businesses may encounter. Legal considerations sit at the forefront - regulations like GDPR and CCPA impose strict requirements on data collection practices, requiring careful compliance with privacy laws. Websites often deploy sophisticated defenses like Cloudflare to detect and block scraping activities through IP restrictions.
The Future of Data Scraping in AI Era
The evolution of AI is transforming web scraping into an intuitive enterprise solution. Imagine simply entering a domain (like zillow.com) and your request (like "scrape all property listings in New York City"), watching the AI automatically map out every relevant data point - from property details to pricing trends - without manual configuration. These intelligent systems will seamlessly integrate scraped data into business workflows, automatically feeding LinkedIn prospect information into CRMs or pushing e-commerce metrics into analytics dashboards. Advanced pattern recognition will enable predictive scraping capabilities that proactively monitor for inventory changes or emerging market trends. Crucially, AI will handle compliance dynamically, adapting scraping parameters in real-time to meet evolving regulations while maintaining transparent audit trails.
The AI-driven paradigm shift not only democratizes access to critical business intelligence but fundamentally reimagines how organizations interact with web data. As these technologies mature, early adopters who implement AI-powered scraping solutions like Thunderbit will gain decisive competitive advantages in data-driven decision making.
FAQs
-
What is Thunderbit? Thunderbit is a smart browser extension based on large language models (LLM), designed for modern data collection needs. It not only offers AI web scraping capabilities but also integrates multimodal data processing, supporting comprehensive data extraction from dynamic web pages, PDF documents, images, and videos. As a localized browser solution, it can directly handle login-required pages (like LinkedIn) and automatically adapt to modern front-end framework changes.
-
How does Thunderbit's AI web scraper work? Thunderbit's AI web scraper uses AI to extract structured data from websites. Users can click "AI Suggest Columns" to let AI suggest how to scrape the current site, then click "Scrape" to collect data. It can process data from any website, PDF, or image in just two clicks.
-
What's the difference between list scraping and subpage scraping? List scraping is optimized for paginated scenarios (like e-commerce product lists), automatically recognizing pagination logic and scraping thousands of data entries. Subpage scraping uses a tree structure collection mode (like Zillow property listings → detail pages → floor plans), automatically establishing main-sub table relationships through semantic association.
-
Can non-programmers use Thunderbit? Thunderbit features a natural language interaction design: users simply describe their needs, like "name, email, phone," and the system automatically generates a scraping plan. Our test data shows that 85% of users complete their first data collection within 10 minutes, without any web programming knowledge.
-
What types of data can Thunderbit handle? Thunderbit supports intelligent recognition of many data types:
- Structured data: tables, lists (e.g., Amazon product specifications)
- Unstructured data: review text, PDF documents (automatic recognition)
- Multimodal data: price tags in images, video subtitle extraction
- Dynamic data: infinite scrolling content, lazy-loading images
- Related data: cross-page relationship mapping (e.g., LinkedIn contacts → company information)
-
How to start using Thunderbit? Learn more about our scraping capabilities or explore our template library to get started immediately.
Learn More:
- The Best Web Scraping Tools & Software in 2025
- How to Scrape Any Website Using AI
- How to set up Thunderbit
Try AI Web Scraper Get Started Free




