
It’s 2026, and if you’re in sales, operations, or just about any business function, you’ve probably noticed that the web is both your best friend and your biggest time sink. There’s more valuable information out there than ever before—leads, prices, reviews, competitor moves—but actually getting that content into a spreadsheet or dashboard? That’s where things get interesting. I’ve seen teams spend hours copy-pasting, only to end up with messy, outdated data and a serious case of spreadsheet fatigue.

But here’s the good news: scraping content from other websites doesn’t have to be a chore reserved for developers or data scientists. With the rise of AI-powered, no-code tools like , even non-technical users can grab the data they need—fast, accurately, and without the drama. In this guide, I’ll walk you through what web scraping really means, why it’s become essential for modern business, and how you can start scraping content from websites efficiently (and legally) in 2026. Whether you’re a total beginner or just looking to level up your workflow, you’re in the right place.
What Does "Scraping Content from Other Websites" Mean?
Let’s break it down: scraping content from other websites simply means using software to automatically extract information from web pages and organize it into a structured format—think tables, spreadsheets, or databases. Instead of manually copying and pasting product details, business contacts, or reviews, a scraper does the heavy lifting for you ().
Here’s a quick analogy: imagine you’re at a library, and instead of taking notes by hand from every book, you have a robot assistant who scans the pages and hands you a neatly organized summary. That’s what web scraping does for the internet.
Why do people scrape content from websites?
- Lead generation: Pulling names, emails, and phone numbers from directories or business listings.
- Competitor analysis: Monitoring prices, product launches, or reviews on ecommerce sites.
- Market research: Aggregating news, blog posts, or forum discussions to spot trends.
- Content aggregation: Gathering articles or resources for newsletters or internal knowledge bases.
The difference between manual copy-paste and automated scraping is night and day: scraping is faster, more accurate, and scales to thousands of pages in minutes ().
Why Scraping Content from Other Websites Matters for Business Users
If you’re still relying on manual research, you’re missing out on the speed and intelligence that modern teams are using to get ahead. Data-driven companies are , and by 2026, will be fully data-driven.
Here’s how scraping content from other websites delivers real business value:
| Use Case | What to Scrape | Benefit |
|---|---|---|
| Lead generation | Business directories, LinkedIn, Yellow Pages | Build targeted prospect lists, fill your pipeline faster |
| Price monitoring | Competitor product listings, ecommerce sites | Adjust your pricing strategy in real time |
| Customer insights | Reviews, social media posts, forums | Analyze feedback, spot trends, improve products |
| Content aggregation | News sites, blogs, industry forums | Curate industry news, fuel your content marketing |
By automating these tasks, you’re not just saving time—you’re making better, faster decisions and freeing your team to focus on what really matters ().
How to Choose the Right Web Scraping Tool: A Beginner’s Guide
If you’re new to scraping content from other websites, the first big decision is picking the right tool. Here’s what I’ve learned (often the hard way): your choice should depend on your technical comfort, the complexity of your target sites, and how quickly you want to get results.
Main types of web scraping tools:
- Code-based tools (e.g., Python with BeautifulSoup or Scrapy): Maximum flexibility, but you need to code. Best for developers or teams with IT support.
- No-code tools (e.g., ParseHub, Octoparse): Visual interfaces, templates, and point-and-click workflows. Great for non-coders, but can get complex on tricky sites.
- Browser extensions (e.g., Thunderbit, Web Scraper): Run directly in Chrome, easy to install, and perfect for quick, targeted scrapes.
For most business users—especially beginners—ease of use is everything. That’s why I recommend starting with a browser extension like . It’s designed for non-technical users and leverages AI to make setup a breeze.
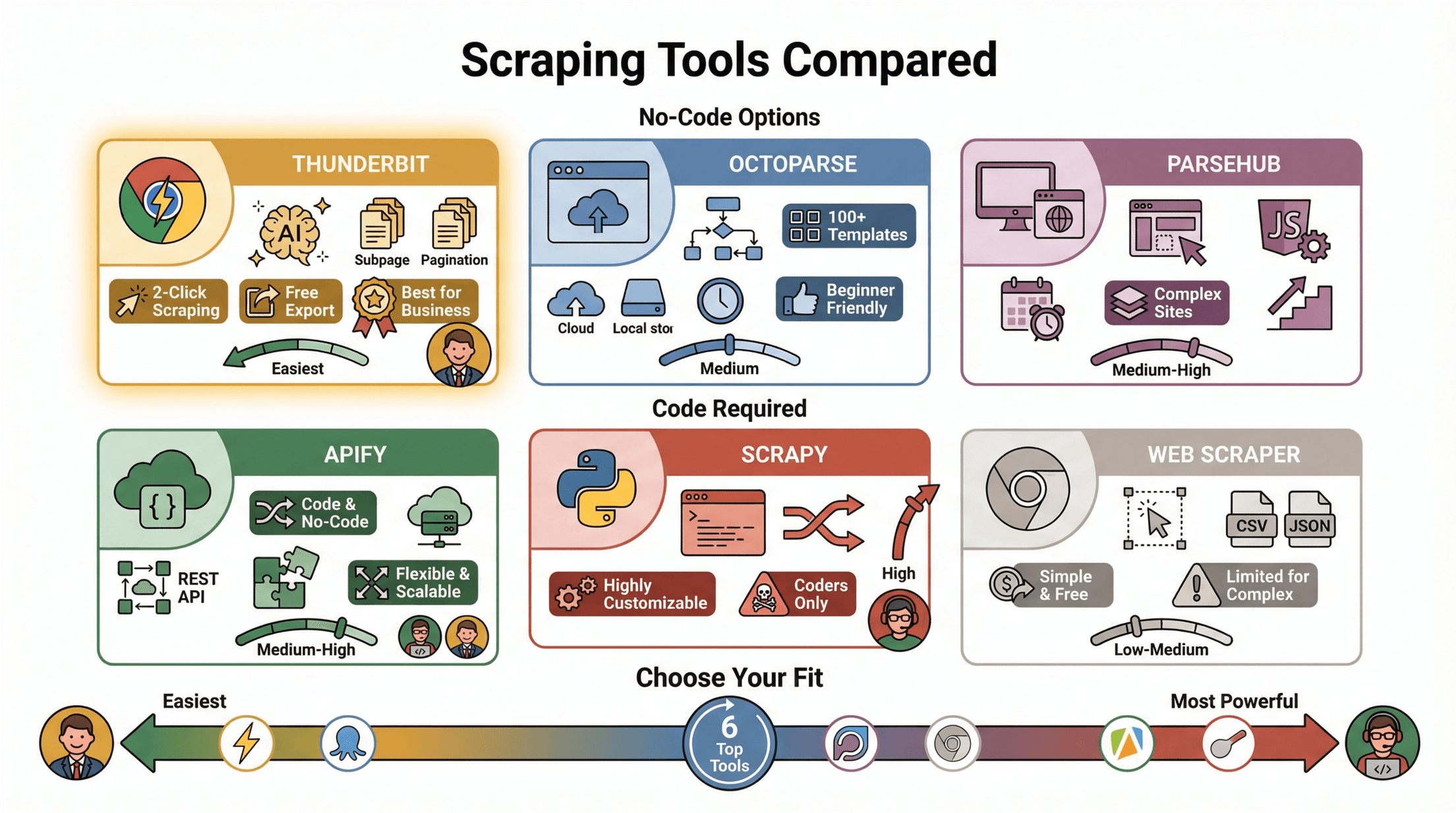
Comparing Popular Web Scraping Tools
Let’s see how some of the top tools stack up for scraping content from other websites:
| Tool | Type | Key Features | Pros / Cons |
|---|---|---|---|
| Thunderbit | Chrome Extension, AI | 2-click scraping, AI field suggestions, subpage & pagination, free export | Super easy, no code, best for business users |
| Octoparse | Desktop App, No-code | Visual workflow, 100+ templates, cloud/local, scheduling | Beginner-friendly, but free tier is limited |
| ParseHub | Desktop/Web, No-code | Visual builder, handles dynamic/JS-heavy pages, scheduling | Good for complex sites, but steeper learning curve |
| Apify | Cloud/Code/No-code | Code & no-code, serverless, REST API, integrations | Flexible, scalable, some tech skill needed |
| Scrapy | Python Library, Code | Asynchronous crawling, highly customizable | Powerful, but for coders only |
| Web Scraper | Chrome Extension, No-code | Visual selection, export CSV/JSON | Simple, free, but limited for complex sites |
For most business users, Thunderbit and Octoparse are the easiest to get started with ().
Thunderbit’s Unique Advantages for Scraping Content from Other Websites
Now, let me put on my Thunderbit hat for a second (okay, it’s more of a digital hoodie): what makes stand out is just how friendly it is for beginners and business users.
Here’s what sets Thunderbit apart:
- Natural language interface: Just describe what you want (“Get all product reviews and ratings from this page”), and Thunderbit’s AI figures out the rest.
- AI Suggest Fields & Improve Fields: Thunderbit scans the page and recommends the best columns to extract—names, prices, emails, you name it. No fiddling with selectors or code.
- 2-click workflow: Click “AI Suggest Fields,” then “Scrape.” That’s it. Even my mom could do it (and she still thinks “the cloud” is just bad weather).
- Subpage and pagination support: Thunderbit can follow links to detail pages (like individual product reviews) and handle multi-page listings automatically.
- Instant export: Push your data straight into Excel, Google Sheets, Airtable, or Notion—no extra steps, no extra cost.
Example: Say you want to extract product reviews from an ecommerce site. Open the reviews page, click the Thunderbit icon, hit “AI Suggest Fields,” and Thunderbit will propose columns like “Reviewer Name,” “Rating,” and “Review Text.” Click “Scrape,” and you’re done. Need more details from each review? Use subpage scraping to grab them all.
Users consistently mention how Thunderbit “handled longer pages better than I expected” and “made scraping dynamic sites a breeze” ().
Extracting Content from Complex Websites: Pagination and Subpage Scraping
Let’s be honest: not all websites make it easy to grab the data you want. Ecommerce platforms, directories, and review sites often use pagination (multiple pages of listings) or nested subpages (like clicking into each product or business for more details).
The challenge: Traditional scrapers often miss data hidden behind “Next” buttons or in subpages. Manual scraping? Forget it—you’ll be clicking for days.
Thunderbit’s solution: The AI detects pagination links or infinite scroll and keeps scraping until it’s got everything. For subpages, Thunderbit can visit each link in your table (like every product or business listing), pull extra fields, and merge them into your main dataset.
Step-by-Step: Scraping Multi-Page and Subpage Content
Here’s how to tackle a complex site with Thunderbit:
- Open the main listing page (e.g., an ecommerce category or directory).
- Click the Thunderbit icon and select “AI Suggest Fields.” Thunderbit will propose columns like “Product Name,” “Price,” “Link.”
- Click “Scrape.” Thunderbit will extract all items on the current page—and automatically follow pagination to get the rest.
- Need more details? Click “Scrape Subpages.” Thunderbit will visit each item’s detail page and pull extra info (like reviews, specs, or contact info).
- Review and export your complete, enriched dataset.
Tip: Use subpage scraping when you see links to “details,” “reviews,” or “contact”—it’s perfect for ecommerce, yellow pages, or real estate listings.
Organizing and Analyzing Extracted Data: Tags, Categories, and Export Options
Scraping content is just the first step. To get real value, you need to organize, analyze, and share your data.
Thunderbit makes this easy:
- Tagging and categorization: Add tags or categories to your fields (e.g., “Product Type,” “Region,” “Lead Status”) so you can filter and analyze later.
- Field AI Prompts: Want to categorize SKUs or translate reviews? Add a custom instruction to the field, and Thunderbit’s AI will handle it as it scrapes.
- Export options: Instantly send your data to Excel, Google Sheets, Airtable, or Notion. You can also download as CSV or JSON for further analysis.
Best practices for organizing your data:
- Use clear, consistent column names.
- Add tags or categories for easy filtering.
- Archive raw scrapes alongside cleaned datasets.
- Set up regular exports or scheduled scrapes for ongoing projects.
Sales teams can label leads by source or status, while operations teams might categorize products by supplier or region. The goal: make your scraped data actionable and easy to share.
Staying Compliant: Legal Considerations When Scraping Content from Other Websites
Before you go wild scraping the web, let’s talk compliance. The good news: scraping public data is generally legal if you follow a few simple rules (, ).
Key compliance tips:
- Scrape only publicly available content. Don’t bypass logins, paywalls, or security measures.
- Respect robots.txt and Terms of Service. While not always legally binding, these indicate the site owner’s wishes.
- Avoid scraping copyrighted or personal data. Stick to factual info (names, prices, specs) and don’t republish large blocks of copyrighted text or images.
- Cite your sources if you use scraped data in reports or publications.
- Throttle your requests to avoid overloading websites.
Checklist for risk-free scraping:
- ✅ Public pages only (no logins)
- ✅ Check robots.txt and TOS
- ✅ No copyrighted or personal data
- ✅ Attribute sources
- ✅ Don’t scrape too fast
Thunderbit encourages responsible scraping by making it easy to target only the data you need and export it for internal use.
Step-by-Step Guide: Scraping Content from Other Websites with Thunderbit
Ready to try it yourself? Here’s how to scrape content from other websites using :
- Install the Thunderbit Chrome Extension: and sign up for a free account.
- Open your target website: Navigate to the page you want to scrape (e.g., product listings, business directory, review page).
- Click the Thunderbit icon: In your Chrome toolbar, click Thunderbit to open the extension.
- Use “AI Suggest Fields”: Thunderbit scans the page and suggests columns to extract (like “Name,” “Price,” “Email”).
- Adjust columns if needed: Rename, add, or remove fields as you like. You can also add custom AI prompts for labeling or categorization.
- Click “Scrape”: Thunderbit extracts the data from the current page—and follows pagination if it’s there.
- Scrape subpages (optional): For more details, click “Scrape Subpages” to grab info from linked pages.
- Review and export: Preview your data, then export to Excel, Google Sheets, Airtable, Notion, or download as CSV/JSON.
Troubleshooting common issues:
- Login-required pages: Use Thunderbit’s Browser Scraping mode while logged in.
- Blocked or slow sites: Try scraping at off-peak times, or break your scrape into smaller batches.
- Dynamic content not loading: Scroll the page fully before scraping, or use Thunderbit’s browser mode.
- Layout changes: Re-run “AI Suggest Fields” to let the AI adapt to new page structures.
If you run into trouble, Thunderbit’s and support team are always ready to help.
Conclusion & Key Takeaways
Scraping content from other websites has gone from a developer’s secret weapon to an everyday business necessity. In 2025, with the explosion of web data and the rise of no-code, AI-powered tools, anyone can extract the information they need—quickly, accurately, and without the headaches.
Here’s what to remember:
- Scraping content from other websites is essential for lead generation, market research, and staying competitive.
- Modern tools like make web scraping accessible to everyone, with natural language prompts, AI field suggestions, and instant exports.
- Thunderbit’s support for pagination, subpage scraping, and data organization means you can handle even the most complex sites.
- Stay compliant: scrape only public data, respect site rules, and avoid copyrighted or personal content.
- Getting started is as easy as installing a Chrome extension and clicking a few buttons.
Ready to leave copy-paste behind? and see how much time (and sanity) you can save on your next web data project. For more tips and tutorials, check out the .
FAQs
1. Is it legal to scrape content from other websites?
Generally, yes—if you stick to publicly available data, respect robots.txt and Terms of Service, and avoid scraping copyrighted or personal information. Always check the rules for each site and use scraped data responsibly ().
2. Do I need to know how to code to scrape content from websites?
No! Tools like are designed for non-technical users. You can extract data with just a few clicks, using natural language prompts and AI-powered field suggestions.
3. What types of websites can I scrape with Thunderbit?
Thunderbit works on a wide range of sites—ecommerce, directories, review platforms, real estate listings, and more. It can handle pagination, subpages, and even dynamic content in most cases.
4. How do I organize and analyze the data I scrape?
Thunderbit lets you tag, categorize, and label your data as you extract it. You can export directly to Excel, Google Sheets, Airtable, or Notion for further analysis and sharing.
5. What should I do if a website blocks my scraper or changes its layout?
Try scraping at a slower rate, use Thunderbit’s Browser Scraping mode, or re-run “AI Suggest Fields” to adapt to new layouts. For persistent issues, consult Thunderbit’s or support team for help.
Happy scraping—and may your spreadsheets always be clean, structured, and ready for action.
Learn More